GSP1050

Übersicht
Cloud Spanner ist der vollständig verwaltete, horizontal skalierbare relationale Datenbankdienst von Google. Kundinnen und Kunden aus den Bereichen Finanzdienstleistungen, Gaming, Einzelhandel und vielen anderen Branchen vertrauen darauf, dass sie ihre anspruchsvollsten Arbeitslasten ausführen können, bei denen Konsistenz und Verfügbarkeit im großen Maßstab entscheidend sind.
In diesem Lab lernen Sie schemabezogene Funktionen von Cloud Spanner kennen und wenden diese auf eine Datenbank für Bankgeschäfte an. Außerdem erfahren Sie, nach welchen Methoden und Regeln Cloud Spanner Abfragepläne erstellt.
Aufgaben
In diesem Lab lernen Sie, schemabezogene Attribute einer Cloud Spanner-Instanz zu ändern.
- Daten in Tabellen laden
- Vordefinierten Python-Clientbibliothekscode zum Laden von Daten verwenden
- Daten mit Clientbibliotheken abfragen
- Datenbankschema aktualisieren
- Einen sekundären Index hinzufügen
- Abfragepläne prüfen
Einrichtung und Anforderungen
Vor dem Klick auf „Start Lab“ (Lab starten)
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange Google Cloud-Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
- Einen Standardbrowser (empfohlen wird Chrome)
Hinweis: Nutzen Sie den privaten oder Inkognitomodus (empfohlen), um dieses Lab durchzuführen. So wird verhindert, dass es zu Konflikten zwischen Ihrem persönlichen Konto und dem Teilnehmerkonto kommt und zusätzliche Gebühren für Ihr persönliches Konto erhoben werden.
- Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Hinweis: Verwenden Sie für dieses Lab nur das Teilnehmerkonto. Wenn Sie ein anderes Google Cloud-Konto verwenden, fallen dafür möglicherweise Kosten an.
Lab starten und bei der Google Cloud Console anmelden
-
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Dialogfeld geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können.
Auf der rechten Seite befindet sich der Bereich Lab-Einrichtung und ‑Zugriff:
- Button Google Cloud Console öffnen
- Die temporären Anmeldedaten (Nutzername und Passwort), die Sie für dieses Lab verwenden müssen
- Gegebenenfalls weitere Informationen für dieses Lab
Der Lab-Timer befindet sich oben auf der Seite und zeigt die verbleibende Zeit an.
-
Klicken Sie auf Google Cloud Console öffnen. Wenn Sie Chrome verwenden, können Sie auch rechtsklicken und Link in Inkognitofenster öffnen auswählen.
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite „Anmelden“ geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden.
-
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}}
Sie finden den Nutzernamen auch im Bereich Lab-Einrichtung und ‑Zugriff.
-
Klicken Sie auf Weiter.
-
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}}
Sie finden das Passwort auch im Bereich Lab-Einrichtung und ‑Zugriff.
-
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos.
Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen.
-
Klicken Sie sich durch die nachfolgenden Seiten:
- Akzeptieren Sie die Nutzungsbedingungen.
- Fügen Sie keine Wiederherstellungsoptionen oder 2-Faktor-Authentifizierung hinzu, da dies nur ein temporäres Konto ist.
- Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.
Hinweis: Wenn Sie auf Google Cloud-Produkte und ‑Dienste zugreifen möchten, klicken Sie auf das Navigationsmenü oder geben Sie den Namen des Produkts oder Dienstes in das Feld Suchen ein.

Cloud Shell aktivieren
Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Mit Cloud Shell erhalten Sie Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen.
-
Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren  .
.
-
Klicken Sie sich durch die folgenden Fenster:
- Fahren Sie mit dem Informationsfenster zu Cloud Shell fort.
- Autorisieren Sie Cloud Shell, Ihre Anmeldedaten für Google Cloud API-Aufrufe zu verwenden.
Wenn eine Verbindung besteht, sind Sie bereits authentifiziert und das Projekt ist auf Project_ID, eingestellt. Die Ausgabe enthält eine Zeile, in der die Project_ID für diese Sitzung angegeben ist:
Ihr Cloud-Projekt in dieser Sitzung ist festgelegt als {{{project_0.project_id | "PROJECT_ID"}}}
gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
- (Optional) Sie können den aktiven Kontonamen mit diesem Befehl auflisten:
gcloud auth list
- Klicken Sie auf Autorisieren.
Ausgabe:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
Um das aktive Konto festzulegen, führen Sie diesen Befehl aus:
$ gcloud config set account `ACCOUNT`
- (Optional) Sie können die Projekt-ID mit diesem Befehl auflisten:
gcloud config list project
Ausgabe:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Hinweis: Die vollständige Dokumentation für gcloud finden Sie in Google Cloud in der Übersicht zur gcloud CLI.
Cloud Spanner-Instanz
Damit Sie dieses Lab schneller durcharbeiten können, wurden die Cloud Spanner-Instanz, die Datenbank und Tabellen automatisch für Sie erstellt.
Hier sind einige Details dazu:
| Element |
Name |
Details |
| Cloud Spanner-Instanz |
banking-ops-instance |
Instanz auf Projektebene |
| Cloud Spanner-Datenbank |
banking-ops-db |
Instanzspezifische Datenbank |
| Tabelle |
Portfolio |
Enthält Bankangebote auf höchstem Niveau |
| Tabelle |
Category |
Enthält Gruppierungen von Bankangeboten der zweiten Ebene |
| Tabelle |
Product |
Enthält bestimmte Bankangebote für Werbebuchungen |
| Tabelle |
Campaigns |
Enthält Details zu Marketinginitiativen |
Aufgabe 1: Daten in Tabellen laden
Die Datenbank banking-ops-db wurde mit leeren Tabellen erstellt. Führen Sie die folgenden Schritte aus, um Daten in drei der Tabellen (Portfolio, Category und Product) zu laden.
-
Öffnen Sie in der Cloud Console das Navigationsmenü  > Alle Produkte ansehen. Klicken Sie unter Datenbanken auf Spanner.
> Alle Produkte ansehen. Klicken Sie unter Datenbanken auf Spanner.
-
Der Name der Instanz ist banking-ops-instance. Klicken Sie auf den Namen, um die Datenbanken aufzurufen.
-
Die zugehörige Datenbank heißt banking-ops-db. Klicken Sie auf den Namen, scrollen Sie nach unten zu Tabellen. Sie sehen, dass bereits vier Tabellen vorhanden sind.
-
Klicken Sie im linken Bereich der Console auf Spanner Studio. Klicken Sie dann im rechten Frame auf die Taste + Neuer SQL-Editor-Tab.
-
Daraufhin wird die Seite Abfrage eingeblendet. Fügen Sie die folgenden Insert-Anweisungen als Block ein, um die Tabelle Portfolio zu laden. Spanner führt die Anweisungen nacheinander aus. Klicken Sie auf Ausführen.
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (1, "Banking", "Bnkg", "All Banking Business");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (2, "Asset Growth", "AsstGrwth", "All Asset Focused Products");
insert into Portfolio (PortfolioId, Name, ShortName, PortfolioInfo) values (3, "Insurance", "Ins", "All Insurance Focused Products");
-
Auf der unteren Seite des Bildschirms werden die Ergebnisse des Einfügens zeilenweise angezeigt. Außerdem erscheint in jeder Zeile mit eingefügten Daten ein grünes Häkchen. Die Tabelle Portfolio enthält jetzt drei Zeilen.
-
Klicken Sie oben auf der Seite auf Löschen.
-
Fügen Sie die folgenden Insert-Anweisungen als Block ein, um die Tabelle Category zu laden. Klicken Sie auf Ausführen.
insert into Category (CategoryId,PortfolioId,CategoryName) values (1,1,"Cash");
insert into Category (CategoryId,PortfolioId,CategoryName) values (2,2,"Investments - Short Return");
insert into Category (CategoryId,PortfolioId,CategoryName) values (3,2,"Annuities");
insert into Category (CategoryId,PortfolioId,CategoryName) values (4,3,"Life Insurance");
-
Auf der unteren Seite des Bildschirms werden die Ergebnisse des Einfügens zeilenweise angezeigt. Außerdem erscheint in jeder Zeile mit eingefügten Daten ein grünes Häkchen. Die Tabelle Category enthält jetzt vier Zeilen.
-
Klicken Sie oben auf der Seite auf Löschen.
-
Fügen Sie die folgenden Insert-Anweisungen als Block ein, um die Tabelle Product zu laden. Klicken Sie auf Ausführen.
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (1,1,1,"Checking Account","ChkAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (2,2,2,"Mutual Fund Consumer Goods","MFundCG","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (3,3,2,"Annuity Early Retirement","AnnuFixed","Investment LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (4,4,3,"Term Life Insurance","TermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (5,1,1,"Savings Account","SavAcct","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (6,1,1,"Personal Loan","PersLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (7,1,1,"Auto Loan","AutLn","Banking LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (8,4,3,"Permanent Life Insurance","PermLife","Insurance LOB");
insert into Product (ProductId,CategoryId,PortfolioId,ProductName,ProductAssetCode,ProductClass) values (9,2,2,"US Savings Bonds","USSavBond","Investment LOB");
-
Auf der unteren Seite des Bildschirms werden die Ergebnisse des Einfügens zeilenweise angezeigt. Außerdem erscheint in jeder Zeile mit eingefügten Daten ein grünes Häkchen. Die Tabelle Product enthält jetzt neun Zeilen.
-
Klicken Sie auf Fortschritt prüfen.
Daten in die Tabellen „Portfolio“, „Category“ und „Product“ laden
Aufgabe 2: Vorab erstellten Python-Clientbibliothekscode zum Laden von Daten verwenden
In den nächsten Schritten verwenden Sie die in Python geschriebenen Clientbibliotheken.
- Öffnen Sie die Cloud Shell und fügen Sie die folgenden Befehle ein. Damit erstellen und öffnen Sie ein neues Verzeichnis, in dem die erforderlichen Dateien gespeichert werden.
mkdir python-helper
cd python-helper
- Laden Sie zwei Dateien herunter. Eine wird zum Einrichten der Umgebung verwendet. Die andere ist der Lab-Code.
wget https://storage.googleapis.com/cloud-training/OCBL373/requirements.txt
wget https://storage.googleapis.com/cloud-training/OCBL373/snippets.py
- Erstellen Sie eine isolierte Python-Umgebung und installieren Sie Abhängigkeiten für den Cloud Spanner-Client.
pip install -r requirements.txt
pip install setuptools
- Die Datei snippets.py ist eine konsolidierte Datei mit mehreren Cloud Spanner-DDL-, DML- und DCL-Funktionen, die Sie in diesem Lab als Hilfsmittel verwenden. Führen Sie snippets.py mit dem Argument insert_data aus, um die Tabelle Campaigns mit Daten zu füllen.
python snippets.py banking-ops-instance --database-id banking-ops-db insert_data
- Klicken Sie auf Fortschritt prüfen.
Daten in die Tabelle „Campaigns“ laden
Aufgabe 3: Daten mit Clientbibliotheken abfragen
Mit der Funktion query_data() in snippets.py können Sie die Datenbank abfragen. In diesem Fall verwenden Sie sie, um die in die Tabelle Campaigns geladenen Daten zu bestätigen. Sie nehmen keine Änderungen am Code vor. Der hier gezeigte Abschnitt dient nur als Referenz.
def query_data(instance_id, database_id):
"""Queries sample data from the database using SQL."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
results = snapshot.execute_sql(
"SELECT CampaignId,PortfolioId,CampaignStartDate,CampaignEndDate,CampaignName,CampaignBudget FROM Campaigns"
)
for row in results:
print(u"CampaignId: {}, PortfolioId: {}, CampaignStartDate: {}, CampaignEndDate: {}, CampaignName: {}, CampaignBudget: {}".format(*row))
- Führen Sie snippets.py mit dem Argument query_data aus, um die Tabelle Campaigns abzufragen.
python snippets.py banking-ops-instance --database-id banking-ops-db query_data
Das Ergebnis sollte etwa so aussehen:
CampaignId: 1, PortfolioId: 1, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: New Account Reward, CampaignBudget: 15000
CampaignId: 2, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Intro to Investments, CampaignBudget: 5000
CampaignId: 3, PortfolioId: 2, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Youth Checking Accounts, CampaignBudget: 25000
CampaignId: 4, PortfolioId: 3, CampaignStartDate: 2022-06-07, CampaignEndDate: 2022-06-07, CampaignName: Protect Your Family, CampaignBudget: 10000
Aufgabe 4: Datenbankschema aktualisieren
Als Datenbankadministrator müssen Sie der Tabelle Category eine neue Spalte mit dem Namen MarketingBudget hinzufügen. Damit einer vorhandenen Tabelle eine neue Spalte hinzugefügt werden kann, muss das Datenbankschema aktualisiert werden. Cloud Spanner unterstützt Schemaaktualisierungen für Datenbanken, ohne dass die Traffic-Bereitstellung unterbrochen werden muss. Bei einer Schemaaktualisierung muss die Datenbank nicht offline geschaltet und es müssen keine ganzen Tabellen oder Spalten gesperrt werden. Sie können während der Aktualisierung weiter Daten in die Datenbank schreiben oder darin lesen.
Mit Python eine Spalte hinzufügen
Die Methode update_ddl() der Klasse Database wird verwendet, um das Schema zu ändern.
Verwenden Sie die Funktion add_column() in snippets.py, die diese Methode implementiert. Sie nehmen keine Änderungen am Code vor. Der hier gezeigte Abschnitt dient nur als Referenz.
def add_column(instance_id, database_id):
"""Adds a new column to the Albums table in the example database."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["ALTER TABLE Category ADD COLUMN MarketingBudget INT64"]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the MarketingBudget column.")
- Führen Sie snippets.py mit dem Argument add_column aus.
python snippets.py banking-ops-instance --database-id banking-ops-db add_column
- Klicken Sie auf Fortschritt prüfen.
Der Tabelle „Category“ eine Spalte hinzufügen
Weitere Optionen zum Hinzufügen einer Spalte zu vorhandenen Tabellen:
Einen DDL-Befehl über die gcloud CLI ausgeben
Hinweis: Diese Option wird als alternatives Beispiel gezeigt. Führen Sie diesen Befehl nicht aus.
Das folgende Codebeispiel erledigt dieselbe Aufgabe, die Sie gerade mit Python ausgeführt haben.
gcloud spanner databases ddl update banking-ops-db --instance=banking-ops-instance --ddl='ALTER TABLE Category ADD COLUMN MarketingBudget INT64;'
Einen DDL-Befehl in der Cloud Console ausgeben
Hinweis: Diese Option wird als alternatives Beispiel gezeigt. Führen Sie diese Aktion nicht aus.
- Klicken Sie in der Datenbankliste auf den Namen der Tabelle.
- Klicken Sie rechts oben auf der Seite auf DDL schreiben.
- Fügen Sie die entsprechende DDL in das Feld DDL-Vorlagen ein.
- Klicken Sie auf Senden.
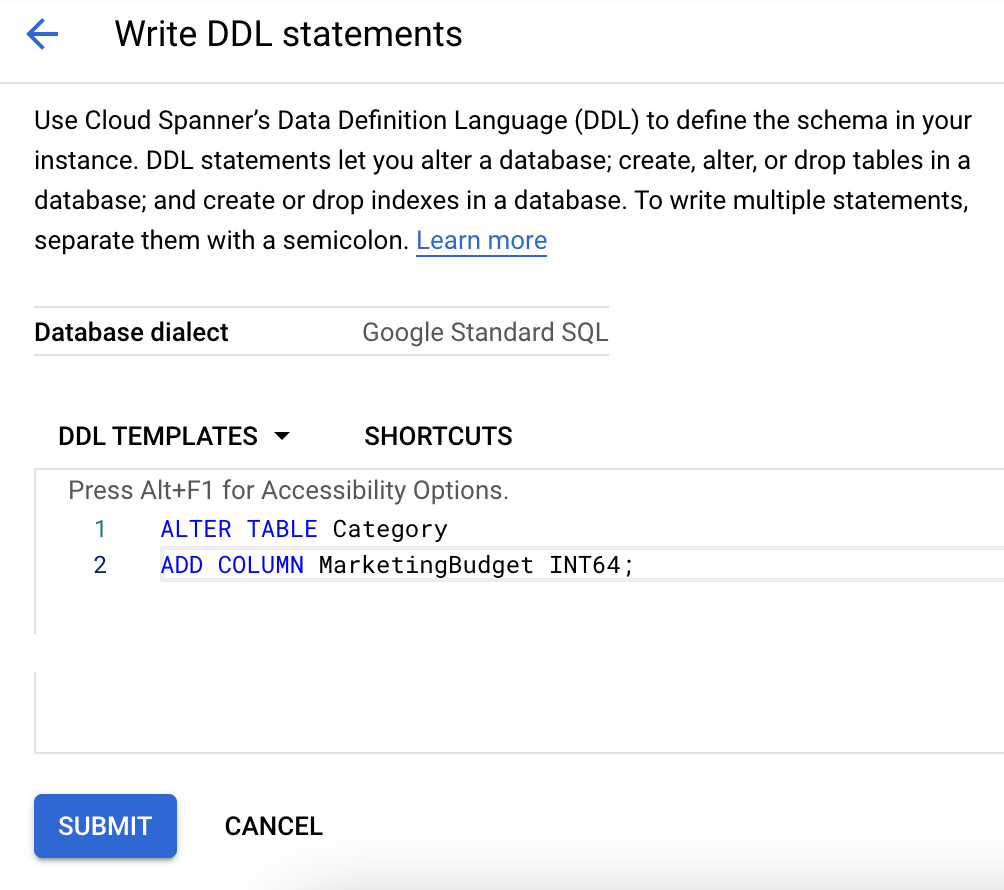
Daten in die neue Spalte schreiben
Mit dem folgenden Code werden Daten in die neue Spalte geschrieben. Er legt für MarketingBudget den Wert 100000 für die Zeile mit CategoryId = 1 und PortfolioId = 1 fest und den Wert 500000 für die Zeile mit CategoryId = 3 und PortfolioId = 2. Sie nehmen keine Änderungen am Code vor. Der hier gezeigte Abschnitt dient nur als Referenz.
def update_data(instance_id, database_id):
"""Updates sample data in the database.
Dadurch wird die Spalte „MarketingBudget“ aktualisiert, die vor dem Ausführen dieses Beispiels erstellt werden muss. Sie können die Spalte hinzufügen, indem Sie das Beispiel „add_column“
oder diese DDL-Anweisung für Ihre Datenbank ausführen.
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.batch() as batch:
batch.update(
table="Category",
columns=("CategoryId", "PortfolioId", "MarketingBudget"),
values=[(1, 1, 100000), (3, 2, 500000)],
)
print("Updated data.")
- Führen Sie snippets.py mit dem Argument update_data aus.
python snippets.py banking-ops-instance --database-id banking-ops-db update_data
- Führen Sie die Abfrage noch einmal aus, um die Aktualisierung anzuzeigen. Führen Sie snippets.py mit dem Argument query_data_with_new_column aus.
python snippets.py banking-ops-instance --database-id banking-ops-db query_data_with_new_column
Das Ergebnis sollte so aussehen:
CategoryId: 1, PortfolioId: 1, MarketingBudget: 100000
CategoryId: 2, PortfolioId: 2, MarketingBudget: None
CategoryId: 3, PortfolioId: 2, MarketingBudget: 500000
CategoryId: 4, PortfolioId: 3, MarketingBudget: None
Aufgabe 5: Einen sekundären Index hinzufügen
Angenommen, Sie möchten alle Zeilen aus „Categories“ abrufen, deren Werte für „CategoryNames“ in einem bestimmten Bereich liegen. Sie könnten dazu alle Werte aus der Spalte CategoryName mit einer SQL-Anweisung oder einem Leseaufruf lesen und dann die Zeilen verwerfen, die die Kriterien nicht erfüllen. Dieser vollständige Tabellenscan wäre jedoch sehr kostspielig, insbesondere bei Tabellen mit vielen Zeilen. Stattdessen können Sie einen sekundären Index für die Tabelle erstellen und damit das Abrufen von Zeilen beim Suchen über Spalten mit nicht primärem Schlüssel beschleunigen.
Damit ein sekundärer Index einer vorhandenen Tabelle hinzugefügt werden kann, muss das Schema aktualisiert werden. Wie bei anderen Schemaaktualisierungen kann mit Cloud Spanner ein Index hinzugefügt werden, ohne dass die Traffic-Bereitstellung unterbrochen werden muss. Cloud Spanner füllt den Index im Hintergrund mit Daten (auch als „Backfill“ bezeichnet). Backfills können einige Minuten dauern, aber Sie müssen die Datenbank nicht offline schalten und können während des Vorgangs weiter in alle Tabellen oder Spalten schreiben.
Einen sekundären Index mit der Python-Clientbibliothek hinzufügen
Verwenden Sie die Methode add_index(), um einen sekundären Index zu erstellen. Sie nehmen keine Änderungen am Code vor. Der hier gezeigte Abschnitt dient nur als Referenz.
def add_index(instance_id, database_id):
"""Adds a simple index to the example database."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
["CREATE INDEX CategoryByCategoryName ON Category(CategoryName)"]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the CategoryByCategoryName index.")
- Führen Sie snippets.py mit dem Argument add_index aus.
python snippets.py banking-ops-instance --database-id banking-ops-db add_index
- Klicken Sie auf Fortschritt prüfen.
Der Tabelle „Category“ einen sekundären Index hinzufügen
Mit dem Index auslesen
Um Daten mit dem Index auszulesen, rufen Sie eine Variante der Methode read() auf, die einen Index enthält. Sie nehmen keine Änderungen am Code vor. Der hier gezeigte Abschnitt dient nur als Referenz.
def read_data_with_index(instance_id, database_id):
"""Reads sample data from the database using an index.
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName"),
keyset=keyset,
index="CategoryByCategoryName",
)
for row in results:
print("CategoryId: {}, CategoryName: {}".format(*row))
- Führen Sie snippets.py mit dem Argument read_data_with_index aus.
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_index
Das Ergebnis sollte so aussehen:
CategoryId: 3, CategoryName: Annuities
CategoryId: 1, CategoryName: Cash
CategoryId: 2, CategoryName: Investments - Short Return
CategoryId: 4, CategoryName: Life Insurance
Index mit einer STORING-Klausel hinzufügen
Vielleicht haben Sie bemerkt, dass im obigen Beispiel das Lesen der Spalte MarketingBudget nicht enthalten ist. Die Leseschnittstelle von Cloud Spanner unterstützt nicht die Möglichkeit, einen Index mit einer Datentabelle zu verbinden, um Werte zu suchen, die nicht im Index gespeichert sind.
Um diese Einschränkung zu umgehen, erstellen Sie eine alternative Definition des Index CategoryByCategoryName, die eine Kopie von MarketingBudget im Index speichert.
Verwenden Sie die Methode update_ddl() der Klasse Database, um einen Index mit einer STORING-Klausel hinzuzufügen. Sie nehmen keine Änderungen am Code vor. Der hier gezeigte Abschnitt dient nur als Referenz.
def add_storing_index(instance_id, database_id):
"""Adds an storing index to the example database."""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
operation = database.update_ddl(
[
"CREATE INDEX CategoryByCategoryName2 ON Category(CategoryName)"
"STORING (MarketingBudget)"
]
)
print("Waiting for operation to complete...")
operation.result(OPERATION_TIMEOUT_SECONDS)
print("Added the CategoryByCategoryName2 index.")
- Führen Sie snippets.py mit dem Argument add_storing_index aus.
python snippets.py banking-ops-instance --database-id banking-ops-db add_storing_index
Sie können jetzt einen Lesevorgang ausführen, der die Spalten CategoryId, CategoryName und MarketingBudget abruft, während Sie den Index CategoryByCategoryName2 verwenden. Sie nehmen keine Änderungen am Code vor. Der hier gezeigte Abschnitt dient nur als Referenz.
def read_data_with_storing_index(instance_id, database_id):
"""Reads sample data from the database using an index with a storing
clause.
"""
spanner_client = spanner.Client()
instance = spanner_client.instance(instance_id)
database = instance.database(database_id)
with database.snapshot() as snapshot:
keyset = spanner.KeySet(all_=True)
results = snapshot.read(
table="Category",
columns=("CategoryId", "CategoryName", "MarketingBudget"),
keyset=keyset,
index="CategoryByCategoryName2",
)
for row in results:
print(u"CategoryNameId: {}, CategoryName: {}, " "MarketingBudget: {}".format(*row))
- Führen Sie snippets.py mit dem Argument read_data_with_storing_index aus.
python snippets.py banking-ops-instance --database-id banking-ops-db read_data_with_storing_index
Das Ergebnis sollte so aussehen:
CategoryNameId: 3, CategoryName: Annuities, MarketingBudget: 500000
CategoryNameId: 1, CategoryName: Cash, MarketingBudget: 100000
CategoryNameId: 2, CategoryName: Investments - Short Return, MarketingBudget: None
CategoryNameId: 4, CategoryName: Life Insurance, MarketingBudget: None
Aufgabe 6: Abfragepläne prüfen
In diesem Abschnitt lernen Sie Abfragepläne in Cloud Spanner kennen.
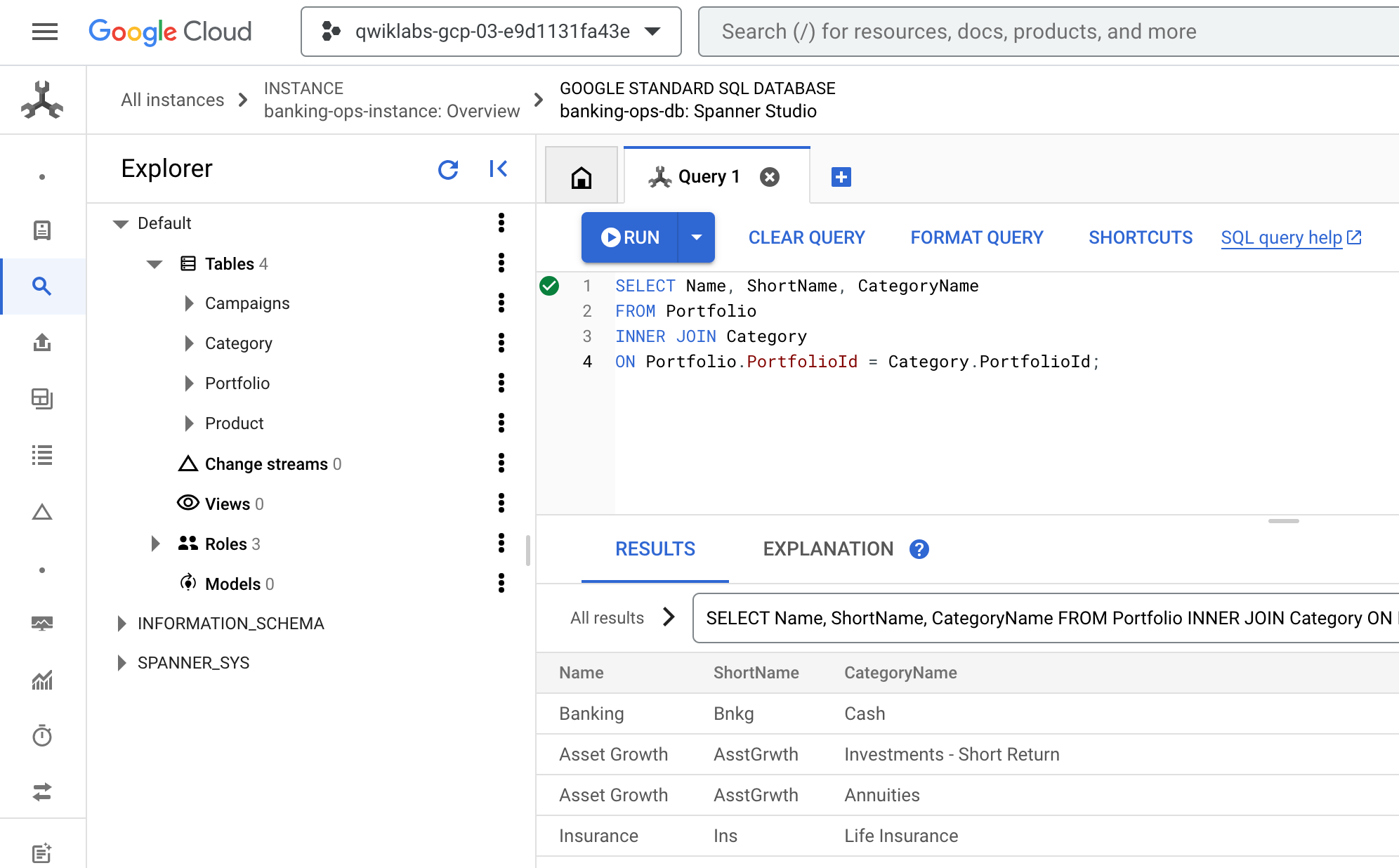
- Kehren Sie zur Cloud Console zurück. Sie sollten sich immer noch auf dem Tab Abfrage in Spanner Studio befinden. Löschen Sie alle vorhandenen Abfragen, fügen Sie die folgende Abfrage ein und führen Sie sie aus:
SELECT Name, ShortName, CategoryName
FROM Portfolio
INNER JOIN Category
ON Portfolio.PortfolioId = Category.PortfolioId;
- Das Ergebnis sollte so aussehen:
Phasen einer Abfrage
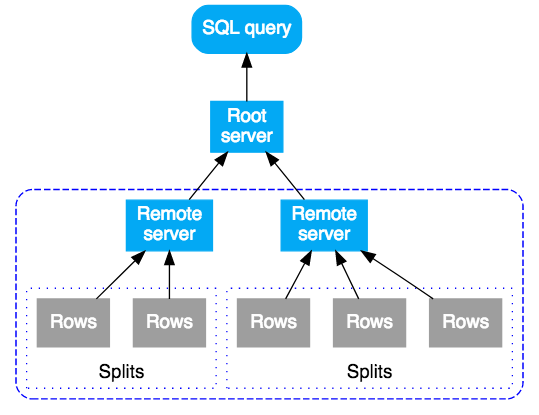
Eine SQL-Abfrage in Cloud Spanner wird zuerst in einen Ausführungsplan kompiliert und anschließend zur Ausführung an einen ersten Root-Server gesendet. Der Root-Server ist so gewählt, dass die Anzahl der Sprünge (Hops), die die abgefragten Daten erreichen, minimiert wird. Anschließend führt der Root-Server folgende Schritte durch:
- Initiierung der Remote-Ausführung von Teilplänen (falls erforderlich)
- Warten auf die Ergebnisse der Remote-Ausführungen
- Verwaltung aller verbleibenden lokalen Ausführungsschritte, zum Beispiel das Aggregieren von Ergebnissen
- Ausgabe der Ergebnisse für die Abfrage
Remote-Server, die einen Teilplan erhalten, fungieren als „Root“-Server für ihren Teilplan und folgen demselben Modell wie der oberste Root-Server. Das Ergebnis ist eine Struktur von Remote-Ausführungen. Die Abfrageausführung wird konzeptionell von oben nach unten ausgeführt und Abfrageergebnisse werden von unten nach oben ausgegeben. Im folgenden Diagramm sehen Sie dieses Muster:
Aggregierte Abfrage
Sehen Sie sich den Abfrageplan für eine aggregierte Abfrage an.
- Löschen Sie auf dem Tab Abfrage in Spanner Studio die vorhandene Abfrage, fügen Sie die folgende Abfrage ein und führen Sie sie aus.
SELECT pr.ProductId, COUNT(*) AS ProductCount
FROM Product AS pr
WHERE pr.ProductId < 100
GROUP BY pr.ProductId;
- Sobald die Abfrage abgeschlossen ist, klicken Sie unter dem Text der Abfrage auf den Tab Erklärung, um den Abfrageplan zu prüfen.
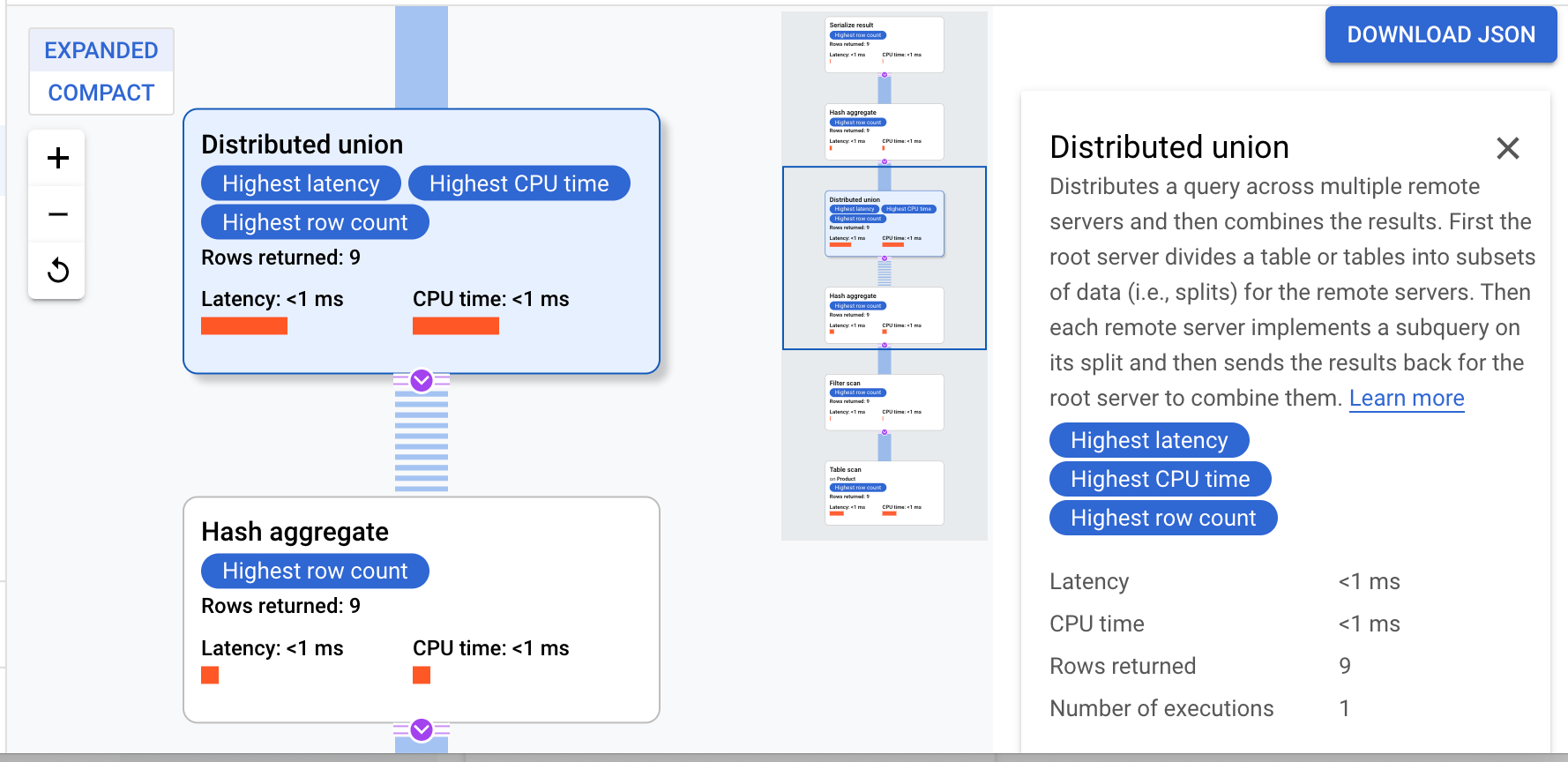
Cloud Spanner sendet den Ausführungsplan an einen Root-Server, der die Abfrageausführung koordiniert und die Remote-Verteilung von Teilplänen ausführt.
Dieser Ausführungsplan beginnt mit einer Serialisierung, die alle ausgegebenen Werte ordnet. Dann führt der Plan einen ersten Hash-Aggregat-Operator aus, um vorläufige Ergebnisse zu berechnen. Dann wird eine Distributed Union ausgeführt, die Teilpläne an Remote-Server verteilt, deren Splits ProductId < 100 erfüllen. Die Distributed Union sendet Ergebnisse an einen finalen Hash-Aggregat-Operator. Der Aggregate-Operator führt die-Zusammenfassung nach ProductId aus und gibt Ergebnisse an einen Operator des Typs Serialize Result aus. Schließlich wird ein Scan durchgeführt, um die auszugebenden Ergebnisse zu sortieren.
Das Ergebnis sollte so aussehen:
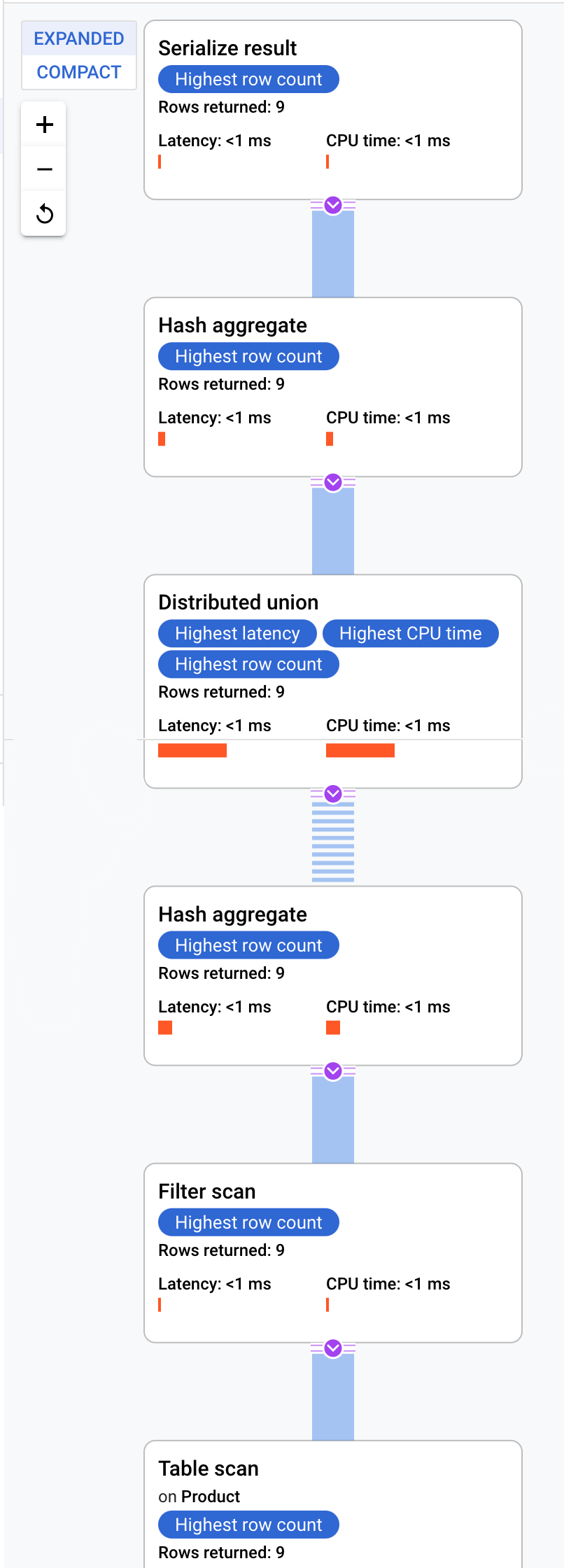
Tipp: Wenn Sie weitere Details zu den einzelnen Schritten im Abfrageplan erhalten möchten, klicken Sie auf einen der Operatoren. Die rechte Seite des Bildschirms ändert sich dann entsprechend.
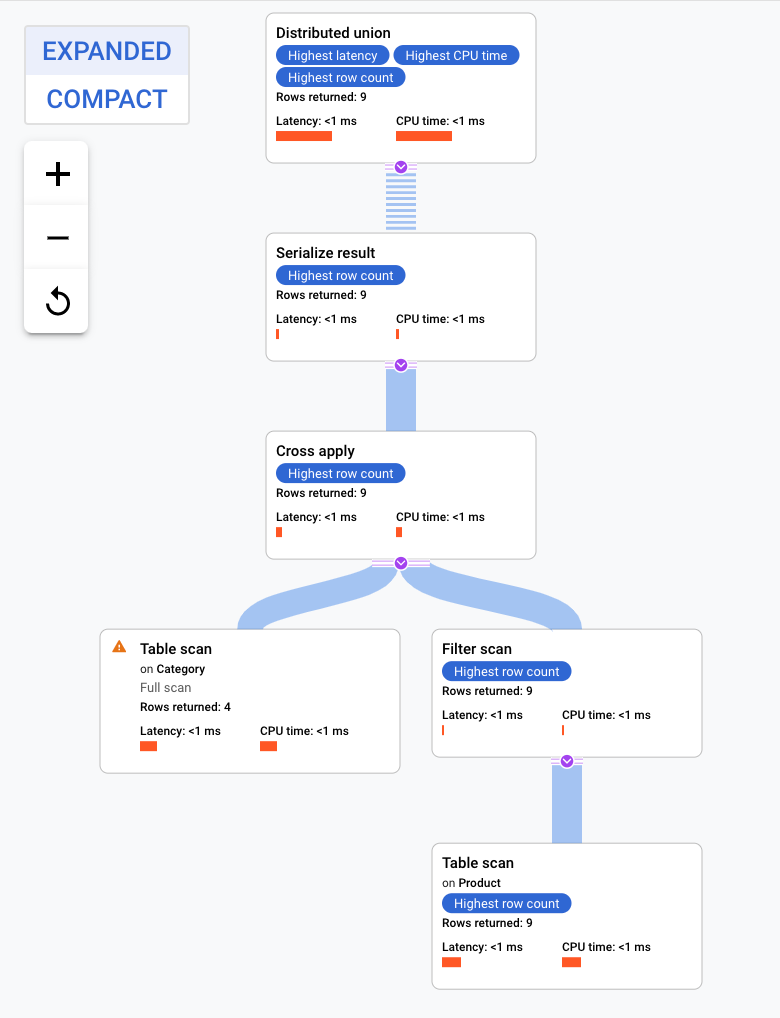
Zusammengelegte Join-Abfragen
Verschachtelte Tabellen werden gemeinsam mit ihren Zeilen zusammengehöriger Tabellen physisch gespeichert. Ein Join zwischen verschachtelten Tabellen wird als „zusammengelegter Join“ bezeichnet. Zusammengelegte Joins können Leistungsverbesserungen gegenüber Joins bieten, für die Indizes oder Back-Joins erforderlich sind.
- Löschen Sie auf dem Tab Abfrage in Spanner Studio die vorhandene Abfrage, fügen Sie die folgende Abfrage ein und führen Sie sie aus.
SELECT c.CategoryName, pr.ProductName
FROM Category AS c, Product AS pr
WHERE c.PortfolioId = pr.PortfolioId AND c.CategoryId = pr.CategoryId;
- Sobald die Abfrage abgeschlossen ist, klicken Sie unter dem Text der Abfrage auf den Tab Erklärung, um den Abfrageplan zu prüfen.
Dieser Ausführungsplan beginnt mit dem Operator „Distributed Union“. Er verteilt Teilpläne an Remote-Server, die Splits der Tabelle Category haben. Da es sich bei Product um eine verschachtelte Tabelle von Category handelt, kann jeder Remote-Server den gesamten Teilplan auf jedem Remote-Server ausführen, ohne dass eine Verbindung zu einem anderen Server hergestellt werden muss.
Der Teilplan enthält einen Cross Apply. Jeder Cross Apply führt einen Tabellenscan (Table Scan) der Tabelle Category aus, um PortfolioId, CategoryId und CategoryName abzurufen. Der Cross Apply ordnet dann die Ausgabe aus dem Tabellenscan der Ausgabe eines Indexscans des Indexes CategoryByCategoryName zu. Dazu muss die gefilterte PortfolioId im Index mit der PortfolioId aus der Ausgabe des Tabellenscans übereinstimmen. Jeder Cross Apply sendet seine Ergebnisse an einen Operator „Serialize Result“, der die Daten von CategoryName und ProductName serialisiert und an die „Local Distributed Unions“ ausgibt. Die „Distributed Union“ aggregiert die Ergebnisse der „Local Distributed Unions“ und gibt sie als Abfrageergebnis aus.
Das wars! Sie haben das Lab erfolgreich abgeschlossen.
Sie haben jetzt ein solides Verständnis für die schemabezogenen Funktionen von Cloud Spanner sowie für die Methoden, nach denen Spanner Abfragepläne erstellt.
Google Cloud-Schulungen und -Zertifizierungen
In unseren Schulungen erfahren Sie alles zum optimalen Einsatz unserer Google Cloud-Technologien und können sich entsprechend zertifizieren lassen. Unsere Kurse vermitteln technische Fähigkeiten und Best Practices, damit Sie möglichst schnell mit Google Cloud loslegen und Ihr Wissen fortlaufend erweitern können. Wir bieten On-Demand-, Präsenz- und virtuelle Schulungen für Anfänger wie Fortgeschrittene an, die Sie individuell in Ihrem eigenen Zeitplan absolvieren können. Mit unseren Zertifizierungen weisen Sie nach, dass Sie Experte im Bereich Google Cloud-Technologien sind.
Anleitung zuletzt am 14. Oktober 2024 aktualisiert
Lab zuletzt am 14. Oktober 2024 getestet
© 2026 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.





