GSP1139

概要
Document AI は、ドキュメント、メール、請求書、フォームなどの非構造化データを簡単に理解、分析、利用できるようにするドキュメント理解ソリューションです。この API は、コンテンツ分類、エンティティ抽出、高度な検索機能などを利用して、データ構造を提供します。
このラボでは、Document AI の Form パーサーを使用して Python で手書きフォームを解析する方法を学びます。ここでは簡単な医療用登録フォームを例として使用しますが、DocAI でサポートされている一般的なフォームであれば、すべてにこの手順を使用できます。
目標
このラボでは、次のタスクの実行方法について学びます。
- Document AI の Form パーサーを使用してスキャンしたフォームからデータを抽出する
- Document AI の Form パーサーを使用してフォームから Key-Value ペアを抽出する
- Document AI の Form パーサーを使用してフォームから CSV データを抽出してエクスポートする
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
注: このラボの実行には、シークレット モード(推奨)またはシークレット ブラウジング ウィンドウを使用してください。これにより、個人アカウントと受講者アカウント間の競合を防ぎ、個人アカウントに追加料金が発生しないようにすることができます。
- ラボを完了するための時間(開始後は一時停止できません)
注: このラボでは、受講者アカウントのみを使用してください。別の Google Cloud アカウントを使用すると、そのアカウントに料金が発生する可能性があります。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。
右側の [ラボの設定とアクセス] パネルには、以下が表示されます。
- [Google Cloud コンソールを開く] ボタン
- このラボで使用する一時的な認証情報(ユーザー名とパスワード)
- このラボを行うために必要なその他の情報(ある場合)
ラボのタイマーはページの上部に表示され、残り時間が示されます。
-
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示された場合は、[別のアカウントを使用] をクリックします。
-
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
{{{user_0.username | "Username"}}}
[ラボの設定とアクセス] パネルでもユーザー名を確認できます。
-
[次へ] をクリックします。
-
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
{{{user_0.password | "Password"}}}
[ラボの設定とアクセス] パネルでもパスワードを確認できます。
-
[次へ] をクリックします。
重要: ラボで指定された認証情報を使用する必要があります。ご自身の Google Cloud アカウントの認証情報は使用しないでください。
注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。
-
その後のページはクリックして先に進みます。
- 利用規約に同意します。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
しばらくすると、このタブで Google Cloud コンソールが開きます。
注: Google Cloud のプロダクトやサービスにアクセスするには、ナビゲーション メニューをクリックするか、[検索] フィールドにサービス名またはプロダクト名を入力します。

Cloud Shell をアクティブにする
Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
-
Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン  をクリックします。
をクリックします。
-
ウィンドウで次の操作を行います。
- Cloud Shell 情報ウィンドウで操作を進めます。
- Cloud Shell が認証情報を使用して Google Cloud API を呼び出すことを承認します。
接続した時点で認証が完了しており、プロジェクトに各自の Project_ID、 が設定されます。出力には、このセッションの PROJECT_ID を宣言する次の行が含まれています。
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
- (省略可)次のコマンドを使用すると、有効なアカウント名を一覧表示できます。
gcloud auth list
- [承認] をクリックします。
出力:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (省略可)次のコマンドを使用すると、プロジェクト ID を一覧表示できます。
gcloud config list project
出力:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
注: Google Cloud における gcloud ドキュメントの全文については、gcloud CLI の概要ガイドをご覧ください。
タスク 1. Document AI API を有効にする
Document AI を使用するには、API を有効にする必要があります。
-
コンソールの上部にある [Cloud Shell をアクティブにする] ボタンをクリックして、Cloud Shell を開きます。
-
Cloud Shell で次のコマンドを実行して、Document AI の API を有効にします。
gcloud services enable documentai.googleapis.com
次のように表示されます。
Operation "operations/..." finished successfully.
Python 用のオープンソース データ分析ライブラリである Pandas もインストールする必要があります。
- 次のコマンドを実行して Pandas をインストールします。
pip3 install --upgrade pandas
- 次のコマンドを実行して、Document AI 用の Python クライアント ライブラリをインストールします。
pip3 install --upgrade google-cloud-documentai
次のように表示されます。
...
Installing collected packages: google-cloud-documentai
Successfully installed google-cloud-documentai-2.15.0
これで、Document AI API を使用する準備ができました。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Document AI API を有効にする
タスク 2. Form パーサー プロセッサを作成する
このチュートリアルでは最初に、Document AI Platform で使用する Form パーサー プロセッサのインスタンスを作成する必要があります。
- Cloud コンソールのナビゲーション メニュー(
 )を開き、[すべてのプロダクトを表示] > [AI] > [Document AI] をクリックします。
)を開き、[すべてのプロダクトを表示] > [AI] > [Document AI] をクリックします。
- [プロセッサを確認] をクリックし、[一般] で [Form パーサー] をクリックして [プロセッサの作成] ページを開きます。
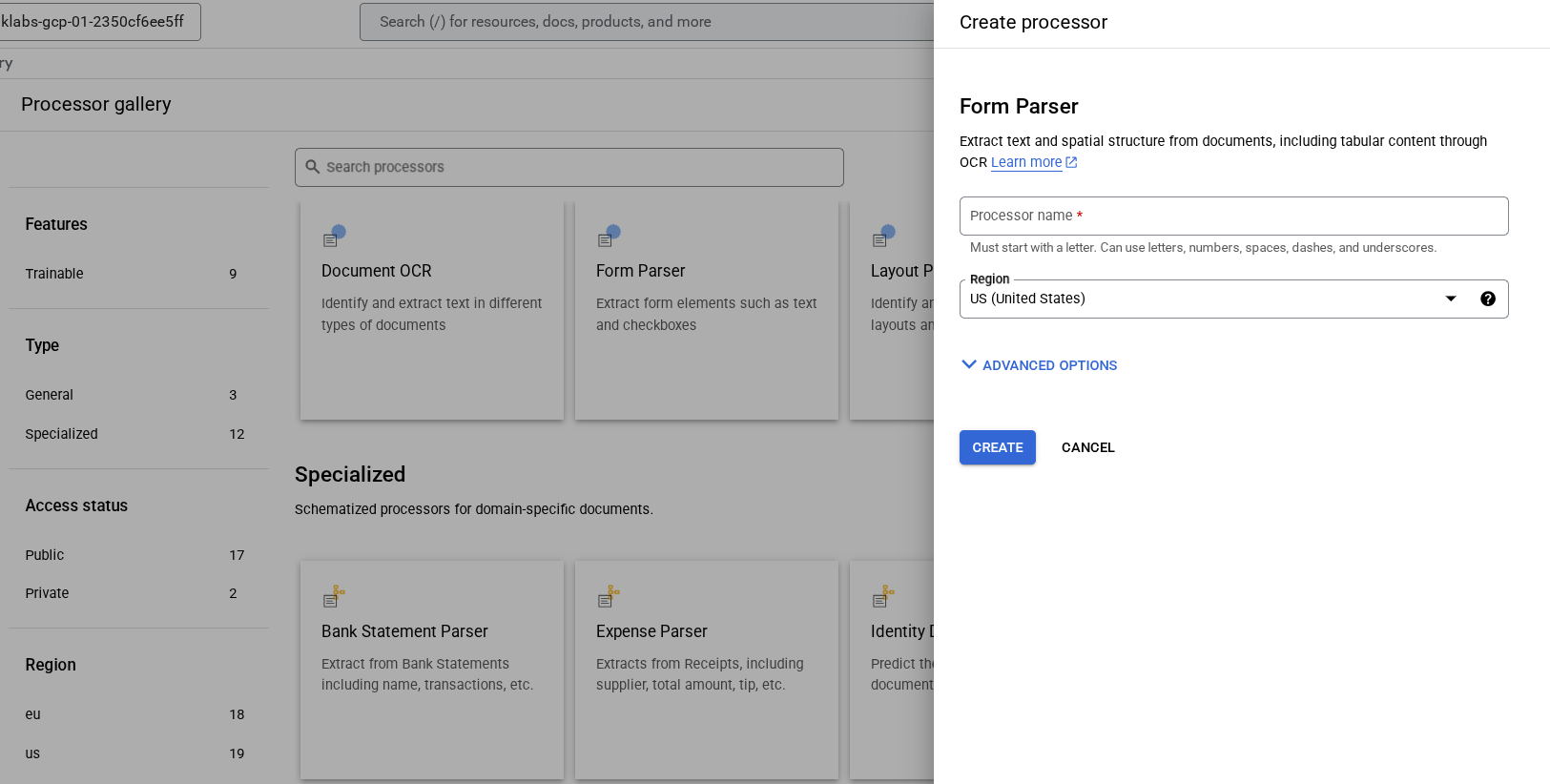
-
名前を「lab-form-parser」にして、リストから最も近いリージョンを選択します。
-
[作成] をクリックして、プロセッサを作成します。
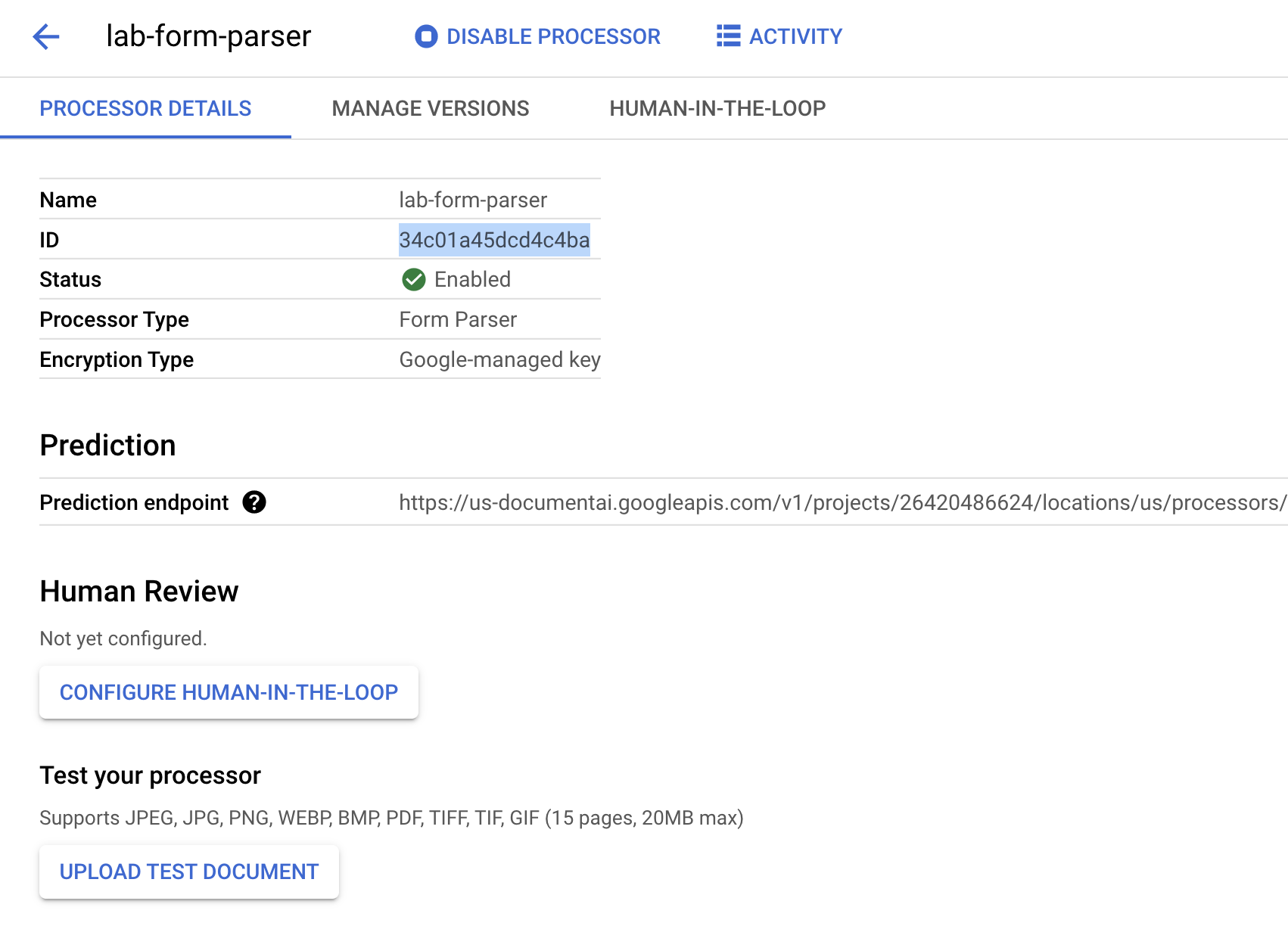
-
プロセッサ ID をコピーします。これは、後でコードを作成する際に使用します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
プロセッサを作成する
Cloud コンソールでプロセッサをテストする
ドキュメントをアップロードして、コンソールでプロセッサをテストします。
- 下の画像を右クリックし、[名前を付けて画像を保存] を選択して、フォームのサンプルをダウンロードします。

- [プロセッサの詳細] ページで、[テスト ドキュメントをアップロード] をクリックします。ダウンロードしたフォームを選択します。
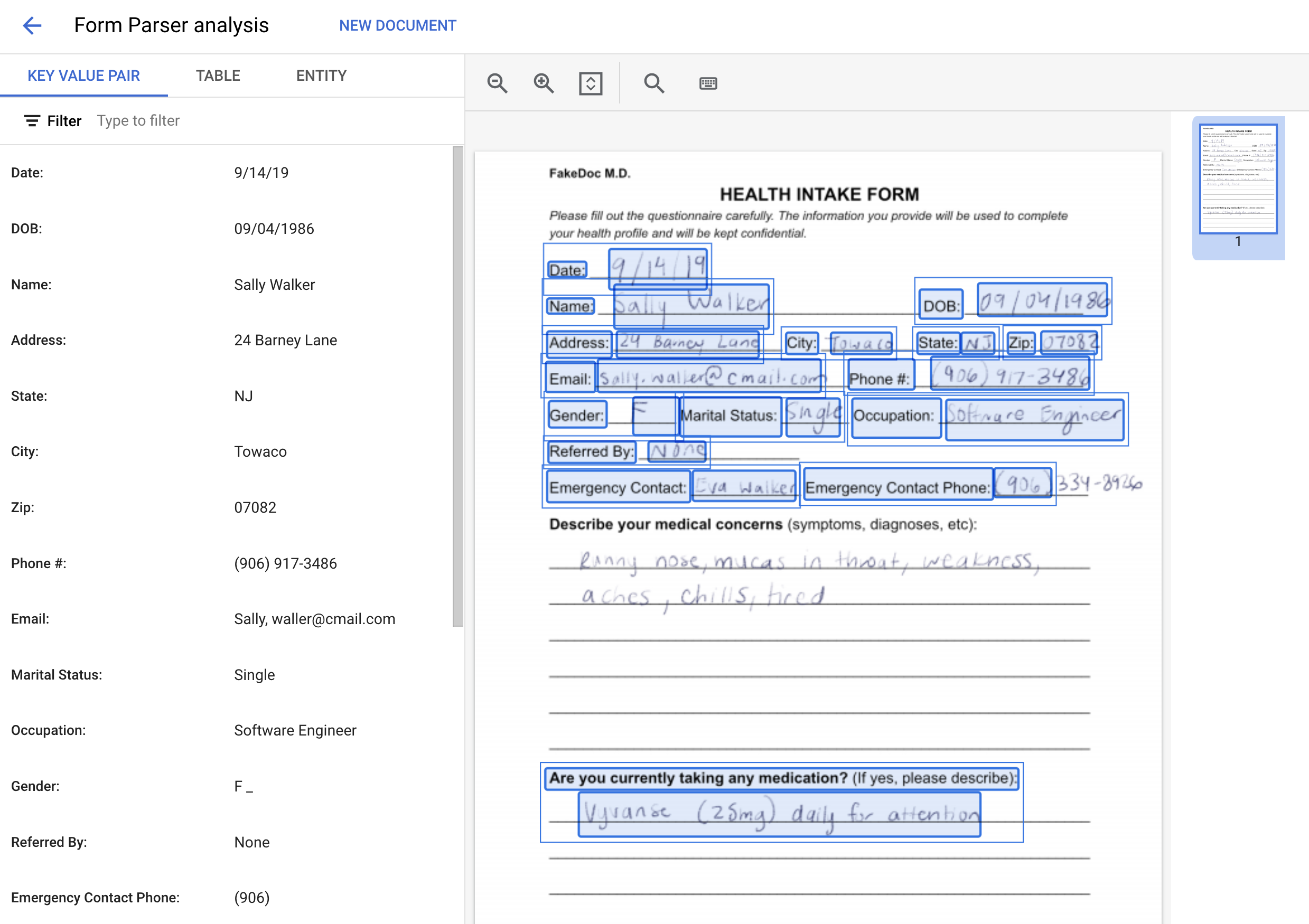
Form パーサー プロセッサがドキュメントを処理し、解析されたフォームデータが返されます。次のようになります。
タスク 3. サンプル フォームをダウンロードする
このセクションでは、簡単な医療用登録フォームを含むサンプル ドキュメントをダウンロードします。
- 次のコマンドを実行して、サンプル フォームを Cloud Shell にダウンロードします。
gcloud storage cp gs://cloud-samples-data/documentai/codelabs/form-parser/intake-form.pdf .
- 次のコマンドを使用して、ファイルが Cloud Shell にダウンロードされたことを確認します。
ls intake-form.pdf
タスク 4. フォームの Key-Value ペアを抽出する
このセクションでは、オンライン処理 API を使用して、先ほど作成した Form パーサー プロセッサを呼び出します。次に、ドキュメントで見つかった Key-Value ペアを抽出します。
オンライン処理は、単一のドキュメントを送信してレスポンスを待つ場合に使用します。複数のファイルを送信する場合や、ファイルサイズがオンライン処理の最大ページ数を超える場合は、バッチ処理を使用することもできます。
プロセス リクエストを行うコードは、プロセッサ ID を除き、すべてのプロセッサ タイプで同じです。Document レスポンス オブジェクトには、入力ドキュメントのページのリストが含まれます。各 page オブジェクトには、フォーム フィールドのリストとテキスト内の位置が含まれます。
次のコードは、各ページを反復処理し、それぞれのキー、値、信頼スコアを抽出します。これは、データベースに簡単に保存したり、他のアプリケーションで使用したりできる構造化データです。
- Cloud Shell で、
form_parser.py という名前のファイルを作成し、次のコードを貼り付けます。
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Document AI オンライン処理 API を使用してドキュメントを処理します。
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# クライアントをインスタンス化します
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# プロセッサの完全なリソース名。例:
# projects/project-id/locations/location/processor/processor-id
# まず Cloud コンソールで新しいプロセッサを作成する必要があります
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# ファイルをメモリに読み込みます
with open(file_path, "rb") as image:
image_content = image.read()
# バイナリデータを Document AI RawDocument オブジェクトに読み込みます
raw_document = documentai.RawDocument(
content=image_content, mime_type=mime_type
)
# プロセス リクエストを構成します
request = documentai.ProcessRequest(
name=resource_name, raw_document=raw_document
)
# Document AI クライアントを使用してサンプル フォームを処理します
result = documentai_client.process_document(request=request)
return result.document
def trim_text(text: str):
"""
テキストから余分な空白文字(空白、改行、タブなど)を削除します。
"""
return text.strip().replace("\n", " ")
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # 形式: 'us' または 'eu'
PROCESSOR_ID = "FORM_PARSER_ID" # Cloud コンソールでプロセッサを作成します
# 現在の作業ディレクトリ内のローカル ファイル
FILE_PATH = "form.pdf"
# サポートされるファイル形式は https://cloud.google.com/document-ai/docs/processors-list
# を参照
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
names = []
name_confidence = []
values = []
value_confidence = []
for page in document.pages:
for field in page.form_fields:
# 抽出されたフィールド名を取得します
names.append(trim_text(field.field_name.text_anchor.content))
# 信頼度 - このモデルがテキストの正確性をどの程度「信頼」しているか
name_confidence.append(field.field_name.confidence)
values.append(trim_text(field.field_value.text_anchor.content))
value_confidence.append(field.field_value.confidence)
# Pandas Dataframe を作成して表形式で値を出力します。
df = pd.DataFrame(
{
"Field Name": names,
"Field Name Confidence": name_confidence,
"Field Value": values,
"Field Value Confidence": value_confidence,
}
)
print(df)
-
YOUR_PROJECT_ID、YOUR_PROJECT_LOCATION、YOUR_PROCESSOR_ID、FILE_PATH は、環境に適した値に置き換えます。
注: FILE_PATH は、前の手順で Cloud Shell にダウンロードしたファイルの名前です。ファイルの名前を変更していない場合は、intake-form.pdf です。必要に応じて変更してください。
- 次のコマンドを使用してスクリプトを実行します。
python3 form_parser.py
次の出力が表示されます。
Field Name Field Name Confidence Field Value Field Value Confidence
0 Phone #: 0.999982 (906) 917-3486 0.999982
1 Emergency Contact: 0.999972 Eva Walker 0.999972
2 Marital Status: 0.999951 Single 0.999951
3 Gender: 0.999933 F 0.999933
4 Occupation: 0.999914 Software Engineer 0.999914
5 Referred By: 0.999862 None 0.999862
6 Date: 0.999858 9/14/19 0.999858
7 DOB: 0.999716 09/04/1986 0.999716
8 Address: 0.999147 24 Barney Lane 0.999147
9 City: 0.997718 Towaco 0.997718
10 Name: 0.997345 Sally Walker 0.997345
11 State: 0.996944 NJ 0.996944
...
タスク 5. テーブルを解析する
Form パーサーは、ドキュメント内のテーブルからデータを抽出することもできます。このセクションでは、新しいサンプル ドキュメントをダウンロードして、テーブルからデータを抽出します。Pandas にデータが読み込まれているため、このデータは単一のメソッド呼び出しで CSV ファイルや他の多くの形式に出力できます。
テーブルを含むサンプル フォームをダウンロードする
サンプル フォームとテーブルを含むサンプル ドキュメントが用意されています。
- 次のコマンドを実行して、サンプル フォームを Cloud Shell にダウンロードします。
gcloud storage cp gs://cloud-samples-data/documentai/codelabs/form-parser/form_with_tables.pdf .
- 次のコマンドを使用して、ファイルが Cloud Shell にダウンロードされたことを確認します。
ls form_with_tables.pdf
テーブルデータを抽出する
テーブルデータの処理リクエストは、Key-Value ペアの抽出リクエストと同じです。レスポンスからどのフィールドのデータを抽出するかが異なります。テーブルデータは pages[].tables[] フィールドに保存されます。
この例では、それぞれのテーブルとページについて、テーブル ヘッダー行と本文行から情報を抽出し、テーブルを出力して CSV ファイルとして保存します。
-
table_parsing.py という名前のファイルを作成し、次のコードを貼り付けます。
# type: ignore[1]
"""
Document AI オンライン処理を使用して Form パーサー プロセッサを呼び出します。
ドキュメント内のテーブルとデータを抽出します。"""
from os.path import splitext
from typing import List, Sequence
import pandas as pd
from google.cloud import documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Document AI オンライン処理 API を使用してドキュメントを処理します。
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# クライアントをインスタンス化します
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# プロセッサの完全なリソース名。例:
# projects/project-id/locations/location/processor/processor-id
# まず、Cloud コンソールで新しいプロセッサを作成する必要があります
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# ファイルをメモリに読み込みます
with open(file_path, "rb") as image:
image_content = image.read()
# バイナリデータを Document AI RawDocument オブジェクトに読み込みます
raw_document = documentai.RawDocument(
content=image_content, mime_type=mime_type
)
# 処理リクエストを構成します
request = documentai.ProcessRequest(
name=resource_name, raw_document=raw_document
)
# Document AI クライアントを使用してサンプル フォームを処理します
result = documentai_client.process_document(request=request)
return result.document
def get_table_data(
rows: Sequence[documentai.Document.Page.Table.TableRow], text: str
) -> List[List[str]]:
"""
テーブル行からテキストデータを取得します
"""
all_values: List[List[str]] = []
for row in rows:
current_row_values: List[str] = []
for cell in row.cells:
current_row_values.append(
text_anchor_to_text(cell.layout.text_anchor, text)
)
all_values.append(current_row_values)
return all_values
def text_anchor_to_text(text_anchor: documentai.Document.TextAnchor, text: str) -> str:
"""
Document AI が、ドキュメントのテキスト全体のオフセットによってテーブルデータを識別します。この関数は、オフセットを文字列に変換します。
"""
response = ""
# テキスト セグメントが複数行にわたる場合は、
# 異なるテキスト セグメントに格納されます
for segment in text_anchor.text_segments:
start_index = int(segment.start_index)
end_index = int(segment.end_index)
response += text[start_index:end_index]
return response.strip().replace("\n", " ")
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # 形式: 'us' または 'eu'
PROCESSOR_ID = "FORM_PARSER_ID" # サンプルを実行する前にプロセッサを作成します
# 現在の作業ディレクトリ内のローカル ファイル
FILE_PATH = "form_with_tables.pdf"
# サポートされているファイル形式は https://cloud.google.com/document-ai/docs/file-types
# を参照
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
header_row_values: List[List[str]] = []
body_row_values: List[List[str]] = []
# ファイル名(拡張子なし)を入力します
output_file_prefix = splitext(FILE_PATH)[0]
for page in document.pages:
for index, table in enumerate(page.tables):
header_row_values = get_table_data(table.header_rows, document.text)
body_row_values = get_table_data(table.body_rows, document.text)
# Pandas Dataframe を作成して表形式で値を出力します。
df = pd.DataFrame(
data=body_row_values,
columns=pd.MultiIndex.from_arrays(header_row_values),
)
print(f"Page {page.page_number} - Table {index}")
print(df)
# 各テーブルを CSV ファイルとして保存します
output_filename = f"{output_file_prefix}_pg{page.page_number}_tb{index}.csv"
df.to_csv(output_filename, index=False)
-
YOUR_PROJECT_ID、YOUR_PROJECT_LOCATION、YOUR_PROCESSOR_ID、FILE_PATH は、環境に適した値に置き換えます。
注: FILE_PATH は、前の手順で Cloud Shell にダウンロードしたファイルの名前です。ファイルの名前を変更していない場合は、form_with_tables.pdf です。これはデフォルト値であり、変更する必要はありません。
- 次のコマンドを使用してスクリプトを実行します。
python3 table_parsing.py
次の出力が表示されます。
Page 1 - Table 0
Item Description
0 Item 1 Description 1
1 Item 2 Description 2
2 Item 3 Description 3
コードを実行したディレクトリに新しい CSV ファイルも作成されます。
- 次のコマンドを実行して、現在の作業ディレクトリにあるファイルを一覧表示します。
ls
次の出力が表示されます。
form_with_tables_pg1_tb0.csv
お疲れさまでした
このラボでは、Document AI API を使用して手書きのフォームからデータを抽出しました。また、Document AI Python クライアント ライブラリを使用して、フォームから Key-Value ペアを抽出する方法と、テーブルを含むフォームから表形式データを抽出する方法も学びました。
次のステップと詳細情報
Document AI と Python クライアント ライブラリの詳細については、以下のリソースをご覧ください。
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2025 年 7 月 21 日
ラボの最終テスト日: 2025 年 7 月 21 日
Copyright 2026 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。





