Mettez en pratique vos compétences dans la console Google Cloud
Points de contrôle
Create BigQuery dataset and tables
Vérifier ma progression
/ 20
Load data into event table
Vérifier ma progression
/ 20
Create nested and repeated fields
Vérifier ma progression
/ 20
Create partitioned tables
Vérifier ma progression
/ 20
Create clustered tables
Vérifier ma progression
/ 20
Instructions et exigences de configuration de l'atelier
Protégez votre compte et votre progression. Utilisez toujours une fenêtre de navigation privée et les identifiants de l'atelier pour exécuter cet atelier.
Concevoir des schémas de tables BigQuery pour les utilisateurs professionnels de Snowflake
Ce contenu n'est pas encore optimisé pour les appareils mobiles.
Pour une expérience optimale, veuillez accéder à notre site sur un ordinateur de bureau en utilisant un lien envoyé par e-mail.
Présentation
Dans BigQuery, vous organisez les données en ensembles de données BigQuery et définissez le schéma (c'est-à-dire la structure) de chaque table à l'aide de noms de colonnes et de types de données. Ces schémas peuvent avoir une incidence sur le coût et les performances des requêtes, car ils déterminent la rapidité et l'efficacité avec lesquelles BigQuery peut accéder aux données d'une table et les traiter. BigQuery accepte les schémas flexibles, et vous pouvez les modifier sans avoir à réécrire les données.
Cet atelier vise à fournir aux utilisateurs professionnels de Snowflake les connaissances et les compétences nécessaires pour commencer à concevoir et à implémenter des schémas de tables BigQuery efficaces. Au terme de l'atelier, vous aurez une meilleure compréhension de la façon dont vous pouvez concevoir, optimiser et interroger les schémas de tables dans BigQuery.
Dans cet atelier, vous allez créer des ensembles de données et des tables BigQuery pour stocker des données, créer des champs imbriqués et répétés afin de maintenir les relations dans les données dénormalisées, et créer des tables partitionnées et groupées pour optimiser les performances des requêtes.
créer des ensembles de données et des tables dans BigQuery ;
créer et interroger des champs imbriqués et répétés dans BigQuery ;
créer des tables partitionnées et les interroger dans BigQuery ;
créer des tables groupées et les interroger dans BigQuery.
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Google Skills dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pourrez pas le mettre sur pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à la console Google Cloud.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront facturés.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Démarrer votre atelier et vous connecter à la console
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous verrez un panneau contenant les identifiants temporaires à utiliser pour cet atelier.
Copiez le nom d'utilisateur, puis cliquez sur Ouvrir la console Google.
L'atelier lance les ressources, puis la page Sélectionner un compte dans un nouvel onglet.
Remarque : Ouvrez les onglets dans des fenêtres distinctes, placées côte à côte.
Sur la page "Sélectionner un compte", cliquez sur Utiliser un autre compte. La page de connexion s'affiche.
Collez le nom d'utilisateur que vous avez copié dans le panneau "Détails de connexion". Copiez et collez ensuite le mot de passe.
Remarque : Vous devez utiliser les identifiants fournis dans le panneau "Détails de connexion", et non ceux de votre compte Google Skills. Si vous possédez un compte Google Cloud, ne vous en servez pas pour cet atelier (vous éviterez ainsi que des frais vous soient facturés).
Accédez aux pages suivantes :
Acceptez les conditions d'utilisation.
N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
Ne vous inscrivez pas aux essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Vous pouvez afficher le menu qui contient la liste des produits et services Google Cloud en cliquant sur le menu de navigation en haut à gauche.
Tâche 1 : Créer un ensemble de données et des tables BigQuery
Dans BigQuery, vous pouvez utiliser le langage de définition de données (LDD) pour créer des ensembles de données et des tables. L'instruction SQL LOAD DATA vous permet quant à elle de charger les données d'un ou de plusieurs fichiers dans une table nouvelle ou existante.
Pour en savoir plus sur l'utilisation des instructions LDD pour créer des ensembles de données et des tables BigQuery, ainsi que sur l'utilisation de l'instruction SQL LOAD DATA pour charger des données, consultez la documentation sur les instructions CREATE SCHEMA, CREATE TABLE et LOAD DATA.
Dans cette tâche, vous allez utiliser des instructions LDD pour créer un ensemble de données et des tables dans BigQuery, puis charger des données dans ces nouvelles tables à l'aide de l'instruction LOAD DATA.
Dans la console Google Cloud, accédez au menu de navigation (), puis sous "Analyse", cliquez sur BigQuery.
Le message "Bienvenue sur BigQuery dans la console Cloud" s'affiche. Il contient un lien vers le guide de démarrage rapide et les notes de version.
Cliquez sur OK.
Dans la barre d'outils de l'espace de travail SQL, cliquez sur l'icône Éditeur pour ouvrir l'éditeur de requête SQL.
Copiez la requête suivante et collez-la dans l'éditeur de requête, puis cliquez sur Exécuter :
CREATE SCHEMA IF NOT EXISTS
ticket_sales OPTIONS(
location="us");
Cette requête crée un ensemble de données BigQuery nommé ticket_sales. Notez que l'instruction LDD utilise le terme "SCHEMA" pour désigner une collection logique de tables, de vues et d'autres ressources, ce qui correspond à un "ensemble de données" dans BigQuery.
Développez le volet "Explorateur" (à gauche) qui liste l'ensemble de données, puis cliquez sur le nom de l'ensemble de données ticket_sales pour confirmer qu'il a bien été créé.
Dans l'éditeur de requête, exécutez la requête suivante :
Cette requête utilise une définition explicite du schéma de table pour charger des données dans la table sales à partir d'un fichier CSV dans Cloud Storage.
Le volet Résultats affiche un message indiquant que l'instruction LOAD s'est exécutée correctement.
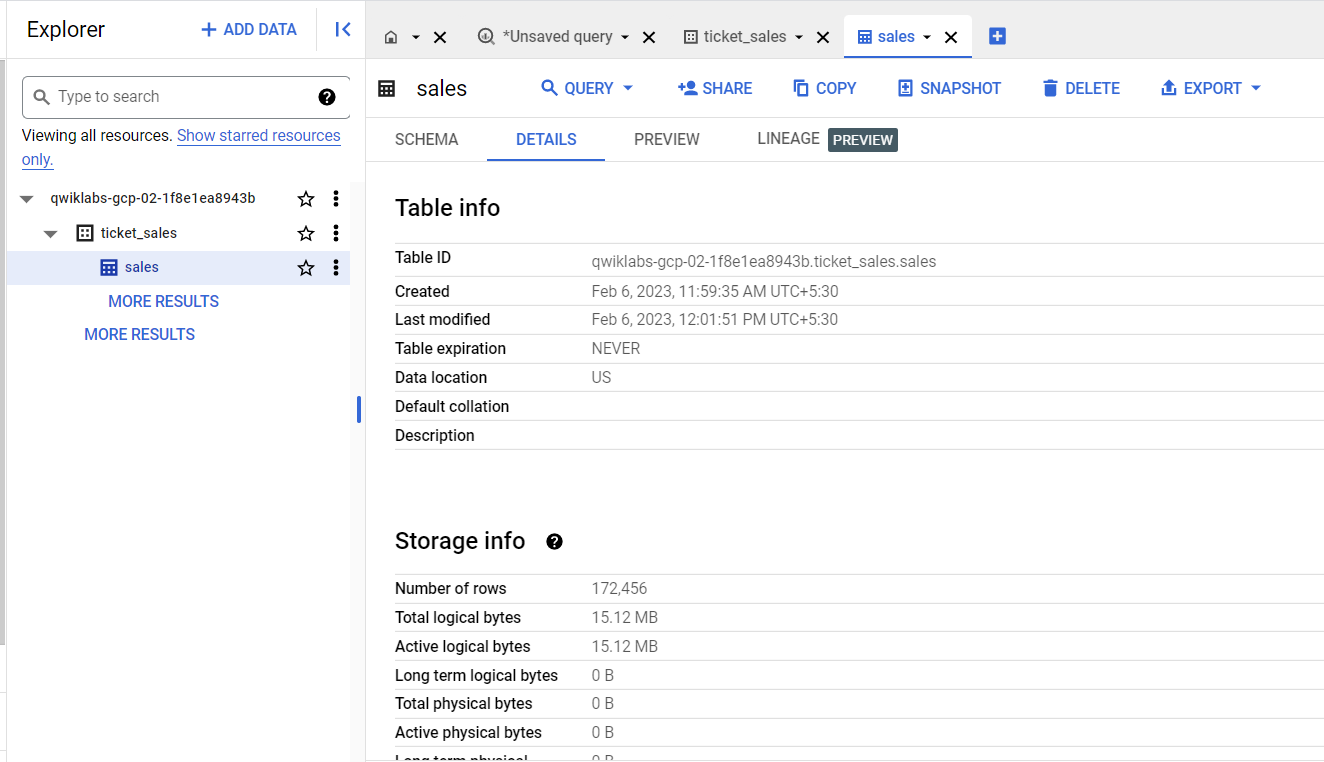
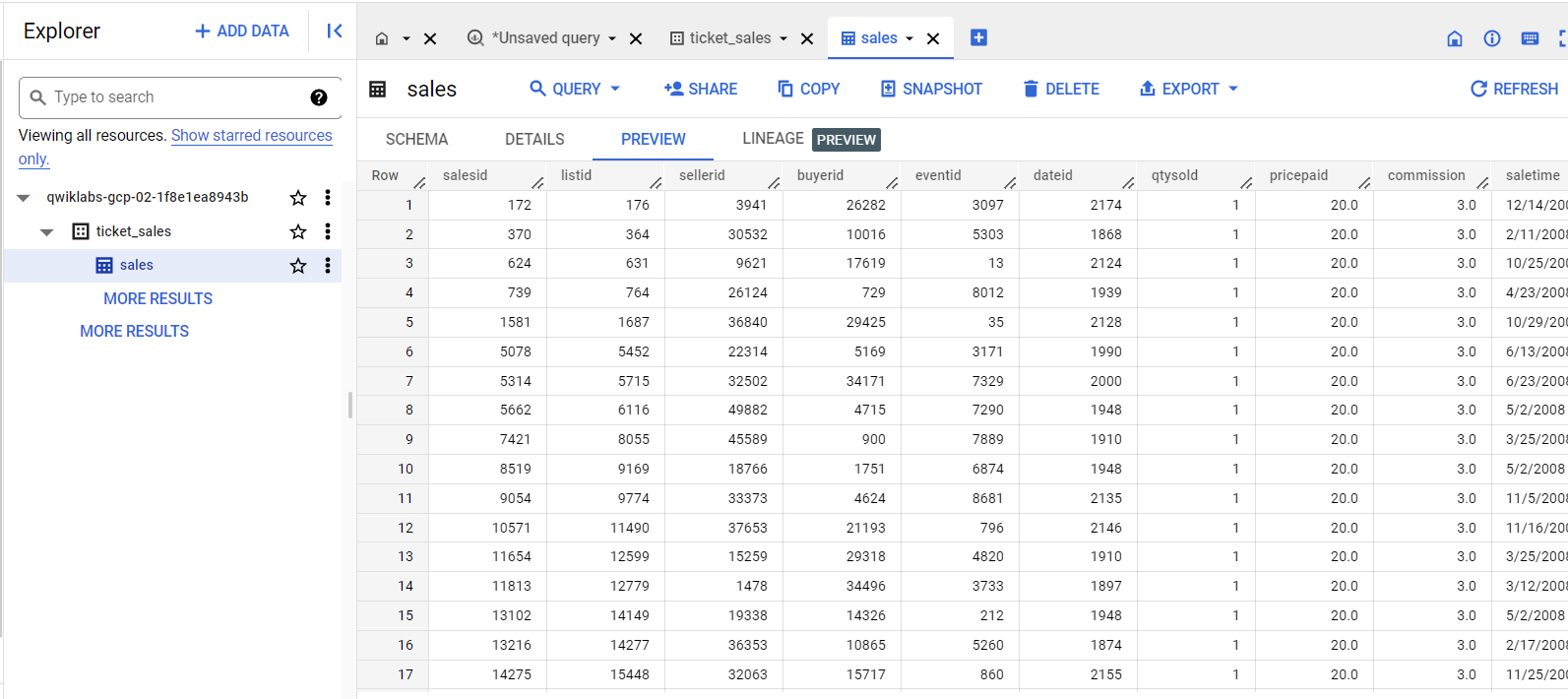
Dans le volet "Explorateur", cliquez sur les onglets Détails et Aperçu pour vérifier que les données ont été chargées dans la table sales.
Vous pouvez cliquer sur Actualiser (en haut à droite) pour mettre à jour les données dans l'onglet Aperçu.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer un ensemble de données et des tables BigQuery
Vous avez utilisé des instructions SQL dans BigQuery pour créer un ensemble de données et une table, puis y charger des données. Vous allez à présent créer une autre table et y charger des données contenant les informations sur les événements.
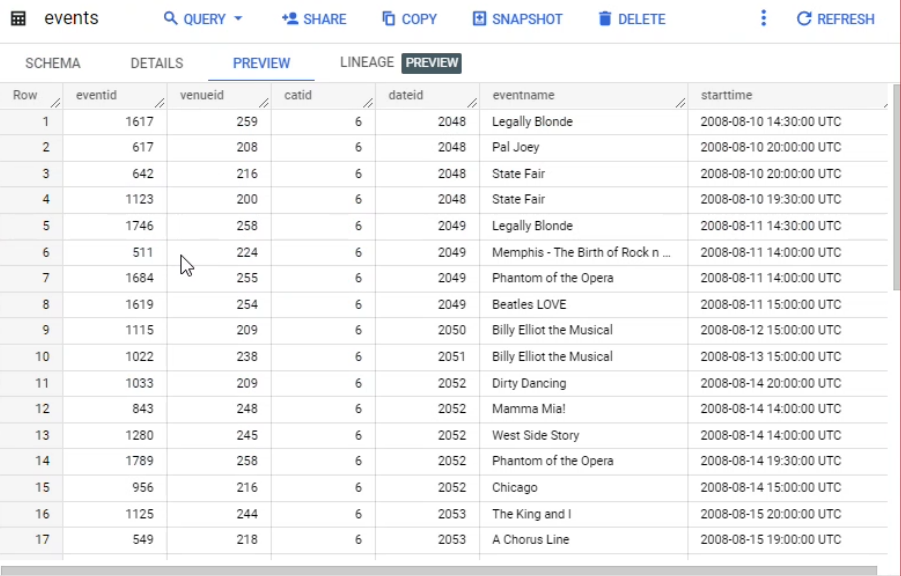
Dans l'éditeur de requête, exécutez la requête suivante pour créer une table nommée events :
Examinez le volet Explorateur et vérifiez qu'il contient désormais deux tables : sales et events.
Dans l'éditeur de requête, exécutez la requête suivante pour charger des données dans la table events :
LOAD DATA INTO ticket_sales.events
FROM FILES (
skip_leading_rows=1,
format = 'CSV',
field_delimiter = ',',
max_bad_records = 10,
uris =['gs://tcd_repo/data/entertainment_media/ticket-sales/events.csv']);
Cette requête utilise la détection automatique de schéma pour charger des données dans la table events à partir d'un fichier CSV dans Cloud Storage.
Le volet Résultats affiche un message indiquant que l'instruction LOAD s'est exécutée correctement.
Cliquez sur les onglets Détails et Aperçu pour vérifier que les données ont été chargées dans la table events.
Vous pouvez cliquer sur Actualiser (en haut à droite) pour mettre à jour les données dans l'onglet Aperçu.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Charger des données dans la table d'événements
Tâche 2 : Créer et interroger des champs imbriqués et répétés
La dénormalisation est une stratégie courante qui permet d'améliorer les performances de lecture sur des ensembles de données relationnels auparavant normalisés. Dans BigQuery, la méthode recommandée pour dénormaliser des données consiste à utiliser des champs imbriqués et répétés. Ces éléments vous permettent de maintenir les relations dans des données dénormalisées sans avoir à aplatir complètement vos données.
Dans cette tâche, vous allez apprendre à créer et à interroger des champs imbriqués et répétés dans BigQuery.
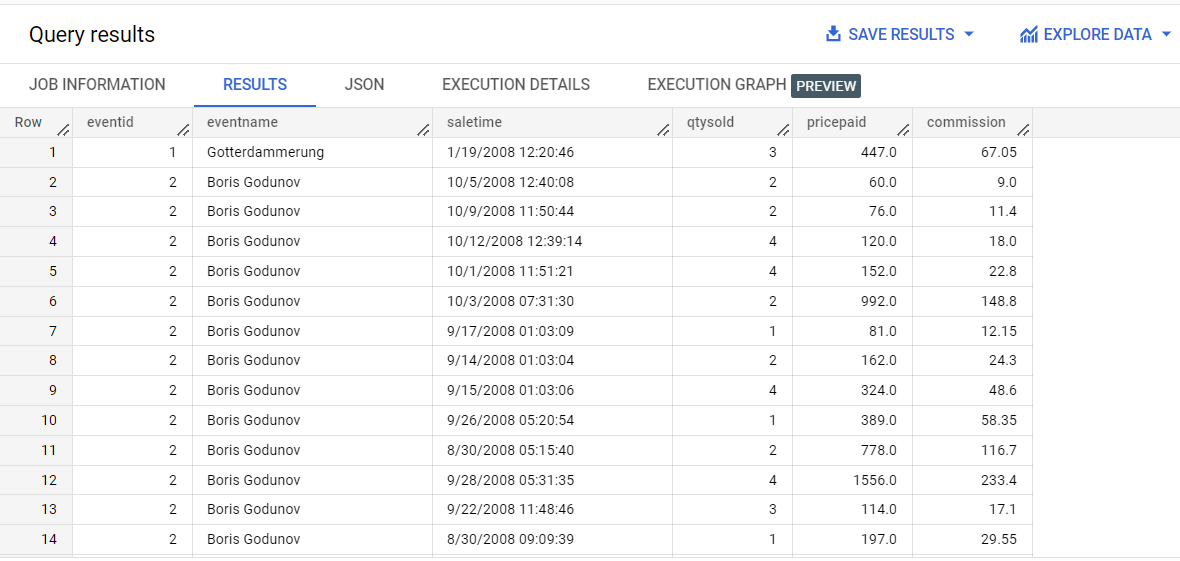
Dans l'éditeur de requête, exécutez la requête suivante :
SELECT
e.eventid,
e.eventname,
s.saletime,
s.qtysold,
s.pricepaid,
s.commission
FROM
ticket_sales.events e
JOIN
ticket_sales.sales s
ON
e.eventid = s.eventid
ORDER BY
eventid, eventname;
Remarque : Il existe une relation de type un à plusieurs entre la table "events" et la table "sales". Lorsque vous exécutez cette requête, vous constatez une répétition du côté "un" de cette relation : pour chaque vente, l'événement est répété. Vous pouvez y remédier en regroupant les données de ventes dans un tableau.
Dans l'éditeur de requête, exécutez la requête suivante :
SELECT
e.eventid,
e.eventname,
ARRAY_AGG(STRUCT(
s.saletime,
s.qtysold,
s.pricepaid,
s.commission)) as sales
FROM
ticket_sales.events e
JOIN
ticket_sales.sales s
ON
e.eventid = s.eventid
GROUP BY
eventid, eventname
ORDER BY
eventid, eventname;
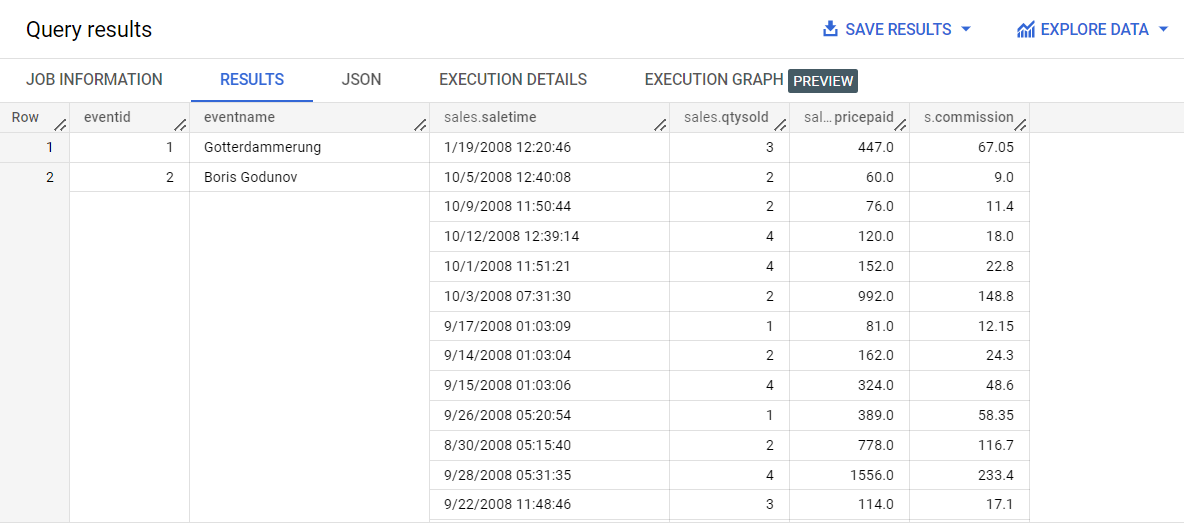
Le code SQL de l'étape 2 ressemble à celui de l'étape 1, mais il inclut les fonctions ARRAY_AGG, STRUCT et GROUP BY.
Examinez les résultats de la requête.
Au lieu de répéter les données du côté "un" de la relation un à plusieurs, les données du côté "plusieurs" se trouvent désormais dans un tableau de structs.
Vous pouvez aussi encapsuler la requête précédente dans une instruction CREATE TABLE pour créer une table hiérarchique imbriquée.
Dans l'éditeur de requête, exécutez la requête suivante :
CREATE OR REPLACE TABLE ticket_sales.event_sales
as (
SELECT
e.eventid,
e.eventname,
ARRAY_AGG(STRUCT(
s.saletime,
s.qtysold,
s.pricepaid,
s.commission)) as sales
FROM
ticket_sales.events e
JOIN
ticket_sales.sales s
ON
e.eventid = s.eventid
GROUP BY
eventid, eventname
);
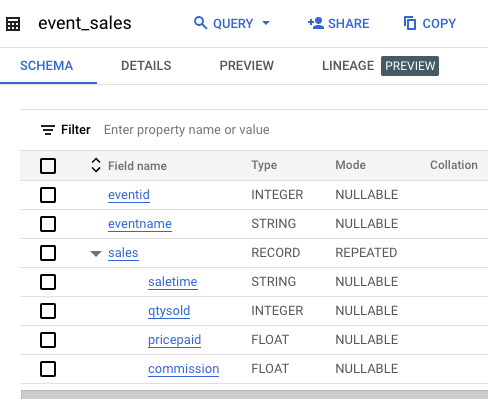
Cliquez sur Accéder à la table, puis examinez le schéma de la table.
Ce schéma inclut un champ imbriqué et répété nommé sales, qui contient l'heure de la vente, la quantité vendue, le prix payé et la commission pour chaque vente d'événement.
Cette nouvelle structure imbriquée et répétée modifie la façon dont vous rédigez les requêtes.
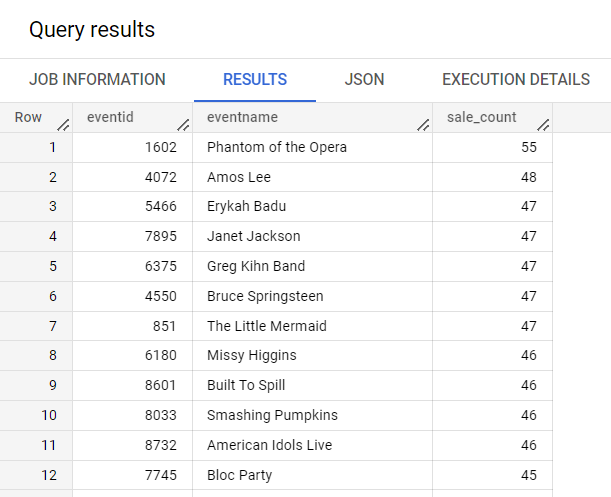
Pour compter le nombre de ventes par événement, exécutez la requête suivante :
SELECT
eventid,
eventname,
ARRAY_LENGTH(sales) AS sale_count
FROM
ticket_sales.event_sales
ORDER BY
sale_count DESC;
Vous voulez connaître les commissions les plus élevées par événement ? Cela nécessite d'interroger les éléments à l'intérieur du tableau. Pour cela, vous devez le désimbriquer (ou l'aplatir).
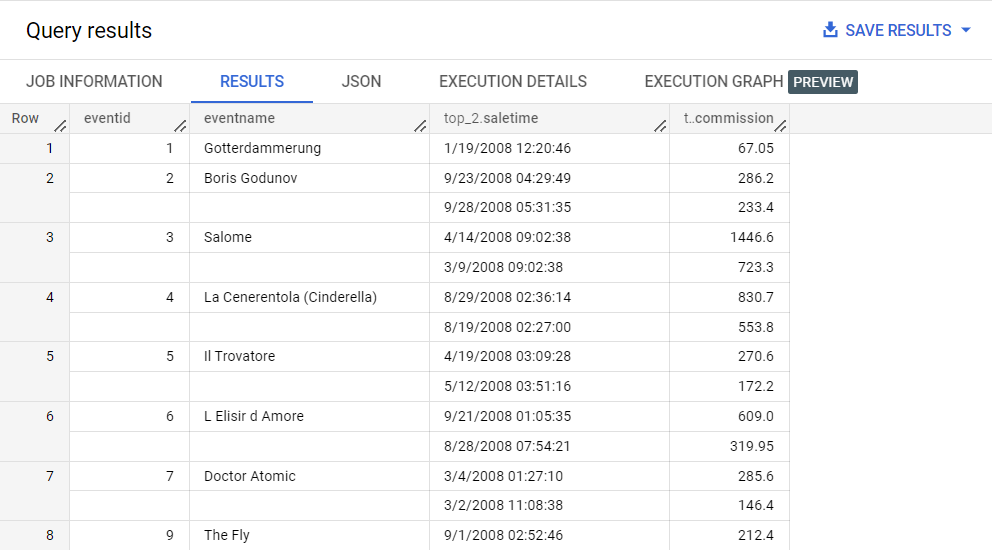
Pour désimbriquer le tableau et identifier les deux commissions les plus élevées par événement, exécutez la requête suivante :
SELECT
eventid,
eventname,
ARRAY((SELECT AS STRUCT saletime, commission FROM UNNEST(sales)
ORDER BY(commission) DESC LIMIT 2)) as top_2
FROM
ticket_sales.event_sales
ORDER BY
eventid;
L'opérateur UNNEST permet d'aplatir le tableau "sales" afin de pouvoir l'interroger. Les résultats sont ensuite convertis en tableau.
Pour en savoir plus sur l'aplatissement de tableaux avec UNNEST, consultez la documentation intitulée Opérateur UNNEST.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer et interroger des champs imbriqués et répétés
Tâche 3 : Créer et interroger des tables partitionnées
Dans BigQuery, une méthode pour réduire le nombre d'octets traités par une requête consiste à diviser une grande table en segments plus petits appelés partitions, puis à inclure un filtre dans vos requêtes pour sélectionner uniquement les données de la partition appropriée. Ce processus s'appelle l'élagage de partitions : il permet de réduire le coût des requêtes.
Dans cette tâche, vous allez apprendre à créer et à interroger des tables partitionnées par unité de temps (sur une colonne DATETIME) afin de réduire au minimum le nombre d'octets traités par les requêtes.
Dans l'éditeur de requête, collez le code suivant, mais ne cliquez pas sur "Exécuter" :
SELECT * FROM ticket_sales.sales;
L'outil de validation des requêtes BigQuery fournit une estimation du nombre d'octets qui seront traités avant l'exécution de la requête. Notez le nombre estimé pour cette requête (15,12 Mo).
Collez la requête suivante, mais ne cliquez pas sur "Exécuter" :
SELECT * FROM ticket_sales.sales
WHERE saletime = '12/14/2008 09:13:17';
Vous constaterez que le nombre d'octets traités est le même que pour la requête de l'étape 1 (15,12 Mo), même si cette nouvelle requête ne concerne que les ventes à partir d'une date spécifique.
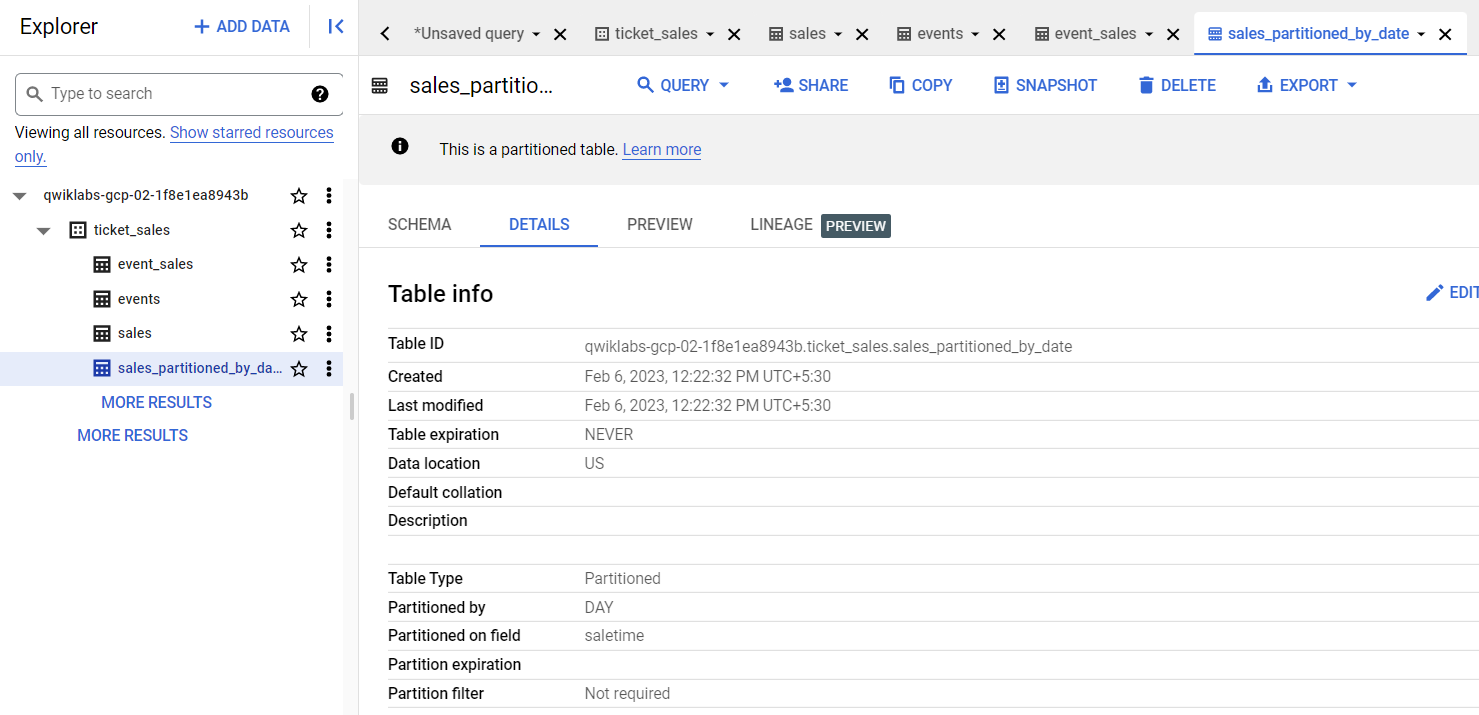
Pour créer une table "sales" partitionnée quotidiennement selon la colonne saletime, exécutez la requête suivante :
CREATE OR REPLACE TABLE
ticket_sales.sales_partitioned_by_date
PARTITION BY
DATETIME_TRUNC(saletime, DAY)
AS (
SELECT
* except (saletime),
PARSE_DATETIME( "%m/%d/%Y %H:%M:%S", saletime) as saletime
FROM
ticket_sales.sales );
Cliquez sur l'onglet Détails pour confirmer que la table est partitionnée par jour (DAY) sur la colonne nommée saletime.
Collez la requête suivante et remarquez l'estimation plus faible de données à traiter (18,98 Ko).
SELECT *
FROM ticket_sales.sales_partitioned_by_date
WHERE saletime = parse_datetime("%m/%d/%Y %H:%M:%S", '12/14/2008 09:13:17');
Cliquez sur Exécuter pour récupérer les résultats de la requête.
La requête traite moins de données (18,98 Ko), car elle s'exécute sur la table partitionnée. BigQuery peut utiliser l'élagage de partitions pour traiter moins de données, ce qui peut contribuer à la réduction des coûts et à l'accélération des requêtes.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer des tables partitionnées et les interroger
Tâche 4 : Créer et interroger des tables groupées
Une autre méthode pour optimiser les performances des requêtes dans BigQuery consiste à rassembler les valeurs dans une table afin de trier et de regrouper les données en blocs de stockage logiques. Les requêtes qui utilisent des filtres ou des agrégations selon les colonnes groupées analysent seulement les blocs nécessaires, et non l'intégralité de la table ou de la partition de table. Ce processus s'appelle l'élagage de blocs : il permet d'accélérer les opérations de jointure, de recherche, de regroupement et de tri.
Dans cette tâche, vous allez apprendre à créer et à interroger des tables groupées pour optimiser les performances des requêtes.
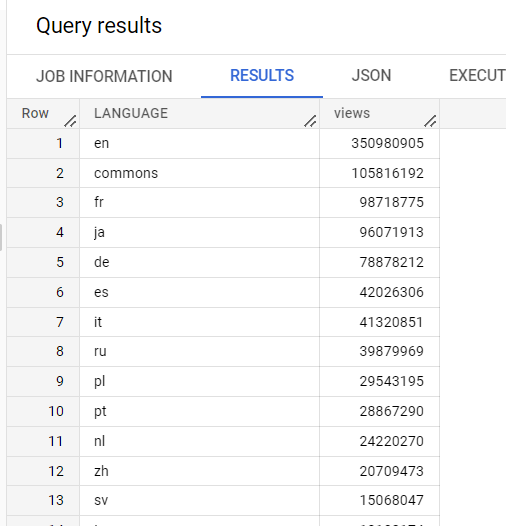
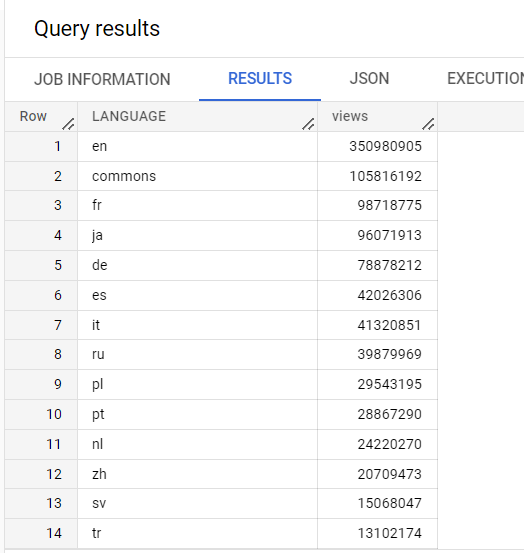
Dans l'éditeur de requête, exécutez la requête suivante :
SELECT
LANGUAGE,
COUNT(views) AS views
FROM
`cloud-training-demos.wikipedia_benchmark.Wiki1B`
GROUP BY
LANGUAGE
ORDER BY
views DESC;
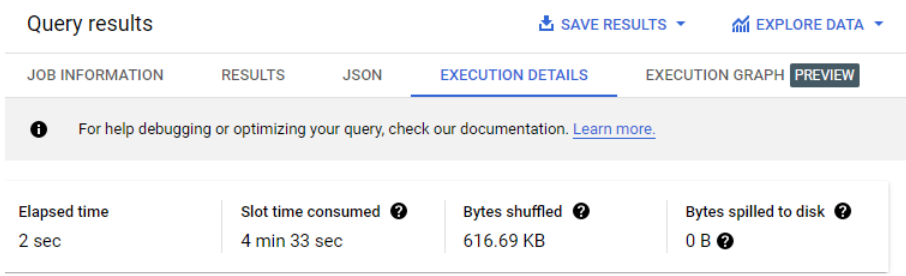
Cette requête utilise l'un des ensembles de données publics de Google, qui contient une grande quantité de données (dans ce cas, un milliard de lignes). Elle compte les vues par langue dans une table de données Wikipédia.
Dans le volet Résultats, cliquez sur l'onglet Détails de l'exécution.
Notez que le nombre d'octets brassés s'élève à 619,68 Ko.
Pour créer un ensemble de données pour les données Wikipédia, exécutez la requête suivante :
CREATE SCHEMA IF NOT EXISTS
wiki_clustered OPTIONS(
location="us");
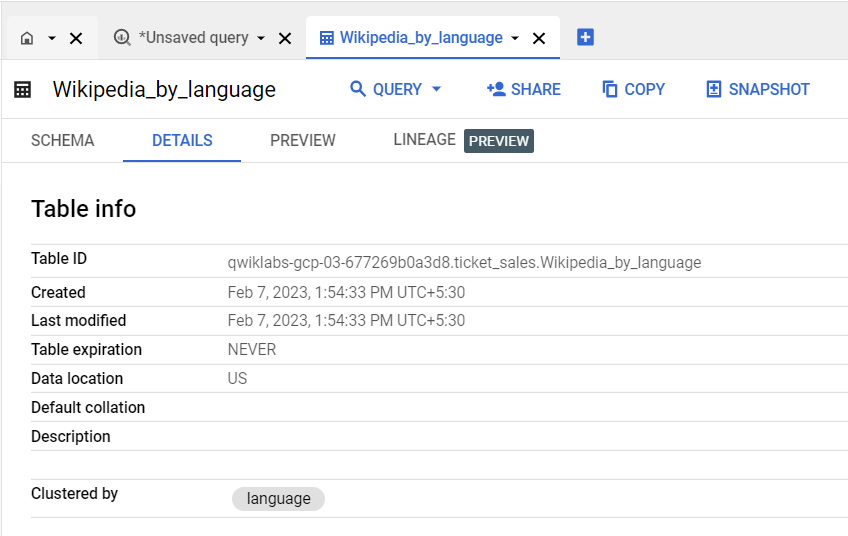
Pour créer une table groupée sur la colonne langue, exécutez la requête suivante :
CREATE OR REPLACE TABLE
wiki_clustered.Wikipedia_by_language
CLUSTER BY
language
AS (
SELECT * FROM `cloud-training-demos.wikipedia_benchmark.Wiki1B`);
L'exécution de cette commande peut prendre plusieurs minutes.
Examinez l'onglet Détails de la table pour confirmer qu'elle est groupée sur la colonne langue.
Pour interroger la table groupée, exécutez la requête suivante :
SELECT
LANGUAGE,
COUNT(views) AS views
FROM
wiki_clustered.Wikipedia_by_language
GROUP BY
language
ORDER BY
views DESC;
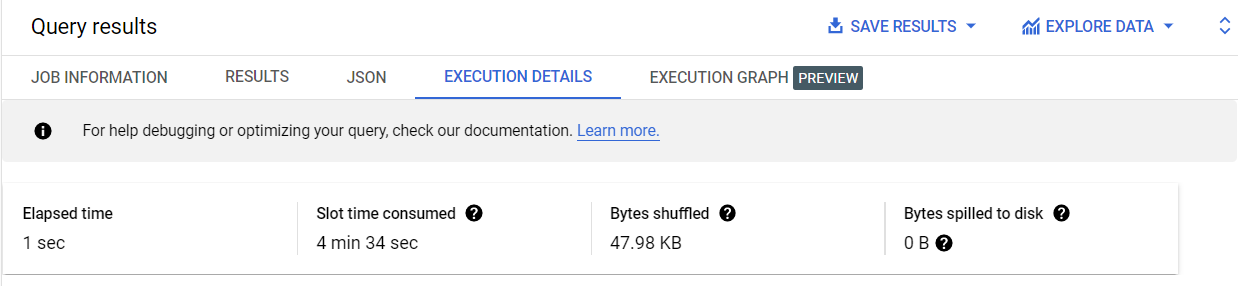
Dans le volet Résultats, cliquez sur l'onglet Détails de l'exécution.
Remarquez que le nombre d'octets brassés est plus faible (47,98 Ko) lorsque la même requête est exécutée sur la table groupée. Un nombre réduit d'octets brassés signifie un temps d'exécution plus rapide dans BigQuery.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer et interroger des tables groupées
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Skills supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Voici à quoi correspond le nombre d'étoiles que vous pouvez attribuer à un atelier :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Le meilleur moyen d'exécuter cet atelier consiste à utiliser une fenêtre de navigation privée. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Dans cet atelier, vous allez apprendre à définir et à interroger des schémas de tables dans BigQuery, notamment à créer et à interroger des champs imbriqués et répétés, des tables partitionnées et des tables groupées.
Durée :
0 min de configuration
·
Accessible pendant 90 min
·
Terminé après 60 min




 ), puis sous "Analyse", cliquez sur BigQuery.
), puis sous "Analyse", cliquez sur BigQuery.