GSP1139

개요
Document AI는 문서, 이메일, 청구서, 양식과 같은 비정형 데이터를 가져와 데이터의 이해, 분석, 사용을 쉽게 만들어 주는 문서 이해 솔루션입니다. 이 API는 콘텐츠 분류, 항목 추출, 고급검색 등을 통해 구조를 제공합니다.
이 실습에서는 Document AI 양식 파서를 사용해 Python으로 필기 양식을 파싱하는 방법을 알아봅니다. 간단한 의료 접수 양식을 예로 사용하지만 여기에서 소개하는 절차는 Document AI에서 지원하는 일반화된 양식에 사용할 수 있습니다.
목표
이 실습에서는 다음 작업을 수행하는 방법을 알아봅니다.
- Document AI 양식 파서를 사용하여 스캔한 양식에서 데이터 추출
- Document AI 양식 파서를 사용하여 양식에서 키-값 쌍 추출
- Document AI 양식 파서를 사용하여 양식에서 CSV 데이터 추출 및 내보내기
설정 및 요건
실습 시작 버튼을 클릭하기 전에
다음 안내를 확인하세요. 실습에는 시간 제한이 있으며 일시중지할 수 없습니다. 실습 시작을 클릭하면 타이머가 시작됩니다. 이 타이머는 Google Cloud 리소스를 사용할 수 있는 시간이 얼마나 남았는지를 표시합니다.
실무형 실습을 통해 시뮬레이션이나 데모 환경이 아닌 실제 클라우드 환경에서 실습 활동을 진행할 수 있습니다. 실습 시간 동안 Google Cloud에 로그인하고 액세스하는 데 사용할 수 있는 새로운 임시 사용자 인증 정보가 제공됩니다.
이 실습을 완료하려면 다음을 준비해야 합니다.
- 표준 인터넷 브라우저 액세스 권한(Chrome 브라우저 권장)
참고: 이 실습을 실행하려면 시크릿 모드(권장) 또는 시크릿 브라우저 창을 사용하세요. 개인 계정과 학습자 계정 간의 충돌로 개인 계정에 추가 요금이 발생하는 일을 방지해 줍니다.
- 실습을 완료하기에 충분한 시간(실습을 시작하고 나면 일시중지할 수 없음)
참고: 이 실습에는 학습자 계정만 사용하세요. 다른 Google Cloud 계정을 사용하는 경우 해당 계정에 비용이 청구될 수 있습니다.
실습을 시작하고 Google Cloud 콘솔에 로그인하는 방법
-
실습 시작 버튼을 클릭합니다. 실습 비용을 결제해야 하는 경우 결제 수단을 선택할 수 있는 대화상자가 열립니다.
오른쪽에는 다음과 같은 항목이 포함된 실습 설정 및 액세스 패널이 있습니다.
-
Google Cloud 콘솔 열기 버튼
- 이 실습에 사용해야 하는 임시 사용자 인증 정보(사용자 이름 및 비밀번호)
- 필요한 경우 실습 진행을 위한 기타 정보
실습 타이머는 페이지 상단에 있으며 남은 시간을 표시합니다.
-
Google Cloud 콘솔 열기를 클릭합니다(Chrome 브라우저를 실행 중인 경우 마우스 오른쪽 버튼으로 클릭하고 시크릿 창에서 링크 열기를 선택합니다).
실습에서 리소스가 가동되면 다른 탭이 열리고 로그인 페이지가 표시됩니다.
팁: 두 개의 탭을 각각 별도의 창으로 나란히 정렬하세요.
참고: 계정 선택 대화상자가 표시되면 다른 계정 사용을 클릭합니다.
-
필요한 경우 아래의 사용자 이름을 복사하여 로그인 대화상자에 붙여넣습니다.
{{{user_0.username | "Username"}}}
실습 설정 및 액세스 패널에서도 사용자 이름을 확인할 수 있습니다.
-
다음을 클릭합니다.
-
아래의 비밀번호를 복사하여 시작하기 대화상자에 붙여넣습니다.
{{{user_0.password | "Password"}}}
실습 설정 및 액세스 패널에서도 비밀번호를 확인할 수 있습니다.
-
다음을 클릭합니다.
중요: 실습에서 제공하는 사용자 인증 정보를 사용해야 합니다. Google Cloud 계정 사용자 인증 정보를 사용하지 마세요.
참고: 이 실습에 자신의 Google Cloud 계정을 사용하면 추가 요금이 발생할 수 있습니다.
-
이후에 표시되는 페이지를 클릭하여 넘깁니다.
- 이용약관에 동의하세요.
- 임시 계정이므로 복구 옵션이나 2단계 인증을 추가하지 마세요.
- 무료 체험판을 신청하지 마세요.
잠시 후 Google Cloud 콘솔이 이 탭에서 열립니다.
참고: Google Cloud 제품 및 서비스에 액세스하려면 탐색 메뉴를 클릭하거나 검색창에 제품 또는 서비스 이름을 입력합니다.

Cloud Shell 활성화
Cloud Shell은 다양한 개발 도구가 탑재된 가상 머신으로, 5GB의 영구 홈 디렉터리를 제공하며 Google Cloud에서 실행됩니다. Cloud Shell을 사용하면 명령줄을 통해 Google Cloud 리소스에 액세스할 수 있습니다.
-
Google Cloud 콘솔 상단에서 Cloud Shell 활성화  를 클릭합니다.
를 클릭합니다.
-
다음 창을 클릭합니다.
- Cloud Shell 정보 창을 통해 계속 진행합니다.
- 사용자 인증 정보를 사용하여 Google Cloud API를 호출할 수 있도록 Cloud Shell을 승인합니다.
연결되면 사용자 인증이 이미 처리된 것이며 프로젝트가 학습자의 PROJECT_ID, (으)로 설정됩니다. 출력에 이 세션의 PROJECT_ID를 선언하는 줄이 포함됩니다.
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud는 Google Cloud의 명령줄 도구입니다. Cloud Shell에 사전 설치되어 있으며 명령줄 자동 완성을 지원합니다.
- (선택사항) 다음 명령어를 사용하여 활성 계정 이름 목록을 표시할 수 있습니다.
gcloud auth list
-
승인을 클릭합니다.
출력:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (선택사항) 다음 명령어를 사용하여 프로젝트 ID 목록을 표시할 수 있습니다.
gcloud config list project
출력:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
참고: gcloud 전체 문서는 Google Cloud에서 gcloud CLI 개요 가이드를 참고하세요.
작업 1. Document AI API 사용 설정
Document AI를 사용하려면 우선 API를 사용 설정해야 합니다.
-
콘솔 상단에 있는 Cloud Shell 활성화 버튼을 클릭하여 Cloud Shell을 엽니다.
-
Cloud Shell에서 다음 명령어를 실행하여 Document AI용 API를 사용 설정합니다.
gcloud services enable documentai.googleapis.com
다음과 같은 결과를 확인할 수 있습니다.
Operation "operations/..." finished successfully.
Python용 오픈소스 데이터 분석 라이브러리인 Pandas도 설치해야 합니다.
- 다음 명령어를 실행하여 Pandas를 설치합니다.
pip3 install --upgrade pandas
- 다음 명령어를 실행하여 Document AI용 Python 클라이언트 라이브러리를 설치합니다.
pip3 install --upgrade google-cloud-documentai
다음과 같은 결과를 확인할 수 있습니다.
...
Installing collected packages: google-cloud-documentai
Successfully installed google-cloud-documentai-2.15.0
이제 Document AI API를 사용할 준비가 되었습니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
Document AI API 사용 설정
작업 2. 양식 파서 프로세서 만들기
먼저 이 튜토리얼의 Document AI 플랫폼에서 사용할 양식 파서 프로세서 인스턴스를 만들어야 합니다.
- Cloud 콘솔에서 탐색 메뉴(
 )를 열고 모든 제품 보기 > 인공지능 > Document AI를 클릭합니다.
)를 열고 모든 제품 보기 > 인공지능 > Document AI를 클릭합니다.
-
프로세서 살펴보기를 클릭하고 일반에서 양식 파서를 클릭하여 프로세서 만들기 페이지를 엽니다.
-
이름을 lab-form-parser로 지정하고 목록에서 가장 가까운 리전을 선택합니다.
-
만들기를 클릭하여 프로세서를 만듭니다.
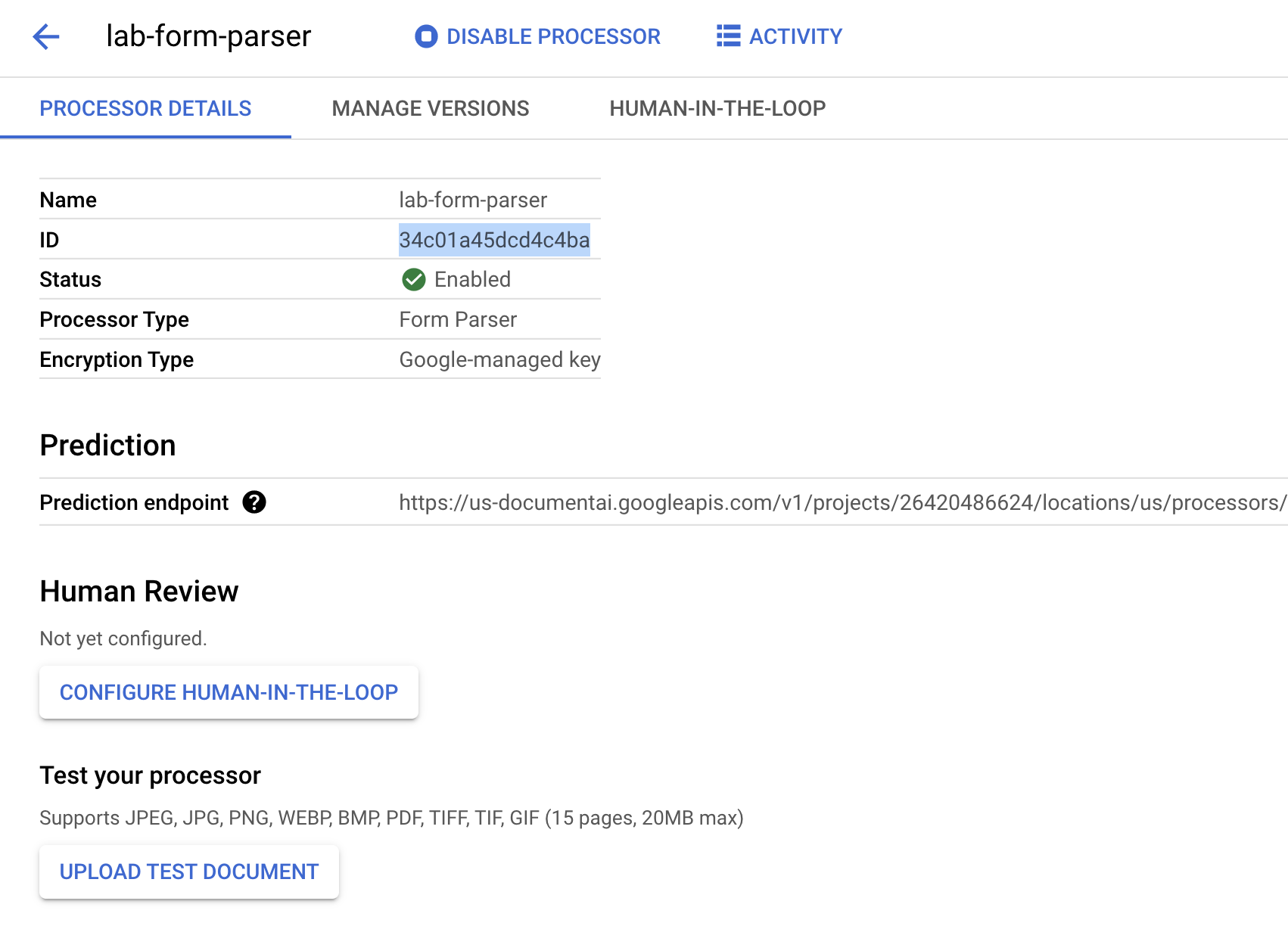
-
프로세서 ID를 복사합니다. 나중에 코드에서 이 ID를 사용해야 합니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
프로세서 만들기
Cloud 콘솔에서 프로세서 테스트
콘솔에서 문서를 업로드하여 프로세서를 테스트할 수 있습니다.
- 아래 이미지를 마우스 오른쪽 버튼으로 클릭하고 이미지를 다른 이름으로 저장을 선택하여 샘플 양식을 다운로드합니다.

-
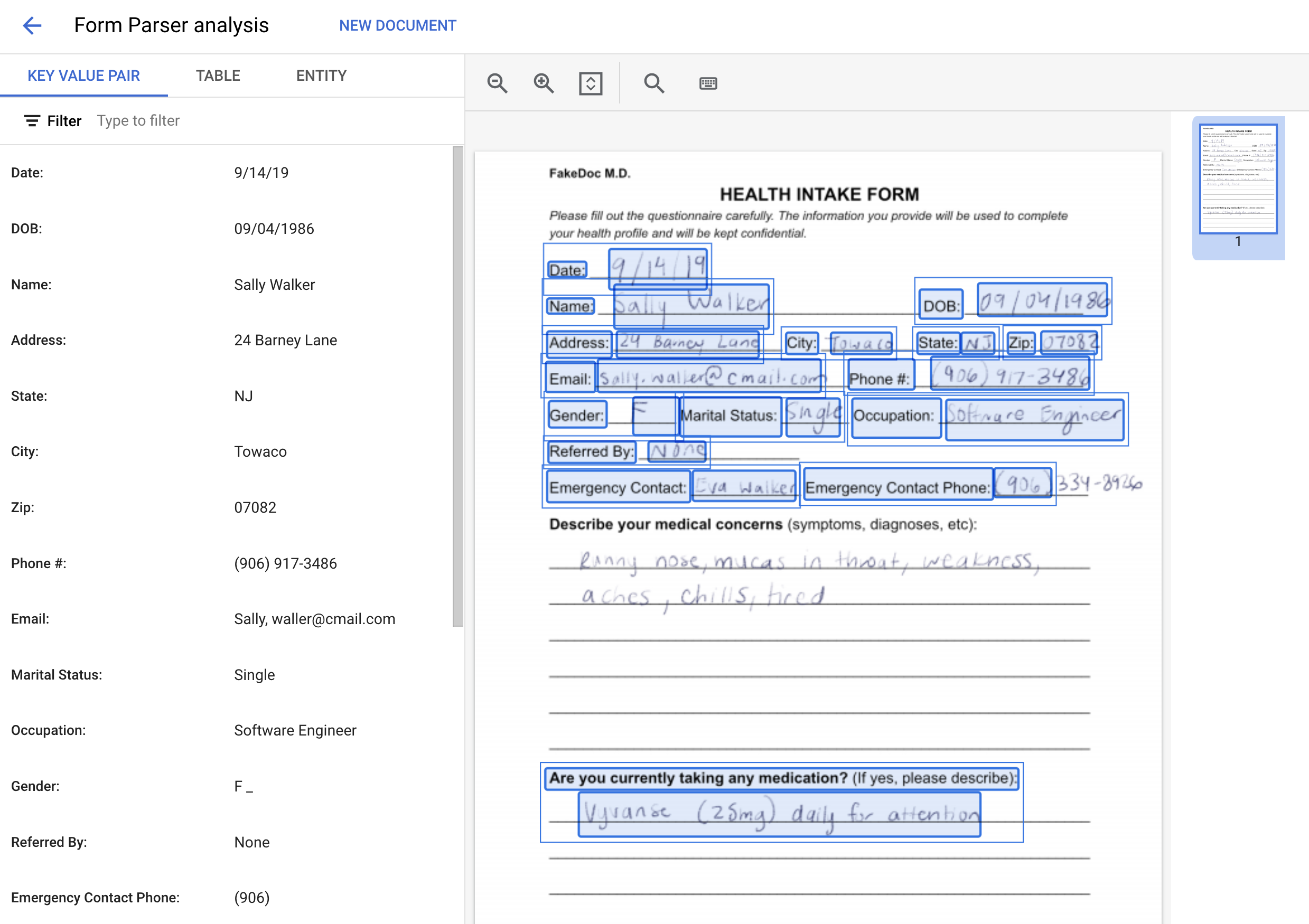
프로세서 세부정보 페이지에서 테스트 문서 업로드를 클릭합니다. 방금 다운로드한 양식을 선택합니다.
양식 파서 프로세서가 문서를 처리하고 파싱된 양식 데이터를 반환합니다. 다음과 같은 결과를 확인할 수 있습니다.
작업 3. 샘플 양식 다운로드
이 섹션에서는 간단한 의료 접수 양식이 포함된 샘플 문서를 다운로드합니다.
- 다음 명령어를 실행하여 샘플 양식을 Cloud Shell에 다운로드합니다.
gcloud storage cp gs://cloud-samples-data/documentai/codelabs/form-parser/intake-form.pdf .
- 아래 명령어를 사용하여 파일이 Cloud Shell에 다운로드되었는지 확인합니다.
ls intake-form.pdf
작업 4. 양식 키-값 쌍 추출
이 섹션에서는 온라인 처리 API를 사용하여 이전에 만든 양식 파서 프로세서를 호출합니다. 그런 다음 문서에서 찾은 키-값 쌍을 추출합니다.
온라인 처리는 단일 문서를 전송하고 응답을 기다리는 데 사용됩니다. 여러 파일을 보내거나 파일 크기가 온라인 처리 최대 페이지 수를 초과하는 경우 일괄 처리를 사용할 수도 있습니다.
처리 요청을 만드는 코드는 프로세서 ID를 제외하고 모든 프로세서 유형에서 동일합니다. Document 응답 객체에는 입력 문서의 페이지 목록이 포함됩니다. 각 page 객체에는 텍스트의 양식 필드 목록과 위치가 포함됩니다.
다음 코드는 각 페이지를 반복하면서 각 키, 값, 신뢰도 점수를 추출합니다. 데이터베이스에 저장하거나 다른 애플리케이션에서 사용하기에 더 쉬운 정형 데이터입니다.
- Cloud Shell에서
form_parser.py라는 파일을 만들고 다음 코드를 붙여넣습니다.
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(
content=image_content, mime_type=mime_type
)
# Configure the process request
request = documentai.ProcessRequest(
name=resource_name, raw_document=raw_document
)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
def trim_text(text: str):
"""
Remove extra space characters from text (blank, newline, tab, etc.)
"""
return text.strip().replace("\n", " ")
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "FORM_PARSER_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "form.pdf"
# Refer to https://cloud.google.com/document-ai/docs/processors-list
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
names = []
name_confidence = []
values = []
value_confidence = []
for page in document.pages:
for field in page.form_fields:
# Get the extracted field names
names.append(trim_text(field.field_name.text_anchor.content))
# Confidence - How "sure" the Model is that the text is correct
name_confidence.append(field.field_name.confidence)
values.append(trim_text(field.field_value.text_anchor.content))
value_confidence.append(field.field_value.confidence)
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame(
{
"Field Name": names,
"Field Name Confidence": name_confidence,
"Field Value": values,
"Field Value Confidence": value_confidence,
}
)
print(df)
-
YOUR_PROJECT_ID, YOUR_PROJECT_LOCATION, YOUR_PROCESSOR_ID, FILE_PATH를 환경에 적합한 값으로 바꿉니다.
참고: FILE_PATH는 이전 단계에서 Cloud Shell에 다운로드한 파일의 이름입니다. 파일 이름을 변경하지 않은 경우 이름이 intake-form.pdf이며, 코드에서 업데이트해야 합니다.
- 다음 명령어를 실행하여 스크립트를 실행합니다.
python3 form_parser.py
다음과 같은 출력이 표시됩니다.
Field Name Field Name Confidence Field Value Field Value Confidence
0 Phone #: 0.999982 (906) 917-3486 0.999982
1 Emergency Contact: 0.999972 Eva Walker 0.999972
2 Marital Status: 0.999951 Single 0.999951
3 Gender: 0.999933 F 0.999933
4 Occupation: 0.999914 Software Engineer 0.999914
5 Referred By: 0.999862 None 0.999862
6 Date: 0.999858 9/14/19 0.999858
7 DOB: 0.999716 09/04/1986 0.999716
8 Address: 0.999147 24 Barney Lane 0.999147
9 City: 0.997718 Towaco 0.997718
10 Name: 0.997345 Sally Walker 0.997345
11 State: 0.996944 NJ 0.996944
...
작업 5. 테이블 파싱
양식 파서는 문서 내 테이블에서 데이터를 추출할 수도 있습니다. 이 섹션에서는 새 샘플 문서를 다운로드하고 테이블에서 데이터를 추출합니다. 데이터를 Pandas에 로드하므로 단일 메서드 호출로 이 데이터를 CSV 파일 및 기타 여러 형식으로 출력할 수 있습니다.
테이블이 포함된 샘플 양식 다운로드
샘플 양식과 테이블이 포함된 샘플 문서가 준비되어 있습니다.
- 다음 명령어를 실행하여 샘플 양식을 Cloud Shell에 다운로드합니다.
gcloud storage cp gs://cloud-samples-data/documentai/codelabs/form-parser/form_with_tables.pdf .
- 아래 명령어를 사용하여 파일이 Cloud Shell에 다운로드되었는지 확인합니다.
ls form_with_tables.pdf
테이블 데이터 추출
테이블 데이터의 처리 요청은 키-값 쌍 추출 처리 요청과 정확히 동일합니다. 차이점은 응답에서 데이터를 추출하는 필드입니다. 테이블 데이터는 pages[].tables[] 필드에 저장됩니다.
이 예에서는 각 테이블과 페이지의 테이블 헤더 행과 본문 행에서 정보를 추출한 다음 테이블을 출력하고 CSV 파일로 저장합니다.
-
table_parsing.py라는 파일을 만들고 다음 코드를 붙여넣습니다.
# type: ignore[1]
"""
Uses Document AI online processing to call a form parser processor
Extracts the tables and data in the document.
"""
from os.path import splitext
from typing import List, Sequence
import pandas as pd
from google.cloud import documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(
content=image_content, mime_type=mime_type
)
# Configure the process request
request = documentai.ProcessRequest(
name=resource_name, raw_document=raw_document
)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
def get_table_data(
rows: Sequence[documentai.Document.Page.Table.TableRow], text: str
) -> List[List[str]]:
"""
Get Text data from table rows
"""
all_values: List[List[str]] = []
for row in rows:
current_row_values: List[str] = []
for cell in row.cells:
current_row_values.append(
text_anchor_to_text(cell.layout.text_anchor, text)
)
all_values.append(current_row_values)
return all_values
def text_anchor_to_text(text_anchor: documentai.Document.TextAnchor, text: str) -> str:
"""
Document AI identifies table data by their offsets in the entirety of the
document's text. This function converts offsets to a string.
"""
response = ""
# If a text segment spans several lines, it will
# be stored in different text segments.
for segment in text_anchor.text_segments:
start_index = int(segment.start_index)
end_index = int(segment.end_index)
response += text[start_index:end_index]
return response.strip().replace("\n", " ")
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "FORM_PARSER_ID" # Create processor before running sample
# The local file in your current working directory
FILE_PATH = "form_with_tables.pdf"
# Refer to https://cloud.google.com/document-ai/docs/file-types
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
header_row_values: List[List[str]] = []
body_row_values: List[List[str]] = []
# Input Filename without extension
output_file_prefix = splitext(FILE_PATH)[0]
for page in document.pages:
for index, table in enumerate(page.tables):
header_row_values = get_table_data(table.header_rows, document.text)
body_row_values = get_table_data(table.body_rows, document.text)
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame(
data=body_row_values,
columns=pd.MultiIndex.from_arrays(header_row_values),
)
print(f"Page {page.page_number} - Table {index}")
print(df)
# Save each table as a CSV file
output_filename = f"{output_file_prefix}_pg{page.page_number}_tb{index}.csv"
df.to_csv(output_filename, index=False)
-
YOUR_PROJECT_ID, YOUR_PROJECT_LOCATION, YOUR_PROCESSOR_ID, FILE_PATH를 환경에 적합한 값으로 바꿉니다.
참고: FILE_PATH는 이전 단계에서 Cloud Shell에 다운로드한 파일의 이름입니다. 파일 이름을 바꾸지 않았다면 기본값인 form_with_tables.pdf이며 변경할 필요가 없습니다.
- 다음 명령어를 실행하여 스크립트를 실행합니다.
python3 table_parsing.py
다음과 같은 출력이 표시됩니다.
Page 1 - Table 0
Item Description
0 Item 1 Description 1
1 Item 2 Description 2
2 Item 3 Description 3
코드를 실행하는 디렉터리에 새 CSV 파일도 있을 것입니다.
- 다음 명령어를 실행하여 현재 작업 디렉터리의 파일을 나열합니다.
ls
다음과 같은 출력이 표시됩니다.
form_with_tables_pg1_tb0.csv
수고하셨습니다
수고하셨습니다. 이 실습에서는 Document AI API를 사용하여 필기 양식에서 데이터를 추출했습니다. 또한 Document AI Python 클라이언트 라이브러리를 사용하여 양식에서 키-값 쌍을 추출하는 방법과 테이블이 있는 양식에서 테이블 형식 데이터를 추출하는 방법도 알아봤습니다.
다음 단계/더 학습하기
Document AI 및 Python 클라이언트 라이브러리에 대해 자세히 알아보려면 다음 리소스를 확인하세요.
Google Cloud 교육 및 자격증
Google Cloud 기술을 최대한 활용하는 데 도움이 됩니다. Google 강의에는 빠른 습득과 지속적인 학습을 지원하는 기술적인 지식과 권장사항이 포함되어 있습니다. 기초에서 고급까지 수준별 학습을 제공하며 바쁜 일정에 알맞은 주문형, 실시간, 가상 옵션이 포함되어 있습니다. 인증은 Google Cloud 기술에 대한 역량과 전문성을 검증하고 입증하는 데 도움이 됩니다.
설명서 최종 업데이트: 2025년 7월 21일
실습 최종 테스트: 2025년 7월 21일
Copyright 2026 Google LLC. All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.





