GSP1050

Présentation
Cloud Spanner est le service de base de données relationnelle entièrement géré et à évolutivité horizontale de Google. Les clients des secteurs des services financiers, des jeux vidéo, du commerce et de bien d'autres domaines d'activité font confiance à Cloud Spanner pour exécuter leurs charges de travail les plus exigeantes, où la cohérence et la disponibilité à grande échelle sont primordiales.
Dans cet atelier, vous allez passer en revue les fonctionnalités de Cloud Spanner liées aux schémas et les appliquer à une base de données d'opérations bancaires. Vous découvrirez également les méthodes et les règles que Cloud Spanner utilise pour créer des plans de requête.
Objectifs de l'atelier
Dans cet atelier, vous allez apprendre à modifier les attributs liés au schéma d'une instance Cloud Spanner.
- Chargez des données dans des tables.
- Utilisez le code prédéfini de la bibliothèque cliente Python pour charger des données.
- Interrogez des données avec des bibliothèques clientes.
- Apportez des modifications au schéma de base de données.
- Ajoutez un index secondaire.
- Examinez des plans de requêtes.
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Des identifiants temporaires vous sont fournis pour vous permettre de vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- Vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome).
Remarque : Ouvrez une fenêtre de navigateur en mode incognito (recommandé) ou de navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
- Vous disposez d'un temps limité. N'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Utilisez uniquement le compte de participant pour cet atelier. Si vous utilisez un autre compte Google Cloud, des frais peuvent être facturés à ce compte.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, une boîte de dialogue s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la droite, vous trouverez le panneau Préparation et accès à l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google Cloud
- Les identifiants temporaires (nom d'utilisateur et mot de passe) que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier, si nécessaire
Notez que le minuteur de l'atelier se trouve en haut de la page et indique le temps restant.
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans une fenêtre en navigation privée si vous utilisez Chrome).
L'atelier lance les ressources, puis ouvre la page "Se connecter" dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
-
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}}
Vous trouverez également le nom d'utilisateur dans le panneau Préparation et accès à l'atelier.
-
Cliquez sur Suivant.
-
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}}
Vous trouverez également le mot de passe dans le panneau Préparation et accès à l'atelier.
-
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. N'utilisez pas les identifiants de votre compte Google Cloud.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires pourront vous être facturés.
-
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Pour accéder aux produits et services Google Cloud, cliquez sur le menu de navigation ou saisissez le nom du service ou du produit dans le champ Recherche.

Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud.
-
Cliquez sur Activer Cloud Shell  en haut de la console Google Cloud.
en haut de la console Google Cloud.
-
Passez les fenêtres suivantes :
- Accédez à la fenêtre d'informations de Cloud Shell.
- Autorisez Cloud Shell à utiliser vos identifiants pour effectuer des appels d'API Google Cloud.
Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET : . Le résultat contient une ligne qui déclare l'ID_PROJET pour cette session :
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
- (Facultatif) Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
gcloud auth list
- Cliquez sur Autoriser.
Résultat :
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (Facultatif) Vous pouvez lister les ID de projet à l'aide de cette commande :
gcloud config list project
Résultat :
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Remarque : Pour consulter la documentation complète sur gcloud, dans Google Cloud, accédez au guide de présentation de la gcloud CLI.
Instance Cloud Spanner
Pour vous permettre de progresser plus rapidement dans cet atelier, une instance, une base de données et des tables Cloud Spanner ont été créées automatiquement pour vous.
Voici quelques informations complémentaires pour vous aider :
| Élément |
Nom |
Détails |
| Instance Cloud Spanner |
banking-ops-instance |
Il s'agit de l'instance au niveau du projet |
| Base de données Cloud Spanner |
banking-ops-db |
Il s'agit de la base de données spécifique à l'instance |
| Table |
Portfolio |
Contient des offres bancaires générales |
| Table |
Category |
Contient des regroupements d'offres bancaires secondaires |
| Table |
Product |
Contient des offres bancaires spécifiques |
| Table |
Campaigns |
Contient des informations détaillées sur les initiatives marketing |
Tâche 1 : Charger les données dans des tables
La base de données banking-ops-db a été créée avec des tables vides. Suivez les étapes ci-dessous pour charger des données dans trois des tables (Portfolio, Category et Product).
-
Dans la console Cloud, ouvrez le menu de navigation ( ) > Afficher tous les produits. Sous Bases de données, cliquez sur Spanner.
) > Afficher tous les produits. Sous Bases de données, cliquez sur Spanner.
-
Le nom de l'instance est banking-ops-instance. Cliquez dessus pour explorer les bases de données.
-
La base de données associée s'appelle banking-ops-db. Cliquez dessus, faites défiler la page jusqu'à Tables, et vous verrez qu'il y a déjà quatre tables.
-
Dans le volet de gauche de la console, cliquez sur Spanner Studio. Cliquez ensuite sur le bouton + Nouvel onglet de l'éditeur SQL dans le cadre de droite.
-
Vous êtes alors redirigé vers la page Requête. Collez les instructions d'insertion ci-dessous en un seul bloc pour charger la table Portfolio. Spanner les exécutera successivement. Cliquez sur Exécuter :
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (1, "Banking", "Bnkg", "All Banking Business");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (2, "Asset Growth", "AsstGrwth", "All Asset Focused Products");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (3, "Insurance", "Ins", "All Insurance Focused Products");
-
La partie inférieure de l'écran affiche les résultats de l'insertion des données une ligne à la fois. Une coche verte apparaît également sur chaque ligne de données insérées. La table Portfolio contient maintenant trois lignes.
-
Cliquez sur Effacer en haut de la page.
-
Collez les instructions d'insertion ci-dessous en un seul bloc pour charger la table Category. Cliquez sur Exécuter :
insert into Category (CategoryId,PortfolioId,CategoryName) values (1,1,"Cash");
insert into Category (CategoryId,PortfolioId,CategoryName) values (2,2,"Investments - Short Return");
insert into Category (CategoryId,PortfolioId,CategoryName) values (3,2,"Annuities");
insert into Category (CategoryId,PortfolioId,CategoryName) values (4,3,"Life Insurance");
-
La partie inférieure de l'écran affiche les résultats de l'insertion des données une ligne à la fois. Une coche verte apparaît également sur chaque ligne de données insérées. La table Category contient maintenant quatre lignes.
-
Cliquez sur Effacer en haut de la page.
-
Collez les instructions d'insertion ci-dessous en un seul bloc pour charger la table Product. Cliquez sur Exécuter :
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (1,1,1,"Checking Account","ChkAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (2,2,2,"Mutual Fund Consumer Goods","MFundCG","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (3,3,2,"Annuity Early Retirement","AnnuFixed","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (4,4,3,"Term Life Insurance","TermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (5,1,1,"Savings Account","SavAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (6,1,1,"Personal Loan","PersLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (7,1,1,"Auto Loan","AutLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (8,4,3,"Permanent Life Insurance","PermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (9,2,2,"US Savings Bonds","USSavBond","Investment LOB");
-
La partie inférieure de l'écran affiche les résultats de l'insertion des données une ligne à la fois. Une coche verte apparaît également sur chaque ligne de données insérées. La table Product contient maintenant neuf lignes.
-
Cliquez sur Vérifier ma progression pour valider l'objectif.
Charger des données dans les tables "Portfolio", "Category" et "Product"
Tâche 2 : Utiliser du code prédéfini de bibliothèques clientes Python pour charger des données
Dans les prochaines étapes, vous allez utiliser les bibliothèques clientes écrites en Python.
- Ouvrez Cloud Shell et collez les commandes ci-dessous pour créer un répertoire et y accéder. Ce répertoire contiendra les fichiers requis.
mkdir python-helper
cd python-helper
- Ensuite, téléchargez deux fichiers. L'un sert à configurer l'environnement. L'autre est le code de l'atelier.
wget https://storage.googleapis.com/cloud-training/OCBL373/requirements.txt
wget https://storage.googleapis.com/cloud-training/OCBL373/snippets.py
- Créez un environnement Python isolé et installez les dépendances pour le client Cloud Spanner.
pip install -r requirements.txt
pip install setuptools
- Le fichier snippets.py est un fichier consolidé contenant plusieurs fonctions LDD, LMD et LCD Cloud Spanner que vous allez utiliser comme aide pendant cet atelier. Exécutez snippets.py en utilisant l'argument insert_data pour remplir la table Campaigns.
python snippets.py banking-ops-instance --database-id banking-ops-db insert_data
- Cliquez sur Vérifier ma progression pour valider l'objectif.
Charger des données dans la table "Campaigns"
Tâche 3 : Interroger des données avec des bibliothèques clientes
La fonction query_data() dans snippets.py peut servir à interroger votre base de données. Dans ce cas, vous l'utilisez pour confirmer que les données ont bien été chargées dans la table Campaigns. Aucune modification n'est à apporter ici, cette portion de code n'est présentée qu'à titre de référence.
def query_data(instance_id, database_id):
"""Queries sample data from the database using SQL."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
results = snapshot.execute_sql(
"SELECT CampaignId,PortfolioId,CampaignStartDate,CampaignEndDate,CampaignName,CampaignBudget FROM Campaigns"
)
for row in results:
print(u"CampaignId: {}, PortfolioId: {}, CampaignStartDate: {}, CampaignEndDate: {}, CampaignName: {}, CampaignBudget: {}".format(*row))
- Exécutez snippets.py avec l'argument query_data pour interroger la table Campaigns.
python snippets.py banking-ops-instance --database-id banking-ops-db query_data
Le résultat devrait ressembler à ce qui suit :
CampaignId: 1, PortfolioId: 1, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: New Account Reward, CampaignBudget: 15000
CampaignId: 2, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Intro to Investments, CampaignBudget: 5000
CampaignId: 3, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Youth Checking Accounts, CampaignBudget: 25000
CampaignId: 4, PortfolioId: 3, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Protect Your Family, CampaignBudget: 10000
Tâche 4 : Mettre à jour le schéma de base de données
En tant qu'administrateur de base de données, vous devez ajouter une colonne MarketingBudget à la table Category. L'ajout d'une colonne à une table existante nécessite une mise à jour du schéma de base de données. Cloud Spanner permet de mettre à jour le schéma d'une base de données pendant que celle-ci continue de diffuser du trafic. Les mises à jour du schéma ne nécessitent pas la mise hors connexion de la base de données et ne verrouillent pas des tables ou des colonnes entières. Vous pouvez continuer à écrire des données dans la base de données pendant ces mises à jour.
Ajouter une colonne à l'aide de Python
La méthode update_ddl() de la classe Database permet de modifier le schéma.
Utilisez la fonction add_column() dans snippets.py, qui implémente cette méthode. Aucune modification n'est à apporter ici, cette portion de code n'est présentée qu'à titre de référence.
def add_column(instance_id, database_id):
"""Adds a new column to the Albums table in the example database."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["ALTER TABLE Category ADD COLUMN MarketingBudget INT64"]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the MarketingBudget column.")
- Exécutez snippets.py en spécifiant l'argument add_column.
python snippets.py banking-ops-instance --database-id banking-ops-db add_column
- Cliquez sur Vérifier ma progression pour valider l'objectif.
Ajouter une colonne à la table "Category"
Voici d'autres options pour ajouter une colonne à une table existante :
Émettre une commande DDL via la gcloud CLI.
Remarque : Cette option est présentée à titre d'exemple. N'exécutez pas la commande.
L'exemple de code ci-dessous effectue la même tâche que celle que vous venez d'exécuter via Python.
gcloud spanner databases ddl update banking-ops-db --instance=banking-ops-instance --ddl='ALTER TABLE Category ADD COLUMN MarketingBudget INT64;'
Émettre une commande LDD dans la console Cloud
Remarque : Cette option est présentée à titre d'exemple. N'effectuez pas cette action.
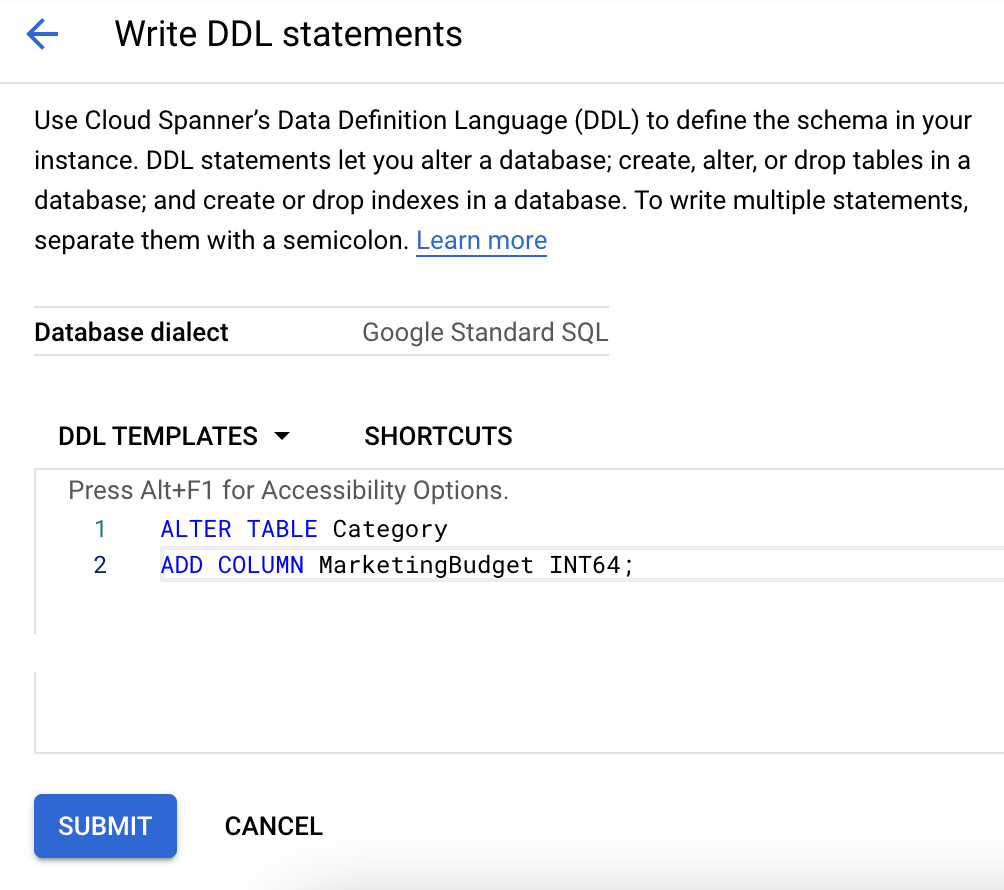
- Cliquez sur le nom de la table dans la liste des bases de données.
- Cliquez sur Écrire un DDL en haut à droite de la page.
- Collez le DDL approprié dans la zone Modèles DDL.
- Cliquez sur Envoyer.
Écrire des données dans la nouvelle colonne
Le code ci-dessous permet d'écrire des données dans la nouvelle colonne. Il définit MarketingBudget sur 100000 pour la ligne avec un CategoryId de 1 et un PortfolioId de 1, et sur 500000 pour la ligne avec un CategoryId de 3 et un PortfolioId de 2. Aucune modification n'est à apporter ici, cette portion de code n'est présentée qu'à titre de référence.
def update_data(instance_id, database_id):
"""Updates sample data in the database.
Cette requête met à jour la colonne "MarketingBudget", qui doit être créée avant d'exécuter cet exemple. Vous pouvez ajouter la colonne en exécutant l'exemple "add_column" ou cette instruction DDL sur votre base de données :
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.batch() as batch:
batch.update(
table="Category",
columns=("CategoryId", "PortfolioId", "MarketingBudget"),
values=[(1, 1, 100000), (3, 2, 500000)],
)
print("Updated data.")
- Exécutez snippets.py en spécifiant l'argument update_data.
python snippets.py banking-ops-instance --database-id banking-ops-db update_data
- Interrogez à nouveau la table pour voir la mise à jour. Exécutez snippets.py en utilisant l'argument query_data_with_new_column.
python snippets.py banking-ops-instance --database-id banking-ops-db query_data_with_new_column
Vous devez obtenir le résultat suivant :
CategoryId: 1, PortfolioId: 1, MarketingBudget: 100000
CategoryId: 2, PortfolioId: 2, MarketingBudget: None
CategoryId: 3, PortfolioId: 2, MarketingBudget: 500000
CategoryId: 4, PortfolioId: 3, MarketingBudget: None
Tâche 5 : Ajouter un index secondaire
Supposons que vous vouliez récupérer toutes les lignes de la table "Category" dont les valeurs "CategoryNames" sont comprises dans une certaine plage. Vous pouvez lire toutes les valeurs de la colonne CategoryName à l'aide d'une instruction SQL ou d'un appel de lecture, puis supprimer les lignes qui ne correspondent pas aux critères. Toutefois, cette analyse complète de la table est coûteuse, en particulier si celle-ci comporte beaucoup de lignes. Pour accélérer la récupération des lignes lors de recherches par colonnes de clés non primaires, créez plutôt un index secondaire pour la table.
L'ajout d'un index secondaire à une table existante nécessite une mise à jour du schéma. Comme pour les autres mises à jour de schéma, le service Cloud Spanner permet d'ajouter l'index alors que la base de données continue de diffuser du trafic. Il insère des données dans l'index (on parle de "remplissage") en arrière-plan. Les remplissages peuvent prendre quelques minutes. Toutefois, ce processus ne requiert pas la mise hors connexion de la base de données et ne vous empêche pas d'écrire dans certaines tables ou colonnes.
Ajouter un index secondaire à l'aide de la bibliothèque cliente Python
Utilisez la méthode add_index() pour créer un index secondaire. Aucune modification n'est à apporter ici, cette portion de code n'est présentée qu'à titre de référence.
def add_index(instance_id, database_id):
"""Adds a simple index to the example database."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["CREATE INDEX CategoryByCategoryName ON Category(CategoryName)"]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the CategoryByCategoryName index.")
- Exécutez snippets.py en spécifiant l'argument add_index.
python snippets.py banking-ops-instance --database-id banking-ops-db add_index
- Cliquez sur Vérifier ma progression pour valider l'objectif.
Ajouter un index secondaire à la table "Category"
Lire des données avec l'index
Pour lire des données à l'aide de l'index, appelez une variante de la méthode read() en incluant un index. Aucune modification n'est à apporter ici, cette portion de code n'est présentée qu'à titre de référence.
def read_data_with_index(instance_id, database_id):
"""Reads sample data from the database using an index.
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName"),
keyset=keyset,
index="CategoryByCategoryName",
)
for row in results:
print("CategoryId: {}, CategoryName: {}".format(*row))
- Exécutez snippets.py en spécifiant l'argument read_data_with_index.
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_index
Le résultat doit ressembler à ceci :
CategoryId: 3, CategoryName: Annuities
CategoryId: 1, CategoryName: Cash
CategoryId: 2, CategoryName: Investments - Short Return
CategoryId: 4, CategoryName: Life Insurance
Ajouter un index avec une clause STORING
Vous avez peut-être remarqué que l'exemple ci-dessus n'incluait pas la lecture de la colonne MarketingBudget. En effet, l'interface de lecture de Cloud Spanner ne permet pas de joindre un index à une table de données pour rechercher des valeurs qui ne sont pas stockées dans l'index.
Pour contourner cette restriction, créez une autre définition de l'index CategoryByCategoryName qui stocke une copie de MarketingBudget dans l'index.
Utilisez la méthode update_ddl() de la classe Database pour ajouter un index avec une clause STORING. Aucune modification n'est à apporter ici, cette portion de code n'est présentée qu'à titre de référence.
def add_storing_index(instance_id, database_id):
"""Adds an storing index to the example database."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
[
"CREATE INDEX CategoryByCategoryName2 ON Category(CategoryName)"
"STORING (MarketingBudget)"
]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the CategoryByCategoryName2 index.")
- Exécutez snippets.py en spécifiant l'argument add_storing_index.
python snippets.py banking-ops-instance --database-id banking-ops-db add_storing_index
Vous pouvez maintenant exécuter une opération de lecture permettant de récupérer les colonnes CategoryId, CategoryName et MarketingBudget à l'aide de l'index CategoryByCategoryName2. Aucune modification n'est à apporter ici, cette portion de code n'est présentée qu'à titre de référence.
def read_data_with_storing_index(instance_id, database_id):
"""Reads sample data from the database using an index with a storing
clause.
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName", "MarketingBudget"),
keyset=keyset,
index="CategoryByCategoryName2",
)
for row in results:
print(u"CategoryNameId: {}, CategoryName: {}, " "MarketingBudget: {}".format(*row))
- Exécutez snippets.py en spécifiant l'argument read_data_with_storing_index.
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_storing_index
Vous devez obtenir le résultat suivant :
CategoryNameId: 3, CategoryName: Annuities, MarketingBudget: 500000
CategoryNameId: 1, CategoryName: Cash, MarketingBudget: 100000
CategoryNameId: 2, CategoryName: Investments - Short Return, MarketingBudget: None
CategoryNameId: 4, CategoryName: Life Insurance, MarketingBudget: None
Tâche 6 : Examiner des plans de requêtes
Dans cette section, vous allez découvrir les plans de requête Cloud Spanner.
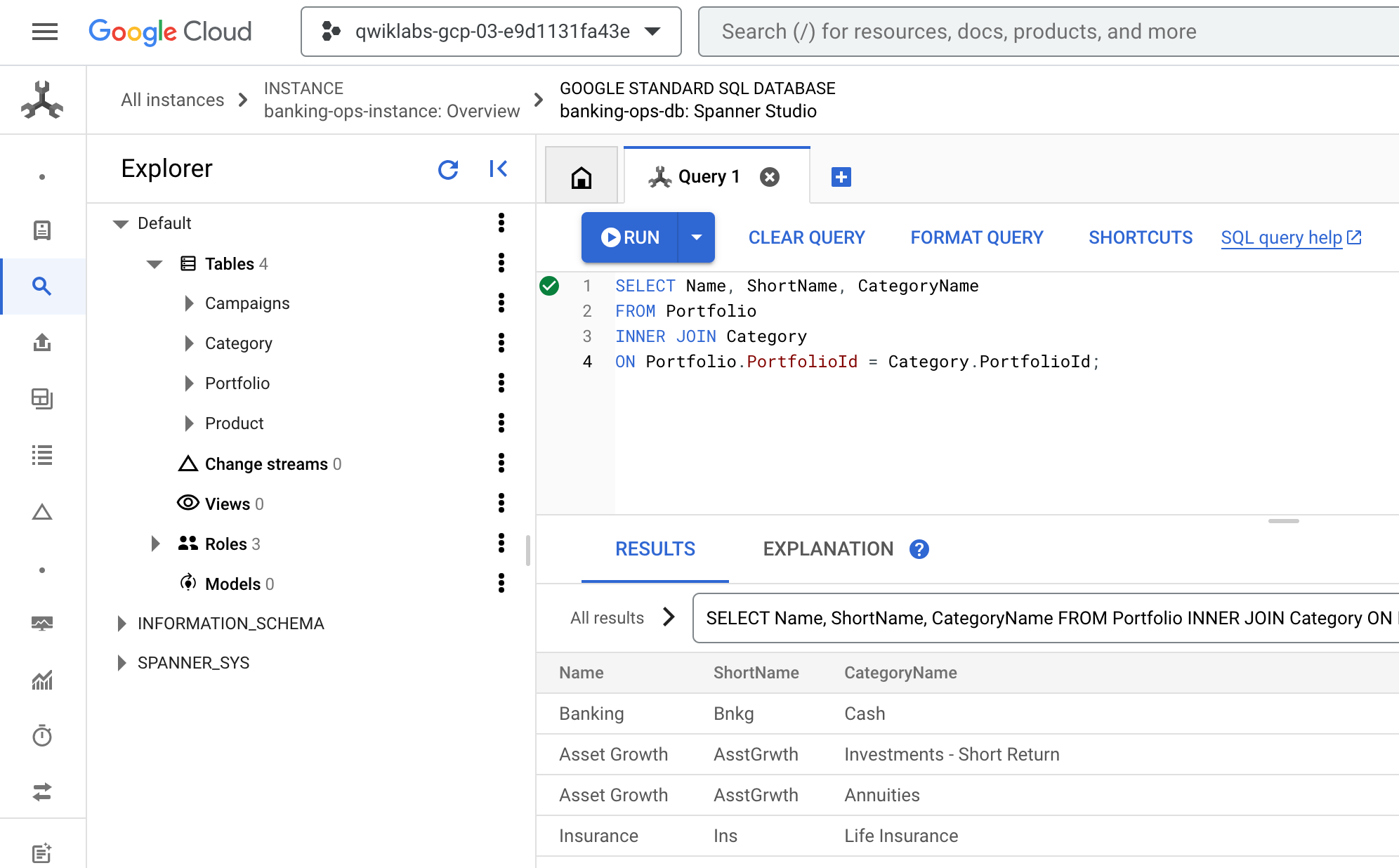
- Revenez à la console Cloud. L'onglet Requête de Spanner Studio doit toujours être ouvert. Effacez toute requête existante, collez la requête suivante, puis cliquez sur Exécuter :
SELECT Name, ShortName, CategoryName
FROM Portfolio
INNER JOIN Category
ON Portfolio.PortfolioId = Category.PortfolioId;
- Le résultat doit ressembler à ceci :
Cycle de vie d'une requête
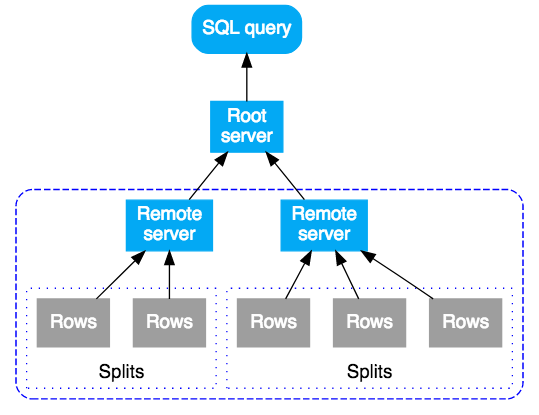
Une requête SQL dans Cloud Spanner est d'abord compilée dans un plan d'exécution, puis envoyée à un serveur racine initial pour exécution. Le serveur racine est choisi de manière à réduire le nombre de sauts nécessaires pour atteindre les données interrogées. Puis, le serveur racine :
- lance l'exécution à distance des sous-plans (si nécessaire) ;
- attend les résultats des exécutions à distance ;
- gère toutes les étapes d'exécution locales restantes, telles que l'agrégation des résultats ;
- renvoie les résultats de la requête.
Les serveurs distants qui reçoivent un sous-plan agissent comme serveur "racine" de ce sous-plan, et suivent le même modèle que le serveur racine initial. On obtient donc une arborescence d'exécutions à distance. Sur le plan conceptuel, l'exécution de la requête se fait de haut en bas, et les résultats de la requête sont renvoyés de bas en haut. Le diagramme suivant illustre ce schéma :
Requête d'agrégation
Examinons maintenant le plan pour une requête d'agrégation.
- Dans l'onglet Requête de Spanner Studio, effacez la requête existante, collez la requête suivante, puis cliquez sur Exécuter.
SELECT pr.ProductId, COUNT(*) AS ProductCount
FROM Product AS pr
WHERE pr.ProductId < 100
GROUP BY pr.ProductId;
- Une fois la requête exécutée, cliquez sur l'onglet Explication sous le corps de la requête pour examiner le plan de requête.
Cloud Spanner envoie le plan d'exécution à un serveur racine qui coordonne l'exécution de la requête et effectue la distribution à distance des sous-plans.
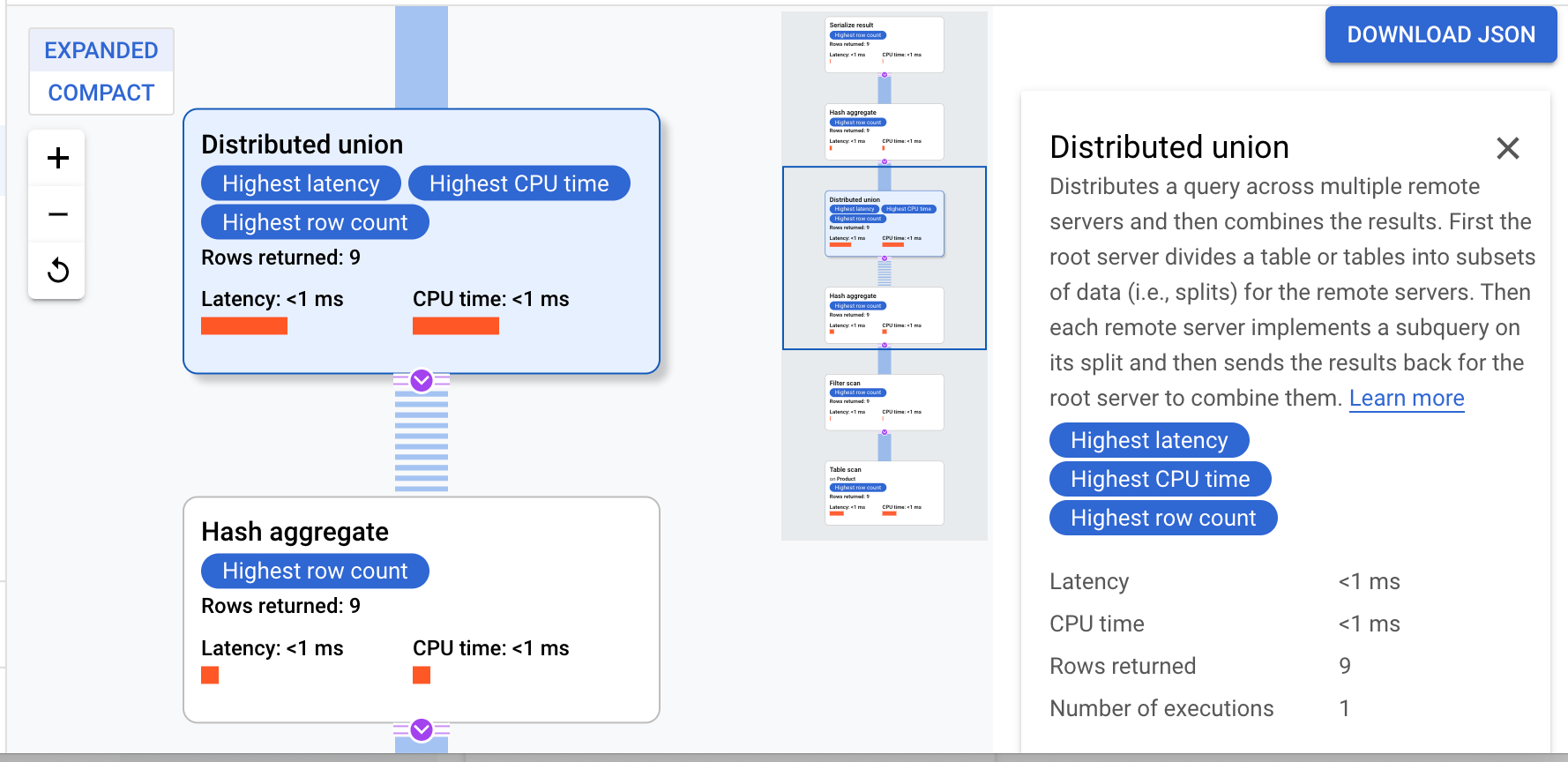
Ce plan d'exécution commence par une sérialisation qui ordonne toutes les valeurs renvoyées. Le plan exécute ensuite un opérateur d'agrégation par hachage initial pour calculer les résultats préliminaires. Ensuite, une union distribuée est exécutée, qui distribue des sous-plans aux serveurs distants avec des divisions répondant à la condition ProductId < 100. L'union distribuée envoie les résultats à un opérateur d'agrégation par hachage final. L'opérateur d'agrégation effectue l'agrégation COUNT par ProductId et renvoie les résultats à un opérateur de sérialisation de résultat. Enfin, une analyse est effectuée pour classer les résultats à renvoyer.
Le résultat doit ressembler à ceci :
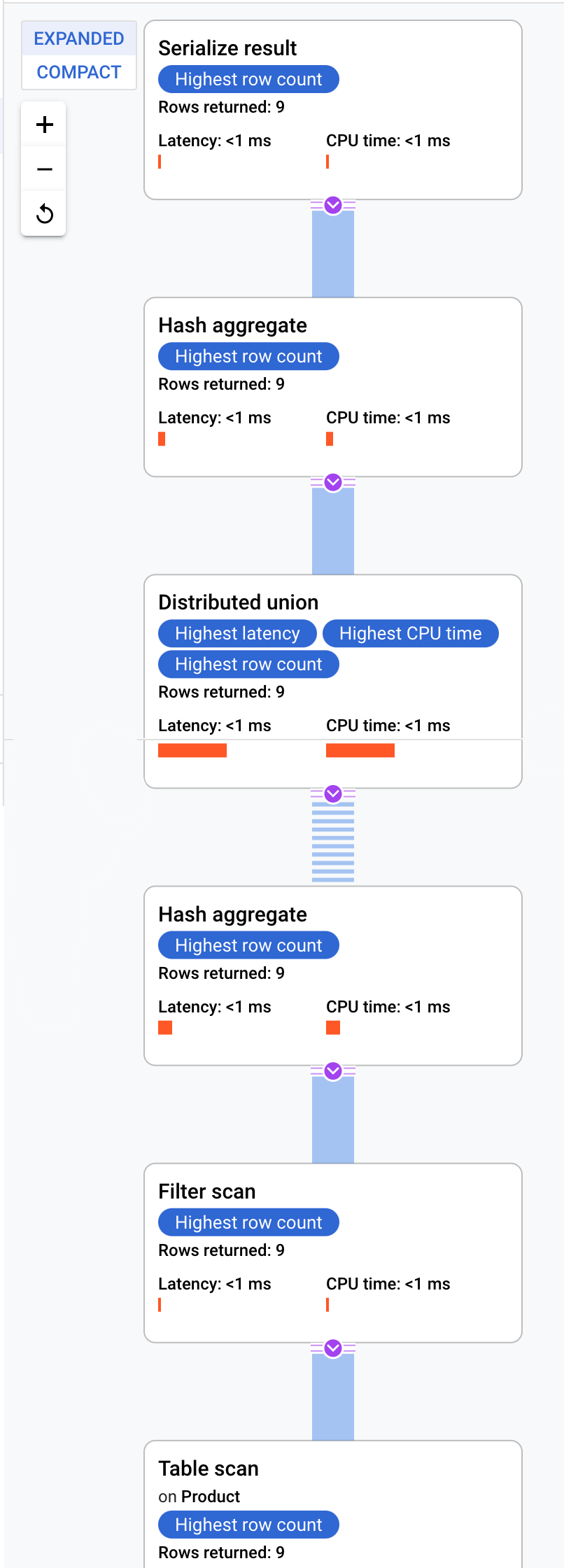
Conseil : Pour obtenir plus de détails sur chaque étape du plan de requête, cliquez sur l'un des opérateurs. La partie droite de l'écran est modifiée en conséquence.
Requêtes de jointure colocalisée
Les tables entrelacées sont stockées physiquement, avec leurs lignes de tables associées colocalisées. Une jointure entre des tables entrelacées est appelée jointure colocalisée. Ce type de jointure peut offrir de meilleures performances que les jointures nécessitant des index ou des jointures ultérieures.
- Dans l'onglet Requête de Spanner Studio, effacez la requête existante, collez la requête suivante, puis cliquez sur Exécuter.
SELECT c.CategoryName, pr.ProductName
FROM Category AS c, Product AS pr
WHERE c.PortfolioId = pr.PortfolioId AND c.CategoryId = pr.CategoryId;
- Une fois la requête exécutée, cliquez sur l'onglet Explication sous le corps de la requête pour examiner le plan de requête.
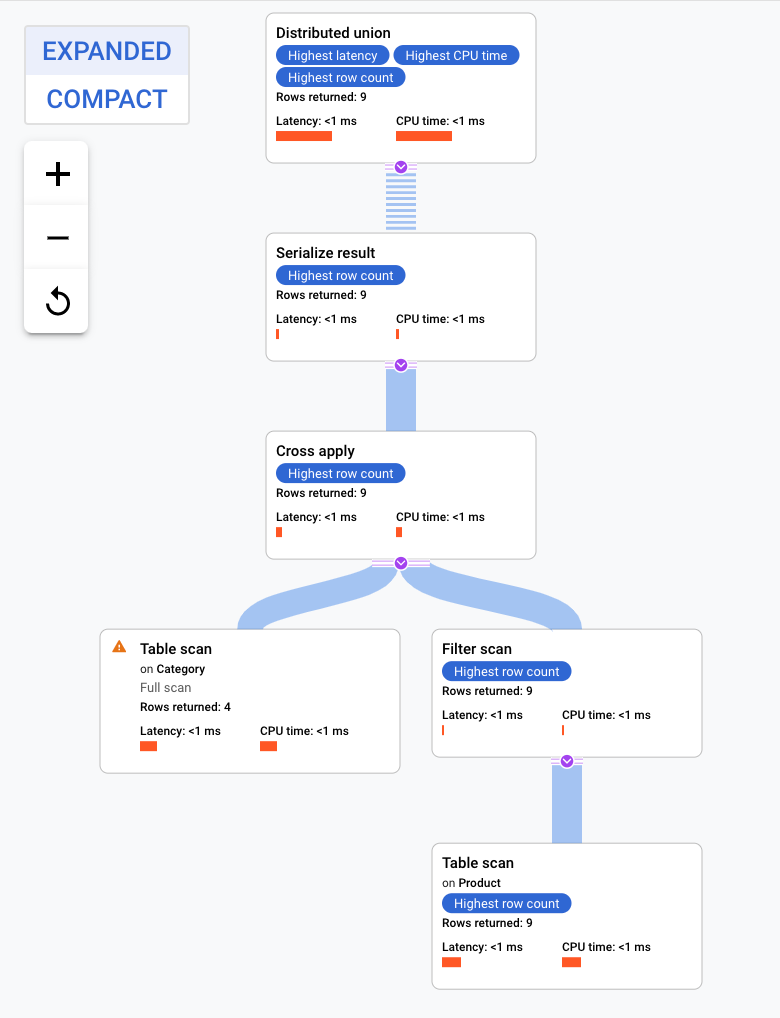
Ce plan d'exécution commence par une union distribuée, qui distribue des sous-plans aux serveurs distants contenant des divisions de la table Category. Comme Product est une table entrelacée de Category, chaque serveur distant peut exécuter l'intégralité du sous-plan sans avoir à ajouter une jointure à un autre serveur.
Les sous-plans contiennent une application croisée. Chaque application croisée effectue une analyse sur la table Category pour récupérer PortfolioId, CategoryId et CategoryName. L'application croisée mappe ensuite les résultats de l'analyse de la table avec ceux d'une analyse de l'index CategoryByCategoryName, avec la condition que le PortfolioId de l'index corresponde au PortfolioId du résultat de l'analyse de la table. Chaque application croisée envoie ses résultats à un opérateur qui sérialise les données CategoryName et ProductName, et renvoie les résultats aux unions distribuées locales. L'union distribuée agrège les résultats provenant des unions distribuées locales, puis les renvoie en tant que résultats de la requête.
Félicitations !
Vous maîtrisez désormais les fonctionnalités de Cloud Spanner liées aux schémas, ainsi que les méthodes utilisées par Spanner pour créer des plans de requête.
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 14 octobre 2024
Dernier test de l'atelier : 14 octobre 2024
Copyright 2026 Google LLC. Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.





