GSP1050

概览
Cloud Spanner 是 Google 的全托管式、可横向扩缩关系型数据库服务。金融服务、游戏、零售及众多其他行业的客户都信赖该服务,依托其运行自身要求最严苛的工作负载。在此类场景下进行大规模部署时,服务的一致性和可用性都至关重要。
在本实验中,您将回顾与架构相关的 Cloud Spanner 功能,并将这些功能应用于银行业务数据库。您还将回顾 Cloud Spanner 创建查询计划时所遵循的方法和规则。
您将执行的操作
在本实验中,您将学习修改 Cloud Spanner 实例的架构相关属性。
- 将数据加载到表中
- 使用预定义的 Python 客户端库代码来加载数据
- 使用客户端库查询数据
- 更新数据库架构
- 添加二级索引
- 审视查询计划
设置和要求
点击“开始实验”按钮前的注意事项
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。为此,我们会向您提供新的临时凭据,您可以在该实验的规定时间内通过此凭据登录和访问 Google Cloud。
为完成此实验,您需要:
- 能够使用标准的互联网浏览器(建议使用 Chrome 浏览器)。
注意:请使用无痕模式(推荐)或无痕浏览器窗口运行此实验。这可以避免您的个人账号与学生账号之间发生冲突,这种冲突可能导致您的个人账号产生额外费用。
注意:请仅使用学生账号完成本实验。如果您使用其他 Google Cloud 账号,则可能会向该账号收取费用。
如何开始实验并登录 Google Cloud 控制台
-
点击开始实验按钮。如果该实验需要付费,系统会打开一个对话框供您选择支付方式。右侧是实验设置和访问权限面板,其中包含以下内容:
-
打开 Google Cloud 控制台按钮
- 您在本实验中必须使用的临时凭证(用户名和密码)
- 帮助您逐步完成该实验所需的其他信息(如果需要)
请注意,实验计时器位于页面顶部附近,将显示剩余时间。
-
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示“登录”页面。
提示:可以将这些标签页分别放在不同的窗口中,并排显示。
注意:如果您看见选择账号对话框,请点击使用其他账号。
-
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
{{{user_0.username | "<用户名>"}}}
您也可以在实验设置和访问权限面板中找到“用户名”。
-
点击下一步。
-
复制下面的密码,然后将其粘贴到欢迎对话框中。
{{{user_0.password | "<密码>"}}}
您也可以在实验设置和访问权限面板中找到“密码”。
-
点击下一步。
重要提示:您必须使用实验提供的凭证。请勿使用您的 Google Cloud 账号凭证。
注意:在本实验中使用您自己的 Google Cloud 账号可能会产生额外费用。
-
依次点击进入后续页面:
- 接受条款及条件。
- 由于这是临时账号,请勿添加账号恢复选项或双重身份验证。
- 请勿注册免费试用。
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。
注意:如需访问 Google Cloud 产品和服务,请点击导航菜单,或在搜索字段中输入服务或产品的名称。

激活 Cloud Shell
Cloud Shell 是一种装有开发者工具的虚拟机。它提供了一个永久性的 5GB 主目录,并且在 Google Cloud 上运行。Cloud Shell 提供可用于访问您的 Google Cloud 资源的命令行工具。
-
点击 Google Cloud 控制台顶部的激活 Cloud Shell  。
。
-
在弹出的窗口中执行以下操作:
- 继续完成 Cloud Shell 信息窗口中的设置。
- 授权 Cloud Shell 使用您的凭据进行 Google Cloud API 调用。
如果您连接成功,即表示您已通过身份验证,且项目 ID 会被设为您的 Project_ID 。输出内容中有一行说明了此会话的 Project_ID:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud 是 Google Cloud 的命令行工具。它已预先安装在 Cloud Shell 上,且支持 Tab 自动补全功能。
- (可选)您可以通过此命令列出活跃账号名称:
gcloud auth list
- 点击授权。
输出:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (可选)您可以通过此命令列出项目 ID:
gcloud config list project
输出:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
注意:如需查看在 Google Cloud 中使用 gcloud 的完整文档,请参阅 gcloud CLI 概览指南。
Cloud Spanner 实例
为让您能够更快完成本实验,已为您自动创建 Cloud Spanner 实例、数据库和表。
以下是一些详细信息,供您参考:
| 项 |
名称 |
详细信息 |
| Cloud Spanner 实例 |
banking-ops-instance |
这是项目级实例 |
| Cloud Spanner 数据库 |
banking-ops-db |
这是实例专属数据库 |
| 表 |
Portfolio |
包含顶级银行产品/服务 |
| 表 |
Category |
包含第二级银行产品/服务分组 |
| 表 |
Product |
包含具体的银行产品/服务明细项 |
| 表 |
Campaigns |
包含营销计划的详细信息 |
任务 1. 将数据加载到表中
所创建的 banking-ops-db 包含空表。请按照以下步骤,将数据加载到 Portfolio、Category 和 Product 三个表中。
-
在 Cloud 控制台中,打开导航菜单 ( ) > 查看所有产品,然后在数据库下点击 Spanner。
) > 查看所有产品,然后在数据库下点击 Spanner。
-
实例名称为 banking-ops-instance,请点击该名称以探究数据库。
-
关联的数据库名为 banking-ops-db。点击该名称,向下滚动到表,您会看到已有四个表。
-
在控制台的左侧窗格中,点击 Spanner Studio。然后,点击右侧框架中的 + 新建 SQL 编辑器标签页按钮。
-
您将来到查询页面。将下面的 INSERT 语句作为一个整体代码块进行粘贴,以便为 Portfolio 表加载数据。Spanner 将依次执行每个语句。点击运行。
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (1, "Banking", "Bnkg", "All Banking Business");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (2, "Asset Growth", "AsstGrwth", "All Asset Focused Products");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (3, "Insurance", "Ins", "All Insurance Focused Products");
-
屏幕下半部分会显示逐行插入数据的结果。每一行插入数据还会分别显示一个绿色对勾标记。Portfolio 表现在有三行数据。
-
点击页面顶部的清除。
-
将下面的 INSERT 语句作为一个整体代码块进行粘贴,以便为 Category 表加载数据。点击运行:
insert into Category (CategoryId,PortfolioId,CategoryName) values (1,1,"Cash");
insert into Category (CategoryId,PortfolioId,CategoryName) values (2,2,"Investments - Short Return");
insert into Category (CategoryId,PortfolioId,CategoryName) values (3,2,"Annuities");
insert into Category (CategoryId,PortfolioId,CategoryName) values (4,3,"Life Insurance");
-
屏幕下半部分会显示逐行插入数据的结果。每一行插入数据还会分别显示一个绿色对勾标记。Category 表现在有四行数据。
-
点击页面顶部的清除。
-
将下面的 INSERT 语句作为一个整体代码块进行粘贴,以便为 Product 表加载数据。点击运行:
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (1,1,1,"Checking Account","ChkAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (2,2,2,"Mutual Fund Consumer Goods","MFundCG","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (3,3,2,"Annuity Early Retirement","AnnuFixed","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (4,4,3,"Term Life Insurance","TermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (5,1,1,"Savings Account","SavAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (6,1,1,"Personal Loan","PersLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (7,1,1,"Auto Loan","AutLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (8,4,3,"Permanent Life Insurance","PermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (9,2,2,"US Savings Bonds","USSavBond","Investment LOB");
-
屏幕下半部分会显示逐行插入数据的结果。每一行插入数据还会分别显示一个绿色对勾标记。Product 表现在有九行数据。
-
点击检查我的进度以验证是否完成了以下目标:
将数据加载到 Portfolio、Category 和 Product 表中
任务 2. 使用预构建的 Python 客户端库代码来加载数据
在接下来的几个步骤中,您将使用以 Python 编写的客户端库。
- 打开 Cloud Shell,粘贴以下命令以创建新目录并切换到该目录,以便存放所需的文件。
mkdir python-helper
cd python-helper
- 接下来,下载两个文件。其中一个文件用于设置环境。另一个文件是实验代码。
wget https://storage.googleapis.com/cloud-training/OCBL373/requirements.txt
wget https://storage.googleapis.com/cloud-training/OCBL373/snippets.py
- 创建一个隔离的 Python 环境,并安装 Cloud Spanner 客户端的依赖项。
pip install -r requirements.txt
pip install setuptools
-
snippets.py 是一个包含多个 Cloud Spanner DDL、DML 和 DCL 函数的合并文件,您将在本实验中将其用作辅助工具。使用 insert_data 参数执行 snippets.py,以便填充 Campaigns 表。
python snippets.py banking-ops-instance --database-id banking-ops-db insert_data
- 点击检查我的进度以验证是否完成了以下目标:
将数据加载到 Campaigns 表中
任务 3. 使用客户端库查询数据
snippets.py 中的 query_data() 函数可用于查询数据库。在本例中,您将使用它来确认数据已加载到 Campaigns 表中。请勿更改任何代码,此处显示了该部分供您参考。
def query_data(instance_id, database_id):
"""Queries sample data from the database using SQL."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
results = snapshot.execute_sql(
"SELECT CampaignId,PortfolioId,CampaignStartDate,CampaignEndDate,CampaignName,CampaignBudget FROM Campaigns"
)
for row in results:
print(u"CampaignId: {}, PortfolioId: {}, CampaignStartDate: {}, CampaignEndDate: {}, CampaignName: {}, CampaignBudget: {}".format(*row))
- 使用 query_data 参数执行 snippets.py,以便查询 Campaigns 表。
python snippets.py banking-ops-instance --database-id banking-ops-db query_data
结果应如下所示
CampaignId: 1, PortfolioId: 1, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: New Account Reward, CampaignBudget: 15000
CampaignId: 2, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Intro to Investments, CampaignBudget: 5000
CampaignId: 3, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Youth Checking Accounts, CampaignBudget: 25000
CampaignId: 4, PortfolioId: 3, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Protect Your Family, CampaignBudget: 10000
任务 4. 更新数据库架构
作为数据库管理员 (DBA),职责要求您向 Category 表添加一个名为 MarketingBudget 的新列。向现有表添加新列需要更新数据库架构。Cloud Spanner 支持在数据库继续处理流量的同时,对数据库进行架构更新。架构更新不需要使数据库离线,也不会锁定整个表或列;在架构更新期间,您可以继续对数据库进行数据读写操作。
使用 Python 添加列
Database 类的 update_ddl() 方法用于修改架构。
请使用 snippets.py 中的 add_column() 函数,该函数实现了上述方法。请勿更改任何代码,此处显示了该部分供您参考。
def add_column(instance_id, database_id):
"""Adds a new column to the Albums table in the example database."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["ALTER TABLE Category ADD COLUMN MarketingBudget INT64"]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the MarketingBudget column.")
- 使用 add_column 参数执行 snippets.py。
python snippets.py banking-ops-instance --database-id banking-ops-db add_column
- 点击检查我的进度以验证是否完成了以下目标:
向 Category 表中添加列
向现有表中添加列的其他可选方法包括:
通过 gcloud CLI 发出 DDL 命令。
注意:此方法仅作为备选示例展示。请勿发出此命令。
下面的代码示例同样会完成您刚才通过 Python 执行的任务。
gcloud spanner databases ddl update banking-ops-db --instance=banking-ops-instance --ddl='ALTER TABLE Category ADD COLUMN MarketingBudget INT64;'
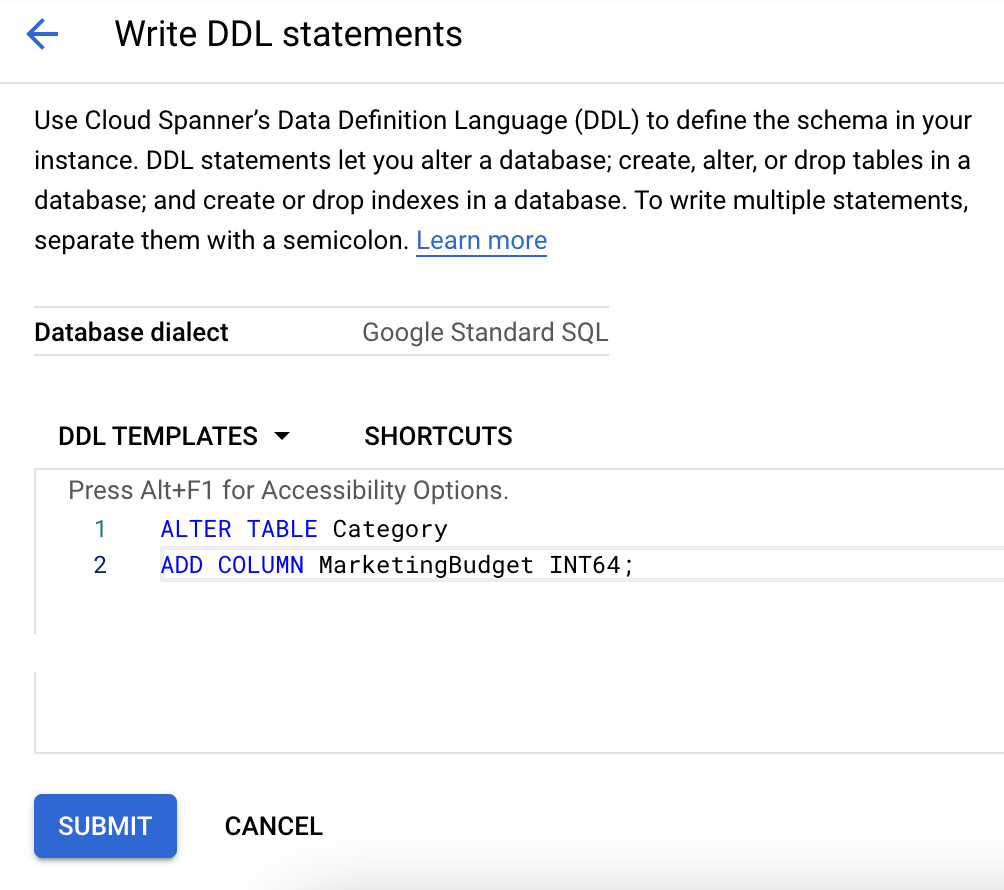
在 Cloud 控制台中发出 DDL 命令。
注意:此方法仅作为备选示例展示。请勿执行此操作。
- 点击数据库列表中的表名称。
- 点击页面右上角的编写 DDL。
- 将相应的 DDL 粘贴到 DDL 模板框中。
- 点击提交。
将数据写入新列
以下代码可将数据写入新列。对于 CategoryId 为 1 且 PortfolioId 为 1 的行,它会将 MarketingBudget 设置为 100000;对于 CategoryId 为 3 且 PortfolioId 为 2 的行,则设置为 500000。请勿更改任何代码,此处显示了该部分供您参考。
def update_data(instance_id, database_id):
"""Updates sample data in the database.
This updates the `MarketingBudget` column which must be created before
running this sample. You can add the column by running the `add_column`
sample or by running this DDL statement against your database
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.batch() as batch:
batch.update(
table="Category",
columns=("CategoryId", "PortfolioId", "MarketingBudget"),
values=[(1, 1, 100000), (3, 2, 500000)],
)
print("Updated data.")
- 使用 update_data 参数执行 snippets.py。
python snippets.py banking-ops-instance --database-id banking-ops-db update_data
- 再次查询该表,查看更新结果。使用 query_data_with_new_column 参数执行 snippets.py。
python snippets.py banking-ops-instance --database-id banking-ops-db query_data_with_new_column
结果应为:
CategoryId: 1, PortfolioId: 1, MarketingBudget: 100000
CategoryId: 2, PortfolioId: 2, MarketingBudget: None
CategoryId: 3, PortfolioId: 2, MarketingBudget: 500000
CategoryId: 4, PortfolioId: 3, MarketingBudget: None
任务 5. 添加二级索引
假设您想要提取 Categories 表中 CategoryNames 值处于某一范围内的所有行。您可以使用 SQL 语句或读取调用,来读取 CategoryName 列中的所有值,然后舍弃不符合条件的行。不过,执行这种全表扫描开销很大,对包含大量行的表来说更是如此。相反,如果对表创建二级索引,按非主键列进行搜索,则可以提高行检索速度。
向现有表中添加二级索引需要更新架构。与其他架构更新一样,Cloud Spanner 支持在数据库继续处理流量的同时添加索引。Cloud Spanner 会在后台使用数据来填充索引(也称为“回填”)。回填可能需要几分钟才能完成,但在此过程中,您无需使数据库离线,也无需避免向某些表或列执行写操作。
使用 Python 客户端库添加二级索引
使用 add_index() 方法创建二级索引。请勿更改任何代码,此处显示了该部分供您参考。
def add_index(instance_id, database_id):
"""Adds a simple index to the example database."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["CREATE INDEX CategoryByCategoryName ON Category(CategoryName)"]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the CategoryByCategoryName index.")
- 使用 add_index 参数执行 snippets.py。
python snippets.py banking-ops-instance --database-id banking-ops-db add_index
- 点击检查我的进度以验证是否完成了以下目标:
向 Category 表中添加二级索引
使用索引读取数据
如需使用索引来读取数据,请调用包含索引参数的 read() 方法的变体。请勿更改任何代码,此处显示了该部分供您参考。
def read_data_with_index(instance_id, database_id):
"""Reads sample data from the database using an index.
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName"),
keyset=keyset,
index="CategoryByCategoryName",
)
for row in results:
print("CategoryId: {}, CategoryName: {}".format(*row))
- 使用 read_data_with_index 参数执行 snippets.py。
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_index
结果应如下所示:
CategoryId: 3, CategoryName: Annuities
CategoryId: 1, CategoryName: Cash
CategoryId: 2, CategoryName: Investments - Short Return
CategoryId: 4, CategoryName: Life Insurance
添加带 STORING 子句的索引
您可能已经注意到,上面的读取示例没有包含读取 MarketingBudget 列。这是因为,Cloud Spanner 的读取接口不支持将索引与数据表联接起来,以查找未存储在索引中的值。
为了绕过此限制,请创建 CategoryByCategoryName 索引的备选定义,在索引中存储 MarketingBudget 的副本。
使用 Database 类的 update_ddl() 方法,添加带 STORING 子句的索引。请勿更改任何代码,此处显示了该部分供您参考。
def add_storing_index(instance_id, database_id):
"""Adds an storing index to the example database."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
[
"CREATE INDEX CategoryByCategoryName2 ON Category(CategoryName)"
"STORING (MarketingBudget)"
]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the CategoryByCategoryName2 index.")
- 使用 add_storing_index 参数执行 snippets.py。
python snippets.py banking-ops-instance --database-id banking-ops-db add_storing_index
现在,您可以在使用 CategoryByCategoryName2 索引的同时,执行读取操作来提取 CategoryId、CategoryName 和 MarketingBudget 列中的数据。请勿更改任何代码,此处显示了该部分供您参考。
def read_data_with_storing_index(instance_id, database_id):
"""Reads sample data from the database using an index with a storing
clause.
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName", "MarketingBudget"),
keyset=keyset,
index="CategoryByCategoryName2",
)
for row in results:
print(u"CategoryNameId: {}, CategoryName: {}, " "MarketingBudget: {}".format(*row))
- 使用 read_data_with_storing_index 参数执行 snippets.py。
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_storing_index
结果应为
CategoryNameId: 3, CategoryName: Annuities, MarketingBudget: 500000
CategoryNameId: 1, CategoryName: Cash, MarketingBudget: 100000
CategoryNameId: 2, CategoryName: Investments - Short Return, MarketingBudget: None
CategoryNameId: 4, CategoryName: Life Insurance, MarketingBudget: None
任务 6. 审视查询计划
在本部分,您将探索 Cloud Spanner 查询计划。
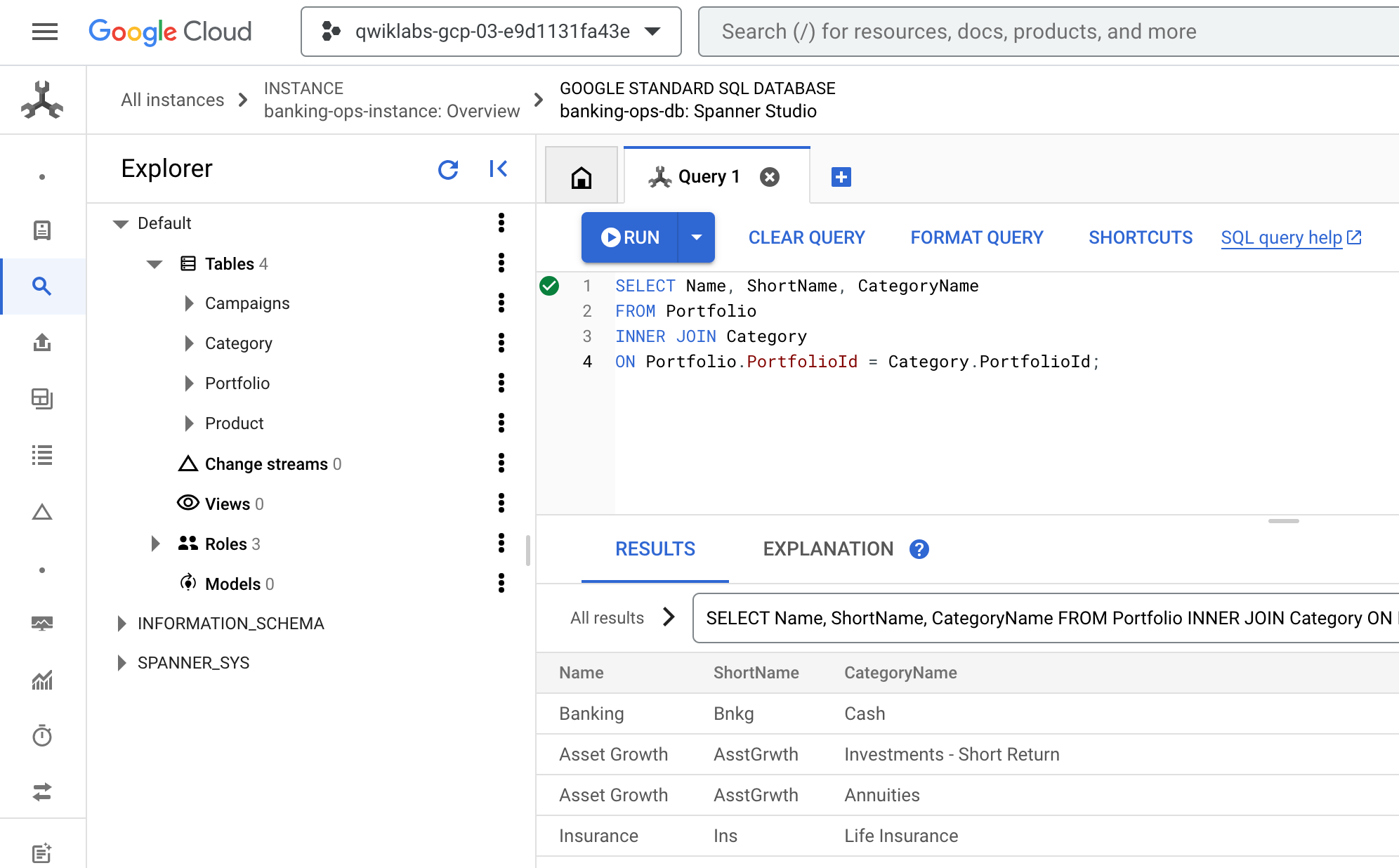
- 返回 Cloud 控制台,它应该仍然位于 Spanner Studio 的查询标签页上。清除所有现有查询,粘贴并运行以下查询:
SELECT Name, ShortName, CategoryName
FROM Portfolio
INNER JOIN Category
ON Portfolio.PortfolioId = Category.PortfolioId;
- 结果应如下所示:
查询的生命周期
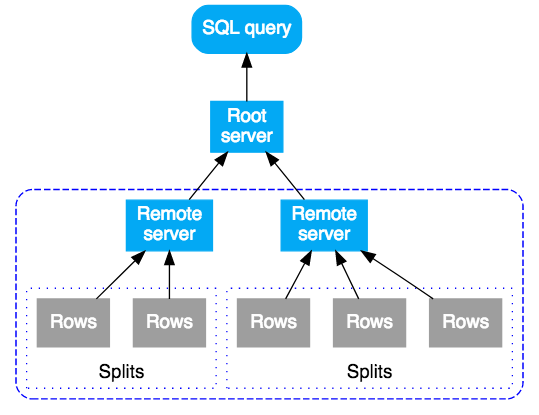
Cloud Spanner 中的 SQL 查询首先被编译为执行计划,然后发送到初始根服务器进行执行。之所以选择根服务器,是为了最大限度减少到达所查询的数据而经历的跃点数。根服务器然后执行以下操作:
- 启动子计划的远程执行(如有必要)
- 等待远程执行的结果
- 处理剩余的本地执行步骤,例如聚合结果
- 返回查询的结果
接收子计划的远程服务器充当其子计划的“根”服务器,遵循与最顶层根服务器相同的模式。其结果是一个远程执行树。从概念上讲,查询执行从上到下进行,而查询结果自下而上返回。以下图表展示了这种模式:
聚合查询
现在来看一下聚合查询的查询计划。
- 在 Spanner Studio 的查询标签页中,清除现有查询,粘贴并运行以下查询。
SELECT pr.ProductId, COUNT(*) AS ProductCount
FROM Product AS pr
WHERE pr.ProductId < 100
GROUP BY pr.ProductId;
- 查询完成后,点击查询主体下方的解释标签页,审视查询计划。
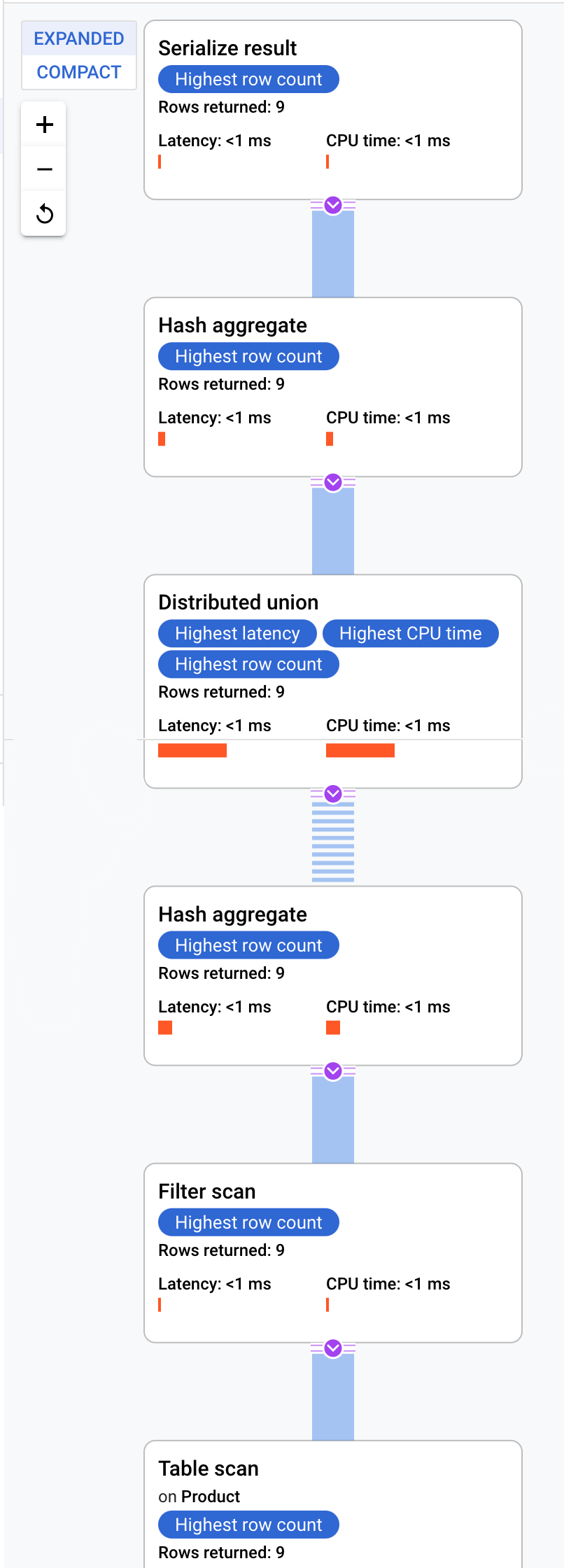
Cloud Spanner 会将执行计划发送到根服务器,该服务器将负责协调查询的执行并执行子计划的远程分发。
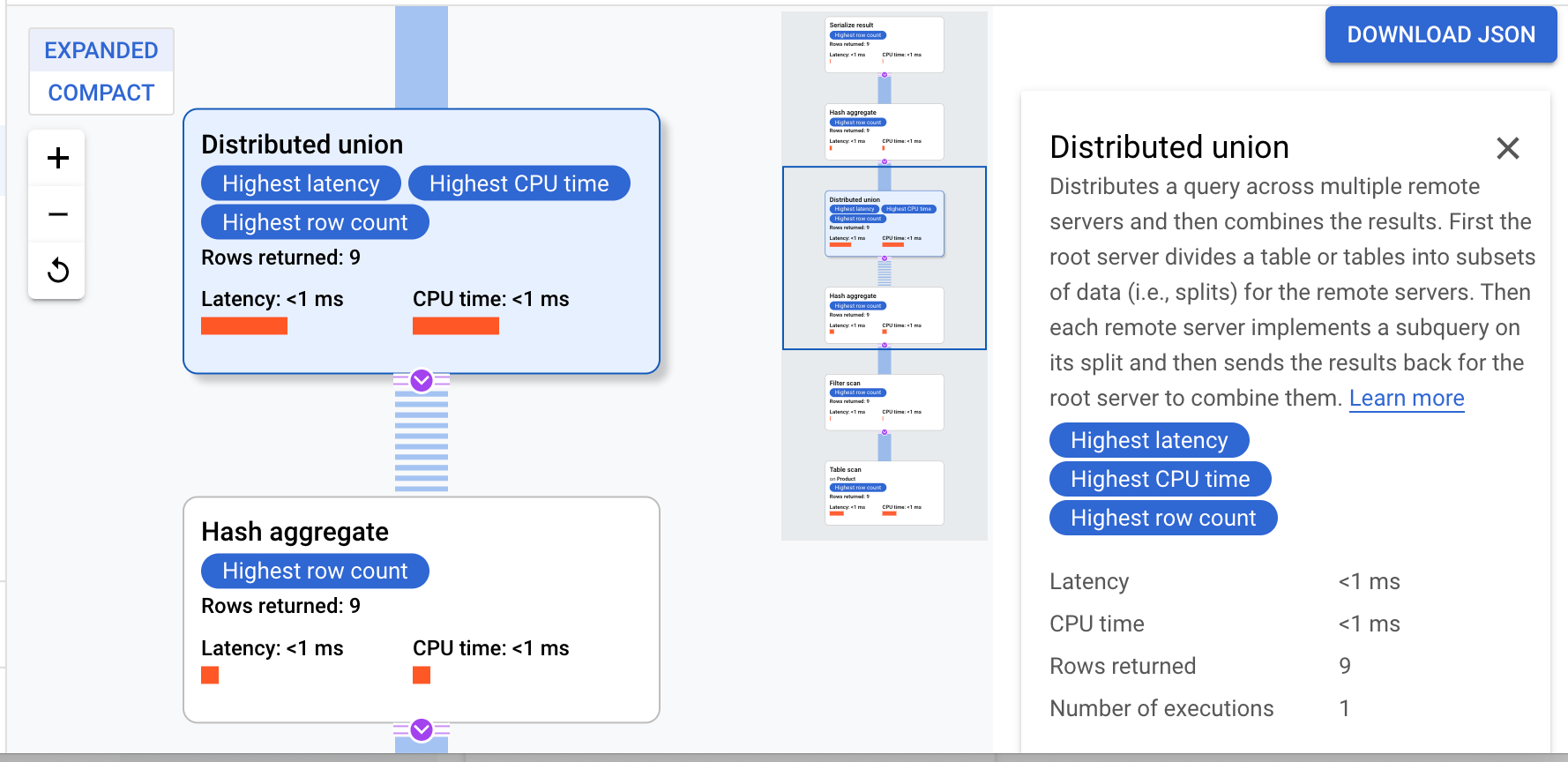
此执行计划首先进行序列化,对所有返回的值进行排序。然后,该计划会完成初始哈希聚合操作符的执行,以初步计算结果。接下来执行分布式联合,将子计划分发给那些数据分块满足 ProductId < 100 条件的远程服务器。分布式联合会将结果发送给最终哈希聚合操作符。该聚合操作符会按 ProductId 执行 COUNT 聚合,并将结果返回给序列化结果操作符。最后执行扫描,对要返回的结果进行排序。
结果应如下所示:
提示:如需了解查询计划中每个步骤的更多详细信息,请点击任意操作符,屏幕右侧将相应地发生变化。
同位联接查询
交错表以物理方式进行存储,会将相关表的行共同放置在一处。交错表之间的联接称为同位联接。与需要索引的联接或回表联接相比,同位联接具备性能优势。
- 在 Spanner Studio 的查询标签页中,清除现有查询,粘贴并运行以下查询。
SELECT c.CategoryName, pr.ProductName
FROM Category AS c, Product AS pr
WHERE c.PortfolioId = pr.PortfolioId AND c.CategoryId = pr.CategoryId;
- 查询完成后,点击查询主体下方的解释标签页,审视查询计划。
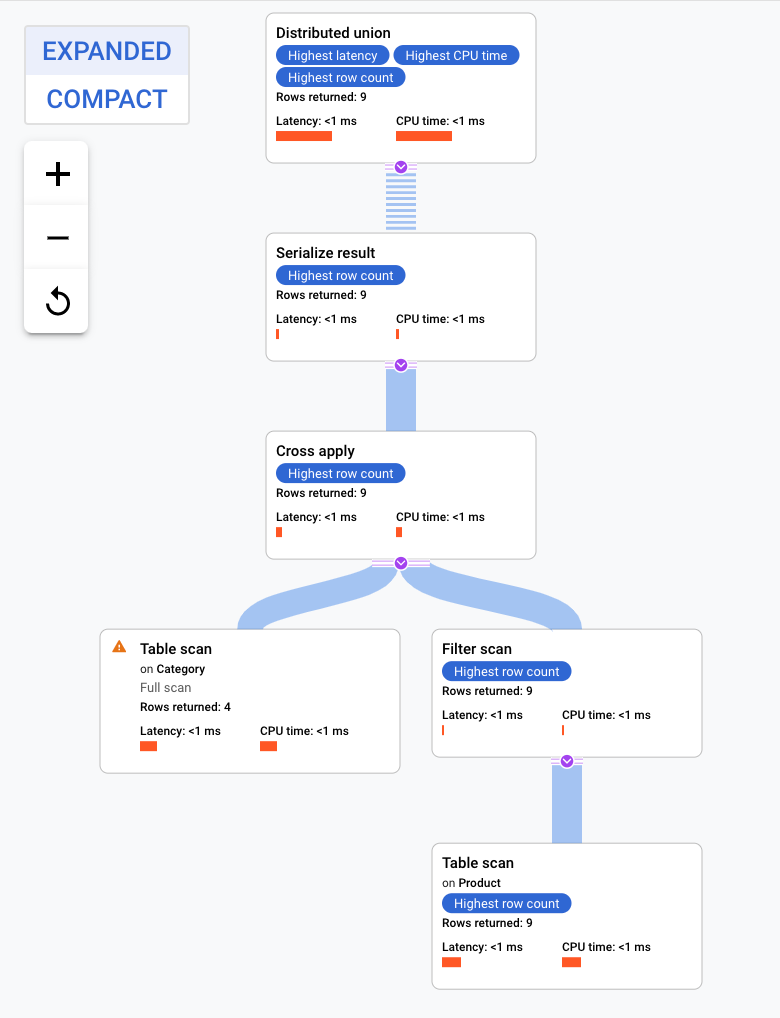
此执行计划首先执行分布式联合,将子计划分发到具有 Category 表数据分块的远程服务器。由于 Product 是 Category 的交错表,因此每台远程服务器都可以执行整个子计划,而无需联接其他服务器。
子计划包含交叉应用操作。每一次交叉应用操作都会对 Category 表执行表扫描,以检索 PortfolioId、CategoryId 和 CategoryName。然后,交叉应用操作会将表扫描的输出,映射到对 CategoryByCategoryName 索引执行的索引扫描输出,所遵循的过滤条件是索引中的 PortfolioId 与表扫描输出中的 PortfolioId 相匹配。每一次交叉应用操作都会将其结果发送给序列化结果操作符,该操作符会将 CategoryName 和 ProductName 数据序列化,并将结果返回给局部分布式联合。分布式联合会聚合来自局部分布式联合的结果,并将其作为查询结果返回。
恭喜!
现在,您已经对 Cloud Spanner 的架构相关功能以及 Spanner 创建查询计划的方法有了扎实的理解。
Google Cloud 培训和认证
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
上次更新手册的时间:2024 年 10 月 14 日
上次测试实验的时间:2024 年 10 月 14 日
版权所有 2026 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。





