![[認証情報] パネル](https://cdn.qwiklabs.com/%2FtHp4GI5VSDyTtdqi3qDFtevuY014F88%2BFow%2FadnRgE%3D)
![[別のアカウントを使用] オプションがハイライト表示されている、アカウントのダイアログ ボックスを選択します。](https://cdn.qwiklabs.com/eQ6xPnPn13GjiJP3RWlHWwiMjhooHxTNvzfg1AL2WPw%3D)












始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create BigQuery dataset and tables
/ 20
Load data into event table
/ 20
Create nested and repeated fields
/ 20
Create partitioned tables
/ 20
Create clustered tables
/ 20

BigQuery では、データを BigQuery データセットに整理し、列名とデータ型を使用して各テーブルのスキーマ(構造)を定義します。テーブルのスキーマは、BigQuery でのクエリのパフォーマンスと費用に影響します。テーブルのスキーマによって、BigQuery でテーブル内のデータにアクセスして処理する速度と効率が左右されるためです。BigQuery は柔軟なスキーマをサポートしており、データを書き換えることなくスキーマを変更できます。
このラボの目的は、Teradata プロフェッショナルが効果的な BigQuery テーブル スキーマの設計と実装を開始するうえで必要な知識とスキルを提供することです。このラボを完了すると、Teradata プロフェッショナルは BigQuery でテーブル スキーマを設計、最適化、クエリする方法をより深く理解できるようになります。
このラボでは、データを保存するために BigQuery データセットとテーブルを作成します。また、非正規化されたデータの関係を維持するために、ネストした繰り返しフィールドを作成します。さらには、クエリのパフォーマンスを最適化するために、パーティション分割テーブルとクラスタ化テーブルを作成します。
このラボでは、次の方法について学びます。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
シークレット ウィンドウを使用して Google Skills にログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud コンソールにログインする際に使用します。
[Google コンソールを開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。 他の認証情報を使用すると、エラーや料金が発生します。
利用規約に同意し、再設定用のリソースページをスキップします。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側のパネルには、このラボで使用する必要がある一時的な認証情報が表示されます。
ユーザー名をコピーし、[Google Console を開く] をクリックします。 ラボでリソースが起動し、別のタブで [アカウントの選択] ページが表示されます。
[アカウントの選択] ページで [別のアカウントを使用] をクリックします。[ログイン] ページが開きます。
[接続の詳細] パネルでコピーしたユーザー名を貼り付けます。パスワードもコピーして貼り付けます。
しばらくすると、このタブで Cloud コンソールが開きます。

BigQuery では、データ定義言語(DDL)を使用してデータセットとテーブルを作成できます。また、SQL ステートメント LOAD DATA を使用して、1 つ以上のファイルからデータを新規または既存のテーブルに読み込むこともできます。
DDL ステートメントを使用して BigQuery データセットとテーブルを作成する方法、および LOAD DATA SQL ステートメントを使用してデータを読み込む方法について詳しくは、CREATE SCHEMA ステートメント、CREATE TABLE ステートメント、LOAD DATA ステートメントに関するドキュメントをご覧ください。
このタスクでは、DDL を使用して BigQuery にデータセットとテーブルを作成し、LOAD DATA ステートメントを使用して新しいテーブルにデータを読み込みます。
 )で、[アナリティクス] の [BigQuery] をクリックします。
)で、[アナリティクス] の [BigQuery] をクリックします。[Cloud コンソールの BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスには、クイックスタート ガイドとリリースノートへのリンクが表示されます。
[完了] をクリックします。
SQL ワークスペースのツールバーで、[エディタ] アイコンをクリックして SQL クエリエディタを開きます。
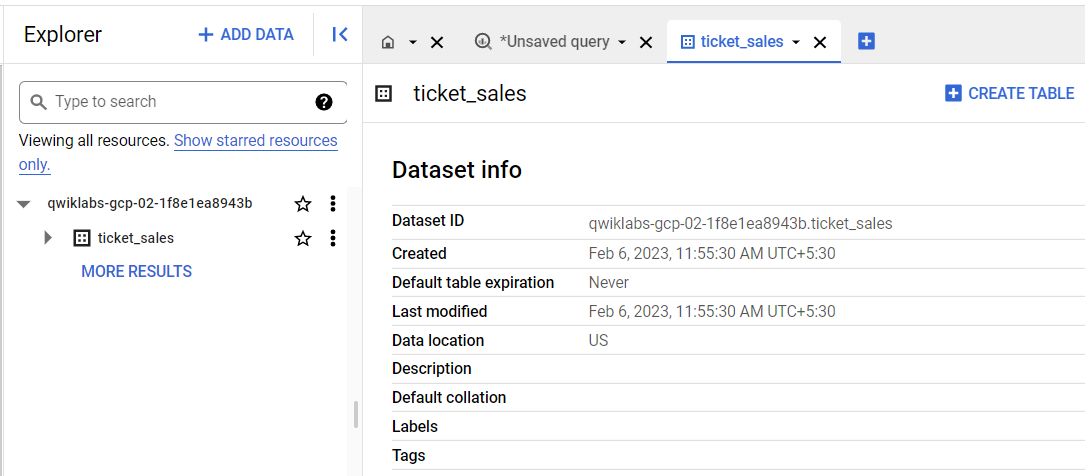
このクエリは、ticket_sales という名前の新しい BigQuery データセットを作成します。DDL ステートメントでは、SCHEMA という用語はテーブル、ビュー、その他のリソースの論理的なコレクションを指します。これは BigQuery ではデータセットと呼ばれます。
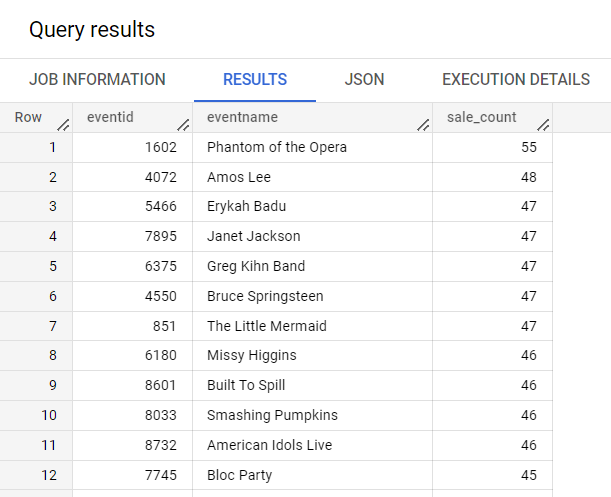
このクエリは、ticket_sales データセットに sales という名前の新しいテーブルを作成します。
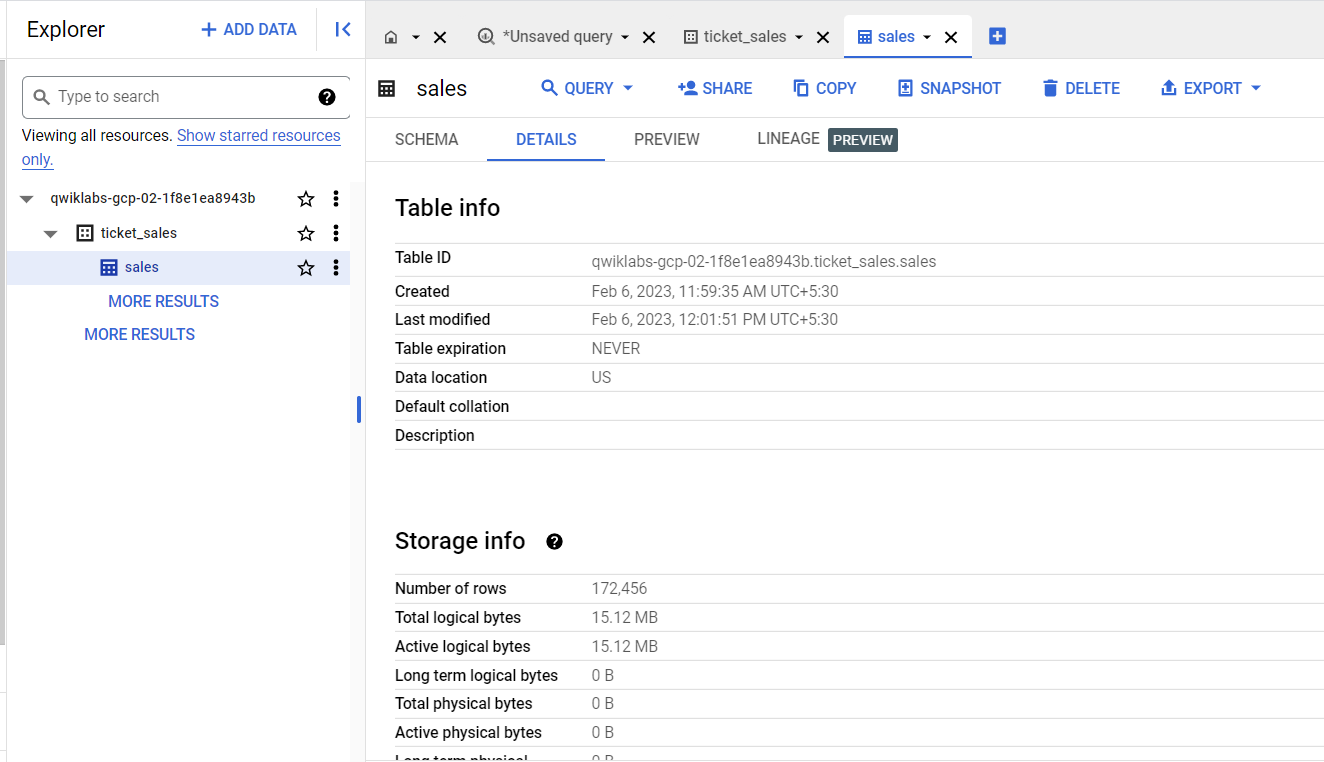
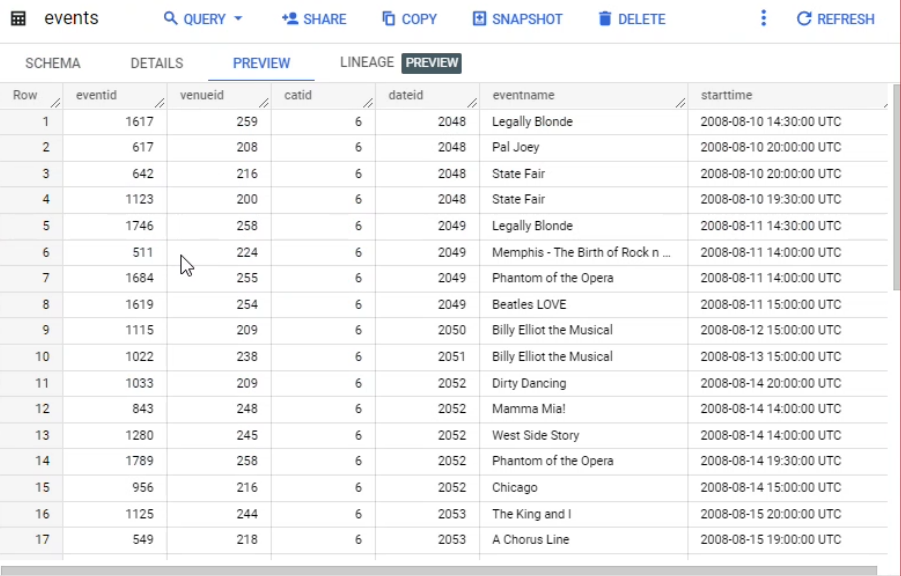
[エクスプローラ] ペインを開きます。データセットとテーブルのリストが表示されるので、テーブル名 sales をクリックします。
[詳細] タブと [プレビュー] タブをクリックして、テーブルの詳細情報を確認します。
テーブルにはまだデータがないことに注目してください。
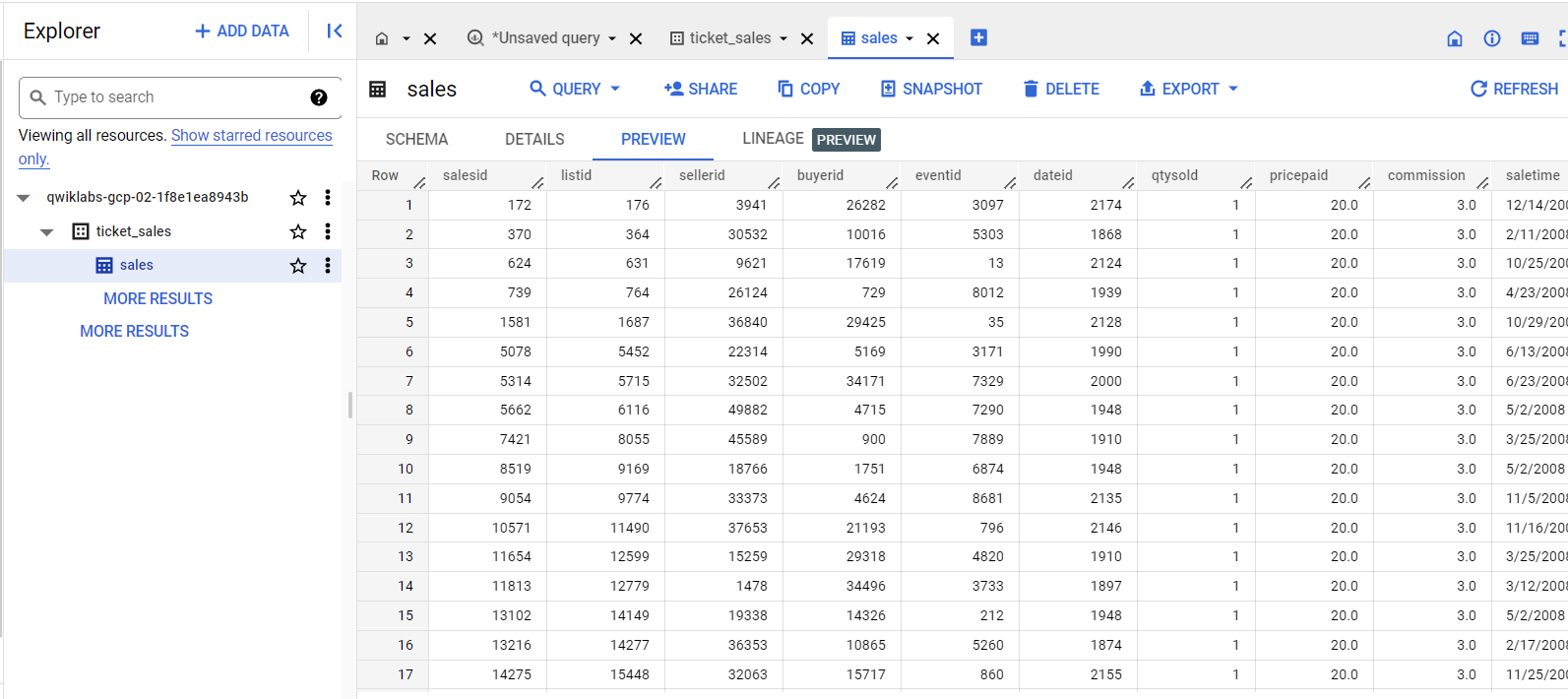
このクエリは、明示的なテーブル スキーマ定義を使用して、Cloud Storage の CSV ファイルから sales テーブルにデータを読み込みます。
[結果] ペインに、LOAD ステートメントが正常に実行されたことを示すメッセージが表示されます。
[プレビュー] タブのデータを更新するには、[更新](右上)をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
BigQuery で SQL ステートメントを使用してデータセットとテーブルを作成し、データを読み込みました。さらにテーブルを作成する練習を行います。今度はイベント情報のデータを読み込みます。
このクエリは、スキーマの自動検出を使用して、Cloud Storage の CSV ファイルから events テーブルにデータを読み込みます。
[結果] ペインに、LOAD ステートメントが正常に実行されたことを示すメッセージが表示されます。
[プレビュー] タブのデータを更新するには、[更新](右上)をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
非正規化は、以前に正規化されたリレーショナル データセットの読み取りパフォーマンスを向上させるための一般的な手法です。BigQuery でデータを非正規化するための推奨される方法は、ネストした繰り返しフィールドを使用することです。データを完全にフラットにするのではなく、ネストした繰り返しフィールドを使用して、非正規化されたデータの関係を維持できます。
BigQuery のネストした繰り返しフィールドの詳細については、ネストされ繰り返されているフィールドを使用するをご覧ください。
このタスクでは、BigQuery でネストした繰り返しフィールドを作成してクエリする方法について説明します。
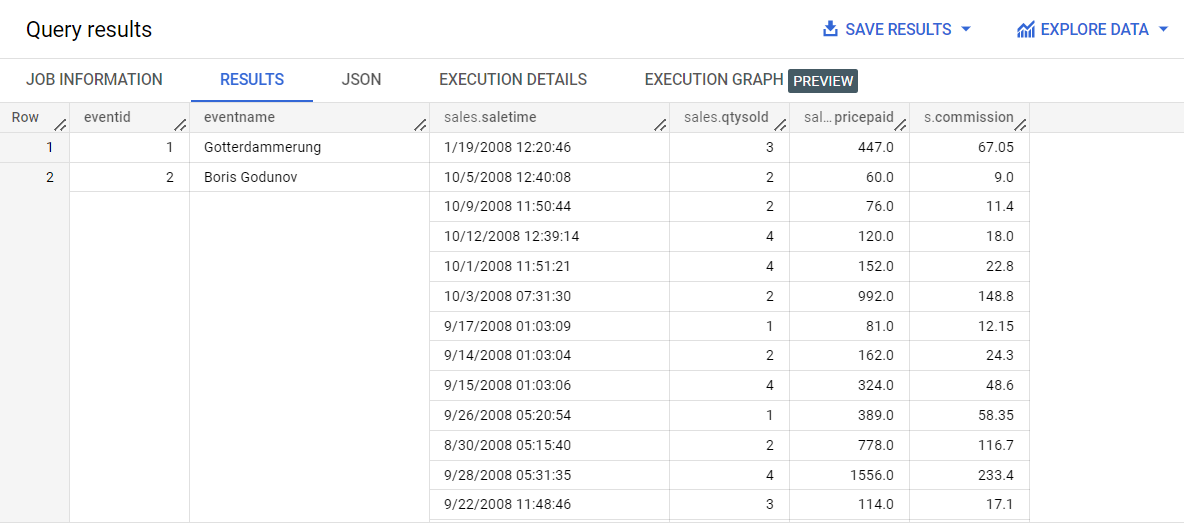
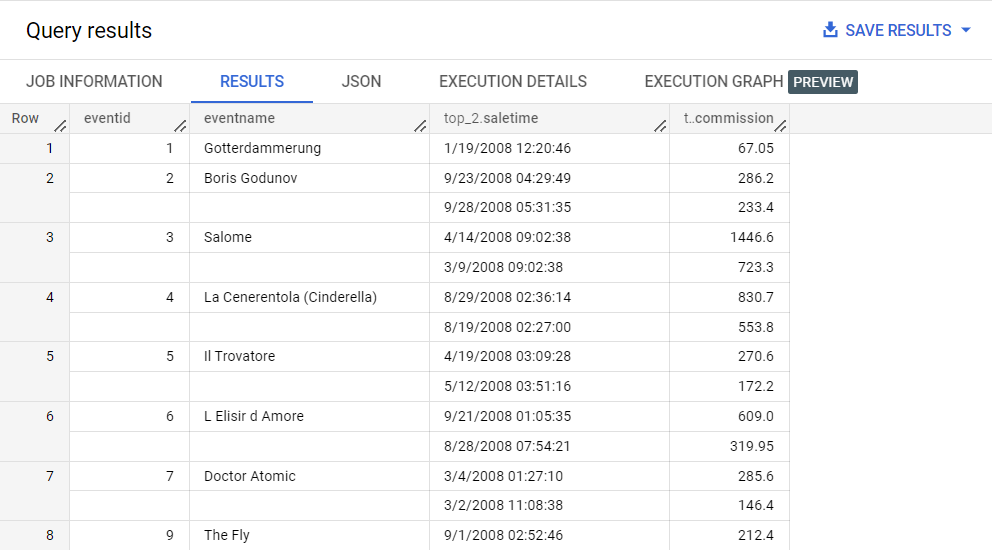
ステップ 2 の SQL はステップ 1 の SQL と似ていますが、ARRAY_AGG 関数、STRUCT 関数、GROUP BY 関数が追加されていることに注目してください。
1 対多の関係の「1」側のデータを繰り返すのではなく、「多」側のデータが 1 つの構造体の配列に含まれるようになりました。
前のクエリを CREATE TABLE ステートメントでラップして、ネストした階層テーブルを作成することもできます。
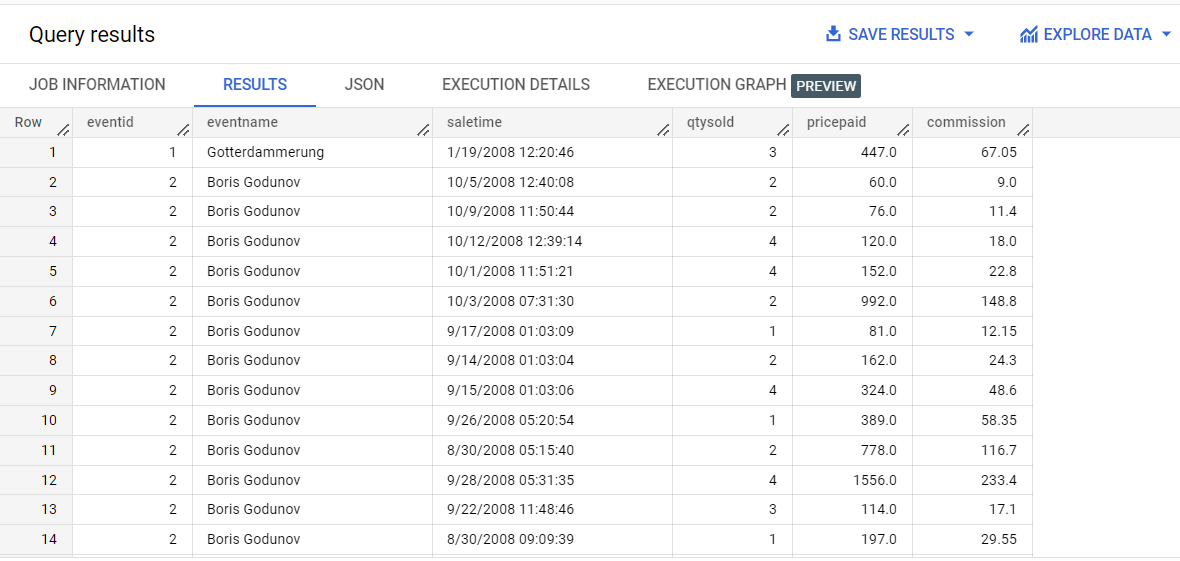
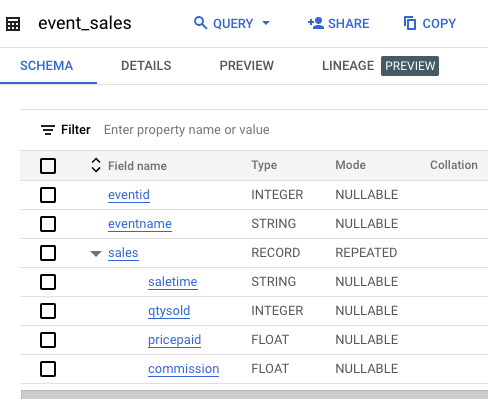
スキーマには、ネストした繰り返しフィールド sales が含まれています。このフィールドには、イベントの個々の販売の販売時間、販売数量、支払い価格、手数料が含まれています。
この新しいネストと繰り返しの構造により、クエリの書き方が変わります。
イベントごとの上位の手数料を確認したい場合はどうすればよいでしょうか?これには、配列内のクエリが必要になります。そのためには、配列のネストを解除(フラット化)する必要があります。
sales 配列をフラット化するには UNNEST 演算子を使用します。これにより、クエリした結果が配列に変換されます。
UNNEST を使用して配列をフラット化する方法について詳しくは、UNNEST 演算子をご覧ください。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
BigQuery でクエリによって処理されるバイト数を減らす方法の 1 つに、大きなテーブルをパーティションと呼ばれる小さなセグメントに分割する方法があります。この場合、クエリには目的のパーティションのデータのみを選択するフィルタを含めるようにします。このプロセスはパーティション プルーニングと呼ばれ、クエリの費用を削減するために使用できます。
パーティション分割テーブルとパーティション プルーニングについて詳しくは、パーティション分割テーブルの概要とパーティション分割テーブルに対するクエリをご覧ください。
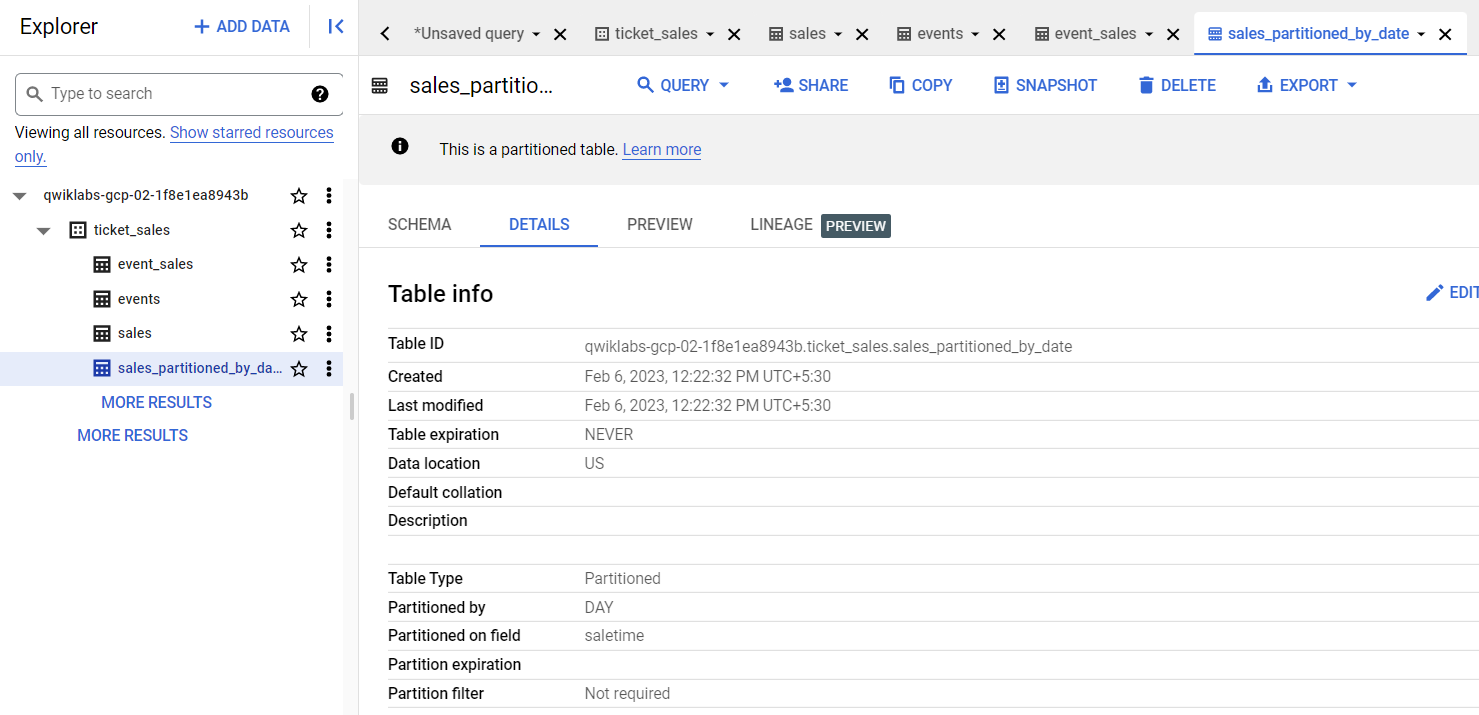
このタスクでは、クエリで処理されるバイト数を最小限に抑えるために、時間単位のパーティション分割テーブル(DATETIME 列)を作成してクエリを実行する方法を学びます。
BigQuery クエリ検証ツールを使用すると、クエリを実行する前に、クエリで処理される推定バイト数を知ることができます。このクエリの推定バイト数(15.12 MB)をメモしておきます。
新しいクエリでは、特定の日付の売上のみをリクエストしているにもかかわらず、処理されるバイト数がステップ 1 のクエリと同じ(15.12 MB)であることに注目してください。
パーティション分割テーブルに対してクエリが実行されるため、クエリで処理されるデータは少なくなります(18.98 KB)。BigQuery ではパーティション プルーニングを使用して処理するデータを減らすことができます。これは、コスト削減やクエリの高速化に役立ちます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
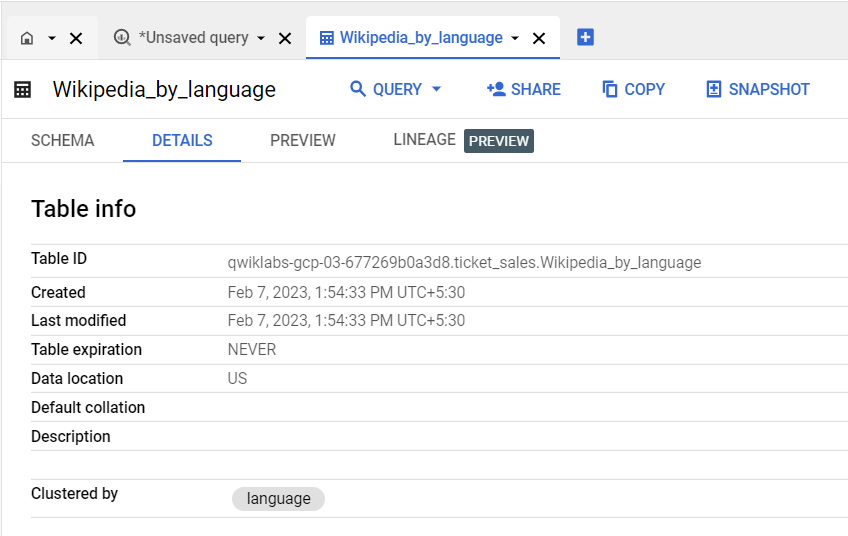
BigQuery でクエリ パフォーマンスを最適化する別の方法として、テーブル内の値をクラスタ化し、データを並べ替えてグループ化し、論理ストレージ ブロックに格納するという方法があります。クラスタ列でフィルタや集計を行うクエリは、テーブルまたはテーブル パーティション全体をスキャンするのではなく、クラスタ列に基づいて該当するブロックのみをスキャンします。このプロセスはブロック プルーニングと呼ばれ、結合、検索、グループ化、並べ替えを高速化できます。
クラスタ化テーブルとブロック プルーニングについて詳しくは、クラスタ化テーブルの概要とクラスタ化テーブルのクエリをご覧ください。
このタスクでは、クラスタ化テーブルを作成してクエリを実行し、クエリのパフォーマンスを最適化する方法を学習します。
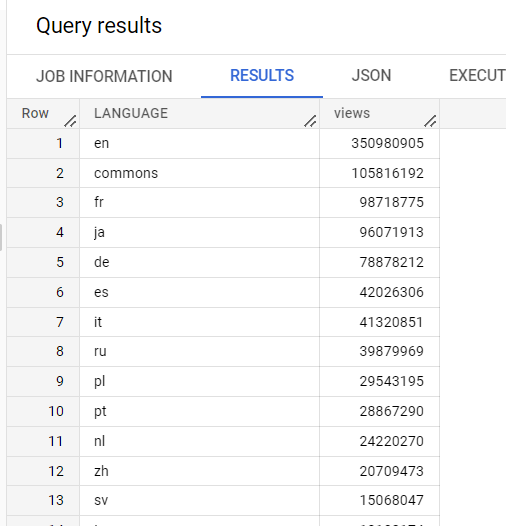
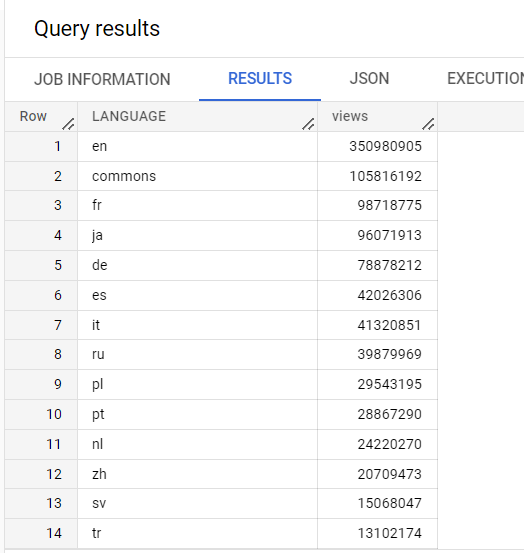
このクエリでは、大量のデータ(この場合は 10 億行)を含む Google の一般公開データセットの 1 つを使用し、Wikipedia データのテーブルで言語ごとの閲覧数をカウントします。
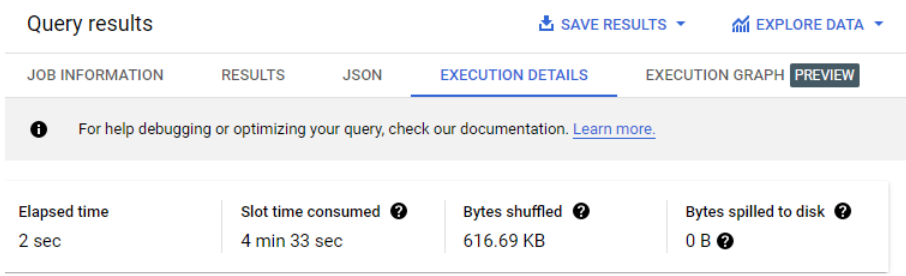
シャッフルされたバイト数(619.68 KB)をメモします。
このコマンドの実行には数分かかることがあります。
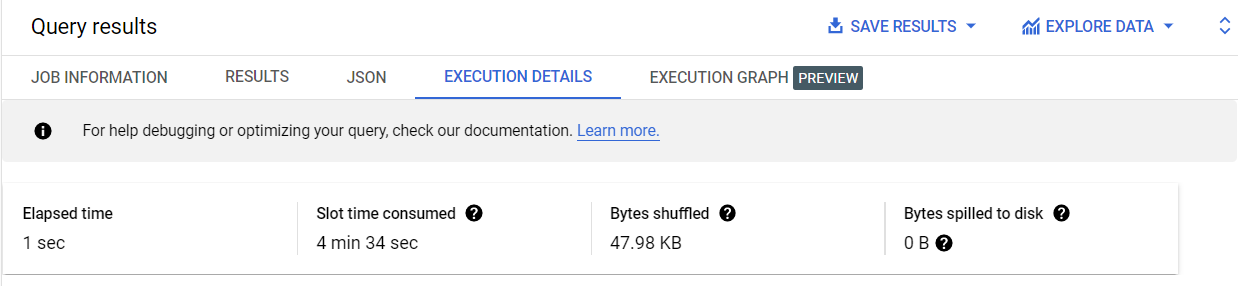
同じクエリをクラスタ化テーブルに対して実行すると、シャッフルされるバイト数が少なくなる(47.98 KB)ことに注目してください。シャッフルされるバイト数が少ないほど、BigQuery の実行時間が短くなります。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Skills から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください