GSP1050

總覽
Cloud Spanner 是 Google 全代管、可水平擴充的關聯式資料庫服務。金融服務、遊戲、零售業和許多其他產業的客戶都信任 Cloud Spanner,會使用這項服務執行最嚴苛的工作負載,確保大規模作業的一致性和可用性。
在本實驗室中,您將回顧 Cloud Spanner 的結構定義相關功能,並將這些功能套用至銀行作業資料庫。另外,您也將回顧 Cloud Spanner 建立查詢計畫的方法和規則。
學習內容
在本實驗室中,您將瞭解如何修改 Cloud Spanner 執行個體的結構定義相關屬性。
- 將資料載入資料表
- 使用預先定義的 Python 用戶端程式庫程式碼載入資料
- 以用戶端程式庫查詢資料
- 更新資料庫結構定義
- 新增次要索引
- 檢查查詢計畫
設定和需求
瞭解以下事項後,再點選「Start Lab」按鈕
請詳閱以下操作說明。實驗室活動會計時,且中途無法暫停。點選「Start Lab」後就會開始計時,顯示可使用 Google Cloud 資源的時間。
您將在真正的雲端環境完成實作實驗室活動,而不是模擬或示範環境。為此,我們會提供新的暫時憑證,供您在實驗室活動期間登入及存取 Google Cloud。
為了順利完成這個實驗室,請先確認:
- 可以使用標準的網際網路瀏覽器 (Chrome 瀏覽器為佳)。
注意事項:請使用無痕模式 (建議選項) 或私密瀏覽視窗執行此實驗室,這可以防止個人帳戶和學員帳戶之間的衝突,避免個人帳戶產生額外費用。
- 是時候完成實驗室活動了!別忘了,活動一旦開始將無法暫停。
注意事項:務必使用實驗室專用的學員帳戶。如果使用其他 Google Cloud 帳戶,可能會產生額外費用。
如何開始實驗室及登入 Google Cloud 控制台
-
按一下「Start Lab」按鈕。如果實驗室會產生費用,請在開啟的對話方塊中選取付款方式。右側的「Lab setup and access」面板會顯示下列項目:
- 「Open Google Cloud console」按鈕
- 此實驗室所需的臨時憑證 (使用者名稱和密碼)
- 完成此實驗室所需的其他資訊 (如有)
請注意,實驗室計時器位於頁面頂端附近,會顯示剩餘時間。
-
按一下「Open Google Cloud console」。如果使用 Chrome 瀏覽器,也可以按一下滑鼠右鍵,選取「在無痕視窗中開啟連結」。
接著,實驗室會啟動相關資源,並開啟另一個分頁,顯示「登入」頁面。
提示:您可以在不同的視窗並排開啟分頁。
注意:頁面顯示「選擇帳戶」對話方塊時,請點選「使用其他帳戶」。
-
如有必要,請將下方的 Username 貼到「登入」對話方塊。
{{{user_0.username | "Username"}}}
您也可以在「Lab setup and access」面板找到「Username」。
-
點選「下一步」。
-
複製下方的 Password,並貼到「歡迎使用」對話方塊。
{{{user_0.password | "Password"}}}
您也可以在「Lab setup and access」面板找到「Password」。
-
點選「下一步」。
重要事項:請務必使用實驗室提供的憑證,而非自己的 Google Cloud 帳戶憑證。
注意:如果使用自己的 Google Cloud 帳戶來進行這個實驗室,可能會產生額外費用。
-
繼續點按後續頁面:
- 接受條款及細則。
- 由於這是臨時帳戶,請勿新增救援選項或雙重驗證機制。
- 請勿申請免費試用。
Google Cloud 控制台稍後會在這個分頁開啟。
注意:如要使用 Google Cloud 產品和服務,請按一下「導覽選單」,或在「搜尋」欄位輸入服務或產品名稱。
啟動 Cloud Shell
Cloud Shell 是搭載多項開發工具的虛擬機器,提供永久的 5 GB 主目錄,而且在 Google Cloud 中運作。Cloud Shell 提供指令列存取權,方便您使用 Google Cloud 資源。
-
點按 Google Cloud 控制台頂端的「啟用 Cloud Shell」圖示  。
。
-
系統顯示視窗時,請按照下列步驟操作:
- 繼續操作 Cloud Shell 視窗。
- 授權 Cloud Shell 使用您的憑證發出 Google Cloud API 呼叫。
連線建立完成即代表已通過驗證,而且專案已設為您的 Project_ID:。輸出內容中有一行文字,宣告本工作階段的 Project_ID:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud 是 Google Cloud 的指令列工具,已預先安裝於 Cloud Shell,並支援 Tab 鍵自動完成功能。
- (選用) 您可以執行下列指令來列出使用中的帳戶:
gcloud auth list
- 點按「授權」。
輸出內容:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (選用) 您可以使用下列指令來列出專案 ID:
gcloud config list project
輸出內容:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
注意:如需 gcloud 的完整說明,請前往 Google Cloud 參閱 gcloud CLI 總覽指南。
Cloud Spanner 執行個體
為了方便您更快完成本實驗室,系統已自動為您建立 Cloud Spanner 執行個體、資料庫和資料表。
以下列出詳細資料供您參考:
| 項目 |
名稱 |
詳細資料 |
| Cloud Spanner 執行個體 |
banking-ops-instance |
這是專案層級執行個體 |
| Cloud Spanner 資料庫 |
banking-ops-db |
這是執行個體專屬資料庫 |
| 資料表 |
Portfolio |
包含頂層銀行服務 |
| 資料表 |
Category |
包含第二層銀行服務分組 |
| 資料表 |
Product |
包含具體銀行服務明細項目 |
| 資料表 |
Campaigns |
包含行銷計畫的詳細資料 |
工作 1:將資料載入資料表
banking-ops-db 資料庫已建立,但資料表為空白。請按照下列步驟,將資料載入 Portfolio、Category 和 Product 這三個資料表。
-
開啟 Cloud 控制台導覽選單 ( ) >「查看所有產品」,然後在「資料庫」下方點選「Spanner」。
) >「查看所有產品」,然後在「資料庫」下方點選「Spanner」。
-
執行個體名稱為 banking-ops-instance,點選該名稱即可探索資料庫。
-
相關資料庫名稱為 banking-ops-db。點按該名稱,然後向下捲動至「資料表」,即可看到已建立的四份資料表。
-
點選控制台左窗格中的「Spanner Studio」,接著點選右窗格中的「+ 開啟新的 SQL 編輯器分頁」按鈕。
-
系統會將您導向「查詢」頁面。貼上以下 INSERT 陳述式做為單一區塊,載入 Portfolio 資料表。Spanner 將接連執行各個陳述式。請點選「執行」:
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (1, "Banking", "Bnkg", "All Banking Business");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (2, "Asset Growth", "AsstGrwth", "All Asset Focused Products");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (3, "Insurance", "Ins", "All Insurance Focused Products");
-
螢幕頁面下方會顯示逐一插入資料列的結果,插入的各個資料列也會顯示綠色勾號。Portfolio 資料表現在會有三列資料。
-
點按頁面頂端的「清除」。
-
貼上以下 INSERT 陳述式做為單一區塊,載入 Category 資料表。接著點選「執行」:
insert into Category (CategoryId,PortfolioId,CategoryName) values (1,1,"Cash");
insert into Category (CategoryId,PortfolioId,CategoryName) values (2,2,"Investments - Short Return");
insert into Category (CategoryId,PortfolioId,CategoryName) values (3,2,"Annuities");
insert into Category (CategoryId,PortfolioId,CategoryName) values (4,3,"Life Insurance");
-
螢幕頁面下方會顯示逐一插入資料列的結果,插入的各個資料列也會顯示綠色勾號。Category 資料表現在會有四列資料。
-
點按頁面頂端的「清除」。
-
貼上以下 INSERT 陳述式做為單一區塊,載入 Product 資料表。接著點選「執行」:
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (1,1,1,"Checking Account","ChkAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (2,2,2,"Mutual Fund Consumer Goods","MFundCG","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (3,3,2,"Annuity Early Retirement","AnnuFixed","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (4,4,3,"Term Life Insurance","TermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (5,1,1,"Savings Account","SavAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (6,1,1,"Personal Loan","PersLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (7,1,1,"Auto Loan","AutLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (8,4,3,"Permanent Life Insurance","PermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (9,2,2,"US Savings Bonds","USSavBond","Investment LOB");
-
螢幕頁面下方會顯示逐一插入資料列的結果,插入的各個資料列也會顯示綠色勾號。Product 資料表現在會有九列資料。
-
點選「Check my progress」確認目標已達成。
將資料載入 Portfolio、Category 和 Product 資料表
工作 2:使用預先建構的 Python 用戶端程式庫程式碼載入資料
您將使用以 Python 編寫的用戶端程式庫,完成接下來的幾個步驟。
- 開啟 Cloud Shell 並貼上以下指令,即可建立並更改為新目錄,以存放所需檔案。
mkdir python-helper
cd python-helper
- 接著下載兩個檔案。其中一個會用於設定環境,另一個則是實驗室程式碼。
wget https://storage.googleapis.com/cloud-training/OCBL373/requirements.txt
wget https://storage.googleapis.com/cloud-training/OCBL373/snippets.py
- 建立獨立的 Python 環境,並安裝 Cloud Spanner 用戶端依附元件。
pip install -r requirements.txt
pip install setuptools
-
snippets.py 為整合式檔案,其中包含多個您將在本實驗室用到的 Cloud Spanner DDL、DML 和 DCL 輔助函式。請使用 insert_data 引數執行 snippets.py,將資料載入 Campaigns 資料表。
python snippets.py banking-ops-instance --database-id banking-ops-db insert_data
- 點選「Check my progress」確認目標已達成。
將資料載入 Campaigns 資料表
工作 3:以用戶端程式庫查詢資料
snippets.py 中的 query_data() 函式可用來查詢資料庫。在本例中,您將使用這個函式確認資料已載入 Campaigns 資料表。您不會變更任何程式碼,以下顯示該區段供您參考。
def query_data(instance_id, database_id):
"""使用 SQL 在資料庫中查詢範例資料。"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
results = snapshot.execute_sql(
"SELECT CampaignId,PortfolioId,CampaignStartDate,CampaignEndDate,CampaignName,CampaignBudget FROM Campaigns"
)
for row in results:
print(u"CampaignId: {}, PortfolioId: {}, CampaignStartDate: {}, CampaignEndDate: {}, CampaignName: {}, CampaignBudget: {}".format(*row))
- 使用 query_data 引數執行 snippets.py,來查詢 Campaigns 資料表。
python snippets.py banking-ops-instance --database-id banking-ops-db query_data
結果應大致如下:
CampaignId: 1, PortfolioId: 1, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: New Account Reward, CampaignBudget: 15000
CampaignId: 2, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Intro to Investments, CampaignBudget: 5000
CampaignId: 3, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Youth Checking Accounts, CampaignBudget: 25000
CampaignId: 4, PortfolioId: 3, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Protect Your Family, CampaignBudget: 10000
工作 4:更新資料庫結構定義
身為資料庫管理員,您須負責在 Category 資料表新增 MarketingBudget 的資料欄。不過,您須更新資料庫結構定義,才能在現有資料表新增資料欄。Cloud Spanner 可支援更新資料庫結構定義,同時讓資料庫持續處理流量。結構定義更新作業不需要讓資料庫離線,也不會鎖定整個資料表或資料欄;您可以在結構定義更新期間,持續將資料寫入資料庫。
使用 Python 新增資料欄
您將透過 Database 類別的 update_ddl() 方法修改結構定義。
使用 snippets.py 中的 add_column() 函式,即可實作該方法。您不會變更任何程式碼,以下顯示該區段供您參考。
def add_column(instance_id, database_id):
"""在範例資料庫中的 Albums 資料表新增一個資料欄。"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["ALTER TABLE Category ADD COLUMN MarketingBudget INT64"]
)
print("正在等待作業完成…")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("已新增 MarketingBudget 資料欄。")
- 使用 add_column 引數執行 snippets.py。
python snippets.py banking-ops-instance --database-id banking-ops-db add_column
- 點選「Check my progress」確認目標已達成。
在 Category 資料表新增資料欄
您還可以透過以下其他方法,在現有資料表中新增資料欄:
透過 gcloud CLI 發出 DDL 指令。
注意:這裡舉例示範的方法為備用選項,請勿發出這個指令。
下方的程式碼範例會完成您剛才透過 Python 執行的工作。
gcloud spanner databases ddl update banking-ops-db --instance=banking-ops-instance --ddl='ALTER TABLE Category ADD COLUMN MarketingBudget INT64;'
在 Cloud 控制台發出 DDL 指令。
注意:這裡舉例示範的方法為備用選項,請勿執行這項操作。
- 在資料庫清單中點選資料表名稱。
- 點選頁面右上角的「寫入 DDL」。
- 將適當的 DDL 貼入「DDL 範本」方塊。
- 點選「提交」。
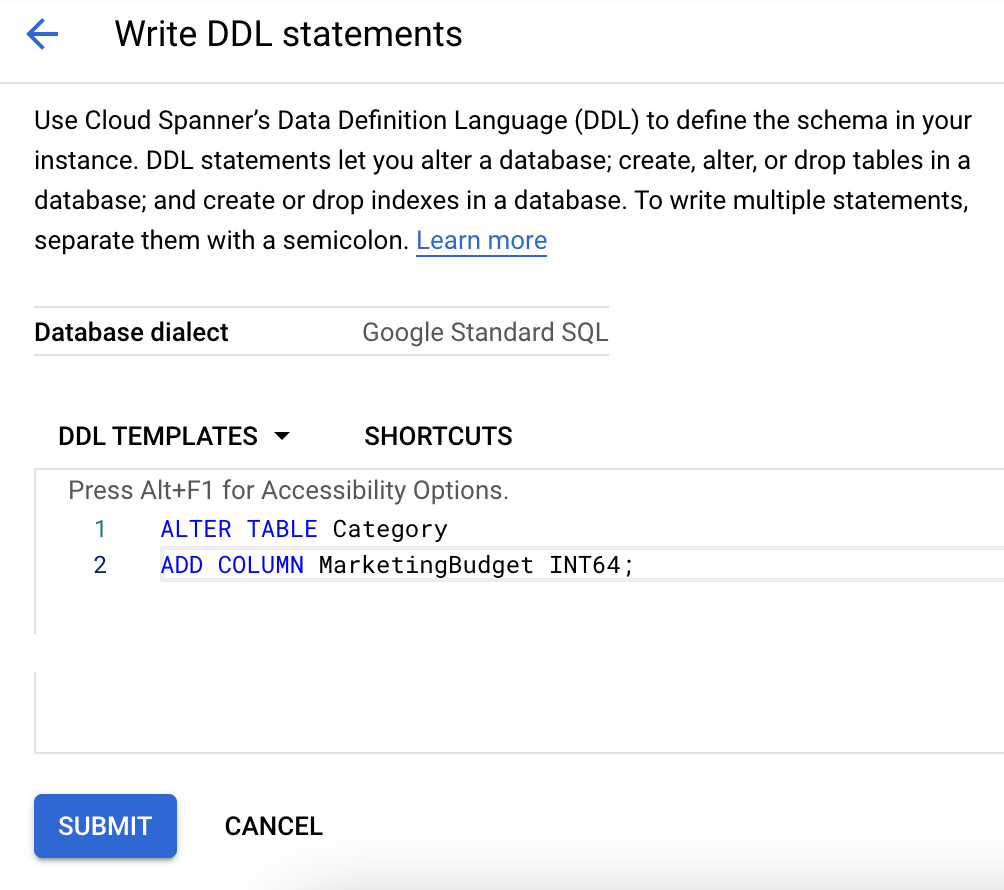
將資料寫入新資料欄
以下程式碼會將資料寫入新資料欄,在 CategoryId 和 PortfolioId 皆為 1 的資料列,以及 CategoryId 為 3 且 PortfolioId 為 2 的資料列,將 MarketingBudget 分別設為 100000、500000。您不會變更任何程式碼,以下顯示該區段供您參考。
def update_data(instance_id, database_id):
"""更新資料庫中的範例資料。
這會更新「MarketingBudget」資料欄,因此必須先建立該資料欄,才能執行執行這個範例。
您可以執行「add_column」範例或對資料庫執行這個 DDL 陳述式,
來新增資料欄
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.batch() as batch:
batch.update(
table="Category",
columns=("CategoryId", "PortfolioId", "MarketingBudget"),
values=[(1, 1, 100000), (3, 2, 500000)],
)
print("Updated data.")
- 使用 update_data 引數執行 snippets.py。
python snippets.py banking-ops-instance --database-id banking-ops-db update_data
- 再次查詢資料表,即可查看更新內容。請使用 query_data_with_new_column 引數執行 snippets.py。
python snippets.py banking-ops-instance --database-id banking-ops-db query_data_with_new_column
結果應為:
CategoryId: 1, PortfolioId: 1, MarketingBudget: 100000
CategoryId: 2, PortfolioId: 2, MarketingBudget: None
CategoryId: 3, PortfolioId: 2, MarketingBudget: 500000
CategoryId: 4, PortfolioId: 3, MarketingBudget: None
工作 5:新增次要索引
假設您要擷取 CategoryNames 值在特定範圍內的所有 Categories 資料列,您可以先使用 SQL 陳述式或讀取呼叫,來讀取 CategoryName 資料欄的所有值,然後捨棄條件不符的資料列。不過,掃描完整資料表的費用高昂,資料表內含大量資料列時更是如此。因此您可以改為在資料表建立次要索引,這樣一來,將非主鍵資料欄做為搜尋條件時,就能加快資料列的擷取速度。
您必須先更新結構定義,才能在現有資料表新增次要索引。如同其他結構定義更新作業,Cloud Spanner 可支援新增索引,同時讓資料庫持續處理流量。Cloud Spanner 的具體做法是將資料填入索引,也稱為「補充作業」。補充作業可能需要幾分鐘才能完成,在這個過程中,您不需將資料庫設為離線,可照常執行特定資料表或資料欄的寫入作業。
使用 Python 用戶端程式庫,新增次要索引
使用 add_index() 方法建立次要索引。您不會變更任何程式碼,以下顯示該區段供您參考。
def add_index(instance_id, database_id):
"""在範例資料庫新增簡單的索引。"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["CREATE INDEX CategoryByCategoryName ON Category(CategoryName)"]
)
print("正在等待作業完成…")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("已新增 CategoryByCategoryName 索引。")
- 使用 add_index 引數執行 snippets.py。
python snippets.py banking-ops-instance --database-id banking-ops-db add_index
- 點選「Check my progress」確認目標已達成。
在 Category 資料表新增次要索引
使用索引讀取資料
叫用 read() 方法的變化版本並加入索引,即可使用索引讀取資料。您不會變更任何程式碼,以下顯示該區段供您參考。
def read_data_with_index(instance_id, database_id):
"""使用索引讀取資料庫的範例資料。
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName"),
keyset=keyset,
index="CategoryByCategoryName",
)
for row in results:
print("CategoryId: {}, CategoryName: {}".format(*row))
- 使用 read_data_with_index 引數執行 snippets.py。
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_index
結果看起來大致如下:
CategoryId: 3, CategoryName: Annuities
CategoryId: 1, CategoryName: Cash
CategoryId: 2, CategoryName: Investments - Short Return
CategoryId: 4, CategoryName: Life Insurance
使用 STORING 子句新增索引
您也許已經注意到,上述的讀取範例並未包含讀取 MarketingBudget 資料欄。這是因為 Cloud Spanner 的讀取介面不支援透過 join 彙整索引與資料表,再查詢未儲存於索引中的值。
如要略過這項限制,請建立 CategoryByCategoryName 索引的替代定義,將 MarketingBudget 的副本儲存於索引中。
使用 Database 類別的 update_ddl() 方法,即可透過 STORING 子句新增索引。您不會變更任何程式碼,以下顯示該區段供您參考。
def add_storing_index(instance_id, database_id):
"""在範例資料庫新增 STORING 索引。"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
[
"CREATE INDEX CategoryByCategoryName2 ON Category(CategoryName)"
"STORING (MarketingBudget)"
]
)
print("正在等待作業完成…")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("已新增 CategoryByCategoryName2 索引。")
- 使用 add_storing_index 引數執行 snippets.py。
python snippets.py banking-ops-instance --database-id banking-ops-db add_storing_index
現在您可以執行讀取作業,使用 CategoryByCategoryName2 索引擷取 CategoryId、CategoryName 和 MarketingBudget 資料欄。您不會變更任何程式碼,以下顯示該區段供您參考。
def read_data_with_storing_index(instance_id, database_id):
"""使用索引搭配 STORING 子句,讀取資料庫的範例
資料。
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName", "MarketingBudget"),
keyset=keyset,
index="CategoryByCategoryName2",
)
for row in results:
print(u"CategoryNameId: {}, CategoryName: {}, " "MarketingBudget: {}".format(*row))
- 使用 read_data_with_storing_index 引數執行 snippets.py。
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_storing_index
結果應為
CategoryNameId: 3, CategoryName: Annuities, MarketingBudget: 500000
CategoryNameId: 1, CategoryName: Cash, MarketingBudget: 100000
CategoryNameId: 2, CategoryName: Investments - Short Return, MarketingBudget: None
CategoryNameId: 4, CategoryName: Life Insurance, MarketingBudget: None
工作 6:檢查查詢計畫
在本節中,您將瞭解 Cloud Spanner 查詢計畫。
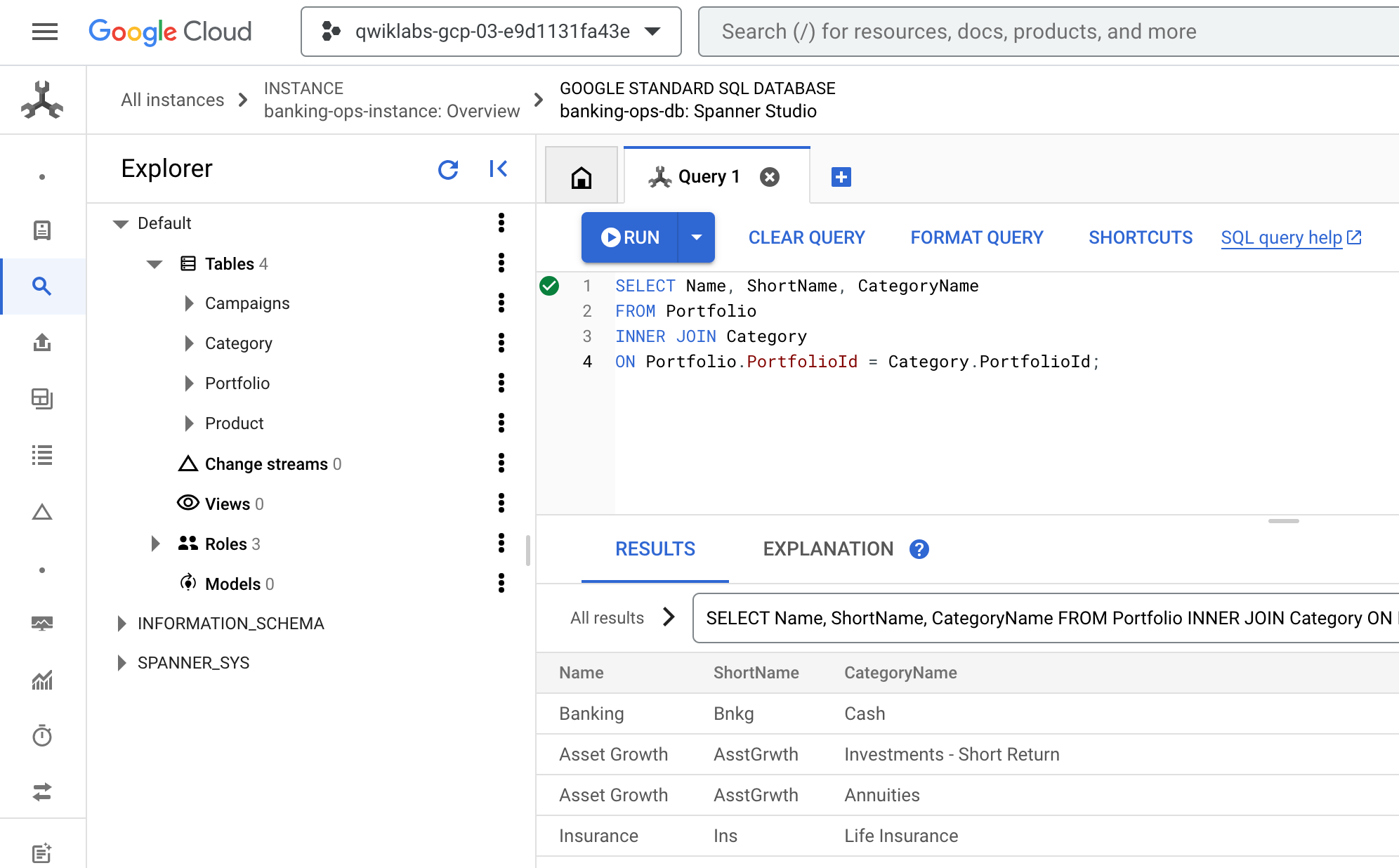
- 返回 Cloud 控制台,畫面應仍為「Spanner Studio」的「查詢」分頁。清除現有查詢,然後貼上並執行下列查詢:
SELECT Name, ShortName, CategoryName
FROM Portfolio
INNER JOIN Category
ON Portfolio.PortfolioId = Category.PortfolioId;
- 結果看起來大致如下:
查詢的生命週期
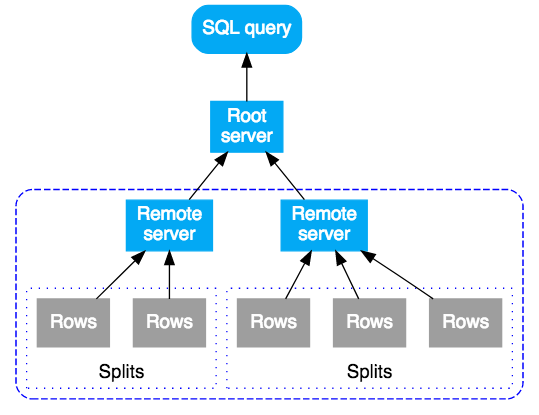
Cloud Spanner 中的 SQL 查詢會先編譯成執行計畫,再傳送到初始根伺服器來執行。系統會選擇能以最少躍點到達查詢資料的根伺服器。然後,根伺服器會:
- 啟動子計畫的遠端執行作業 (如有必要)
- 等待遠端執行的結果。
- 完成任何剩餘的本機執行步驟,例如匯總結果
- 傳回查詢的結果
收到子計畫的遠端伺服器會做為其子計畫的「根」伺服器,按照頂層根伺服器的模式執行。結果會是遠端執行作業的樹狀結構。概念上,查詢流程是由上往下執行,查詢結果則是由下往上傳回。這個模式如下圖所示:
匯總查詢
現在來看匯總查詢的查詢計畫。
- 在「Spanner Studio」的「查詢」分頁中,清除現有查詢,然後貼上並執行下列查詢。
SELECT pr.ProductId, COUNT(*) AS ProductCount
FROM Product AS pr
WHERE pr.ProductId < 100
GROUP BY pr.ProductId;
- 查詢完成後,點選查詢主體下方的「說明」分頁標籤,即可深入瞭解查詢計畫。
Cloud Spanner 會將查詢計畫傳送至協調查詢執行作業的根伺服器,然後執行子計畫的遠端分散作業。
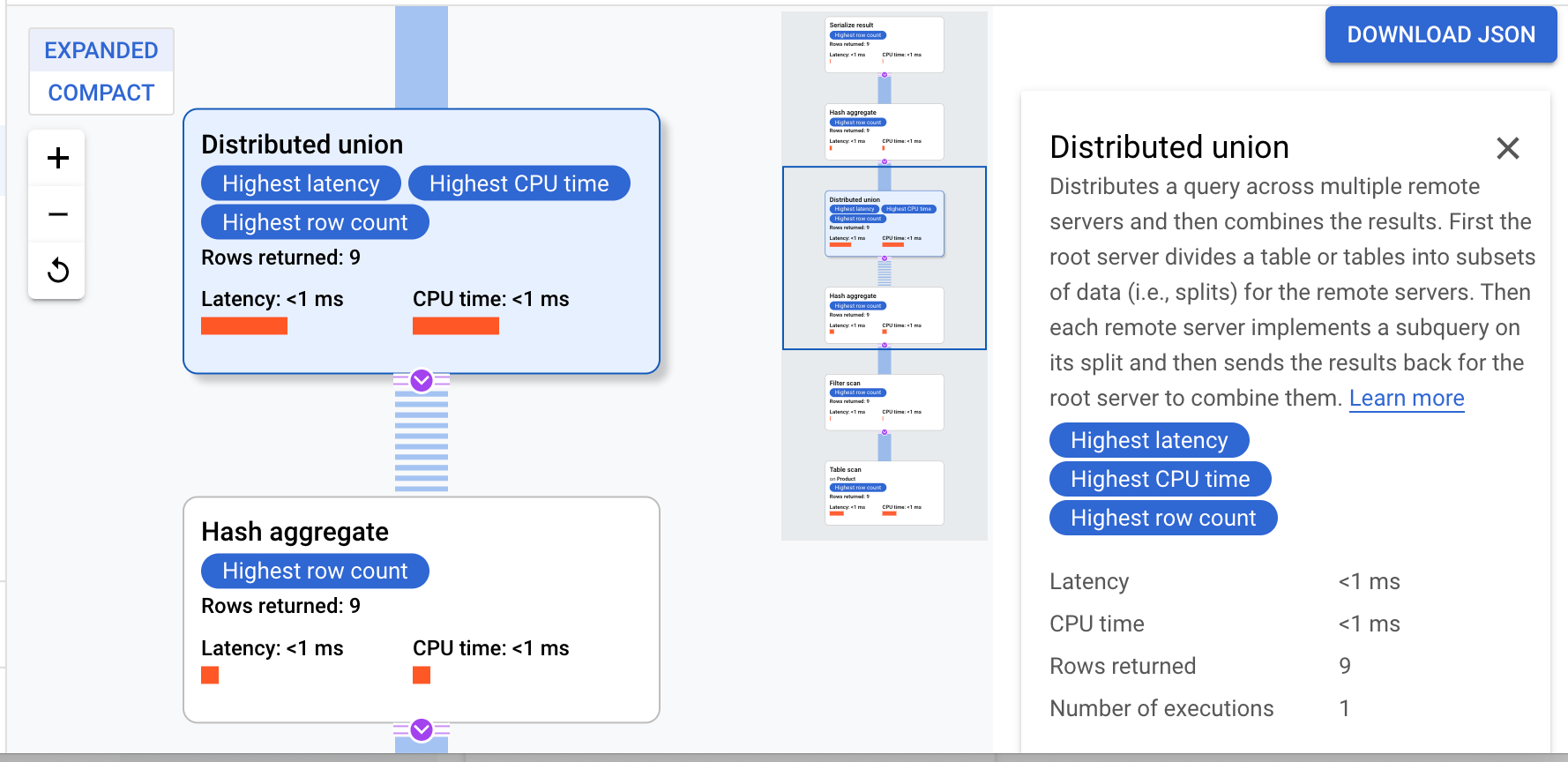
這個執行計畫從序列化開始,也就是將所有傳回的值排序。接著,計畫會完成初始雜湊彙整運算子來計算初步結果,再執行分散式聯集,將子計畫分散至分割符合 ProductId < 100 的遠端伺服器。分散式聯集會將結果傳送至最後的雜湊匯總運算子。匯總運算子則會依 ProductId 執行 COUNT 匯總作業,然後將結果傳回 serialize result 運算子。最後會執行掃描,將要傳回的結果排序。
結果看起來大致如下:
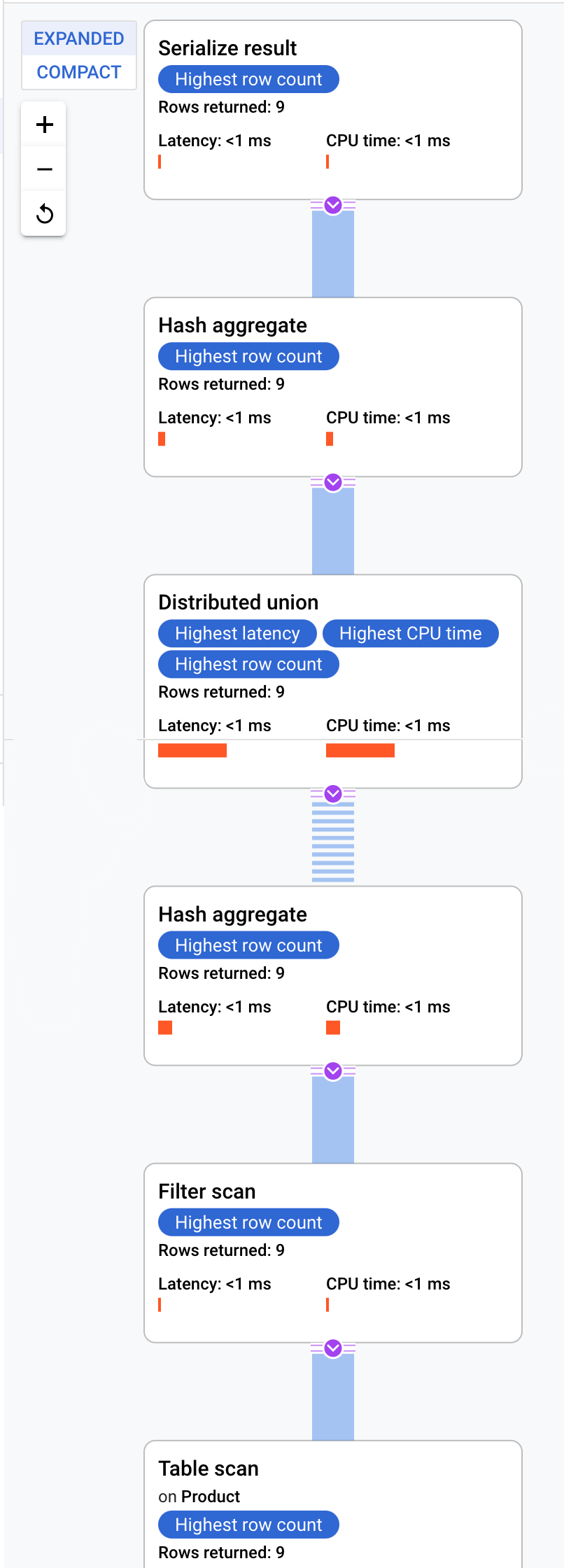
提示:如要進一步瞭解查詢計畫的各個步驟,只要點按任一運算子即可。畫面右側的資訊會隨之改變。
co-located join 查詢
交錯式資料表和相關資料表的資料列會儲存在同一位置。交錯式資料表之間的 join 稱為 co-located join,比需要索引的 join 或 back join 更具效能優勢。
- 在「Spanner Studio」的「查詢」分頁中,清除現有查詢,然後貼上並執行下列查詢。
SELECT c.CategoryName, pr.ProductName
FROM Category AS c, Product AS pr
WHERE c.PortfolioId = pr.PortfolioId AND c.CategoryId = pr.CategoryId;
- 查詢完成後,點選查詢主體下方的「說明」分頁標籤,即可深入瞭解查詢計畫。
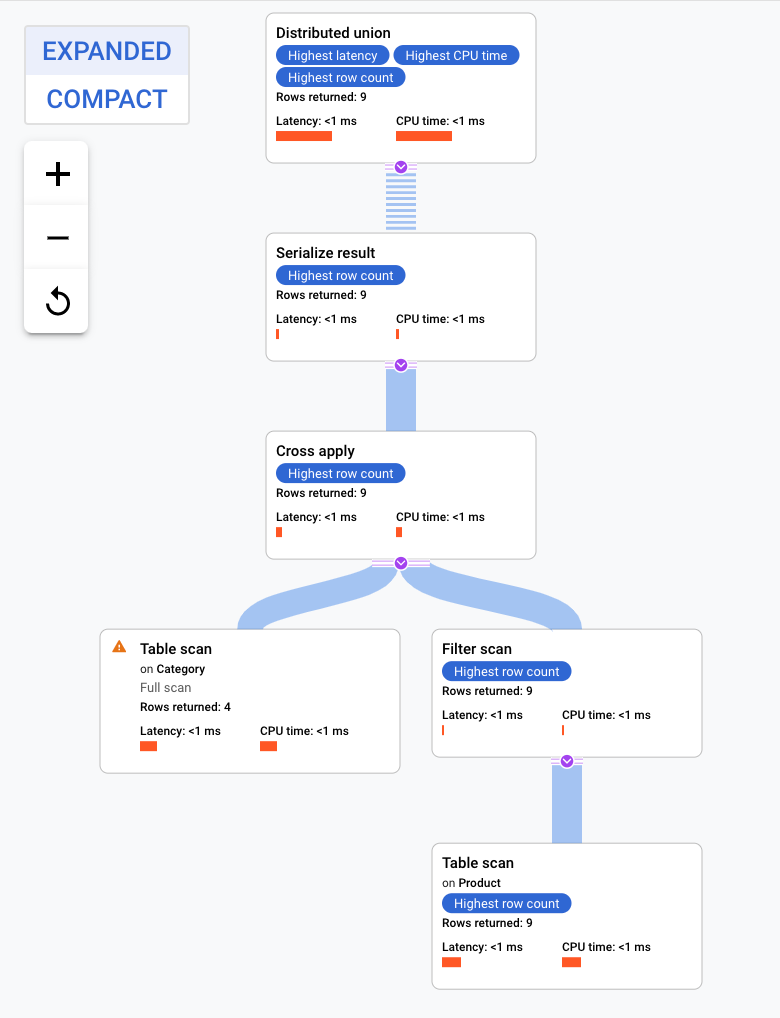
這項執行計畫從分散式聯集開始,將子計畫分散至具有 Category 資料表分割的遠端伺服器。由於 Product 是 Category 的交錯式資料表,每個遠端伺服器都能執行整個子計畫,無須與不同伺服器彙整。
子計畫包含 cross apply。每個 cross apply 都會掃描 Category 資料表,以擷取 PortfolioId、CategoryId 和 CategoryName。然後,cross apply 會將資料表掃描輸出內容對應至 CategoryByCategoryName索引掃描輸出內容,並將篩選條件設為索引的 PortfolioId 與資料表掃描輸出內容的 PortfolioId 相符。每個 cross apply 都會將結果傳送至 serialize result 運算子,將 CategoryName 和 ProductName 資料序列化,再將結果傳回本機分散式聯集。分散式聯集匯總本機分散式聯集的結果後,會傳回這些結果做為查詢結果。
恭喜!
您現在已充分瞭解 Cloud Spanner 的結構定義相關功能,以及 Spanner 建立查詢計畫的方法。
Google Cloud 教育訓練與認證
協助您瞭解如何充分運用 Google Cloud 的技術。我們的課程會介紹專業技能和最佳做法,讓您可以快速掌握要領並持續進修。我們提供從基本到進階等級的訓練課程,並有隨選、線上和虛擬課程等選項,方便您抽空參加。認證可協助您驗證及證明自己在 Google Cloud 技術方面的技能和專業知識。
使用手冊上次更新日期:2024 年 10 月 14 日
實驗室上次測試日期:2024 年 10 月 14 日
Copyright 2026 Google LLC 保留所有權利。Google 和 Google 標誌是 Google LLC 的商標,其他公司和產品名稱則有可能是其關聯公司的商標。





