GSP1050

Aspectos gerais
O Cloud Spanner é o serviço de banco de dados relacional do Google, totalmente gerenciado e com capacidade de escalonamento horizontal. Ele costuma ser usado para a execução de cargas de trabalho mais exigentes, em que a consistência e a disponibilidade em grande escala são essenciais. Clientes de diversos setores, como serviços financeiros, jogos, varejo, entre outros, já usam o Spanner.
Neste laboratório, vamos analisar os recursos de esquemas do Cloud Spanner e aplicá-los a um banco de dados de operações bancárias. Você também vai conhecer os métodos e as regras que o Cloud Spanner usa para criar planos de consulta.
Atividades deste laboratório
Neste laboratório, você vai aprender a modificar atributos de esquemas de uma instância do Cloud Spanner.
- Carregar dados em tabelas
- Usar o código predefinido da biblioteca de cliente Python para carregar dados
- Consultar dados com bibliotecas de cliente
- Fazer atualizações no esquema do banco de dados
- Adicionar um índice secundário
- Analisar planos de consulta
Configuração e requisitos
Antes de clicar no botão Começar o Laboratório
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é ativado quando você clica em Iniciar laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, e não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima (recomendado) ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e de estudante, o que poderia causar cobranças extras na sua conta pessoal.
- Tempo para concluir o laboratório: não se esqueça que, depois de começar, não será possível pausar o laboratório.
Observação: use apenas a conta de estudante neste laboratório. Se usar outra conta do Google Cloud, você poderá receber cobranças nela.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar laboratório. Se for preciso pagar por ele, uma caixa de diálogo vai aparecer para você selecionar a forma de pagamento.
À direita, você encontra o painel Configuração e acesso ao laboratório com as seguintes informações:
- O botão Abrir console do Google Cloud
- As credenciais temporárias (nome de usuário e senha) que você vai usar no laboratório
- Outros dados, se necessários
O timer do laboratório fica na parte de cima da página e mostra o tempo restante.
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página "Login" em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
-
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Login.
{{{user_0.username | "Username"}}}
Você também encontra o nome de usuário no painel Configuração e acesso ao laboratório.
-
Clique em Avançar.
-
Copie a Senha abaixo e cole na caixa de diálogo Olá!.
{{{user_0.password | "Password"}}}
Você também encontra a senha no painel Configuração e acesso ao laboratório.
-
Clique em Avançar.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, talvez receba cobranças adicionais.
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes sem custo financeiro.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.
Observação: para acessar os produtos e serviços do Google Cloud, clique no Menu de navegação ou digite o nome do serviço ou produto no campo Pesquisar.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual com várias ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
-
Clique em Ativar o Cloud Shell  na parte de cima do console do Google Cloud.
na parte de cima do console do Google Cloud.
-
Clique nas seguintes janelas:
- Continue na janela de informações do Cloud Shell.
- Autorize o Cloud Shell a usar suas credenciais para fazer chamadas de APIs do Google Cloud.
Depois de se conectar, você verá que sua conta já está autenticada e que o projeto está configurado com seu Project_ID, . A saída contém uma linha que declara o projeto PROJECT_ID para esta sessão:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
- (Opcional) É possível listar o nome da conta ativa usando este comando:
gcloud auth list
- Clique em Autorizar.
Saída:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (Opcional) É possível listar o ID do projeto usando este comando:
gcloud config list project
Saída:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Observação: consulte a documentação completa da gcloud no Google Cloud no guia de visão geral da gcloud CLI.
Instância do Cloud Spanner
Para você progredir mais rapidamente neste laboratório, uma instância do Cloud Spanner, um banco de dados e tabelas foram criados de forma automática.
Confira alguns detalhes:
| Item |
Nome |
Detalhes |
| Instância do Cloud Spanner |
banking-ops-instance |
Essa é a instância do projeto |
| Banco de dados do Cloud Spanner |
banking-ops-db |
Esse é o banco de dados específico da instância |
| Tabela |
Portfólio |
Contém soluções bancárias de nível superior |
| Tabela |
Categoria |
Contém agrupamentos de soluções bancárias secundárias |
| Tabela |
Produto |
Contém soluções bancárias de itens de linha específicos |
| Tabela |
Campanhas |
Contém detalhes sobre iniciativas de marketing |
Tarefa 1: carregar dados em tabelas
O banking-ops-db foi criado com tabelas vazias. Siga as etapas abaixo para carregar dados em três tabelas: Portfólio, Categoria e Produto.
-
No console do Cloud, abra o menu de navegação ( ) > Ver todos os produtos. Em Bancos de dados, clique em Spanner.
) > Ver todos os produtos. Em Bancos de dados, clique em Spanner.
-
O nome da instância é banking-ops-instance. Clique no nome para conferir os bancos de dados.
-
O banco de dados associado é chamado de banking-ops-db. Clique no nome e role para baixo até Tabelas. Já existem quatro tabelas.
-
No painel esquerdo do console, clique em Spanner Studio. No frame à direita, clique no botão + Nova guia do SQL Editor.
-
A página Consulta será exibida. Cole as instruções "insert" abaixo como um único bloco para carregar a tabela Portfólio. O Spanner vai executar cada uma delas em sequência. Clique em Executar:
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (1, "Banking", "Bnkg", "All Banking Business");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (2, "Asset Growth", "AsstGrwth", "All Asset Focused Products");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (3, "Insurance", "Ins", "All Insurance Focused Products");
-
A parte de baixo da tela mostra os resultados da inserção dos dados, uma linha por vez. Uma marca de seleção verde aparece em cada linha dos dados inseridos. A tabela Portfólio vai exibir três linhas.
-
Clique em Limpar na parte de cima da página.
-
Cole as instruções "insert" abaixo como um único bloco para carregar a tabela Categoria. Clique em Executar:
insert into Category (CategoryId,PortfolioId,CategoryName) values (1,1,"Cash");
insert into Category (CategoryId,PortfolioId,CategoryName) values (2,2,"Investments - Short Return");
insert into Category (CategoryId,PortfolioId,CategoryName) values (3,2,"Annuities");
insert into Category (CategoryId,PortfolioId,CategoryName) values (4,3,"Life Insurance");
-
A parte de baixo da tela mostra os resultados da inserção dos dados, uma linha por vez. Uma marca de seleção verde aparece em cada linha dos dados inseridos. A tabela Categoria vai exibir quatro linhas.
-
Clique em Limpar na parte de cima da página.
-
Cole as instruções "insert" abaixo como um único bloco para carregar a tabela Produto. Clique em Executar:
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (1,1,1,"Checking Account","ChkAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (2,2,2,"Mutual Fund Consumer Goods","MFundCG","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (3,3,2,"Annuity Early Retirement","AnnuFixed","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (4,4,3,"Term Life Insurance","TermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (5,1,1,"Savings Account","SavAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (6,1,1,"Personal Loan","PersLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (7,1,1,"Auto Loan","AutLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (8,4,3,"Permanent Life Insurance","PermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (9,2,2,"US Savings Bonds","USSavBond","Investment LOB");
-
A parte de baixo da tela mostra os resultados da inserção dos dados, uma linha por vez. Uma marca de seleção verde aparece em cada linha dos dados inseridos. A tabela Produto vai exibir nove linhas.
-
Clique em Verificar meu progresso para conferir o objetivo.
Carregar dados nas tabelas "Portfólio", "Categoria" e "Produto"
Tarefa 2: usar o código pré-criado da biblioteca de cliente Python para carregar dados
Você vai usar as bibliotecas de cliente escritas em Python nas próximas etapas.
- Abra o Cloud Shell e cole os comandos abaixo para criar e mudar para um novo diretório e armazenar os arquivos necessários.
mkdir python-helper
cd python-helper
- Em seguida, baixe dois arquivos. Um será usado para configurar o ambiente. O outro é o código do laboratório.
wget https://storage.googleapis.com/cloud-training/OCBL373/requirements.txt
wget https://storage.googleapis.com/cloud-training/OCBL373/snippets.py
- Crie um ambiente Python isolado e instale as dependências do cliente do Cloud Spanner.
pip install -r requirements.txt
pip install setuptools
- O snippets.py é um arquivo consolidado com várias funções DDL, DML e DCL do Cloud Spanner, que vão auxiliar você neste laboratório. Para preencher a tabela Campanhas, execute snippets.py usando o argumento insert_data.
python snippets.py banking-ops-instance --database-id banking-ops-db insert_data
- Clique em Verificar meu progresso para conferir o objetivo.
Carregar dados na tabela "Campanhas"
Tarefa 3: consultar dados com bibliotecas de cliente
É possível usar a função query_data() em snippets.py para consultar o banco de dados. Nesse caso, use-a para confirmar os dados carregados na tabela Campanhas. Como esta seção serve apenas como referência, você não precisa mudar o código.
def query_data(instance_id, database_id):
"""Consulta dados de amostra do banco de dados usando SQL."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
results = snapshot.execute_sql(
"SELECT CampaignId,PortfolioId,CampaignStartDate,CampaignEndDate,CampaignName,CampaignBudget FROM Campaigns"
)
for row in results:
print(u"CampaignId: {}, PortfolioId: {}, CampaignStartDate: {}, CampaignEndDate: {}, CampaignName: {}, CampaignBudget: {}".format(*row))
- Para consultar a tabela Campanhas, execute snippets.py usando o argumento query_data.
python snippets.py banking-ops-instance --database-id banking-ops-db query_data
O resultado precisa ser semelhante a este:
CampaignId: 1, PortfolioId: 1, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: New Account Reward, CampaignBudget: 15000
CampaignId: 2, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Intro to Investments, CampaignBudget: 5000
CampaignId: 3, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Youth Checking Accounts, CampaignBudget: 25000
CampaignId: 4, PortfolioId: 3, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Protect Your Family, CampaignBudget: 10000
Tarefa 4: como atualizar o esquema do banco de dados
Como parte das responsabilidades de DBA, você precisa adicionar uma nova coluna chamada MarketingBudget à tabela Categoria. Para isso, atualize o esquema do banco de dados. Com o Cloud Spanner, é possível atualizar esquemas, enquanto o banco de dados continua a disponibilizar o tráfego. Para atualizar esquemas, não é necessário desconectar o banco de dados nem bloquear tabelas ou colunas inteiras. É possível ler e gravar dados no banco de dados durante a atualização.
Como usar Python para adicionar uma coluna
O método update_ddl() da classe Banco de dados modifica o esquema.
Use a função add_column() em snippets.py para implementar esse método. Como esta seção serve apenas como referência, você não precisa mudar o código.
def add_column(instance_id, database_id):
"""Adiciona uma coluna à tabela ‘Álbuns’ no exemplo de banco de dados."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["ALTER TABLE Category ADD COLUMN MarketingBudget INT64"]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the MarketingBudget column.")
- Use o argumento add_column para executar snippets.py.
python snippets.py banking-ops-instance --database-id banking-ops-db add_column
- Clique em Verificar meu progresso para conferir o objetivo.
Adicionar coluna à tabela "Categoria"
Estas são outras opções para adicionar uma coluna a uma tabela:
Executar um comando DDL usando a gcloud CLI.
Observação: esta opção é mostrada como um exemplo alternativo. Não execute este comando.
O exemplo de código abaixo realiza a mesma tarefa que você acabou de executar usando Python.
gcloud spanner databases ddl update banking-ops-db --instance=banking-ops-instance --ddl='ALTER TABLE Category ADD COLUMN MarketingBudget INT64;'
Executar um comando DDL no console do Cloud.
Observação: esta opção é mostrada como um exemplo alternativo. Não realize esta ação.
- Clique no nome da tabela na lista de bancos de dados.
- Clique em Gravar DDL no canto superior direito da página.
- Cole o DDL apropriado na caixa Modelos DDL.
- Clique em Enviar.
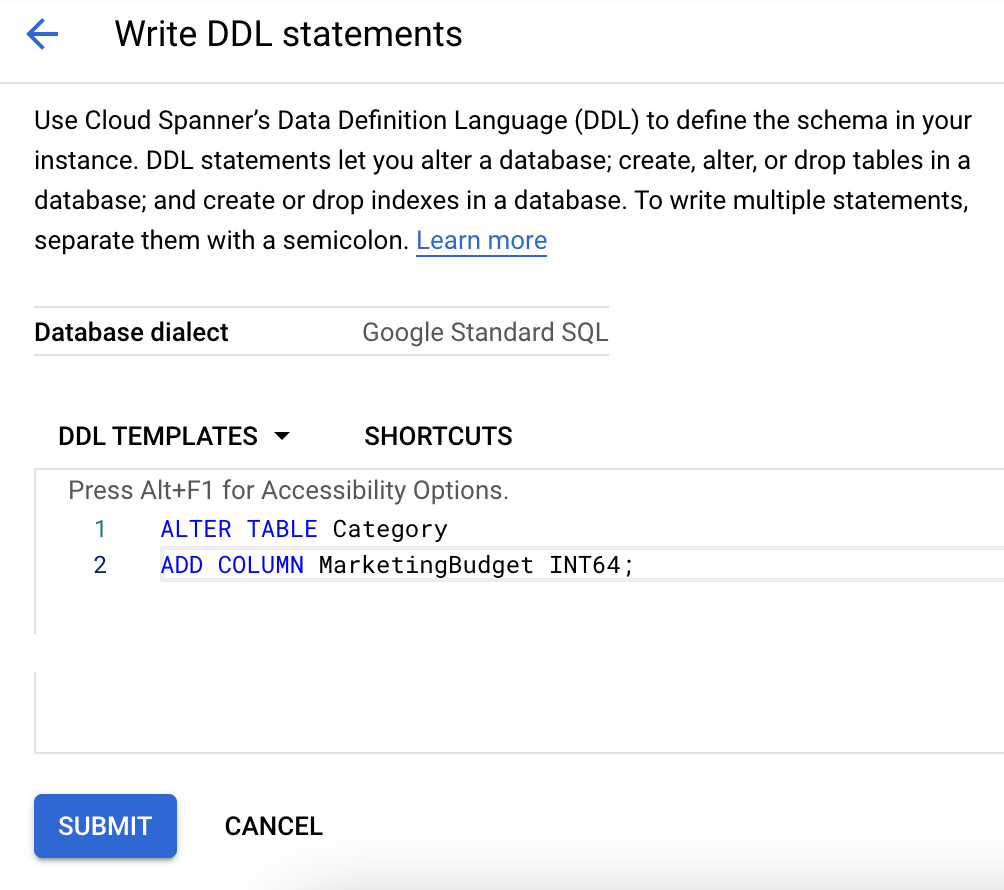
Gravar dados na coluna nova
O código a seguir grava dados na coluna nova. Ele define MarketingBudget como 100000 para a linha com CategoryId 1 e PortfolioId 1, e como 500000 para a linha com CategoryId 3 e PortfolioId 2. Como esta seção serve apenas como referência, você não precisa mudar o código.
def update_data(instance_id, database_id):
"""Atualiza os dados de amostra no banco de dados.
Atualiza a coluna ‘MarketingBudget’, que precisa ser criada antes
da execução desta amostra. É possível adicionar a coluna executando o exemplo ‘add_column’
ou esta instrução DDL no banco de dados
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.batch() as batch:
batch.update(
table="Category",
columns=("CategoryId", "PortfolioId", "MarketingBudget"),
values=[(1, 1, 100000), (3, 2, 500000)],
)
print("Updated data.")
- Use o argumento update_data para executar snippets.py.
python snippets.py banking-ops-instance --database-id banking-ops-db update_data
- Consulte a tabela novamente para conferir a atualização. Use o argumento query_data_with_new_column para executar snippets.py.
python snippets.py banking-ops-instance --database-id banking-ops-db query_data_with_new_column
O resultado precisa ser:
CategoryId: 1, PortfolioId: 1, MarketingBudget: 100000
CategoryId: 2, PortfolioId: 2, MarketingBudget: None
CategoryId: 3, PortfolioId: 2, MarketingBudget: 500000
CategoryId: 4, PortfolioId: 3, MarketingBudget: None
Tarefa 5: adicionar um índice secundário
Suponha que você queira encontrar todas as linhas da tabela "Categorias" que tenham valores "CategoryNames" em um determinado intervalo. É possível usar uma instrução SQL ou uma chamada de leitura para ler todos os valores da coluna CategoryName e descartar as linhas que não atendem aos critérios, mas fazer essa verificação na tabela inteira é caro, especialmente quando há muitas linhas. Em vez disso, ao pesquisar colunas principais não primárias, crie um índice secundário na tabela para acelerar a recuperação de linhas.
Adicionar um índice secundário a uma tabela requer uma atualização de esquema. Como outras atualizações de esquema, com o Cloud Spanner, é possível adicionar um índice enquanto o banco de dados continua a disponibilizar o tráfego. O Cloud Spanner preenche o índice com dados (também conhecido como "backfill") em segundo plano. Os preenchimentos podem demorar alguns minutos para serem concluídos, mas não é necessário deixar o banco de dados off-line ou evitar a gravação em determinadas tabelas ou colunas durante esse processo.
Adicionar um índice secundário usando a biblioteca de cliente Python
Use o método add_index() para criar um índice secundário. Como esta seção serve apenas como referência, você não precisa mudar o código.
def add_index(instance_id, database_id):
"""Adiciona um índice simples ao exemplo de banco de dados."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["CREATE INDEX CategoryByCategoryName ON Category(CategoryName)"]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the CategoryByCategoryName index.")
- Use o argumento add_index para executar snippets.py.
python snippets.py banking-ops-instance --database-id banking-ops-db add_index
- Clique em Verificar meu progresso para conferir o objetivo.
Adicionar índice secundário à tabela "Categorias"
Ler usando o índice
Para fazer uma leitura com o índice, invoque uma variação do método read() com um índice incluído. Como esta seção serve apenas como referência, você não precisa mudar o código.
def read_data_with_index(instance_id, database_id):
"""Lê dados de amostra do banco de dados usando um índice.
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName"),
keyset=keyset,
index="CategoryByCategoryName",
)
for row in results:
print("CategoryId: {}, CategoryName: {}".format(*row))
- Use o argumento read_data_with_index para executar snippets.py.
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_index
O resultado precisa ser semelhante a este:
CategoryId: 3, CategoryName: Annuities
CategoryId: 1, CategoryName: Cash
CategoryId: 2, CategoryName: Investments - Short Return
CategoryId: 4, CategoryName: Life Insurance
Adicionar um índice com uma cláusula STORING
Observe que o exemplo de leitura acima não inclui a leitura da coluna MarketingBudget. Isso acontece porque a interface de leitura do Cloud Spanner não mescla um índice com uma tabela de dados para pesquisar valores que não estão armazenados no índice.
Para contornar essa restrição, crie uma definição alternativa do índice CategoryByCategoryName que armazene uma cópia de MarketingBudget no próprio índice.
Use o método update_ddl() da classe "Banco de dados" para adicionar um índice com uma cláusula STORING. Como esta seção serve apenas como referência, você não precisa mudar o código.
def add_storing_index(instance_id, database_id):
"""Inclui um índice ‘Storing’ ao exemplo de banco de dados."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
[
"CREATE INDEX CategoryByCategoryName2 ON Category(CategoryName)"
"STORING (MarketingBudget)"
]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the CategoryByCategoryName2 index.")
- Use o argumento add_storing_index para executar snippets.py.
python snippets.py banking-ops-instance --database-id banking-ops-db add_storing_index
Agora é possível usar o índice CategoryByCategoryName2 para ler as colunas CategoryId, CategoryName e MarketingBudget. Como esta seção serve apenas como referência, você não precisa mudar o código.
def read_data_with_storing_index(instance_id, database_id):
"""Lê os dados de amostra do banco de dados usando um índice com uma cláusula
‘Storing’.
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName", "MarketingBudget"),
keyset=keyset,
index="CategoryByCategoryName2",
)
for row in results:
print(u"CategoryNameId: {}, CategoryName: {}, " "MarketingBudget: {}".format(*row))
- Use o argumento read_data_with_storing_index para executar snippets.py.
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_storing_index
O resultado precisa ser:
CategoryNameId: 3, CategoryName: Annuities, MarketingBudget: 500000
CategoryNameId: 1, CategoryName: Cash, MarketingBudget: 100000
CategoryNameId: 2, CategoryName: Investments - Short Return, MarketingBudget: None
CategoryNameId: 4, CategoryName: Life Insurance, MarketingBudget: None
Tarefa 6: analisar planos de consulta
Nesta seção, você vai conhecer os planos de consulta do Cloud Spanner.
- Retorne ao console do Cloud, que ainda deve estar na guia Consulta do Spanner Studio. Limpe a consulta atual. Em seguida, cole e execute esta consulta:
SELECT Name, ShortName, CategoryName
FROM Portfolio
INNER JOIN Category
ON Portfolio.PortfolioId = Category.PortfolioId;
- O resultado precisa ser semelhante a este:
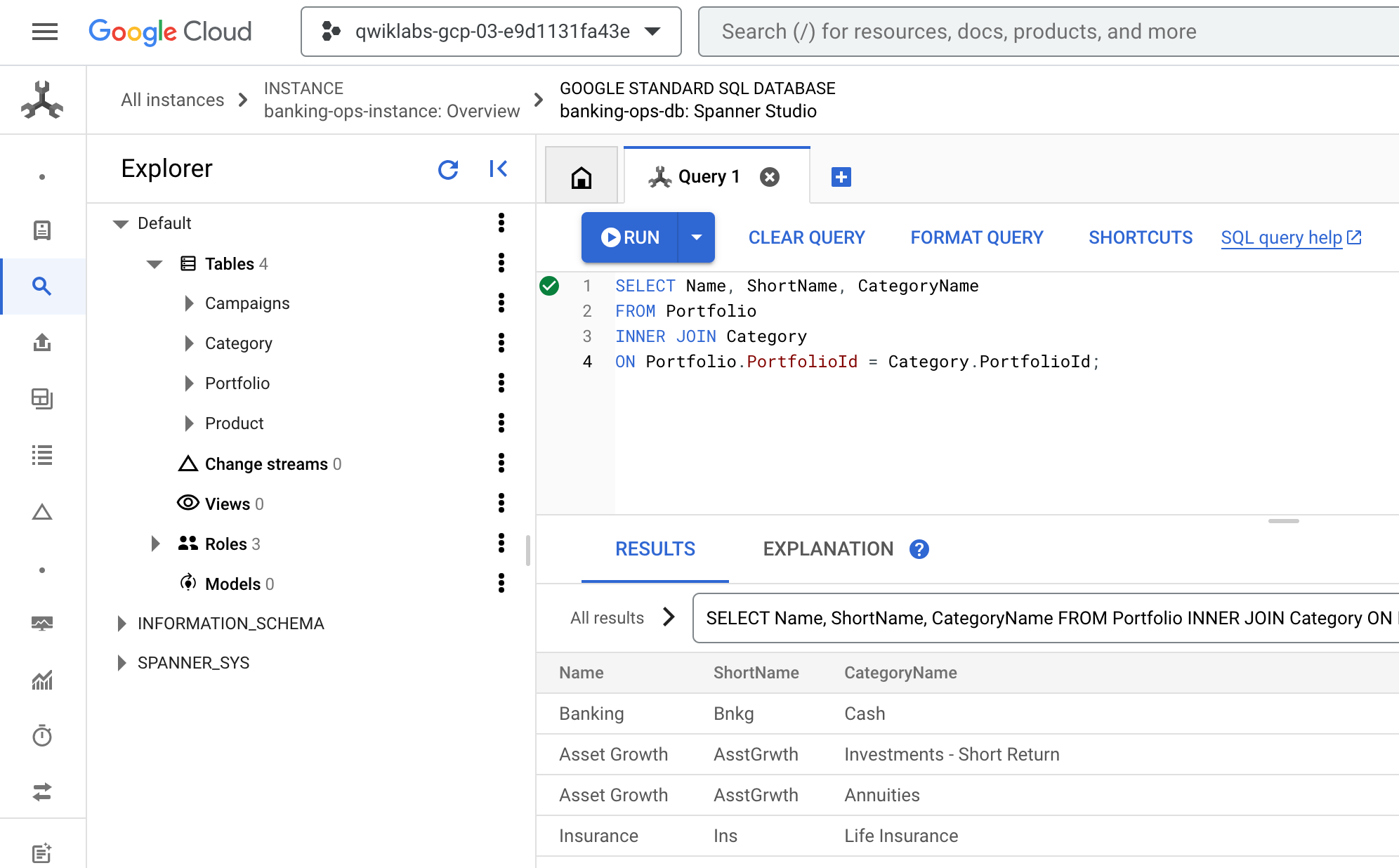
Vida útil de uma consulta
Uma consulta SQL no Cloud Spanner é compilada em um plano de execução, depois é enviada a um servidor raiz inicial para ser executada. O servidor raiz é escolhido para reduzir o número de saltos para alcançar os dados consultados. O servidor raiz:
- Inicia a execução remota de subplanos (se necessário)
- Aguarda os resultados das execuções remotas
- Processa as etapas de execução local restantes, como a agregação de resultados
- Retorna os resultados da consulta
Os servidores remotos que recebem um subplano atuam como servidor "raiz" do subplano, seguindo o mesmo modelo que o servidor raiz principal. O resultado é uma árvore de execuções remotas. Conceitualmente, a execução da consulta flui de cima para baixo e os resultados da consulta são retornados de baixo para cima. Este diagrama mostra esse padrão:
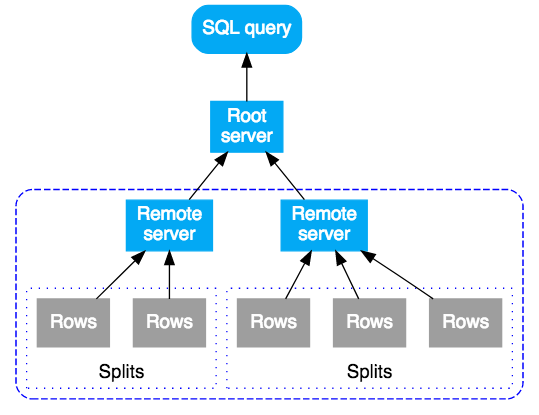
Consulta agregada
Confira o plano de uma consulta agregada.
- Na guia Consulta do Spanner Studio, limpe a consulta atual. Depois cole e execute a consulta a seguir.
SELECT pr.ProductId, COUNT(*) AS ProductCount
FROM Product AS pr
WHERE pr.ProductId < 100
GROUP BY pr.ProductId;
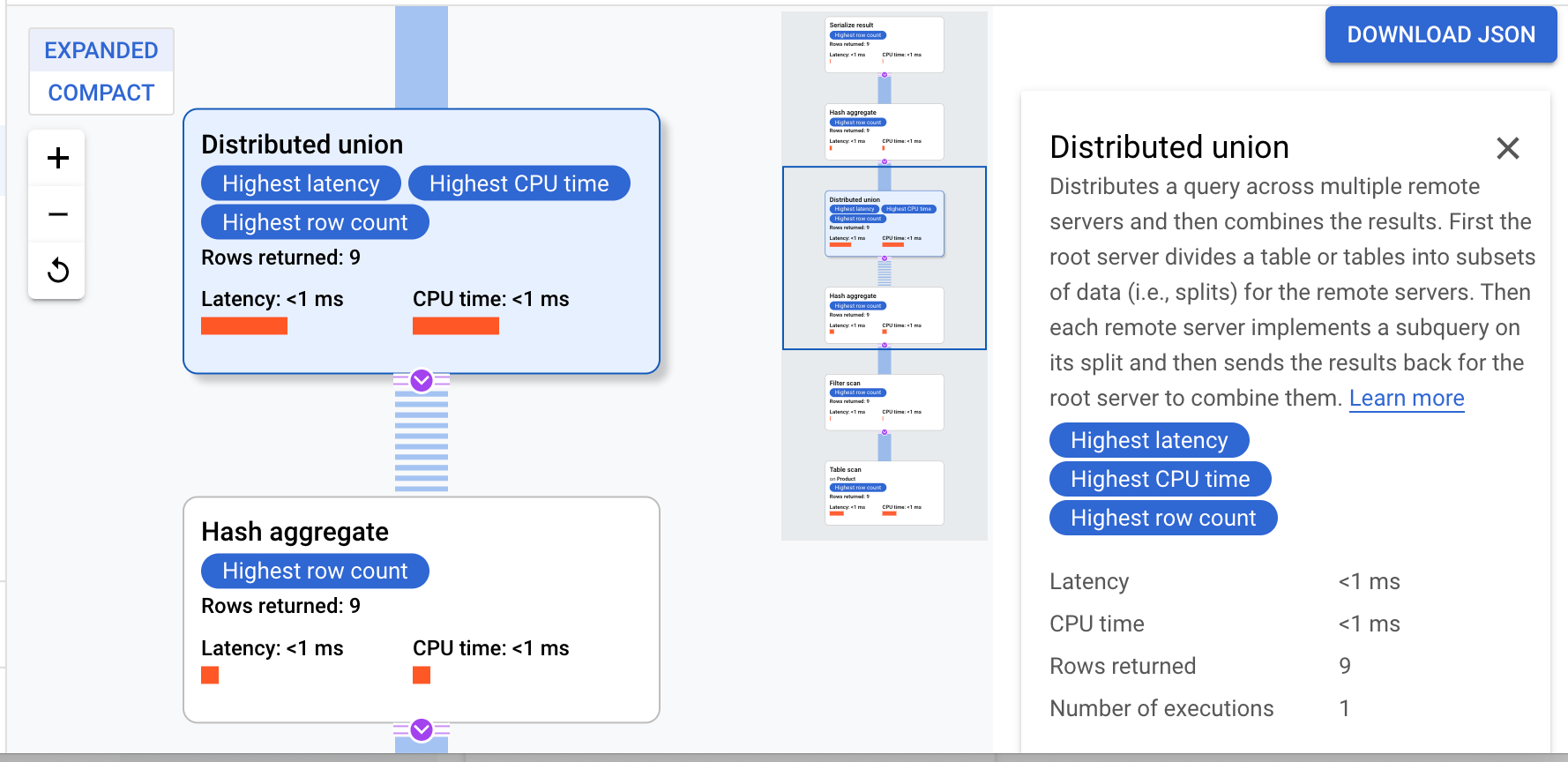
- Depois de concluída, clique na guia Explicação abaixo do corpo da consulta para analisar o plano.
O Cloud Spanner envia o plano para um servidor raiz que coordena a execução da consulta e distribui os subplanos de forma remota.
O plano de execução começa com uma serialização, que ordena todos os valores retornados. Em seguida, ele realiza um operador "hash aggregate" inicial para calcular os resultados preliminarmente. Um "distributed union" é executado e os subplanos são enviados para servidores remotos com divisões que atendem ao critério ProductId < 100. O "distributed union" envia os resultados para um operador "hash aggregate" final. O operador "aggregate" executa a agregação COUNT por ProductId e retorna os resultados a um operador "serialize result". Por fim, uma verificação ordena os resultados que serão retornados.
O resultado precisa ser semelhante a este:
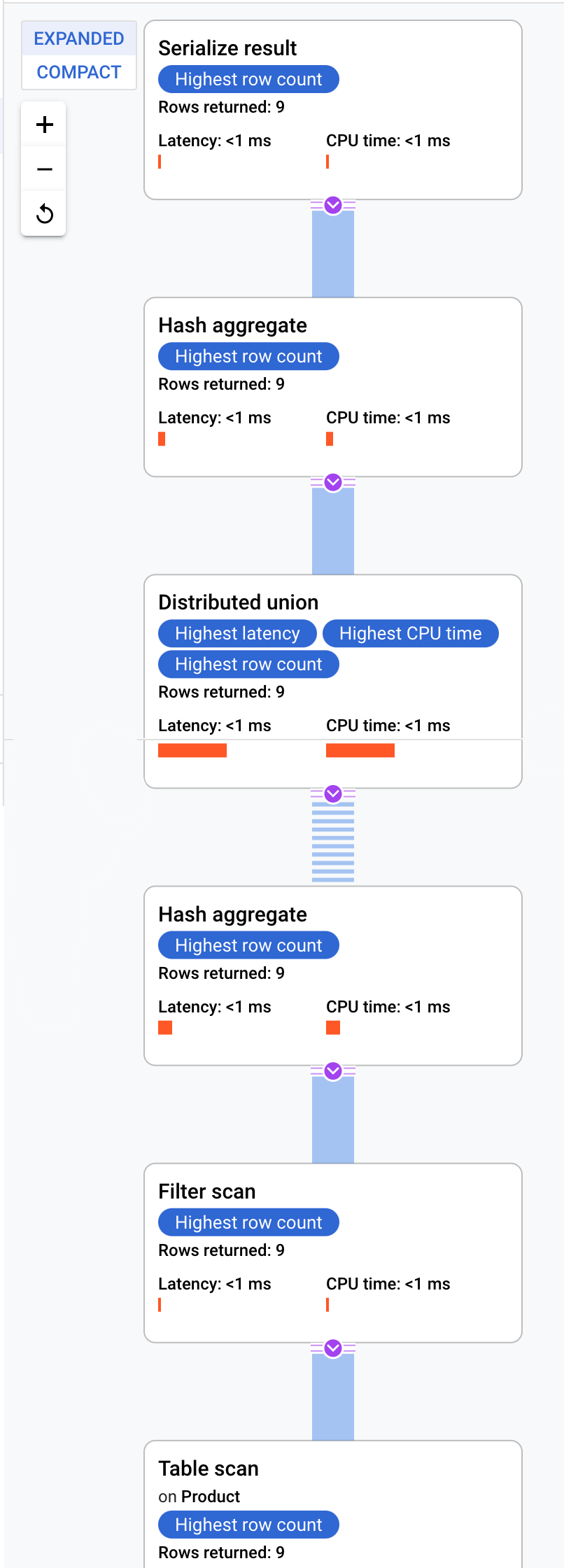
Dica: para conferir mais detalhes de cada etapa do plano de consulta, clique em qualquer um dos operadores. O lado direito da tela muda de acordo com o operador selecionado.
Consultas de mesclagem colocalizadas
As tabelas intercaladas são armazenadas fisicamente de forma que as linhas das tabelas relacionadas fiquem colocalizadas. Uma mesclagem de tabelas intercaladas é conhecida como mesclagem colocalizada. As mesclagens colocalizadas oferecem benefícios de desempenho melhores do que as que exigem índices ou mesclagens reversas.
- Na guia Consulta do Spanner Studio, limpe a consulta atual. Depois cole e execute a consulta a seguir.
SELECT c.CategoryName, pr.ProductName
FROM Category AS c, Product AS pr
WHERE c.PortfolioId = pr.PortfolioId AND c.CategoryId = pr.CategoryId;
- Depois de concluída, clique na guia Explicação abaixo do corpo da consulta para analisar o plano.
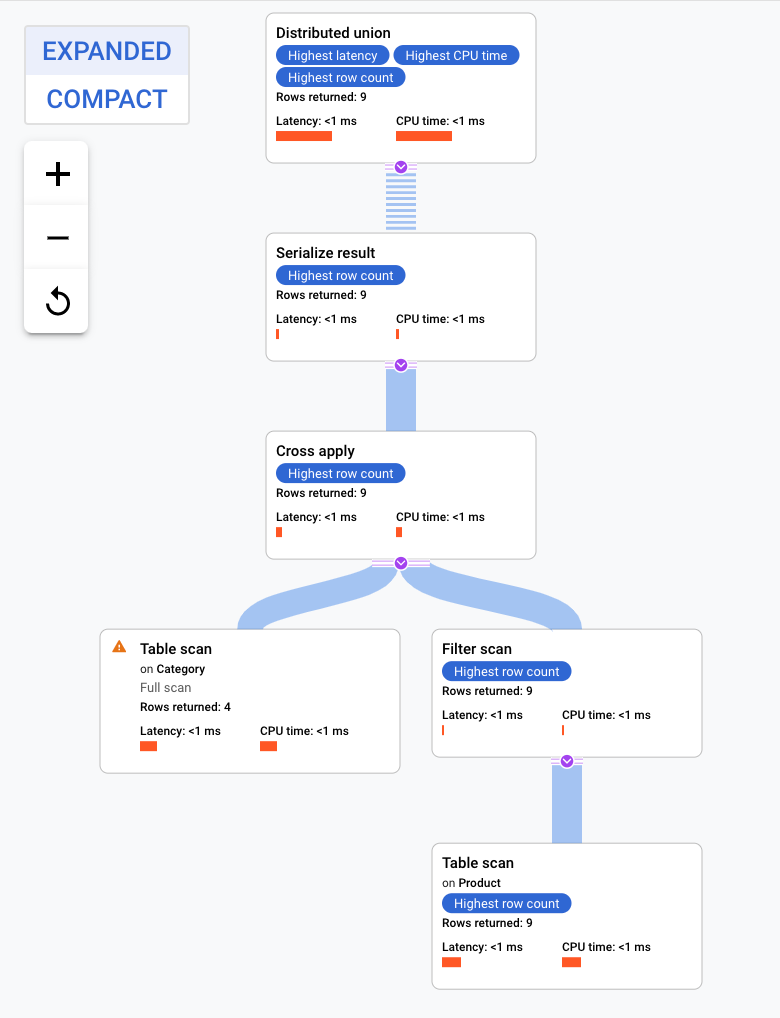
Esse plano de execução começa com um "distributed union", que envia subplanos para servidores remotos com divisões da tabela Categoria. Como Produto é uma tabela intercalada da tabela Categoria, cada servidor remoto executa todo o subplano sem exigir uma mesclagem com um servidor diferente.
Os subplanos contêm um "cross apply". Cada "cross apply" executa uma verificação na tabela Categoria para recuperar PortfolioId, CategoryId e CategoryName. Depois ele associa o resultado da verificação da tabela ao resultado de uma verificação do índice CategoryByCategoryName, sujeito a um filtro do PortfolioId no índice que corresponde ao PortfolioId do resultado da verificação de tabela. Cada "cross apply" envia os resultados a um operador "serialize result", que serializa os dados de CategoryName e ProductName e retorna resultados para os "distributed union" locais. O "distributed union" agrega os resultados dos "distributed union" locais e os retorna como resultado da consulta.
Parabéns.
Agora você tem uma compreensão sólida dos recursos de esquemas do Cloud Spanner, bem como dos métodos que o Spanner usa para criar planos de consulta.
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 14 de outubro de 2024
Laboratório testado em 14 de outubro de 2024
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.





