GSP811

Présentation
Dans cet atelier, vous allez apprendre à utiliser le plug-in Sensitive Data Protection pour Cloud Fusion afin de masquer les données sensibles.
Prenons le scénario suivant, dans lequel certaines informations client sensibles doivent être masquées.
Scénario : Votre équipe d'assistance consigne les détails de chaque demande d'assistance. Toutes les informations contenues dans les demandes d'assistance sont extraites dans un fichier CSV. Les techniciens d'assistance ne sont pas censés consigner les informations client considérées comme sensibles, mais ils le font parfois par erreur. Vous remarquez que les numéros de téléphone de certains clients figurent dans le fichier CSV.
Vous souhaitez parcourir le fichier CSV et masquer tous les numéros de téléphone. Vous créez un pipeline Cloud Data Fusion qui masque les données client sensibles à l'aide du plug-in Sensitive Data Protection.
Vous allez créer un pipeline qui effectue les opérations suivantes :
- Il masque les numéros de téléphone et les adresses e-mail des clients à l'aide du caractère #.
- Il stocke les données sensibles masquées et les données non sensibles dans Cloud Storage.
Objectifs
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
- Connecter Cloud Data Fusion à une source Cloud Storage
- Déployer le plug-in Sensitive Data Protection
- Créer un modèle Sensitive Data Protection personnalisé
- Utiliser le plug-in de transformation "Redact" (Masquer) pour masquer les données client sensibles
- Écrire les données de sortie dans Cloud Storage
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
-
Connectez-vous à Google Skills dans une fenêtre de navigation privée.
-
Vérifiez le temps imparti pour l'atelier (par exemple : 02:00:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
-
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Remarque : Une fois que vous avez cliqué sur Démarrer l'atelier, il faut compter environ 15-20 minutes pour que les ressources nécessaires soient provisionnées et une instance Data Fusion créée.
Pendant ce temps, vous pouvez parcourir les étapes ci-dessous pour vous familiariser avec les objectifs de l'atelier.
Les identifiants pour l'atelier (Username (Nom d'utilisateur) et Password (Mot de passe)) s'afficheront dans le volet de gauche une fois l'instance créée. Vous pourrez alors vous connecter à la console.
-
Notez ces identifiants (Username (Nom d'utilisateur) et Password (Mot de passe)). Ils vous serviront à vous connecter à la console Google Cloud.
-
Cliquez sur Open Google Console (Ouvrir la console Google).
-
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
-
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Remarque : Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer. Votre travail et le projet seront alors supprimés.
Se connecter à la console Google Cloud
- Dans l'onglet ou la fenêtre de navigateur que vous utilisez pour cet atelier, copiez les données de Username (Nom d'utilisateur) indiqué dans le panneau Connection Details (Détails de connexion), puis cliquez sur le bouton Open Google Console (Ouvrir la console Google).
Remarque : Si vous êtes invité à choisir un compte, cliquez sur Use another account (Utiliser un autre compte).
- Collez les données de Username (Nom d'utilisateur) et de Password (Mot de passe) lorsque vous y êtes invité :
- Cliquez sur Next (Suivant).
- Acceptez les conditions d'utilisation.
Comme il s'agit d'un compte temporaire auquel vous aurez accès uniquement pendant la durée de cet atelier :
- n'ajoutez pas d'options de récupération ;
- ne vous inscrivez pas à des essais sans frais.
- Une fois la console ouverte, affichez la liste des services en cliquant sur le menu de navigation (
 ) en haut à gauche.
) en haut à gauche.

Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient des outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Google Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud. gcloud est l'outil de ligne de commande associé à Google Cloud. Il est préinstallé sur Cloud Shell et permet la saisie semi-automatique via la touche Tabulation.
-
Dans Google Cloud Console, dans le volet de navigation, cliquez sur Activer Cloud Shell ( ).
).
-
Cliquez sur Continuer.
Le provisionnement et la connexion à l'environnement prennent quelques instants. Une fois connecté, vous êtes en principe authentifié, et le projet est défini sur votre ID_PROJET. Exemple :

Exemples de commandes
gcloud auth list
(Résultat)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Exemple de résultat)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Résultat)
[core]
project = <ID_Projet>
(Exemple de résultat)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Vérifier les autorisations du projet
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
-
Dans la console Google Cloud, accédez au menu de navigation (), puis cliquez sur IAM et administration > IAM.
-
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle Éditeur. Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation Cloud.

Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle Éditeur, procédez comme suit pour lui attribuer le rôle approprié.
-
Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation Cloud.
-
Sur la carte Informations sur le projet, copiez le numéro du projet.
-
Dans le menu de navigation, cliquez sur IAM et administration > IAM.
-
En haut de la page IAM, cliquez sur Ajouter.
-
Dans le champ Nouveaux comptes principaux, saisissez :
{project-number}-compute@developer.gserviceaccount.com
Remplacez {project-number} par le numéro de votre projet.
-
Dans le champ Sélectionnez un rôle, sélectionnez De base (ou Projet) > Éditeur.
-
Cliquez sur Enregistrer.
Tâche 1 : Configurer le bucket Cloud Storage
Vous allez créer un bucket Cloud Storage dans votre projet pour que le pipeline puisse stocker les données de sortie.
Le nom du bucket créé correspond à l'ID de votre projet.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Configurer un bucket Cloud Storage
Tâche 2 : Ajouter les autorisations nécessaires pour votre instance Cloud Data Fusion
- Dans la barre de titre de la console Google Cloud, saisissez Data Fusion dans le champ Recherche, puis cliquez sur Data Fusion dans les résultats de recherche. Vous devriez voir une instance Cloud Data Fusion déjà configurée et prête à être utilisée.
Remarque : La création de l'instance prend environ 20 minutes. Attendez qu'elle soit prête avant de continuer.
Vous allez ensuite accorder des autorisations au compte de service associé à l'instance en suivant les étapes ci-dessous.
-
Dans la console Google Cloud, accédez à IAM et Administration > IAM.
-
Vérifiez que le compte de service par défaut Compute Engine {project-number}-compute@developer.gserviceaccount.com est présent, puis copiez le Compte de service dans votre presse-papiers.
-
Sur la page des autorisations IAM, cliquez sur +Accorder l'accès.
-
Collez le compte de service dans le champ "Nouveaux principaux".
-
Cliquez dans le champ Sélectionner un rôle et commencez à saisir Agent de service de l'API Cloud Data Fusion, puis sélectionnez ce rôle lorsqu'il apparaît.
-
Cliquez sur Enregistrer.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Ajouter le rôle Agent de service de l'API Cloud Data Fusion au compte de service
Accorder l'autorisation Utilisateur du compte de service
-
Dans la console, accédez au menu de navigation et cliquez sur IAM et administration > IAM.
-
Cochez la case Inclure les attributions de rôles fournies par Google.
-
Faites défiler la liste jusqu'au compte de service Cloud Data Fusion géré par Google semblable à service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com. Copiez le nom du compte de service dans votre presse-papiers.

-
Ensuite, accédez à IAM et administration > Comptes de service.
-
Cliquez sur le compte Compute Engine par défaut, semblable à {project-number}-compute@developer.gserviceaccount.com, et sélectionnez l'onglet Comptes principaux avec accès dans la barre de navigation supérieure.
-
Cliquez sur le bouton Accorder l'accès.
-
Dans le champ Nouveaux comptes principaux, collez le nom du compte de service que vous avez copié plus tôt.
-
Dans le menu déroulant Rôle, sélectionnez Utilisateur du compte de service.
-
Cliquez sur Enregistrer.
Tâche 3 : Obtenir les autorisations Sensitive Data Protection
-
Dans la console Cloud, accédez au menu de navigation > IAM.
-
En haut à droite de la table des autorisations, cochez la case Inclure les attributions de rôles fournies par Google.

- Dans la table des autorisations, dans la colonne Principal, recherchez le compte de service correspondant au format
service-project-number@gcp-sa-datafusion.iam.gserviceaccount.com.

-
Cliquez sur le bouton Modifier à droite du compte de service.
-
Cliquez sur Ajouter un autre rôle.
-
Cliquez sur le menu déroulant qui s'affiche.
-
Utilisez la barre de recherche pour afficher et sélectionner Administrateur DLP.
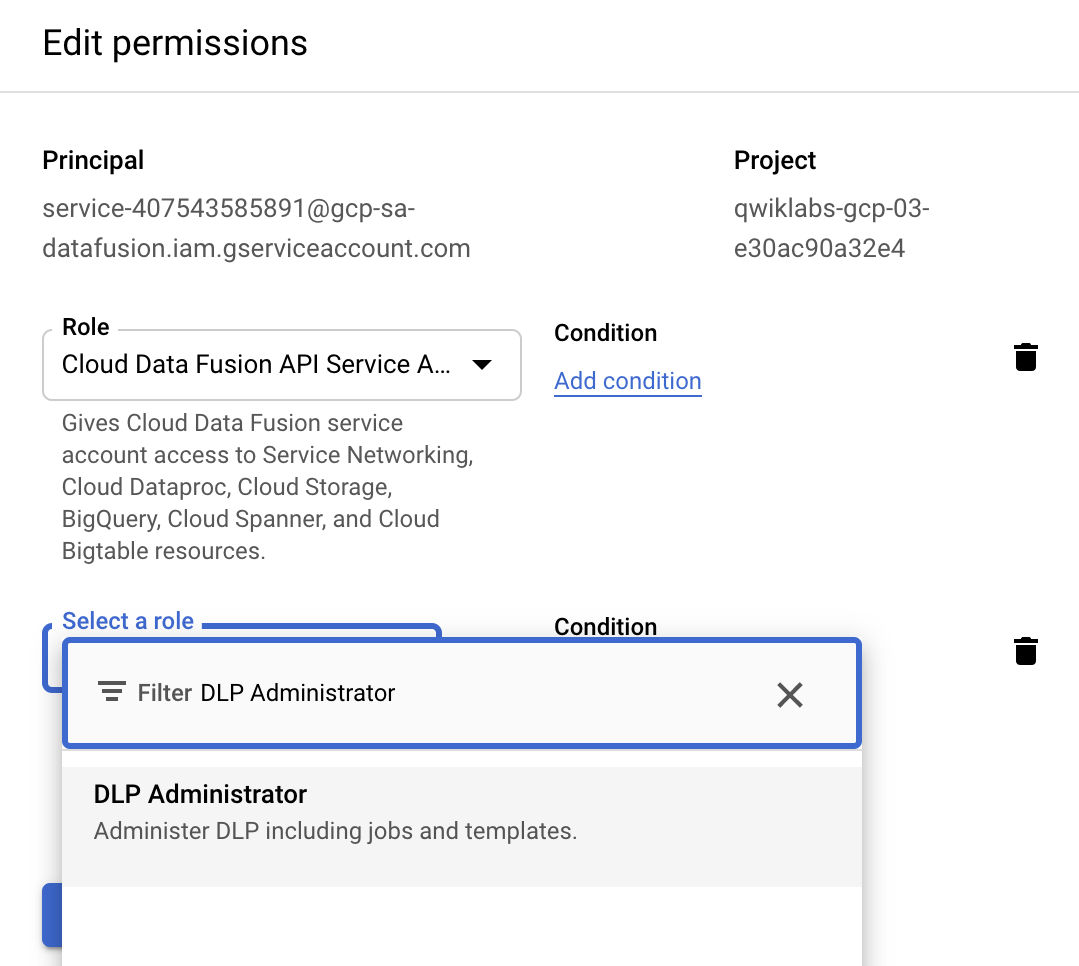
-
Cliquez sur Enregistrer.
-
Vérifiez que Administrateur DLP apparaît dans la colonne Rôle.

Cliquez sur Vérifier ma progression pour valider l'objectif.
Obtenir les autorisations Sensitive Data Protection
Tâche 4 : Accéder à l'UI de Cloud Data Fusion
-
Accédez à Data Fusion, cliquez sur Instances, puis sur le lien Afficher l'instance à côté de votre instance Data Fusion. Si nécessaire, utilisez les identifiants qui vous ont été attribués pour cet atelier afin de vous connecter. Si vous êtes invité à découvrir le service, cliquez sur Non, merci. L'UI de Cloud Data Fusion s'ouvre.
-
Dans l'UI de Cloud Data Fusion, cliquez sur le menu de navigation en haut à gauche, puis accédez à la page Studio. Vous allez maintenant créer un pipeline.
Tâche 5 : Créer le pipeline
Le pipeline que vous allez créer effectue les opérations suivantes :
* Il lit les données d'entrée à l'aide du plug-in source Cloud Storage.
* Il déploie le plug-in Sensitive Data Protection à partir du hub et applique le plug-in de transformation "Redact" (Masquer).
* Il écrit les données de sortie à l'aide d'un plug-in récepteur Cloud Storage.
- Dans le panneau de gauche de la page Studio, sous le menu Source, cliquez sur le plug-in Google Cloud Storage (GCS).
-
Maintenez le pointeur sur le nœud GCS qui s'affiche, puis cliquez sur Properties (Propriétés).
-
Sous Reference Name (Nom de référence), saisissez un nom de référence.
-
Cet atelier utilise l'ensemble de données d'entrée SampleRecords.csv, fourni dans un bucket Cloud Storage accessible au public. Sous Path (Chemin d'accès), saisissez gs://cloud-training/OCBL167/SampleRecords.csv.
-
Pour Format, sélectionnez CSV.
-
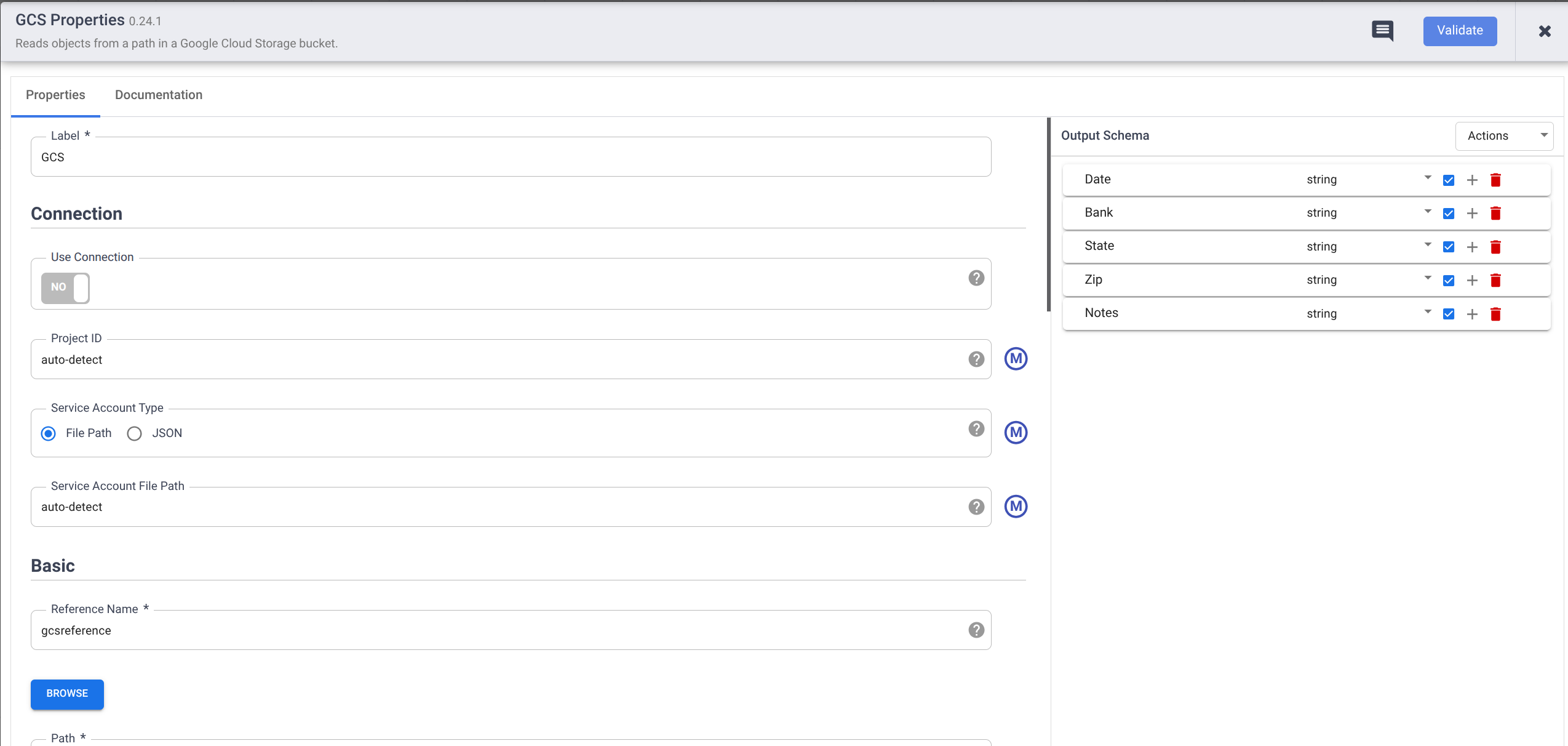
Pour Output Schema (Schéma de sortie), sous Field name (Nom du champ), saisissez les informations suivantes en cliquant sur le bouton + pour chaque type de données. Supprimez tous les types de données existants, le cas échéant.
- Date
- Bank (Banque)
- State (État)
- Zip (Code postal)
- Notes
-
Assurez-vous que tous les types de données sont définis sur string (chaîne). Pour modifier le type, cliquez sur Type et sélectionnez String (Chaîne) dans le menu déroulant.
-
Cochez la case correspondant à chaque type de données. Cela permet de s'assurer que le pipeline n'échoue pas lorsqu'il rencontre une valeur nulle (vide).
-
Cliquez sur Validate (Valider) pour vérifier qu'il n'y a pas d'erreurs.
-
Cliquez sur le bouton X dans l'angle supérieur droit de la boîte de dialogue.
Tâche 6 : Masquer les données sensibles
Le plug-in de transformation "Redact" (Masquer) identifie les enregistrements sensibles dans votre flux de données d'entrée et applique les transformations que vous définissez à ces enregistrements. Un enregistrement de données est considéré comme sensible s'il correspond à des filtres Sensitive Data Protection prédéfinis que vous choisissez ou à un modèle personnalisé que vous définissez.
Pour cet atelier, vous souhaitez masquer les numéros de téléphone de clients que certains techniciens d'assistance ont notés par inadvertance. Ils ont saisi ces informations sensibles dans la section Notes des demandes d'assistance, qui apparaissent dans la colonne Notes du fichier CSV. Vous allez créer un modèle d'inspection Sensitive Data Protection personnalisé, puis indiquez son ID dans le menu des propriétés du plug-in de transformation "Redact" (Masquer).
Tâche 7 : Déployer le plug-in Sensitive Data Protection
-
Dans l'UI de Cloud Data Fusion, cliquez sur Hub en haut à droite.
-
Cliquez sur le plug-in Data Loss Prevention (Protection contre la perte de données).
-
Cliquez sur Deploy (Déployer).
-
Cliquez sur Finish (Terminer).
-
Cliquez sur le bouton X dans l'angle supérieur droit de la boîte de dialogue Data Loss Prevention | Deploy (Protection contre la perte de données | Déployer).
-
Cliquez sur le bouton X pour quitter le hub.
Tâche 8 : Créer un modèle personnalisé
-
Dans la barre de titre de la console Google Cloud, saisissez Sécurité dans le champ Recherche, puis cliquez sur Sécurité dans les résultats de recherche. Sélectionnez Sensitive Data Protection.
-
Cliquez sur l'onglet Configuration, puis sur Créer un modèle.
-
Sous Définir le modèle, dans le champ ID du modèle, saisissez un ID pour votre modèle. Vous aurez besoin de cet ID dans la suite de ce tutoriel.
-
Cliquez sur Continuer.
-
Pour Configurer la détection, cliquez sur Gérer les infoTypes.
-
Dans l'onglet Intégrés, filtrez la recherche sur phone number (numéro de téléphone).
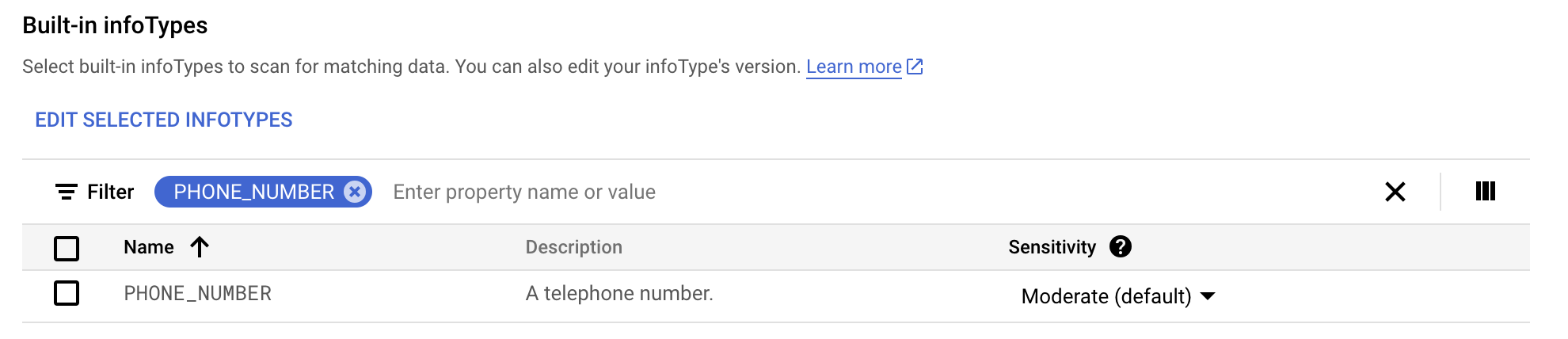
-
Sélectionnez PHONE_NUMBER.
-
Cliquez sur OK.
-
Cliquez sur Créer.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer un modèle personnalisé
Tâche 9 : Appliquer la transformation "Redact" (Masquer)
-
De retour dans l'UI de Cloud Data Fusion, sur la page Studio, cliquez pour développer le menu Transform (Transformation).
-
Cliquez sur le plug-in de transformation Google DLP Redact (Masquer avec Google DLP).
- Faites glisser une flèche de connexion du nœud GCS vers le nœud Google DLP Redact (Masquer avec Google DLP).
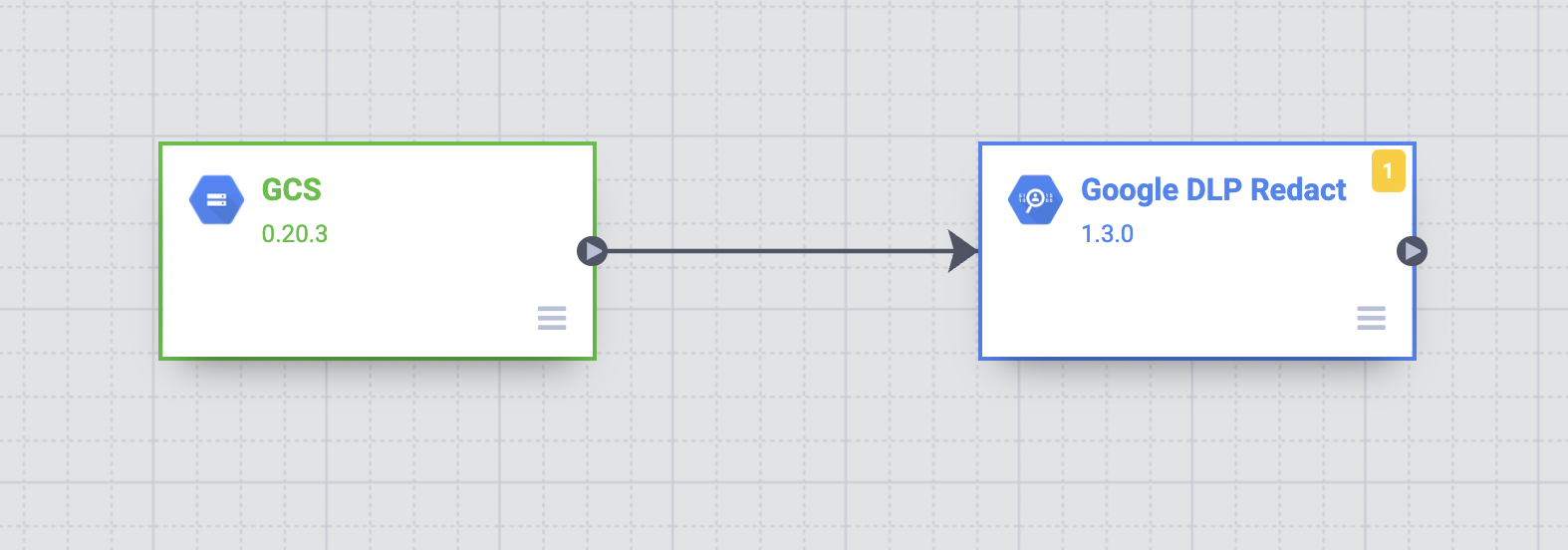
- Maintenez le pointeur de la souris sur le nœud Google DLP Redact (Masquer avec Google DLP) et cliquez sur Properties (Propriétés).
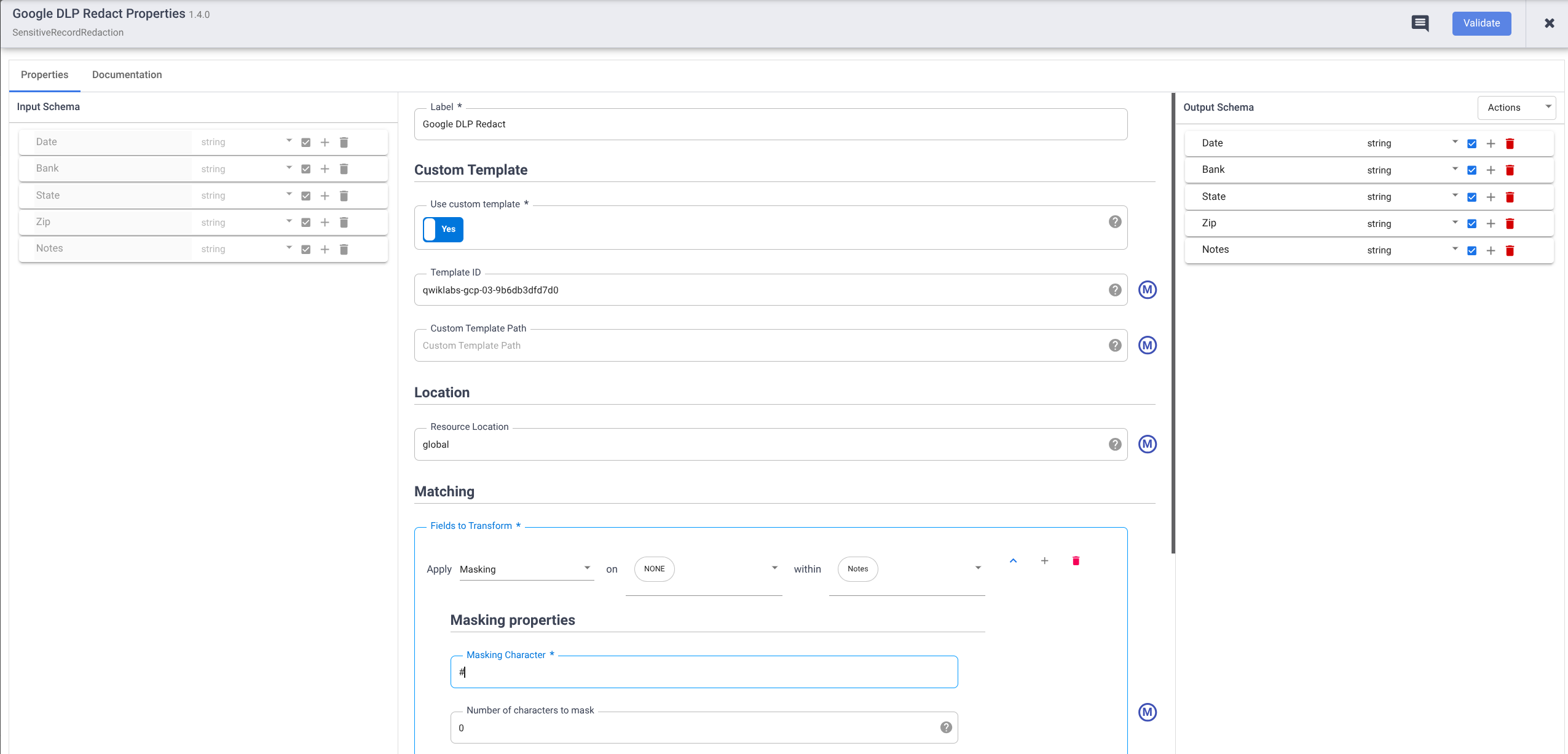
- Définissez Use custom template (Utiliser un modèle personnalisé) sur Yes (Oui).
- Sous Template ID (ID du modèle), saisissez l'ID du modèle personnalisé que vous avez créé.
- Sous Matching (Correspondance), appliquez la transformation Masking (Masquage) au Custom template (Modèle personnalisé) dans Notes.
Remarque : En plus du masquage, d'autres transformations Sensitive Data Protection sont disponibles avec le plug-in Sensitive Data Protection. Pour en savoir plus, consultez l'onglet "Documentation" dans le menu des propriétés du plug-in "Redact" (Masquer).
- Pour Masking Character (Caractère de masquage), saisissez
#.
-
Cliquez sur Validate (Valider) pour vérifier qu'il n'y a pas d'erreurs.
-
Cliquez sur le bouton X dans l'angle supérieur droit de la boîte de dialogue.
Tâche 10 : Stocker les données de sortie
Stockez les résultats de votre pipeline dans un fichier Cloud Storage.
-
Dans l'UI de Cloud Data Fusion, sur la page Studio, cliquez pour développer le menu Sink (Récepteur).
-
Cliquez sur GCS.
-
Faites glisser une flèche de connexion du nœud Google DLP Redact (Masquer avec Google DLP) vers le nœud GCS2.
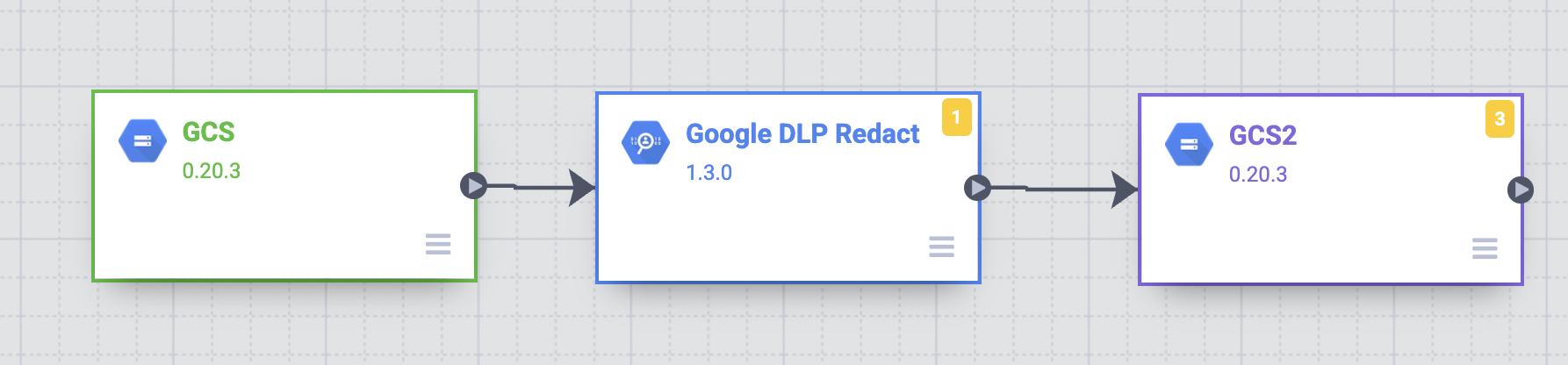
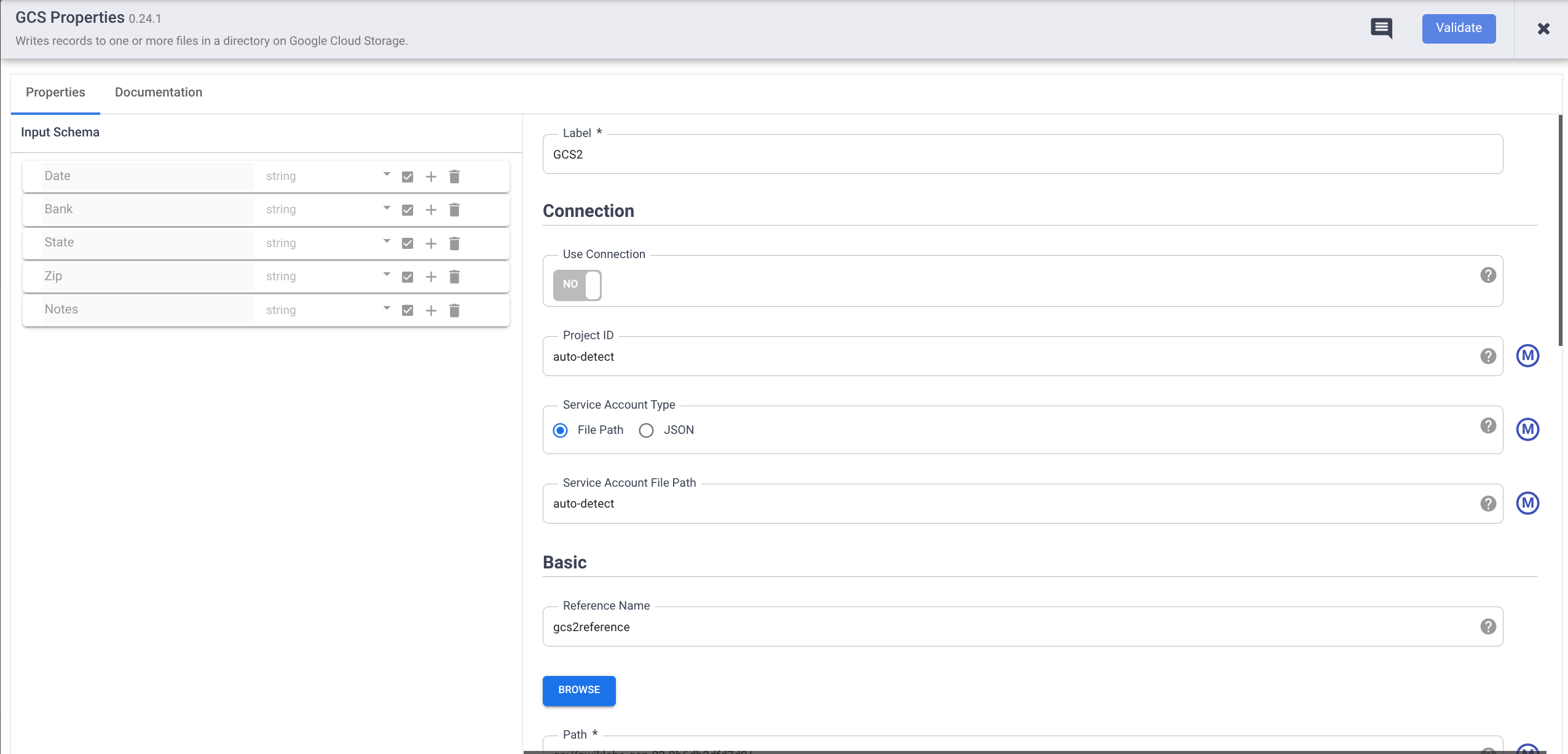
- Maintenez le pointeur sur le nœud GCS2, puis cliquez sur Properties (Propriétés).
- Sous Reference Name (Nom de référence), saisissez un nom de référence.
- Pour Path (Chemin d'accès), saisissez le chemin d'accès au bucket Cloud Storage que vous avez créé au début de cet atelier.
- Pour Format, sélectionnez CSV.
-
Cliquez sur Validate (Valider) pour vérifier qu'il n'y a pas d'erreurs.
-
Cliquez sur le bouton X dans l'angle supérieur droit de la boîte de dialogue.
Tâche 11 : Exécuter le pipeline en mode aperçu
Exécutez à présent le pipeline en mode aperçu avant de le déployer.
- Cliquez sur Preview (Aperçu), puis sur Run (Exécuter).

Le bouton Run (Exécuter) affiche l'état du pipeline, à savoir Starting (Démarrage), puis Stop (Arrêter) et enfin Run (Exécuter).
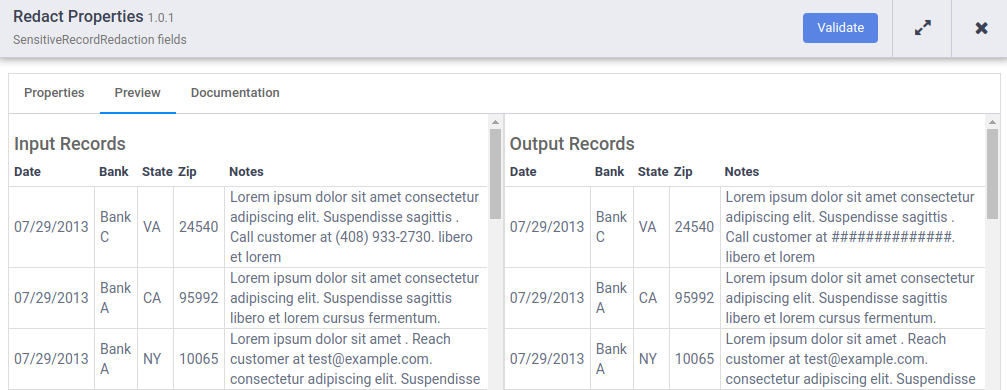
- Une fois l'exécution de l'aperçu terminée, sur le nœud Google DLP Redact (Masquer avec Google DLP), cliquez sur Preview Data (Prévisualiser les données) pour afficher un comparatif des données d'entrée et de sortie. Vérifiez que les numéros de téléphone ont été masqués à l'aide du caractère #.
 3. Cliquez sur le bouton X pour fermer Preview Data (Prévisualiser les données).
3. Cliquez sur le bouton X pour fermer Preview Data (Prévisualiser les données).
Remarque : Si vous ne voyez pas les numéros de téléphone dans la colonne Notes, pointez sur les entrées pour vérifier le résultat.
Tâche 12 : Masquer un autre type de données
Lors de l'examen des résultats d'exécution de l'aperçu, vous remarquez que d'autres informations sensibles apparaissent dans la colonne Notes, à savoir des adresses e-mail. Revenez en arrière et modifiez le modèle d'inspection Sensitive Data Protection pour masquer également les adresses e-mail.
-
Accédez à Sécurité > Sensitive Data Protection.
-
Dans l'onglet Configuration, sélectionnez votre modèle.
-
Cliquez sur Modifier.
-
Cliquez sur Gérer les infoTypes.
-
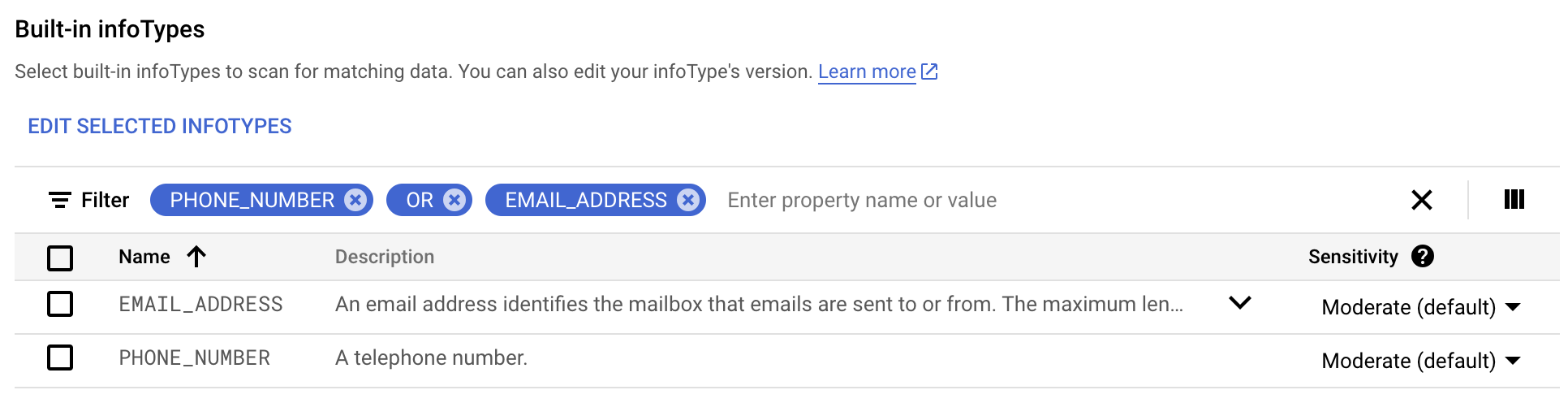
Dans l'onglet Intégrés, filtrez la recherche sur phone number (numéro de téléphone) OR (OU) mail address (adresse e-mail).
-
Sélectionnez tout, puis cliquez sur OK.
-
Cliquez sur Enregistrer.
-
Dans le pop-up, cliquez sur Confirmer l'enregistrement.
-
Exécutez à nouveau votre pipeline en mode aperçu. Cloud Data Fusion utilisera automatiquement le modèle Sensitive Data Protection mis à jour.
-
Vérifiez que les numéros de téléphone et les adresses e-mail ont été masqués à l'aide du caractère #.
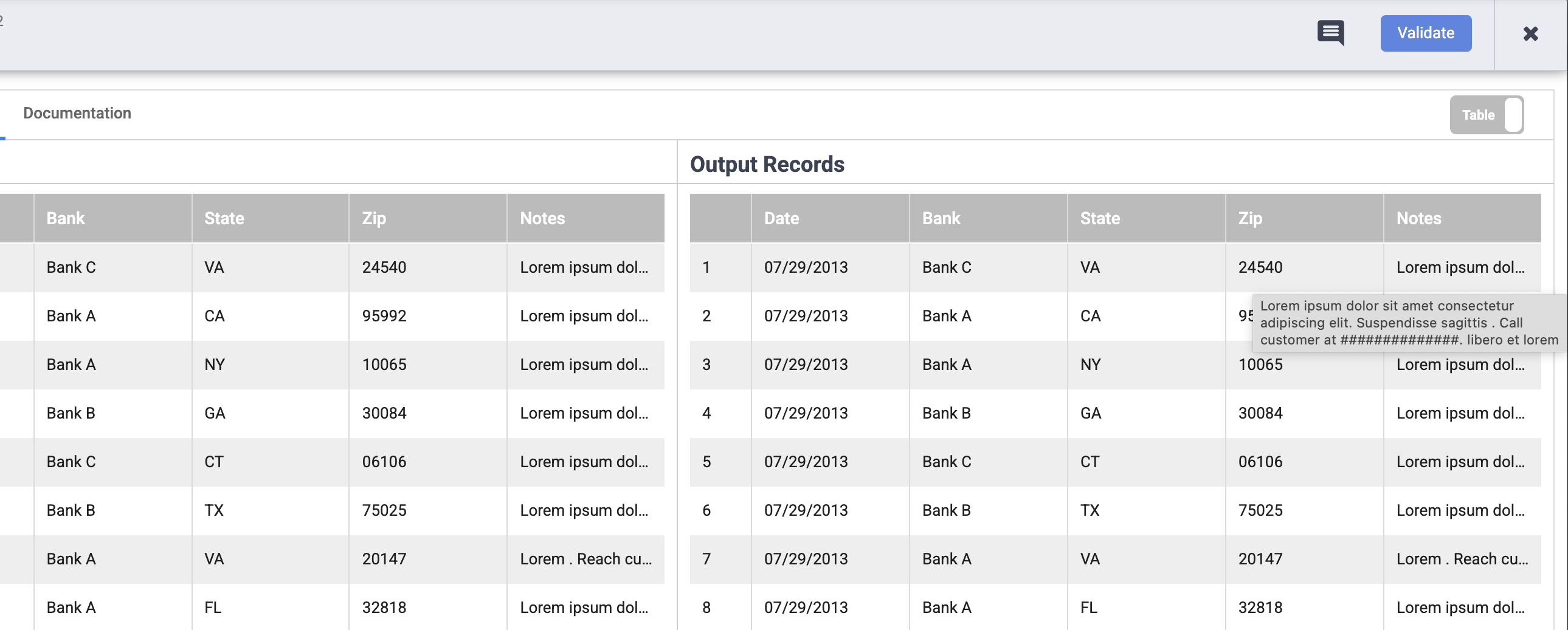
Remarque : Si vous ne voyez pas les numéros de téléphone et les adresses e-mail dans la colonne Notes, pointez sur les entrées pour vérifier le résultat.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Masquer un autre type de données
Tâche 13 : Déployer et exécuter le pipeline
-
Assurez-vous que le mode Preview (Aperçu) est décoché.
-
Cliquez sur Save (Enregistrer). Lorsque vous cliquez sur Save (Enregistrer), vous êtes invité à nommer votre pipeline. Nommez-le, puis cliquez sur Save (Enregistrer).
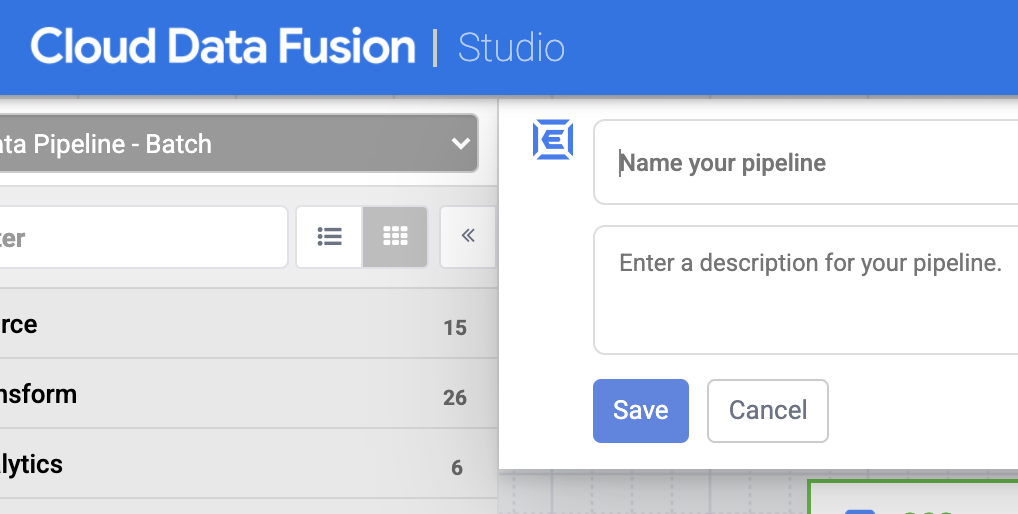
-
Cliquez sur Deploy (Déployer).
-
Une fois le déploiement terminé, cliquez sur Run (Exécuter). L'exécution de votre pipeline peut prendre quelques minutes. Pendant ce temps, vous pouvez observer le Status (État) du pipeline passer de Provisioning (Provisionnement) à Starting (Démarrage), puis à Running (En cours d'exécution) et enfin Succeeded (Succès).
Remarque : Si le pipeline échoue, réexécutez-le.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Déployer et exécuter le pipeline
Tâche 14 : Afficher les résultats
-
Dans la console Cloud, accédez à Cloud Storage.
-
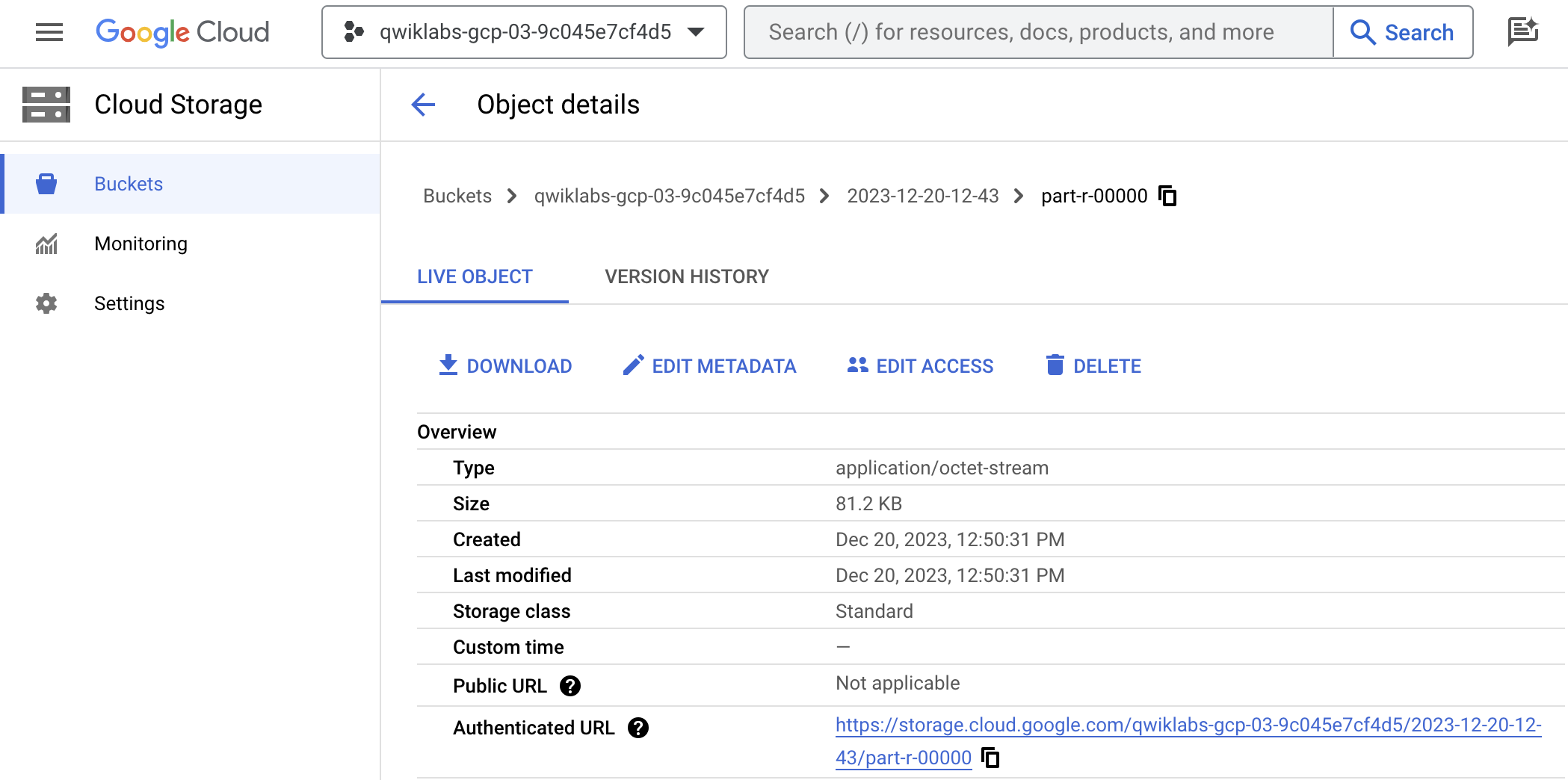
Dans le Navigateur de stockage, accédez au bucket Cloud Storage que vous avez spécifié dans les propriétés du plug-in récepteur Cloud Storage.
-
Dans URL authentifiée, copiez le lien et collez-le dans un nouvel onglet de navigateur pour télécharger le fichier CSV contenant les résultats. Vérifiez que les numéros de téléphone et les adresses e-mail ont été masqués à l'aide du caractère #.
Félicitations !
Dans cet atelier, vous avez appris à utiliser Sensitive Data Protection pour masquer certaines parties des données qui passent par le pipeline Data Fusion. Cela vous permet de supprimer ou de masquer les informations permettant d'identifier personnellement les utilisateurs qui figurent dans vos données avant de les partager avec votre audience.
Pour en savoir plus sur la création de modèles Sensitive Data Protection, consultez la documentation.
Dernière mise à jour du manuel : 9 décembre 2025
Dernier test de l'atelier : 9 décembre 2024
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.





