Vertex AI is now Gemini Enterprise Agent Platform! We are currently updating our content to reflect this change. Please bear with us if you encounter naming inconsistencies during this transition.
Apply your skills in Google Cloud console
Checkpoints
Enable the Document AI API
Check my progress
/ 10
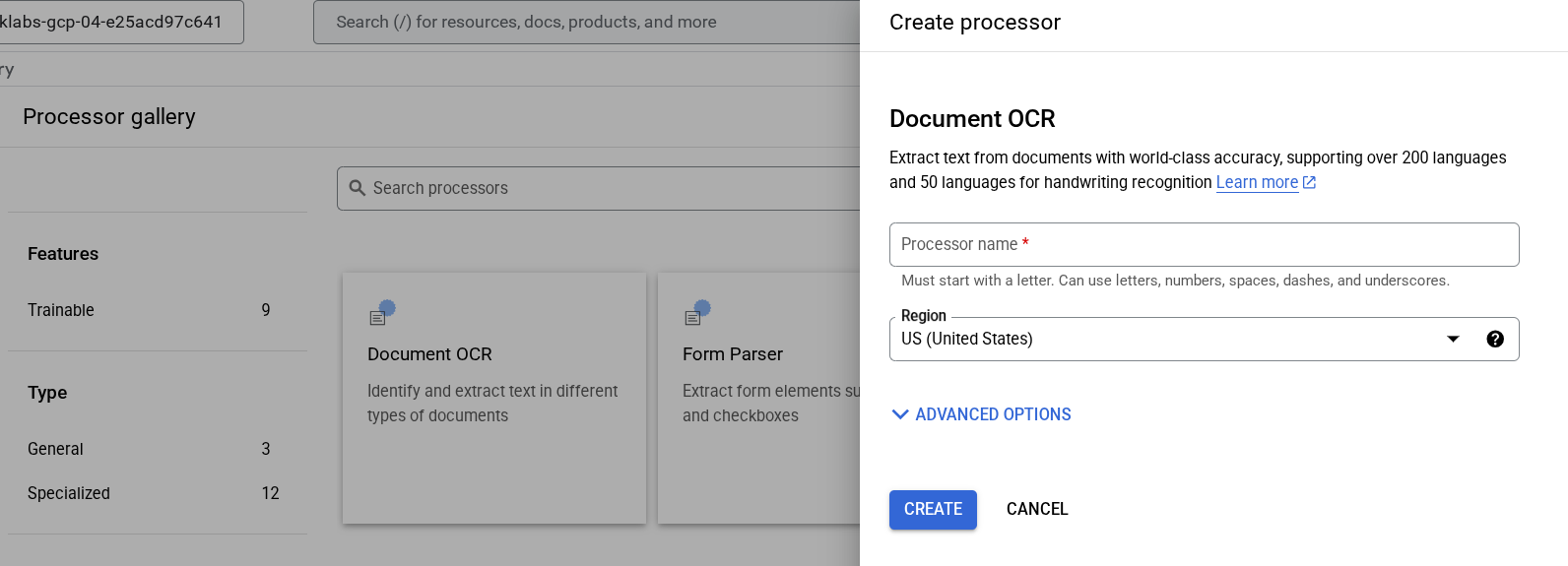
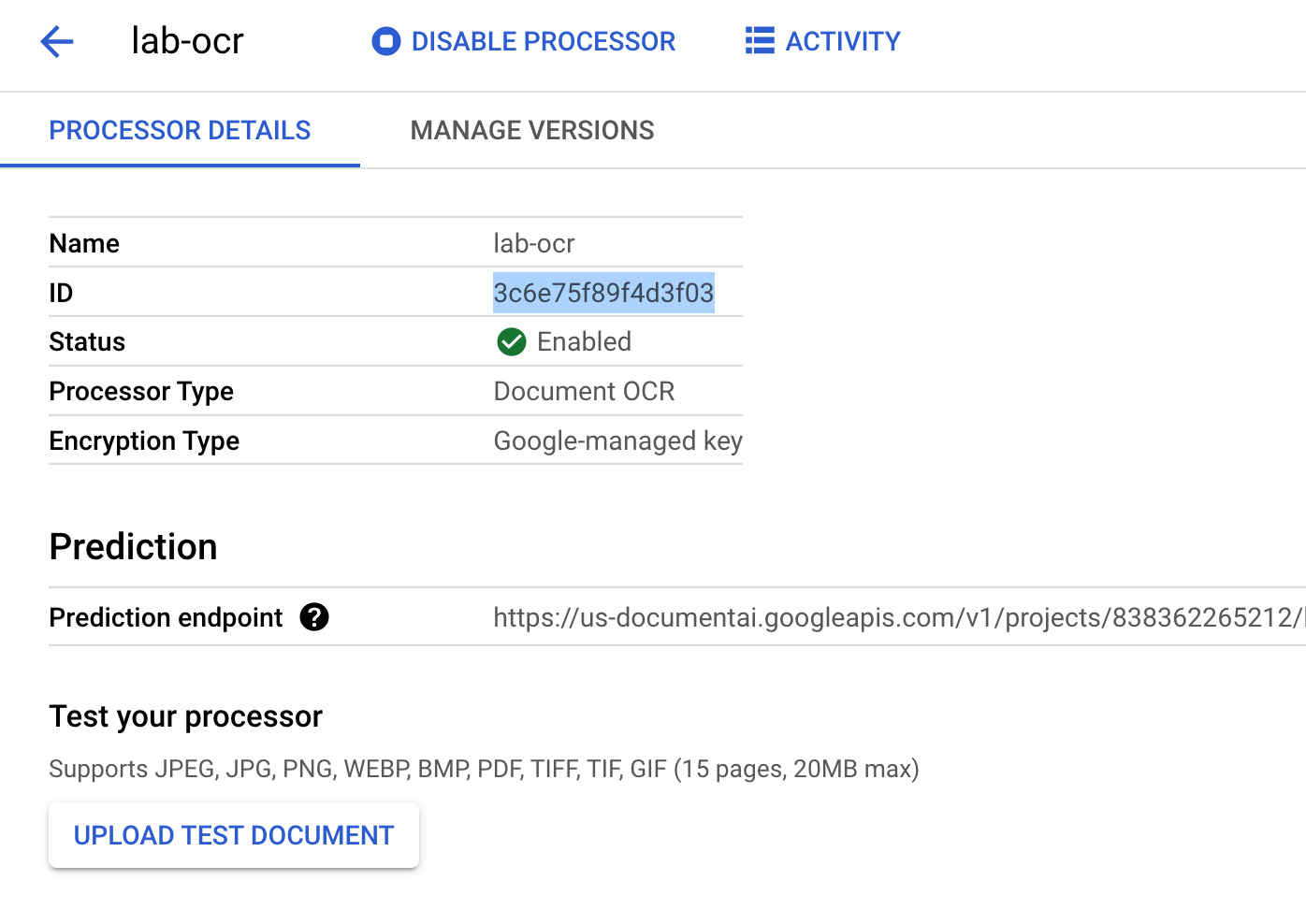
Create a processor
Check my progress
/ 20
Authenticate API requests
Check my progress
/ 30
Make a batch processing request
Check my progress
/ 20
Make a batch processing request for a directory
Check my progress
/ 20
Lab setup instructions and requirements
Protect your account and progress. Always use a private browser window and lab credentials to run this lab.
如要向 Document AI API 提出要求,必須使用「服務帳戶」。「服務帳戶」屬於您的專案,Python 用戶端程式庫會使用此帳戶提出 API 要求。服務帳戶與其他使用者帳戶一樣,都是以電子郵件地址表示。在本節中,您將使用「Cloud SDK」建立服務帳戶,然後建立以服務帳戶身分進行驗證所需的憑證。
Document processing complete.
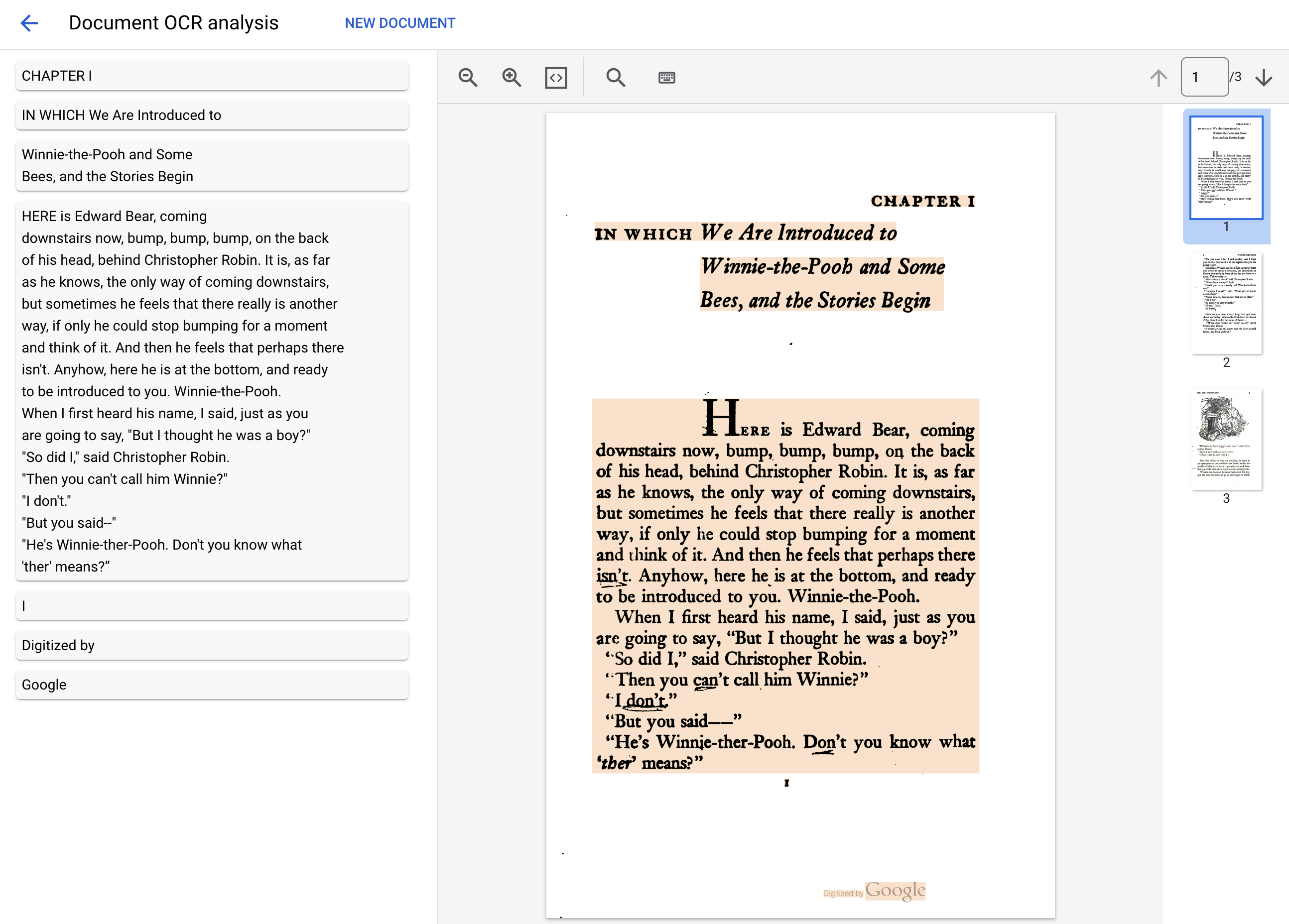
Text: IN WHICH We Are Introduced to
CHAPTER I
Winnie-the-Pooh and Some
Bees, and the Stories Begin
HERE is Edward Bear, coming
downstairs now, bump, bump, bump, on the back
of his head, behind Christopher Robin. It is, as far
as he knows, the only way of coming downstairs,
but sometimes he feels that there really is another
way, if only he could stop bumping for a moment
and think of it. And then he feels that perhaps there
isn't. Anyhow, here he is at the bottom, and ready
to be introduced to you. Winnie-the-Pooh.
When I first heard his name, I said, just as you
are going to say, "But I thought he was a boy?"
"So did I," said Christopher Robin.
"Then you can't call him Winnie?"
"I don't."
"But you said--"
...
工作 6:發出批次處理要求
現在,假設您想閱讀整本小說的內容。
線上處理功能對可傳送的頁數和檔案大小設有限制,且每次 API 呼叫只能處理一個文件檔案。
批次處理功能可透過非同步方法處理較大或多個檔案。
在本節中,您將使用 Document AI 批次處理 API 處理整本《小熊維尼》小說,並將文字輸出至 Google Cloud Storage Bucket。
Document processing complete.
Fetching 16218185426403815298/0/Winnie_the_Pooh-0.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-1.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-10.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-11.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-12.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-13.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-14.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-15.json
..
This is a reproduction of a library book that was digitized
by Google as part of an ongoing effort t
0
TAM MTAA
Digitized by
Google
Introduction
(I₂
F YOU happen to have read another
book about Christo
84
Eeyore took down his right hoof from his right
ear, turned round, and with great difficulty put u
94
..
Document processing complete.
Fetching 16354972755137859334/0/Winnie_the_Pooh_Page_0-0.json
Fetching 16354972755137859334/1/Winnie_the_Pooh_Page_1-0.json
Fetching 16354972755137859334/2/Winnie_the_Pooh_Page_10-0.json
..
Introduction
(I₂
F YOU happen to have read another
book about Christopher Robin, you may remember
th
IN WHICH We Are Introduced to
CHAPTER I
Winnie-the-Pooh and Some
Bees, and the Stories Begin
HERE is
..
太好了!您已成功使用 Document AI Python 用戶端程式庫,透過 Document AI 處理器處理文件目錄,並將結果輸出至 Cloud Storage。
點按「Check my progress」,確認目標已達成。
對目錄提出批次處理要求
恭喜!
恭喜!在本實驗室中,您學會如何使用 Document AI Python 用戶端程式庫,透過 Document AI 處理器處理目錄中的文件,並將結果輸出至 Cloud Storage。您也學會如何使用服務帳戶金鑰檔案驗證 API 要求、安裝 Document AI Python 用戶端程式庫,以及使用線上 (同步) 和批次 (非同步) API 處理要求。
Labs create a Google Cloud project and resources for a fixed time
Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
On the top left of your screen, click Start lab to begin
Use private browsing
Copy the provided Username and Password for the lab
Click Open console in private mode
Sign in to the Console
Sign in using your lab credentials. Using other credentials might cause errors or incur charges.
Accept the terms, and skip the recovery resource page
Don't click End lab unless you've finished the lab or want to restart it, as it will clear your work and remove the project
This content is not currently available
We will notify you via email when it becomes available
Great!
We will contact you via email if it becomes available
One lab at a time
Confirm to end all existing labs and start this one
Use private browsing to run the lab
Using an Incognito or private browser window is the best way to run
this lab. This prevents any conflicts between your personal account
and the Student account, which may cause extra charges incurred to
your personal account.
在本實驗室中,您將瞭解如何使用 Python 搭配 Document AI API 來執行光學字元辨識。