GSP1050

概要
Cloud Spanner は Google の水平スケーリングが可能なフルマネージド リレーショナル データベース サービスです。金融サービス、ゲーム、小売など多くの業界のお客様が、大規模な整合性と可用性が要求されるワークロードの実行に使用しています。
このラボでは、Cloud Spanner のスキーマ関連の機能を確認し、それらの機能を銀行業務データベースに適用します。また、Cloud Spanner がクエリプランを作成する方法とルールについても確認します。
演習内容
このラボでは、Cloud Spanner インスタンスのスキーマ関連の属性を変更する方法を学びます。
- テーブルにデータを読み込む
- 事前定義された Python クライアント ライブラリ コードを使用してデータを読み込む
- クライアント ライブラリでデータをクエリする
- データベース スキーマを更新する
- セカンダリ インデックスを追加する
- クエリプランを調べる
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
注: このラボの実行には、シークレット モード(推奨)またはシークレット ブラウジング ウィンドウを使用してください。これにより、個人アカウントと受講者アカウント間の競合を防ぎ、個人アカウントに追加料金が発生しないようにすることができます。
- ラボを完了するための時間(開始後は一時停止できません)
注: このラボでは、受講者アカウントのみを使用してください。別の Google Cloud アカウントを使用すると、そのアカウントに料金が発生する可能性があります。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。
右側の [ラボの設定とアクセス] パネルには、以下が表示されます。
- [Google Cloud コンソールを開く] ボタン
- このラボで使用する一時的な認証情報(ユーザー名とパスワード)
- このラボを行うために必要なその他の情報(ある場合)
ラボのタイマーはページの上部に表示され、残り時間が示されます。
-
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示された場合は、[別のアカウントを使用] をクリックします。
-
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
{{{user_0.username | "Username"}}}
[ラボの設定とアクセス] パネルでもユーザー名を確認できます。
-
[次へ] をクリックします。
-
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
{{{user_0.password | "Password"}}}
[ラボの設定とアクセス] パネルでもパスワードを確認できます。
-
[次へ] をクリックします。
重要: ラボで指定された認証情報を使用する必要があります。ご自身の Google Cloud アカウントの認証情報は使用しないでください。
注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。
-
その後のページはクリックして先に進みます。
- 利用規約に同意します。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
しばらくすると、このタブで Google Cloud コンソールが開きます。
注: Google Cloud のプロダクトやサービスにアクセスするには、ナビゲーション メニューをクリックするか、[検索] フィールドにサービス名またはプロダクト名を入力します。

Cloud Shell をアクティブにする
Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
-
Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン  をクリックします。
をクリックします。
-
ウィンドウで次の操作を行います。
- Cloud Shell 情報ウィンドウで操作を進めます。
- Cloud Shell が認証情報を使用して Google Cloud API を呼び出すことを承認します。
接続した時点で認証が完了しており、プロジェクトに各自の Project_ID、 が設定されます。出力には、このセッションの PROJECT_ID を宣言する次の行が含まれています。
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
- (省略可)次のコマンドを使用すると、有効なアカウント名を一覧表示できます。
gcloud auth list
- [承認] をクリックします。
出力:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (省略可)次のコマンドを使用すると、プロジェクト ID を一覧表示できます。
gcloud config list project
出力:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
注: Google Cloud における gcloud ドキュメントの全文については、gcloud CLI の概要ガイドをご覧ください。
Cloud Spanner インスタンス
このラボをより迅速に進められるように、Cloud Spanner のインスタンス、データベース、テーブルが自動的に作成されています。
参考までに、詳細を以下に示します。
| 項目 |
名前 |
詳細 |
| Cloud Spanner インスタンス |
banking-ops-instance |
これはプロジェクト レベルのインスタンスです。 |
| Cloud Spanner データベース |
banking-ops-db |
これはインスタンス固有のデータベースです。 |
| テーブル |
Portfolio |
銀行の最上位のサービスが含まれます。 |
| テーブル |
Category |
第 2 層の銀行のサービス グループが含まれます。 |
| テーブル |
Product |
特定の項目の銀行サービスが含まれます。 |
| テーブル |
Campaigns |
マーケティング イニシアチブの詳細が含まれます。 |
タスク 1. テーブルにデータを読み込む
banking-ops-db が空のテーブルとともに作成されました。以下の手順に沿って、3 つのテーブル(Portfolio、Category、Product)にデータを読み込みます。
-
Cloud コンソールで、ナビゲーション メニュー( )> [すべてのプロダクトを表示] を開き、[データベース] から [Spanner] をクリックします。
)> [すべてのプロダクトを表示] を開き、[データベース] から [Spanner] をクリックします。
-
インスタンス名は banking-ops-instance です。名前をクリックしてデータベースを確認します。
-
関連付けられたデータベースの名前は banking-ops-db です。名前をクリックし、[テーブル] までスクロールすると、すでに 4 つのテーブルが配置されていることがわかります。
-
コンソールの左側のペインで、[Spanner Studio] をクリックします。次に、右側のフレームにある [+ 新しい SQL エディタタブ] ボタンをクリックします。
-
クリックすると、[クエリ] ページが表示されます。以下の挿入ステートメントを 1 つのブロックとして貼り付け、Portfolio テーブルを読み込みます。Spanner はそれぞれを連続して実行します。[実行] をクリックします。
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (1, "Banking", "Bnkg", "All Banking Business");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (2, "Asset Growth", "AsstGrwth", "All Asset Focused Products");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (3, "Insurance", "Ins", "All Insurance Focused Products");
-
画面の下のページに、データを 1 行ずつ挿入した結果が表示されます。挿入されたデータの各行には緑色のチェックマークも表示されます。これで、Portfolio テーブルの行が 3 つになりました。
-
ページの上部にある [クリア] をクリックします。
-
以下の挿入ステートメントを 1 つのブロックとして貼り付け、Category テーブルを読み込みます。[実行] をクリックします。
insert into Category (CategoryId,PortfolioId,CategoryName) values (1,1,"Cash");
insert into Category (CategoryId,PortfolioId,CategoryName) values (2,2,"Investments - Short Return");
insert into Category (CategoryId,PortfolioId,CategoryName) values (3,2,"Annuities");
insert into Category (CategoryId,PortfolioId,CategoryName) values (4,3,"Life Insurance");
-
画面の下のページに、データを 1 行ずつ挿入した結果が表示されます。挿入されたデータの各行には緑色のチェックマークも表示されます。これで、Category テーブルの行が 4 つになりました。
-
ページの上部にある [クリア] をクリックします。
-
以下の挿入ステートメントを 1 つのブロックとして貼り付け、Product テーブルを読み込みます。[実行] をクリックします。
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (1,1,1,"Checking Account","ChkAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (2,2,2,"Mutual Fund Consumer Goods","MFundCG","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (3,3,2,"Annuity Early Retirement","AnnuFixed","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (4,4,3,"Term Life Insurance","TermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (5,1,1,"Savings Account","SavAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (6,1,1,"Personal Loan","PersLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (7,1,1,"Auto Loan","AutLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (8,4,3,"Permanent Life Insurance","PermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (9,2,2,"US Savings Bonds","USSavBond","Investment LOB");
-
画面の下のページに、データを 1 行ずつ挿入した結果が表示されます。挿入されたデータの各行には緑色のチェックマークも表示されます。これで、Product テーブルの行が 9 つになりました。
-
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Portfolio、Category、Product テーブルにデータを読み込む
タスク 2. 事前構築済みの Python クライアント ライブラリ コードを使用してデータを読み込む
次のいくつかのステップでは、Python で記述されたクライアント ライブラリを使用します。
-
Cloud Shell を開き、以下のコマンドを貼り付けて、必要なファイルを保存する新しいディレクトリを作成し、そのディレクトリに移動します。
mkdir python-helper
cd python-helper
- 次に、2 つのファイルをダウンロードします。1 つは環境の設定に使用されます。もう 1 つはラボコードです。
wget https://storage.googleapis.com/cloud-training/OCBL373/requirements.txt
wget https://storage.googleapis.com/cloud-training/OCBL373/snippets.py
- 隔離された Python 環境を作成し、Cloud Spanner クライアントの依存関係をインストールします。
pip install -r requirements.txt
pip install setuptools
-
snippets.py は、このラボでヘルパーとして使用する複数の Cloud Spanner DDL、DML、DCL 関数を統合したファイルです。insert_data 引数を使用して snippets.py を実行し、Campaigns テーブルにデータを入力します。
python snippets.py banking-ops-instance --database-id banking-ops-db insert_data
- [進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Campaigns テーブルにデータを読み込む
タスク 3. クライアント ライブラリでデータをクエリする
snippets.py の query_data() 関数は、データベースにクエリを実行する際に使用できます。ここでは、Campaigns テーブルに読み込まれたデータを確認するために使用します。コードを変更することはありません。以下は参照用のセクションです。
def query_data(instance_id, database_id):
"""SQL を使用してデータベースからサンプルデータをクエリします。"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
results = snapshot.execute_sql(
"SELECT CampaignId,PortfolioId,CampaignStartDate,CampaignEndDate,CampaignName,CampaignBudget FROM Campaigns"
)
for row in results:
print(u"CampaignId: {}, PortfolioId: {}, CampaignStartDate: {}, CampaignEndDate: {}, CampaignName: {}, CampaignBudget: {}".format(*row))
-
query_data 引数を使用して snippets.py を実行し、Campaigns テーブルをクエリします。
python snippets.py banking-ops-instance --database-id banking-ops-db query_data
結果は次のようになります。
CampaignId: 1, PortfolioId: 1, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: New Account Reward, CampaignBudget: 15000
CampaignId: 2, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Intro to Investments, CampaignBudget: 5000
CampaignId: 3, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Youth Checking Accounts, CampaignBudget: 25000
CampaignId: 4, PortfolioId: 3, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Protect Your Family, CampaignBudget: 10000
タスク 4. データベース スキーマを更新する
データベース管理者の業務の一環として、MarketingBudget という列を新たに Category テーブルに追加する必要があります。既存のテーブルに新しい列を追加するには、データベース スキーマの更新が必要です。Cloud Spanner では、データベースでのトラフィックの処理中にデータベースのスキーマを更新できます。スキーマの更新では、データベースをオフラインにする必要がなく、テーブル全体や列全体がロックされることもないため、スキーマの更新中もデータベースへのデータの読み取りと書き込みを続けることができます。
Python を使用して列を追加する
スキーマを変更するには、Database クラスの update_ddl() メソッドを使用します。
snippets.py の add_column() 関数にそのメソッドが実装されていますので、この関数を使用します。コードを変更することはありません。以下は参照用のセクションです。
def add_column(instance_id, database_id):
"""サンプル データベースの Albums テーブルに新しい列を追加します。"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["ALTER TABLE Category ADD COLUMN MarketingBudget INT64"]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the MarketingBudget column.")
-
add_column 引数を使用して snippets.py を実行します。
python snippets.py banking-ops-instance --database-id banking-ops-db add_column
- [進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Category テーブルに列を追加する
既存のテーブルに列を追加するその他のオプションは次のとおりです。
gcloud CLI を使用して DDL コマンドを発行する
注: このオプションは代替例として示されています。このコマンドは発行しないでください。
以下のコードサンプルは、先ほど Python で実行したのと同じタスクを実行します。
gcloud spanner databases ddl update banking-ops-db --instance=banking-ops-instance --ddl='ALTER TABLE Category ADD COLUMN MarketingBudget INT64;'
Cloud コンソールで DDL コマンドを発行する
注: このオプションは代替例として示されています。この操作は行わないでください。
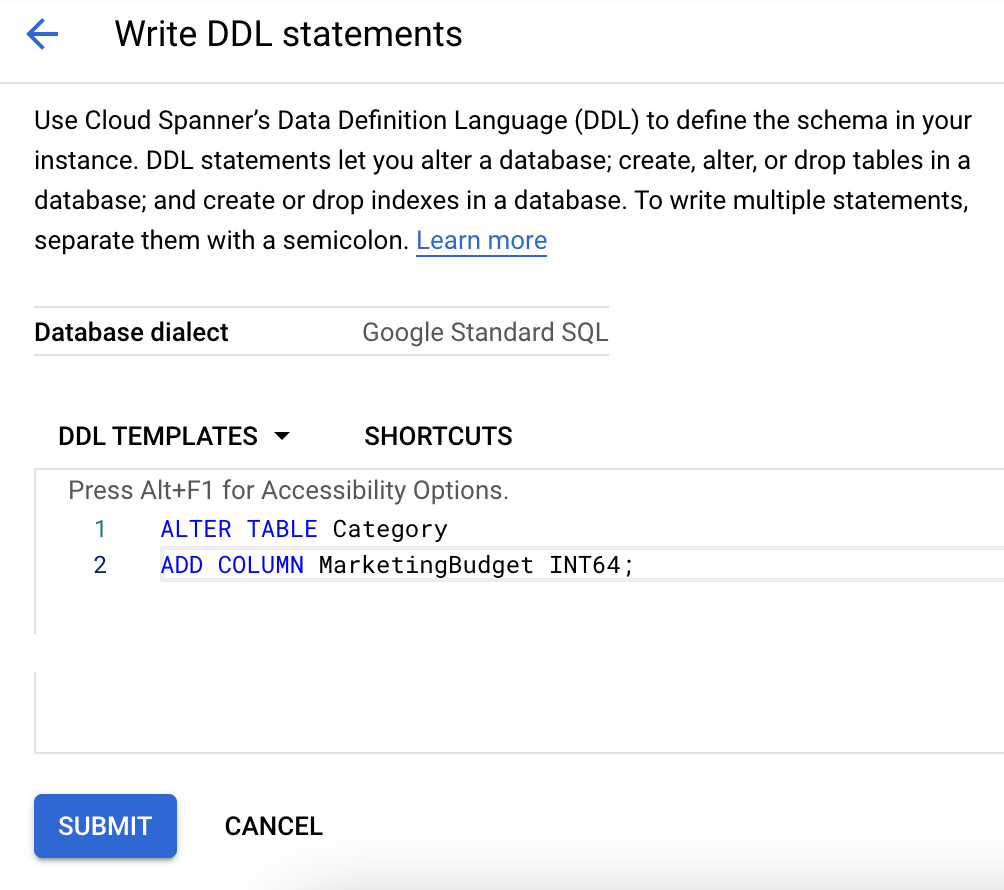
- データベース リストでテーブル名をクリックします。
- ページの右上にある [DDL を記述] をクリックします。
- 適切な DDL を [DDL テンプレート] ボックスに貼り付けます。
- [送信] をクリックします。
新しい列にデータを書き込む
次のコードは、新しい列にデータを書き込みます。MarketingBudget の値を、CategoryId が 1 で PortfolioId が 1 の行では 100,000 に、CategoryId が 3 で PortfolioId が 2 の行では 500,000 に設定します。コードを変更することはありません。以下は参照用のセクションです。
def update_data(instance_id, database_id):
"""データベース内のサンプルデータを更新します。
これにより、このサンプルを実行する前に作成しておく必要がある `MarketingBudget` 列が更新されます。この列を追加するには、`add_column` サンプルを実行するか、データベースに対して次の DDL ステートメントを実行します。
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.batch() as batch:
batch.update(
table="Category",
columns=("CategoryId", "PortfolioId", "MarketingBudget"),
values=[(1, 1, 100000), (3, 2, 500000)],
)
print("Updated data.")
-
update_data 引数を使用して snippets.py を実行します。
python snippets.py banking-ops-instance --database-id banking-ops-db update_data
- テーブルに再度クエリを実行して、更新を確認します。query_data_with_new_column 引数を使用して snippets.py を実行します。
python snippets.py banking-ops-instance --database-id banking-ops-db query_data_with_new_column
結果は次のようになります。
CategoryId: 1, PortfolioId: 1, MarketingBudget: 100000
CategoryId: 2, PortfolioId: 2, MarketingBudget: None
CategoryId: 3, PortfolioId: 2, MarketingBudget: 500000
CategoryId: 4, PortfolioId: 3, MarketingBudget: None
タスク 5. セカンダリ インデックスを追加する
Categories から CategoryNames の値が特定の範囲内にある行すべてを取得すると仮定します。SQL ステートメントまたは読み取り呼び出しを使用して CategoryName 列からすべての値を読み取り、基準を満たしていない行を破棄することもできますが、このようなテーブル全体のスキャンは負荷が大きくなります(特に、行数が多いテーブルの場合)。代わりに、テーブルにセカンダリ インデックスを作成することにより、主キー以外の列を検索するときの行の取得速度を上げることができます。
既存のテーブルにセカンダリ インデックスを追加するには、スキーマの更新が必要です。他のスキーマの更新と同様に、Cloud Spanner ではデータベースがトラフィックを提供している間にインデックスを追加できます。Cloud Spanner は、内部的にインデックスにデータを入力(バックフィル)します。バックフィルには数分かかることがありますが、このプロセスの間に、データベースをオフラインにする必要はありません。また、特定のテーブルや列への書き込みを控える必要もありません。
Python クライアント ライブラリを使用してセカンダリ インデックスを追加する
add_index() メソッドを使用してセカンダリ インデックスを作成します。コードを変更することはありません。以下は参照用のセクションです。
def add_index(instance_id, database_id):
"""サンプル データベースに単純なインデックスを追加します。"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["CREATE INDEX CategoryByCategoryName ON Category(CategoryName)"]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the CategoryByCategoryName index.")
-
add_index 引数を使用して snippets.py を実行します。
python snippets.py banking-ops-instance --database-id banking-ops-db add_index
- [進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Category テーブルにセカンダリ インデックスを追加する
インデックスを使用して読み取りを行う
インデックスを使用して読み取りを行うには、インデックスを含めて read() メソッドのバリエーションを呼び出します。コードを変更することはありません。以下は参照用のセクションです。
def read_data_with_index(instance_id, database_id):
"""インデックスを使用してデータベースからサンプルデータを読み取ります。
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName"),
keyset=keyset,
index="CategoryByCategoryName",
)
for row in results:
print("CategoryId: {}, CategoryName: {}".format(*row))
-
read_data_with_index 引数を使用して snippets.py を実行します。
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_index
結果は次のようになります。
CategoryId: 3, CategoryName: Annuities
CategoryId: 1, CategoryName: Cash
CategoryId: 2, CategoryName: Investments - Short Return
CategoryId: 4, CategoryName: Life Insurance
STORING 句を指定してインデックスを追加する
上記の読み取り例では、MarketingBudget 列の読み取りが含まれていませんでした。これは、Cloud Spanner の読み取りインターフェースが、インデックスとデータテーブルを結合してインデックスに格納されていない値を検索する機能をサポートしていないためです。
この制限を回避するため、MarketingBudget のコピーをインデックスに格納する CategoryByCategoryName インデックスの代替定義を作成します。
Database クラスの update_ddl() メソッドを使用し、STORING 句を指定してインデックスを追加します。コードを変更することはありません。以下は参照用のセクションです。
def add_storing_index(instance_id, database_id):
"""サンプル データベースに STORING インデックスを追加します。"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
[
"CREATE INDEX CategoryByCategoryName2 ON Category(CategoryName)"
"STORING (MarketingBudget)"
]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the CategoryByCategoryName2 index.")
-
add_storing_index 引数を使用して snippets.py を実行します。
python snippets.py banking-ops-instance --database-id banking-ops-db add_storing_index
これで、CategoryByCategoryName2 インデックスを使用して CategoryId、CategoryName、MarketingBudget 列を取得する読み取りを実行できるようになりました。コードを変更することはありません。以下は参照用のセクションです。
def read_data_with_storing_index(instance_id, database_id):
"""STORING 句ありでインデックスを使用して、データベースからサンプルデータを読み取ります。
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName", "MarketingBudget"),
keyset=keyset,
index="CategoryByCategoryName2",
)
for row in results:
print(u"CategoryNameId: {}, CategoryName: {}, " "MarketingBudget: {}".format(*row))
-
read_data_with_storing_index 引数を使用して snippets.py を実行します。
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_storing_index
結果は次のようになります。
CategoryNameId: 3, CategoryName: Annuities, MarketingBudget: 500000
CategoryNameId: 1, CategoryName: Cash, MarketingBudget: 100000
CategoryNameId: 2, CategoryName: Investments - Short Return, MarketingBudget: None
CategoryNameId: 4, CategoryName: Life Insurance, MarketingBudget: None
タスク 6. クエリプランを調べる
このセクションでは、Cloud Spanner のクエリプランについて説明します。
-
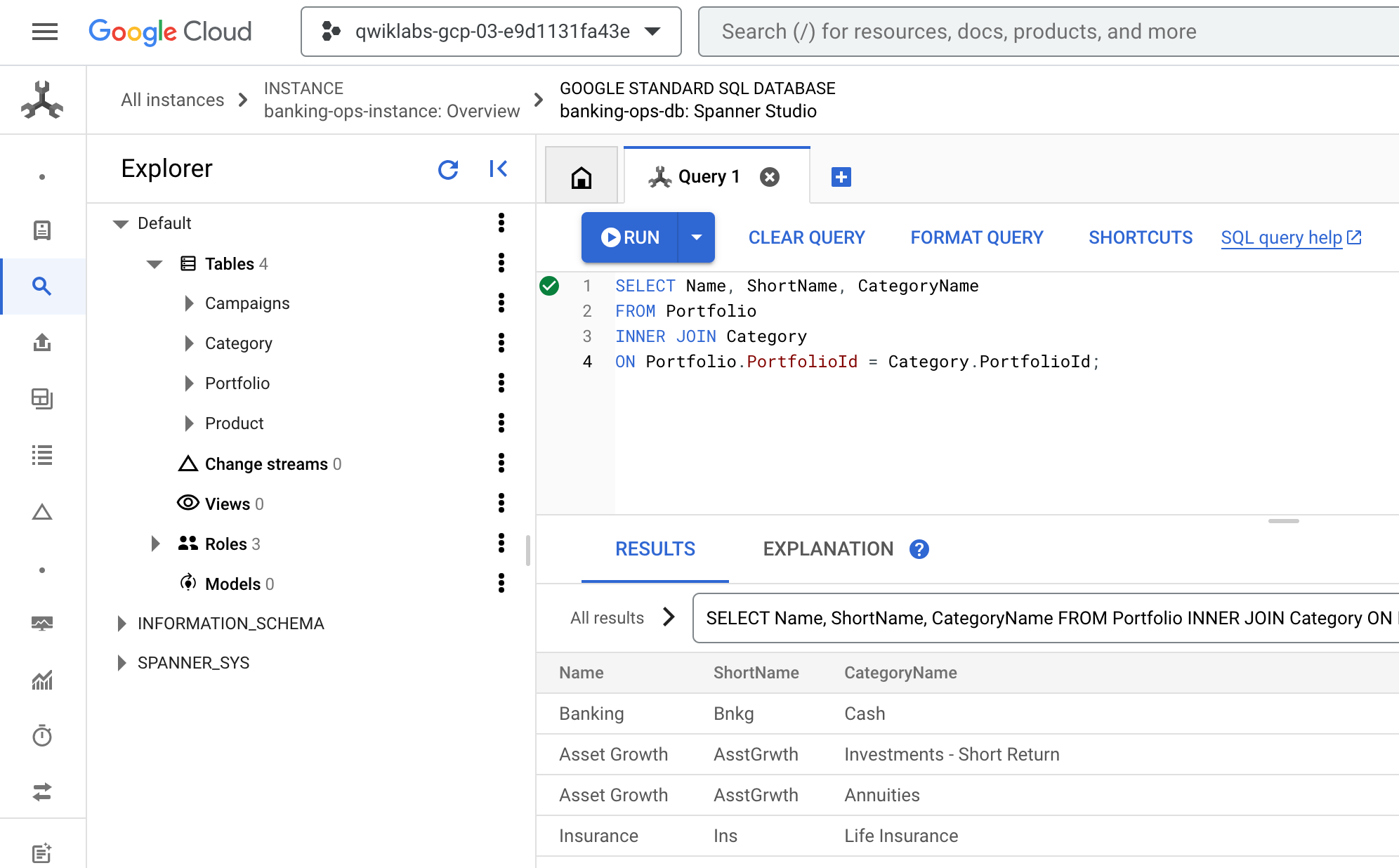
Cloud コンソールに戻ります。Spanner Studio の [クエリ] タブがまだ表示されているはずです。既存のクエリをクリアし、次のクエリを貼り付けて実行します。
SELECT Name, ShortName, CategoryName
FROM Portfolio
INNER JOIN Category
ON Portfolio.PortfolioId = Category.PortfolioId;
- 結果は次のようになります。
クエリのライフサイクル
Cloud Spanner の SQL クエリは、最初に実行プランにコンパイルされた後、実行のために最初のルートサーバーに送信されます。ルートサーバーは、クエリ対象のデータに到達するためのホップ数が最小になるように選択されます。ルートサーバーでは次の処理が行われます。
- サブプランのリモート実行を開始する(必要な場合)
- リモート実行からの結果を待つ
- 結果の集計など、残りのローカル実行ステップを処理する
- クエリの結果を返す
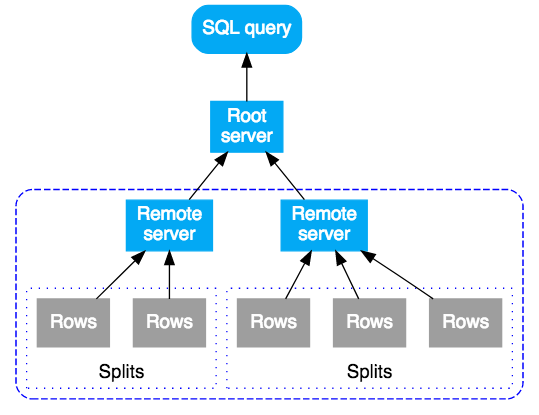
サブプランを受け取ったリモート サーバーは、そのサブプランに対する「ルート」サーバーとなり、最上位のルートサーバーと同じモデルに従います。結果として、リモート実行のツリーが形成されます。概念的には、クエリの実行は上位から下位に向かって行われ、クエリ結果は下位から上位に向かって返されます。次の図はこのパターンを示したものです。
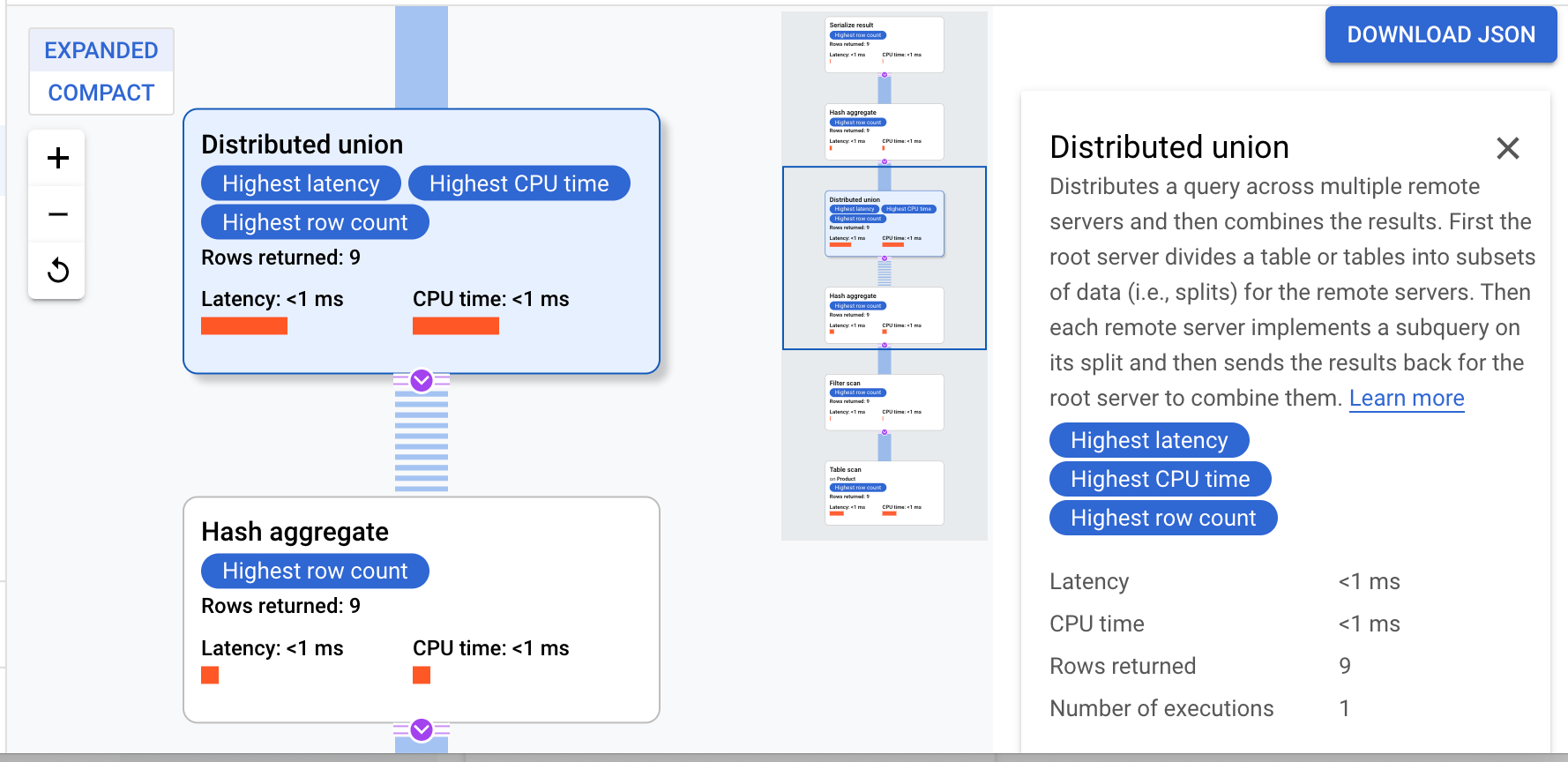
集計クエリ
次に、集計クエリのクエリプランを見てみましょう。
-
Spanner Studio の [クエリ] タブで、既存のクエリをクリアし、次のクエリを貼り付けて実行します。
SELECT pr.ProductId, COUNT(*) AS ProductCount
FROM Product AS pr
WHERE pr.ProductId < 100
GROUP BY pr.ProductId;
- クエリが完了したら、クエリ本文の下にある [説明] タブをクリックしてクエリプランを確認します。
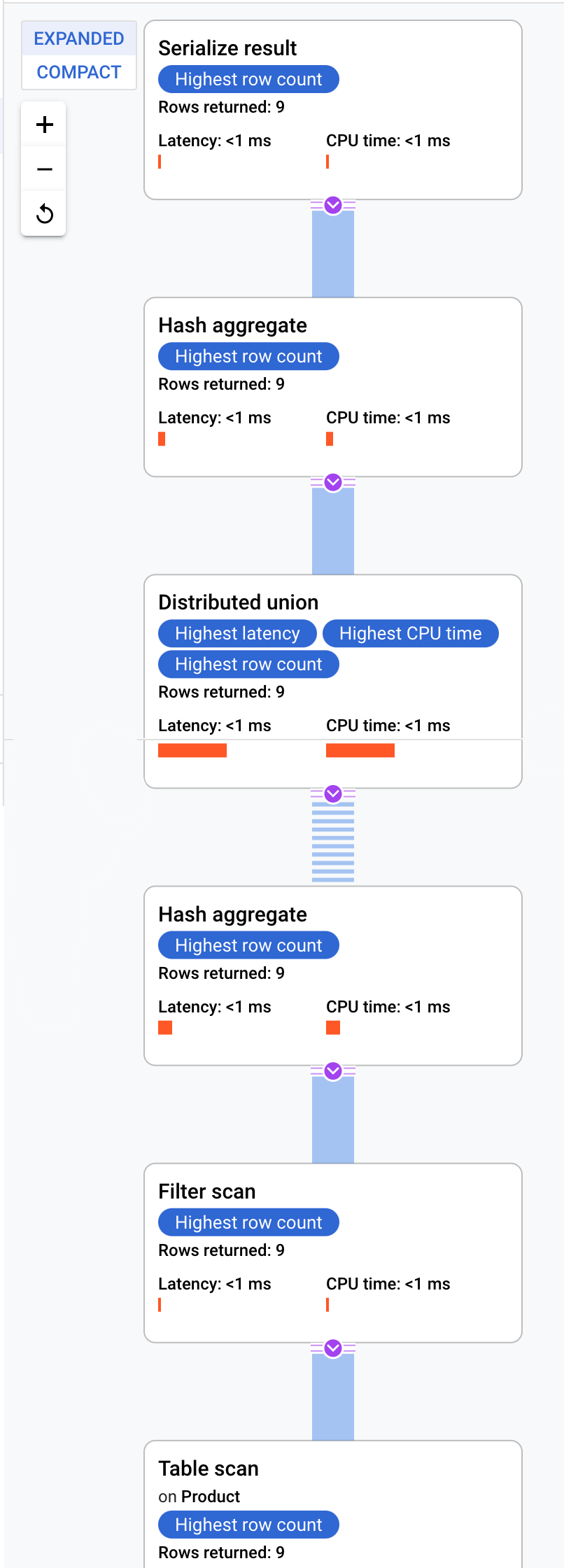
Cloud Spanner は、実行プランをルートサーバーに送信します。ルートサーバーはクエリの実行を調整し、サブプランのリモート分散を実行します。
この実行プランは、返されたすべての値を順序付けるシリアル化から始まります。その後、プランは最初のハッシュ集計演算子を完了して、結果を予備的に算出します。次に、分散ユニオンが実行され、スプリットが ProductId < 100 を満たすリモート サーバーにサブプランが分散されます。分散ユニオンは、結果を最終的なハッシュ集計演算子に送信します。集計演算子は ProductId による COUNT 集計を実行し、結果のシリアル化演算子に結果を返します。最後に、スキャンが実行され、返される結果が並べ替えられます。
結果は次のようになります。
ヒント: クエリプランの各ステップの詳細を確認するには、いずれかの演算子をクリックします。画面の右側がそれに応じて変化します。
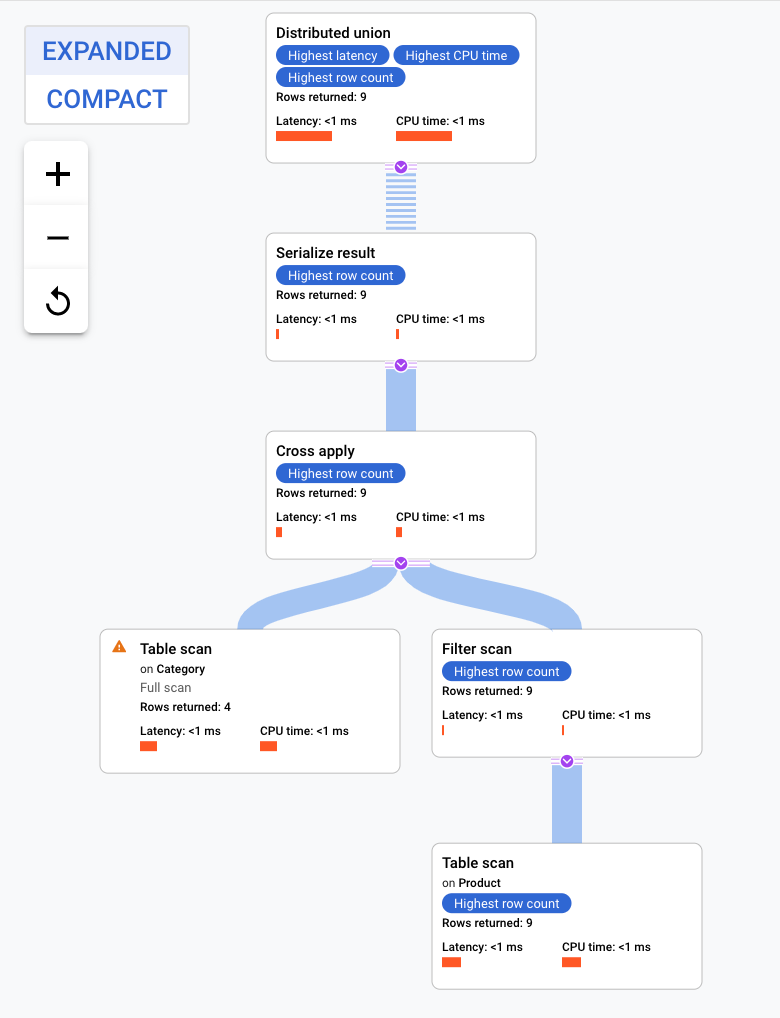
併置結合クエリ
インターリーブされたテーブルは、同じ場所に配置された関連のあるテーブルの行とともに物理的に格納されます。インターリーブされたテーブル間の結合は、併置結合と呼ばれます。併置結合は、インデックスを必要とする結合またはバック結合よりパフォーマンスが向上します。
-
Spanner Studio の [クエリ] タブで、既存のクエリをクリアし、次のクエリを貼り付けて実行します。
SELECT c.CategoryName, pr.ProductName
FROM Category AS c, Product AS pr
WHERE c.PortfolioId = pr.PortfolioId AND c.CategoryId = pr.CategoryId;
- クエリが完了したら、クエリ本文の下にある [説明] タブをクリックしてクエリプランを確認します。
この実行プランは分散ユニオンで開始します。この分散ユニオンは、テーブル Category のスプリットを含むリモート サーバーにサブプランを分散させます。Product は Category のインターリーブされたテーブルなので、各リモート サーバーは、異なるサーバーへの結合を必要とせずに、各リモート サーバー上でサブプラン全体を実行できます。
サブプランにはクロス適用が含まれます。各クロス適用は、テーブル Category でテーブル スキャンを実行し、PortfolioId、CategoryId、CategoryName を取得します。その後、クロス適用は、テーブル スキャンからの出力を、インデックス CategoryByCategoryName でのインデックス スキャンからの出力にマッピングします。これは、テーブル スキャン出力からの PortfolioId と一致するインデックスに PortfolioId のフィルタを適用したものです。各クロス適用は結果のシリアル化演算子に結果を送信します。この演算子は CategoryName と ProductName のデータをシリアル化し、結果をローカル分散ユニオンに返します。分散ユニオンはローカル分散ユニオンからの結果を集計し、それをクエリ結果として返します。
お疲れさまでした
これで、Cloud Spanner のスキーマ関連の機能と、Spanner がクエリプランを作成する方法について、しっかりと理解できました。
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2024 年 10 月 14 日
ラボの最終テスト日: 2024 年 10 月 14 日
Copyright 2026 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。





