
始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Enable the Agent Platform API
/ 20
Extract the content of the image
/ 20
Extract the content of the video
/ 20
Create prompts with text
/ 40
Enable the Agent Platform API
/ 20
Extract the content of the image
/ 20
Extract the content of the video
/ 20
Create prompts with text
/ 40

免責事項: このコースの情報は教育目的のみに使用されるものであり、診断や治療、患者の直接的なケアを目的とした Google の生成 AI サービスの使用を Google が承認するものではありません。
Agent Platform は、予測 AI と生成 AI の両方の機能を備え、医療アプリケーションを強化するように設計された強力な ML プラットフォームです。Agent Studio は直感的なインターフェースとして機能し、医療従事者や研究者はこれを使用して、ML に関する幅広い専門知識がなくても、生成 AI モデルを簡単にテスト、カスタマイズできます。このユーザー フレンドリーなプラットフォームには、UI ベースのインタラクションやサンプルコードなど、さまざまなツールとリソースが用意されているため、医療アプリケーションで生成 AI の機能を簡単に活用できます。
このハンズオンラボでは、Agent Studio を詳しく掘り下げ、Gemini マルチモーダルなどの最先端の生成 AI モデルの機能を探っていきます。Gemini を使用して、プロンプト設計手法を試し、テキストの要約、質問への回答、センチメントの分類を行います。これらはすべて Google Cloud コンソール内で直接行うことができ、複雑な API や Python SDK は必要ありません。そのため、さまざまなレベルの技術的な専門知識を持つ医療従事者が利用できます。
このラボでは、次の方法について学びます。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

このセクションでは、Gemini を使用して画像を分析します。画像から情報を抽出するプロンプトを設計し、モデルの回答を観察します。
Google Cloud コンソールで、上部の検索バーに「Agent Platform API」と入力します。
[マーケットプレイスと API] の下で検索結果の「Agent Platform API」をクリックします。
[有効にする] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
 )で、[Agent Platform] > [Agent Studio]
> [+ 新規] を選択し、[
)で、[Agent Platform] > [Agent Studio]
> [+ 新規] を選択し、[チャット] を選択します。
UI には次の 3 つのメイン セクションがあります。
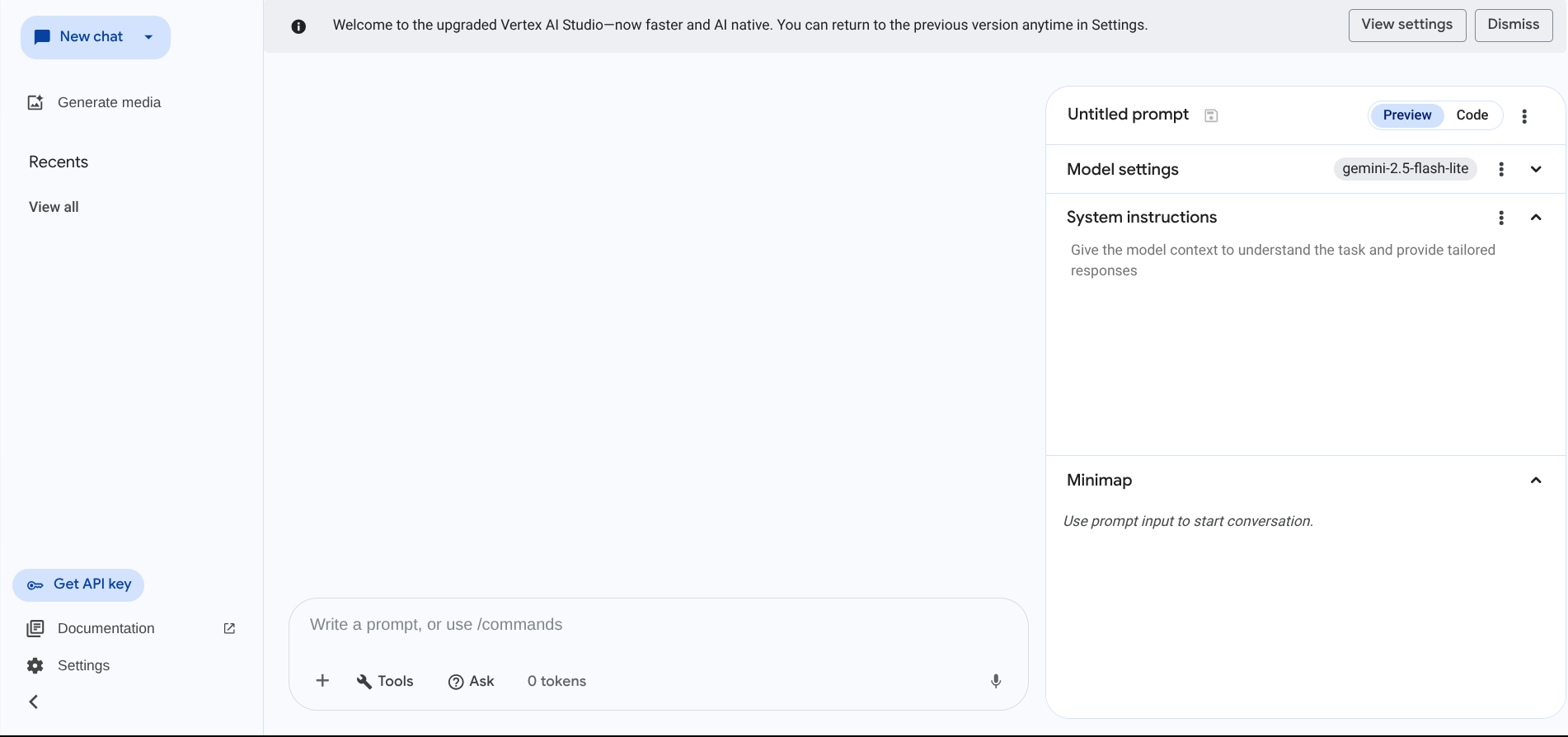
右上の [無題のプロンプト]
をクリックして、プロンプトの名前を「Medical Image Analysis」に変更します。
右側の [構成] セクションで、モデル名
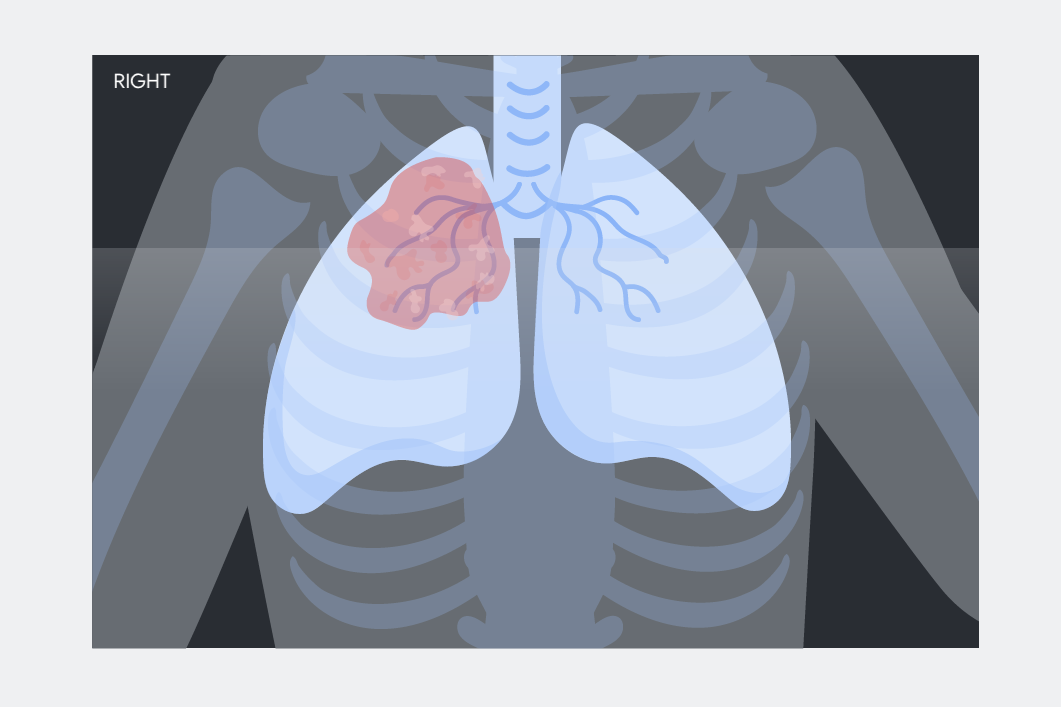
サンプル画像をダウンロードします。胸部 X 線画像を右クリックして、パソコンに保存します。
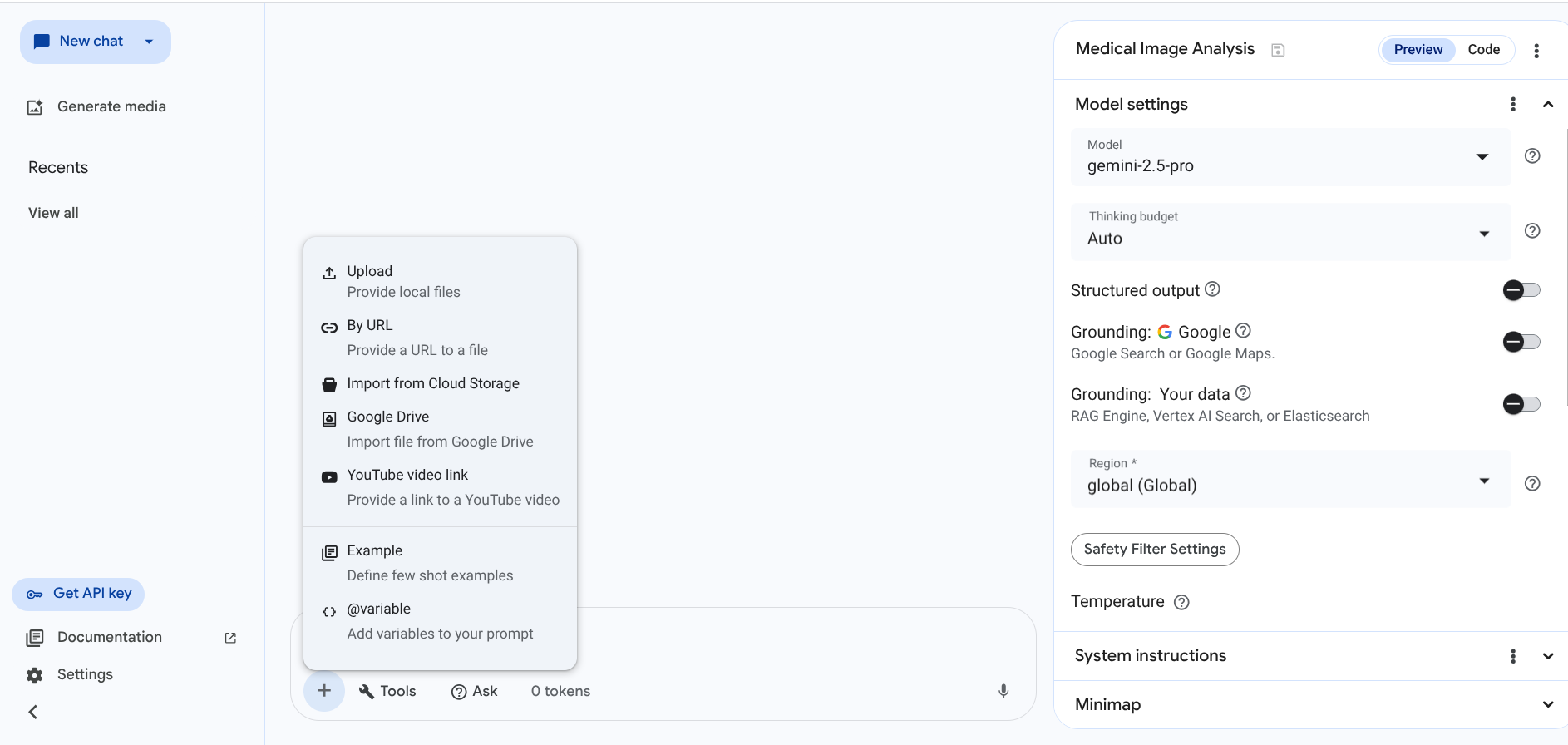
または、次のように具体的に指定します。
タイトルは期待どおりでしたか?プロンプトを変更して、異なる結果が出力されるかどうかを確認してください。
さらに、出力をリスト形式にする場合は、前のプロンプトを以下の内容に置き換えます。
さまざまなプロンプトを試してみましょう。前のプロンプトと比べて結果はどのように異なりますか?
結果は期待どおりですか?各種タスクにさまざまなプロンプトを試してみることをおすすめします。また、温度の設定を変更して結果の変化を確認してみましょう。
プロンプトの設計が完了したら、[構成] セクション右上の
[保存]
ロゴをクリックしてプロンプトを保存します。リージョンについては、プルダウンから
[
保存したプロンプトを確認するには、左側のメニューで [最近使用したアイテム] の [すべて] に移動し、[プロンプト] を選択します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Gemini マルチモーダルでは、画像やテキストだけでなく、動画を入力として受け入れて、出力としてテキストを生成できます。動画を取得するには、肺のアニメーション動画へのリンクをクリックし、動画をパソコンに保存して、Agent Studio にアップロードします。
[Agent Studio] > [+ 新規]
に戻り、[チャット] を選択します。
[無題のプロンプト] をクリックして、プロンプトの名前を「Medical Video Analysis」に変更します。
[構成] セクションで、モデル名
[メディアを挿入] > [アップロード] をクリックします。ダウンロードした肺のアニメーション動画を選択して、[開く] をクリックします。
独自のプロンプトを入力して、動画に関する情報を生成します。たとえば、動画を詳しく説明するには、以下の内容を [プロンプト] セクションにコピーして、[送信] ボタンをクリックします。
注: プロンプトが自動保存機能ですでに保存されている場合は、プロンプトの名前が正しいことと、プロンプト管理ページに表示されることを確認してください。
Gemini を活用したマルチモーダルには、複雑な画像を簡単に説明する機能、動画を分析する機能、教育用のマルチメディア ビジュアル補助教材を生成する機能など、さまざまな機能があります。詳しくは、マルチモーダル プロンプトを設計するをご覧ください。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このセクションでは、Agent Studio でのテキスト プロンプト設計を試します。ゼロショット プロンプト、ワンショット プロンプト、少数ショット プロンプトを確認し、テキスト要約の生成、質問への回答、テキストの分類を行います。
質問などの任意の入力テキストをモデルにフィードできます。これにより、モデルは、プロンプトの構成や表現方法に基づいてレスポンスを提供できます。モデルから最も望ましいレスポンスを得るための最良の入力テキスト(プロンプト)を解明して設計するプロセスはプロンプト設計と呼ばれます。
プロンプトの設計方法は主に 3 つあります。
温度とトークンの上限は、モデルのレスポンスに影響を与えるために調整できる 2 つの重要なパラメータです。
[Agent Studio] > [+ 新規]
に戻り、[チャット] を選択します。
[無題のプロンプト] をクリックして、プロンプトの名前を「Medical Condition Analysis」に変更します。
[構成] セクションで、モデル名
[送信] ボタンをクリックします。
次の内容をプロンプトの入力フィールドにコピーします。
モデルは、1 型糖尿病の基礎的なメカニズムに関する詳細な説明を返します。
モデルは、足関節捻挫の一般的な治療法のリストを返します。
ワンショット プロンプトでは、回答を生成するために、モデルに 1 つの例を提供します。
ツールバーの共有アイコンの横にあるその他メニュー(⋮)をクリックし、[削除] オプションを選択してプロンプトをクリアします。
[Agent Studio] > [+ 新規] に戻り、[チャット] を選択します。
[無題のプロンプト] をクリックして、プロンプトの名前を「Medical Example Prompt」に変更します。
[構成] セクションで、モデル名
[プロンプト] セクションで、[例を追加] ボタンをクリックします。
[例を追加] ボタンをクリックします。
例を追加すると、{Input} とプロンプトの 2
つのセクションに入力する必要があります。プロンプトを送信するには、プロンプトに加えて、別の入力例を指定する必要があります。
[{Input}] フィールドに、次のように入力します。
モデルは、小学 6 年生の読解レベルに合わせて簡略化された糖尿病の説明を返します。
今回はモデルの出力のベースとなるいくつかの例を追加します。
| 入力 | 出力 |
|---|---|
| ぜんそく | 気道が狭くなり、呼吸が困難になります |
| 湿疹 | 皮膚が乾燥し、かゆくなったり赤くなったりします |
{INPUT}] フィールドに、次のように入力します。完了したら、[例を追加] ボタンをクリックします。
[送信] ボタンをクリックします。
モデルがレスポンスを生成する方法に影響を与えることに成功しました。これで、モデルによって生成されたがんの説明が小学 6 年生の読解レベルに合わせて易しく書き直され、表に表示されます。
次の演習では、モデルを使用して段落を 1 つの文に要約します。
[Agent Studio] > [+ 新規] に戻り、[チャット] を選択します。
[無題のプロンプト] をクリックして、プロンプトの名前を「Text Summarization」に変更します。
[構成] セクションで、モデル名
次の段落を [プロンプト] フィールドにコピーします。
モデルは質問に対する回答を返します(回答は異なる場合があります)。
モデルは質問に対する回答を返します(回答は異なる場合があります)。
モデルは質問に対する回答を返します(回答は異なる場合があります)。
注: プロンプトが自動保存機能ですでに保存されている場合は、プロンプトの名前が正しいことと、プロンプト管理ページに表示されることを確認してください。
保存したプロンプトは、[プロンプト管理] セクションに表示されます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
これで完了です。このラボでは、ヘルスケア向け Agent Studio の機能を探りました。Gemini マルチモーダルを使用して画像と動画を分析し、テキスト プロンプトを設計しました。また、ゼロショット プロンプト、ワンショット プロンプト、少数ショット プロンプトについても調べ、テキスト要約、質問への回答、テキスト分類を生成する方法も学びました。これで、生成 AI モデルの機能を活用する準備が整いました。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2026 年 2 月 13 日
ラボの最終テスト日: 2026 年 2 月 13 日
Copyright 2026 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。