GSP1050

개요
Cloud Spanner는 Google의 완전 관리되고 수평 확장 가능한 관계형 데이터베이스 서비스입니다. 금융 서비스, 게임, 소매, 기타 여러 업종의 고객은 일관성과 대규모 가용성이 중요한 까다로운 워크로드를 실행하는 데 Cloud Spanner를 사용합니다.
이 실습에서는 Cloud Spanner의 스키마 관련 기능을 검토하고 이를 은행 운영 데이터베이스에 적용합니다. 또한 Cloud Spanner가 쿼리 계획을 생성하는 방법과 규칙을 검토합니다.
실습할 내용
이 실습에서는 Cloud Spanner 인스턴스의 스키마 관련 속성을 수정하는 방법을 알아봅니다.
- 테이블에 데이터 로드하기
- 사전 정의된 Python 클라이언트 라이브러리 코드를 사용하여 데이터 로드하기
- 클라이언트 라이브러리를 사용하여 데이터 쿼리하기
- 데이터베이스 스키마 업데이트하기
- 보조 색인 추가하기
- 쿼리 계획 검토하기
설정 및 요건
실습 시작 버튼을 클릭하기 전에
다음 안내를 확인하세요. 실습에는 시간 제한이 있으며 일시중지할 수 없습니다. 실습 시작을 클릭하면 타이머가 시작됩니다. 이 타이머는 Google Cloud 리소스를 사용할 수 있는 시간이 얼마나 남았는지를 표시합니다.
실무형 실습을 통해 시뮬레이션이나 데모 환경이 아닌 실제 클라우드 환경에서 실습 활동을 진행할 수 있습니다. 실습 시간 동안 Google Cloud에 로그인하고 액세스하는 데 사용할 수 있는 새로운 임시 사용자 인증 정보가 제공됩니다.
이 실습을 완료하려면 다음을 준비해야 합니다.
- 표준 인터넷 브라우저 액세스 권한(Chrome 브라우저 권장)
참고: 이 실습을 실행하려면 시크릿 모드(권장) 또는 시크릿 브라우저 창을 사용하세요. 개인 계정과 학습자 계정 간의 충돌로 개인 계정에 추가 요금이 발생하는 일을 방지해 줍니다.
- 실습을 완료하기에 충분한 시간(실습을 시작하고 나면 일시중지할 수 없음)
참고: 이 실습에는 학습자 계정만 사용하세요. 다른 Google Cloud 계정을 사용하는 경우 해당 계정에 비용이 청구될 수 있습니다.
실습을 시작하고 Google Cloud 콘솔에 로그인하는 방법
-
실습 시작 버튼을 클릭합니다. 실습 비용을 결제해야 하는 경우 결제 수단을 선택할 수 있는 대화상자가 열립니다.
오른쪽에는 다음과 같은 항목이 포함된 실습 설정 및 액세스 패널이 있습니다.
-
Google Cloud 콘솔 열기 버튼
- 이 실습에 사용해야 하는 임시 사용자 인증 정보(사용자 이름 및 비밀번호)
- 필요한 경우 실습 진행을 위한 기타 정보
실습 타이머는 페이지 상단에 있으며 남은 시간을 표시합니다.
-
Google Cloud 콘솔 열기를 클릭합니다(Chrome 브라우저를 실행 중인 경우 마우스 오른쪽 버튼으로 클릭하고 시크릿 창에서 링크 열기를 선택합니다).
실습에서 리소스가 가동되면 다른 탭이 열리고 로그인 페이지가 표시됩니다.
팁: 두 개의 탭을 각각 별도의 창으로 나란히 정렬하세요.
참고: 계정 선택 대화상자가 표시되면 다른 계정 사용을 클릭합니다.
-
필요한 경우 아래의 사용자 이름을 복사하여 로그인 대화상자에 붙여넣습니다.
{{{user_0.username | "Username"}}}
실습 설정 및 액세스 패널에서도 사용자 이름을 확인할 수 있습니다.
-
다음을 클릭합니다.
-
아래의 비밀번호를 복사하여 시작하기 대화상자에 붙여넣습니다.
{{{user_0.password | "Password"}}}
실습 설정 및 액세스 패널에서도 비밀번호를 확인할 수 있습니다.
-
다음을 클릭합니다.
중요: 실습에서 제공하는 사용자 인증 정보를 사용해야 합니다. Google Cloud 계정 사용자 인증 정보를 사용하지 마세요.
참고: 이 실습에 자신의 Google Cloud 계정을 사용하면 추가 요금이 발생할 수 있습니다.
-
이후에 표시되는 페이지를 클릭하여 넘깁니다.
- 이용약관에 동의하세요.
- 임시 계정이므로 복구 옵션이나 2단계 인증을 추가하지 마세요.
- 무료 체험판을 신청하지 마세요.
잠시 후 Google Cloud 콘솔이 이 탭에서 열립니다.
참고: Google Cloud 제품 및 서비스에 액세스하려면 탐색 메뉴를 클릭하거나 검색창에 제품 또는 서비스 이름을 입력합니다.

Cloud Shell 활성화
Cloud Shell은 다양한 개발 도구가 탑재된 가상 머신으로, 5GB의 영구 홈 디렉터리를 제공하며 Google Cloud에서 실행됩니다. Cloud Shell을 사용하면 명령줄을 통해 Google Cloud 리소스에 액세스할 수 있습니다.
-
Google Cloud 콘솔 상단에서 Cloud Shell 활성화  를 클릭합니다.
를 클릭합니다.
-
다음 창을 클릭합니다.
- Cloud Shell 정보 창을 통해 계속 진행합니다.
- 사용자 인증 정보를 사용하여 Google Cloud API를 호출할 수 있도록 Cloud Shell을 승인합니다.
연결되면 사용자 인증이 이미 처리된 것이며 프로젝트가 학습자의 PROJECT_ID, (으)로 설정됩니다. 출력에 이 세션의 PROJECT_ID를 선언하는 줄이 포함됩니다.
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud는 Google Cloud의 명령줄 도구입니다. Cloud Shell에 사전 설치되어 있으며 명령줄 자동 완성을 지원합니다.
- (선택사항) 다음 명령어를 사용하여 활성 계정 이름 목록을 표시할 수 있습니다.
gcloud auth list
-
승인을 클릭합니다.
출력:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (선택사항) 다음 명령어를 사용하여 프로젝트 ID 목록을 표시할 수 있습니다.
gcloud config list project
출력:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
참고: gcloud 전체 문서는 Google Cloud에서 gcloud CLI 개요 가이드를 참고하세요.
Cloud Spanner 인스턴스
이 실습을 더 빠르게 진행할 수 있도록 Cloud Spanner 인스턴스, 데이터베이스, 테이블이 자동으로 생성되었습니다.
참고하실 수 있도록 아래에 몇 가지 세부정보를 정리했습니다.
| 항목 |
이름 |
세부정보 |
| Cloud Spanner 인스턴스 |
banking-ops-instance |
프로젝트 수준 인스턴스입니다. |
| Cloud Spanner 데이터베이스 |
banking-ops-db |
인스턴스 전용 데이터베이스입니다. |
| 테이블 |
Portfolio |
최상위 수준 은행 상품을 포함합니다. |
| 테이블 |
Category |
2차 수준 은행 상품 그룹화를 포함합니다. |
| 테이블 |
Product |
특정 개별 은행 상품을 포함합니다. |
| 테이블 |
Campaigns |
마케팅 이니셔티브에 대한 세부정보를 포함합니다. |
작업 1. 테이블에 데이터 로드하기
banking-ops-db가 생성되었고 테이블이 비어 있습니다. 아래 단계에 따라 데이터를 3개의 테이블(Portfolio, Category, Product)에 로드합니다.
-
Cloud 콘솔에서 탐색 메뉴( ) > 모든 제품 보기를 열고 데이터베이스에서 Spanner를 클릭합니다.
) > 모든 제품 보기를 열고 데이터베이스에서 Spanner를 클릭합니다.
-
인스턴스 이름은 banking-ops-instance입니다. 이름을 클릭하여 데이터베이스를 살펴봅니다.
-
연결된 데이터베이스의 이름은 banking-ops-db입니다. 이름을 클릭하고 테이블로 스크롤하면 4개의 테이블이 있는 것을 볼 수 있습니다.
-
콘솔의 왼쪽 창에서 Spanner Studio를 클릭합니다. 그런 다음 오른쪽 프레임에서 + 새 SQL 편집기 탭 버튼을 클릭합니다.
-
그러면 쿼리 페이지로 이동합니다. 아래의 insert 문을 단일 블록으로 붙여넣어 Portfolio 테이블을 로드합니다. Spanner가 각 insert 문을 순차적으로 실행합니다. 실행을 클릭합니다.
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (1, "Banking", "Bnkg", "All Banking Business");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (2, "Asset Growth", "AsstGrwth", "All Asset Focused Products");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (3, "Insurance", "Ins", "All Insurance Focused Products");
-
화면 하단 페이지에 데이터를 한 행씩 삽입한 결과가 표시됩니다. 삽입된 데이터의 각 행에는 녹색 체크표시가 나타납니다. 이제 Portfolio 테이블에 3개의 행이 있습니다.
-
페이지 상단에서 삭제를 클릭합니다.
-
아래의 insert 문을 단일 블록으로 붙여넣어 Category 테이블을 로드합니다. 실행을 클릭합니다.
insert into Category (CategoryId,PortfolioId,CategoryName) values (1,1,"Cash");
insert into Category (CategoryId,PortfolioId,CategoryName) values (2,2,"Investments - Short Return");
insert into Category (CategoryId,PortfolioId,CategoryName) values (3,2,"Annuities");
insert into Category (CategoryId,PortfolioId,CategoryName) values (4,3,"Life Insurance");
-
화면 하단 페이지에 데이터를 한 행씩 삽입한 결과가 표시됩니다. 삽입된 데이터의 각 행에는 녹색 체크표시가 나타납니다. 이제 Category 테이블에 4개의 행이 있습니다.
-
페이지 상단에서 삭제를 클릭합니다.
-
아래의 insert 문을 단일 블록으로 붙여넣어 Product 테이블을 로드합니다. 실행을 클릭합니다.
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (1,1,1,"Checking Account","ChkAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (2,2,2,"Mutual Fund Consumer Goods","MFundCG","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (3,3,2,"Annuity Early Retirement","AnnuFixed","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (4,4,3,"Term Life Insurance","TermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (5,1,1,"Savings Account","SavAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (6,1,1,"Personal Loan","PersLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (7,1,1,"Auto Loan","AutLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (8,4,3,"Permanent Life Insurance","PermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (9,2,2,"US Savings Bonds","USSavBond","Investment LOB");
-
화면 하단 페이지에 데이터를 한 행씩 삽입한 결과가 표시됩니다. 삽입된 데이터의 각 행에는 녹색 체크표시가 나타납니다. 이제 Product 테이블에 9개의 행이 있습니다.
-
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
Portfolio, Category, Product 테이블에 데이터 로드하기
작업 2. 사전 빌드된 Python 클라이언트 라이브러리 코드를 사용하여 데이터 로드하기
아래의 여러 단계에서는 Python으로 작성된 클라이언트 라이브러리를 사용합니다.
-
Cloud Shell을 열고 아래 명령어를 붙여넣어 필요한 파일을 저장할 새 디렉터리를 만들고 이 디렉터리로 이동합니다.
mkdir python-helper
cd python-helper
- 다음으로, 두 개의 파일을 다운로드합니다. 하나는 환경을 설정하는 데 사용되고 다른 하나는 실습 코드입니다.
wget https://storage.googleapis.com/cloud-training/OCBL373/requirements.txt
wget https://storage.googleapis.com/cloud-training/OCBL373/snippets.py
- 격리된 Python 환경을 만들고 Cloud Spanner 클라이언트의 종속 항목을 설치합니다.
pip install -r requirements.txt
pip install setuptools
-
snippets.py는 이 실습에서 도우미로 사용할 여러 Cloud Spanner DDL, DML, DCL 함수가 들어 있는 통합된 파일입니다. insert_data 인수를 사용하여 snippets.py를 실행하여 Campaigns 테이블을 채웁니다.
python snippets.py banking-ops-instance --database-id banking-ops-db insert_data
-
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
Campaigns 테이블에 데이터 로드하기
작업 3. 클라이언트 라이브러리를 사용하여 데이터 쿼리하기
snippets.py의 query_data() 함수는 데이터베이스를 쿼리하는 데 사용할 수 있습니다. 여기서는 Campaigns 테이블에 로드된 데이터를 확인하는 데 사용합니다. 코드는 변경하지 않습니다. 이 섹션은 참고용입니다.
def query_data(instance_id, database_id):
"""Queries sample data from the database using SQL."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
results = snapshot.execute_sql(
"SELECT CampaignId,PortfolioId,CampaignStartDate,CampaignEndDate,CampaignName,CampaignBudget FROM Campaigns"
)
for row in results:
print(u"CampaignId: {}, PortfolioId: {}, CampaignStartDate: {}, CampaignEndDate: {}, CampaignName: {}, CampaignBudget: {}".format(*row))
-
query_data 인수를 사용하여 snippets.py를 실행하여 Campaigns 테이블을 쿼리합니다.
python snippets.py banking-ops-instance --database-id banking-ops-db query_data
다음과 같은 결과가 표시됩니다.
CampaignId: 1, PortfolioId: 1, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: New Account Reward, CampaignBudget: 15000
CampaignId: 2, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Intro to Investments, CampaignBudget: 5000
CampaignId: 3, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Youth Checking Accounts, CampaignBudget: 25000
CampaignId: 4, PortfolioId: 3, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Protect Your Family, CampaignBudget: 10000
작업 4. 데이터베이스 스키마 업데이트하기
여러분은 DBA 업무의 일환으로 Category 테이블에 MarketingBudget라는 새 열을 추가해야 합니다. 기존 테이블에 새 열을 추가하려면 데이터베이스 스키마를 업데이트해야 합니다. Cloud Spanner는 데이터베이스에서 계속해서 트래픽을 전달하는 동안 데이터베이스에서 스키마가 업데이트되는 것을 지원합니다. 스키마 업데이트 시 데이터베이스를 오프라인으로 전환할 필요가 없고 전체 테이블 또는 열이 잠기지 않습니다. 따라서 스키마 업데이트 중에도 계속해서 데이터베이스의 데이터를 읽고 쓸 수 있습니다.
Python을 사용하여 열 추가하기
Database 클래스의 update_ddl() 메서드는 스키마를 수정하는 데 사용됩니다.
여기서는 이 메서드를 구현하는 snippets.py의 add_column() 함수를 사용합니다. 코드는 변경하지 않습니다. 이 섹션은 참고용입니다.
def add_column(instance_id, database_id):
"""Adds a new column to the Albums table in the example database."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["ALTER TABLE Category ADD COLUMN MarketingBudget INT64"]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the MarketingBudget column.")
-
add_column 인수를 사용하여 snippets.py를 실행합니다.
python snippets.py banking-ops-instance --database-id banking-ops-db add_column
-
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
Category 테이블에 열 추가하기
기존 테이블에 열을 추가하는 또 다른 방법은 다음과 같습니다.
gcloud CLI를 통해 DDL 명령어 실행하기
참고: 이 옵션은 대체 예시로 제시되었습니다. 이 명령어를 실행하지 마세요.
아래 코드 샘플은 방금 Python을 통해 실행한 것과 동일한 작업을 수행합니다.
gcloud spanner databases ddl update banking-ops-db --instance=banking-ops-instance --ddl='ALTER TABLE Category ADD COLUMN MarketingBudget INT64;'
Cloud 콘솔에서 DDL 명령어 실행하기
참고: 이 옵션은 대체 예시로 제시되었습니다. 이 작업을 수행하지 마세요.
- 데이터베이스 목록에서 테이블 이름을 클릭합니다.
- 페이지 오른쪽 상단에서 DDL 작성을 클릭합니다.
-
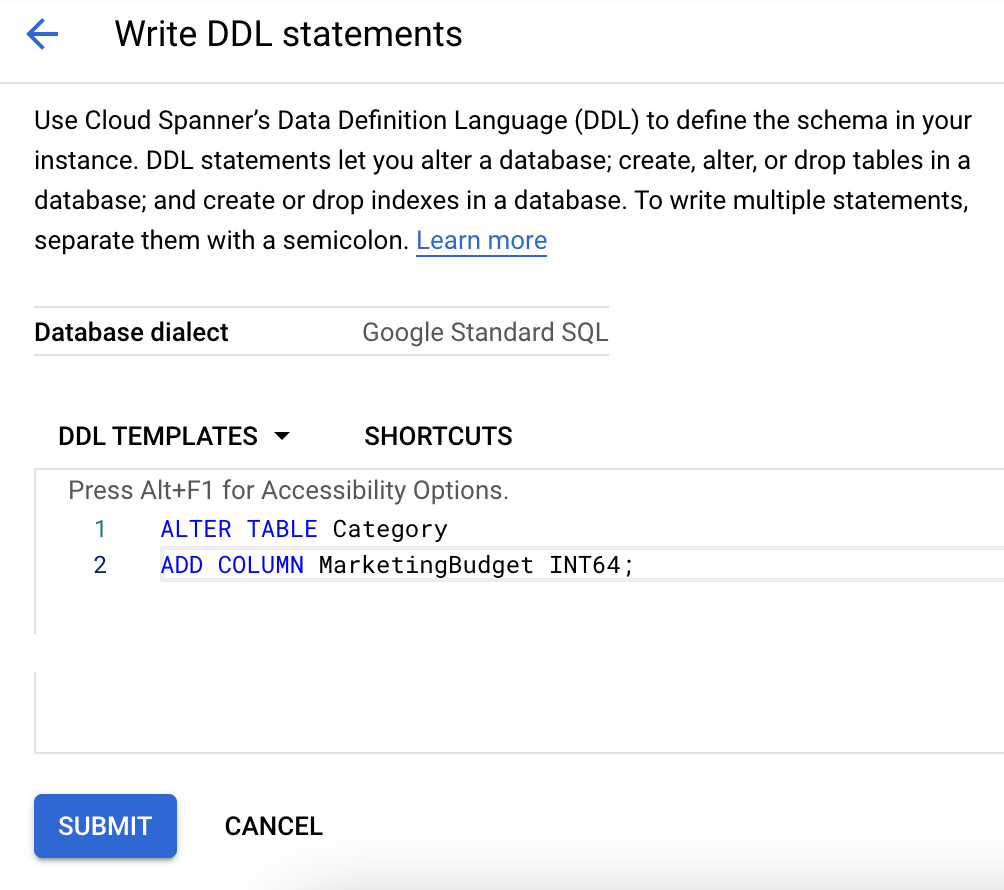
DDL 템플릿 상자에 적절한 DDL을 붙여넣습니다.
-
제출을 클릭합니다.
새 열에 데이터 쓰기
다음 코드는 새 열에 데이터를 씁니다. CategoryId가 1이고 PortfolioId가 1인 행의 MarketingBudget을 100000으로, CategoryId가 3이고 PortfolioId가 2인 행의 MarketingBudget을 500000으로 설정합니다. 코드는 변경하지 않습니다. 이 섹션은 참고용입니다.
def update_data(instance_id, database_id):
"""Updates sample data in the database.
This updates the `MarketingBudget` column which must be created before
running this sample. You can add the column by running the `add_column`
sample or by running this DDL statement against your database
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.batch() as batch:
batch.update(
table="Category",
columns=("CategoryId", "PortfolioId", "MarketingBudget"),
values=[(1, 1, 100000), (3, 2, 500000)],
)
print("Updated data.")
-
update_data 인수를 사용하여 snippets.py를 실행합니다.
python snippets.py banking-ops-instance --database-id banking-ops-db update_data
- 테이블을 다시 쿼리하여 업데이트를 확인합니다. query_data_with_new_column 인수를 사용하여 snippets.py를 실행합니다.
python snippets.py banking-ops-instance --database-id banking-ops-db query_data_with_new_column
결과는 다음과 같습니다.
CategoryId: 1, PortfolioId: 1, MarketingBudget: 100000
CategoryId: 2, PortfolioId: 2, MarketingBudget: None
CategoryId: 3, PortfolioId: 2, MarketingBudget: 500000
CategoryId: 4, PortfolioId: 3, MarketingBudget: None
작업 5. 보조 색인 추가하기
특정 범위의 CategoryNames 값을 갖는 Categories의 모든 행을 가져오려고 한다고 가정하겠습니다. SQL 문 또는 읽기 호출을 사용하여 CategoryName 열에서 모든 값을 읽은 다음 기준을 충족하지 않는 행을 삭제하면 되겠지만, 이렇게 전체 테이블을 스캔하면 비용이 많이 들며, 특히 행이 많은 테이블은 상당한 비용이 발생합니다. 대신 테이블에 보조 색인을 만들어 기본 키가 아닌 열로 검색하면 행을 빠르게 가져올 수 있습니다.
기존 테이블에 보조 색인을 추가하려면 스키마를 업데이트해야 합니다. 다른 스키마 업데이트와 같이, Cloud Spanner는 데이터베이스에서 계속해서 트래픽을 전달하는 동안 데이터베이스에 색인이 추가되는 것을 지원합니다. Cloud Spanner는 내부적으로 색인에 데이터를 입력하는데, 이 작업을 '백필'이라고 합니다. 백필을 완료하는 데는 몇 분 정도 걸릴 수 있지만 이 프로세스가 진행되는 동안 데이터베이스를 오프라인으로 전환하거나 특정 테이블 또는 열에 대한 쓰기를 금지할 필요는 없습니다.
Python 클라이언트 라이브러리를 사용하여 보조 색인 추가하기
add_index() 메서드를 사용하여 보조 색인을 만듭니다. 코드는 변경하지 않습니다. 이 섹션은 참고용입니다.
def add_index(instance_id, database_id):
"""Adds a simple index to the example database."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["CREATE INDEX CategoryByCategoryName ON Category(CategoryName)"]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the CategoryByCategoryName index.")
-
add_index 인수를 사용하여 snippets.py를 실행합니다.
python snippets.py banking-ops-instance --database-id banking-ops-db add_index
-
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
Category 테이블에 보조 색인 추가하기
색인을 사용하여 읽기
색인을 사용하여 읽으려면 read() 메서드의 변형에 색인을 포함하여 호출해야 합니다. 코드는 변경하지 않습니다. 이 섹션은 참고용입니다.
def read_data_with_index(instance_id, database_id):
"""Reads sample data from the database using an index.
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName"),
keyset=keyset,
index="CategoryByCategoryName",
)
for row in results:
print("CategoryId: {}, CategoryName: {}".format(*row))
-
read_data_with_index 인수를 사용하여 snippets.py를 실행합니다.
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_index
결과는 다음과 같습니다.
CategoryId: 3, CategoryName: Annuities
CategoryId: 1, CategoryName: Cash
CategoryId: 2, CategoryName: Investments - Short Return
CategoryId: 4, CategoryName: Life Insurance
STORING 절을 사용하여 색인 추가하기
위의 읽기 예시에서는 MarketingBudget 열을 읽지 않은 것을 눈치채셨을 수 있을 텐데요. Cloud Spanner의 읽기 인터페이스는 색인을 데이터 테이블에 조인하여 색인에 저장되어 있지 않은 값을 조회하는 기능을 지원하지 않기 때문입니다.
이 제한을 우회하려면 색인에 MarketingBudget의 사본을 저장하는 CategoryByCategoryName 색인의 대체 정의를 만듭니다.
Database 클래스의 update_ddl() 메서드를 사용하여 색인과 STORING 절을 추가합니다. 코드는 변경하지 않습니다. 이 섹션은 참고용입니다.
def add_storing_index(instance_id, database_id):
"""Adds an storing index to the example database."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
[
"CREATE INDEX CategoryByCategoryName2 ON Category(CategoryName)"
"STORING (MarketingBudget)"
]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the CategoryByCategoryName2 index.")
-
add_storing_index 인수를 사용하여 snippets.py를 실행합니다.
python snippets.py banking-ops-instance --database-id banking-ops-db add_storing_index
이제 CategoryByCategoryName2 색인을 사용하여 CategoryId, CategoryName, MarketingBudget 열을 가져오는 읽기를 실행할 수 있습니다. 코드는 변경하지 않습니다. 이 섹션은 참고용입니다.
def read_data_with_storing_index(instance_id, database_id):
"""Reads sample data from the database using an index with a storing
clause.
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName", "MarketingBudget"),
keyset=keyset,
index="CategoryByCategoryName2",
)
for row in results:
print(u"CategoryNameId: {}, CategoryName: {}, " "MarketingBudget: {}".format(*row))
-
read_data_with_storing_index 인수를 사용하여 snippets.py를 실행합니다.
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_storing_index
결과는 다음과 같습니다.
CategoryNameId: 3, CategoryName: Annuities, MarketingBudget: 500000
CategoryNameId: 1, CategoryName: Cash, MarketingBudget: 100000
CategoryNameId: 2, CategoryName: Investments - Short Return, MarketingBudget: None
CategoryNameId: 4, CategoryName: Life Insurance, MarketingBudget: None
작업 6. 쿼리 계획 검토하기
이 섹션에서는 Cloud Spanner 쿼리 계획을 살펴봅니다.
-
Cloud 콘솔로 돌아갑니다. Spanner Studio의 쿼리 탭에 있습니다. 기존 쿼리를 지우고 다음 쿼리를 붙여넣은 다음 실행합니다.
SELECT Name, ShortName, CategoryName
FROM Portfolio
INNER JOIN Category
ON Portfolio.PortfolioId = Category.PortfolioId;
- 결과는 다음과 같습니다.
쿼리 수명
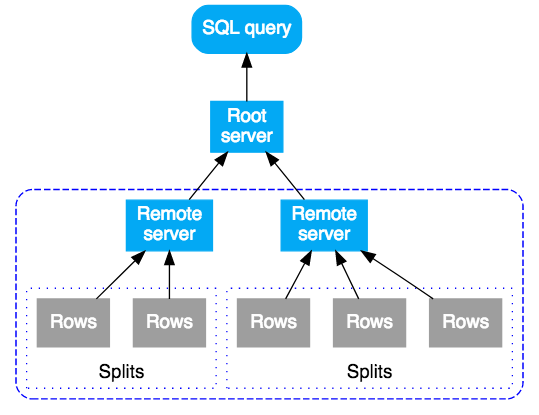
Cloud Spanner의 SQL 쿼리는 먼저 실행 계획으로 컴파일된 후 실행을 위해 초기 루트 서버로 보내집니다. 루트 서버는 쿼리 대상 데이터에 도달하기 위한 홉 수가 최소화되도록 선택됩니다. 쿼리를 수신한 루트 서버는 다음을 수행합니다.
- 하위 계획의 원격 실행 시작(필요한 경우)
- 원격 실행의 결과 대기
- 결과 집계와 같은 나머지 로컬 실행 단계 처리
- 쿼리의 결과 반환
하위 계획을 수신하는 원격 서버는 최상위 루트 서버와 동일한 방식으로 하위 계획의 '루트' 서버로 작동합니다. 결과는 원격 실행으로 구성된 트리입니다. 쿼리 실행은 위에서 아래로 진행되고, 쿼리 결과는 아래에서 위로 반환됩니다. 다음 다이어그램은 이러한 패턴을 보여 줍니다.
집계 쿼리
이번에는 집계된 쿼리의 쿼리 계획을 살펴보겠습니다.
-
Spanner Studio의 쿼리 탭에서 기존 쿼리를 지우고 다음 쿼리를 붙여넣은 다음 실행합니다.
SELECT pr.ProductId, COUNT(*) AS ProductCount
FROM Product AS pr
WHERE pr.ProductId < 100
GROUP BY pr.ProductId;
- 쿼리가 완료되면 쿼리 본문 아래의 설명 탭을 클릭하여 쿼리 계획을 검사합니다.
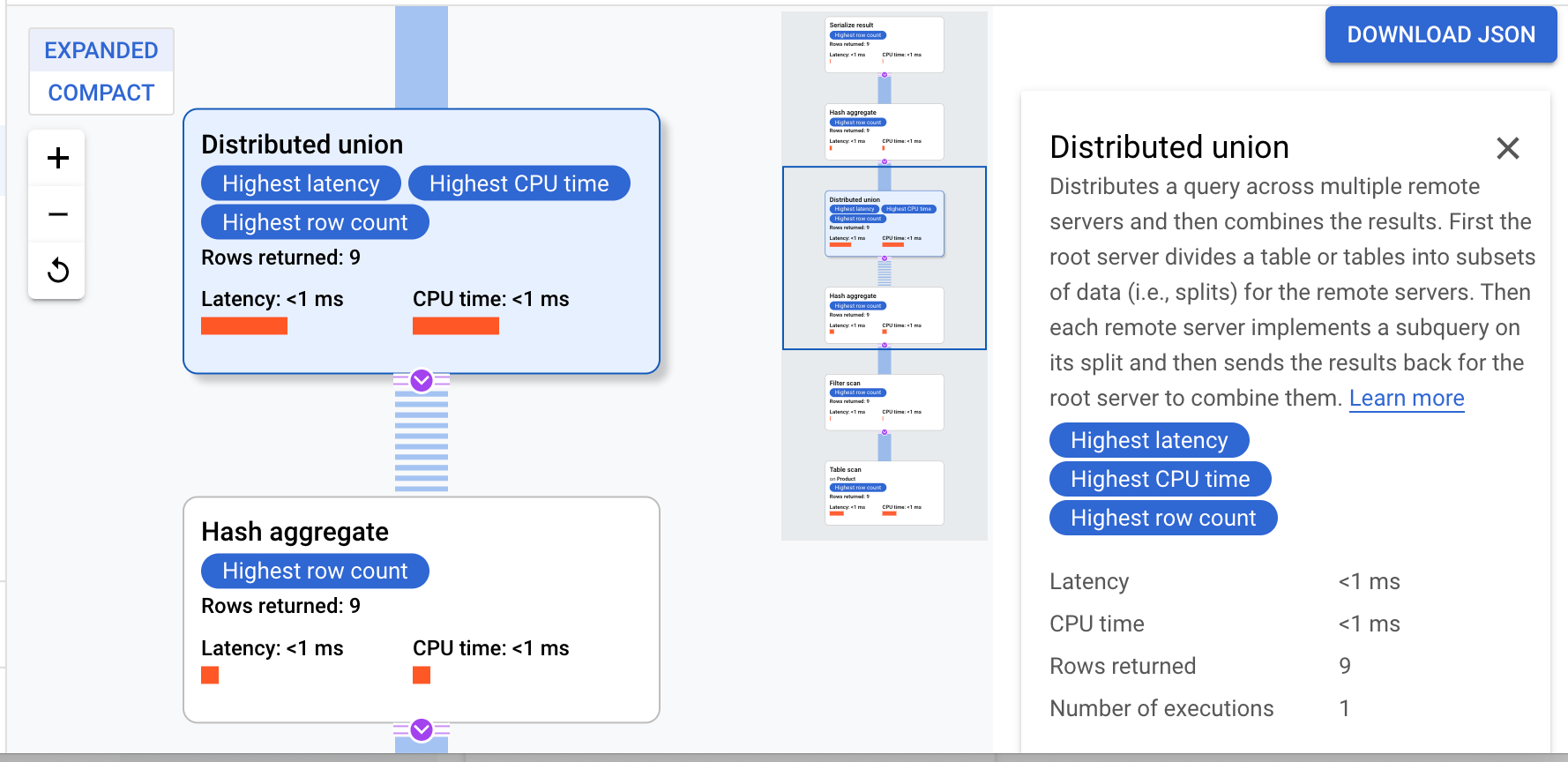
Cloud Spanner는 쿼리 실행을 조정하고 하위 계획의 원격 배포를 수행하는 루트 서버로 실행 계획을 보냅니다.
이 실행 계획은 반환된 모든 값을 정렬하는 직렬화를 시작한 다음 초기 해시 집계 연산자를 수행하여 예비 결과를 계산합니다. 그런 다음 분산 통합이 실행되어 분할이 ProductId < 100을 충족하는 원격 서버로 하위 계획을 배포합니다. 분산 통합은 결과를 최종 해시 집계 작업자로 보냅니다. 집계 작업자는 ProductId를 기준으로 COUNT 집계를 수행하고 결과를 결과 직렬화 연산자에 반환합니다. 마지막으로, 스캔이 수행되어 반환할 결과를 정렬합니다.
결과는 다음과 같습니다.
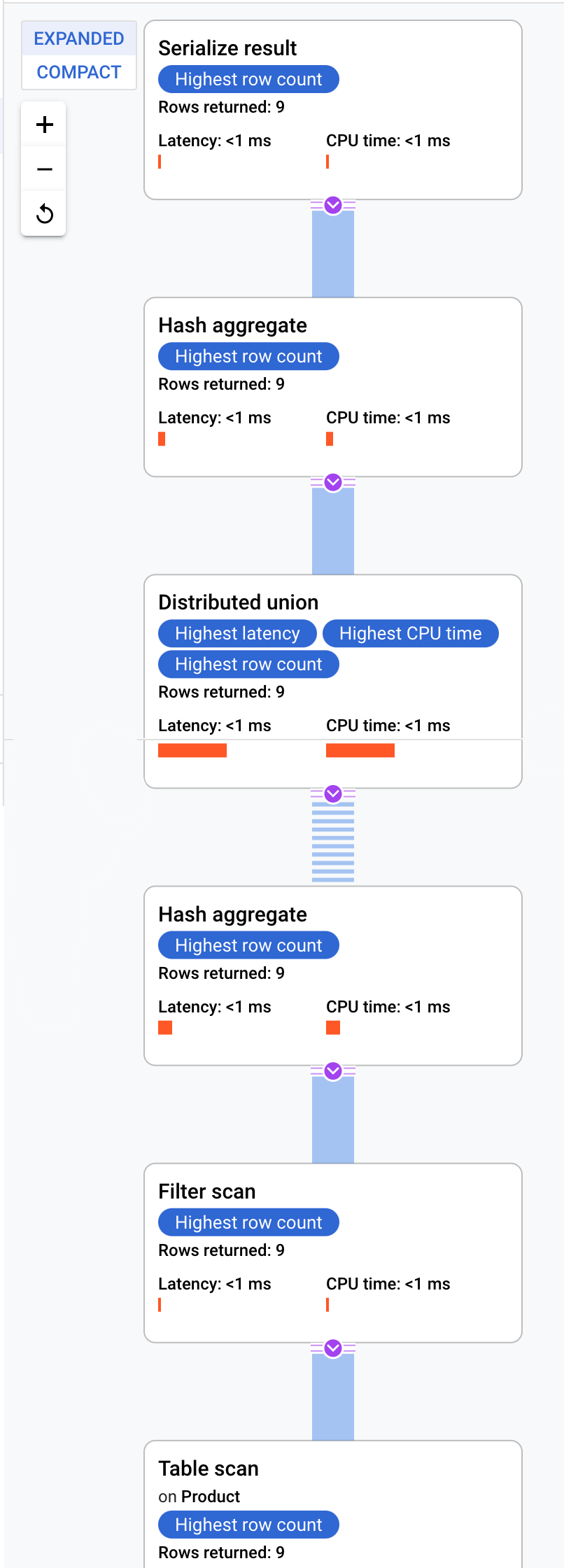
팁:쿼리 계획의 각 단계에 대한 자세한 내용을 보려면 작업자를 클릭하여 화면 오른쪽에 표시되는 내용을 확인하세요.
공동 배치된 조인 쿼리
인터리브 처리된 테이블은 관련 테이블의 행과 공동 배치된 상태로 물리적으로 저장됩니다. 인터리브 처리된 테이블 간의 조인을 공동 배치된 조인이라고 합니다. 공동 배치된 조인은 색인이 필요한 조인이나 백 조인에 비해 성능상의 이점을 제공합니다.
-
Spanner Studio의 쿼리 탭에서 기존 쿼리를 지우고 다음 쿼리를 붙여넣은 다음 실행합니다.
SELECT c.CategoryName, pr.ProductName
FROM Category AS c, Product AS pr
WHERE c.PortfolioId = pr.PortfolioId AND c.CategoryId = pr.CategoryId;
- 쿼리가 완료되면 쿼리 본문 아래의 설명 탭을 클릭하여 쿼리 계획을 검사합니다.
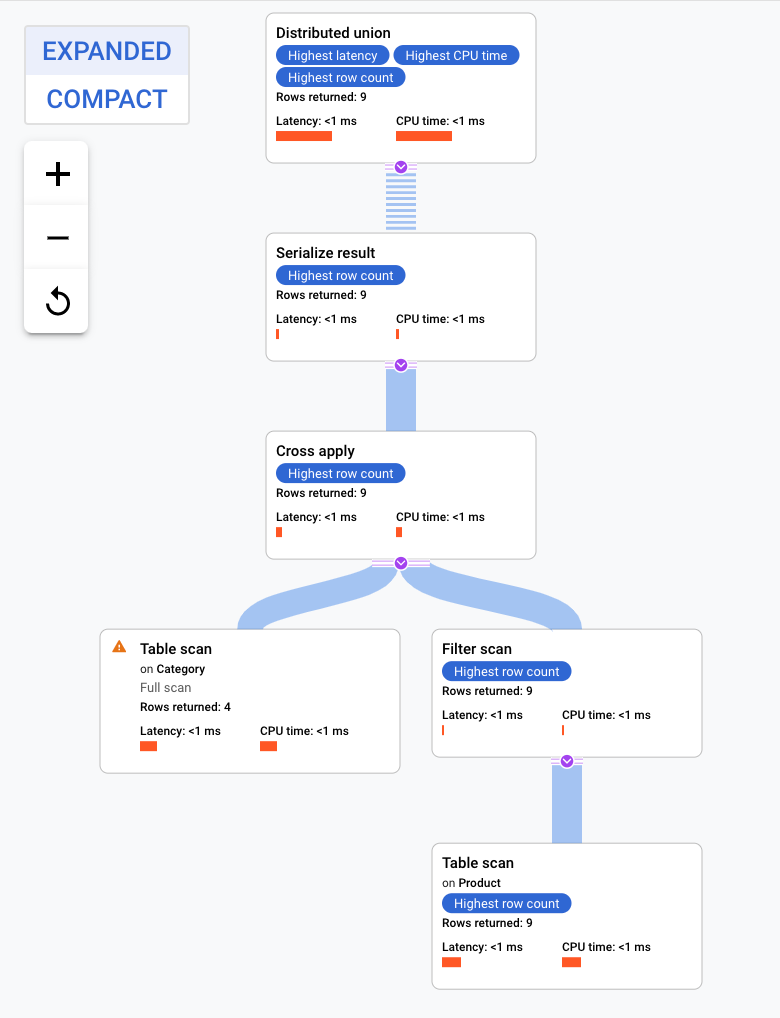
이 실행 계획은 분산 통합을 시작하여 Category 테이블의 분할이 있는 원격 서버로 하위 계획을 배포합니다. Product는 Category의 인터리브 처리된 테이블이므로 각 원격 서버는 다른 서버에 조인할 필요 없이 각 원격 서버에서 하위 계획 전체를 실행할 수 있습니다.
하위 계획에는 교차 적용이 포함됩니다. 각 교차 적용은 Category 테이블에 대해 테이블 스캔을 수행하여 PortfolioId, CategoryId, CategoryName을 가져옵니다. 그런 다음 테이블 스캔 출력의 PortfolioId와 일치하는 색인에서 PortfolioId의 필터를 적용해 테이블 스캔의 출력을 색인 CategoryByCategoryName의 색인 스캔 출력에 매핑합니다. 각 교차 적용은 결과 직렬화 작업자로 결과를 보냅니다. 결과 직렬화 작업자는 CategoryName및 ProductName 데이터를 직렬화하고 결과를 로컬 분산 통합으로 반환합니다. 분산 통합은 로컬 분산 통합의 결과를 집계하여 쿼리 결과로 반환합니다.
축하합니다.
Cloud Spanner의 스키마 관련 기능과 Spanner가 쿼리 계획을 생성하는 방법을 알게 되었습니다.
Google Cloud 교육 및 자격증
Google Cloud 기술을 최대한 활용하는 데 도움이 됩니다. Google 강의에는 빠른 습득과 지속적인 학습을 지원하는 기술적인 지식과 권장사항이 포함되어 있습니다. 기초에서 고급까지 수준별 학습을 제공하며 바쁜 일정에 알맞은 주문형, 실시간, 가상 옵션이 포함되어 있습니다. 인증은 Google Cloud 기술에 대한 역량과 전문성을 검증하고 입증하는 데 도움이 됩니다.
설명서 최종 업데이트: 2024년 10월 14일
실습 최종 테스트: 2024년 10월 14일
Copyright 2026 Google LLC. All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.





