Vertex AI is now Gemini Enterprise Agent Platform! We are currently updating our content to reflect this change. Please bear with us if you encounter naming inconsistencies during this transition.
Mettez en pratique vos compétences dans la console Google Cloud
Points de contrôle
Enable the Document AI API
Vérifier ma progression
/ 10
Create a processor
Vérifier ma progression
/ 20
Authenticate API requests
Vérifier ma progression
/ 30
Make a batch processing request
Vérifier ma progression
/ 20
Make a batch processing request for a directory
Vérifier ma progression
/ 20
Instructions et exigences de configuration de l'atelier
Protégez votre compte et votre progression. Utilisez toujours une fenêtre de navigation privée et les identifiants de l'atelier pour exécuter cet atelier.
Reconnaissance optique des caractères (OCR) avec Document AI et Python
Ce contenu n'est pas encore optimisé pour les appareils mobiles.
Pour une expérience optimale, veuillez accéder à notre site sur un ordinateur de bureau en utilisant un lien envoyé par e-mail.
GSP1138
Présentation
Document AI est une solution de reconnaissance de documents qui exploite des données non structurées (par exemple, des documents, des e-mails, des factures, des formulaires, etc.) et en facilite la compréhension, l'analyse et l'utilisation. L'API fournit une structure via la classification de contenu, l'extraction d'entités, la recherche avancée, etc.
Dans cet atelier, vous allez effectuer une reconnaissance optique des caractères (OCR) pour des documents PDF à l'aide de Document AI et Python. Vous apprendrez à envoyer des requêtes de traitement en ligne (synchrones) et par lot (asynchrones).
Nous allons utiliser un fichier PDF du roman classique "Winnie l'ourson" d'Alan Alexander Milne, qui est récemment entré dans le domaine public aux États-Unis. Ce fichier a été scanné et numérisé par Google Livres.
Objectifs
Dans cet atelier, vous apprendrez à effectuer les tâches suivantes :
Activer l'API Document AI
Authentifier les requêtes API
Installer la bibliothèque cliente pour Python
Utiliser les API de traitement en ligne et par lot
Analyser le texte d'un fichier PDF
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Des identifiants temporaires vous sont fournis pour vous permettre de vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
Vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome).
Remarque : Ouvrez une fenêtre de navigateur en mode incognito (recommandé) ou de navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Vous disposez d'un temps limité. N'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Utilisez uniquement le compte de participant pour cet atelier. Si vous utilisez un autre compte Google Cloud, des frais peuvent être facturés à ce compte.
Démarrer l'atelier et se connecter à la console Google Cloud
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, une boîte de dialogue s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous trouverez le panneau "Détails concernant l'atelier", qui contient les éléments suivants :
Le bouton "Ouvrir la console Google Cloud"
Le temps restant
Les identifiants temporaires que vous devez utiliser pour cet atelier
Des informations complémentaires vous permettant d'effectuer l'atelier
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page "Se connecter" dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}}
Vous trouverez également le nom d'utilisateur dans le panneau "Détails concernant l'atelier".
Cliquez sur Suivant.
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}}
Vous trouverez également le mot de passe dans le panneau "Détails concernant l'atelier".
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. Ne saisissez pas ceux de votre compte Google Cloud.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés.
Accédez aux pages suivantes :
Acceptez les conditions d'utilisation.
N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
Ne vous inscrivez pas à des essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Pour accéder aux produits et services Google Cloud, cliquez sur le menu de navigation ou saisissez le nom du service ou du produit dans le champ Recherche.
Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud.
Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.
Passez les fenêtres suivantes :
Accédez à la fenêtre d'informations de Cloud Shell.
Autorisez Cloud Shell à utiliser vos identifiants pour effectuer des appels d'API Google Cloud.
Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET : . Le résultat contient une ligne qui déclare l'ID_PROJET pour cette session :
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
(Facultatif) Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
gcloud auth list
Cliquez sur Autoriser.
Résultat :
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
(Facultatif) Vous pouvez lister les ID de projet à l'aide de cette commande :
gcloud config list project
Résultat :
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Remarque : Pour consulter la documentation complète sur gcloud, dans Google Cloud, accédez au guide de présentation de la gcloud CLI.
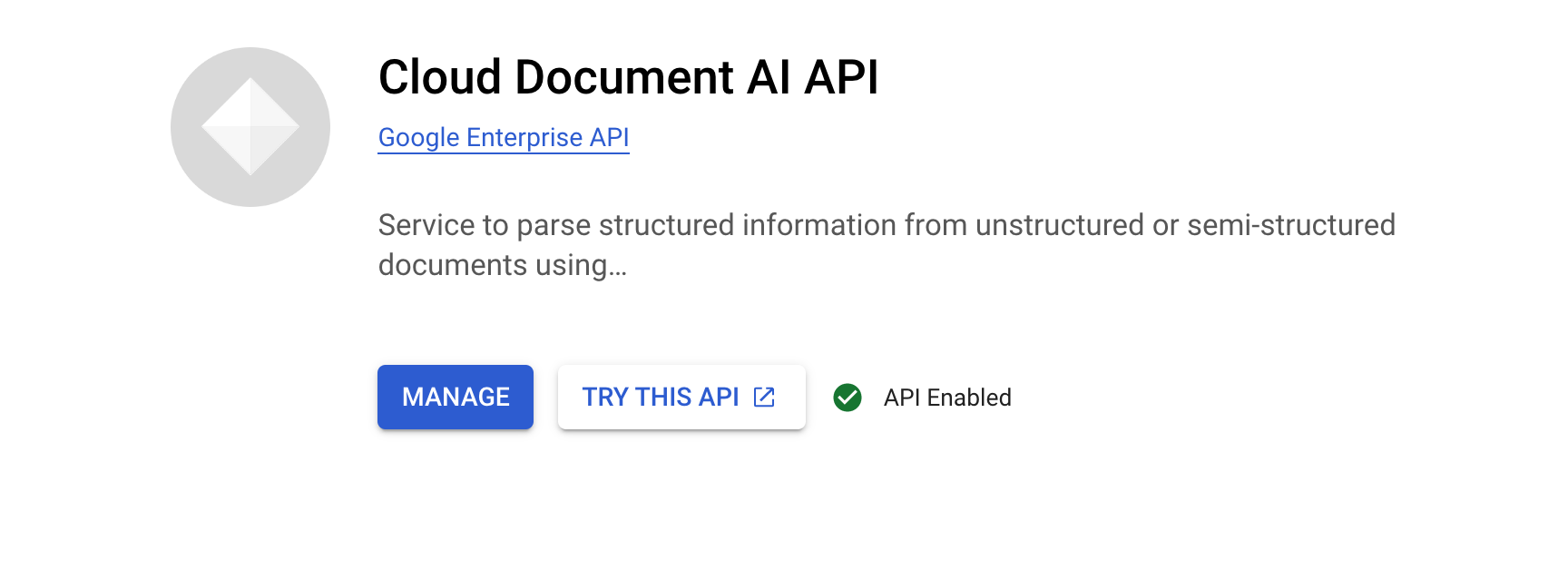
Tâche 1 : Activer l'API Document AI
Avant de pouvoir utiliser Document AI, vous devez activer l'API.
Dans la barre de recherche située en haut de la console, recherchez l'API Document AI, puis cliquez sur Activer pour utiliser l'API dans votre projet Google Cloud.
Utilisez la barre de recherche pour rechercher l'API Cloud Storage. Si elle n'est pas déjà activée, cliquez sur Activer.
Vous pouvez également activer les API à l'aide des commandes gcloud suivantes.
L'écran qui s'affiche devrait ressembler à ce qui suit :
Operation "operations/..." finished successfully.
Vous pouvez maintenant utiliser Document AI.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Activer l'API Document AI
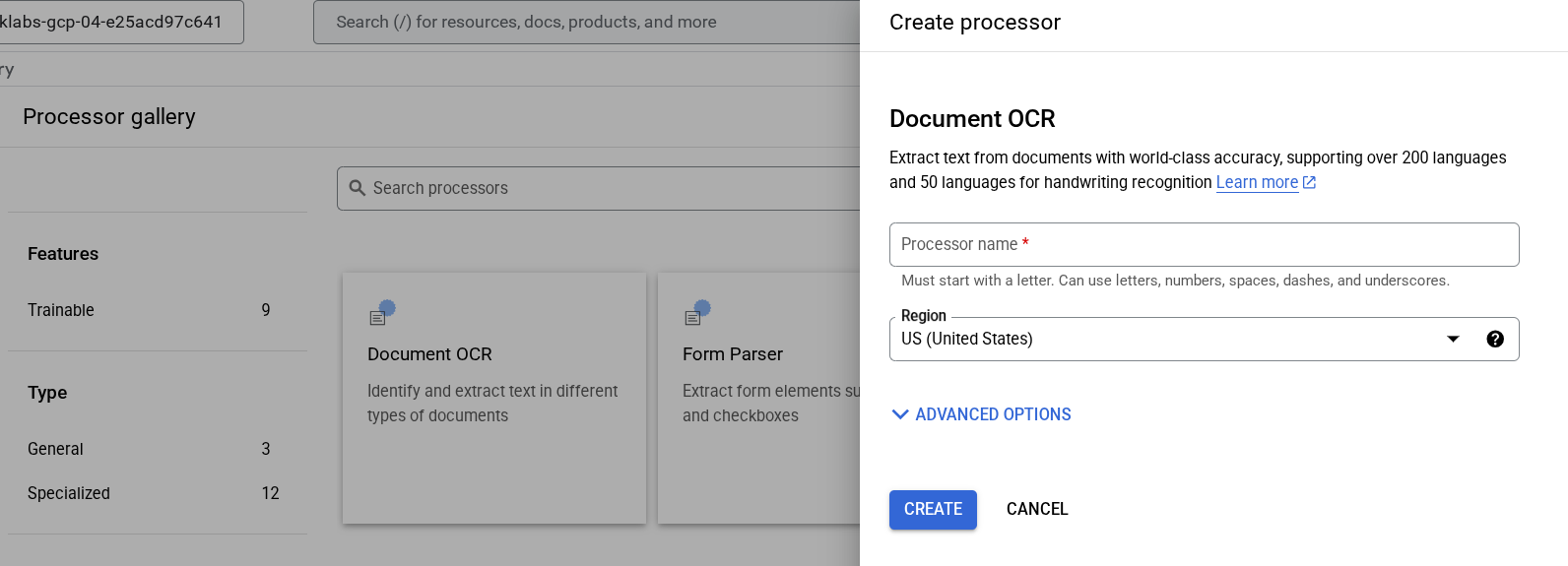
Tâche 2 : Créer et tester un processeur
Vous devez d'abord créer une instance du processeur de reconnaissance optique des caractères dans les documents qui exécutera l'extraction. Pour ce faire, utilisez la console Cloud ou l'API de gestion des processeurs.
Dans le menu de navigation, cliquez sur Afficher tous les produits. Sous Intelligence artificielle, sélectionnez Document AI.
Cliquez sur Explorer les processeurs, puis sur OCR dans les documents.
Nommez-le lab-ocr, puis sélectionnez la région la plus proche dans la liste.
Cliquez sur Créer pour créer le processeur.
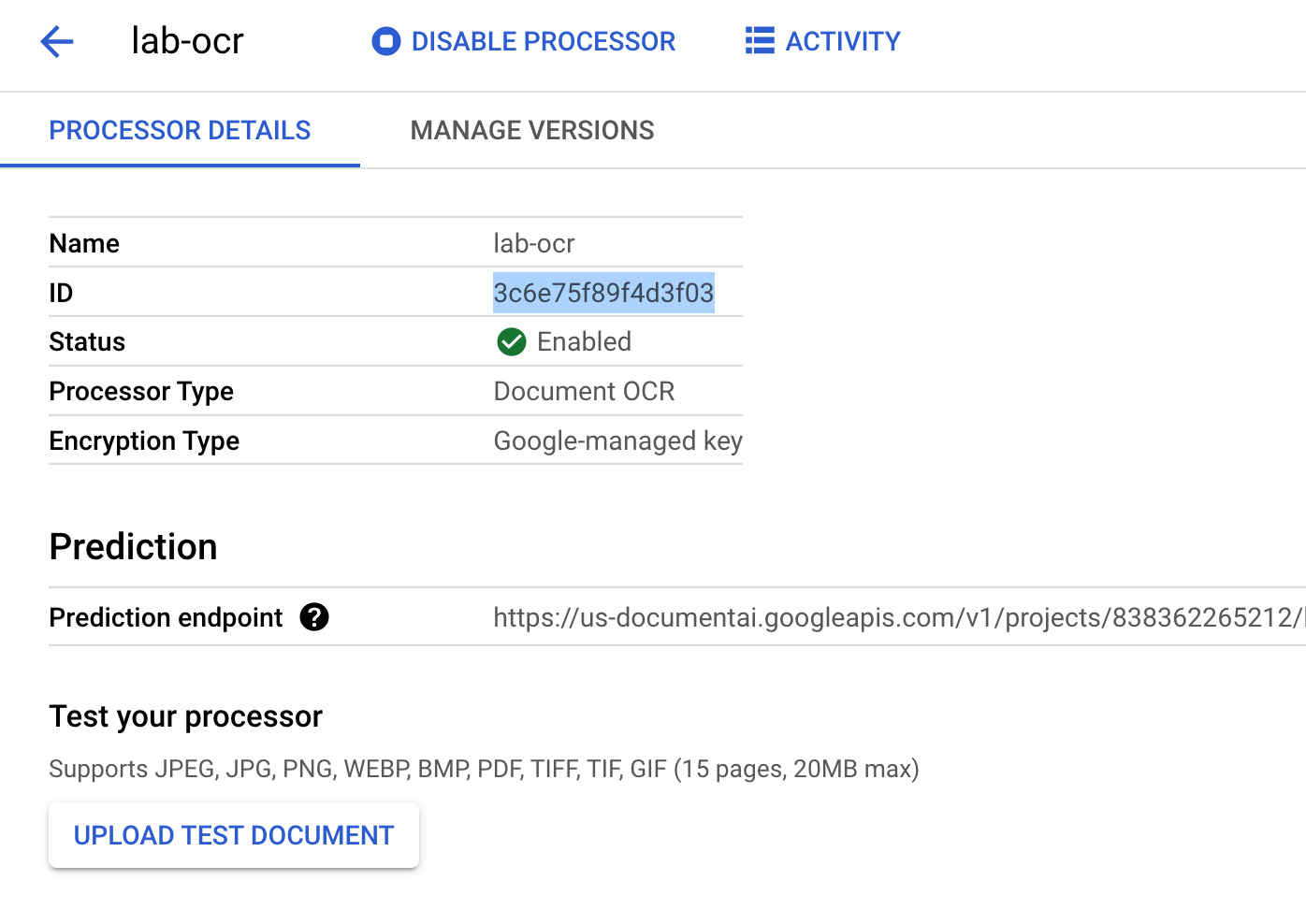
Copiez l'ID de votre processeur. Vous devrez l'utiliser ultérieurement dans votre code.
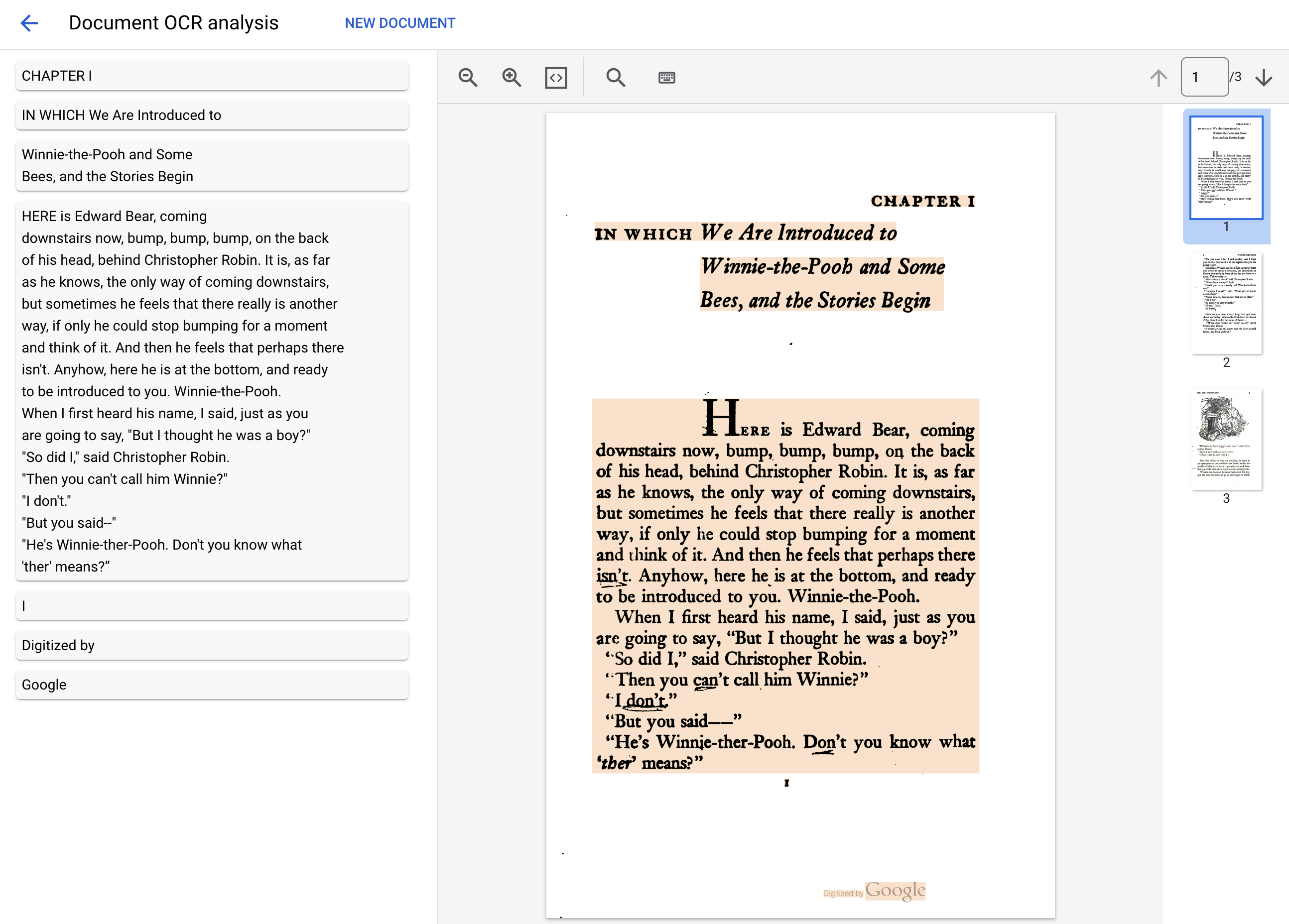
Téléchargez le fichier PDF ci-dessous, qui contient les trois premières pages du roman "Winnie l'ourson" d'Alan Alexander Milne.
Vous pouvez maintenant tester votre processeur dans la console en important un document.
Cliquez sur Importer un document de test, puis sélectionnez le fichier PDF que vous avez téléchargé.
Votre résultat doit se présenter comme suit :
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer et tester un processeur
Tâche 3 : Authentifier les requêtes API
Pour envoyer des requêtes à l'API Document AI, vous devez utiliser un compte de service. Ce compte de service appartient à votre projet. Il permet à la bibliothèque cliente Python d'envoyer des requêtes API. Comme tout autre compte utilisateur, un compte de service est représenté par une adresse e-mail. Dans cette section, vous allez utiliser le Cloud SDK pour créer un compte de service, puis créer les identifiants nécessaires pour vous authentifier en tant que compte de service.
Commencez par ouvrir une nouvelle fenêtre Cloud Shell, puis définissez une variable d'environnement avec l'ID de votre projet en exécutant la commande suivante :
Créez des identifiants permettant à votre code Python de se connecter avec ce nouveau compte de service, et enregistrez-les dans un fichier JSON ~/key.json à l'aide de la commande suivante :
gcloud iam service-accounts keys create ~/key.json \
--iam-account my-docai-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Enfin, définissez la variable d'environnement GOOGLE_APPLICATION_CREDENTIALS, qui permet à la bibliothèque de rechercher vos identifiants. La variable d'environnement doit être définie sur le chemin d'accès complet au fichier JSON d'identifiants que vous avez créé, à l'aide de la commande suivante :
Tâche 5 : Envoyer une requête de traitement en ligne
Au cours de cette étape, vous allez traiter les trois premières pages du roman en utilisant l'API (synchrone) de traitement en ligne. Cette méthode est particulièrement adaptée au documents peu volumineux stockés localement. Consultez la liste complète des processeurs pour voir le nombre de pages et la taille de fichier à ne pas dépasser pour chaque type de processeur.
Dans Cloud Shell, créez un fichier nommé online_processing.py et collez-y le code suivant :
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "Winnie_the_Pooh_3_Pages.pdf"
# Refer to https://cloud.google.com/document-ai/docs/file-types
# for supported file types
MIME_TYPE = "application/pdf"
# Instantiates a client
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# Read the file into memory
with open(FILE_PATH, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=image_content, mime_type=MIME_TYPE)
# Configure the process request
request = documentai.ProcessRequest(name=RESOURCE_NAME, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = docai_client.process_document(request=request)
document_object = result.document
print("Document processing complete.")
print(f"Text: {document_object.text}")
Remplacez YOUR_PROJECT_ID, YOUR_PROJECT_LOCATION, YOUR_PROCESSOR_ID et FILE_PATH par les valeurs appropriées pour votre environnement.
Remarque : FILE_PATH est le nom du fichier que vous avez importé dans Cloud Shell à l'étape précédente. Si vous n'avez pas renommé le fichier, il devrait s'appeler Winnie_the_Pooh_3_Pages.pdf. Il s'agit de la valeur par défaut, et vous n'avez pas besoin de la modifier.
Exécutez le code, qui permet d'extraire le texte et de l'imprimer dans la console.
python3 online_processing.py
Vous devriez obtenir le résultat suivant :
Document processing complete.
Text: IN WHICH We Are Introduced to
CHAPTER I
Winnie-the-Pooh and Some
Bees, and the Stories Begin
HERE is Edward Bear, coming
downstairs now, bump, bump, bump, on the back
of his head, behind Christopher Robin. It is, as far
as he knows, the only way of coming downstairs,
but sometimes he feels that there really is another
way, if only he could stop bumping for a moment
and think of it. And then he feels that perhaps there
isn't. Anyhow, here he is at the bottom, and ready
to be introduced to you. Winnie-the-Pooh.
When I first heard his name, I said, just as you
are going to say, "But I thought he was a boy?"
"So did I," said Christopher Robin.
"Then you can't call him Winnie?"
"I don't."
"But you said--"
...
Tâche 6 : Envoyer une requête de traitement par lot
Supposons maintenant que vous souhaitiez lire le texte du roman dans son intégralité.
Le traitement en ligne limite le nombre de pages et la taille des fichiers pouvant être envoyées. En outre, elle ne permet d'utiliser qu'un fichier de document par appel d'API.
Le traitement par lot prend en charge des fichiers plus volumineux et en plus grand nombre grâce à une méthode asynchrone.
Dans cette section, nous allons traiter l'intégralité du roman "Winnie l'ourson" avec l'API de traitement par lot Document AI et générer le texte dans un bucket Google Cloud Storage.
Le traitement par lot utilise des opérations de longue durée pour gérer les requêtes de manière asynchrone. Nous devons donc envoyer la requête et récupérer la sortie différemment qu'avec le traitement en ligne.
Cependant, la sortie aura le même format d'objet Document, que nous utilisions le traitement en ligne ou par lot.
Cette section explique comment fournir des documents spécifiques à Document AI pour qu'il les traite. Une section ultérieure indiquera comment traiter l'intégralité d'un répertoire de documents.
Importer un PDF dans Cloud Storage
La méthode batch_process_documents() accepte actuellement les fichiers provenant de Google Cloud Storage. Pour en savoir plus sur la structure des objets, consultez la section documentai_v1.types.BatchProcessRequest.
Exécutez la commande suivante pour créer un bucket Google Cloud Storage afin d'y stocker le fichier PDF, puis importez le fichier dans ce bucket. :
Créez un fichier nommé batch_processing.py et collez-y le code suivant :
import re
from typing import List
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
from google.cloud import storage
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Create processor in Cloud Console
# Format 'gs://input_bucket/directory/file.pdf'
GCS_INPUT_URI = "gs://cloud-samples-data/documentai/codelabs/ocr/Winnie_the_Pooh.pdf"
INPUT_MIME_TYPE = "application/pdf"
# Format 'gs://output_bucket/directory'
GCS_OUTPUT_URI = "YOUR_OUTPUT_BUCKET_URI"
# Instantiates a client
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# Cloud Storage URI for the Input Document
input_document = documentai.GcsDocument(
gcs_uri=GCS_INPUT_URI, mime_type=INPUT_MIME_TYPE
)
# Load GCS Input URI into a List of document files
input_config = documentai.BatchDocumentsInputConfig(
gcs_documents=documentai.GcsDocuments(documents=[input_document])
)
# Cloud Storage URI for Output directory
gcs_output_config = documentai.DocumentOutputConfig.GcsOutputConfig(
gcs_uri=GCS_OUTPUT_URI
)
# Load GCS Output URI into OutputConfig object
output_config = documentai.DocumentOutputConfig(gcs_output_config=gcs_output_config)
# Configure Process Request
request = documentai.BatchProcessRequest(
name=RESOURCE_NAME,
input_documents=input_config,
document_output_config=output_config,
)
# Batch Process returns a Long Running Operation (LRO)
operation = docai_client.batch_process_documents(request)
# Continually polls the operation until it is complete.
# This could take some time for larger files
# Format: projects/PROJECT_NUMBER/locations/LOCATION/operations/OPERATION_ID
print(f"Waiting for operation {operation.operation.name} to complete...")
operation.result()
# NOTE: Can also use callbacks for asynchronous processing
#
# def my_callback(future):
# result = future.result()
#
# operation.add_done_callback(my_callback)
print("Document processing complete.")
# Once the operation is complete,
# get output document information from operation metadata
metadata = documentai.BatchProcessMetadata(operation.metadata)
if metadata.state != documentai.BatchProcessMetadata.State.SUCCEEDED:
raise ValueError(f"Batch Process Failed: {metadata.state_message}")
documents: List[documentai.Document] = []
# Storage Client to retrieve the output files from GCS
storage_client = storage.Client()
# One process per Input Document
for process in metadata.individual_process_statuses:
# output_gcs_destination format: gs://BUCKET/PREFIX/OPERATION_NUMBER/0
# The GCS API requires the bucket name and URI prefix separately
output_bucket, output_prefix = re.match(
r"gs://(.*?)/(.*)", process.output_gcs_destination
).groups()
# Get List of Document Objects from the Output Bucket
output_blobs = storage_client.list_blobs(output_bucket, prefix=output_prefix)
# DocAI may output multiple JSON files per source file
for blob in output_blobs:
# Document AI should only output JSON files to GCS
if ".json" not in blob.name:
print(f"Skipping non-supported file type {blob.name}")
continue
print(f"Fetching {blob.name}")
# Download JSON File and Convert to Document Object
document = documentai.Document.from_json(
blob.download_as_bytes(), ignore_unknown_fields=True
)
documents.append(document)
# Print Text from all documents
# Truncated at 100 characters for brevity
for document in documents:
print(document.text[:100])
Remplacez YOUR_PROJECT_ID, YOUR_PROJECT_LOCATION, YOUR_PROCESSOR_ID, GCS_INPUT_URI et GCS_OUTPUT_URI par les valeurs appropriées pour votre environnement.
Pour GCS_INPUT_URI, utilisez l'URI du fichier que vous avez importé dans votre bucket à l'étape précédente, c'est-à-dire gs:///Winnie_the_Pooh.pdf.
Pour GCS_OUTPUT_URI, utilisez l'URI du bucket que vous avez créé à l'étape précédente, c'est-à-dire gs://.
Exécutez le code. Vous devriez obtenir le texte complet du roman, extrait et imprimé dans votre console.
python3 batch_processing.py
Remarque : Cette opération peut prendre un certain temps, car le fichier est beaucoup plus volumineux que l'exemple précédent. Toutefois, avec l'API de traitement par lot, vous recevrez un ID d'opération que vous pourrez utiliser pour obtenir la sortie de Cloud Storage une fois la tâche terminée.
Votre résultat doit se présenter comme suit :
Document processing complete.
Fetching 16218185426403815298/0/Winnie_the_Pooh-0.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-1.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-10.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-11.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-12.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-13.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-14.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-15.json
..
This is a reproduction of a library book that was digitized
by Google as part of an ongoing effort t
0
TAM MTAA
Digitized by
Google
Introduction
(I₂
F YOU happen to have read another
book about Christo
84
Eeyore took down his right hoof from his right
ear, turned round, and with great difficulty put u
94
..
Parfait ! Vous avez réussi à extraire du texte d'un fichier PDF à l'aide de l'API de traitement par lot Document AI.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Envoyer une requête de traitement par lot
Tâche 7 : Envoyer une requête de traitement par lot pour un répertoire
Dans certains cas, vous souhaiterez peut-être traiter l'intégralité d'un répertoire de documents, sans devoir indiquer chacun des documents. La méthode batch_process_documents() prend en charge l'entrée d'une liste de documents spécifiques ou d'un chemin d'accès au répertoire.
Dans cette section, vous allez apprendre à traiter l'intégralité d'un répertoire de fichiers. Le code est, en grande partie, le même que celui de l'étape précédente, à la différence de l'URI GCS envoyé avec BatchProcessRequest.
Exécutez la commande suivante pour copier l'exemple de répertoire (qui contient plusieurs pages du roman dans des fichiers distincts) dans votre bucket Cloud Storage.
Vous pouvez lire les fichiers directement ou les copier dans votre propre bucket Cloud Storage.
Créez un fichier nommé batch_processing_directory.py et collez-y le code suivant :
import re
from typing import List
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
from google.cloud import storage
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Create processor in Cloud Console
# Format 'gs://input_bucket/directory'
GCS_INPUT_PREFIX = "gs://cloud-samples-data/documentai/codelabs/ocr/multi-document"
# Format 'gs://output_bucket/directory'
GCS_OUTPUT_URI = "YOUR_OUTPUT_BUCKET_URI"
# Instantiates a client
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# Cloud Storage URI for the Input Directory
gcs_prefix = documentai.GcsPrefix(gcs_uri_prefix=GCS_INPUT_PREFIX)
# Load GCS Input URI into Batch Input Config
input_config = documentai.BatchDocumentsInputConfig(gcs_prefix=gcs_prefix)
# Cloud Storage URI for Output directory
gcs_output_config = documentai.DocumentOutputConfig.GcsOutputConfig(
gcs_uri=GCS_OUTPUT_URI
)
# Load GCS Output URI into OutputConfig object
output_config = documentai.DocumentOutputConfig(gcs_output_config=gcs_output_config)
# Configure Process Request
request = documentai.BatchProcessRequest(
name=RESOURCE_NAME,
input_documents=input_config,
document_output_config=output_config,
)
# Batch Process returns a Long Running Operation (LRO)
operation = docai_client.batch_process_documents(request)
# Continually polls the operation until it is complete.
# This could take some time for larger files
# Format: projects/PROJECT_NUMBER/locations/LOCATION/operations/OPERATION_ID
print(f"Waiting for operation {operation.operation.name} to complete...")
operation.result()
# NOTE: Can also use callbacks for asynchronous processing
#
# def my_callback(future):
# result = future.result()
#
# operation.add_done_callback(my_callback)
print("Document processing complete.")
# Once the operation is complete,
# get output document information from operation metadata
metadata = documentai.BatchProcessMetadata(operation.metadata)
if metadata.state != documentai.BatchProcessMetadata.State.SUCCEEDED:
raise ValueError(f"Batch Process Failed: {metadata.state_message}")
documents: List[documentai.Document] = []
# Storage Client to retrieve the output files from GCS
storage_client = storage.Client()
# One process per Input Document
for process in metadata.individual_process_statuses:
# output_gcs_destination format: gs://BUCKET/PREFIX/OPERATION_NUMBER/0
# The GCS API requires the bucket name and URI prefix separately
output_bucket, output_prefix = re.match(
r"gs://(.*?)/(.*)", process.output_gcs_destination
).groups()
# Get List of Document Objects from the Output Bucket
output_blobs = storage_client.list_blobs(output_bucket, prefix=output_prefix)
# DocAI may output multiple JSON files per source file
for blob in output_blobs:
# Document AI should only output JSON files to GCS
if ".json" not in blob.name:
print(f"Skipping non-supported file type {blob.name}")
continue
print(f"Fetching {blob.name}")
# Download JSON File and Convert to Document Object
document = documentai.Document.from_json(
blob.download_as_bytes(), ignore_unknown_fields=True
)
documents.append(document)
# Print Text from all documents
# Truncated at 100 characters for brevity
for document in documents:
print(document.text[:100])
Remplacez PROJECT_ID, LOCATION, PROCESSOR_ID, GCS_INPUT_PREFIX et GCS_OUTPUT_URI par les valeurs appropriées pour votre environnement.
Pour GCS_INPUT_PREFIX, utilisez l'URI du répertoire que vous avez importé dans votre bucket dans la section précédente, c'est-à-dire gs:///multi-document.
Pour GCS_OUTPUT_URI, utilisez l'URI du bucket que vous avez créé dans la section précédente, c'est-à-dire gs://.
Exécutez la commande suivante pour exécuter le code. Vous devriez obtenir le texte extrait de tous les fichiers dans le répertoire Cloud Storage.
python3 batch_processing_directory.py
Votre résultat doit se présenter comme suit :
Document processing complete.
Fetching 16354972755137859334/0/Winnie_the_Pooh_Page_0-0.json
Fetching 16354972755137859334/1/Winnie_the_Pooh_Page_1-0.json
Fetching 16354972755137859334/2/Winnie_the_Pooh_Page_10-0.json
..
Introduction
(I₂
F YOU happen to have read another
book about Christopher Robin, you may remember
th
IN WHICH We Are Introduced to
CHAPTER I
Winnie-the-Pooh and Some
Bees, and the Stories Begin
HERE is
..
Parfait ! Vous avez réussi à utiliser la bibliothèque cliente Python Document AI pour traiter un répertoire de documents à l'aide d'un processeur Document AI, et à générer les résultats dans Cloud Storage.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Envoyer une requête de traitement par lot pour un répertoire
Félicitations !
Félicitations ! Dans cet atelier, vous avez appris à utiliser la bibliothèque cliente Python Document AI pour traiter un répertoire de documents à l'aide d'un processeur Document AI, et à générer les résultats dans Cloud Storage. Vous avez également appris à authentifier les requêtes API à l'aide d'un fichier de clé de compte de service, à installer la bibliothèque cliente Python Document AI et à utiliser les API en ligne (synchrone) et par lot (asynchrone) pour traiter les requêtes.
Étapes suivantes et informations supplémentaires
Consultez les ressources suivantes pour en savoir plus sur Document AI et la bibliothèque cliente Python :
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 13 juin 2024
Dernier test de l'atelier : 13 juin 2024
Copyright 2026 Google LLC. Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Le meilleur moyen d'exécuter cet atelier consiste à utiliser une fenêtre de navigation privée. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Dans cet atelier, vous allez apprendre à effectuer une reconnaissance optique des caractères à l'aide de l'API Document AI avec Python.
Durée :
0 min de configuration
·
Accessible pendant 60 min
·
Terminé après 25 min



 en haut de la console Google Cloud.
en haut de la console Google Cloud.