
始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create a virtual machine
/ 20
Install necessary software and create a firewall rule
/ 40
Run the sample solution (hello-https)
/ 20
Run the sample solution to capture audio on webpage
/ 20


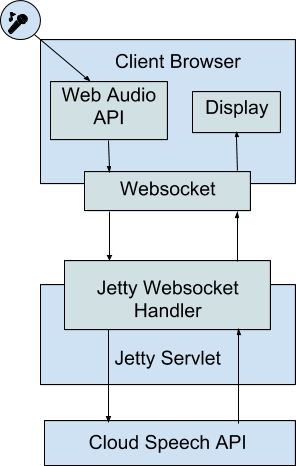
Google Cloud Speech ストリーミング API を使用すると、デベロッパーは話し言葉をリアルタイムでテキストに変換できます。Java サーブレットは、API を JavaScript の Web Audio API および Websocket と組み合わせて使用することで、ウェブページからストリーミングされた音声を受け取り、そのテキスト文字起こしを提供できます。これにより、あらゆるウェブページで、話し言葉を追加のユーザー インターフェースとして使用できるようになります。
このラボは複数のセクションに分かれており、各セクションでは最終的なウェブ アプリケーションのコンポーネントを紹介します。
作成するウェブアプリは、クライアントのマイクから音声を取得し、Java サーブレットにストリーミングします。Java サーブレットはデータを Cloud Speech API に渡し、Cloud Speech API は検出した音声文字変換をサーブレットにストリーミングします。サーブレットは音声文字変換結果をクライアントに渡し、クライアントがページに表示します。
これを行うには、次のいくつかのコンポーネントを作成する必要があります。
このラボは、次の内容を理解していることを前提としています。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

Compute Engine は、Google のインフラストラクチャで VM を起動できるサービスです。このラボでは、VM を作成して使用し、ウェブサイトをホストする、Java 8 で記述されたサーブレットを実行します。また、Cloud Speech API を使用して、クライアントに動的な音声文字変換を提供します。このラボでは、VM を使用してコードも実行します。
新しい VM を作成するには、ナビゲーション メニュー(
新しいインスタンスを作成するには、[インスタンスを作成] をクリックします。
[マシンの構成] を参照します。
新しいインスタンスに speaking-with-a-webpage という名前を付けます。
ゾーンとして
その他の値はデフォルトのままにします。
[OS とストレージ] をクリックします。
[変更] をクリックしてブートディスクの構成を開始し、次の値を選択します。
[オペレーティング システム] で [Debian] を選択します。
[バージョン] で、[Debian GNU/Linux 12(bookworm)] を選択します。
[ブートディスクの種類] はデフォルトのままにします。
ウィンドウの下部にある [選択] をクリックします。
[ネットワーキング] をクリックします。
[セキュリティ] をクリックします。
[ID と API へのアクセス] の [サービス アカウント] はデフォルトのままにします。
[アクセス スコープ] では、[すべての Cloud API に完全アクセス権を許可] を選択します。
[作成] をクリックします。
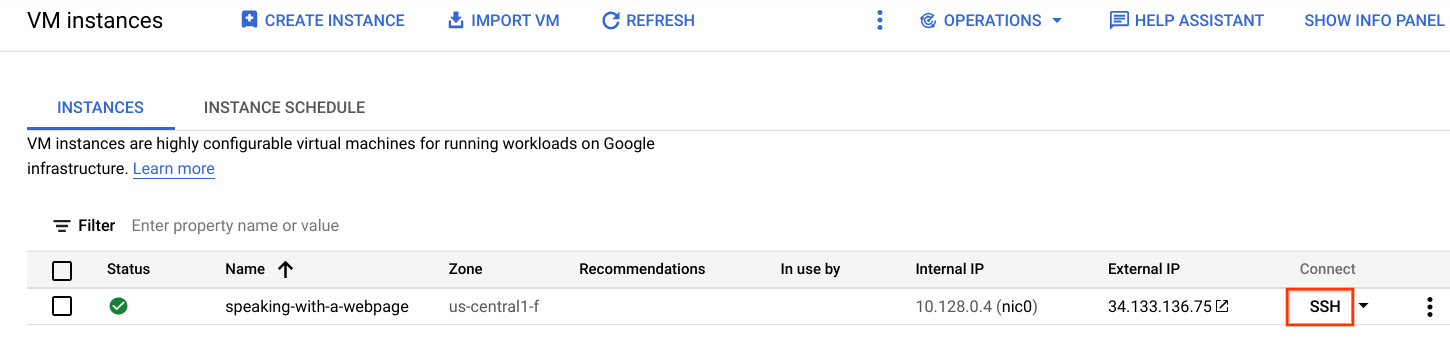
数分後、VM が起動して実行されます。[VM インスタンス] リストで、VM とその詳細を表示します。次のステップで使用する [SSH] ボタンと、このラボで後ほど使用する [外部 IP] を確認します。
新しいウィンドウが開き、VM に接続してコマンド プロンプトが表示されます。このラボの残りの部分では、このインターフェースを使用します。
[進行状況を確認] をクリックして、実行したタスクを確認します。
Compute Engine とそのさまざまな機能については、Compute Engine のドキュメントをご覧ください。
これにより、次の各セクションのサブディレクトリを含む speaking-with-a-webpage ディレクトリが作成されます。各サブディレクトリは前のサブディレクトリをベースに、新しい機能を段階的に追加しています。
01-hello-https - 静的ファイルと HTTPS 経由で提供されるハンドラを含む最小限の Jetty サーブレットが含まれています。02-webaudio - クライアントサイドの JavaScript を入力して、クライアントのマイクから音声を録音し、動作を確認するためのビジュアリゼーションを表示します。03-websockets - クライアントとサーバーの両方を変更して、WebSocket を介して相互に通信します。04-speech - サーバーを変更して、音声を Cloud Speech API に送信し、後続の音声文字変換を JavaScript クライアントに送信します。このラボで使用する例では、通常の HTTPS ポートは使用されていません。開発目的で、非特権ポート 8443 が使用されています。
cd ~/speaking-with-a-webpage
git diff --no-index 01-hello-https/ 02-webaudio/
02-https ディレクトリと 03-webaudio ディレクトリ / ステップでの違いが表示されます。矢印キー、PgUp / PgDn を使用して移動し、q を使用して終了します。[進行状況を確認] をクリックして、実行したタスクを確認します。
Java サーブレットは、このウェブアプリをサポートするバックボーンです。必要なクライアントサイドの HTML、CSS、JavaScript コードを提供し、Cloud Speech API に接続して音声文字変換を提供します。
ウェブページからユーザーのマイクにアクセスする場合、ブラウザは盗聴を防ぐために、ウェブページが安全なチャネルを介して通信することを要求します。そのため、HTTPS 経由でウェブページを配信するようにサーブレットを設定します。安全なウェブページの構成と配信はそれ自体がトピックであるため、このラボでは、用意されているサンプル ソリューションの自己署名証明書と Jetty 構成ファイルを使用します。開発環境ではこれで十分です。
このセクションでは、01-hello-https で用意されている Maven プロジェクトを読み、実行します。src/ ディレクトリ内のファイルは、以降のステップでビルドされる主要なファイルであるため、特に注意してください。
src/main/webapp のファイルには、Jetty によって静的に提供される JavaScript、CSS、HTML ファイルが含まれています。TranscribeServlet.java では、パス /transcribe へのリクエストを処理するサーブレットを定義します。提供された speaking-with-a-webpage リポジトリの 01-hello-https サブディレクトリには、HTTPS 用に構成された Maven サーブレット プロジェクトが含まれています。このサーブレットは、Jetty サーブレット フレームワークを使用して、静的ファイルと動的エンドポイントの両方を提供します。また、上記のブログ投稿を使用して、Key Tool コマンドで自己署名証明書を生成し、HTTPS をサポートする Jetty 構成を追加します。
01-hello-https に移動します。https://<your-external-ip>:8443 を指定します。![Cloud コンソールの [VM インスタンス] ページで [外部 IP] フィールドがハイライト表示されている。](https://cdn.qwiklabs.com/3xrpjknF9EimX%2Fsx3vWXS0L7KRYF4Xh2quK3Oljs4NI%3D) サンプル サーブレットは標準以外のポートでリッスンしているため、[外部 IP] リンクを直接クリックしても、実行中のサーブレットに移動しません。サーブレットにアクセスするには、上記のように関連するポートを追加する必要があります。
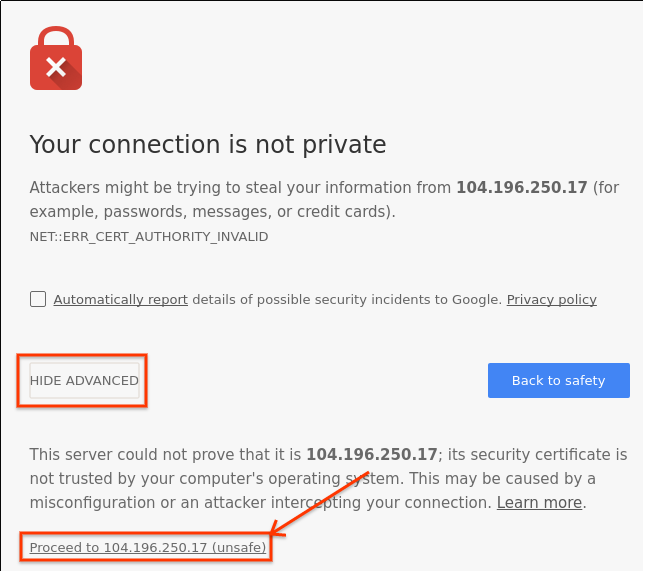
サンプル サーブレットは標準以外のポートでリッスンしているため、[外部 IP] リンクを直接クリックしても、実行中のサーブレットに移動しません。サーブレットにアクセスするには、上記のように関連するポートを追加する必要があります。HTTPS URL を使用してウェブアプリに初めてアクセスすると、接続がプライベートではないという警告がブラウザに表示されることがあります。これは、サンプルアプリで開発用に自己署名 SSL 証明書を使用しているためです。本番環境では、認証局が署名した SSL 証明書が必要になりますが、このラボでは自己署名 SSL 証明書で十分です。ただし、ウェブページで秘密を話さないようにしてください。😁
[進行状況を確認] をクリックして、実行したタスクを確認します。
Web Audio API を使用すると、ユーザーの同意を得たうえで、ウェブページでユーザーのマイクから音声データをキャプチャできます。Cloud Speech API では、この元データを特定の形式で必要とし、サンプリング レートを把握する必要があります。
提供された speaking-with-a-webpage リポジトリの 02-webaudio サブディレクトリは、Web Audio の getUserMedia 関数を追加して、ユーザーのマイクを音声の可視化に接続することで、01-hello-https サンプルコードを基に構築されています。次に、サーバーに送信する準備として、オーディオ パイプラインに ScriptProcessorNode を追加して、未加工の音声バイトを取得します。Cloud Speech API でも最終的に sampleRate が必要になるため、これも取得します。次のように 02-webaudio アプリを起動します。
Ctrl + C キーを押してサーバーを停止します。
02-webaudio を含むディレクトリに移動します。
https://<your-external-ip>:8443 にアクセスします。01-hello-https)と現在のセクション(02-webaudio)の間の変更点を確認できます。
cd ~/speaking-with-a-webpage
git diff --no-index 01-hello-https/ 02-webaudio/
[進行状況を確認] をクリックして、実行したタスクを確認します。
通常の HTTP 接続は、音声のリアルタイム ストリーミングをサーバーに送信し、音声文字変換が利用可能になったら受信するのに適していません。このセクションでは、クライアントからサーバーへのウェブ ソケット接続を作成し、それを使用して音声メタデータ(サンプルレートなど)とデータをサーバーに送信すると同時に、レスポンス(データの文字起こしなど)をリッスンします。
提供されている例では、WebSocketAdapter を登録するために、TranscribeServlet を WebSocketServlet から拡張するように変更しています。定義する WebSocketAdapter は、受信したメッセージを取得してクライアントに送り返すだけです。
クライアントでは、サンプルは前の手順の scriptNode を、後で定義するソケットにデータを送信するノードに置き換えます。次に、サーバーへの安全な WebSocket 接続を作成します。サーバーとマイクの両方が接続されると、サーバーからのメッセージのリッスンを開始し、サーバーにサンプルレートを送信します。サーバーがサンプルレートをエコーバックすると、クライアントはリスナーをより永続的な音声文字変換ハンドラに置き換え、scriptNode を接続してサーバーへの音声バイトのストリーミングを開始します。
03-websockets を含むディレクトリに移動します。実行中のウェブアプリにアクセスするには、Cloud コンソールの [VM インスタンス] ページで [外部 IP] アドレスを探し、ブラウザで https://<your-external-ip>:8443 にアクセスします。
Ctrl + C キーを押してサーバーを停止します。
Google Cloud Speech ストリーミング API を使用すると、音声バイトを API にリアルタイムで送信し、検出された音声文字変換を非同期で受け取ることができます。API は、リクエストの先頭で送信される構成によって決定される特定の形式でバイトが送信されることを想定しています。このウェブアプリでは、API の未加工の音声サンプルを LINEAR16 形式で送信します。つまり、各サンプルは 16 ビットの符号付き整数で、クライアントが取得したサンプルレートで送信されます。
提供された speaking-with-a-webpage リポジトリの 04-speech サブディレクトリは、03-websockets ステップのサーバーコードを完成させます。上記の StreamingRecognizeClient サンプルコードのコードを組み込んで、Cloud Speech API との接続、音声バイトの受け渡し、Cloud Speech API からの文字起こしの受信を行います。文字起こしを非同期で受信すると、JavaScript クライアントへの接続を使用して、それらを渡します。JavaScript クライアントは、それをウェブページに出力するだけです。
https://<your-external-ip>:8443 にアクセスします。今回のラボで学習した内容の理解を深めていただくため、以下の多肢選択式問題を用意しました。正解を目指して頑張ってください。
gcloud を使用して VM を作成し、Java サーブレットを起動して音声をキャプチャし、ウェブページでテキストに文字起こしする方法を学習しました。
追加できるソフトウェアの改善点を検討します。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2025 年 9 月 15 日
ラボの最終テスト日: 2025 年 9 月 15 日
Copyright 2026 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください