GSP1249

Présentation
Dans cet atelier, vous allez apprendre à extraire des mots clés et à évaluer
les sentiments exprimés dans les avis clients en utilisant BigQuery
Machine Learning avec des modèles distants (Gemini Flash).
BigQuery est une plate-forme d'analyse de données entièrement gérée et
compatible avec l'IA, conçue pour être multimoteur, multiformat et multicloud.
Elle vous aide à maximiser la valeur de vos données. BigQuery
Machine Learning, l'une de ses fonctionnalités essentielles, vous permet de
créer et d'exécuter des modèles de machine learning (ML)
à l'aide de requêtes SQL ou avec des notebooks Colab Enterprise.
Gemini
est une famille de modèles d'IA générative développés par Google DeepMind, et
conçus pour les cas d'utilisation multimodaux. L'API Gemini vous donne accès
au
modèle Gemini Flash.
À la fin de cet atelier, vous créerez une application de service client basée
sur Python dans un notebook Colab Enterprise au sein de BigQuery, utilisant le
modèle Gemini Flash pour répondre aux avis clients audio.
Objectifs
Dans cet atelier, vous allez apprendre à :
- créer un notebook Python dans BigQuery à l'aide de Colab Enterprise ;
- créer une connexion à une ressource cloud dans BigQuery ;
- créer l'ensemble de données et les tables dans BigQuery ;
- créer les modèles distants Gemini dans BigQuery ;
-
demander à Gemini d'analyser les mots clés et les sentiments (positifs ou
négatifs) des avis clients textuels ;
- générer un rapport avec le nombre d'avis positifs et négatifs ;
- répondre aux avis clients à grande échelle ;
-
créer une application pour les conseillers clientèle afin qu'ils puissent
répondre aux avis clients audio.
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Des identifiants temporaires vous sont fournis pour vous permettre de vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- Vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome).
Remarque : Ouvrez une fenêtre de navigateur en mode incognito (recommandé) ou de navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
- Vous disposez d'un temps limité. N'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Utilisez uniquement le compte de participant pour cet atelier. Si vous utilisez un autre compte Google Cloud, des frais peuvent être facturés à ce compte.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, une boîte de dialogue s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous trouverez le panneau "Détails concernant l'atelier", qui contient les éléments suivants :
- Le bouton "Ouvrir la console Google Cloud"
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page "Se connecter" dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
-
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}}
Vous trouverez également le nom d'utilisateur dans le panneau "Détails concernant l'atelier".
-
Cliquez sur Suivant.
-
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}}
Vous trouverez également le mot de passe dans le panneau "Détails concernant l'atelier".
-
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. Ne saisissez pas ceux de votre compte Google Cloud.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés.
-
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Pour accéder aux produits et services Google Cloud, cliquez sur le menu de navigation ou saisissez le nom du service ou du produit dans le champ Recherche.

Tâche 1 : Créer un notebook Python dans BigQuery et le connecter à
l'environnement d'exécution
Dans cette tâche, vous allez créer un notebook Python dans BigQuery et le
connecter à l'environnement d'exécution.
Créer le notebook Python dans BigQuery
-
Dans la console Google Cloud, accédez au
menu de navigation, puis cliquez sur
BigQuery.
-
Cliquez sur OK dans le pop-up de bienvenue.
-
Cliquez sur Notebook.
-
Sélectionnez
pour la région.
-
Cliquez sur SÉLECTIONNER.
Vous pouvez remarquer que le notebook Python est ajouté à la section des
notebooks de l'explorateur sous votre projet.
-
Supprimez toutes les cellules présentes dans le notebook en cliquant sur
l'icône Corbeille qui s'affiche lorsque vous pointez sur chacune des
cellules.
Vous avez terminé cette étape lorsque le notebook est vide. Vous pouvez alors
passer à l'étape suivante.
Se connecter à l'environnement d'exécution
-
Dans l'éditeur de notebook BigQuery, cliquez sur
Se connecter.
-
Dans la fenêtre pop-up OAuth, cliquez sur Ouvrir.
-
Cliquez sur l'ID de participant Qwiklabs.
Patientez quelques instants. La connexion à l'environnement d'exécution
peut prendre jusqu'à trois minutes.
Quand cela sera fait, vous verrez que l'état de connexion passera à
"Connecté" en bas de la fenêtre du navigateur.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer un notebook Python dans BigQuery et le connecter à l'environnement
d'exécution
Tâche 2 : Créer la connexion à une ressource cloud et attribuer un rôle IAM
Créer la connexion à une ressource cloud dans BigQuery
Dans cette tâche, vous allez créer une
connexion à une ressource cloud
dans BigQuery pour pouvoir travailler avec le modèle Gemini Flash. Vous allez
également accorder des autorisations IAM au compte de service de la connexion
à la ressource cloud en lui attribuant un rôle, afin de lui permettre
d'accéder aux services Agent Platform.
Vous utiliserez le SDK Python et Google Cloud CLI pour créer la connexion à la
ressource. Notez que vous devez d'abord importer les bibliothèques Python,
ainsi que définir les variables "project_id" et "region".
-
Dans l'éditeur de notebook BigQuery, cliquez sur
+ Code pour créer une cellule de code. Ajoutez le code
suivant :
# Import Python libraries
import vertexai
from vertexai.generative_models import GenerativeModel, Part
from google.cloud import bigquery
from google.cloud import storage
import json
import io
import matplotlib.pyplot as plt
from IPython.display import HTML, display
from IPython.display import Audio
from pprint import pprint
Ce code importera les bibliothèques Python.
-
Exécutez cette cellule. Les bibliothèques sont désormais chargées et
prêtes à être utilisées.
-
Créez une cellule de code en cliquant sur + Code, puis
ajoutez le code ci-dessous :
import os
PROJECT_ID = "{{{project_0.project_id | PROJECT_ID}}}"
LOCATION = os.environ.get("GOOGLE_CLOUD_REGION", "global")
Remarque : "PROJECT_ID" et "LOCATION" sont enregistrées ici en tant que variables Python et non SQL. Vous ne pouvez donc y faire référence que dans des cellules utilisant du code Python, et non du code SQL.
-
Exécutez cette cellule. Les variables pour "PROJECT_ID" et "LOCATION" sont
définies.
-
Créez une cellule de code en cliquant sur + Code, puis
ajoutez le code ci-dessous :
# Create the resource connection
!bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=US \
gemini_conn
Ce code utilisera la commande bq mk --connection de
Google Cloud CLI pour créer la connexion à la ressource.
-
Exécutez cette cellule. La connexion à la ressource est maintenant créée.
-
Cliquez sur le bouton Afficher les actions à côté de l'ID
de votre projet dans l'explorateur.
-
Cliquez sur Actualiser le contenu.
-
Développez Connexions sous le projet
. Vous pouvez constater que us.gemini_conn est maintenant
listé comme connexion externe.
-
Cliquez sur us.gemini_conn.
-
Copiez l'ID de compte de service indiqué dans le volet
"Informations de connexion" dans un fichier texte. Vous en aurez besoin à
l'étape suivante.
Attribuer le rôle d'utilisateur Agent Platform au compte de service de la
connexion
-
Dans le menu de navigation de la console, cliquez sur
IAM et administration.
-
Cliquez sur Accorder l'accès.
-
Dans le champ Nouveaux comptes principaux, saisissez l'ID
de compte de service que vous avez copié précédemment.
-
Dans le champ "Sélectionner un rôle", saisissez
Agent Platform, puis choisissez le rôle
Utilisateur Agent Platform.
-
Cliquez sur Enregistrer.
Le compte de service inclut désormais le rôle Utilisateur Agent Platform.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer la connexion à une ressource cloud et attribuer un rôle IAM
Tâche 3 : Examiner les fichiers audio et l'ensemble de données, et attribuer
un rôle IAM au compte de service
Dans cette tâche, vous allez examiner l'ensemble de données et les fichiers
audio. Vous accorderez ensuite des autorisations IAM au compte de service de
la connexion à la ressource cloud.
Examiner les fichiers audio, les fichiers image et l'ensemble de données
d'avis clients sur Cloud Storage
Avant de commencer cette tâche visant à accorder des autorisations au compte
de service de la connexion à la ressource, examinez l'ensemble de données et
les fichiers image.
-
Dans la console Google Cloud, sélectionnez le
menu de navigation ( ), puis Cloud Storage > Buckets.
), puis Cloud Storage > Buckets.
-
Cliquez sur le bucket Cloud Storage
.
-
Une fois dans le bucket, ouvrez le dossier gsp1249. Celui-ci
contient quatre éléments :
-
Le dossier
audio contient tous les fichiers audio que vous
allez analyser. Vous pouvez y accéder et prendre connaissance des
fichiers audio.
-
Le fichier
customer_reviews.csv est l'ensemble de données
qui contient les avis clients textuels.
-
Le dossier
images contient un fichier image que vous allez
utiliser dans la suite de cet atelier. Vous pouvez accéder à ce dossier
et voir le fichier image qu'il contient.
-
notebook.ipynb est une copie du notebook que vous créez
dans cet atelier. Vous pouvez l'examiner au besoin.
Remarque : Vous pouvez utiliser l'URL authentifiée pour télécharger et examiner chaque élément.
Attribuer le rôle IAM "Administrateur des objets Storage" au compte de service
de la connexion
Vous allez attribuer les autorisations IAM requises au compte de service de la
connexion à la ressource avant de commencer à travailler dans BigQuery. Vous
vous assurez ainsi d'éviter les erreurs de type "accès refusé" lors de
l'exécution des requêtes.
-
Revenez à la racine du bucket.
-
Cliquez sur AUTORISATIONS.
-
Cliquez sur ACCORDER L'ACCÈS.
-
Dans le champ Nouveaux comptes principaux, saisissez l'ID
de compte de service que vous avez copié précédemment.
-
Dans le champ "Sélectionner un rôle", saisissez
Administrateur des objets de l'espace de stockage, puis
sélectionnez le rôle.
-
Cliquez sur Enregistrer.
Le compte de service inclut désormais le rôle d'Administrateur des objets
de l'espace de stockage.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Examiner les images et l'ensemble de données, et attribuer un rôle IAM au
compte de service
Tâche 4 : Créer l'ensemble de données et la table des avis clients dans
BigQuery
Dans cette tâche, vous allez créer un ensemble de données pour le projet,
ainsi que la table pour les avis clients.
Créer l'ensemble de données
Pour l'ensemble de données, vous allez utiliser les propriétés suivantes :
| Champ |
Valeur |
| ID de l'ensemble de données |
gemini_demo |
| Type d'emplacement |
Sélectionnez Multirégional
|
| Emplacement multirégional |
Sélectionnez États-Unis
|
-
Revenez au notebook Python dans BigQuery.
-
Créez une cellule de code en cliquant sur + Code, puis
ajoutez le code ci-dessous :
# Create the dataset
%%bigquery
CREATE SCHEMA IF NOT EXISTS `{{{project_0.project_id | PROJECT ID | disablehighlight}}}.gemini_demo`
OPTIONS(location="US");
Notez que le code commence par %%bigquery. Cela indique à
Python que le code suivant immédiatement cette instruction sera du code
SQL.
-
Exécutez cette cellule.
-
Cliquez sur le bouton Afficher les actions à côté de l'ID
de votre projet dans l'explorateur.
-
Cliquez sur Actualiser le contenu.
Le code SQL crée alors l'ensemble de données gemini_demo dans
votre projet résidant dans la région "us" listée sous votre projet dans le
volet "Explorateur" de BigQuery.
Créer la table des avis clients avec des exemples de données
Pour créer la table des avis clients, vous allez utiliser une requête SQL.
-
Créez une cellule de code en cliquant sur + Code, puis
ajoutez le code ci-dessous :
# Create the customer reviews table
%%bigquery
LOAD DATA OVERWRITE gemini_demo.customer_reviews
(customer_review_id INT64, customer_id INT64, location_id INT64, review_datetime DATETIME, review_text STRING, social_media_source STRING, social_media_handle STRING)
FROM FILES (
format = 'CSV',
uris = ['gs://{{{project_0.project_id | PROJECT ID | disablehighlight}}}-bucket/gsp1249/customer_reviews.csv']);
-
Exécutez cette cellule.
La table customer_reviews est créée avec des exemples de
données d'avis clients, incluant les éléments
customer_review_id, customer_id,
location_id, review_datetime,
review_text, social_media_source et
social_media_handle pour chaque avis de l'ensemble de
données.
-
Cliquez sur le bouton Afficher les actions à côté de l'ID
de votre projet dans l'explorateur.
-
Cliquez sur Actualiser le contenu.
-
Dans l'explorateur, accédez à l'ensemble de données
gemini_demo, puis cliquez sur la table
customer_reviews pour examiner le schéma et les détails.
-
Pour interroger la table afin d'examiner les enregistrements, créez une
cellule de code avec le code ci-dessous.
# Create the customer reviews table
%%bigquery
SELECT * FROM `gemini_demo.customer_reviews`
ORDER BY review_datetime
-
Exécutez cette cellule.
Les enregistrements provenant de la table sont affichés avec toutes les
colonnes incluses.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer l'ensemble de données et la table des avis clients dans BigQuery
Tâche 5 : Créer le modèle Gemini Flash dans BigQuery
Maintenant que les tables sont créées, vous pouvez commencer à les utiliser.
Dans cette tâche, vous allez créer le modèle Gemini Flash dans BigQuery.
-
Revenez au notebook Python.
-
Créez une cellule de code en cliquant sur + Code, puis
ajoutez le code ci-dessous :
# Create the customer reviews table
%%bigquery
CREATE OR REPLACE MODEL `gemini_demo.gemini_flash`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = '{{{project_0.startup_script.gemini_flash_model_id | model_id | disablehighlight}}}')
-
Exécutez cette cellule.
Ce code crée le modèle gemini_flash. Celui-ci est ajouté à
l'ensemble de données gemini_demo, dans la section des
modèles.
-
Cliquez sur le bouton Afficher les actions à côté de l'ID
de votre projet dans l'explorateur.
-
Cliquez sur Actualiser le contenu.
-
Dans l'explorateur, accédez à l'ensemble de données
gemini_demo, cliquez sur le modèle
gemini_flash, puis examinez le schéma et les détails.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer le modèle Gemini Flash dans BigQuery
Tâche 6 : Demander à Gemini d'analyser les mots clés et les sentiments des
avis clients
Dans cette tâche, vous allez utiliser le modèle Gemini Flash pour analyser le
sentiment, positif ou négatif, de chaque avis client.
Analyser les avis clients pour déterminer si le sentiment est positif ou
négatif
-
Créez une cellule de code en cliquant sur + Code, puis
ajoutez le code ci-dessous :
# Create the sentiment analysis table
%%bigquery
CREATE OR REPLACE TABLE
`gemini_demo.customer_reviews_analysis` AS (
SELECT ml_generate_text_llm_result, social_media_source, review_text, customer_id, location_id, review_datetime
FROM
ML.GENERATE_TEXT(
MODEL `gemini_demo.gemini_flash`,
(
SELECT social_media_source, customer_id, location_id, review_text, review_datetime, CONCAT(
'Classify the sentiment of the following text as positive or negative.',
review_text, "In your response don't include the sentiment explanation. Remove all extraneous information from your response, it should be a boolean response either positive or negative.") AS prompt
FROM `gemini_demo.customer_reviews`
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
-
Exécutez cette cellule.
Ce code récupère les avis clients de la table
customer_reviews, crée le prompt, puis utilise ces éléments
avec le modèle gemini_flash afin de classer le sentiment de
chaque avis. Les résultats sont ensuite stockés dans une nouvelle table
appelée customer_reviews_analysis, à laquelle vous pourrez
vous reporter ultérieurement pour réaliser des analyses approfondies.
Patientez quelques instants. Le traitement des enregistrements d'avis
clients par le modèle prend environ 30 secondes.
Lorsque le modèle a terminé cette opération, la table
customer_reviews_analysis est créée.
-
Cliquez sur le bouton Afficher les actions à côté de l'ID
de votre projet dans l'explorateur.
-
Cliquez sur Actualiser le contenu.
-
Dans l'explorateur, cliquez sur la table
customer_reviews_analysis, et examinez le schéma et les
détails.
-
Créez une cellule de code en cliquant sur + Code, puis
ajoutez le code ci-dessous :
# Pull the first 50 records from the customer_reviews_analysis table
%%bigquery
SELECT * FROM `gemini_demo.customer_reviews_analysis`
ORDER BY review_datetime
-
Exécutez cette cellule.
Les lignes renvoyées comportent la colonne
ml_generate_text_llm_result (qui contient l'analyse des
sentiments), le texte de l'avis client, le numéro client et l'ID de zone
géographique.
Examinez quelques enregistrements. Vous remarquerez peut-être que le
format de certains résultats, classés positifs ou négatifs, est incorrect.
Ils peuvent par exemple contenir des caractères superflus, tels que des
points ou des espaces en trop. Vous pouvez nettoyer les enregistrements en
utilisant la vue ci-dessous.
Créer une vue pour nettoyer les enregistrements
-
Créez une cellule de code en cliquant sur + Code, puis
ajoutez le code ci-dessous :
# Sanitize the records within a new view
%%bigquery
CREATE OR REPLACE VIEW gemini_demo.cleaned_data_view AS
SELECT REPLACE(REPLACE(LOWER(ml_generate_text_llm_result), '.', ''), ' ', '') AS sentiment,
REGEXP_REPLACE(
REGEXP_REPLACE(
REGEXP_REPLACE(social_media_source, r'Google(\+|\sReviews|\sLocal|\sMy\sBusiness|\sreviews|\sMaps)?', 'Google'),
'YELP', 'Yelp'
),
r'SocialMedia1?', 'Social Media'
) AS social_media_source,
review_text, customer_id, location_id, review_datetime
FROM `gemini_demo.customer_reviews_analysis`;
-
Exécutez cette cellule.
Le code crée la vue cleaned_data_view, qui comprend les
résultats d'analyse des sentiments, le texte de l'avis, le numéro client
et l'ID de zone géographique. Ensuite, il nettoie le résultat d'analyse du
sentiment (positif ou négatif) : il met toutes les lettres en minuscules
et supprime les caractères superflus, comme les espaces en trop ou les
points. La vue obtenue facilitera les analyses plus approfondies réalisées
ultérieurement au cours de cet atelier.
-
Créez une cellule de code en cliquant sur + Code, puis
ajoutez le code ci-dessous :
# Pull the first 50 records from the cleaned_data_view view
%%bigquery
SELECT * FROM `gemini_demo.cleaned_data_view`
ORDER BY review_datetime
-
Exécutez cette cellule.
Notez que la colonne sentiment contient désormais des valeurs
nettoyées pour les avis positifs et négatifs. Vous pourrez utiliser cette
vue ultérieurement pour créer un rapport.
Créer un rapport sur les nombres d'avis positifs et négatifs
Vous pouvez utiliser Python et la bibliothèque matplotlib pour créer un
rapport avec graphique à barres sur les nombres d'avis positifs et négatifs.
-
Créez une cellule et ajoutez-y le code ci-dessous afin d'utiliser le
client BigQuery pour interroger la vue cleaned_data_view sur les avis
positifs et négatifs, de regrouper les avis par sentiment et de stocker
les résultats dans un DataFrame.
# Task 6.5 - Create the BigQuery client, and query the cleaned data view for positive and negative reviews, store the results in a dataframe and then show the first 10 records
client = bigquery.Client()
query = "SELECT sentiment, COUNT(*) AS count FROM `gemini_demo.cleaned_data_view` WHERE sentiment like 'negative%' OR sentiment like 'positive%' GROUP BY sentiment;"
query_job = client.query(query)
results = query_job.result().to_dataframe()
results.head(10)
-
Exécutez cette cellule.
Le résultat de l'exécution de la cellule est une table contenant les
nombres totaux d'avis positifs et négatifs.
-
Créez une cellule pour définir les variables du rapport.
# Define variable for the report.
sentiment = results["sentiment"].tolist()
count = results["count"].tolist()
-
Exécutez cette cellule. Aucun résultat n'est produit.
-
Créez une cellule pour générer le rapport.
# Task 6.7 - Build the report.
plt.bar(sentiment, count, color='skyblue')
plt.xlabel("Sentiment")
plt.ylabel("Total Count")
plt.title("Bar Chart from BigQuery Data")
plt.show()
-
Exécutez cette cellule.
Le résultat est un graphique à barres présentant les nombres d'avis
positifs et négatifs.
-
Vous pouvez également créer un rapport simple avec un code couleur pour
visualiser le nombre de sentiments négatifs et positifs à l'aide du code
ci-dessous :
# Create an HTML table for the counts of negative and positive sentiment and color codes the results.
html_counts = f"""
| Negative |
Positive |
| {count[0]} |
{count[1]} |
"""
# Display the HTML tables
display(HTML(html_counts))
Cliquez sur Vérifier ma progression pour valider l'objectif.
Demander à Gemini d'analyser les mots clés et les sentiments des avis
clients
Tâche 7 : Répondre aux avis clients
Data Beans souhaite tester des avis clients utilisant des images et des
enregistrements audio. Dans cette section du notebook, vous allez utiliser
Cloud Storage, BigQuery, Gemini Flash et Python pour réaliser une analyse des
sentiments sur les avis clients fournis à Data Beans sous forme d'images et de
fichiers audio. À partir de l'analyse obtenue, vous allez générer les réponses
à envoyer au client pour le remercier de son avis, ainsi que les actions
possibles pour la chaîne de cafés en fonction de l'avis.
Vous effectuerez cela à grande échelle, puis vous répéterez le processus avec
une image et un fichier audio. Cela vous apprendra à créer une application de
démonstration de faisabilité pour les conseillers clientèle. Ce type de
processus de gestion des commentaires clients permet d'adopter une stratégie
"human-in-the-loop" (avec intervention humaine), où les conseillers clientèle
peuvent agir directement auprès des clients et des établissements.
Traitement des fichiers audio à grande échelle avec réponses JSON
-
Créez une cellule pour effectuer une analyse des sentiments sur les
fichiers audio et répondre au client.
# Conduct sentiment analysis on audio files and respond to the customer.
vertexai.init(project="{{{project_0.project_id | Project ID | disablehighlight }}}", location="{{{project_0.default_region | Region | disablehighlight}}}")
model = GenerativeModel(model_name="{{{project_0.startup_script.gemini_flash_model_id |model_id | disablehighlight}}}")
prompt = """
Please provide a transcript for the audio.
Then provide a summary for the audio.
Then identify the keywords in the transcript.
Be concise and short.
Do not make up any information that is not part of the audio and do not be verbose.
Then determine the sentiment of the audio: positive, neutral or negative.
Also, you are a customer service representative.
How would you respond to this customer review?
From the customer reviews provide actions that the location can take to improve. The response and the actions should be simple, and to the point. Do not include any extraneous characters in your response.
Answer in JSON format with five keys: transcript, summary, keywords, sentiment, response and actions. Transcript should be a string, summary should be a sting, keywords should be a list, sentiment should be a string, customer response should be a string and actions should be string.
"""
bucket_name = "{{{project_0.project_id | PROJECT ID | disablehighlight}}}-bucket"
folder_name = 'gsp1249/audio' # Include the trailing '/'
def list_mp3_files(bucket_name, folder_name):
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
print('Accessing ', bucket, ' with ', storage_client)
blobs = bucket.list_blobs(prefix=folder_name)
mp3_files = []
for blob in blobs:
if blob.name.endswith('.mp3'):
mp3_files.append(blob.name)
return mp3_files
file_names = list_mp3_files(bucket_name, folder_name)
if file_names:
print("MP3 files found:")
print(file_names)
for file_name in file_names:
audio_file_uri = f"gs://{bucket_name}/{file_name}"
print('Processing file at ', audio_file_uri)
audio_file = Part.from_uri(audio_file_uri, mime_type="audio/mpeg")
contents = [audio_file, prompt]
response = model.generate_content(contents)
print(response.text)
else:
print("No MP3 files found in the specified folder.")
Voici quelques points essentiels à propos de cette cellule :
-
La première ligne initialise Agent Platform avec l'ID de votre projet et
la région. Vous devez renseigner ces valeurs.
-
La ligne suivante crée un modèle nommé "model", basé sur le modèle
Gemini Flash, dans BigQuery.
-
Vous définissez ensuite le prompt que le modèle Gemini Flash va
utiliser. Le prompt convertit le fichier audio en texte, puis analyse le
sentiment du texte. Une fois l'analyse terminée, la réponse qui sera
renvoyée au client est générée pour chaque fichier.
-
Vous devez définir votre bucket en tant que variable de chaîne
"bucket_name". Remarque : "folder_name" est également utilisé pour le
sous-dossier gsp1249/audio. Ne modifiez pas cela.
-
Une fonction appelée "list_mp3_files" est créée pour identifier tous les
fichiers mp3 dans le bucket. Ces fichiers sont ensuite traités par le
modèle Gemini Flash dans l'instruction IF.
-
Exécutez cette cellule.
Les cinq fichiers audio sont analysés, et le résultat de l'analyse est
fourni sous forme de réponse JSON. La réponse JSON peut être analysée en
conséquence et acheminée vers les applications appropriées pour fournir
une réponse au client ou indiquer des mesures d'amélioration à un
établissement spécifique.
Créer une application pour les conseillers clientèle
Dans cette section de l'atelier, vous allez apprendre à créer une application
de service client basée sur l'analyse d'un avis négatif. Vous découvrirez
comment :
-
utiliser le même prompt que celui de la cellule précédente pour analyser un
seul avis négatif ;
-
générer la transcription à partir du fichier audio de l'avis négatif, créer
l'objet JSON à partir de la sortie du modèle avec le formatage approprié, et
enregistrer des parties spécifiques de l'objet JSON en tant que variables
Python à utiliser avec HTML dans votre application ;
-
générer la table HTML, charger l'image que le client a importée pour l'avis
et charger le fichier audio dans le lecteur ;
-
afficher la table HTML, avec l'image et le lecteur pour le fichier audio.
-
Créez une cellule et insérez le code suivant pour pouvoir générer la
transcription du fichier audio de l'avis négatif, ainsi que créer l'objet
JSON et les variables associées.
# Generate the transcript for the negative review audio file, create the JSON object, and associated variables
audio_file_uri = f"gs://{bucket_name}/{folder_name}/data-beans_review_7061.mp3"
print(audio_file_uri)
audio_file = Part.from_uri(audio_file_uri, mime_type="audio/mpeg")
contents = [audio_file, prompt]
response = model.generate_content(contents)
print('Generating Transcript...')
#print(response.text)
results = response.text
# print("your results are", results, type(results))
print('Transcript created...')
print('Transcript ready for analysis...')
json_data = results.replace('```json', '')
json_data = json_data.replace('```', '')
jason_data = '"""' + results + '"""'
# print(json_data, type(json_data))
data = json.loads(json_data)
# print(data)
transcript = data["transcript"]
summary = data["summary"]
sentiment = data["sentiment"]
keywords = data["keywords"]
response = data["response"]
actions = data["actions"]
Voici quelques points essentiels à propos de cette cellule :
-
Le code de la cellule sélectionnera un fichier audio spécifique dans
Cloud Storage (data-beans_review_7061.mp3).
-
Il enverra ensuite le fichier au prompt de la cellule précédente
étiquetée "Task 7.1" pour que le modèle Gemini Flash le traite.
- La réponse du modèle est extraite au format JSON.
-
Les données JSON sont ensuite analysées, et les variables Python pour la
transcription, le résumé, le sentiment, les mots clés, la réponse
apportée au client et les actions sont stockées.
-
Exécutez le code de la cellule.
La sortie est réduite au strict minimum. Elle ne contient que l'URI du
fichier audio traité et les messages de traitement.
-
Créez une table HTML à partir des valeurs sélectionnées et chargez le
fichier audio contenant l'avis négatif dans le lecteur.
# Create an HTML table (including the image) from the selected values.
html_string = f"""
| customer_id: 7061 - @coffee_lover789 |
|
| {transcript} |
{sentiment} feedback |
| |
| {keywords[0]} |
| {keywords[1]} |
| {keywords[2]} |
| {keywords[3]} |
|
|
Customer summary:{summary} |
|
Recommended actions:{actions} |
|
Suggested Response:{response} |
"""
print('The table has been created.')
Voici quelques points essentiels à propos de cette cellule :
- Le code présent dans la cellule créera une chaîne de table HTML.
-
Il insèrera ensuite les valeurs pour la transcription, le sentiment, les
mots clés, l'image, le résumé, les actions et la réponse dans les
cellules de la table.
- Le code appliquera également un style aux éléments de la table.
-
Lors de l'exécution de la cellule, la sortie indiquera quand la table
aura été créée.
-
Recherchez le tag <td style="padding:10px;"> avec la
sortie {summary} incluse. Ajoutez une ligne de code avant ce
tag.
-
Collez
<td rowspan="3" style="padding: 10px;"><img
src="<authenticated url here>" alt="Customer Image" style="max-width:
300px;"></td>
dans cette nouvelle ligne de code.
-
Recherchez l'URL authentifiée pour le fichier image_7061.png. Accédez à
Cloud Storage, sélectionnez le seul bucket disponible, puis le dossier
d'images, et cliquez sur l'image.
-
Dans la page qui apparaît, copiez l'URL authentifiée pour l'image.
-
Revenez au notebook Python dans BigQuery. Remplacez
<authenticated url here> par l'URL authentifiée réelle
dans le code que vous venez de coller.
-
Exécutez le code de la cellule.
Encore une fois, la sortie est réduite au strict minimum. Il s'agit
seulement des messages de traitement qui indiquent l'achèvement de chaque
étape.
-
Créez une cellule et insérez-y le code ci-dessous pour pouvoir télécharger
le fichier audio et le charger dans le lecteur :
# Download the audio file from Google Cloud Storage and load into the player
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(f"{folder_name}/data-beans_review_7061.mp3")
audio_bytes = io.BytesIO(blob.download_as_bytes())
# Assuming a sample rate of 44100 Hz (common for MP3 files)
sample_rate = 44100
print('The audio file is loaded in the player.')
Voici quelques points essentiels à propos de cette cellule :
-
Le code dans la cellule accède au bucket Cloud Storage et récupère le
fichier audio concerné (data-beans_review_7061.mp3).
-
Il télécharge ensuite le fichier en tant que flux d'octets et détermine le
taux d'échantillonnage du fichier, de sorte que celui-ci puisse être lu dans
un lecteur directement dans le notebook.
-
Lorsque la cellule est exécutée, la sortie est un message indiquant que le
fichier audio est chargé dans le lecteur et qu'il est prêt à être lu.
-
Exécutez le code de la cellule.
-
Créez une cellule et insérez le code ci-dessous :
# Task 7.5 - Build the mockup as output to the cell.
print('Analysis complete. Review the results below.')
display(HTML(html_string))
display(Audio(audio_bytes.read(), rate=sample_rate, autoplay=True))
- Exécutez le code de la cellule.
C'est dans cette cellule que la magie opère. La méthode "display" permet
d'afficher le HTML et le fichier audio chargé dans le lecteur. Examinez la
sortie de la cellule. Elle doit ressembler à l'image ci-dessous :
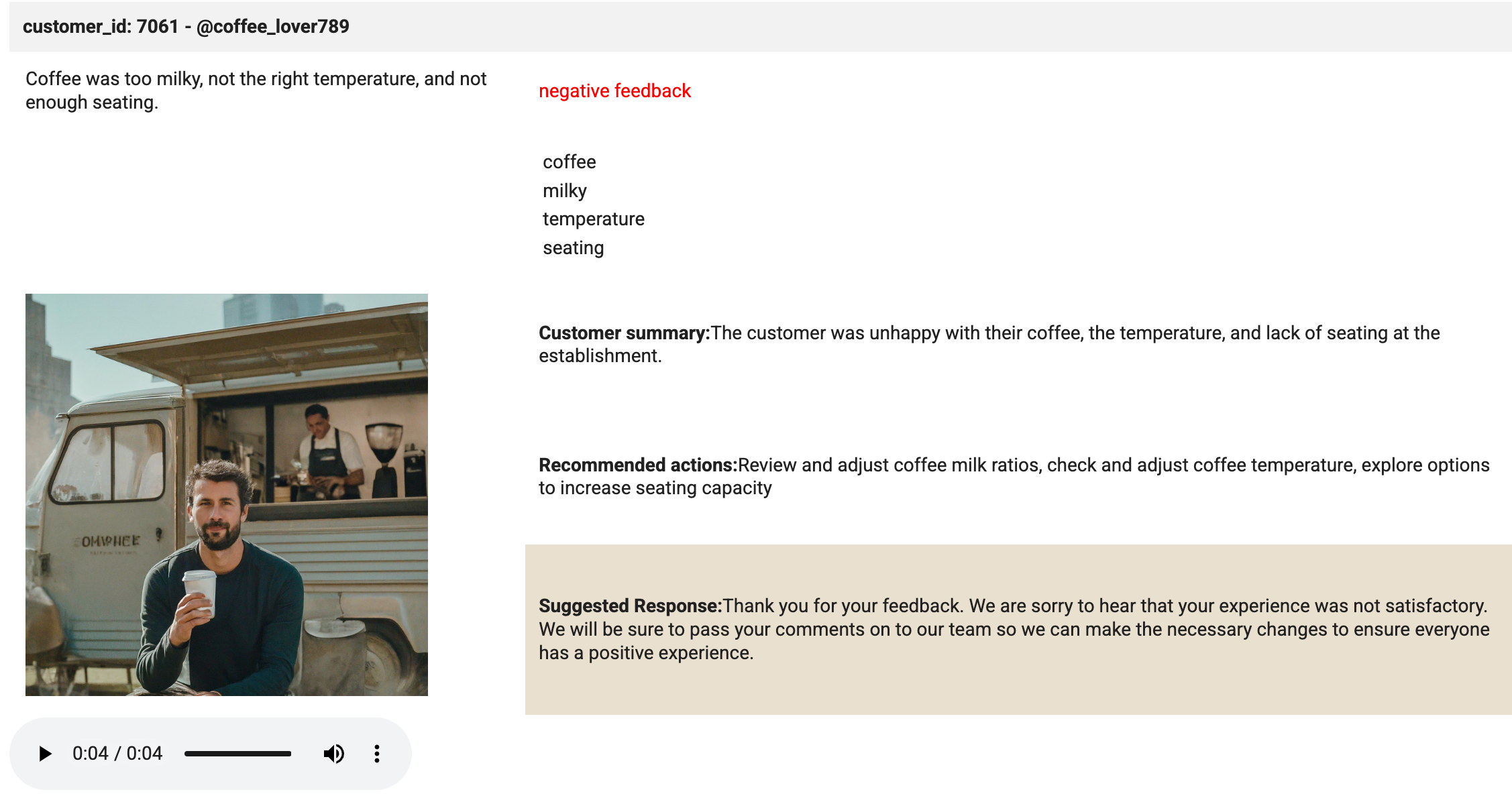
Cliquez sur Vérifier ma progression pour valider l'objectif.
Répondre aux avis clients
Félicitations !
Vous avez créé une connexion à une ressource cloud dans BigQuery. Vous avez
également créé un ensemble de données, des tables et des modèles pour demander
à Gemini d'analyser le sentiment et les mots clés dans des avis clients.
Enfin, vous avez analysé les avis clients audio avec Gemini pour générer des
résumés et des mots clés et répondre aux avis dans une application de service
client.
Étapes suivantes et informations supplémentaires
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 5 novembre 2025
Dernier test de l'atelier : 5 novembre 2025
Copyright 2026 Google LLC. Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.





