



始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create a development machine in Compute Engine
/ 5
Install Software in the development machine
/ 5
Create a GCS bucket
/ 5
Download some sample images into your bucket
/ 5
Create a Cloud Managed Apache Spark cluster
/ 5
Submit a job to the Cloud Managed Apache Spark Cluster
/ 5
Create a development machine in Compute Engine
/ 5
Install Software in the development machine
/ 5
Create a GCS bucket
/ 5
Download some sample images into your bucket
/ 5
Create a Cloud Managed Apache Spark cluster
/ 5
Submit a job to the Cloud Managed Apache Spark Cluster
/ 5

このハンズオンラボでは、Cloud Managed Service for Spark で Apache Spark を使用して、コンピューティング負荷の高い画像処理タスクをクラスタのマシンに分散する方法について学びます。これは科学データを処理する一連のラボの一部です。
このラボは上級者向けです。Cloud Managed Service for Spark と Apache Spark の基本的な知識があることが推奨されますが、必須ではありません。これらのサービスについて学ぶには、以下のラボを受講してください。
準備ができたら下にスクロールして、このラボで使用するサービスについて詳しく学んでいきましょう。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 右側の [ラボの設定とアクセス] パネルには、以下が表示されます。
ラボのタイマーはページの上部に表示され、残り時間が示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの設定とアクセス] パネルでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの設定とアクセス] パネルでもパスワードを確認できます。
[次へ] をクリックします。
その後のページはクリックして先に進みます。
しばらくすると、このタブで Google Cloud コンソールが開きます。

Cloud Managed Service for Spark は、オープンソースのデータツールを利用してバッチ処理、クエリ実行、ストリーミング、ML を行えるマネージド Spark / Hadoop サービスです。Cloud Managed Service for Spark の自動化機能を利用すると、クラスタを速やかに作成し、簡単に管理し、必要ないときには無効にして費用を節約できます。管理にかかる時間と費用が削減されるので、自分の仕事とデータに集中できます。
コンピューティング負荷の高いジョブがあり、以下の条件を満たしている場合は、Cloud Managed Service for Spark を使用してスケールアウトすることを検討してください。
必要な処理の量がサブセットによって異なる場合(または Apache Spark の知識がまだない場合)は、自動スケーリング データ パイプラインに対応している Cloud Dataflow 上の Apache Beam が有力な選択候補となります。
このラボでは、OpenCV で指定した一連の画像処理ルールを使用して、画像に含まれる顔を枠で囲むジョブを実行します。この種の処理には、このように手動でコーディングしたルールより Vision API の方が適していますが、このラボの目的は、コンピューティング負荷の高いジョブを分散方式で実行することにあります。
まず、サービスをホストする仮想マシンを作成します。
![[インスタンスを作成] ボタンへのナビゲーション パス。ハイライト表示されている](https://cdn.qwiklabs.com/3U1qCvvhTTw%2BqvK%2FuZxEnB2BZXmH%2BF3lPefxGzP6EK0%3D)
[マシンの構成] を参照します。
次の値を選択します。
devhost
E2
e2-standard-2(2 vCPU)
[セキュリティ] をクリックします。
[作成] をクリックします。この仮想マシンを開発用の
bastion(踏み台)インスタンスとして使用します。
[進行状況を確認] をクリックして、実行したタスクを確認します。タスクが正常に完了すると、評価スコアが提供されます。
次に、ジョブを実行するソフトウェアを設定します。sbt(オープンソースのビルドツール)を使用して、Cloud
Managed Service for Spark クラスタに送信するジョブの JAR をビルドします。この
JAR
には、プログラムと、ジョブを実行するために必要なパッケージが格納されます。このジョブでは、Cloud
Storage
バケットに保存されている一連の画像ファイルで顔を検出し、顔を枠で囲んだ画像ファイルを
Cloud Storage の同じバケットまたは別のバケットに書き出します。
Scala と
sbt
をインストールします。これにより、コードをコンパイルできるようになります。
次に、Feature Detector のファイルをビルドします。このラボのコードは、GitHub
の Cloud Managed Service for Spark
リポジトリに存在するソリューションを少し変更したものです。コードをダウンロードしてから、cd
でこのラボのディレクトリに移動して、Feature Detector の「fat
JAR」をビルドします。これを後ほど Cloud Managed Service for Spark
に送信します。
[進行状況を確認] をクリックして、実行したタスクを確認します。タスクが正常に完了すると、評価スコアが提供されます。
Feature Detector のファイルがビルドされたら、Cloud Storage バケットを作成してサンプル画像をいくつか追加します。
gcloud とともに Cloud SDK に含まれている
gsutil
プログラムを使用して、サンプル画像を保存するバケットを作成します。
[進行状況を確認] をクリックして、実行したタスクを確認します。タスクが正常に完了すると、評価スコアが提供されます。
以下の画像が Cloud Storage バケットにダウンロードされます。
[進行状況を確認] をクリックして、実行したタスクを確認します。タスクが正常に完了すると、評価スコアが提供されます。
出力:
MYCLUSTER
変数を設定します。この変数をコマンドで使用してクラスタを参照します。
完了までに数分かかります。このラボでは、2
つのワーカーノードを含むデフォルトのクラスタ設定で十分です。クラスタで使用されるコアの総数を減らすために、ワーカーとマスターの両方のマシンタイプに
e2-standard-2 を指定しています。
initialization-actions フラグでは、クラスタの各マシンに
libgtk2.0-dev
ライブラリをインストールするスクリプトを渡します。このライブラリはコードを実行するために必要となります。
gcloud dataproc clusters delete ${MYCLUSTER})、前のクラスタ作成コマンドを再試行してください。
[進行状況を確認] をクリックして、実行したタスクを確認します。タスクが正常に完了すると、評価スコアが提供されます。
このラボで実行するプログラムは顔検出に使用されるため、顔を表す
haar 分類器を入力する必要があります。haar
分類器とは、プログラムで検出する特徴を記述するために使用される XML
ファイルです。ここでは、haar 分類器のファイルをダウンロードし、Cloud Managed Service for Spark
クラスタにジョブを送信する際にその Cloud Storage
パスを最初の引数として指定します。
imgs ディレクトリにアップロードした一連の画像を Feature
Detector
への入力として使用します。そのディレクトリのパスをジョブ送信コマンドの 2
番目の引数として指定する必要があります。
処理する他の画像を、2 番目の引数で指定した Cloud Storage バケットに追加することもできます。
以下のような出力が表示されたら次のステップに進みます。
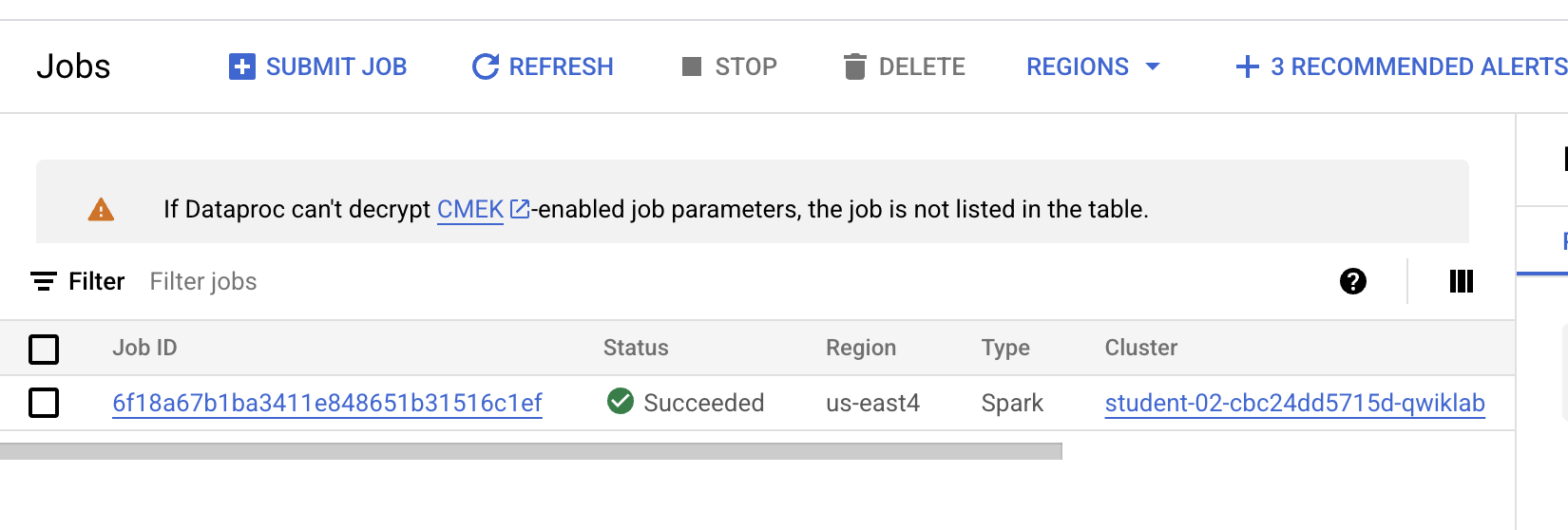
[進行状況を確認] をクリックして、実行したタスクを確認します。タスクが正常に完了すると、評価スコアが提供されます。
ジョブが完了したら、ナビゲーション メニュー > [Cloud Storage] に移動し、作成したバケット(ユーザー名の後に
student-image
と乱数が追加された名前のバケット)を見つけてクリックします。
Out ディレクトリにある任意の画像をクリックします。
[ダウンロード] アイコンをクリックすると、その画像がパソコンにダウンロードされます。
顔検出は正確に機能していますか。この種の処理には、このように手動でコーディングされたルールより Vision API の方が適しています。次のステップで確認してみましょう。
(省略可)作成したバケットの
imgs
フォルダに移動して、アップロードした他の画像をクリックし、3
つのサンプル画像をダウンロードしてパソコンに保存します。
このリンクをクリックして Vision API のページに移動し、[Try the API] セクションまでスクロールして、バケットからダウンロードした画像をアップロードします。数秒で画像検出の結果が表示されます。基盤となる機械学習モデルは継続的に改良されているため、実際の結果は以下と異なる場合があります。


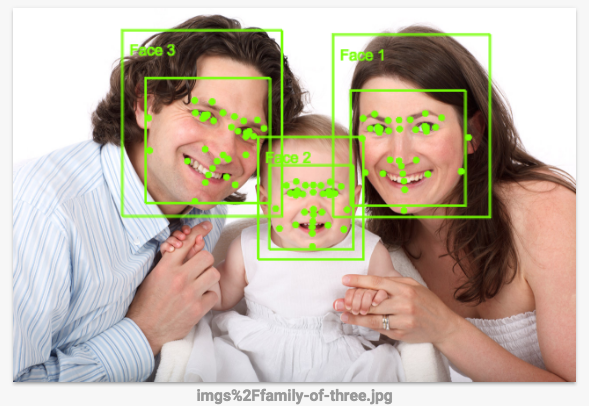
FeatureDetector
のコードを編集して、sbt assembly、gcloud dataproc
と jobs submit コマンドを再実行します。
今回のラボで学習した内容の理解を深めていただくため、以下の多肢選択式問題を用意しました。正解を目指して頑張ってください。
ここでは、Cloud Managed Service for Spark クラスタを作成してジョブを実行する方法を学習しました。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2025 年 7 月 7 日
ラボの最終テスト日: 2025 年 7 月 7 日
Copyright 2026 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。