

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します

このラボでは、Vertex Pipelines を使った ML パイプラインの作成方法と実行方法について学びます。
google_cloud_pipeline_components ライブラリで提供されている事前構築済みコンポーネントを使用して、Vertex AI サービスとのやり取りを行う各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
シークレット ウィンドウを使用して Google Skills にログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
Cloud Shell は、開発ツールが組み込まれた仮想マシンです。5 GB の永続ホーム ディレクトリを提供し、Google Cloud 上で実行されます。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。gcloud は Google Cloud のコマンドライン ツールで、Cloud Shell にプリインストールされており、Tab キーによる入力補完がサポートされています。
Google Cloud Console のナビゲーション パネルで、「Cloud Shell をアクティブにする」アイコン(
[次へ] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続の際に認証も行われ、プロジェクトは現在のプロジェクト ID に設定されます。次に例を示します。
有効なアカウント名前を一覧表示する:
(出力)
(出力例)
プロジェクト ID を一覧表示する:
(出力)
(出力例)
Cloud Shell には、現在の Cloud プロジェクトの名前が格納されている GOOGLE_CLOUD_PROJECT など、いくつかの環境変数があります。本ラボではさまざまな場所でこれを使用します。次を実行すると確認できます。
成功すると次のようなメッセージが表示されます。
Vertex AI でトレーニング ジョブを実行するには、保存対象のモデルアセットを格納するストレージ バケットが必要です。バケットにはリージョンが必要です。ここでは US-central を指定しますが、別のリージョンを使用することもできます(その場合はラボ内の該当箇所をすべて置き換えてください)。
こうすることで、Vertex Pipelines にこのバケットへのファイルの書き込みに必要な権限を付与することができます。
 )で、[Vertex AI] > [ダッシュボード] をクリックします。
)で、[Vertex AI] > [ダッシュボード] をクリックします。Google Cloud コンソール のナビゲーション メニューで、[Vertex AI] > [ワークベンチ] をクリックします。[ユーザー管理のノートブック] を選択します。
ノートブック インスタンスのページで [Create New] をクリックし、[Environment] で [TensorFlow Enterprise 2.6 (with LTS)] の最新バージョンを選択します。
[新しいノートブック] インスタンス ダイアログで、Deep Learning VM の名前を確認します。リージョンとゾーンを変更しない場合は、設定をすべてそのままにして [作成] をクリックします。新しい VM が起動するまでに 2~3 分かかります。
[JUPYTERLAB を開く] をクリックします。
JupyterLab ウィンドウが新しいタブで開きます。
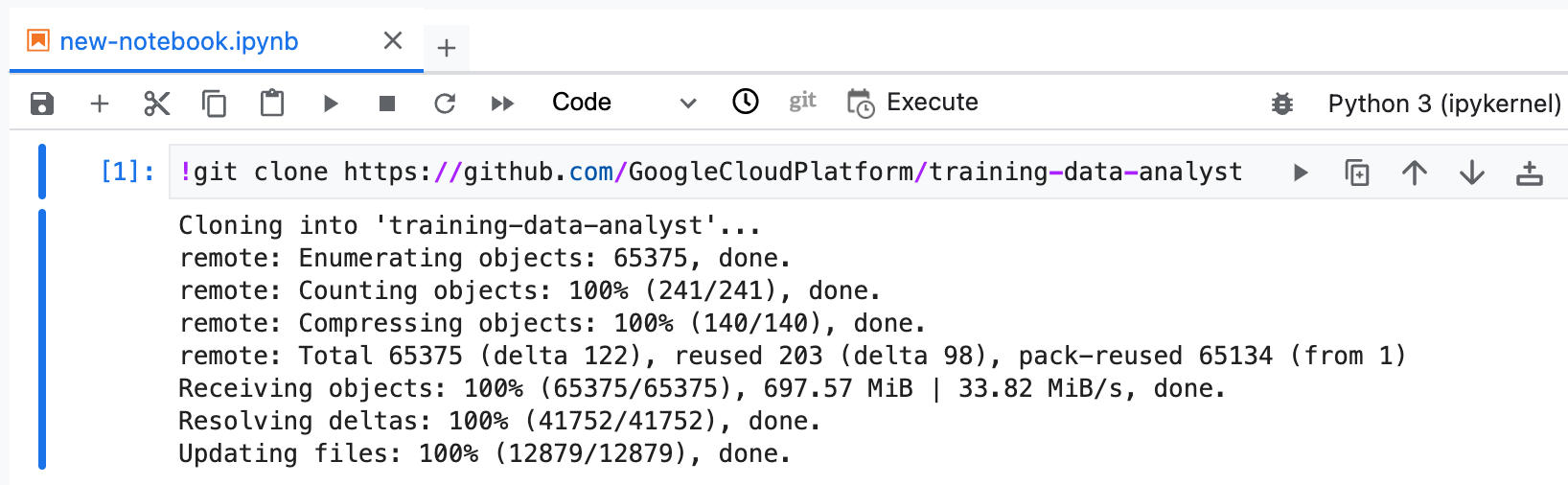
GitHub リポジトリには、コースのラボファイルとソリューション ファイルの両方が含まれています。
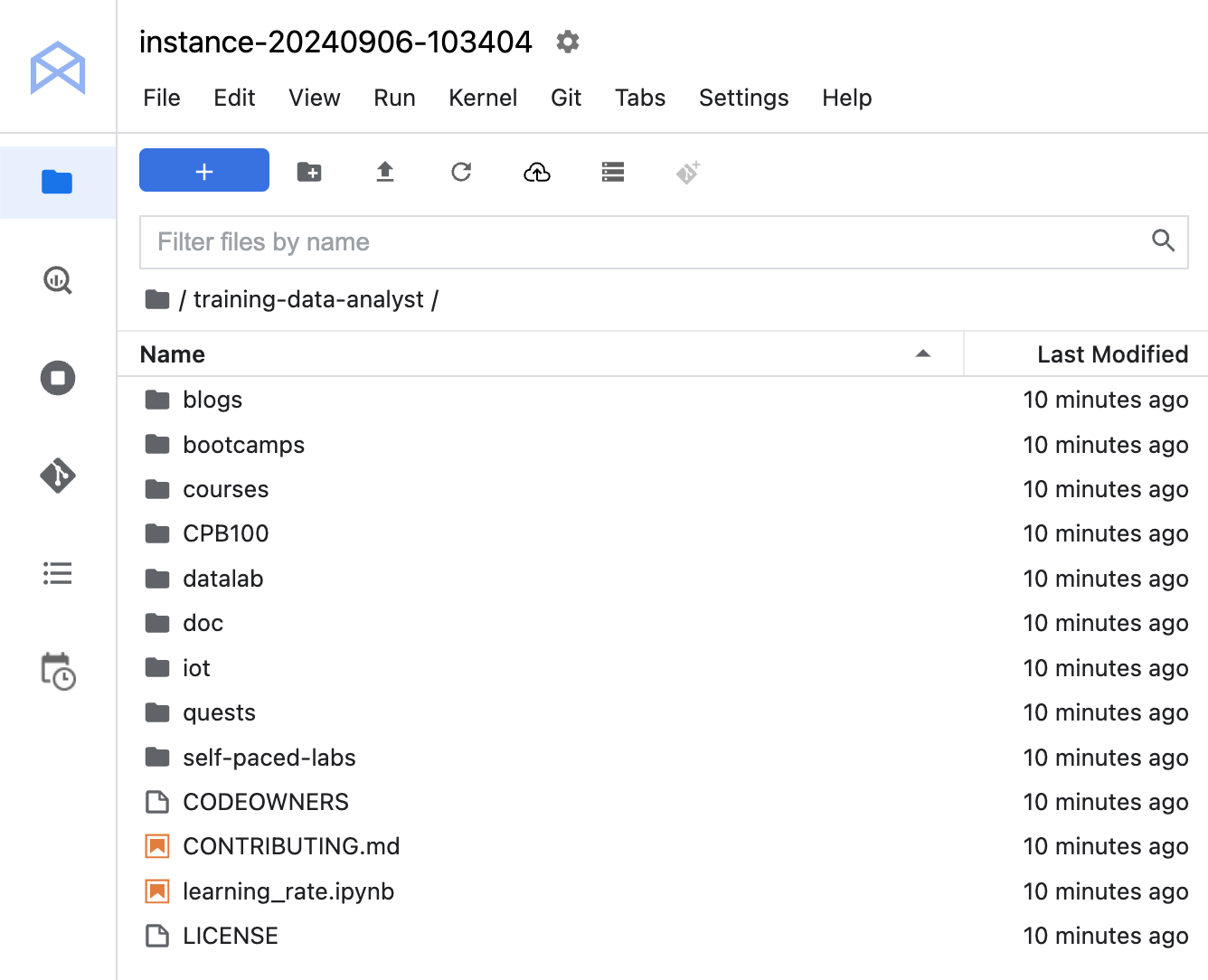
training-data-analyst リポジトリのクローンを作成します。training-data-analyst ディレクトリをダブルクリックし、リポジトリのコンテンツが表示されることを確認します。ノートブック インターフェースで、[training-data-analyst] > [courses] > [machine_learning] > [deepdive2] > [machine_learning_in_the_enterprise] > [labs] に移動して pipelines_intro_kfp.ipynb を開きます。
ノートブック インターフェースで、[Edit] > [Clear All Outputs] をクリックします。
ノートブックの手順をよく読み、コードを入力する必要がある場所に「#TODO」のマークを付けた行を挿入します。
ヒント: 現在のセルを実行するには、そのセルをクリックして、Shift+Enter キーを押します。その他のセルコマンドはノートブック UI 内の [実行] の下にあります。
ラボでの学習が完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Qwiklabs から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバック、ご提案、修正が必要な箇所については、[サポート] タブからお知らせください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください