GSP1138
概要
Document AI は、ドキュメント、メール、請求書、フォームなどの非構造化データを簡単に理解、分析、利用できるようにするドキュメント分析ソリューションです。この API を利用すると、コンテンツ分類、エンティティ抽出、高度な検索機能などを通じてデータを整理できます。
このラボでは、Document AI と Python を使用して PDF ドキュメントの光学式文字認識(OCR)を行います。オンライン(同期)およびバッチ(非同期)で処理をリクエストする方法についても学習します。
ここでは、最近米国でパブリック ドメイン になった A.A. ミルンの名作小説『クマのプーさん』の PDF ファイルを使用します。このファイルは Google ブックス によってスキャンされ、デジタル化されています。
目標
このラボでは、次のタスクの実行方法について学びます。
Document AI API を有効にする
API リクエストを認証する
Python 用クライアント ライブラリをインストールする
オンライン処理とバッチ処理の API を使用する
PDF ファイルのテキストを解析する
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始 ] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
標準的なインターネット ブラウザ(Chrome を推奨)
注: このラボの実行には、シークレット モード(推奨)またはシークレット ブラウジング ウィンドウを使用してください。これにより、個人アカウントと受講者アカウント間の競合を防ぎ、個人アカウントに追加料金が発生しないようにすることができます。
ラボを完了するための時間(開始後は一時停止できません)
注: このラボでは、受講者アカウントのみを使用してください。別の Google Cloud アカウントを使用すると、そのアカウントに料金が発生する可能性があります。
ラボを開始して Google Cloud コンソールにログインする方法
[ラボを開始 ] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。
左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] ボタン
残り時間
このラボで使用する必要がある一時的な認証情報
このラボを行うために必要なその他の情報(ある場合)
[Google Cloud コンソールを開く ] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く ] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択 ] ダイアログが表示されたら、[別のアカウントを使用 ] をクリックします。
必要に応じて、下のユーザー名 をコピーして、[ログイン ] ダイアログに貼り付けます。
{{{user_0.username | "Username"}}}
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ ] をクリックします。
以下のパスワード をコピーして、[ようこそ ] ダイアログに貼り付けます。
{{{user_0.password | "Password"}}}
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ ] をクリックします。
重要: ラボで提供された認証情報を使用する必要があります。Google Cloud アカウントの認証情報は使用しないでください。
注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。
その後次のように進みます。
利用規約に同意してください。
一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
無料トライアルには登録しないでください。
その後、このタブで Google Cloud コンソールが開きます。
注: Google Cloud のプロダクトやサービスにアクセスするには、ナビゲーション メニュー をクリックするか、[検索 ] フィールドにサービス名またはプロダクト名を入力します。
Cloud Shell をアクティブにする
Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする 」アイコン
ウィンドウで次の操作を行います。
Cloud Shell 情報ウィンドウで操作を進めます。
Cloud Shell が認証情報を使用して Google Cloud API を呼び出すことを承認します。
接続した時点で認証が完了しており、プロジェクトに各自の Project_ID 、PROJECT_ID を宣言する次の行が含まれています。
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
(省略可)次のコマンドを使用すると、有効なアカウント名を一覧表示できます。
gcloud auth list
[承認 ] をクリックします。
出力:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
(省略可)次のコマンドを使用すると、プロジェクト ID を一覧表示できます。
gcloud config list project
出力:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
注: Google Cloud における gcloud ドキュメントの全文については、gcloud CLI の概要ガイド をご覧ください。
タスク 1. Document AI API を有効にする
Document AI を使用するには、API を有効にする必要があります。
コンソールの上部にある検索バーで「Document AI API」を検索します。Google Cloud プロジェクトで API を使用するには、[有効にする ] をクリックします。
同様に、検索バーで「Cloud Storage API」を検索し、まだ有効になっていない場合は [有効にする ] をクリックします。
または、次の gcloud コマンドで API を有効にすることもできます。
gcloud services enable documentai.googleapis.com
gcloud services enable storage.googleapis.com
次のように表示されます。
Operation "operations/..." finished successfully.
これで Document AI を使用できるようになりました。
[進行状況を確認 ] をクリックして、目標に沿って進んでいることを確認します。
Document AI API を有効にする
タスク 2. プロセッサを作成してテストする
まず、抽出を実行する Document OCR プロセッサのインスタンスを作成します。この操作には Cloud コンソールまたは Processor Management API を使用します。
ナビゲーション メニューで、[すべてのプロダクトを表示 ] をクリックします。[AI ] で [Document AI ] を選択します。
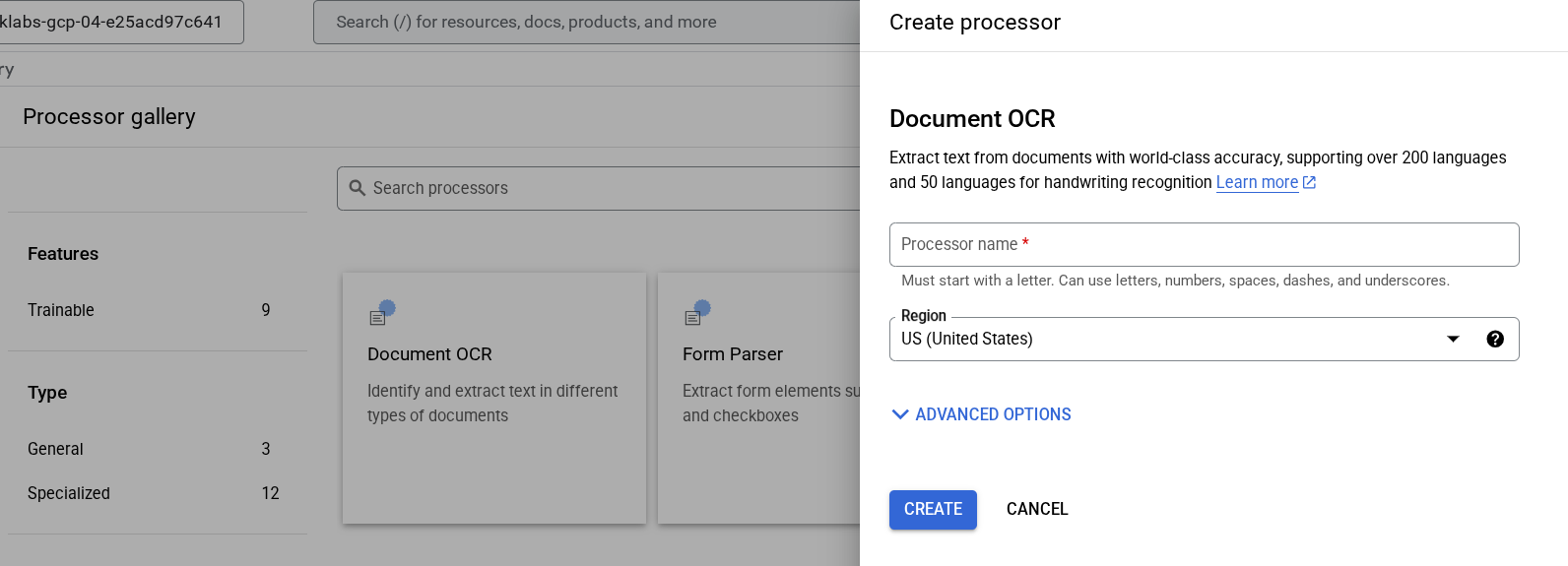
[プロセッサを確認 ] をクリックし、[Document OCR ] をクリックします。
名前を「lab-ocr」にして、リストから最も近いリージョンを選択します。
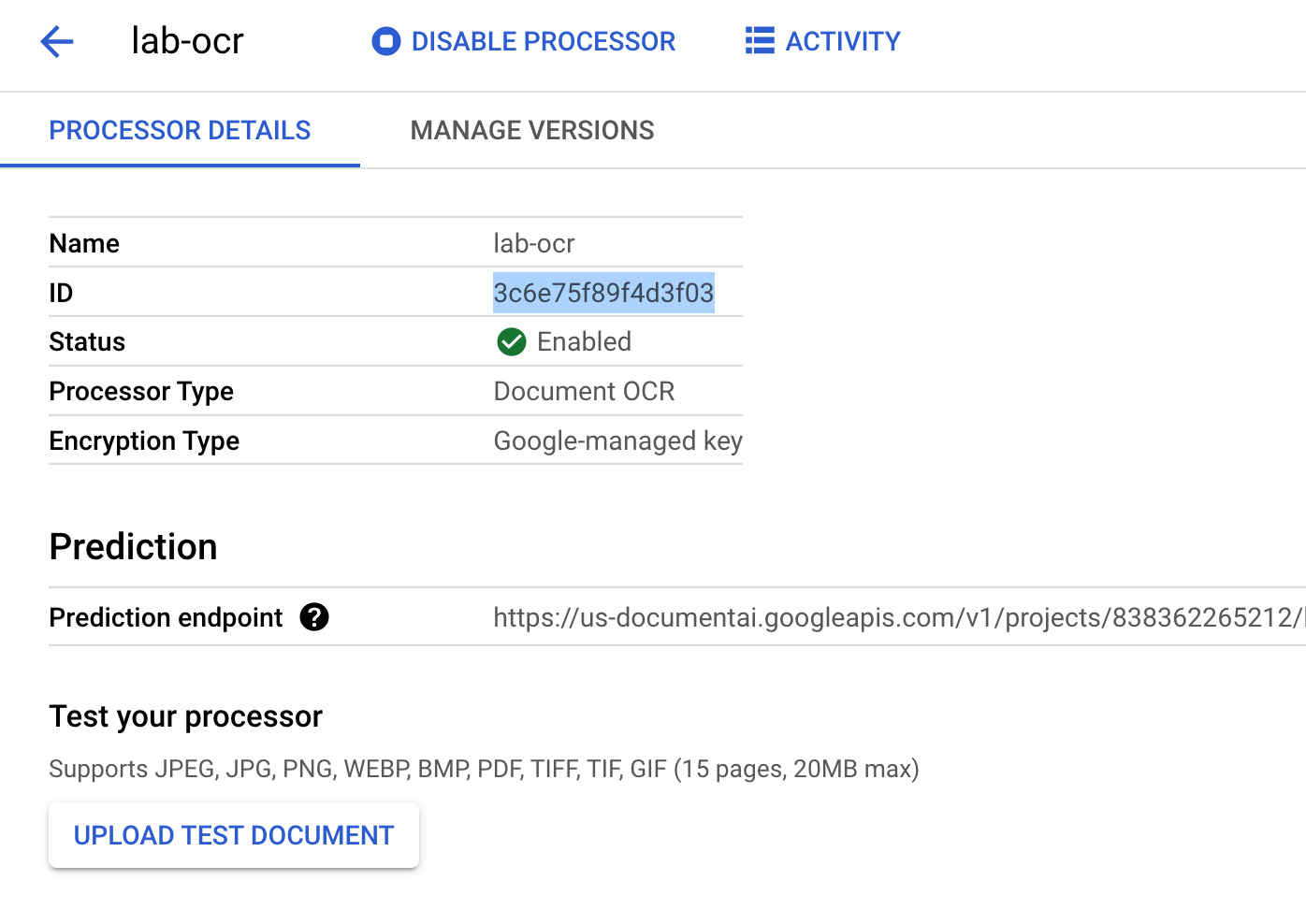
[作成 ] をクリックして、プロセッサを作成します。
プロセッサ ID をコピー します。これは、後でコード内で使用します。
次の PDF ファイルをダウンロードします。このファイルには、A.A. ミルンの小説『クマのプーさん』の最初の 3 ページが含まれています。
PDF をダウンロード
ドキュメントをアップロードして、コンソールでプロセッサをテストしてみましょう。
[テスト ドキュメントをアップロード ] をクリックして、ダウンロードした PDF ファイルを選択します。
出力は次のようになります。
[進行状況を確認 ] をクリックして、目標に沿って進んでいることを確認します。
プロセッサを作成してテストする
タスク 3. API リクエストを認証する
Document AI API にリクエストを送信するには、サービス アカウントを使用する必要があります。
まず、新しい Cloud Shell ウィンドウを開き、次のコマンドを実行してプロジェクト ID を環境変数として設定します。
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
次に、Document AI API にアクセスする新しいサービス アカウントを作成します。
gcloud iam service-accounts create my-docai-sa \
--display-name "my-docai-service-account"
次のコマンドを実行して、Document AI、Cloud Storage、Service Usage にアクセスするための権限をサービス アカウントに付与します。
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} \
--member="serviceAccount:my-docai-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" \
--role="roles/documentai.admin"
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} \
--member="serviceAccount:my-docai-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} \
--member="serviceAccount:my-docai-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" \
--role="roles/serviceusage.serviceUsageConsumer"
作成した新しいサービス アカウントとしてログインするために、Python コードで使用する認証情報を作成します。次のコマンドを使用して認証情報を作成し、JSON ファイル「~/key.json」に保存します。
gcloud iam service-accounts keys create ~/key.json \
--iam-account my-docai-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
最後に、GOOGLE_APPLICATION_CREDENTIALS 環境変数を設定します。これは、認証情報を検索する際にライブラリによって使用されます。先ほど作成した、認証情報を含む JSON ファイルのフルパスを設定する必要があります。
export GOOGLE_APPLICATION_CREDENTIALS=$(realpath key.json)
この認証形式の詳細については、ガイド をご覧ください。
[進行状況を確認 ] をクリックして、目標に沿って進んでいることを確認します。
API リクエストを認証する
タスク 4. クライアント ライブラリをインストールする
Cloud Shell で次のコマンドを実行し、Document AI および Cloud Storage 用の Python クライアント ライブラリをインストールします。
pip3 install --upgrade google-cloud-documentai
pip3 install --upgrade google-cloud-storage
次のように表示されます。
...
Installing collected packages: google-cloud-documentai
Successfully installed google-cloud-documentai-1.4.1
.
.
Installing collected packages: google-cloud-storage
Successfully installed google-cloud-storage-1.43.0
これで、Document AI API を使用する準備ができました。
注: 独自の Python 開発環境を設定する場合は、こちらのガイドライン に従ってください。
サンプル PDF を Cloud Shell にアップロードする
Cloud Shell のツールバーで、その他アイコンをクリックし、[アップロード ] を選択します。
[ファイル ] > [ファイルを選択 ] の順にクリックし、先ほどダウンロードした 3 ページの PDF ファイルを選択します。
[アップロード ] をクリックします。
または 、gcloud storage cp を使用して、Google Cloud Storage の公開バケットから PDF をダウンロードすることもできます。
gcloud storage cp gs://cloud-samples-data/documentai/codelabs/ocr/Winnie_the_Pooh_3_Pages.pdf .
タスク 5. オンライン処理をリクエストする
このステップでは、オンライン処理(同期)API を使用して、小説の最初の 3 ページを処理します。この方法は、ローカルに保存された小さいドキュメントに最適です。各プロセッサ タイプで処理できる最大ページ数とファイル サイズについては、プロセッサの詳細リスト をご覧ください。
Cloud Shell で online_processing.py という名前のファイルを作成し、次のコードを貼り付けます。
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # 形式は 'us' または 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Cloud コンソールでプロセッサを作成します
# 現在の作業ディレクトリにあるローカル ファイル
FILE_PATH = "Winnie_the_Pooh_3_Pages.pdf"
# サポートされているファイル形式については、
# https://cloud.google.com/document-ai/docs/file-types を参照してください
MIME_TYPE = "application/pdf"
# クライアントをインスタンス化します
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# プロセッサの完全なリソース名(例):
# projects/project-id/locations/location/processor/processor-id
# 事前に Cloud コンソールでプロセッサを作成する必要があります
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# ファイルをメモリに読み込みます
with open(FILE_PATH, "rb") as image:
image_content = image.read()
# バイナリデータを Document AI の RawDocument オブジェクトに読み込みます
raw_document = documentai.RawDocument(content=image_content, mime_type=MIME_TYPE)
# 処理リクエストの設定を行います
request = documentai.ProcessRequest(name=RESOURCE_NAME, raw_document=raw_document)
# Document AI クライアントを使用してサンプル フォームを処理します
result = docai_client.process_document(request=request)
document_object = result.document
print("Document processing complete.")
print(f"Text: {document_object.text}")
YOUR_PROJECT_ID、YOUR_PROJECT_LOCATION、YOUR_PROCESSOR_ID、FILE_PATH は環境に合わせて適切な値に置き換えます。
注: FILE_PATH は、前の手順で Cloud Shell にアップロードしたファイルの名前です。ファイル名を変更していない場合は、デフォルト値の Winnie_the_Pooh_3_Pages.pdf になります。この値は変更する必要はありません。
コードを実行します。テキストが抽出され、コンソールに表示されます。
python3 online_processing.py
次の出力が表示されます。
Document processing complete.
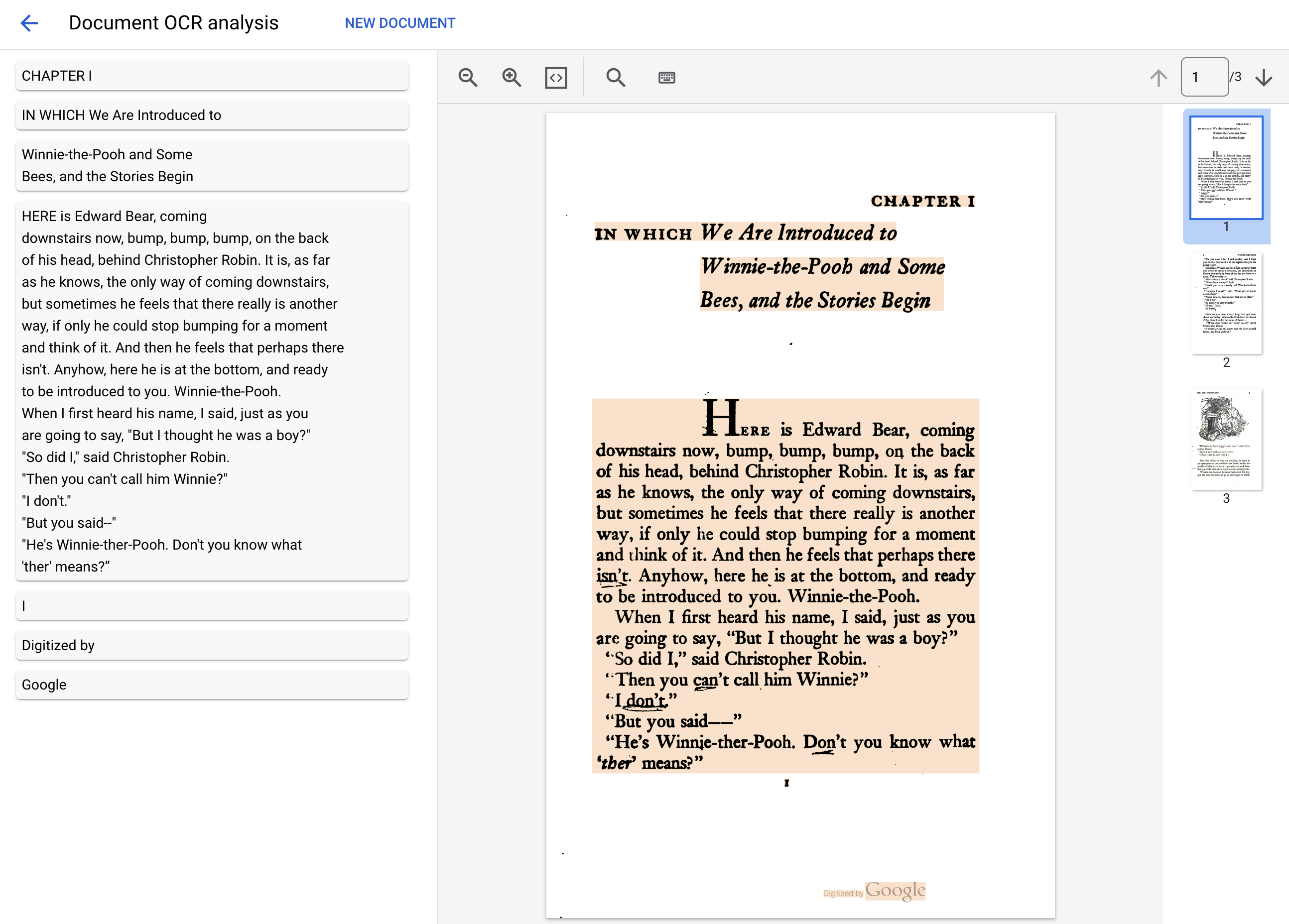
Text: IN WHICH We Are Introduced to
CHAPTER I
Winnie-the-Pooh and Some
Bees, and the Stories Begin
HERE is Edward Bear, coming
downstairs now, bump, bump, bump, on the back
of his head, behind Christopher Robin. It is, as far
as he knows, the only way of coming downstairs,
but sometimes he feels that there really is another
way, if only he could stop bumping for a moment
and think of it. And then he feels that perhaps there
isn't. Anyhow, here he is at the bottom, and ready
to be introduced to you. Winnie-the-Pooh.
When I first heard his name, I said, just as you
are going to say, "But I thought he was a boy?"
"So did I," said Christopher Robin.
"Then you can't call him Winnie?"
"I don't."
"But you said--"
...
タスク 6. バッチ処理をリクエストする
小説全体のテキストを処理したい場合はどうしたらよいでしょう。
オンライン処理では、送信できるページ数とファイルサイズが制限されています。また、1 回の API 呼び出しで許可されるドキュメント ファイルは 1 つだけです。
バッチ処理では、サイズの大きいファイルや複数のファイルを非同期で処理できます。
このセクションでは、Document AI Batch Processing API を使用して『くまのプーさん』全体を処理し、テキストを Google Cloud Storage バケットに出力します。
バッチ処理では、長時間実行オペレーション を使用して、リクエストを非同期で管理します。このため、オンライン処理とはリクエストの送信方法と出力の取得方法が異なります。
ただし、どちらの場合でも出力は同じドキュメント
ここでは、特定のドキュメントを Document AI で処理する方法について説明します。後のセクションでは、ドキュメントを含むディレクトリ全体を処理する方法を紹介します。
Cloud Storage に PDF をアップロードする
batch_process_documents() メソッドは現在、Google Cloud Storage にあるファイルを入力として受け付けます。オブジェクト構造の詳細については、documentai_v1.types.BatchProcessRequest
次のコマンドを実行して、PDF ファイルを保存するための Google Cloud Storage バケットを作成し、PDF をそのバケットにアップロードします。
gcloud storage buckets create gs://$GOOGLE_CLOUD_PROJECT
gcloud storage cp gs://cloud-samples-data/documentai/codelabs/ocr/Winnie_the_Pooh.pdf gs://$GOOGLE_CLOUD_PROJECT/
batch_process_documents() メソッドの使用
batch_processing.py という名前のファイルを作成し、次のコードを貼り付けます。
import re
from typing import List
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
from google.cloud import storage
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # 形式は 'us' または 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Cloud コンソールでプロセッサを作成します
# 形式: 'gs://input_bucket/directory/file.pdf'
GCS_INPUT_URI = "gs://cloud-samples-data/documentai/codelabs/ocr/Winnie_the_Pooh.pdf"
INPUT_MIME_TYPE = "application/pdf"
# 形式: 'gs://output_bucket/directory'
GCS_OUTPUT_URI = "YOUR_OUTPUT_BUCKET_URI"
# クライアントをインスタンス化します
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# プロセッサの完全なリソース名(例):
# projects/project-id/locations/location/processor/processor-id
# 事前に Cloud コンソールでプロセッサを作成する必要があります
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# 入力ドキュメントの Cloud Storage URI
input_document = documentai.GcsDocument(
gcs_uri=GCS_INPUT_URI, mime_type=INPUT_MIME_TYPE
)
# GCS の入力 URI をドキュメント ファイルのリストに読み込みます
input_config = documentai.BatchDocumentsInputConfig(
gcs_documents=documentai.GcsDocuments(documents=[input_document])
)
# 出力ディレクトリの Cloud Storage URI
gcs_output_config = documentai.DocumentOutputConfig.GcsOutputConfig(
gcs_uri=GCS_OUTPUT_URI
)
# GCS の出力 URI を OutputConfig オブジェクトに読み込みます
output_config = documentai.DocumentOutputConfig(gcs_output_config=gcs_output_config)
# 処理リクエストの設定を行います
request = documentai.BatchProcessRequest(
name=RESOURCE_NAME,
input_documents=input_config,
document_output_config=output_config,
)
# バッチ処理は長時間実行オペレーション(LRO)を返します
operation = docai_client.batch_process_documents(request)
# 完了するまでオペレーションをポーリングします。
# ファイルが大きい場合は時間がかかることがあります
# 形式: projects/PROJECT_NUMBER/locations/LOCATION/operations/OPERATION_ID
print(f"Waiting for operation {operation.operation.name} to complete...")
operation.result()
# 注: コールバックを使用して非同期処理を行うこともできます
#
# def my_callback(future):
# result = future.result()
#
# operation.add_done_callback(my_callback)
print("Document processing complete.")
# オペレーションが完了したら、
# オペレーション メタデータから出力ドキュメント情報を取得します
metadata = documentai.BatchProcessMetadata(operation.metadata)
if metadata.state != documentai.BatchProcessMetadata.State.SUCCEEDED:
raise ValueError(f"Batch Process Failed: {metadata.state_message}")
documents: List[documentai.Document] = []
# GCS から出力ファイルを取得するためのストレージ クライアント
storage_client = storage.Client()
# 入力ドキュメントごとに 1 つのプロセス
for process in metadata.individual_process_statuses:
# output_gcs_destination の形式: gs://BUCKET/PREFIX/OPERATION_NUMBER/0
# GCS API では、バケット名と URI の接頭辞を個別に指定する必要があります
output_bucket, output_prefix = re.match(
r"gs://(.*?)/(.*)", process.output_gcs_destination
).groups()
# 出力バケットから Document オブジェクトの一覧を取得します
output_blobs = storage_client.list_blobs(output_bucket, prefix=output_prefix)
# DocAI はソースファイルごとに複数の JSON ファイルを出力する場合があります
for blob in output_blobs:
# Document AI は JSON ファイルのみを GCS に出力します
if ".json" not in blob.name:
print(f"Skipping non-supported file type {blob.name}")
continue
print(f"Fetching {blob.name}")
# JSON ファイルをダウンロードし、Document オブジェクトに変換します
document = documentai.Document.from_json(
blob.download_as_bytes(), ignore_unknown_fields=True
)
documents.append(document)
# すべてのドキュメントのテキストを出力します
# 簡潔にするため 100 文字に切り詰めています
for document in documents:
print(document.text[:100])
YOUR_PROJECT_ID、YOUR_PROJECT_LOCATION、YOUR_PROCESSOR_ID、GCS_INPUT_URI、GCS_OUTPUT_URI は環境に合わせて適切な値に置き換えます。
GCS_INPUT_URI には、前の手順でバケットにアップロードしたファイルの URI(gs://)を使用します。
GCS_OUTPUT_URI には、前の手順で作成したバケットの URI(gs://)を使用します。
コードを実行します。小説全体のテキストが抽出され、コンソールに出力されます。
python3 batch_processing.py
注: 前のサンプル ファイルよりもはるかに大きいので、処理に時間がかかる可能性がありますが、Batch Processing API ではオペレーション ID が返されます。そのため、タスクの完了後にこの ID を使用して Cloud Storage から出力を取得できます。
出力は次のようになります。
Document processing complete.
Fetching 16218185426403815298/0/Winnie_the_Pooh-0.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-1.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-10.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-11.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-12.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-13.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-14.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-15.json
..
This is a reproduction of a library book that was digitized
by Google as part of an ongoing effort t
0
TAM MTAA
Digitized by
Google
Introduction
(I₂
F YOU happen to have read another
book about Christo
84
Eeyore took down his right hoof from his right
ear, turned round, and with great difficulty put u
94
..
これで、Document AI Batch Processing API を使用して PDF ファイルからテキストを抽出できました。
[進行状況を確認 ] をクリックして、目標に沿って進んでいることを確認します。
バッチ処理をリクエストする
タスク 7. ディレクトリに対するバッチ処理をリクエストする
ドキュメントを個別に処理するのではなく、ドキュメントのディレクトリ全体をまとめて処理したい場合もあります。batch_process_documents() メソッドは、ドキュメントのリストだけでなく、ディレクトリ パスにも対応しています。
このセクションでは、ドキュメント ファイルが格納されたディレクトリ全体を処理する方法を学びます。コードのほとんどの部分は前のステップと同じです。違うのは BatchProcessRequest.で GCS URI を送信している点です。
次のコマンドを実行し、サンプル ディレクトリ(小説の複数ページが個別のファイルとして含まれている)を Cloud Storage バケットにコピーします。
gsutil -m cp -r gs://cloud-samples-data/documentai/codelabs/ocr/multi-document/* gs://$GOOGLE_CLOUD_PROJECT/multi-document/
これらのファイルを直接読み込むことも、Cloud Storage バケットにコピーすることもできます。
batch_processing_directory.py という名前のファイルを作成し、次のコードを貼り付けます。
import re
from typing import List
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
from google.cloud import storage
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # 形式は 'us' または 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Cloud コンソールでプロセッサを作成します
# 形式: 'gs://input_bucket/directory'
GCS_INPUT_PREFIX = "gs://cloud-samples-data/documentai/codelabs/ocr/multi-document"
# 形式: 'gs://output_bucket/directory'
GCS_OUTPUT_URI = "YOUR_OUTPUT_BUCKET_URI"
# クライアントをインスタンス化します
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# プロセッサの完全なリソース名(例):
# projects/project-id/locations/location/processor/processor-id
# 事前に Cloud コンソールでプロセッサを作成する必要があります
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# 入力ディレクトリの Cloud Storage URI
gcs_prefix = documentai.GcsPrefix(gcs_uri_prefix=GCS_INPUT_PREFIX)
# GCS の入力 URI をバッチ入力構成に読み込みます
input_config = documentai.BatchDocumentsInputConfig(gcs_prefix=gcs_prefix)
# 出力ディレクトリの Cloud Storage URI
gcs_output_config = documentai.DocumentOutputConfig.GcsOutputConfig(
gcs_uri=GCS_OUTPUT_URI
)
# GCS の出力 URI を OutputConfig オブジェクトに読み込みます
output_config = documentai.DocumentOutputConfig(gcs_output_config=gcs_output_config)
# 処理リクエストの設定を行います
request = documentai.BatchProcessRequest(
name=RESOURCE_NAME,
input_documents=input_config,
document_output_config=output_config,
)
# バッチ処理は長時間実行オペレーション(LRO)を返します
operation = docai_client.batch_process_documents(request)
# 完了するまでオペレーションをポーリングします。
# ファイルが大きい場合は時間がかかることがあります
# 形式: projects/PROJECT_NUMBER/locations/LOCATION/operations/OPERATION_ID
print(f"Waiting for operation {operation.operation.name} to complete...")
operation.result()
# 注: コールバックを使用して非同期処理を行うこともできます
#
# def my_callback(future):
# result = future.result()
#
# operation.add_done_callback(my_callback)
print("Document processing complete.")
# オペレーションが完了したら、
# オペレーション メタデータから出力ドキュメント情報を取得します
metadata = documentai.BatchProcessMetadata(operation.metadata)
if metadata.state != documentai.BatchProcessMetadata.State.SUCCEEDED:
raise ValueError(f"Batch Process Failed: {metadata.state_message}")
documents: List[documentai.Document] = []
# GCS から出力ファイルを取得するためのストレージ クライアント
storage_client = storage.Client()
# 入力ドキュメントごとに 1 つのプロセス
for process in metadata.individual_process_statuses:
# output_gcs_destination の形式: gs://BUCKET/PREFIX/OPERATION_NUMBER/0
# GCS API では、バケット名と URI の接頭辞を個別に指定する必要があります
output_bucket, output_prefix = re.match(
r"gs://(.*?)/(.*)", process.output_gcs_destination
).groups()
# 出力バケットから Document オブジェクトの一覧を取得します
output_blobs = storage_client.list_blobs(output_bucket, prefix=output_prefix)
# DocAI はソースファイルごとに複数の JSON ファイルを出力する場合があります
for blob in output_blobs:
# Document AI は JSON ファイルのみを GCS に出力します
if ".json" not in blob.name:
print(f"Skipping non-supported file type {blob.name}")
continue
print(f"Fetching {blob.name}")
# JSON ファイルをダウンロードし、Document オブジェクトに変換します
document = documentai.Document.from_json(
blob.download_as_bytes(), ignore_unknown_fields=True
)
documents.append(document)
# すべてのドキュメントのテキストを出力します
# 簡潔にするため 100 文字に切り詰めています
for document in documents:
print(document.text[:100])
PROJECT_ID、LOCATION、PROCESSOR_ID、GCS_INPUT_PREFIX、GCS_OUTPUT_URI は環境に合わせて適切な値に置き換えます。
GCS_INPUT_PREFIX には、前のセクションでバケットにアップロードしたディレクトリ の URI(gs://)を使用します。
GCS_OUTPUT_URI には、前のセクションで作成したバケットの URI(gs://)を使用します。
次のコマンドを使用してコードを実行すると、Cloud Storage 内の指定したディレクトリにあるすべてのドキュメント ファイルから抽出されたテキストが表示されます。
python3 batch_processing_directory.py
出力は次のようになります。
Document processing complete.
Fetching 16354972755137859334/0/Winnie_the_Pooh_Page_0-0.json
Fetching 16354972755137859334/1/Winnie_the_Pooh_Page_1-0.json
Fetching 16354972755137859334/2/Winnie_the_Pooh_Page_10-0.json
..
Introduction
(I₂
F YOU happen to have read another
book about Christopher Robin, you may remember
th
IN WHICH We Are Introduced to
CHAPTER I
Winnie-the-Pooh and Some
Bees, and the Stories Begin
HERE is
..
これで、Document AI の Python クライアント ライブラリを使用して、Document AI プロセッサでディレクトリ内のドキュメントを処理し、その結果を Cloud Storage に出力することに成功しました。
[進行状況を確認 ] をクリックして、目標に沿って進んでいることを確認します。
ディレクトリに対するバッチ処理をリクエストする
お疲れさまでした
これで完了です。このラボでは、Document AI の Python クライアント ライブラリを使用して、Document AI プロセッサでドキュメント ディレクトリを処理し、その結果を Cloud Storage に出力する方法を学びました。また、サービス アカウント キー ファイルを使用して API リクエストを認証する方法、Document AI の Python クライアント ライブラリをインストールする方法、オンライン(同期)API とバッチ(非同期)API を使用してリクエストを処理する方法についても学習しました。
次のステップと詳細情報
Document AI と Python クライアント ライブラリの詳細については、以下のリソースをご覧ください。
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラス では、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格 を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2024 年 6 月 13 日
ラボの最終テスト日: 2024 年 6 月 13 日
Copyright 2026 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。