![[認証情報] パネル](https://cdn.qwiklabs.com/%2FtHp4GI5VSDyTtdqi3qDFtevuY014F88%2BFow%2FadnRgE%3D)
![[別のアカウントを使用] オプションがハイライト表示されている、アカウントのダイアログ ボックスを選択します。](https://cdn.qwiklabs.com/eQ6xPnPn13GjiJP3RWlHWwiMjhooHxTNvzfg1AL2WPw%3D)





始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Estimate the amount of data processed by a query
/ 20
Determine slot usage using SQL query
/ 20
Complete a dry run of a query
/ 20

適切なインフラストラクチャを用意することなく大規模なデータセットを保存してクエリを実行すると、多大な時間と費用がかかってしまう可能性があります。BigQuery は、サーバーレスでフルマネージドのエンタープライズ データ ウェアハウスです。Google のインフラストラクチャの処理能力を活用して、高速かつ費用対効果の高いクエリを実現します。BigQuery では、ストレージ リソースとコンピューティング リソースが分離されているため、組織のニーズや要件に応じて柔軟にデータを保存し、クエリを実行できます。
BigQuery では、Google Cloud コンソールの BigQuery クエリ検証ツール、bq コマンドライン ツールのドライラン フラグ、Google Cloud 料金計算ツール、API とクライアント ライブラリなど、さまざまなツールを使用してクエリのリソース使用量と費用を簡単に見積もることができます。
このラボでは、BigQuery のクエリ検証ツールと bq コマンドライン ツールを使用して、クエリを実行する前に処理されるデータ量を推定します。また、SQL クエリと API を使用して、クエリが正常に実行された後のリソース使用量も特定します。
このラボでは、次の方法について学びます。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
シークレット ウィンドウを使用して Google Skills にログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud コンソールにログインする際に使用します。
[Google コンソールを開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。 他の認証情報を使用すると、エラーや料金が発生します。
利用規約に同意し、再設定用のリソースページをスキップします。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側のパネルには、このラボで使用する必要がある一時的な認証情報が表示されます。
ユーザー名をコピーし、[Google Console を開く] をクリックします。 ラボでリソースが起動し、別のタブで [アカウントの選択] ページが表示されます。
[アカウントの選択] ページで [別のアカウントを使用] をクリックします。[ログイン] ページが開きます。
[接続の詳細] パネルでコピーしたユーザー名を貼り付けます。パスワードもコピーして貼り付けます。
しばらくすると、このタブで Cloud コンソールが開きます。

Google Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。
Google Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールで、右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。
[続行] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続した時点で認証が完了しており、プロジェクトに各自のプロジェクト ID が設定されます。次に例を示します。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力例:
出力:
出力例:
Google Cloud コンソールでクエリを入力すると、BigQuery のクエリ検証ツールがクエリ構文を確認し、クエリによって処理されるバイト数を推定します。
このタスクでは、BigQuery 一般公開データセット プログラムによって管理されている一般公開データセット(New York Citi Bikes)をクエリします。このデータセットを使用して、クエリ検証ツールで SQL クエリを検証する方法と、クエリを実行する前にクエリによって処理されるデータ量を推定する方法を学びます。
 )で、[分析] の [BigQuery] をクリックします。
)で、[分析] の [BigQuery] をクリックします。[Cloud コンソールの BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスには、クイックスタート ガイドとリリースノートへのリンクが表示されます。
[完了] をクリックします。
SQL ワークスペースのツールバーで、[エディタ] タブをクリックして SQL クエリエディタを開きます。
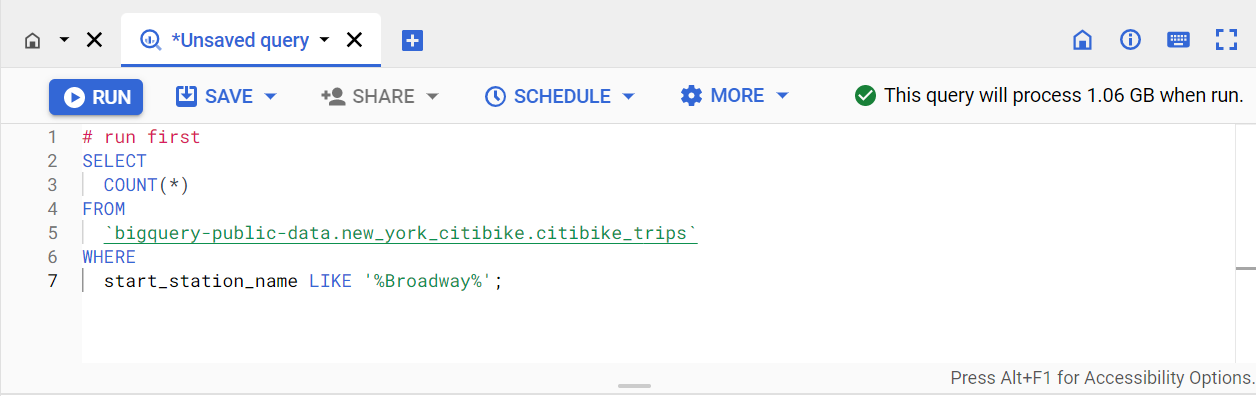
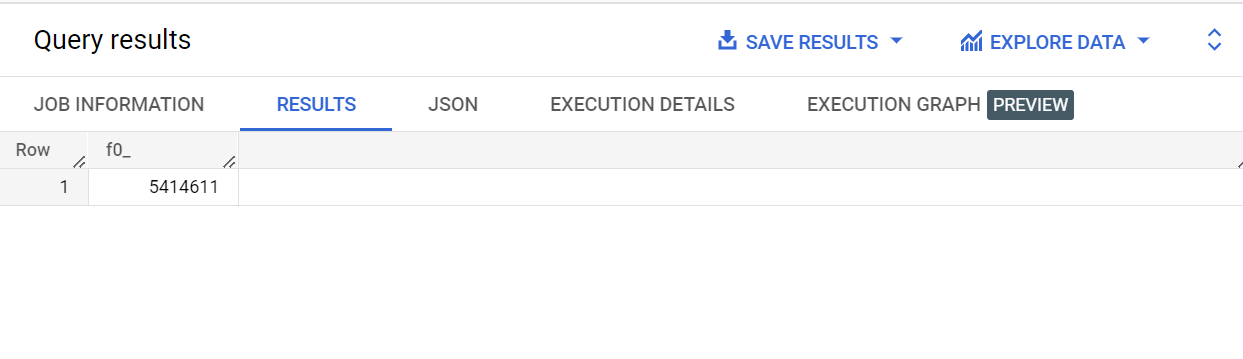
このクエリを実行すると、citibike_trips テーブルの start_station_name 列に「Broadway」というテキストが含まれる駅名の数が返されます。
クエリエディタでコードを追加または変更すると、BigQuery がクエリ検証ツールを自動的に実行します。
クエリが有効か無効かに応じて、クエリエディタの上に緑色または赤色のチェックが表示されます。クエリが有効な場合は、クエリの実行を選択した場合に処理されるデータ量も検証ツールに表示されます。
クエリ検証ツールによると、このクエリを実行すると 1.06 GB が処理されます。
このクエリは、start_station_name という名前の列に「Broadway」というテキストが含まれるレコードの数(5,414,611)を返します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
BigQuery では スロット(仮想 CPU)を使用して SQL クエリが実行され、クエリのサイズと複雑さに応じて、クエリに必要なスロット数が自動的に計算されます。Google Cloud コンソールでクエリを実行すると、その結果と、クエリの実行に使用されたリソース量の概要が表示されます。
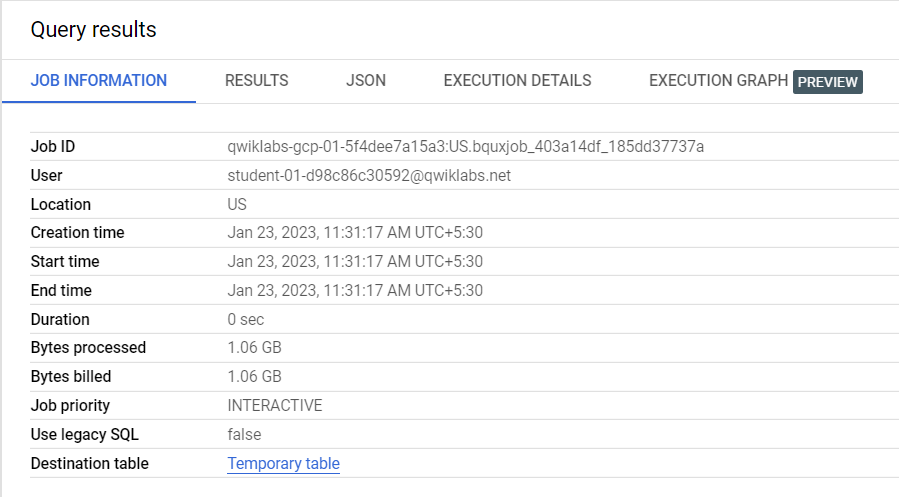
このタスクでは、前のタスクで実行したクエリのジョブ ID を特定し、新しい SQL クエリで使用して、クエリジョブに関する追加情報を取得します。
たとえば、値 qwiklabs-gcp-01-5f4dee7a15a3:US.bquxjob_403a14df_185dd37737a は、プロジェクト ID で始まり、ジョブが実行されたロケーションが続き、ジョブ ID で終わります。:US. の構文は、ジョブが実行された場所を識別します。
プロジェクト ID は最初の部分 qwiklabs-gcp-01-5f4dee7a15a3(:US. の前)で、ジョブ ID は最後の部分 bquxjob_403a14df_185dd37737a(:US. の後)です。
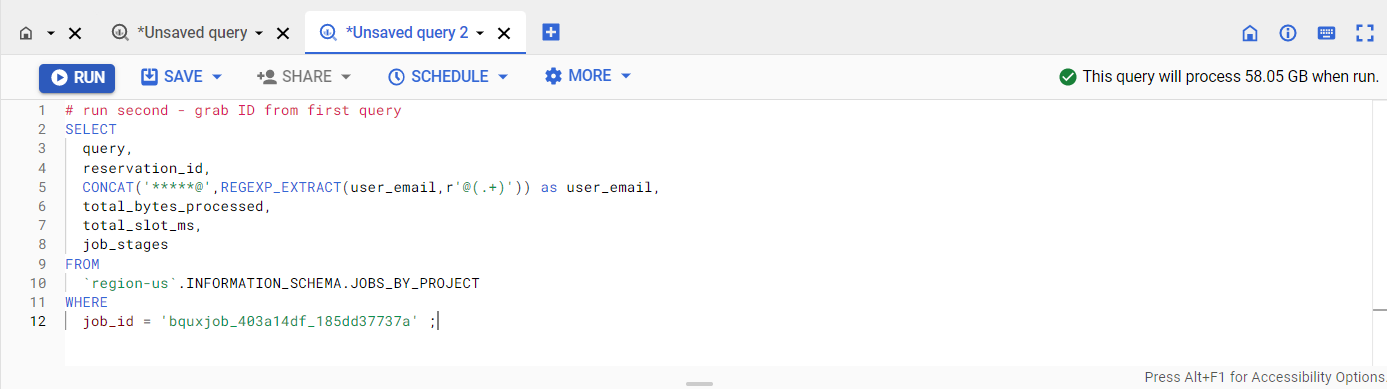
'YOUR_ID' はジョブ ID('bquxjob_403a14df_185dd37737a' など)に置き換えます。このクエリを実行すると、Citi Bikes 一般公開データセットで以前に実行されたクエリジョブのスロット使用量が返されます。
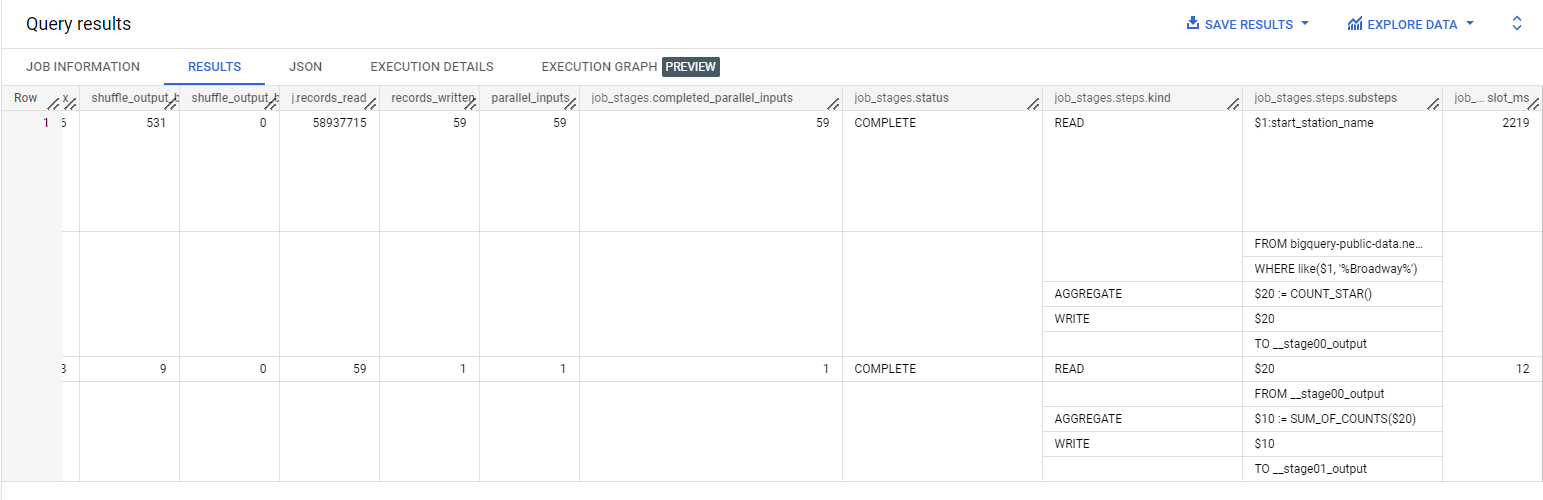
このクエリの出力には、クエリ ステージと各ステージに関連付けられたスロット使用率を示すテーブルが表示されます。
クエリの個々のタスクは 1 つのスロットで実行されるため、job_stages.completed_parallel_inputs という名前の列の値の合計は、クエリの実行に使用されたスロットの合計数です。
ただし、1 つのスロットを割り当てた最初のタスクを完了すると、別のタスクを完了するためにスロットを再割り当てできます。
そのため、クエリの実行に使用された合計スロット時間(total_slot_ms という名前の列に表示される値)を把握することも重要です。具体的には、クエリジョブ全体とクエリの各ステージのスロット時間がミリ秒単位(ms)で提供されます。これは、そのステージの完了に使用されたスロット時間の量を示します。
たとえば、クエリが 150 個のタスクを完了しても、各タスクの実行が速い場合、クエリは実際には 150 スロットではなく 100 スロットなどの少ない数のスロットを使用することがあります。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
API を使用して、特定のクエリジョブに関する情報を取得することもできます。BigQuery では、サーバーにリクエストを送信して API を直接使用するか、C#、Go、Java、Node.js、PHP、Python、Ruby などの任意の言語でクライアント ライブラリを使用できます。
このタスクでは、Google APIs Explorer を使用して BigQuery API をテストし、前のタスクで実行したクエリのスロット使用量を取得します。
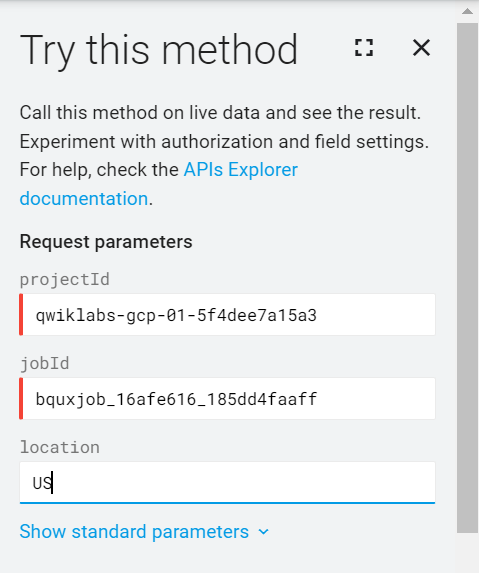
新しいシークレット ブラウザタブで、jobs.get メソッドの BigQuery API ページに移動します。
[Try this method] ウィンドウで、前のタスクで特定したプロジェクト ID とジョブ ID を入力します。
たとえば、先述の値ではプロジェクト ID は qwiklabs-gcp-01-5f4dee7a15a3、ジョブ ID は bquxjob_403a14df_185dd37737a です。
ログインの確認を求められたら、前のタスクで Google Cloud にログインするために使用した受講者のユーザー名(
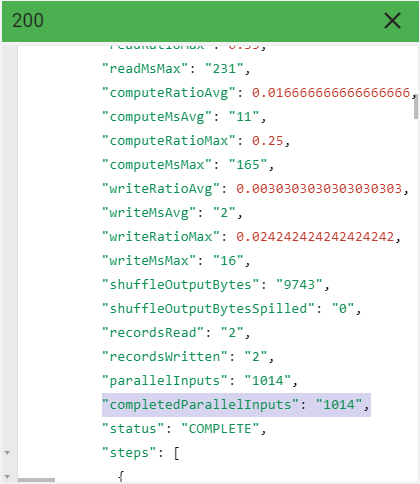
最初のステージの完了した並列入力の値を確認するには、[statistics] > [query] > [queryPlan] > [name: S00] > [completedParallelInputs] までスクロールします。
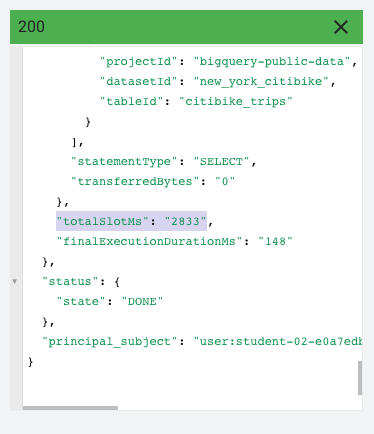
クエリジョブ全体で使用された合計スロット数を確認するには、結果の最後までスクロールして、totalSlotMs の値を確認します。
bq コマンドライン ツールでは、--dry_run フラグを使用して、クエリを実行する前にクエリで読み取られるバイト数を見積もることができます。また、API やクライアント ライブラリを使用してクエリジョブを送信する場合は、dryRun パラメータを使用できます。クエリのドライランはクエリスロットを使用しないため、ドライランの実行に対しては課金されません。
このタスクでは、Cloud Shell の bq コマンドライン ツールを使用して、クエリのドライランを完了する方法を学習します。
出力には、クエリを実行して結果を取得する前にクエリで処理されると推定されるバイト数が表示されます。
クエリでどの程度のバイト数が処理されるかがわかり、ワークフローの次のステップを決定するために必要な情報が得られました。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Skills から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください