GSP1050

Descripción general
Cloud Spanner es el servicio de base de datos relacional de Google, completamente administrado y con escalabilidad horizontal. Clientes de servicios financieros, juegos, venta minorista y muchas otras industrias confían en él para ejecutar sus cargas de trabajo más exigentes, en las que la coherencia y la disponibilidad a gran escala son fundamentales.
En este lab, revisarás las funciones relacionadas con el esquema de Cloud Spanner y las aplicarás a una base de datos de operaciones bancarias. También revisarás los métodos y las reglas con los que Cloud Spanner crea planes de consultas.
Actividades
En este lab, aprenderás a modificar los atributos relacionados con el esquema de una instancia de Cloud Spanner.
- Cargar datos en tablas
- Usar código predefinido de la biblioteca cliente de Python para cargar datos
- Consultar datos con bibliotecas cliente
- Realizar actualizaciones en el esquema de la base de datos
- Agregar un índice secundario
- Examinar los planes de consultas
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs cuentan con un temporizador que no se puede pausar. El temporizador, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar. Se recomienda el navegador Chrome.
Nota: Usa una ventana del navegador privada o de incógnito (opción recomendada) para ejecutar el lab. Así evitarás conflictos entre tu cuenta personal y la cuenta de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
- Tiempo para completar el lab (recuerda que, una vez que comienzas un lab, no puedes pausarlo).
Nota: Usa solo la cuenta de estudiante para este lab. Si usas otra cuenta de Google Cloud, es posible que se apliquen cargos a esa cuenta.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
-
Haz clic en el botón Comenzar lab. Si debes pagar por el lab, se abrirá un diálogo para que selecciones la forma de pago.
A la derecha, se encuentra el panel Configuración del lab y acceso, que tiene los siguientes elementos:
- El botón Abrir la consola de Google Cloud
- Las credenciales temporales (nombre de usuario y contraseña) que debes usar para este lab
- Otra información para completar el lab (si es necesaria)
Ten en cuenta que el cronómetro del lab se encuentra cerca de la parte superior de la página y muestra el tiempo restante.
-
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia los recursos y abre otra pestaña, en la que se muestra la página de acceso.
Sugerencia: Ordena las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usa otra cuenta.
-
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}}
También puedes encontrar el nombre de usuario en el panel Configuración del lab y acceso.
-
Haz clic en Siguiente.
-
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}}
También puedes encontrar la contraseña en el panel Configuración del lab y acceso.
-
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud.
Nota: Usar tu propia cuenta de Google Cloud para este lab podría generar cargos adicionales.
-
Haz clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación ni autenticación de dos factores, ya que esta cuenta es temporal.
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.
Nota: Para acceder a los productos y servicios de Google Cloud, haz clic en el menú de navegación o escribe el nombre del servicio o producto en el campo Buscar.

Activa Cloud Shell
Cloud Shell es una máquina virtual que cuenta con herramientas para desarrolladores. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a tus recursos de Google Cloud.
-
Haz clic en Activar Cloud Shell  en la parte superior de la consola de Google Cloud.
en la parte superior de la consola de Google Cloud.
-
Haz clic para avanzar por las siguientes ventanas:
- Continúa en la ventana de información de Cloud Shell.
- Autoriza a Cloud Shell para que use tus credenciales para realizar llamadas a la API de Google Cloud.
Cuando te conectes, habrás completado la autenticación, y el proyecto estará configurado con tu Project_ID, . El resultado contiene una línea que declara el Project_ID para esta sesión:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud es la herramienta de línea de comandos de Google Cloud. Viene preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
- Puedes solicitar el nombre de la cuenta activa con este comando (opcional):
gcloud auth list
- Haz clic en Autorizar.
Resultado:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Puedes solicitar el ID del proyecto con este comando (opcional):
gcloud config list project
Resultado:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Nota: Para obtener toda la documentación de gcloud, en Google Cloud, consulta la guía con la descripción general de gcloud CLI.
Instancia de Cloud Spanner
Para que puedas avanzar más rápido en este lab, se crearon automáticamente una instancia, una base de datos y tablas de Cloud Spanner.
Estos son algunos detalles para tu referencia:
| Elemento |
Nombre |
Detalles |
| Instancia de Cloud Spanner |
banking-ops-instance |
Esta es la instancia a nivel de proyecto |
| Base de datos de Cloud Spanner |
banking-ops-db |
Esta es la base de datos específica de la instancia |
| Tabla |
Portfolio |
Contiene ofertas bancarias de nivel superior |
| Tabla |
Category |
Contiene agrupaciones de ofertas bancarias de segundo nivel |
| Tabla |
Product |
Contiene ofertas bancarias específicas de concepto |
| Tabla |
Campaigns |
Contiene detalles sobre las iniciativas de marketing |
Tarea 1. Cargar datos en tablas
Se creó la banking-ops-db con tablas vacías. Sigue los pasos que se indican a continuación para cargar datos en tres de las tablas (Portfolio, Category y Product).
-
En la consola de Cloud, abre el menú de navegación ( ) > Ver todos los productos y, en Bases de datos, haz clic en Spanner.
) > Ver todos los productos y, en Bases de datos, haz clic en Spanner.
-
El nombre de la instancia es banking-ops-instance. Haz clic en el nombre para explorar las bases de datos.
-
La base de datos asociada se llama banking-ops-db. Haz clic en el nombre, desplázate hacia abajo hasta Tablas y verás que ya hay cuatro tablas.
-
En el panel izquierdo de la consola, haz clic en Spanner Studio. Luego, haz clic en el botón + Nueva pestaña del editor de SQL en el marco derecho.
-
Esta acción te llevará a la página Consulta. Pega las siguientes instrucciones de inserción como un solo bloque para cargar la tabla Portfolio. Spanner ejecutará cada una en sucesión. Haz clic en Ejecutar:
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (1, "Banking", "Bnkg", "All Banking Business");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (2, "Asset Growth", "AsstGrwth", "All Asset Focused Products");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (3, "Insurance", "Ins", "All Insurance Focused Products");
-
En la parte inferior de la pantalla, se muestran los resultados de insertar los datos una fila a la vez. También aparece una marca de verificación verde en cada fila de los datos insertados. Ahora la tabla Portfolio tiene tres filas.
-
Haz clic en Borrar en la parte superior de la página.
-
Pega las instrucciones de inserción que se encuentran a continuación como un solo bloque para cargar la tabla Category. Haz clic en Ejecutar:
insert into Category (CategoryId,PortfolioId,CategoryName) values (1,1,"Efectivo");
insert into Category (CategoryId,PortfolioId,CategoryName) values (2,2,"Inversiones - Retorno a Corto Plazo");
insert into Category (CategoryId,PortfolioId,CategoryName) values (3,2,"Anualidades");
insert into Category (CategoryId,PortfolioId,CategoryName) values (4,3,"Seguros de Vida");
-
En la parte inferior de la pantalla, se muestran los resultados de insertar los datos una fila a la vez. También aparece una marca de verificación verde en cada fila de los datos insertados. Ahora la tabla Category tiene cuatro filas.
-
Haz clic en Borrar en la parte superior de la página.
-
Pega las instrucciones de inserción que se muestran a continuación como un solo bloque para cargar la tabla Product. Haz clic en Ejecutar:
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (1,1,1,"Checking Account","ChkAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (2,2,2,"Mutual Fund Consumer Goods","MFundCG","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (3,3,2,"Annuity Early Retirement","AnnuFixed","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (4,4,3,"Term Life Insurance","TermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (5,1,1,"Savings Account","SavAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (6,1,1,"Personal Loan","PersLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (7,1,1,"Auto Loan","AutLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (8,4,3,"Permanent Life Insurance","PermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (9,2,2,"US Savings Bonds","USSavBond","Investment LOB");
-
En la parte inferior de la pantalla, se muestran los resultados de insertar los datos una fila a la vez. También aparece una marca de verificación verde en cada fila de los datos insertados. Ahora la tabla Product tiene nueve filas.
-
Haz clic en Revisar mi progreso para verificar el objetivo.
Cargar datos en las tablas de Portfolio, Category y Product
Tarea 2. Usar código de biblioteca cliente de Python precompilado para cargar datos
Usarás las bibliotecas cliente escritas en Python en los próximos pasos.
- Abre Cloud Shell y pega los comandos que se indican a continuación para crear un directorio nuevo y cambiar a él con el propósito de almacenar los archivos necesarios.
mkdir python-helper
cd python-helper
- Luego, descarga dos archivos. Uno se usa para configurar el entorno. El otro es el código del lab.
wget https://storage.googleapis.com/cloud-training/OCBL373/requirements.txt
wget https://storage.googleapis.com/cloud-training/OCBL373/snippets.py
- Crea un entorno aislado de Python y, luego, instala las dependencias para el cliente de Cloud Spanner.
pip install -r requirements.txt
pip install setuptools
- El archivo snippets.py es un archivo consolidado con varias funciones DDL, DML y DCL de Cloud Spanner que usarás como ayuda durante este lab. Ejecuta snippets.py con el argumento insert_data para completar la tabla Campaigns.
python snippets.py banking-ops-instance --database-id banking-ops-db insert_data
- Haz clic en Revisar mi progreso para verificar el objetivo.
Cargar datos en la tabla Campaigns
Tarea 3. Consultar datos con bibliotecas cliente
La función query_data() en snippets.py se puede usar para consultar tu base de datos. En este caso, la usas para confirmar los datos cargados en la tabla Campaigns. No cambiarás ningún código, la sección se muestra aquí para que tengas una referencia.
def query_data(instance_id, database_id):
"""Consulta datos de ejemplo de la base de datos usando SQL."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
results = snapshot.execute_sql(
"SELECT CampaignId,PortfolioId,CampaignStartDate,CampaignEndDate,CampaignName,CampaignBudget FROM Campaigns"
)
for row in results:
print(u"CampaignId: {}, PortfolioId: {}, CampaignStartDate: {}, CampaignEndDate: {}, CampaignName: {}, CampaignBudget: {}".format(*row))
- Ejecuta snippets.py con el argumento query_data para consultar la tabla Campaigns.
python snippets.py banking-ops-instance --database-id banking-ops-db query_data
El resultado debería verse como el siguiente:
CampaignId: 1, PortfolioId: 1, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Recompensa por Nueva Cuenta, CampaignBudget: 15000
CampaignId: 2, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Introducción a Inversiones, CampaignBudget: 5000
CampaignId: 3, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Cuentas Corrientes Juveniles, CampaignBudget: 25000
CampaignId: 4, PortfolioId: 3, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Protege a tu Familia, CampaignBudget: 10000
Tarea 4. Actualizar el esquema de la base de datos
Como parte de tus responsabilidades de DBA, debes agregar una nueva columna llamada MarketingBudget a la tabla Category. Para agregar una columna nueva a una tabla existente, es necesario actualizar el esquema de la base de datos. Cloud Spanner admite actualizaciones del esquema de una base de datos mientras esta sigue entregando tráfico. Las actualizaciones de esquema no requieren que la base de datos esté sin conexión y no bloquean tablas ni columnas completas. Puedes continuar leyendo y escribiendo datos en la base de datos durante la actualización del esquema.
Agregar una columna con Python
El método update_ddl() de la clase Database se usa para modificar el esquema.
Usa la función add_column() en snippets.py, que implementa ese método. No cambiarás ningún código, la sección se muestra aquí para que tengas una referencia.
def add_column(instance_id, database_id):
"""Agrega una nueva columna a la tabla Albums en la base de datos de ejemplo."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["ALTER TABLE Category ADD COLUMN MarketingBudget INT64"]
)
print("Esperando que se complete la operación...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Se agregó la columna MarketingBudget.")
- Ejecuta snippets.py con el argumento add_column.
python snippets.py banking-ops-instance --database-id banking-ops-db add_column
- Haz clic en Revisar mi progreso para verificar el objetivo.
Agrega la columna a la tabla Category
Estas son otras opciones para agregar una columna a una tabla existente:
Emitir un comando DDL a través de gcloud CLI.
Nota: Esta opción se muestra como un ejemplo alternativo. No ejecutes este comando.
La siguiente muestra de código completa la misma tarea que acabas de ejecutar con Python.
gcloud spanner databases ddl update banking-ops-db --instance=banking-ops-instance --ddl='ALTER TABLE Category ADD COLUMN MarketingBudget INT64;'
Emitir un comando DDL en la consola de Cloud.
Nota: Esta opción se muestra como un ejemplo alternativo. No realices esta acción.
- Haz clic en el nombre de la tabla en la ficha Database.
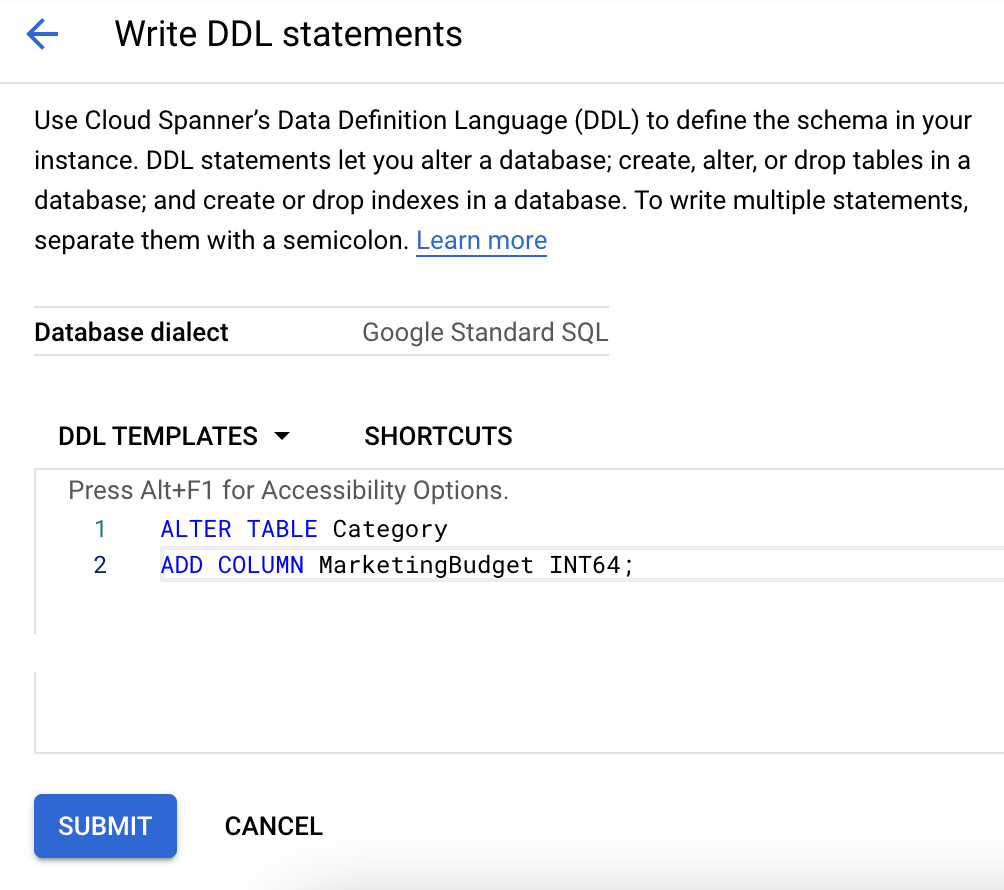
- Haz clic en Escribir DDL en la esquina superior derecha de la página.
- Pega el DDL adecuado en el cuadro Plantillas de DDL.
- Haz clic en Enviar.
Escribir datos en la columna nueva
Con el siguiente código, se escriben datos en la columna nueva. Establece MarketingBudget en 100000 para la fila con un CategoryId de 1 y un PortfolioId de 1, y en 500000 para la fila con un CategoryId de 3 y un PortfolioId de 2. No cambiarás ningún código, la sección se muestra aquí para que tengas una referencia.
def update_data(instance_id, database_id):
"""Actualiza datos de ejemplo en la base de datos.
Esto actualiza la columna "MarketingBudget", que debe crearse antes de
ejecutar este ejemplo. Puedes agregar la columna ejecutando el ejemplo`add_column`
o ejecutando esta sentencia DDL en tu base de datos
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.batch() as batch:
batch.update(
table="Category",
columns=("CategoryId", "PortfolioId", "MarketingBudget"),
values=[(1, 1, 100000), (3, 2, 500000)],
)
print("Datos actualizados.")
- Ejecuta snippets.py con el argumento update_data.
python snippets.py banking-ops-instance --database-id banking-ops-db update_data
- Vuelve a consultar la tabla para ver la actualización. Ejecuta snippets.py con el argumento query_data_with_new_column.
python snippets.py banking-ops-instance --database-id banking-ops-db query_data_with_new_column
El resultado debería ser este:
CategoryId: 1, PortfolioId: 1, MarketingBudget: 100000
CategoryId: 2, PortfolioId: 2, MarketingBudget: None
CategoryId: 3, PortfolioId: 2, MarketingBudget: 500000
CategoryId: 4, PortfolioId: 3, MarketingBudget: None
Tarea 5. Agregar un índice secundario
Supongamos que deseas recuperar todas las filas de categorías que tienen valores CategoryNames en un rango determinado. Puedes leer todos los valores de la columna CategoryName con una sentencia de SQL o una llamada de lectura y, luego, descartar las filas que no cumplan con los criterios. Sin embargo, analizar tablas enteras es costoso, especialmente si tienen muchas filas. En su lugar, crea un índice secundario en la tabla para acelerar la recuperación de filas cuando realizas búsquedas por columnas sin claves primarias.
Para agregar un índice secundario a una tabla existente, es necesario actualizar el esquema. Al igual que otras actualizaciones de esquema, Cloud Spanner admite que se agregue un índice mientras la base de datos continúa entregando tráfico. Cloud Spanner completa el índice con datos (también conocido como "reabastecimiento") en segundo plano. Los reabastecimientos pueden tomar unos minutos en completarse, pero no es necesario que uses la base de datos sin conexión o que evites escribir en ciertas tablas o columnas durante este proceso.
Agregar un índice secundario con la biblioteca cliente de Python
Usa el método add_index() para crear un índice secundario. No cambiarás ningún código, la sección se muestra aquí para que tengas una referencia.
def add_index(instance_id, database_id):
"""Agrega un índice simple a la base de datos de ejemplo."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["CREATE INDEX CategoryByCategoryName ON Category(CategoryName)"]
)
print("Esperando a que se complete la operación...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Se agregó el índice CategoryByCategoryName.")
- Ejecuta snippets.py con el argumento add_index.
python snippets.py banking-ops-instance --database-id banking-ops-db add_index
- Haz clic en Revisar mi progreso para verificar el objetivo.
Agregar un índice secundario a la tabla Category
Leer con el índice
Para leer con el índice, invoca una variación del método read() con un índice incluido. No cambiarás ningún código, la sección se muestra aquí para que tengas una referencia.
def read_data_with_index(instance_id, database_id):
"""Lee datos de ejemplo de la base de datos usando un índice.
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName"),
keyset=keyset,
index="CategoryByCategoryName",
)
for row in results:
print("CategoryId: {}, CategoryName: {}".format(*row))
- Ejecuta snippets.py con el argumento read_data_with_index.
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_index
El resultado debería verse como el siguiente:
CategoryId: 3, CategoryName: Anualidades
CategoryId: 1, CategoryName: Efectivo
CategoryId: 2, CategoryName: Inversiones - Retorno a corto plazo
CategoryId: 4, CategoryName: Seguros de vida
Agrega un índice con una cláusula STORING
Quizás notaste que, en el ejemplo de lectura anterior, no se incluye la lectura de la columna MarketingBudget. Esto se debe a que la interfaz de lectura de Cloud Spanner no admite la posibilidad de unir un índice con una tabla de datos para buscar valores que no están almacenados en el índice.
Para evitar esta restricción, crea una definición alternativa del índice CategoryByCategoryName que almacene una copia de MarketingBudget en el índice.
Usa el método update_ddl() de la clase Database para agregar un índice con una cláusula STORING. No cambiarás ningún código, la sección se muestra aquí para que tengas una referencia.
def add_storing_index(instance_id, database_id):
"""Agrega un índice de almacenamiento a la base de datos de ejemplo."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
[
"CREATE INDEX CategoryByCategoryName2 ON Category(CategoryName)"
"STORING (MarketingBudget)"
]
)
print("Esperando a que se complete la operación...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Se agregó el índice CategoryByCategoryName2.")
- Ejecuta snippets.py con el argumento add_storing_index.
python snippets.py banking-ops-instance --database-id banking-ops-db add_storing_index
Ahora puedes ejecutar una lectura que recupere las columnas CategoryId, CategoryName y MarketingBudget mientras se usa el índice CategoryByCategoryName2. No cambiarás ningún código, la sección se muestra aquí para que tengas una referencia.
def read_data_with_storing_index(instance_id, database_id):
"""Lee datos de ejemplo de la base de datos usando un índice con una cláusula de almacenamiento.
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName", "MarketingBudget"),
keyset=keyset,
index="CategoryByCategoryName2",
)
for row in results:
print(u"CategoryNameId: {}, CategoryName: {}, " "MarketingBudget: {}".format(*row))
- Ejecuta snippets.py con el argumento read_data_with_storing_index.
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_storing_index
El resultado debería ser este:
CategoryNameId: 3, CategoryName: Anualidades, MarketingBudget: 500000
CategoryNameId: 1, CategoryName: Efectivo, MarketingBudget: 100000
CategoryNameId: 2, CategoryName: Inversiones - Retorno a Corto Plazo, MarketingBudget: None
CategoryNameId: 4, CategoryName: Seguros de vida, MarketingBudget: None
Tarea 6. Examinar los planes de consultas
En esta sección, explorarás los planes de consultas de Cloud Spanner.
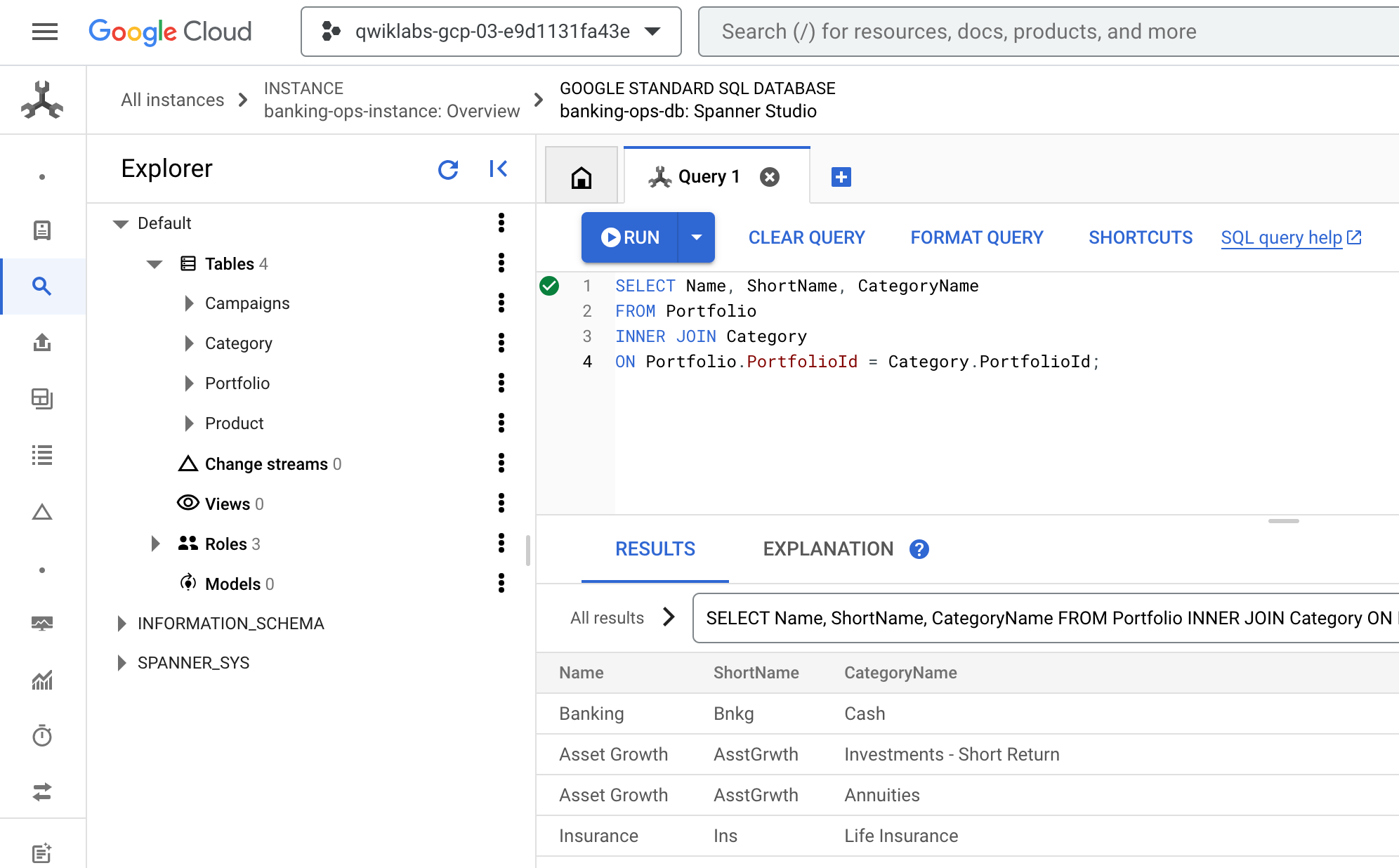
- Regresa a la consola de Cloud. Debería seguir en la pestaña Consulta de Spanner Studio. Borra cualquier consulta existente, pega y ejecuta la siguiente consulta:
SELECT Name, ShortName, CategoryName
FROM Portfolio
INNER JOIN Category
ON Portfolio.PortfolioId = Category.PortfolioId;
- El resultado debería verse como el siguiente:
El ciclo de una consulta
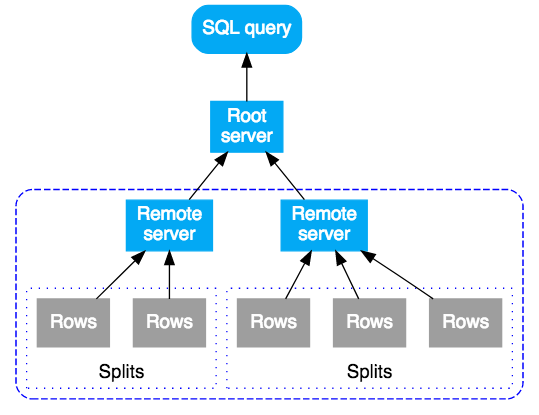
Una consulta en SQL en Cloud Spanner se compila primero en un plan de ejecución y, luego, se envía a un servidor raíz inicial para su ejecución. El servidor raíz se elige para minimizar la cantidad de saltos con el propósito de llegar a los datos que se consultan. El servidor raíz realiza lo siguiente:
- Inicia la ejecución remota de los subplanes (si es necesario)
- Espera los resultados de las ejecuciones remotas
- Maneja los pasos de ejecución local restantes, como la agregación de resultados
- Devuelve los resultados de la consulta
Los servidores remotos que reciben un subplan actúan como el servidor “raíz” para su subplan y siguen el mismo modelo que el servidor raíz superior. El resultado es un árbol de ejecuciones remotas. De forma conceptual, la ejecución de la consulta fluye de arriba abajo y los resultados de la consulta se devuelven de abajo arriba. En el siguiente diagrama, se muestra este patrón:
Consulta de agregación
Ahora, veamos el plan de consultas para una consulta de agregación.
- En la pestaña Consulta de Spanner Studio, borra la consulta existente, y pega y ejecuta la siguiente consulta.
SELECT pr.ProductId, COUNT(*) AS ProductCount
FROM Product AS pr
WHERE pr.ProductId < 100
GROUP BY pr.ProductId;
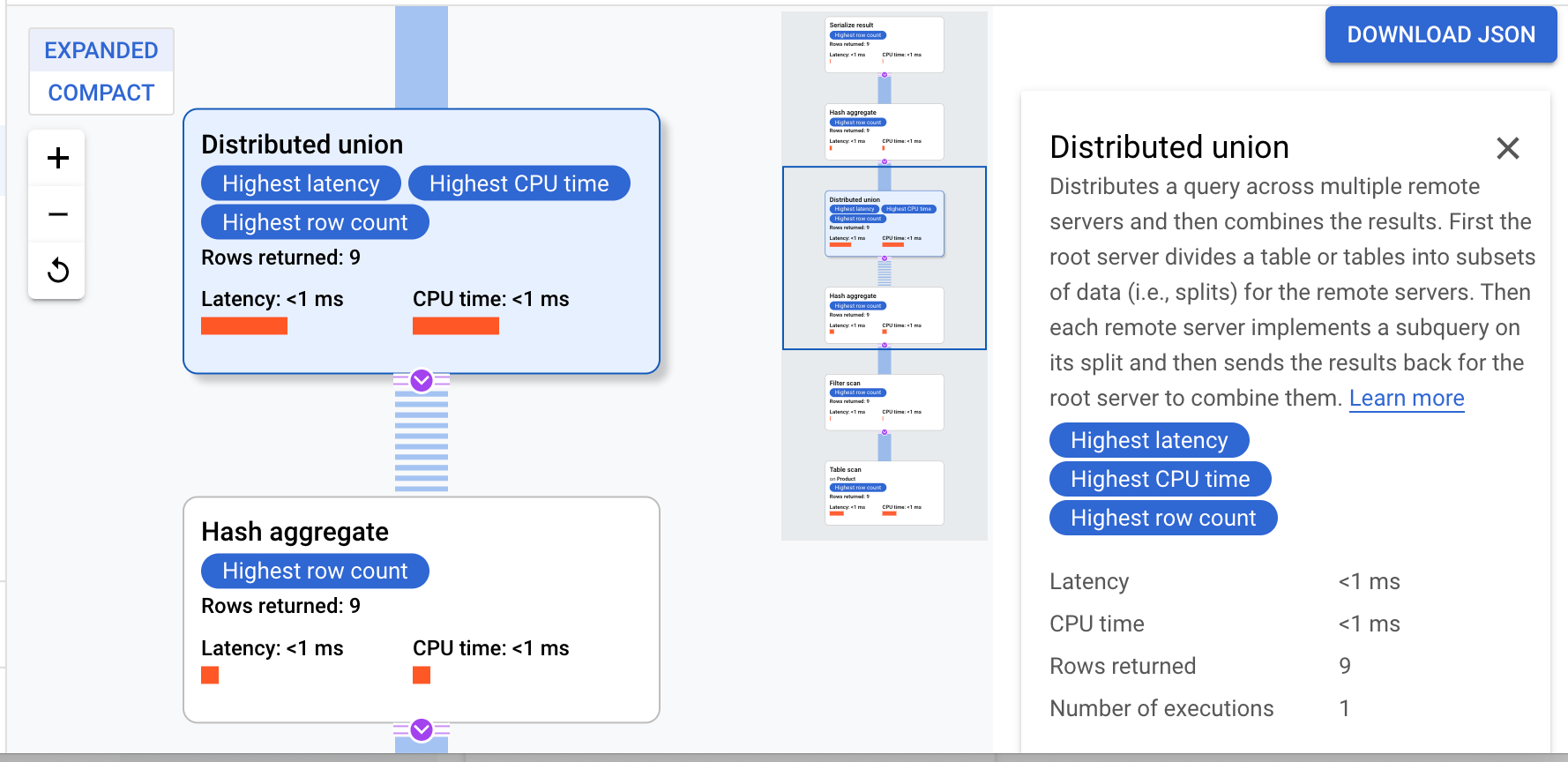
- Una vez que se complete la consulta, haz clic en la pestaña Explicación debajo del cuerpo de la consulta para examinar el plan de consultas.
Cloud Spanner envía el plan de ejecución a un servidor raíz que coordina la ejecución de la consulta y realiza la distribución remota de los subplanes.
Este plan de ejecución comienza con una serialización que ordena todos los valores devueltos. Luego, el plan completa un operador de agregación hash inicial para calcular los resultados de forma preliminar. Después, se ejecuta una unión distribuida que distribuye los subplanes a los servidores remotos cuyas divisiones cumplen con el valor ProductId < 100. La unión distribuida envía los resultados a un operador de agregación hash final. El operador de agregación realiza la agregación COUNT por ProductId y devuelve los resultados a un operador de serialización de resultados. Por último, se realiza un análisis para ordenar los resultados que se devolverán.
El resultado debería verse como el siguiente:
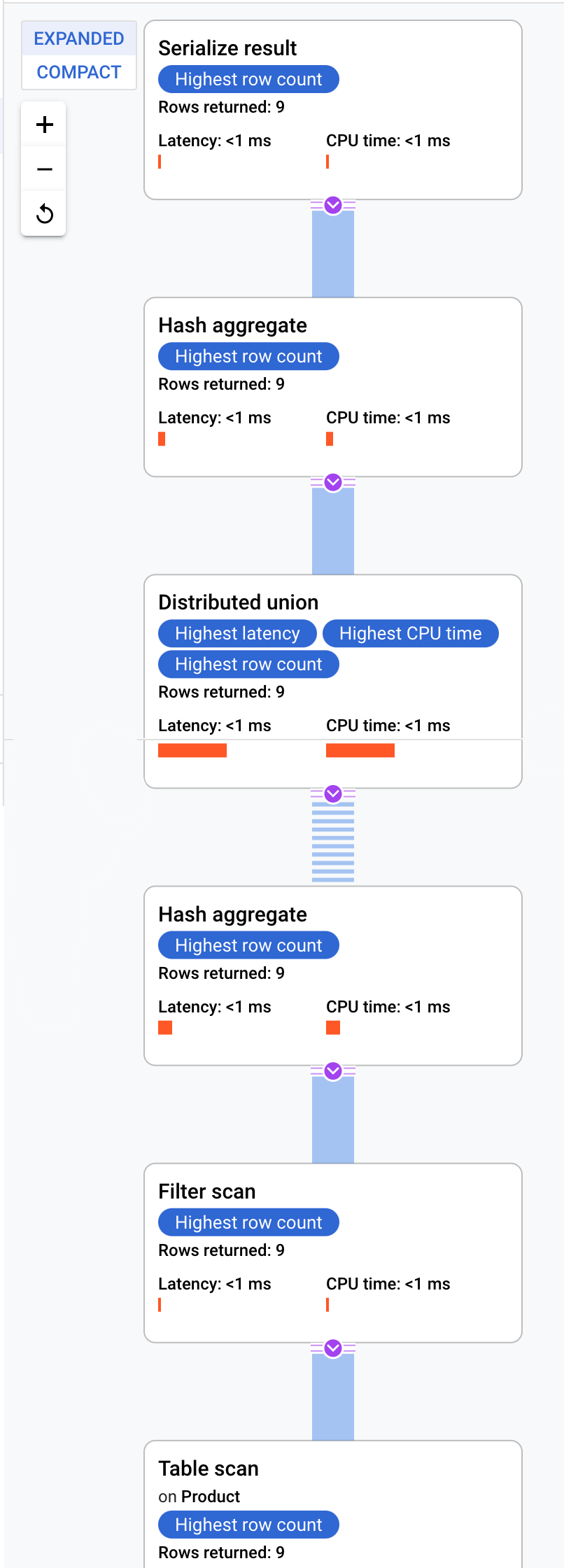
Sugerencia:Para obtener más detalles sobre cada paso del plan de consulta, haz clic en cualquiera de los operadores y el lado derecho de la pantalla cambiará en consecuencia.
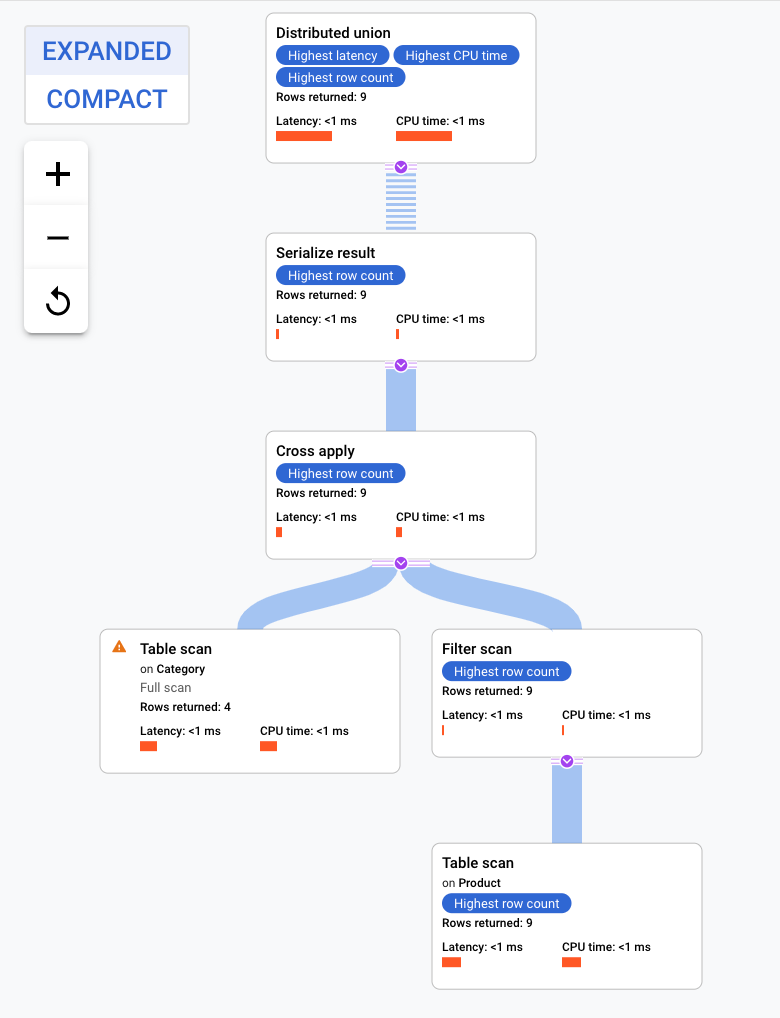
Consultas de unión ubicadas en el mismo lugar
Las tablas intercaladas se almacenan de forma física con sus filas de tablas relacionadas ubicadas en el mismo lugar. Una unión entre tablas intercaladas se conoce como una unión ubicada en el mismo lugar. Las uniones ubicadas en el mismo lugar pueden ofrecer beneficios de rendimiento en comparación con las uniones que requieren índices o reversión de uniones.
- En la pestaña Consulta de Spanner Studio, borra la consulta existente, y pega y ejecuta la siguiente consulta.
SELECT c.CategoryName, pr.ProductName
FROM Category AS c, Product AS pr
WHERE c.PortfolioId = pr.PortfolioId AND c.CategoryId = pr.CategoryId;
- Una vez que se complete la consulta, haz clic en la pestaña Explicación debajo del cuerpo de la consulta para examinar el plan de consultas.
Este plan de ejecución comienza con una unión distribuida, que distribuye los subplanes a los servidores remotos que tienen divisiones de la tabla Category. Como Product es una tabla intercalada de Category, cada servidor remoto puede ejecutar todo el subplan en cada servidor remoto sin necesidad de unirse a un servidor diferente.
Los subplanes contienen una aplicación cruzada. Cada aplicación cruzada realiza un análisis de tabla en la tabla Category para recuperar los valores de PortfolioId, CategoryId CategoryName. La aplicación cruzada asigna el resultado del análisis de la tabla al resultado de un análisis del índice CategoryByCategoryName, sujeto a un filtro del PortfolioId en el índice que coincide con el PortfolioId del resultado del análisis de la tabla. Cada aplicación cruzada envía sus resultados a un operador de serialización de resultados que serializa los datos CategoryName y ProductName , y devuelve resultados a las uniones distribuidas locales. La unión distribuida agrega los resultados de las uniones distribuidas locales y los devuelve como el resultado de la consulta.
¡Felicitaciones!
Ahora tienes un conocimiento sólido de las funciones relacionadas con el esquema de Cloud Spanner, así como de los métodos por los que Spanner crea planes de consultas.
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 14 de octubre de 2024
Prueba más reciente del lab: 14 de octubre de 2024
Copyright 2026 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.





