![Compute Engine のデフォルトのサービス アカウント名と編集者のステータスがハイライト表示された [権限] タブページ](https://cdn.qwiklabs.com/1nytD9OUuNUV9undyjUWeOS7LJmekReBDmkUjveCjcU%3D)

![展開された [表示] メニューでハイライト表示されているエクスプローラ オプション](https://cdn.qwiklabs.com/yeDC%2FCILaUn6YJSJjfGKlB6ju13WPLsGaZj6tEqxpw0%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create Vertex AI Platform Notebooks instance and clone course repo
/ 10
Setup the data environment
/ 15
Run your pipeline from the command line
/ 10
Create a custom Dataflow Flex Template container image
/ 15
Create and stage the flex template
/ 10
Execute the template from the UI and using gcloud
/ 10

このラボでは、次の作業を行います。
前提条件:
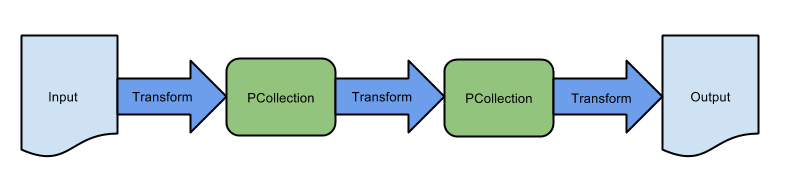
前のラボでは、基本的な抽出-変換-読み込みの順次実行パイプラインを作成し、対応する Dataflow テンプレートを使用して Google Cloud Storage 上にバッチ データストレージを取り込みました。このパイプラインは、以下に示す変換のシーケンスで構成されています。
しかし多くの場合、パイプラインはこのように単純な構造ではありません。このラボでは、より高度な連続的でないパイプラインを構築します。
今回のユースケースではリソース消費量を最適化します。プロダクトによってリソースの利用状況は異なります。また、一つの企業内でもすべてのデータが同じように使われるわけではなく、たとえば分析ワークロードで定期的にクエリされるデータもあれば、復元にのみ使用されるデータもあります。このラボでは、最初のラボで作成したパイプラインのリソース消費量を最適化するために、アナリストが使用するデータのみを BigQuery に保存し、他のデータは低コストで耐久性の高いストレージ サービスである Google Cloud Storage の Coldline Storage にアーカイブします。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
Qwiklabs にシークレット ウィンドウでログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] > [ダッシュボード] から確認できます。
編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。729328892908)をコピーします。{project-number} はプロジェクト番号に置き換えてください。このラボでは、すべてのコマンドをノートブックのターミナルで実行します。
Google Cloud コンソールのナビゲーション メニューで、[Vertex AI] > [Workbench] をクリックします。
[Notebooks API を有効にする] をクリックします。
[Workbench] ページで [ユーザー管理のノートブック] を選択し、[新規作成] をクリックします。
表示された [新しいインスタンス] ダイアログ ボックスで、リージョンを
[環境] で [Apache Beam] を選択します。
ダイアログ ボックスの下部にある [作成] をクリックします。
このラボで使用するコード リポジトリをダウンロードします。
ノートブック環境の左側パネルのファイル ブラウザに、training-data-analyst リポジトリが追加されます。
クローン リポジトリ /training-data-analyst/quests/dataflow_python/ に移動します。ラボごとに、1 つのフォルダが表示されます。このフォルダはさらに、完成させるコードが格納される lab サブフォルダと、ヒントが必要な場合に完全に機能するサンプルを参照できる solution サブフォルダとに分けられています。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
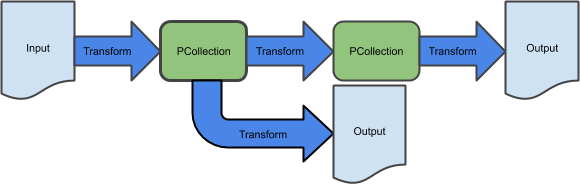
このパートでは、Google Cloud Storage と BigQuery の両方にデータを書き込む、分岐するパイプラインを作成します。
分岐するパイプラインを作成する方法の一つは、2 つの異なる変換を同じ PCollection に適用することにより、2 つの異なる PCollection を作成することです。
これ以降のセクションでヒントが必要な場合は、こちらのソリューションをご利用ください。
このタスクを完了するには、既存のパイプラインを変更し、Cloud Storage に書き込むブランチを追加します。
IDE 環境に新しいターミナルをまだ作成していない場合は作成し、次のコマンドをコピーして貼り付けます。
実際のパイプライン コードの編集を開始できるようにするには、前もって必要な依存関係がインストールされていることを確認する必要があります。
IDE 環境で以前に開いていたターミナルに戻り、このラボの作業用に仮想環境を作成します。
次に、パイプライン中で実行する必要があるパッケージをインストールします。
最後に、Dataflow API が有効になっていることを確認します。
IDE 中で 2_Branching_Pipelines/labs/ にある my_pipeline.py を開きます。パイプラインの本体部分を定義している run() メソッドまで下にスクロールします。現在は次のような内容です。
このコードを変更し、各要素が json から dict に変換される前に、textio.WriteToText を使用して Cloud Storage への書き込みを行う新しい分岐変換を追加します。
これ以降のセクションでヒントが必要な場合は、こちらにあるソリューションをご覧ください。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
この時点では、すべてのデータが 2 回保存されるため、新しいパイプラインでもリソースの消費量は減りません。リソースの消費量を改善するには、重複するデータの量を減らす必要があります。Google Cloud Storage バケットの使用目的は、アーカイブおよびバックアップ ストレージとしての機能なので、すべてのデータを保存する必要があります。一方、BigQuery には必ずしもすべてのデータを送る必要はありません。
たとえば、データ アナリストが頻繁に確認する対象が、ウェブサイトでユーザーがどのリソースにアクセスしているか、そしてそのアクセス パターンが地域と時間によってどのように異なるかであると仮定します。これに必要なフィールドは一部のみです。すでに JSON をパースして辞書型に変換しているので、pop メソッドを使用して容易に Python の呼び出し可能オブジェクトからフィールドを除くことができます。
このタスクを完了するには、Python の呼び出し可能オブジェクトを beam.Map とともに使用して、アナリストが BigQuery で使用しないフィールド user_agent を除きます。
Apache Beam にはフィルタリングの方法が数多くあります。Python 辞書形式の PCollection を取り扱っているため、最も簡単なのはブール値を返す関数である(匿名の)ラムダ関数をフィルタとして利用する方法で、beam.Filter とともに使用します。次に例を示します。
このタスクを完了するには、パイプラインに beam.Filter 変換を追加します。どのような条件でもフィルタできますが、たとえば num_bytes が 120 以上である行を除くということを試してみると良いでしょう。
パイプラインには現在、入力のパスや BigQuery のテーブルの場所など、多くのパラメータがハードコードされています。Cloud Storage の任意の JSON ファイルを読み取ることができれば、パイプラインがさらに便利になります。この機能を追加するには、一連のコマンドライン パラメータへの追加が必要です。
現在は、コマンドライン引数の読み込みと解析に ArgumentParser を使用しています。そして、パイプライン作成時に指定した PipelineOptions() オブジェクトに引数を渡します。
PipelineOptions を使用して、ArgumentParser で読み込んだオプションを解釈します。このパーサに新しいコマンドライン引数を追加するには、以下の構文を使用します。
コードでコマンドライン引数にアクセスするには、引数を解析した結果できる辞書のフィールドを参照します。
このタスクを完了するには、入力パス、Google Cloud Storage 出力パス、BigQuery テーブル名を示すコマンドライン パラメータを追加して、定数の代わりにこれらのパラメータにアクセスするようにパイプライン コードを更新します。
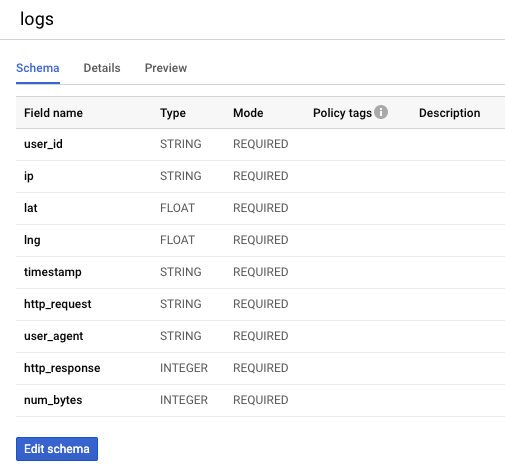
お気づきかもしれませんが、前回のラボで作成した BigQuery テーブルには、すべてのフィールドを REQUIRED とする次のようなスキーマがありました。
データが存在しない NULLABLE フィールドがある Apache Beam スキーマを作成し、パイプライン実行自体および結果の BigQuery テーブルにもそれを反映したスキーマで適用するのが良いでしょう。
次のように、NULL 値を許容したいフィールドに新しいプロパティ mode を追加して JSON BigQuery スキーマを更新します。
このタスクを完成するには、BigQuery スキーマの lat フィールドと lon フィールドを null 値許容に設定します。
このタスクを完了するには、コマンドラインでパイプラインを実行して適切なパラメータを渡します。生成される BigQuery スキーマの NULLABLE フィールドを忘れずにメモしておいてください。コードは次のようになります。
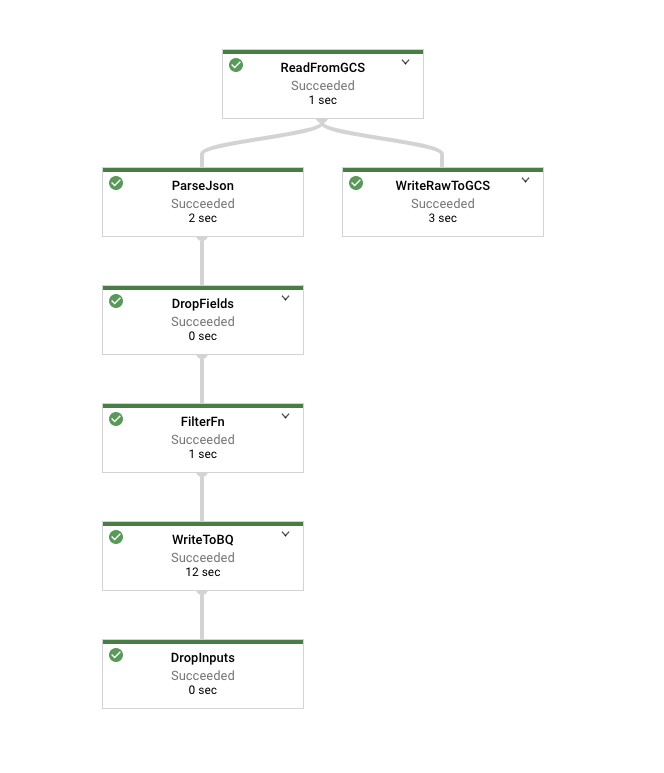
Cloud Dataflow の [ジョブ] ページに移動して、実行中のジョブを確認します。グラフは次のようになっているはずです。
Filter 関数を表すノード(上の図では FilterFn)をクリックします。右側に表示されたパネルで、入力として追加された要素が出力として書き込まれた要素よりも多いことが確認できます。
次に Cloud Storage への書き込みを表すノードをクリックします。すべての要素が書き込まれているので、この数字は Filter 関数への入力の要素数と一致しているはずです。
パイプラインが終了したら、テーブルに対してクエリを実行して BigQuery の結果を確認します。テーブル内のレコード数は Filter 関数で出力された要素の数と一致しているはずです。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
コマンドライン パラメータを受け入れるパイプラインは、パラメータがハードコードされたパイプラインよりもはるかに便利です。しかしその実行には開発環境の作成が必要です。さまざまなユーザーによる再実行や、多種多様なコンテキストでの再実行が想定されるパイプラインには、さらに便利な選択肢があります。それは、Dataflow テンプレートを使うことです。
Google Cloud Platform には、あらかじめ作成された Dataflow テンプレートが多数用意されていて、こちらで確認できます。その中にこのラボのパイプラインと同じ動作をするテンプレートはありません。しかし、ラボのこのパートで、パイプラインを(従来のカスタム テンプレートではなく)新しいカスタム Dataflow Flex テンプレートに変換できます。
パイプラインをカスタム Flex Dataflow テンプレートに変換するには、コードだけでなく依存関係もパッケージ化する Docker コンテナ、ビルド対象のコードを記述する Dockerfile、実際のジョブの作成のためにランタイムに実行する基盤のコンテナをビルドする Cloud Build、ジョブ パラメータを記述するメタデータ ファイルを使用する必要があります。
pip3 freeze を使用して、現環境で使用しているパッケージとそのバージョンを記録します。次に、Dockerfile を作成します。これにより、使用する必要があるコードおよび依存関係を指定します。
a. このタスクを完了するには、IDE のファイル エクスプローラで dataflow_python/2_Branching_Pipelines/lab フォルダに新しいファイルを作成します。
b. 新しいファイルを作成するには、[ファイル] >> [新規] >> [テキスト ファイル] の順にクリックします。
c. ファイル名を Dockerfile に変更します。ファイル名を右クリックすると変更できます。
d. 編集パネルで Dockerfile を開きます。ファイルをクリックすると開きます。
e. 下のコードを Dockerfile ファイルにコピーして保存します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
テンプレートを実行するには、SDK 情報やメタデータなど、ジョブの実行に必要なすべての情報を含むテンプレート仕様ファイルを Cloud Storage に作成する必要があります。
a. IDE のファイル エクスプローラで dataflow_python/2_Branching_Pipelines/lab フォルダに新しいファイルを作成します。
b. 新しいファイルを作成するには、[ファイル] >> [新規] >> [テキスト ファイル] の順にクリックします。
c. ファイル名を metadata.json に変更します。ファイル名を右クリックすると変更できます。
d. 編集パネルで metadata.json ファイルを開きます。ファイルを開くには、metadata.json ファイルを右クリックし、[アプリで開く] >> [エディタ] の順に選択します。
e. このタスクを完了するには、パイプラインで想定されるすべての入力パラメータを記述する次の形式で、metadata.json ファイルを作成します。必要な場合は、こちらでソリューションを参照してください。独自の正規表現チェックを記述する必要があります。おすすめの方法ではありませんが、".*" はあらゆる入力に一致します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクを完了するには、以下の手順に沿って操作します。
GCP コンソールの Cloud Dataflow ページに移動します。
[テンプレートからジョブを作成] をクリックします。
[ジョブ名] フィールドに有効なジョブ名を入力します。
[Cloud Dataflow テンプレート] プルダウン メニューから [カスタム テンプレート] を選択します。
テンプレートの Cloud Storage パスのフィールドに、テンプレート ファイルへの Cloud Storage パスを入力します。
[必須パラメータ] に適切な項目を入力します。
a. [入力ファイルのパス] に、「
b. [出力ファイルの場所] に、「
c. [BigQuery 出力テーブル] に「
[ジョブを実行] をクリックします。
Dataflow テンプレートを使用する利点の一つは、開発環境以外のさまざまなコンテキストで実行できることです。それを確認するために、gcloud を使用してコマンドラインで Dataflow テンプレートを実行します。
このタスクを完了するには、以下のコマンドを、適宜パラメータを変更してターミナルで実行します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください