Mettez en pratique vos compétences dans la console Google Cloud
Points de contrôle
Setup the data environment
Vérifier ma progression
/ 15
Run your pipeline from the command line
Vérifier ma progression
/ 10
Instructions et exigences de configuration de l'atelier
Protégez votre compte et votre progression. Utilisez toujours une fenêtre de navigation privée et les identifiants de l'atelier pour exécuter cet atelier.
Traitement de données sans serveur avec Dataflow : pipelines avec des branches (Java)
Ce contenu n'est pas encore optimisé pour les appareils mobiles.
Pour une expérience optimale, veuillez accéder à notre site sur un ordinateur de bureau en utilisant un lien envoyé par e-mail.
Présentation
Au cours de cet atelier, vous allez :
implémenter un pipeline avec des branches ;
filtrer les données avant l'écriture ;
gérer les données en tant qu'objet <Row> ;
ajouter des paramètres de ligne de commande personnalisés à un pipeline.
Prérequis
Vous devez connaître les bases de Java.
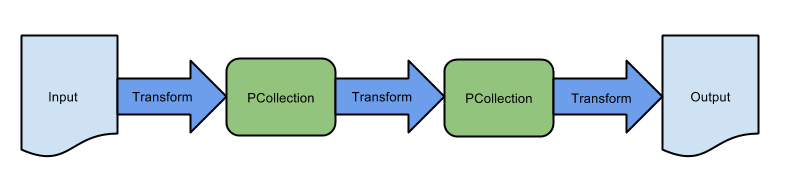
Dans l'atelier précédent, vous avez créé un pipeline séquentiel d'extraction, de transformation et de chargement de base, et utilisé un modèle Dataflow équivalent pour ingérer des données par lot stockées dans Google Cloud Storage. Ce pipeline se compose d'une séquence de transformations :
Cependant, de nombreux pipelines ne présentent pas une structure aussi simple. Dans cet atelier, vous allez créer un pipeline non séquentiel plus sophistiqué.
Le cas d'utilisation consiste ici à optimiser la consommation de ressources. Les produits consomment les ressources de différentes manières. De plus, les données ne sont pas toutes utilisées de la même manière dans une entreprise. Certaines sont régulièrement interrogées, par exemple dans le cadre de charges de travail analytiques, tandis que d'autres ne servent qu'à la récupération.
Dans cet atelier, vous allez optimiser le pipeline du premier atelier pour réduire la consommation de ressources. Pour cela, vous ne stockerez dans BigQuery que les données qui seront utilisées par les analystes, et vous archiverez les autres données dans un service de stockage très économique et hautement durable, le stockage Coldline de Google Cloud Storage.
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Google Skills dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pourrez pas le mettre sur pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à la console Google Cloud.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront facturés.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Activer Google Cloud Shell
Google Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud.
Google Cloud Shell vous permet d'accéder à vos ressources Google Cloud grâce à une ligne de commande.
Dans la barre d'outils située en haut à droite dans la console Cloud, cliquez sur le bouton "Ouvrir Cloud Shell".
Cliquez sur Continuer.
Le provisionnement et la connexion à l'environnement prennent quelques instants. Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET. Par exemple :
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
Vous pouvez lister les ID de projet à l'aide de cette commande :
gcloud config list project
Résultat :
[core]
project =
Exemple de résultat :
[core]
project = qwiklabs-gcp-44776a13dea667a6
Remarque : Pour consulter la documentation complète sur gcloud, accédez au guide de présentation de la gcloud CLI.
Vérifier les autorisations du projet
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
Dans la console Google Cloud, accédez au menu de navigation (), puis sélectionnez IAM et administration > IAM.
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle editor (éditeur). Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation du cloud > Tableau de bord.
Remarque : Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle editor (éditeur), procédez comme suit pour lui attribuer le rôle approprié.
Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation du cloud > Tableau de bord.
Copiez le numéro du projet (par exemple, 729328892908).
Dans le menu de navigation, sélectionnez IAM et administration > IAM.
Sous Afficher par compte principal, en haut de la table des rôles, cliquez sur Accorder l'accès.
Dans le champ Nouveaux comptes principaux, saisissez :
Remplacez {project-number} par le numéro de votre projet.
Dans le champ Rôle, sélectionnez Projet (ou Basique) > Éditeur.
Cliquez sur Enregistrer.
Configurer votre IDE
Dans cet atelier, vous utiliserez principalement un IDE Web Theia hébergé sur Google Compute Engine. Le dépôt de l'atelier y est précloné. L'IDE prend en charge les serveurs au langage Java et comprend un terminal permettant l'accès programmatique aux API Google Cloud avec l'outil de ligne de commande gcloud, comme avec Cloud Shell.
Pour accéder à votre IDE Theia, copiez le lien affiché dans Google Skills et collez-le dans un nouvel onglet.
Remarque : Le provisionnement complet de l'environnement peut prendre entre trois et cinq minutes, même après l'affichage de l'URL. En attendant, le navigateur indiquera une erreur.
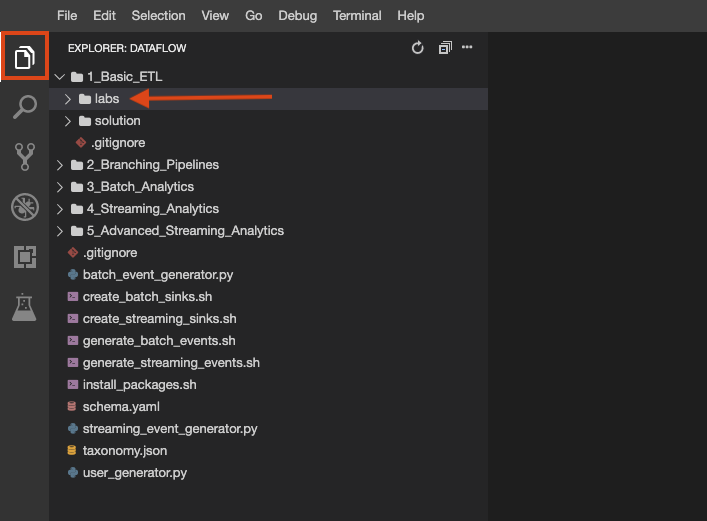
Le dépôt de l'atelier a été cloné dans votre environnement. Chaque atelier est divisé en deux dossiers : le premier, intitulé labs, contient du code que vous devez compléter, tandis que le second, nommé solution, comporte un exemple opérationnel que vous pouvez consulter si vous rencontrez des difficultés.
Cliquez sur le bouton Explorateur de fichiers pour y accéder :
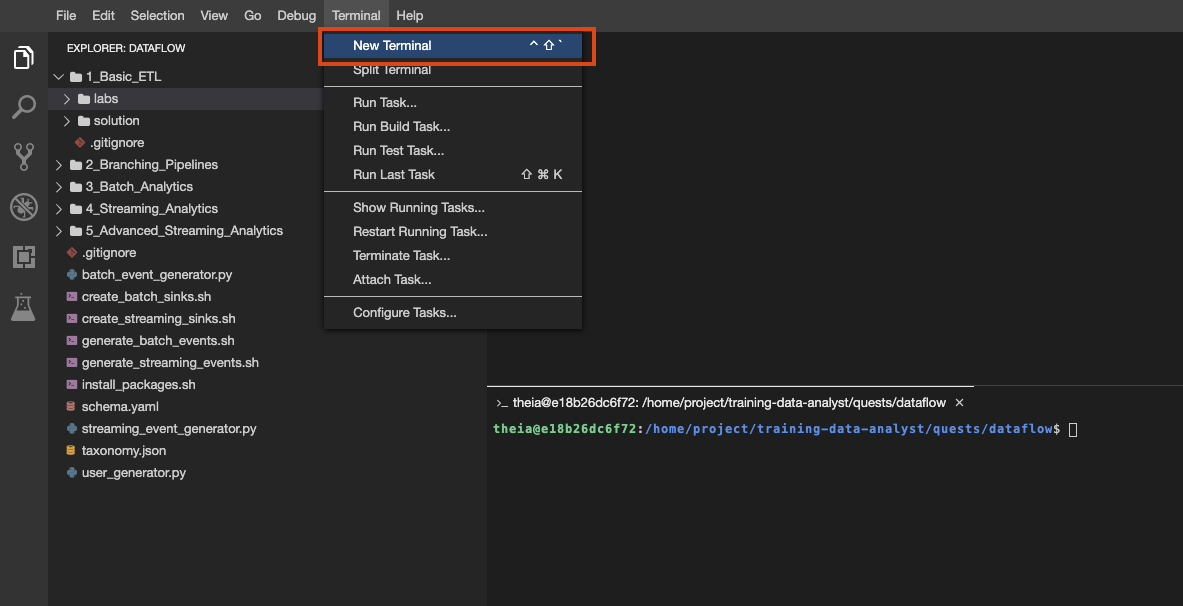
Vous pouvez également créer plusieurs terminaux dans cet environnement, comme vous le feriez avec Cloud Shell :
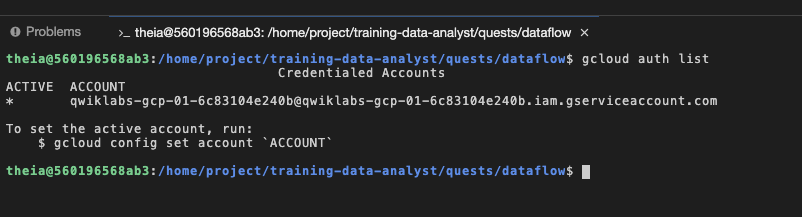
Vous pouvez exécuter la commande gcloud auth list dans le terminal pour vérifier que vous êtes connecté avec un compte de service fourni et que vous disposez donc des mêmes autorisations qu'avec votre compte utilisateur pour l'atelier :
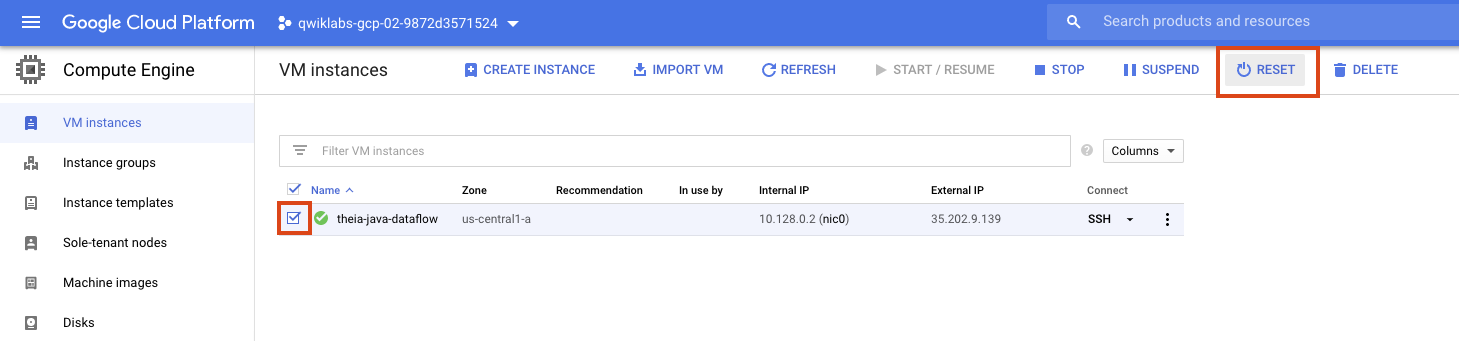
Si votre environnement cesse de fonctionner, vous pouvez essayer de réinitialiser la VM hébergeant votre IDE depuis la console GCE. Pour cela, procédez comme suit :
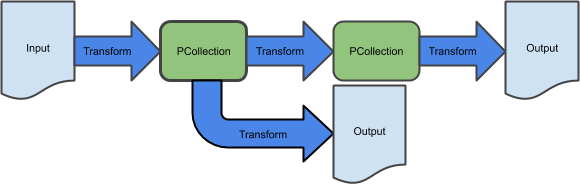
Plusieurs transformations traitent la même collection PCollection
Dans cet atelier, vous allez écrire un pipeline de avec des branches qui écrit des données à la fois dans Google Cloud Storage et dans BigQuery.
Pour écrire un pipeline avec des branches, vous pouvez appliquer deux transformations différentes à la même PCollection, ce qui génère deux PCollections différentes.
Si vous rencontrez des difficultés dans cette section ou dans les sections suivantes, n'hésitez pas à consulter la solution.
Tâche 1 : Ajouter une branche pour écrire dans Cloud Storage
Pour réaliser cette tâche, vous allez modifier un pipeline existant en ajoutant une branche qui écrit dans Cloud Storage.
Ouvrir l'atelier approprié
Si ce n'est pas déjà fait, créez un terminal dans votre environnement IDE, puis copiez et collez la commande suivante :
# Change directory into the lab
cd 2_Branching_Pipelines/labs
# Download dependencies
mvn clean dependency:resolve
export BASE_DIR=$(pwd)
Configurer l'environnement de données
# Create GCS buckets and BQ dataset
cd $BASE_DIR/../..
source create_batch_sinks.sh
# Generate event dataflow
source generate_batch_events.sh
# Change to the directory containing the practice version of the code
cd $BASE_DIR
Cliquez sur Vérifier ma progression pour valider l'objectif.
Configurer l'environnement de données
Ouvrez le fichier MyPipeline.java dans votre IDE. Vous le trouverez dans 2_Branching_Pipelines/labs/src/main/java/com/mypackage/pipeline.
Faites défiler la page jusqu'à la méthode run(), où le corps du pipeline est défini. Il se présente actuellement comme suit :
Modifiez ce code en ajoutant une nouvelle transformation avec branches qui écrit dans Cloud Storage à l'aide de TextIO.write() avant que chaque élément ne soit converti de JSON en <CommonLog>.
Si vous rencontrez des difficultés dans cette section ou dans les sections suivantes, n'hésitez pas à consulter la solution, qui se trouve dans le fichier training-data-analyst.
Tout d'abord, pourquoi utiliser des schémas ?
Les schémas nous fournissent un système de types pour les enregistrements Beam qui est indépendant de tout type de langage de programmation spécifique. Il peut y avoir plusieurs classes Java qui ont toutes le même schéma (par exemple, une classe Protocol Buffers ou une classe POJO), et Beam nous permettra de convertir ces types de manière transparente. Les schémas permettent également de raisonner facilement sur les types dans différentes API de langages de programmation.
Il n'est pas nécessaire de spécifier un codeur pour une PCollection avec un schéma, car Beam sait comment encoder et décoder les lignes de schéma. Beam utilise un encodeur spécial pour encoder les types de schémas. Avant l'introduction de l'API Schema, Beam devait savoir comment encoder tous les objets du pipeline.
Tâche 2 : Filtrer les données par champ
Pour l'instant, le nouveau pipeline ne consomme pas moins de ressources, car toutes les données sont stockées deux fois. Pour commencer à améliorer la consommation de ressources, nous devons réduire la quantité de données dupliquées. Le bucket Google Cloud Storage est destiné à servir d'espace de stockage pour l'archivage et la sauvegarde. Il est donc important que toutes les données y soient stockées. Cependant, il n'est pas nécessaire d'envoyer toutes les données à BigQuery.
Supposons que les analystes de données s'intéressent souvent aux ressources auxquelles les utilisateurs accèdent sur le site Web, et à la façon dont ces schémas d'accès diffèrent en fonction de la zone géographique et de l'heure. Seul un sous-ensemble des champs serait nécessaire.
Vous pouvez écrire une fonction DoFn qui transforme chaque objet et ne renvoie qu'un sous-ensemble des champs. Cependant, Apache Beam fournit une grande variété de transformations relationnelles pour les PCollections qui ont un schéma. Le fait que chaque enregistrement soit composé de champs nommés permet de créer des agrégations simples et lisibles qui référencent les champs par leur nom, comme dans une expression SQL.
Select et DropFields sont deux de ces transformations :
Important : Chacun de ces exemples renverra PCollection<Row> au lieu de PCollection<MyClass>. La classe Row peut prendre en charge n'importe quel schéma et peut être considérée comme un objet schématisé générique. Toute PCollection avec un schéma peut être convertie en PCollection de lignes.
Les deux transformations ci-dessus ne renverront pas un objet CommonLog complet, car des champs sont supprimés. La transformation reviendra donc à renvoyer un Row. Vous pourriez créer un schéma nommé ou enregistrer un schéma POJO intermédiaire, mais il est plus simple d'utiliser Row pour le moment.
Pour cela, ajoutez les importations suivantes et modifiez l'ensemble des champs enregistrés dans BigQuery, afin que seuls ceux que les analystes ont l'intention d'utiliser soient envoyés en ajoutant l'une de ces transformations au pipeline.
Rappel : Si vous avez déjà enchaîné la méthode BigQueryIO.<CommonLog>write(), vous devrez la remplacer par <Row> en raison du nouveau type.
Tâche 3 : Filtrer les données par élément
Il existe de nombreuses façons de filtrer des données dans Apache Beam. Dans la tâche précédente, nous avons utilisé une transformation de schéma. Dans cette implémentation, vous avez filtré des parties de chaque élément, ce qui a généré un nouvel objet Row avec un schéma et un sous-ensemble des champs restants. Vous pouvez tout aussi facilement l'utiliser pour exclure des éléments entiers, comme dans l'exemple ci-dessous :
purchases.apply(Filter.<MyObject>create()
.whereFieldName(“costCents”, (Long c) -> c > 100 * 20)
.whereFieldName(“shippingAddress.country”, (String c) -> c.equals(“de”));
Remarque : Cette transformation Filter, org.apache.beam.sdk.schemas.transforms.Filter, ne doit pas être confondue avec l'ancienne fonction Filter non basée sur un schéma org.apache.beam.sdk.transforms.Filter.
Pour réaliser cette tâche, ajoutez d'abord les instructions d'importation ci-dessous à votre code, puis ajoutez une transformation de filtrage au pipeline. Vous pouvez filtrer les résultats selon les critères de votre choix. Vous devrez peut-être ajouter des indications de type à votre fonction lambda, par exemple (Integer c) -> c > 100.
Tâche 4 : Ajouter des paramètres de ligne de commande personnalisés
Le pipeline comporte actuellement un certain nombre de paramètres codés en dur, y compris le chemin d'accès à l'entrée et l'emplacement de la table dans BigQuery. Cependant, le pipeline serait plus utile s'il pouvait lire n'importe quel fichier JSON dans Cloud Storage. Pour ajouter cette fonctionnalité, vous devez l'ajouter à l'ensemble des paramètres de ligne de commande.
Le pipeline utilise actuellement PipelineOptionsFactory pour générer une instance d'une classe personnalisée appelée "Options". Toutefois, cette classe ne modifie rien par rapport à la classe PipelineOptions. Il s'agit donc en fait d'une instance de PipelineOptions :
public interface Options extends PipelineOptions {
}
public static void main(String[] args) {
Options options = PipelineOptionsFactory.fromArgs(args).withValidation().as(Options.class);
run(options);
}
La classe PipelineOptions interprète les arguments de ligne de commande au format suivant :
--<option>=<value>
Cependant, il s'agit d'un petit ensemble de paramètres prédéfinis. Vous pouvez consulter les fonctions "get" ici.
Pour ajouter un paramètre personnalisé, vous devez effectuer deux opérations.
Commencez par ajouter une variable d'état à la classe "Options", comme dans l'exemple ci-dessous :
public interface Options extends PipelineOptions {
@Description("My custom command line argument.")
@Default.String("DEFAULT")
String getMyCustomOption();
void setMyCustomOption(String myCustomOption);
}
Ensuite, enregistrez votre interface avec PipelineOptionsFactory dans la méthode main(), puis transmettez l'interface lors de la création de l'objet PipelineOptions. Lorsque vous enregistrez l'interface avec la fonction PipelineOptionsFactory, la commande --help vous permet de rechercher l'interface d'options personnalisées et de l'ajouter à la sortie de la commande --help. La fonction PipelineOptionsFactory vérifie également que les options personnalisées sont compatibles avec toutes les autres options enregistrées.
L'exemple de code suivant montre comment enregistrer l'interface d'options personnalisées avec la fonction PipelineOptionsFactory :
Pour réaliser cette tâche, ajoutez d'abord les instructions d'importation suivantes, puis ajoutez des paramètres de ligne de commande pour le chemin d'entrée, le chemin de sortie Google Cloud Storage, et le nom de la table BigQuery. Mettez à jour le code du pipeline pour accéder à ces paramètres au lieu des constantes.
Tâche 5 : Ajouter des champs NULLABLE (pouvant accueillir une valeur nulle) à votre pipeline
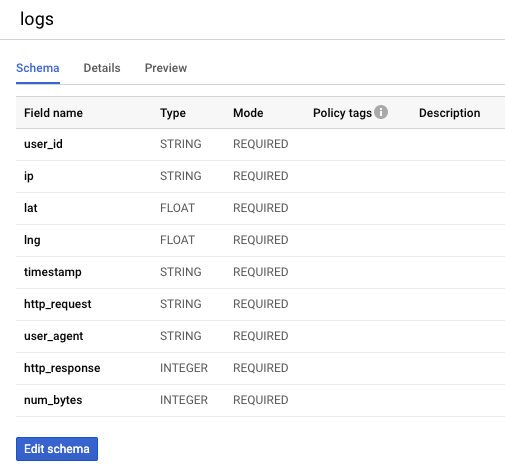
Vous avez peut-être remarqué que la table BigQuery créée dans le dernier atelier comportait un schéma avec tous les champs REQUIRED (valeur obligatoire) comme suit :
Il peut être souhaitable de créer un schéma Apache Beam avec des champs NULLABLE lorsque des données sont manquantes, aussi bien pour l'exécution du pipeline que pour la table BigQuery qui en résulte avec le schéma correspondant.
Vous pouvez ajouter des annotations Javax à votre définition de classe, qui sont ensuite intégrées au schéma Apache Beam comme suit :
@DefaultSchema(JavaFieldSchema.class)
class MyClass {
int field1;
@javax.annotation.Nullable String field2;
}
Pour réaliser cette tâche, marquez les champs lat et lon comme pouvant accepter une valeur nulle dans la définition de la classe.
Tâche 6 : Exécuter votre pipeline à partir de la ligne de commande
Pour effectuer cette tâche, exécutez votre pipeline à partir de la ligne de commande et transmettez les paramètres appropriés. N'oubliez pas de consulter le schéma BigQuery résultant pour les champs NULLABLES. Votre code doit se présenter comme suit :
# Set up environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION={{{ project_0.default_region | "REGION" }}}
export BUCKET=gs://${PROJECT_ID}
export COLDLINE_BUCKET=${BUCKET}-coldline
export PIPELINE_FOLDER=${BUCKET}
export MAIN_CLASS_NAME=com.mypackage.pipeline.MyPipeline
export RUNNER=DataflowRunner
export INPUT_PATH=${PIPELINE_FOLDER}/events.json
export OUTPUT_PATH=${PIPELINE_FOLDER}-coldline
export TABLE_NAME=${PROJECT_ID}:logs.logs_filtered
cd $BASE_DIR
mvn compile exec:java \
-Dexec.mainClass=${MAIN_CLASS_NAME} \
-Dexec.cleanupDaemonThreads=false \
-Dexec.args=" \
--project=${PROJECT_ID} \
--region=${REGION} \
--stagingLocation=${PIPELINE_FOLDER}/staging \
--tempLocation=${PIPELINE_FOLDER}/temp \
--runner=${RUNNER} \
--inputPath=${INPUT_PATH} \
--outputPath=${OUTPUT_PATH} \
--tableName=${TABLE_NAME}"
Remarque : Si votre pipeline se compile correctement, mais que vous constatez de nombreuses erreurs dues à du code ou à une mauvaise configuration dans le service Dataflow, vous pouvez rétablir la valeur "DirectRunner" pour la variable RUNNER, afin d'exécuter le pipeline localement et d'obtenir des commentaires plus rapidement. Dans le cas présent, c'est une approche viable car l'ensemble de données est de taille réduite et vous n'utilisez aucune fonctionnalité non compatible avec DirectRunner.
Tâche 7 : Vérifier les résultats du pipeline
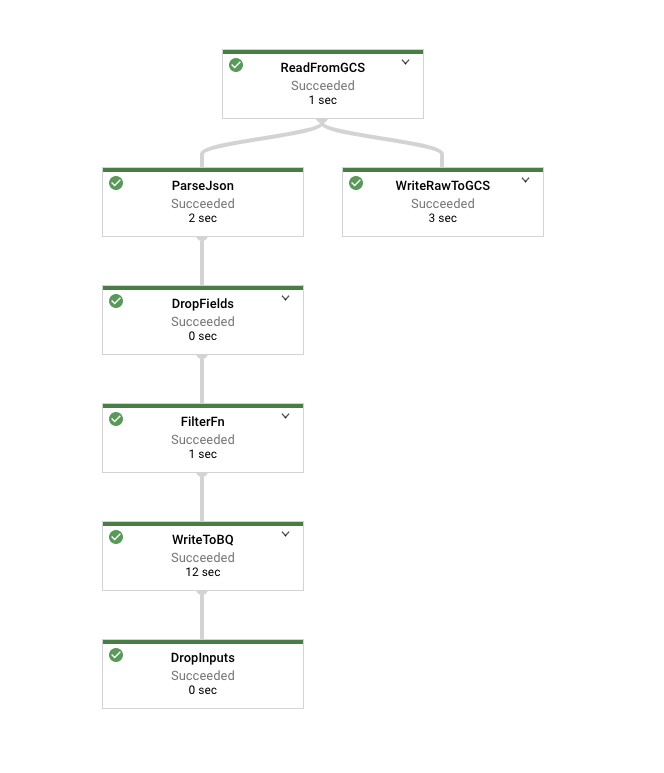
Accédez à la page "Jobs Dataflow" et examinez le job en cours d'exécution. Son graphique doit ressembler à ceci :
Cliquez sur le nœud représentant votre fonction Filter, qui s'appelle FilterFn dans l'image ci-dessus. Dans le panneau qui s'affiche à droite, vous pouvez constater que le nombre d'éléments qui ont été ajoutés en tant qu'entrées est supérieur au nombre d'éléments écrits en tant que sorties.
Cliquez maintenant sur le nœud représentant l'écriture dans Cloud Storage. Puisque tous les éléments ont été écrits, ce nombre doit correspondre au nombre d'éléments dans l'entrée de la fonction Filter.
Une fois le pipeline terminé, examinez les résultats dans BigQuery en interrogeant votre table. Notez que le nombre d'enregistrements dans la table doit correspondre au nombre d'éléments générés par la fonction Filter.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Exécuter le pipeline à partir de la ligne de commande
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Skills supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Voici à quoi correspond le nombre d'étoiles que vous pouvez attribuer à un atelier :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Le meilleur moyen d'exécuter cet atelier consiste à utiliser une fenêtre de navigation privée. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Dans cet atelier, vous allez : a) implémenter un pipeline avec des branches ; b) filtrer des données avant de les écrire ; et c) ajouter des paramètres de ligne de commande personnalisés à un pipeline.
Durée :
1 min de configuration
·
Accessible pendant 120 min
·
Terminé après 120 min



 ), puis sélectionnez IAM et administration > IAM.
), puis sélectionnez IAM et administration > IAM.