Vertex AI is now Gemini Enterprise Agent Platform! We are currently updating our content to reflect this change. Please bear with us if you encounter naming inconsistencies during this transition.
Aplica tus habilidades en la consola de Google Cloud
Puntos de control
Enable the Document AI API
Revisar mi progreso
/ 10
Create a processor
Revisar mi progreso
/ 20
Authenticate API requests
Revisar mi progreso
/ 30
Make a batch processing request
Revisar mi progreso
/ 20
Make a batch processing request for a directory
Revisar mi progreso
/ 20
Instrucciones y requisitos de configuración del lab
Protege tu cuenta y tu progreso. Usa siempre una ventana de navegador privada y las credenciales del lab para ejecutarlo.
Reconocimiento óptico de caracteres (OCR) con Document AI (Python)
Este contenido aún no está optimizado para dispositivos móviles.
Para obtener la mejor experiencia, visítanos en una computadora de escritorio con un vínculo que te enviaremos por correo electrónico.
GSP1138
Descripción general
Document AI es una solución de comprensión de documentos que toma datos no estructurados, como documentos, correos electrónicos, facturas y formularios, entre otros, y facilita la comprensión, el análisis y el consumo de los datos. La API proporciona una estructura mediante la clasificación de contenido, la extracción de entidades, la búsqueda avanzada y mucho más.
En este lab, realizarás reconocimiento óptico de caracteres (OCR) en documentos PDF con Document AI y Python. Descubrirás cómo realizar solicitudes de procesamiento en línea (síncrono) y por lotes (asíncrono).
Utilizaremos un archivo PDF de la novela clásica “Winnie the Pooh” de A. A. Milne que, hace poco, se hizo parte del dominio público en Estados Unidos. Este archivo se escaneó y digitalizó con Google Libros.
Objetivos
En este lab, aprenderás a realizar las siguientes tareas:
Habilitar la API de Document AI
Autenticar solicitudes a la API
Instalar la biblioteca cliente de Python
Usar las APIs de procesamiento en línea y por lotes
Analizar texto de un archivo PDF
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs cuentan con un temporizador que no se puede pausar. El temporizador, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
Acceso a un navegador de Internet estándar. Se recomienda el navegador Chrome.
Nota: Usa una ventana del navegador privada o de incógnito (opción recomendada) para ejecutar el lab. Así evitarás conflictos entre tu cuenta personal y la cuenta de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
Tiempo para completar el lab (recuerda que, una vez que comienzas un lab, no puedes pausarlo).
Nota: Usa solo la cuenta de estudiante para este lab. Si usas otra cuenta de Google Cloud, es posible que se apliquen cargos a esa cuenta.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
Haz clic en el botón Comenzar lab. Si debes pagar por el lab, se abrirá un diálogo para que selecciones la forma de pago.
A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
El botón para abrir la consola de Google Cloud
El tiempo restante
Las credenciales temporales que debes usar para el lab
Otra información para completar el lab, si es necesaria
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordena las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta.
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}}
También puedes encontrar el nombre de usuario en el panel Detalles del lab.
Haz clic en Siguiente.
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}}
También puedes encontrar la contraseña en el panel Detalles del lab.
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud.
Nota: Usar tu propia cuenta de Google Cloud para este lab podría generar cargos adicionales.
Haz clic para avanzar por las páginas siguientes:
Acepta los Términos y Condiciones.
No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.
Nota: Para acceder a los productos y servicios de Google Cloud, haz clic en el menú de navegación o escribe el nombre del servicio o producto en el campo Buscar.
Activa Cloud Shell
Cloud Shell es una máquina virtual que cuenta con herramientas para desarrolladores. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a tus recursos de Google Cloud.
Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.
Haz clic para avanzar por las siguientes ventanas:
Continúa en la ventana de información de Cloud Shell.
Autoriza a Cloud Shell para que use tus credenciales para realizar llamadas a la API de Google Cloud.
Cuando te conectes, habrás completado la autenticación, y el proyecto estará configurado con tu Project_ID, . El resultado contiene una línea que declara el Project_ID para esta sesión:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud es la herramienta de línea de comandos de Google Cloud. Viene preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
Puedes solicitar el nombre de la cuenta activa con este comando (opcional):
gcloud auth list
Haz clic en Autorizar.
Resultado:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Puedes solicitar el ID del proyecto con este comando (opcional):
gcloud config list project
Resultado:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Nota: Para obtener toda la documentación de gcloud, en Google Cloud, consulta la guía con la descripción general de gcloud CLI.
Tarea 1: Habilita la API de Document AI
Antes de comenzar a usar Document AI, debes habilitar la API.
Usa la barra de búsqueda en la parte superior de la consola para buscar "Document AI API" y, luego, haz clic en Habilitar para usar la API en tu proyecto de Google Cloud.
Ingresa "Cloud Storage API" en la barra de búsqueda. Si aún no está habilitada, haz clic en Habilitar.
Como alternativa, las APIs se pueden habilitar con los siguientes comandos de gcloud.
Haz clic en Revisar mi progreso para verificar el objetivo.
Habilitar la API de Document AI
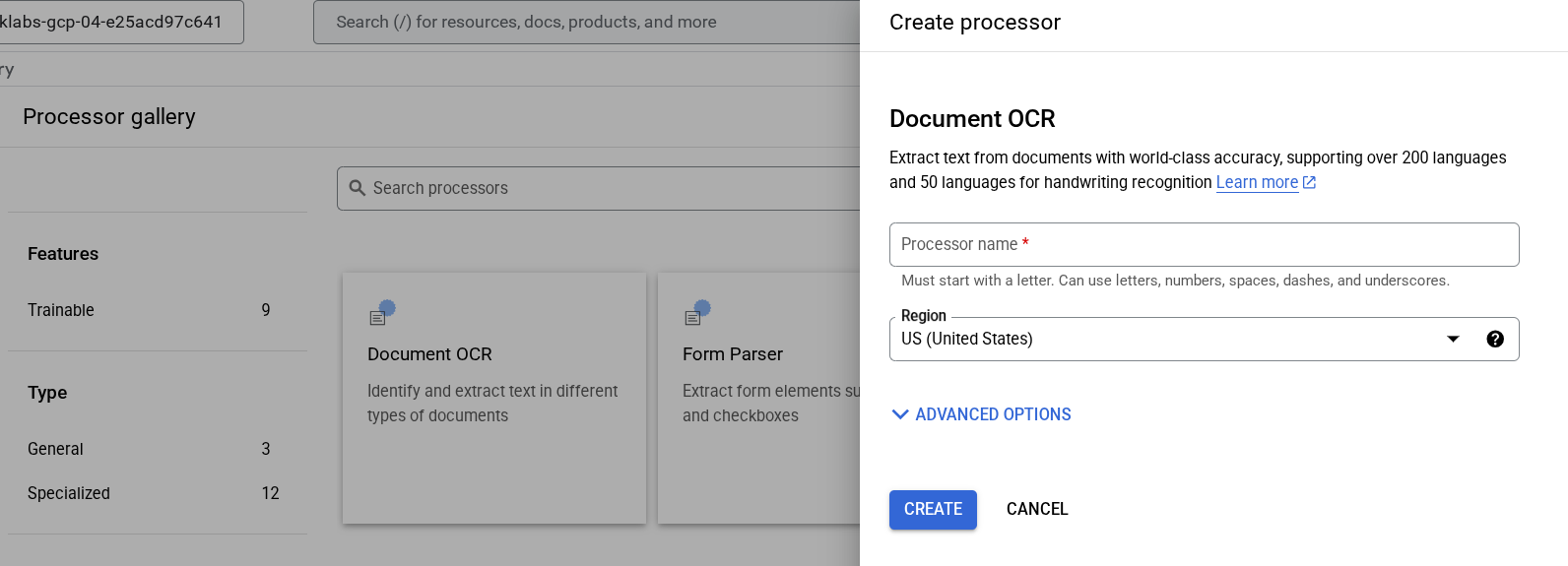
Tarea 2: Crea y prueba un procesador
Primero, debes crear una instancia del procesador de OCR en documentos que realizará la extracción. Esto se puede completar con la consola de Cloud o la API de Processor Management.
En el menú de navegación, haz clic en Ver todos los productos. En Inteligencia Artificial, selecciona Document AI.
Haz clic en Explorar procesadores y, luego, en OCR de documentos.
Asígnale el nombre lab-ocr y selecciona la región más cercana de la lista.
Haz clic en Crear para crear tu procesador.
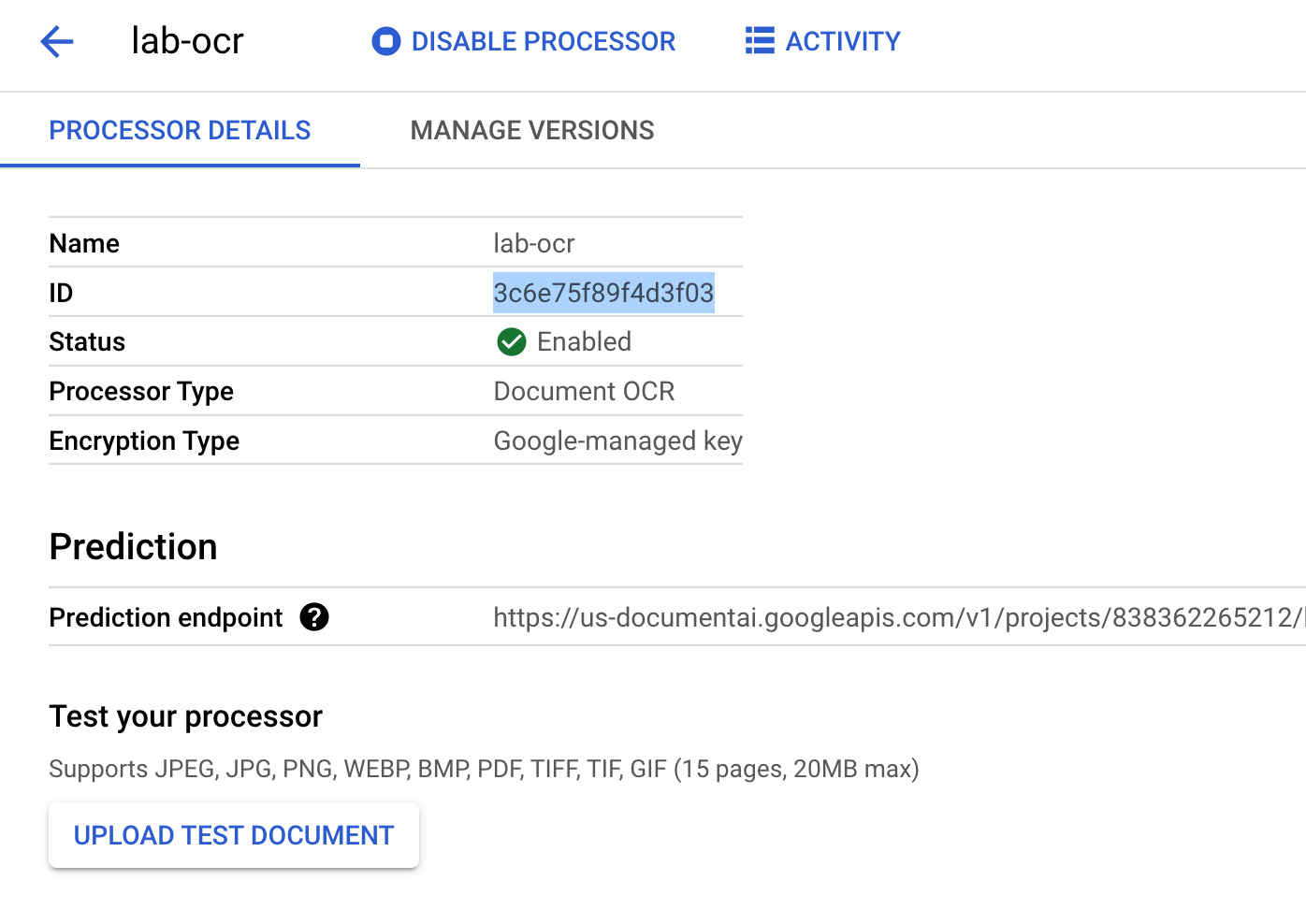
Copia el ID del procesador. Debes usarlo en el código más adelante.
Descarga el siguiente archivo PDF, que contiene las primeras 3 páginas de la novela "Winnie the Pooh" de A. A. Milne.
Para probar tu procesador en la consola, puedes subir un documento.
Haz clic en Subir documento de prueba y selecciona el archivo PDF que descargaste.
El resultado debería ser similar a este:
Haz clic en Revisar mi progreso para verificar el objetivo.
Crear y probar un procesador
Tarea 3: Autentica solicitudes a la API
Para realizar solicitudes a la API de Document AI, debes usar una cuenta de servicio. Una cuenta de servicio pertenece a tu proyecto y la biblioteca cliente de Python la usa para realizar solicitudes a la API. Al igual que cualquier otra cuenta de usuario, una cuenta de servicio está representada por una dirección de correo electrónico. En esta sección, usarás el SDK de Cloud para crear una cuenta de servicio y, luego, crear las credenciales que necesitas para autenticarte como la cuenta de servicio.
Primero, abre una ventana nueva de Cloud Shell y establece una variable de entorno con el ID de tu proyecto con el siguiente comando:
Crea credenciales para que tu código de Python las use para acceder como tu cuenta de servicio nueva. Créalas y guárdalas como un archivo JSON ~/key.json con el siguiente comando:
gcloud iam service-accounts keys create ~/key.json \
--iam-account my-docai-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Por último, configura la variable de entorno GOOGLE_APPLICATION_CREDENTIALS, que la biblioteca usa para encontrar tus credenciales. La variable de entorno se debe establecer con la ruta de acceso completa del archivo JSON de credenciales que creaste, con el siguiente comando:
Tarea 5: Realiza una solicitud de procesamiento en línea
En este paso, procesarás las primeras 3 páginas de la novela con la API de procesamiento en línea (síncrono). Este método funciona mejor en documentos más pequeños que están almacenados de forma local. Consulta la lista completa de procesadores para conocer la cantidad máxima de páginas y el tamaño máximo de los archivos que admite cada tipo de procesador.
En Cloud Shell, crea un archivo llamado online_processing.py y pega el siguiente código en él:
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # El formato debe ser 'us' o 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Crea el procesador en la consola de Cloud
# El archivo local en tu directorio de trabajo actual
FILE_PATH = "Winnie_the_Pooh_3_Pages.pdf"
# Consulta https://cloud.google.com/document-ai/docs/file-types
# para ver los tipos de archivos admitidos
MIME_TYPE = "application/pdf"
# Crea una instancia de cliente
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# El nombre de recurso completo del procesador, p. ej.:
# projects/project-id/locations/location/processor/processor-id
# Debes crear nuevos procesadores en la consola de Cloud
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# Lee el archivo en la memoria
with open(FILE_PATH, "rb") as image:
image_content = image.read()
# Carga los datos binarios en el objeto RawDocument de Document AI
raw_document = documentai.RawDocument(content=image_content, mime_type=MIME_TYPE)
# Configura la solicitud de procesamiento
request = documentai.ProcessRequest(name=RESOURCE_NAME, raw_document=raw_document)
# Usa el cliente de Document AI para procesar el formulario de muestra
result = docai_client.process_document(request=request)
document_object = result.document
print("Document processing complete.")
print(f"Text: {document_object.text}")
Reemplaza YOUR_PROJECT_ID, YOUR_PROJECT_LOCATION, YOUR_PROCESSOR_ID y FILE_PATH por los valores adecuados para tu entorno.
Nota:FILE_PATH es el nombre del archivo que subiste a Cloud Shell en el paso anterior. Si no cambiaste el nombre del archivo, debería ser Winnie_the_Pooh_3_Pages.pdf, que es el valor predeterminado, y no es necesario cambiarlo.
Ejecuta el código, que extraerá el texto y lo imprimirá en la consola.
python3 online_processing.py
Deberías ver el siguiente resultado:
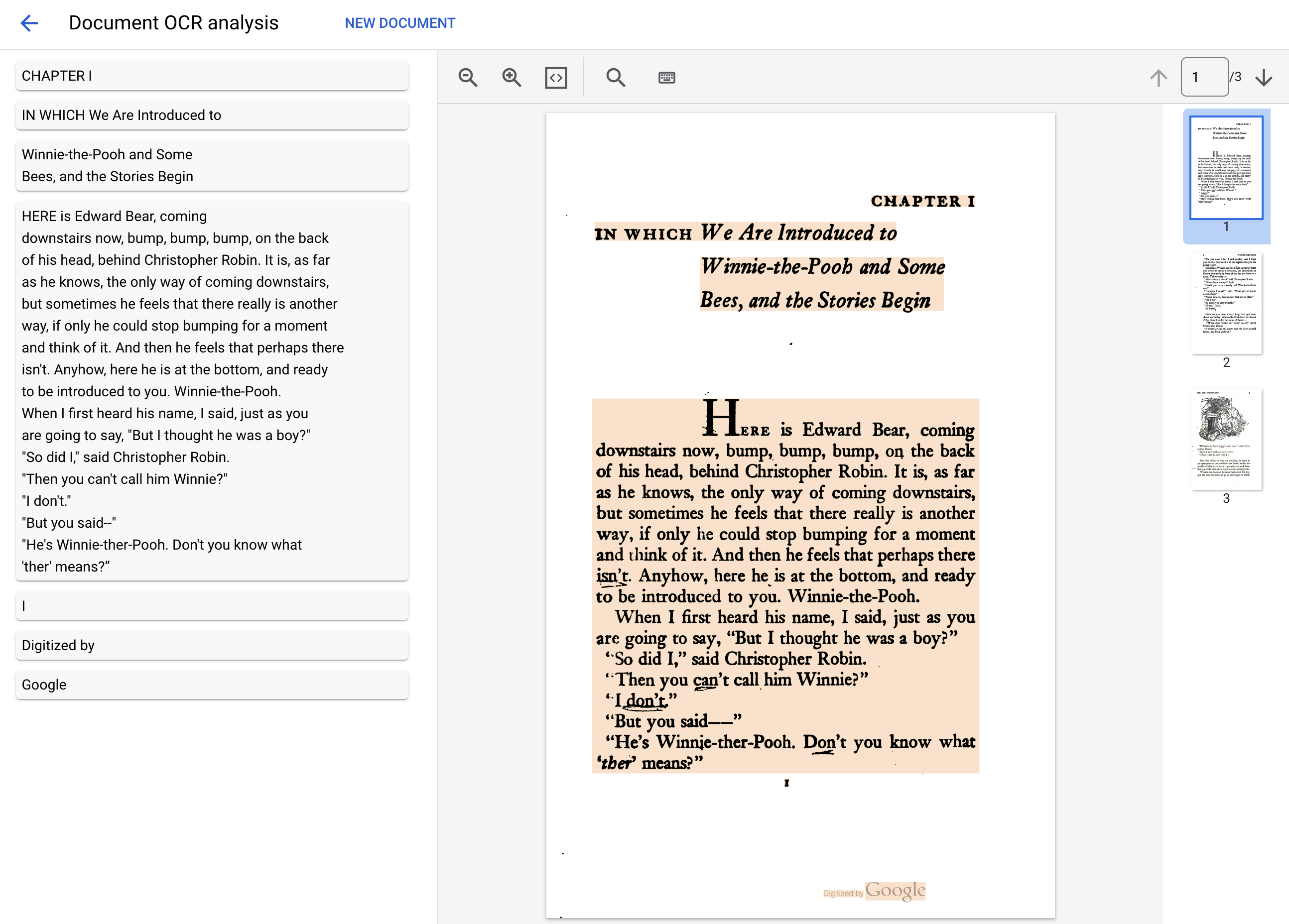
Document processing complete.
Text: IN WHICH We Are Introduced to
CHAPTER I
Winnie-the-Pooh and Some
Bees, and the Stories Begin
HERE is Edward Bear, coming
downstairs now, bump, bump, bump, on the back
of his head, behind Christopher Robin. It is, as far
as he knows, the only way of coming downstairs,
but sometimes he feels that there really is another
way, if only he could stop bumping for a moment
and think of it. And then he feels that perhaps there
isn't. Anyhow, here he is at the bottom, and ready
to be introduced to you. Winnie-the-Pooh.
When I first heard his name, I said, just as you
are going to say, "But I thought he was a boy?"
"So did I," said Christopher Robin.
"Then you can't call him Winnie?"
"I don't."
"But you said--"
...
Tarea 6: Realiza una solicitud de procesamiento por lotes
Ahora, supongamos que quieres leer el texto de toda la novela.
El procesamiento en línea tiene límites para la cantidad de páginas y el tamaño de los archivos que se pueden enviar y solo permite un documento por llamada a la API.
En cambio, el procesamiento por lotes permite procesar archivos más grandes o varios archivos en un método asíncrono.
En esta sección, procesarás toda la novela "Winnie the Pooh" con la API de procesamiento por lotes de Document AI y el texto resultante se almacenará en un bucket de Google Cloud Storage.
El procesamiento por lotes usa operaciones de larga duración para administrar solicitudes de forma asíncrona, por lo que debemos realizar la solicitud y recuperar el resultado de forma distinta al procesamiento en línea.
Sin embargo, el resultado estará en el mismo formato de objeto Document, independiente de si se usa procesamiento por lotes o en línea.
En esta sección, se muestra cómo proporcionar documentos específicos para que Document AI los procese. Más adelante, aprenderás a procesar un directorio de documentos completo.
Sube el documento PDF a Cloud Storage
Actualmente, el método batch_process_documents() acepta archivos de Google Cloud Storage. Puedes consultar documentai_v1.types.BatchProcessRequest para obtener más información sobre la estructura del objeto.
Ejecuta el siguiente comando para crear un bucket de Google Cloud Storage en el que se almacenará el archivo PDF y subir el archivo PDF al bucket:
Crea un archivo llamado batch_processing.py y pega el siguiente código:
import re
from typing import List
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
from google.cloud import storage
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # El formato debe ser 'us' o 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Crea el procesador en la consola de Cloud
# Formato 'gs://input_bucket/directory/file.pdf'
GCS_INPUT_URI = "gs://cloud-samples-data/documentai/codelabs/ocr/Winnie_the_Pooh.pdf"
INPUT_MIME_TYPE = "application/pdf"
# Formato 'gs://output_bucket/directory'
GCS_OUTPUT_URI = "YOUR_OUTPUT_BUCKET_URI"
# Crea una instancia de cliente
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# El nombre de recurso completo del procesador, p. ej.:
# projects/project-id/locations/location/processor/processor-id
# Debes crear nuevos procesadores en la consola de Cloud
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# URI de Cloud Storage para el documento de entrada
input_document = documentai.GcsDocument(
gcs_uri=GCS_INPUT_URI, mime_type=INPUT_MIME_TYPE
)
# Carga el URI de entrada de GCS en una lista de archivos de documentos
input_config = documentai.BatchDocumentsInputConfig(
gcs_documents=documentai.GcsDocuments(documents=[input_document])
)
# URI de Cloud Storage para el directorio de salida
gcs_output_config = documentai.DocumentOutputConfig.GcsOutputConfig(
gcs_uri=GCS_OUTPUT_URI
)
# Carga el URI de salida de GCS en el objeto OutputConfig
output_config = documentai.DocumentOutputConfig(gcs_output_config=gcs_output_config)
# Configura la solicitud de procesamiento
request = documentai.BatchProcessRequest(
name=RESOURCE_NAME,
input_documents=input_config,
document_output_config=output_config,
)
# El procesamiento por lotes devuelve una operación de larga duración (LRO)
operation = docai_client.batch_process_documents(request)
# Sondea la operación continuamente hasta que se completa.
# Esto podría tardar más para archivos más grandes
# Formato: projects/PROJECT_NUMBER/locations/LOCATION/operations/OPERATION_ID
print(f"Waiting for operation {operation.operation.name} to complete...")
operation.result()
# NOTA: También puedes usar devoluciones de llamada para procesamiento asíncrono
#
# def my_callback(future):
# result = future.result()
#
# operation.add_done_callback(my_callback)
print("Document processing complete.")
# Cuando se complete la operación,
# obtén la información del documento de salida a partir de los metadatos de la operación
metadata = documentai.BatchProcessMetadata(operation.metadata)
if metadata.state != documentai.BatchProcessMetadata.State.SUCCEEDED:
raise ValueError(f"Batch Process Failed: {metadata.state_message}")
documents: List[documentai.Document] = []
# Cliente de Storage para recuperar los archivos de salida de GCS
storage_client = storage.Client()
# Un proceso por cada documento de entrada
for process in metadata.individual_process_statuses:
# Formato de output_gcs_destination: gs://BUCKET/PREFIX/OPERATION_NUMBER/0
# La API de GCS requiere el nombre del bucket y el prefijo del URI por separado
output_bucket, output_prefix = re.match(
r"gs://(.*?)/(.*)", process.output_gcs_destination
).groups()
# Obtén la lista de objetos Document del bucket de salida
output_blobs = storage_client.list_blobs(output_bucket, prefix=output_prefix)
# Es posible que DocAI genere varios archivos JSON por archivo de origen
for blob in output_blobs:
# Document AI solo debe generar archivos JSON para GCS
if ".json" not in blob.name:
print(f"Skipping non-supported file type {blob.name}")
continue
print(f"Fetching {blob.name}")
# Descarga el archivo JSON y conviértelo en un objeto Document
document = documentai.Document.from_json(
blob.download_as_bytes(), ignore_unknown_fields=True
)
documents.append(document)
# Imprime el texto de todos los documentos
# Trunca en 100 caracteres para abreviar
for document in documents:
print(document.text[:100])
Reemplaza YOUR_PROJECT_ID, YOUR_PROJECT_LOCATION, YOUR_PROCESSOR_ID, GCS_INPUT_URI y GCS_OUTPUT_URI por los valores adecuados para tu entorno.
Para GCS_INPUT_URI, usa el URI del archivo que subiste a tu bucket en el paso anterior, es decir, gs:///Winnie_the_Pooh.pdf.
Para GCS_OUTPUT_URI, usa el URI del bucket que creaste en el paso anterior, es decir, gs://.
Ejecuta el código y deberías ver el texto de la novela completa extraído y, además, impreso en tu consola.
python3 batch_processing.py
Nota: Este proceso puede tardar en completarse, ya que el archivo es mucho más grande que el del ejemplo anterior. Sin embargo, con la API de procesamiento por lotes, recibirás un ID de operación que se puede usar para obtener el resultado de Cloud Storage cuando se complete la tarea.
El resultado debería ser similar a este:
Document processing complete.
Fetching 16218185426403815298/0/Winnie_the_Pooh-0.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-1.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-10.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-11.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-12.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-13.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-14.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-15.json
..
This is a reproduction of a library book that was digitized
by Google as part of an ongoing effort t
0
TAM MTAA
Digitized by
Google
Introduction
(I₂
F YOU happen to have read another
book about Christo
84
Eeyore took down his right hoof from his right
ear, turned round, and with great difficulty put u
94
..
¡Genial! Extrajiste correctamente texto de un archivo PDF con la API de procesamiento por lotes de Document AI.
Haz clic en Revisar mi progreso para verificar el objetivo.
Realizar una solicitud de procesamiento por lotes
Tarea 7: Realiza una solicitud de procesamiento por lotes para un directorio
A veces, es posible que quieras procesar un directorio de documentos completo, sin tener que enumerar cada documento de forma individual. El método batch_process_documents() admite la entrada de una lista de documentos específicos o una ruta de acceso a un directorio.
En esta sección, aprenderás a procesar un directorio completo de archivos de documentos. La mayoría del código es el mismo que en el paso anterior. La única diferencia es el URI de GCS que se envió con BatchProcessRequest.
Ejecuta el siguiente comando para copiar el directorio de muestra (que contiene varias páginas de la novela en archivos separados) a tu bucket de Cloud Storage.
Puedes leer los archivos directamente o copiarlos en tu propio bucket de Cloud Storage.
Crea un archivo llamado batch_processing_directory.py y pega el siguiente código:
import re
from typing import List
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
from google.cloud import storage
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # El formato debe ser 'us' o 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Crea el procesador en la consola de Cloud
# Formato 'gs://input_bucket/directory'
GCS_INPUT_PREFIX = "gs://cloud-samples-data/documentai/codelabs/ocr/multi-document"
# Formato 'gs://output_bucket/directory'
GCS_OUTPUT_URI = "YOUR_OUTPUT_BUCKET_URI"
# Crea una instancia de cliente
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# El nombre de recurso completo del procesador, p. ej.:
# projects/project-id/locations/location/processor/processor-id
# Debes crear nuevos procesadores en la consola de Cloud
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# URI de Cloud Storage del directorio de entrada
gcs_prefix = documentai.GcsPrefix(gcs_uri_prefix=GCS_INPUT_PREFIX)
# Carga el URI de entrada de GCS en la configuración de entrada por lotes
input_config = documentai.BatchDocumentsInputConfig(gcs_prefix=gcs_prefix)
# URI de Cloud Storage para el directorio de salida
gcs_output_config = documentai.DocumentOutputConfig.GcsOutputConfig(
gcs_uri=GCS_OUTPUT_URI
)
# Carga el URI de salida de GCS en el objeto OutputConfig
output_config = documentai.DocumentOutputConfig(gcs_output_config=gcs_output_config)
# Configura la solicitud de procesamiento
request = documentai.BatchProcessRequest(
name=RESOURCE_NAME,
input_documents=input_config,
document_output_config=output_config,
)
# El procesamiento por lotes devuelve una operación de larga duración (LRO)
operation = docai_client.batch_process_documents(request)
# Sondea la operación continuamente hasta que se completa.
# Esto podría tardar más para archivos más grandes
# Formato: projects/PROJECT_NUMBER/locations/LOCATION/operations/OPERATION_ID
print(f"Waiting for operation {operation.operation.name} to complete...")
operation.result()
# NOTA: También puedes usar devoluciones de llamada para procesamiento asíncrono
#
# def my_callback(future):
# result = future.result()
#
# operation.add_done_callback(my_callback)
print("Document processing complete.")
# Cuando se complete la operación,
# obtén la información del documento de salida a partir de los metadatos de la operación
metadata = documentai.BatchProcessMetadata(operation.metadata)
if metadata.state != documentai.BatchProcessMetadata.State.SUCCEEDED:
raise ValueError(f"Batch Process Failed: {metadata.state_message}")
documents: List[documentai.Document] = []
# Cliente de Storage para recuperar los archivos de salida de GCS
storage_client = storage.Client()
# Un proceso por cada documento de entrada
for process in metadata.individual_process_statuses:
# Formato de output_gcs_destination: gs://BUCKET/PREFIX/OPERATION_NUMBER/0
# La API de GCS requiere el nombre del bucket y el prefijo del URI por separado
output_bucket, output_prefix = re.match(
r"gs://(.*?)/(.*)", process.output_gcs_destination
).groups()
# Obtén la lista de objetos Document del bucket de salida
output_blobs = storage_client.list_blobs(output_bucket, prefix=output_prefix)
# Es posible que DocAI genere varios archivos JSON por archivo de origen
for blob in output_blobs:
# Document AI solo debe generar archivos JSON para GCS
if ".json" not in blob.name:
print(f"Skipping non-supported file type {blob.name}")
continue
print(f"Fetching {blob.name}")
# Descarga el archivo JSON y conviértelo en un objeto Document
document = documentai.Document.from_json(
blob.download_as_bytes(), ignore_unknown_fields=True
)
documents.append(document)
# Imprime el texto de todos los documentos
# Trunca en 100 caracteres para abreviar
for document in documents:
print(document.text[:100])
Reemplaza PROJECT_ID, LOCATION, PROCESSOR_ID, GCS_INPUT_PREFIX y GCS_OUTPUT_URI por los valores adecuados para tu entorno.
Para GCS_INPUT_PREFIX, usa el URI del directorio que subiste a tu bucket en la sección anterior, es decir, gs:///multi-document.
Para GCS_OUTPUT_URI, usa el URI del bucket que creaste en la sección anterior, es decir, gs://.
Usa el siguiente comando para ejecutar el código. Deberías ver el texto extraído de todos los archivos de documentos en el directorio de Cloud Storage.
python3 batch_processing_directory.py
El resultado debería ser similar a este:
Document processing complete.
Fetching 16354972755137859334/0/Winnie_the_Pooh_Page_0-0.json
Fetching 16354972755137859334/1/Winnie_the_Pooh_Page_1-0.json
Fetching 16354972755137859334/2/Winnie_the_Pooh_Page_10-0.json
..
Introduction
(I₂
F YOU happen to have read another
book about Christopher Robin, you may remember
th
IN WHICH We Are Introduced to
CHAPTER I
Winnie-the-Pooh and Some
Bees, and the Stories Begin
HERE is
..
¡Genial! Usaste correctamente la biblioteca cliente de Python para Document AI para procesar un directorio de documentos con un procesador de Document AI y almacenar los resultados en Cloud Storage.
Haz clic en Revisar mi progreso para verificar el objetivo.
Realizar una solicitud de procesamiento por lotes para un directorio
¡Felicitaciones!
¡Felicitaciones! En este lab, aprendiste a usar la biblioteca cliente de Python para Document AI para procesar un directorio de documentos con un procesador de Document AI y almacenar los resultados en Cloud Storage. También aprendiste a autenticar solicitudes a la API con un archivo de claves de cuenta de servicio, instalar la biblioteca cliente de Python para Document AI y usar las APIs de procesamiento en línea (síncrono) y por lotes (asíncrono) para procesar solicitudes.
Próximos pasos / Más información
Consulta los siguientes recursos para obtener más información sobre Document AI y la biblioteca cliente de Python:
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Actualización más reciente del manual: 13 de junio de 2024
Prueba más reciente del lab: 13 de junio de 2024
Copyright 2026 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.
Los labs crean un proyecto de Google Cloud y recursos por un tiempo determinado
.
Los labs tienen un límite de tiempo y no tienen la función de pausa. Si finalizas el lab, deberás reiniciarlo desde el principio.
En la parte superior izquierda de la pantalla, haz clic en Comenzar lab para empezar
Usa la navegación privada
Copia el nombre de usuario y la contraseña proporcionados para el lab
Haz clic en Abrir la consola en modo privado
Accede a la consola
Accede con tus credenciales del lab. Si usas otras credenciales, se generarán errores o se incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación
No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo, ya que se borrará tu trabajo y se quitará el proyecto
Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible
¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible
Un lab a la vez
Confirma para finalizar todos los labs existentes y comenzar este
Usa la navegación privada para ejecutar el lab
Usar una ventana de incógnito o de navegación privada es la mejor forma de ejecutar
este lab. Así evitarás cualquier conflicto entre tu cuenta personal
y la cuenta de estudiante, lo que podría generar cargos adicionales en
tu cuenta personal.
En este lab, aprenderás a realizar reconocimiento óptico de caracteres usando la API de Document AI con Python.
Duración:
0 min de configuración
·
Acceso por 60 min
·
25 min para completar



 en la parte superior de la consola de Google Cloud.
en la parte superior de la consola de Google Cloud.