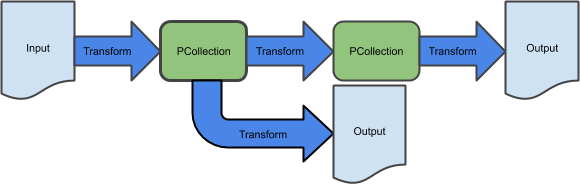
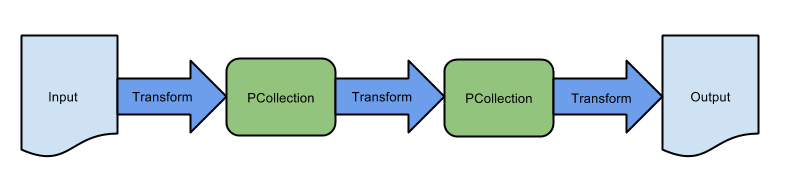
In the previous lab, you created a basic extract-transform-load sequential pipeline and used an equivalent Dataflow Template to ingest batch data storage on Google Cloud Storage. This pipeline consists of a sequence of transformations:
Many pipelines will not exhibit such simple structure though. In this lab, you build a more sophisticated, non-sequential pipeline.
The use case here is to optimize resource consumption. Products vary with respect to how they consume resources. Additionally, not all data is used in the same way within a business; some data will be regularly queried, for example, within analytic workloads, and some data will only be used for recovery.
In this lab, you optimize the pipeline from the first lab for resource consumption, by storing only data that analysts will use in BigQuery while archiving other data in a very-low-cost highly durable storage service, Coldline storage in Google Cloud Storage.
Setup and requirements
For each lab, you get a new Google Cloud project and set of resources for a fixed time at no cost.
Sign in to Qwiklabs using an incognito window.
Note the lab's access time (for example, 1:15:00), and make sure you can finish within that time.
There is no pause feature. You can restart if needed, but you have to start at the beginning.
When ready, click Start lab.
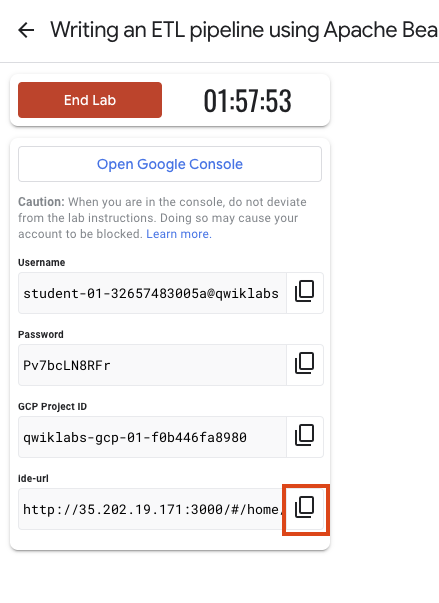
Note your lab credentials (Username and Password). You will use them to sign in to the Google Cloud Console.
Click Open Google Console.
Click Use another account and copy/paste credentials for this lab into the prompts.
If you use other credentials, you'll receive errors or incur charges.
Accept the terms and skip the recovery resource page.
Activate Google Cloud Shell
Google Cloud Shell is a virtual machine that is loaded with development tools. It offers a persistent 5GB home directory and runs on the Google Cloud.
Google Cloud Shell provides command-line access to your Google Cloud resources.
In Cloud console, on the top right toolbar, click the Open Cloud Shell button.
Click Continue.
It takes a few moments to provision and connect to the environment. When you are connected, you are already authenticated, and the project is set to your PROJECT_ID. For example:
gcloud is the command-line tool for Google Cloud. It comes pre-installed on Cloud Shell and supports tab-completion.
You can list the active account name with this command:
[core]
project = qwiklabs-gcp-44776a13dea667a6
Note:
Full documentation of gcloud is available in the
gcloud CLI overview guide
.
Check project permissions
Before you begin your work on Google Cloud, you need to ensure that your project has the correct permissions within Identity and Access Management (IAM).
In the Google Cloud console, on the Navigation menu (), select IAM & Admin > IAM.
Confirm that the default compute Service Account {project-number}-compute@developer.gserviceaccount.com is present and has the editor role assigned. The account prefix is the project number, which you can find on Navigation menu > Cloud Overview > Dashboard.
Note: If the account is not present in IAM or does not have the editor role, follow the steps below to assign the required role.
In the Google Cloud console, on the Navigation menu, click Cloud Overview > Dashboard.
Copy the project number (e.g. 729328892908).
On the Navigation menu, select IAM & Admin > IAM.
At the top of the roles table, below View by Principals, click Grant Access.
Replace {project-number} with your project number.
For Role, select Project (or Basic) > Editor.
Click Save.
Setting up your IDE
For the purposes of this lab, you will mainly be using a Theia Web IDE hosted on Google Compute Engine. It has the lab repo pre-cloned. There is java langauge server support, as well as a terminal for programmatic access to Google Cloud APIs via the gcloud command line tool, similar to Cloud Shell.
To access your Theia IDE, copy and paste the link shown in Google Cloud Skills Boost to a new tab.
Note: You may need to wait 3-5 minutes for the environment to be fully provisioned, even after the url appears. Until then you will see an error in the browser.
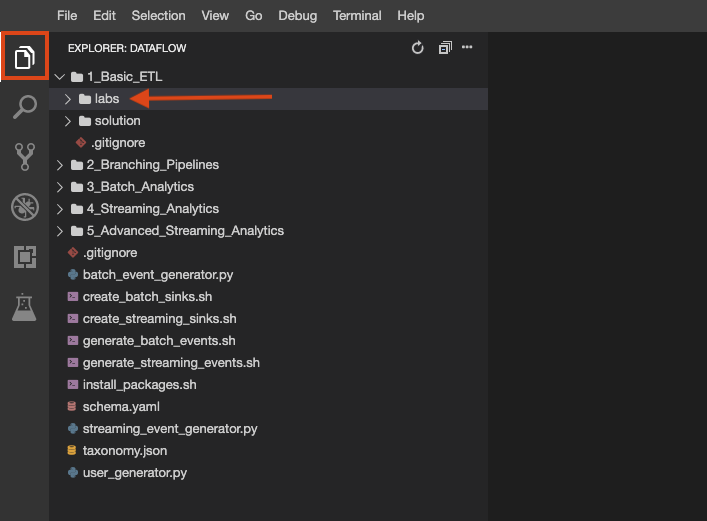
The lab repo has been cloned to your environment. Each lab is divided into a labs folder with code to be completed by you, and a solution folder with a fully workable example to reference if you get stuck.
Click on the File Explorer button to look:
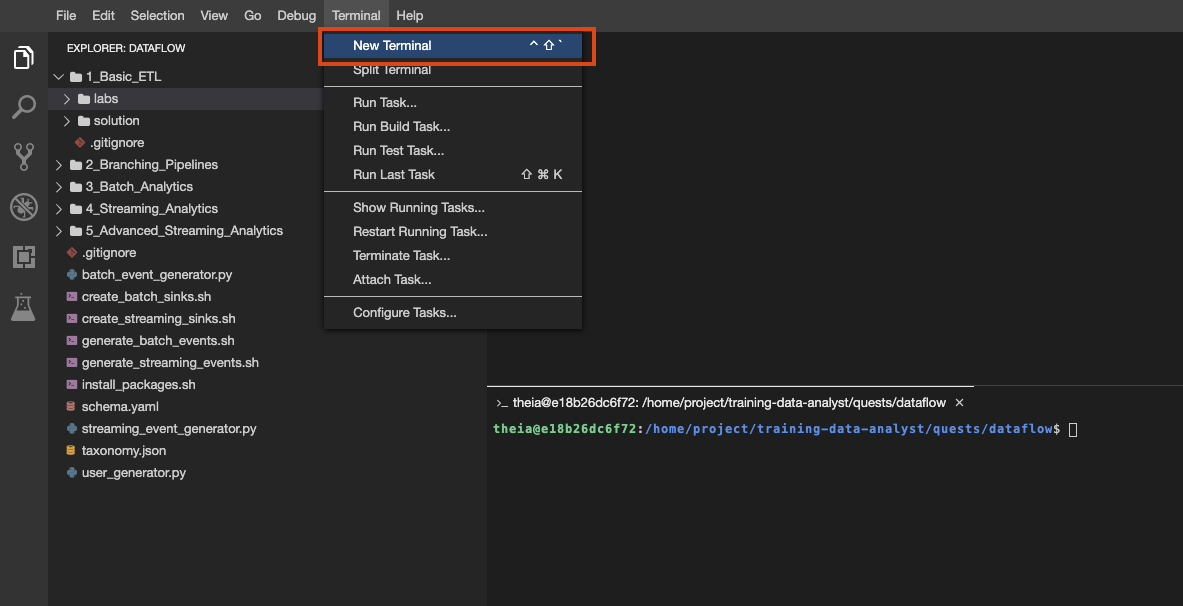
You can also create multiple terminals in this environment, just as you would with cloud shell:
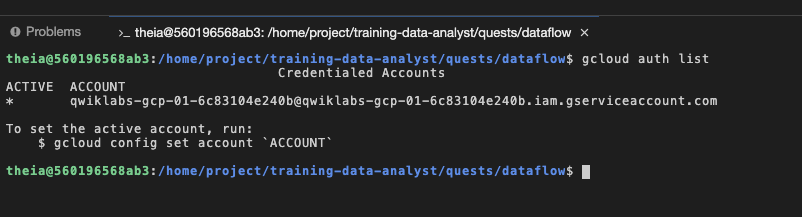
You can see with by running gcloud auth list on the terminal that you're logged in as a provided service account, which has the exact same permissions are your lab user account:
If at any point your environment stops working, you can try resetting the VM hosting your IDE from the GCE console like this:
Multiple transforms process the same PCollection
In this lab, you write a branching pipeline that writes data to both Google Cloud Storage and to BigQuery.
One way of writing a branching pipeline is to apply two different transforms to the same PCollection, resulting in two different PCollections.
If you get stuck in this or later sections, refer to the solution.
Task 1. Add a branch to write to Cloud Storage
To complete this task, modify an existing pipeline by adding a branch that writes to Cloud Storage.
Open the appropriate lab
Create a new terminal in your IDE environment if you haven't already, and then copy and paste the following command:
# Change directory into the lab
cd 2_Branching_Pipelines/labs
# Download dependencies
mvn clean dependency:resolve
export BASE_DIR=$(pwd)
Set up the data environment
# Create GCS buckets and BQ dataset
cd $BASE_DIR/../..
source create_batch_sinks.sh
# Generate event dataflow
source generate_batch_events.sh
# Change to the directory containing the practice version of the code
cd $BASE_DIR
Click Check my progress to verify the objective.
Setup the data environment
Open up MyPipeline.java in your IDE, which can be found in 2_Branching_Pipelines/labs/src/main/java/com/mypackage/pipeline.
Scroll down to the run() method, where the body of the pipeline is defined. It currently looks as follows:
Modify this code by adding a new branching transform that writes to Cloud Storage using TextIO.write() before each element is converted from Json to <CommonLog>.
If you get stuck in this or later sections, refer to the solution, which can be found in the training-data-analyst file
First, why schemas?
Schemas provide us a type-system for Beam records that is independent of any specific programming-language type. There might be multiple Java classes that all have the same schema (for example a Protocol-Buffer class or a POJO class), and Beam will allow us to seamlessly convert between these types. Schemas also provide a simple way to reason about types across different programming-language APIs.
A PCollection with a schema does not need to have a Coder specified, as Beam knows how to encode and decode Schema rows. Beam uses a special coder to encode schema types. Before the introduction of the Schema API, Beam would have to know how to encode all objects in the pipeline.
Task 2. Filter data by field
At the moment, the new pipeline doesn’t actually consume less resources, since all data are being stored twice. To start improving resource consumption, we need to reduce the amount of duplicated data. The Google Cloud Storage bucket is intended to function as archival and backup storage, so it’s important that all data be stored there. However, not all data needs to be sent to BigQuery.
Let’s assume that data analysts often look at what resources users access on the website, and how those access patterns differ as a function of geography and time. Only a subset of the fields would be necessary.
While you could write a DoFn that transforms each object and only returns a subset of the fields, Apache Beam provides a rich variety of relational transforms for PCollections that have a schema. The fact that each record is composed of named fields allows for simple and readable aggregations that reference fields by name, similar to the aggregations in a SQL expression.
Select and DropFields are two of these transforms:
Important: Each of these examples will return PCollection<Row> instead of PCollection<MyClass>. The Row class can support any schema and can be considered a generic schematized object. Any PCollection with a schema can be cast as a PCollection of rows.
Both of the above transforms will not return a full CommonLog object, since fields are being removed, and the transform will thus revert to returning a Row. While you could create a new named schema or register an intermediate POJO schema, it's easier to just use Row for the time being.
To complete this task, add the following imports and change the set of fields that are saved in BigQuery so that only those analysts intend to use are sent by adding one of these transforms to the pipeline.
Remember: If you already have the BigQueryIO.<CommonLog>write() method chained, you will need to change it to <Row> because of the new type.
Task 3. Filter data by element
There are many ways of filtering in Apache Beam. The previous task demonstrated one method: using a Schema Transform. In this implementation, you filtered out parts of each element, resulting in a new Row object with a schema and a subset of the fields remaining. You can just as easily be used to filter out entire elements, as in the example below:
purchases.apply(Filter.<MyObject>create()
.whereFieldName(“costCents”, (Long c) -> c > 100 * 20)
.whereFieldName(“shippingAddress.country”, (String c) -> c.equals(“de”));
Note: This Filter transform, org.apache.beam.sdk.schemas.transforms.Filter, is not to be confused with the older, non-schema Filter Function org.apache.beam.sdk.transforms.Filter
To complete this task, first, add the below import statements to your code and then add a Filter transform to the pipeline. You may filter on whatever criteria you wish. You may need to add type hints to your lambda function, i.e. (Integer c) -> c > 100.
The pipeline currently has a number of parameters hard-coded into it, including the path to the input and the location of the table in BigQuery. However, the pipeline would be more useful if it could read any json file in Cloud Storage. Adding this feature requires adding to the set of command-line parameters.
The pipeline currently uses a PipelineOptionsFactory to generate an instance of a custom class called Options, but this class doesn’t change anything from the PipelineOptions class, so it is effectively an instance of PipelineOptions:
public interface Options extends PipelineOptions {
}
public static void main(String[] args) {
Options options = PipelineOptionsFactory.fromArgs(args).withValidation().as(Options.class);
run(options);
}
The PipelineOptions class interprets command-line arguments that follow the format:
--<option>=<value>
However, it is a small set of predefined parameters; you can see the get- functions here.
To add a custom parameter, do two things.
First, add a state variable to the Options class, as in the example below:
public interface Options extends PipelineOptions {
@Description("My custom command line argument.")
@Default.String("DEFAULT")
String getMyCustomOption();
void setMyCustomOption(String myCustomOption);
}
Second, register your interface with PipelineOptionsFactory inside the main() method and then pass the interface when creating the PipelineOptions object. When you register your interface with PipelineOptionsFactory, the --help can find your custom options interface and add it to the output of the --help command. PipelineOptionsFactory will also validate that your custom options are compatible with all other registered options.
The following example code shows how to register your custom options interface with PipelineOptionsFactory:
To complete this task, first add the following import statements and then add command-line parameters for the input path, the Google Cloud Storage output path, and the BigQuery table name and update the pipeline code to access those parameters instead of constants.
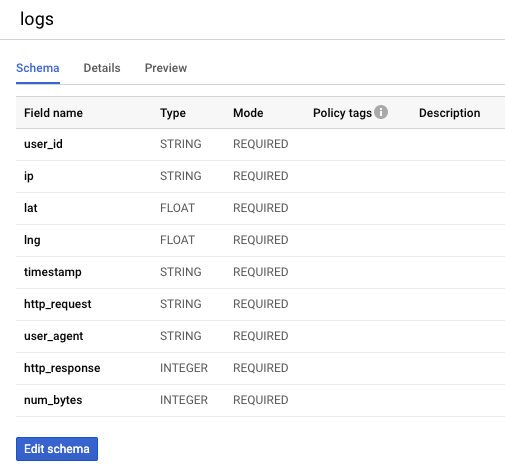
You may have noticed that the BigQuery table created in the last lab had a schema with all REQUIRED fields like this:
It may be desirable to create an Apache Beam schema with NULLABLE fields where data is missing, both for the pipeline execution itself and then a resulting BigQuery table with a schema that reflects this.
Javax notations can be added to your Class definition, which are then incorporated into the Apache Beam schema like this:
@DefaultSchema(JavaFieldSchema.class)
class MyClass {
int field1;
@javax.annotation.Nullable String field2;
}
To complete this task, mark the lat and lon fields as nullable in the class definition.
Task 6. Run your pipeline from the command line
To complete this task, run your pipeline from the command line and pass the appropriate parameters. Remember to take note of the resulting BigQuery schema for NULLABLE fields. Your code should look something like this:
# Set up environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION={{{ project_0.default_region | "REGION" }}}
export BUCKET=gs://${PROJECT_ID}
export COLDLINE_BUCKET=${BUCKET}-coldline
export PIPELINE_FOLDER=${BUCKET}
export MAIN_CLASS_NAME=com.mypackage.pipeline.MyPipeline
export RUNNER=DataflowRunner
export INPUT_PATH=${PIPELINE_FOLDER}/events.json
export OUTPUT_PATH=${PIPELINE_FOLDER}-coldline
export TABLE_NAME=${PROJECT_ID}:logs.logs_filtered
cd $BASE_DIR
mvn compile exec:java \
-Dexec.mainClass=${MAIN_CLASS_NAME} \
-Dexec.cleanupDaemonThreads=false \
-Dexec.args=" \
--project=${PROJECT_ID} \
--region=${REGION} \
--stagingLocation=${PIPELINE_FOLDER}/staging \
--tempLocation=${PIPELINE_FOLDER}/temp \
--runner=${RUNNER} \
--inputPath=${INPUT_PATH} \
--outputPath=${OUTPUT_PATH} \
--tableName=${TABLE_NAME}"
Note: If your pipeline is building successfully, but you're seeing a lot of errors due to code or misconfiguration in the Dataflow service, you can set RUNNER back to 'DirectRunner' to run it locally and receive faster feedback. This approach works in this case because the dataset is small and you are not using any features that aren't supported by DirectRunner.
Task 7. Verify the pipeline’s results
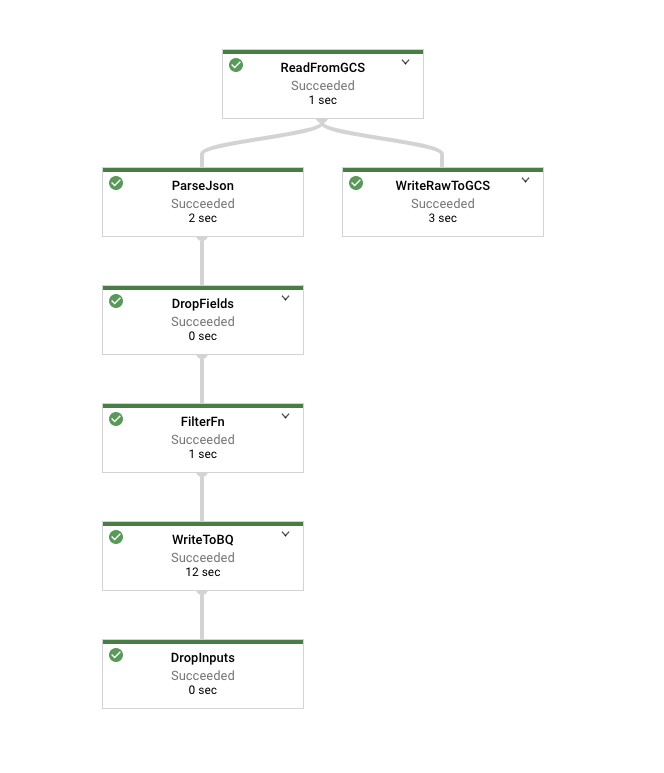
Navigate to the Dataflow Jobs page and look at the job as it’s running. Its graph should resemble the following:
Click on the node representing your Filter function, which in the above picture is called FilterFn. In the panel that appears on the right hand side, you should see that more elements were added as inputs than were written as outputs.
Now click on the node representing the write to Cloud Storage. Since all elements were written, this number should agree with the number of elements in the input to the Filter function.
Once pipeline has finished, examine the results in BigQuery by querying your table. Note that the number of records in the table should agree with the number of elements that were output by the Filter function.
Click Check my progress to verify the objective.
Run your pipeline from the command line
End your lab
When you have completed your lab, click End Lab. Google Cloud Skills Boost removes the resources you’ve used and cleans the account for you.
You will be given an opportunity to rate the lab experience. Select the applicable number of stars, type a comment, and then click Submit.
The number of stars indicates the following:
1 star = Very dissatisfied
2 stars = Dissatisfied
3 stars = Neutral
4 stars = Satisfied
5 stars = Very satisfied
You can close the dialog box if you don't want to provide feedback.
For feedback, suggestions, or corrections, please use the Support tab.
Copyright 2022 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Ouvrez une fenêtre de navigateur en mode navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
In this lab you a) implement a pipeline that has branches b) filter data before write c) add custom command line parameters to a pipeline
Durée :
1 min de configuration
·
Accessible pendant 120 min
·
Terminé après 120 min


 ), select IAM & Admin > IAM.
), select IAM & Admin > IAM.