GSP812

Présentation
Dans cet atelier, vous allez découvrir comment utiliser Cloud Data Fusion pour explorer la traçabilité des données : leur origine et leur mouvement dans le temps.
La traçabilité des données Cloud Data Fusion vous aide à :
- détecter la cause des événements de données de mauvaise qualité ;
- effectuer une analyse d'impact avant de modifier les données.
Cloud Data Fusion fournit une traçabilité au niveau des ensembles de données et au niveau des champs, qui est temporalisée afin de montrer son évolution dans le temps.
- La traçabilité au niveau des ensembles de données indique la relation entre les ensembles de données et les pipelines dans un intervalle de temps sélectionné.
- La traçabilité au niveau des champs affiche les opérations effectuées sur un ensemble de champs présents dans l'ensemble de données source pour produire un autre ensemble de champs dans l'ensemble de données cible.
Pour cet atelier, vous allez utiliser deux pipelines qui illustrent un scénario type dans lequel des données brutes sont nettoyées, puis envoyées pour traitement en aval. La fonctionnalité de traçabilité Cloud Data Fusion permet d'explorer le parcours des données, des données brutes aux données de livraison nettoyées jusqu'aux résultats d'analyse.
Remarque : Actuellement, la fonctionnalité de traçabilité Cloud Data Fusion n'est disponible qu'avec l'édition Enterprise de Cloud Data Fusion.
Objectifs
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
- Exécuter des exemples de pipelines pour produire une traçabilité
- Explorer la traçabilité au niveau des ensembles de données et des champs
- Transmettre des informations de handshake du pipeline en amont au pipeline en aval
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
-
Connectez-vous à Google Skills dans une fenêtre de navigation privée.
-
Vérifiez le temps imparti pour l'atelier (par exemple : 02:00:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
-
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Remarque : Une fois que vous avez cliqué sur Démarrer l'atelier, il faut compter environ 15-20 minutes pour que les ressources nécessaires soient provisionnées et une instance Data Fusion créée.
Pendant ce temps, vous pouvez parcourir les étapes ci-dessous pour vous familiariser avec les objectifs de l'atelier.
Les identifiants pour l'atelier (Username (Nom d'utilisateur) et Password (Mot de passe)) s'afficheront dans le volet de gauche une fois l'instance créée. Vous pourrez alors vous connecter à la console.
-
Notez ces identifiants (Username (Nom d'utilisateur) et Password (Mot de passe)). Ils vous serviront à vous connecter à la console Google Cloud.
-
Cliquez sur Open Google Console (Ouvrir la console Google).
-
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
-
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Remarque : Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer. Votre travail et le projet seront alors supprimés.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, une boîte de dialogue s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous trouverez le panneau "Détails concernant l'atelier", qui contient les éléments suivants :
- Le bouton "Ouvrir la console Google Cloud"
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page "Se connecter" dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
-
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}}
Vous trouverez également le nom d'utilisateur dans le panneau "Détails concernant l'atelier".
-
Cliquez sur Suivant.
-
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}}
Vous trouverez également le mot de passe dans le panneau "Détails concernant l'atelier".
-
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. Ne saisissez pas ceux de votre compte Google Cloud.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés.
-
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Pour accéder aux produits et services Google Cloud, cliquez sur le menu de navigation ou saisissez le nom du service ou du produit dans le champ Recherche.

Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient des outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Google Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud. gcloud est l'outil de ligne de commande associé à Google Cloud. Il est préinstallé sur Cloud Shell et permet la saisie semi-automatique via la touche Tabulation.
-
Dans Google Cloud Console, dans le volet de navigation, cliquez sur Activer Cloud Shell ( ).
).
-
Cliquez sur Continuer.
Le provisionnement et la connexion à l'environnement prennent quelques instants. Une fois connecté, vous êtes en principe authentifié, et le projet est défini sur votre ID_PROJET. Exemple :

Exemples de commandes
gcloud auth list
(Résultat)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Exemple de résultat)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Résultat)
[core]
project = <ID_Projet>
(Exemple de résultat)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Vérifier les autorisations du projet
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
-
Dans la console Google Cloud, accédez au menu de navigation ( ), puis cliquez sur IAM et administration > IAM.
), puis cliquez sur IAM et administration > IAM.
-
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle Éditeur. Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation Cloud.

Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle Éditeur, procédez comme suit pour lui attribuer le rôle approprié.
-
Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation Cloud.
-
Sur la carte Informations sur le projet, copiez le numéro du projet.
-
Dans le menu de navigation, cliquez sur IAM et administration > IAM.
-
En haut de la page IAM, cliquez sur Ajouter.
-
Dans le champ Nouveaux comptes principaux, saisissez :
{project-number}-compute@developer.gserviceaccount.com
Remplacez {project-number} par le numéro de votre projet.
-
Dans le champ Sélectionnez un rôle, sélectionnez De base (ou Projet) > Éditeur.
-
Cliquez sur Enregistrer.
Prérequis
Dans cet atelier, vous allez utiliser deux pipelines :
- Le pipeline Shipment Data Cleansing (Nettoyage des données de livraison), qui lit les données de livraison brutes d'un petit exemple d'ensemble de données et applique des transformations pour nettoyer les données
- Le pipeline Delayed Shipments USA (Retards de livraison aux États-Unis), qui lit les données de livraison nettoyées, les analyse et identifie les retards de livraison aux États-Unis qui dépassent un certain seuil
Cliquez sur les liens Shipment Data Cleansing (Nettoyage des données de livraison) et Delayed Shipments USA (Retards de livraison aux États-Unis) pour télécharger ces exemples d'ensembles de données sur votre ordinateur local.
Tâche 1 : Ajouter les autorisations nécessaires pour votre instance Cloud Data Fusion
- Dans la barre de titre de la console Google Cloud, saisissez Data Fusion dans le champ Recherche, puis cliquez sur Data Fusion dans les résultats de recherche. Cliquez sur Instances.
Remarque : La création de l'instance prend environ 20 minutes. Attendez qu'elle soit prête avant de continuer.
Vous allez à présent accorder des autorisations au compte de service associé à l'instance en suivant les étapes ci-dessous.
-
Dans la console Google Cloud, accédez à IAM et Administration > IAM.
-
Vérifiez que le compte de service par défaut Compute Engine {project-number}-compute@developer.gserviceaccount.com est présent, puis copiez le Compte de service dans votre presse-papiers.
-
Sur la page des autorisations IAM, cliquez sur +Accorder l'accès.
-
Collez le compte de service dans le champ "Nouveaux principaux".
-
Cliquez dans le champ Sélectionner un rôle et commencez à saisir Agent de service de l'API Cloud Data Fusion, puis sélectionnez ce rôle lorsqu'il apparaît.
-
Cliquez sur AJOUTER UN AUTRE RÔLE.
-
Ajoutez le rôle Administrateur Managed Service for Spark.
-
Cliquez sur Enregistrer.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Ajouter le rôle Agent de service de l'API Cloud Data Fusion au compte de service
Accorder l'autorisation Utilisateur du compte de service
-
Dans la console, accédez au menu de navigation et cliquez sur IAM et administration > IAM.
-
Cochez la case Inclure les attributions de rôles fournies par Google.
-
Faites défiler la liste jusqu'au compte de service Cloud Data Fusion géré par Google semblable à service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com. Copiez le nom du compte de service dans votre presse-papiers.

-
Ensuite, accédez à IAM et administration > Comptes de service.
-
Cliquez sur le compte Compute Engine par défaut, semblable à {project-number}-compute@developer.gserviceaccount.com, et sélectionnez l'onglet Comptes principaux avec accès dans la barre de navigation supérieure.
-
Cliquez sur le bouton Accorder l'accès.
-
Dans le champ Nouveaux comptes principaux, collez le nom du compte de service que vous avez copié plus tôt.
-
Dans le menu déroulant Rôle, sélectionnez Utilisateur du compte de service.
-
Cliquez sur Enregistrer.
Tâche 2 : Ouvrir l'UI de Cloud Data Fusion
-
Accédez à Data Fusion, cliquez sur Instances, puis sur le lien Afficher l'instance à côté de votre instance Data Fusion. Pour vous connecter, utilisez les identifiants qui vous ont été attribués pour cet atelier. Si vous êtes invité à découvrir le service, cliquez sur Non, merci. L'UI Cloud Data Fusion s'ouvre.
-
Cliquez sur Studio dans le panneau de navigation de gauche pour ouvrir la page Studio de Cloud Data Fusion.
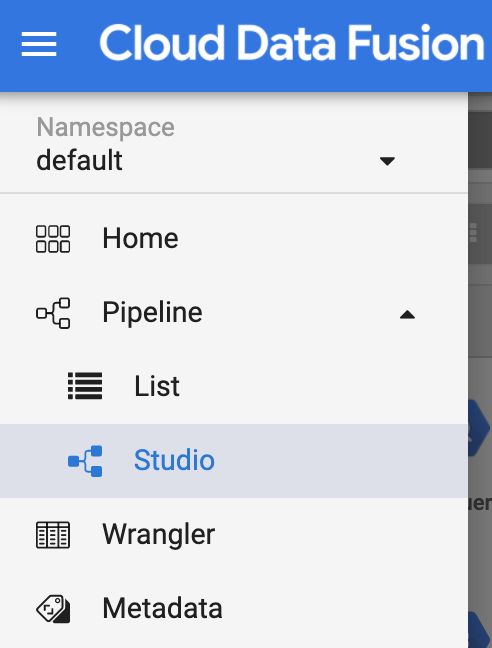
Tâche 3 : Importer, déployer et exécuter le pipeline Shipment Data Cleansing (Nettoyage des données de livraison)
- Vous devez à présent importer les données de livraison brutes. Cliquez sur Import (Importer) en haut à droite de la page "Studio", puis sélectionnez et importez le pipeline Shipment Data Cleansing (Nettoyage des données de livraison) que vous avez téléchargé plus tôt.
Remarque : Si un pop-up vous invite à mettre à niveau les plug-ins du pipeline, cliquez sur Fix All (Tout corriger) afin de mettre à niveau les plug-ins vers les dernières versions.
-
Déployez maintenant le pipeline. Cliquez sur Deploy (Déployer) en haut à droite de la page Studio. Après le déploiement, la page Pipeline s'ouvre.
-
Cliquez sur Run (Exécuter) en haut au centre de la page "Pipeline" pour exécuter le pipeline.
Remarque : Si le pipeline échoue, exécutez-le à nouveau.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Importer, déployer et exécuter le pipeline Shipment Data Cleansing (Nettoyage des données de livraison)
Tâche 4 : Importer, déployer et exécuter le pipeline de données Delayed Shipments USA (Retards de livraison aux États-Unis)
Une fois que le pipeline Shipment Data Cleansing (Nettoyage des données de livraison) est à l'état Succeeded (Succès), importez et déployez le pipeline de données Delayed Shipments USA (Retards de livraison aux États-Unis) que vous avez téléchargé plus tôt.
-
Cliquez sur Studio dans le panneau de navigation de gauche pour revenir à la page Studio de Cloud Data Fusion.
-
Cliquez sur Import (Importer) en haut à droite de la page "Studio", puis sélectionnez et importez le pipeline Delayed Shipments USA (Retards de livraison aux États-Unis) que vous avez téléchargé plus tôt.
Remarque : Si un pop-up vous invite à mettre à niveau les plug-ins du pipeline, cliquez sur Fix All (Tout corriger) afin de mettre à niveau les plug-ins vers les dernières versions.
-
Déployez le pipeline en cliquant sur Deploy (Déployer) en haut à droite de la page Studio. Après le déploiement, la page Pipeline s'ouvre.
-
Cliquez sur Run (Exécuter) en haut au centre de la page "Pipeline" pour exécuter le pipeline.
Remarque : Si le pipeline échoue, exécutez-le à nouveau.
Une fois ce deuxième pipeline terminé, vous pouvez continuer et effectuer les étapes restantes ci-dessous.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Importer, déployer et exécuter le pipeline de données Delayed Shipments USA (Retards de livraison aux États-Unis)
Tâche 5 : Découvrir des ensembles de données
Vous devez découvrir un ensemble de données avant d'explorer sa traçabilité.
- Dans le panneau de navigation situé à gauche dans l'UI de Cloud Data Fusion, sélectionnez Metadata (Métadonnées) pour ouvrir la page de recherche de métadonnées.
- Étant donné que l'ensemble de données Shipment Data Cleansing (Nettoyage des données de livraison) spécifiait "Cleaned-Shipments" (Livraisons-Nettoyées) comme ensemble de données de référence, saisissez
shipment (livraison) dans le champ de recherche. Les résultats de recherche incluent cet ensemble de données.
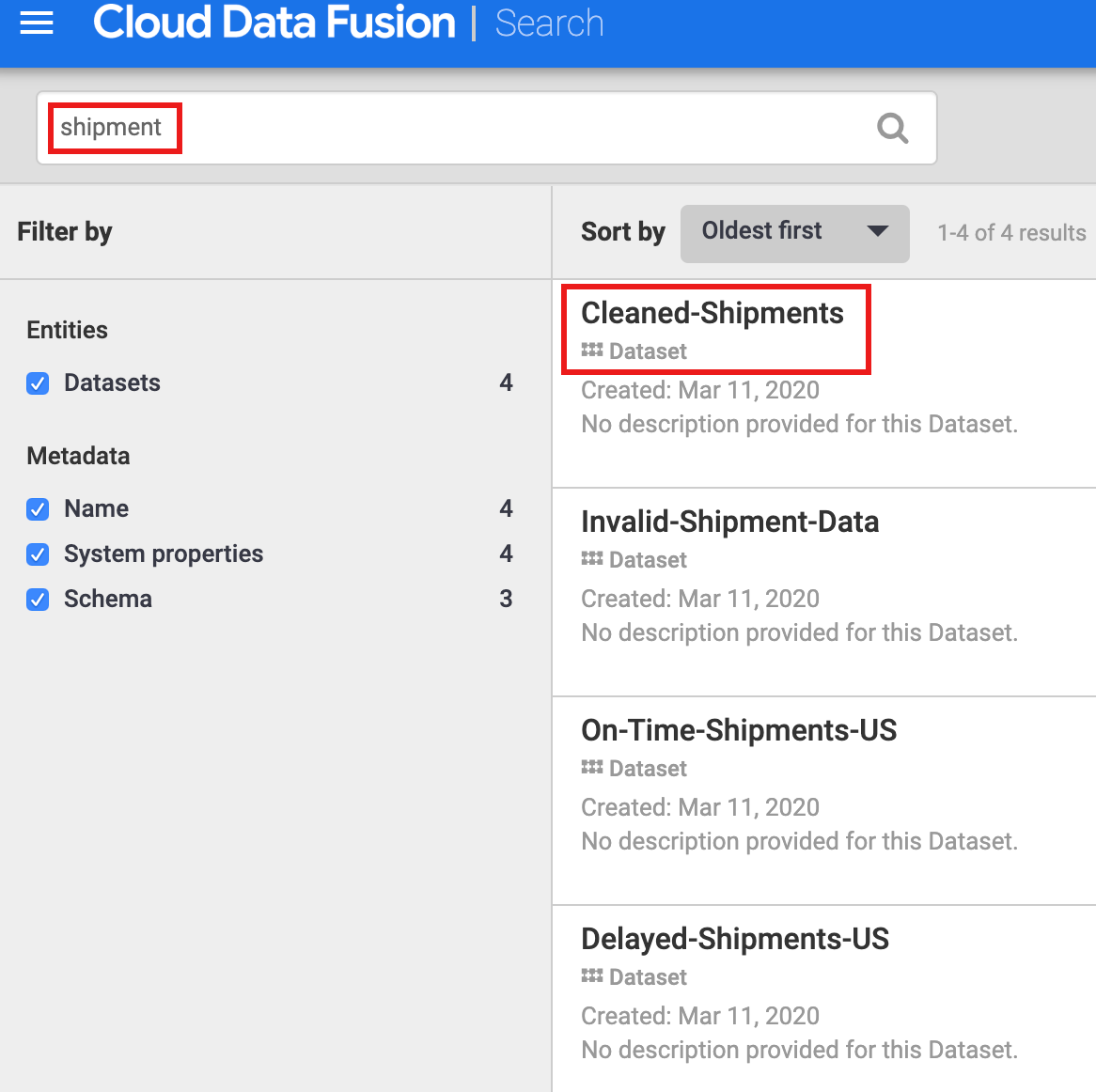
Tâche 6 : Utiliser des tags pour découvrir des ensembles de données
Une recherche de métadonnées découvre des ensembles de données qui ont été utilisés, traités ou générés par des pipelines Cloud Data Fusion. Les pipelines s'exécutent sur un framework structuré qui génère et collecte des métadonnées techniques et opérationnelles. Les métadonnées techniques incluent le nom, le type, le schéma, les champs, l'heure de création et les informations de traitement de l'ensemble de données. Ces informations techniques sont utilisées par les fonctionnalités de recherche et de traçabilité des métadonnées Cloud Data Fusion.
Bien que le nom de référence des sources et récepteurs soit un identifiant d'ensemble de données unique et un excellent terme de recherche, vous pouvez utiliser d'autres métadonnées techniques comme critères de recherche, comme une description, un schéma, un nom de champ ou un préfixe de métadonnées.
Cloud Data Fusion accepte également l'annotation d'ensembles de données avec des métadonnées métier, telles que des tags et des propriétés clé-valeur, qui peuvent être utilisées comme critères de recherche. Par exemple, pour ajouter et rechercher une annotation de tag métier sur l'ensemble de données Raw Shipping Data (Données de livraison brutes) :
-
Dans le panneau de navigation situé à gauche dans l'UI de Cloud Data Fusion, sélectionnez Metadata (Métadonnées) pour ouvrir la page de recherche de métadonnées.
-
Saisissez Raw shipping data (Données de livraison brutes) dans la page de recherche de l'option de métadonnées.
-
Cliquez sur Raw_Shipping_Data (Données_Livraison_Brutes).
-
Sous Business tags (Tags métier), cliquez sur +, puis insérez un nom de tag (les caractères alphanumériques et le trait de soulignement sont autorisés) et appuyez sur Entrée.
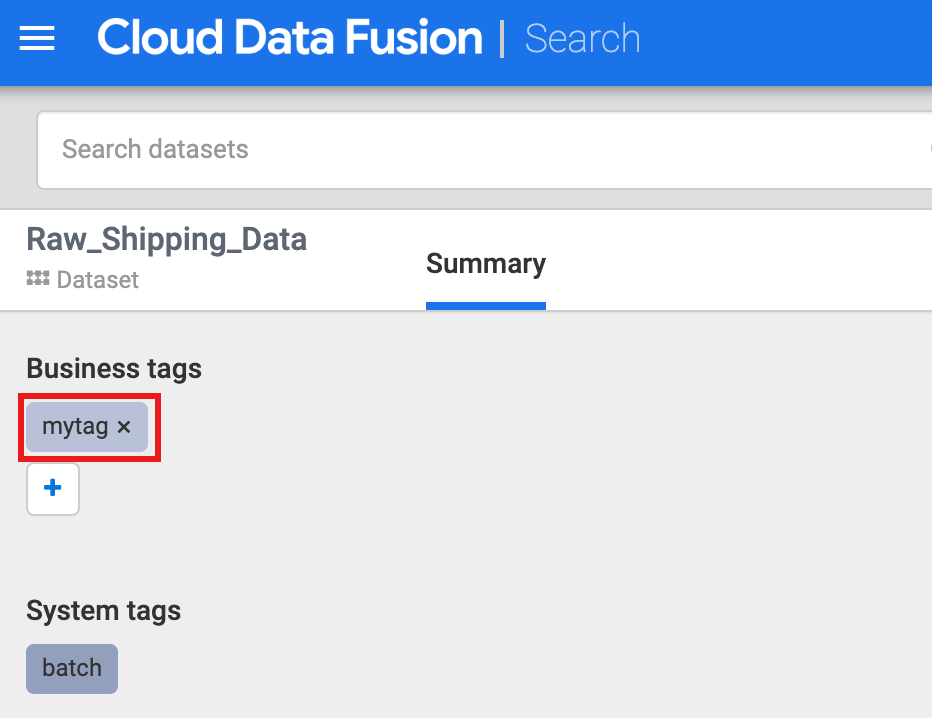
Vous pouvez effectuer une recherche par tag en cliquant sur le nom du tag ou en saisissant tags: tag_name (nom_du_tag) dans le champ de recherche de la page de recherche Metadata (Métadonnées).
Tâche 7 : Explorer la traçabilité des données
Traçabilité au niveau des ensembles de données
-
Dans le panneau de navigation situé à gauche dans l'UI de Cloud Data Fusion, sélectionnez Metadata (Métadonnées) pour ouvrir la page de recherche de métadonnées, puis saisissez shipment (livraison) dans le champ de recherche.
-
Cliquez sur le nom de l'ensemble de données Cleaned-Shipments (Livraisons-Nettoyées) listé sur la page de recherche.
-
Cliquez ensuite sur l'onglet Lineage (Traçabilité). Le graphique de traçabilité indique que cet ensemble de données a été généré par le pipeline "Shipments-Data-Cleansing" (Nettoyage-Données-Livraison), qui avait utilisé l'ensemble de données Raw_Shipping_Data (Données_Livraison_Brutes).
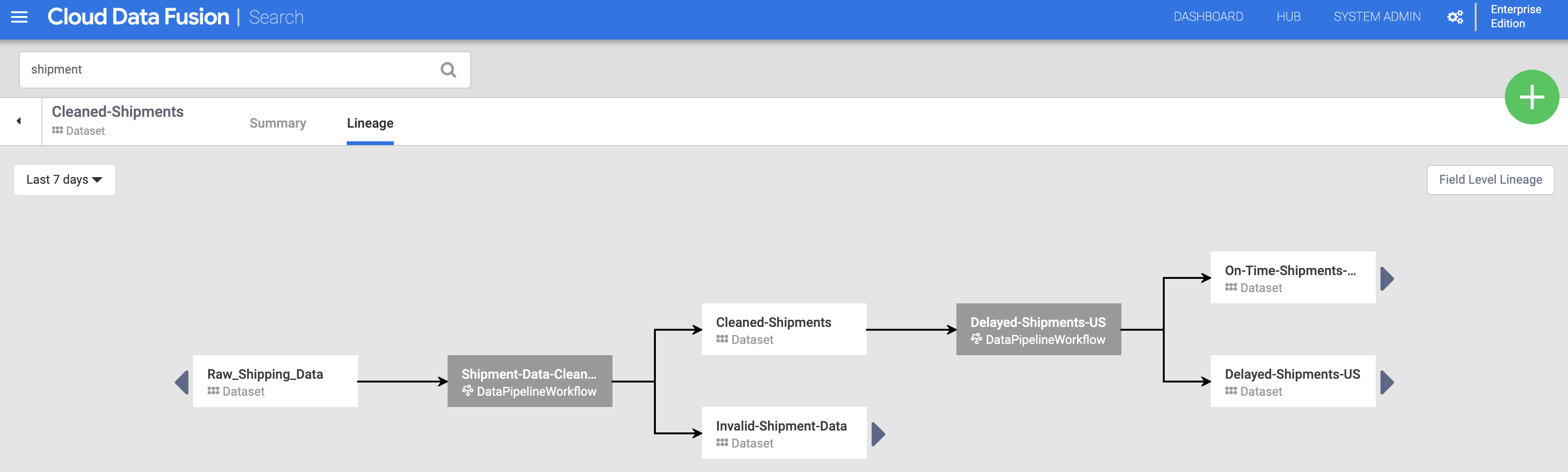
Traçabilité au niveau des champs
La traçabilité au niveau des champs de Cloud Data Fusion montre la relation entre les champs d'un ensemble de données et les transformations effectuées sur un ensemble de champs pour produire un autre ensemble de champs. Comme pour la traçabilité au niveau des ensembles de données, la traçabilité au niveau des champs est temporalisée et ses résultats évoluent avec le temps.
- En reprenant depuis l'étape de traçabilité au niveau des ensembles de données, cliquez sur le bouton Field Level Lineage (Traçabilité au niveau des champs) situé en haut à droite du graphique de traçabilité au niveau de l'ensemble de données Cleaned-Shipments (Livraisons-Nettoyées) pour afficher le graphique de traçabilité au niveau des champs.
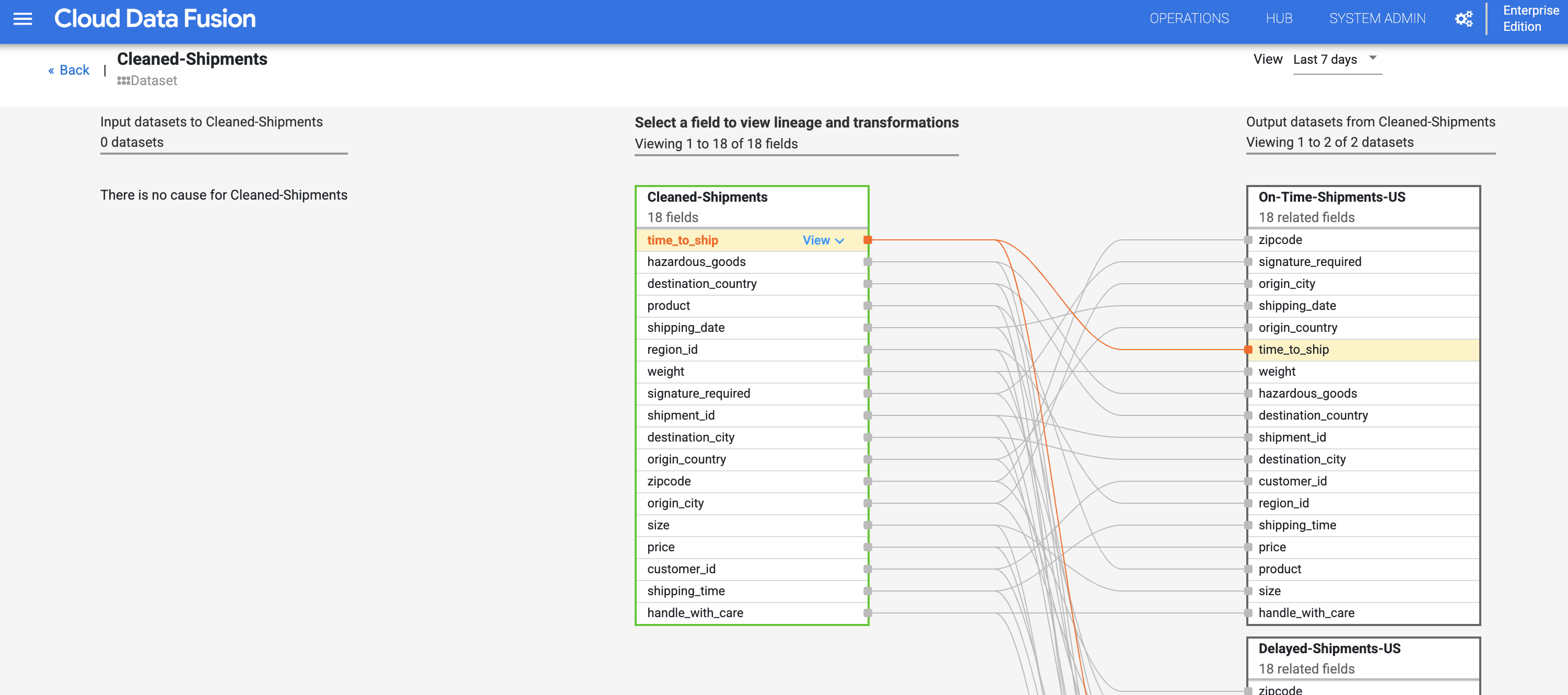
- Le graphique de traçabilité au niveau des champs affiche les connexions entre les champs. Vous pouvez sélectionner un champ pour afficher sa traçabilité. Sélectionnez View (Afficher), puis Pin field (Épingler le champ) pour afficher uniquement la traçabilité de ce champ.
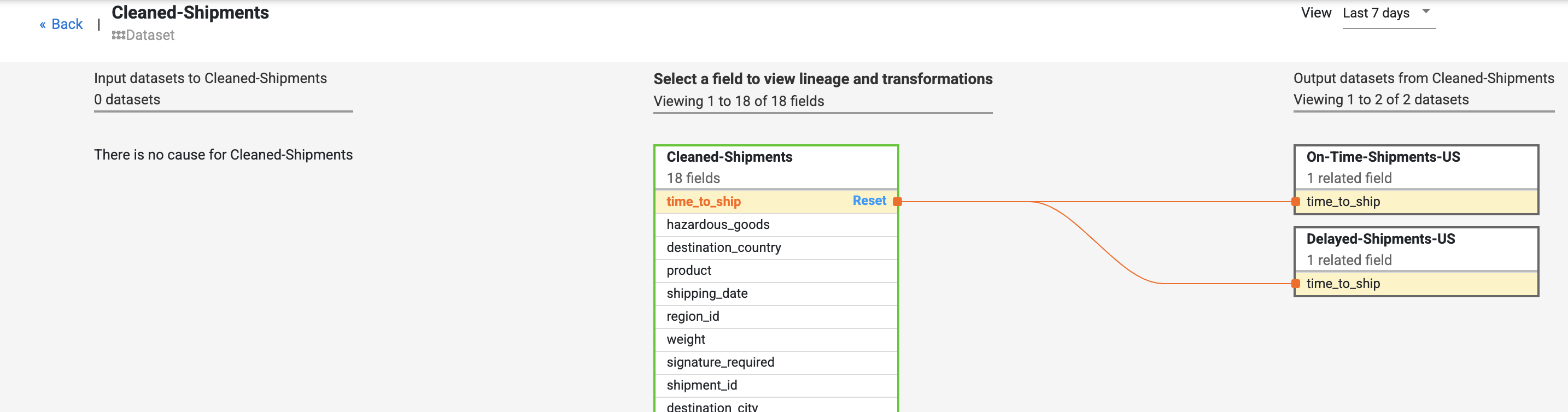
- Localisez le champ time_to_ship (délai_de_livraison) dans l'ensemble de données Cleaned-Shipments (Livraisons-Nettoyées), sélectionnez View (Afficher), puis View l'impact (Voir l'impact) pour effectuer une analyse d'impact.

La traçabilité au niveau des champs montre les transformations d'un champ dans le temps. Notez les transformations du champ time_to_ship (délai_de_livraison) : (i) conversion en colonne de type float, (ii) détermination de la redirection de la valeur vers le nœud suivant ou vers le chemin d'erreur.
La traçabilité expose l'historique des modifications apportées à un champ particulier. Par exemple, vous pouvez concaténer plusieurs champs pour en créer un nouveau (comme first name (prénom) et last name (nom de famille) pour créer le champ name (nom)) ou effectuer des calculs sur un champ (comme convertir un nombre en pourcentage par rapport au nombre total).
Les liens de cause et d'impact indiquent les transformations effectuées des deux côtés d'un champ dans un format lisible.
Félicitations !
Dans cet atelier, vous avez appris à explorer la traçabilité de vos données. Ces informations peuvent être essentielles pour la création de rapports et la gouvernance. Elles peuvent aider différentes audiences à comprendre comment les données ont évolué jusqu'à leur état actuel.
Dernière mise à jour du manuel : 14 novembre 2022
Dernier test de l'atelier : 8 août 2023
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.





