


Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Create a new dataset and table to store the data
/ 20
Execute the query to see how many unique products were viewed
/ 15
Execute the query to use the UNNEST() on array field
/ 15
Create a dataset and a table to ingest JSON data
/ 20
Execute the query to COUNT how many racers were there in total
/ 10
Execute the query that will list the total race time for racers whose names begin with R
/ 10
Execute the query to see which runner ran fastest lap time
/ 10
Create a new dataset and table to store the data
/ 20
Execute the query to see how many unique products were viewed
/ 15
Execute the query to use the UNNEST() on array field
/ 15
Create a dataset and a table to ingest JSON data
/ 20
Execute the query to COUNT how many racers were there in total
/ 10
Execute the query that will list the total race time for racers whose names begin with R
/ 10
Execute the query to see which runner ran fastest lap time
/ 10

BigQuery 是 Google 提供的全代管 NoOps 數據分析資料庫,價格相當實惠。您可以使用 BigQuery 查詢 TB 規模的資料,不必管理基礎架構,也不需要資料庫管理員。BigQuery 使用 SQL 語法,並提供「即付即用」模式。這項服務可讓您專心分析資料,找出有意義的洞察結果。
在本實驗室中,您將深入學習如何在 BigQuery 處理半結構化資料,像是擷取 JSON、陣列資料等。將結構定義反正規化,並製作成有重複欄位的單一巢狀資料表能提升成效,但處理這類陣列資料的 SQL 語法相當複雜。您將練習載入與查詢各種半結構化資料集、排解相關問題,以及解除這類資料的巢狀結構。
本實驗室的內容包括:
請詳閱以下操作說明。實驗室活動會計時,且中途無法暫停。點選「Start Lab」後就會開始計時,顯示可使用 Google Cloud 資源的時間。
您將在真正的雲端環境完成實作實驗室活動,而不是模擬或示範環境。為此,我們會提供新的暫時憑證,供您在實驗室活動期間登入及存取 Google Cloud。
為了順利完成這個實驗室,請先確認:
按一下「Start Lab」按鈕。如果實驗室會產生費用,請在開啟的對話方塊中選取付款方式。右側的「Lab setup and access」面板會顯示下列項目:
請注意,實驗室計時器位於頁面頂端附近,會顯示剩餘時間。
按一下「Open Google Cloud console」。如果使用 Chrome 瀏覽器,也可以按一下滑鼠右鍵,選取「在無痕視窗中開啟連結」。
接著,實驗室會啟動相關資源,並開啟另一個分頁,顯示「登入」頁面。
提示:您可以在不同的視窗並排開啟分頁。
如有必要,請將下方的 Username 貼到「登入」對話方塊。
您也可以在「Lab setup and access」面板找到「Username」。
點選「下一步」。
複製下方的 Password,並貼到「歡迎使用」對話方塊。
您也可以在「Lab setup and access」面板找到「Password」。
點選「下一步」。
繼續點按後續頁面:
Google Cloud 控制台稍後會在這個分頁開啟。

接著,畫面中會顯示「歡迎使用 Cloud 控制台中的 BigQuery」訊息方塊,當中會列出快速入門導覽課程指南的連結和版本資訊。
BigQuery 控制台會隨即開啟。
將「資料集 ID」設為 fruit_store。「資料位置」、「預設到期時間」等其他選項保留預設值。
點選「建立資料集」。
在 SQL 中,每個資料列通常只有一個值,例如下方的水果清單:
|
Row |
Fruit |
|
1 |
raspberry |
|
2 |
blackberry |
|
3 |
strawberry |
|
4 |
cherry |
如果想要店內每個人的水果清單呢?結果應如下所示:
|
Row |
Fruit |
Person |
|
1 |
raspberry |
sally |
|
2 |
blackberry |
sally |
|
3 |
strawberry |
sally |
|
4 |
cherry |
sally |
|
5 |
orange |
frederick |
|
6 |
apple |
frederick |
如果使用傳統關聯式資料庫 SQL,當您發現上方資料表的名稱重複,會立即想到要拆分為兩個獨立的資料表:「水果」和「人物」。這個程序稱為正規化,也就是將一個資料表拆分為多個資料表,這是 mySQL 等交易資料庫的常見做法。
就 data warehousing 而言,資料分析師通常採取相反的做法,也就是反正規化,將多個獨立的資料表合併成一個大型報表表格。
接下來,您將學習使用另一種方法,按照不同精細程度,將資料全部儲存在有重複欄位的單一資料表中:
|
Row |
Fruit (array) |
Person |
|
1 |
raspberry |
sally |
|
blackberry | ||
|
strawberry | ||
|
cherry | ||
|
2 |
orange |
frederick |
|
apple |
前一個資料表有什麼奇怪的地方?
發現重點了嗎?這就是 array 資料類型!
這樣更容易解讀 Fruit (array) 資料欄:
|
Row |
Fruit (array) |
Person |
|
1 |
[raspberry, blackberry, strawberry, cherry] |
sally |
|
2 |
[orange, apple] |
frederick |
這兩個資料表的內容完全相同,並呈現兩個重點:
現在換您試試看。
點選「執行」。
接下來試著執行下列查詢:
您會收到類似下方的錯誤訊息:
Error: Array elements of types {INT64, STRING} do not have a common supertype at [3:1]
陣列只能使用相同的資料類型,例如全都是字串,或全都是數值。
點選「執行」。
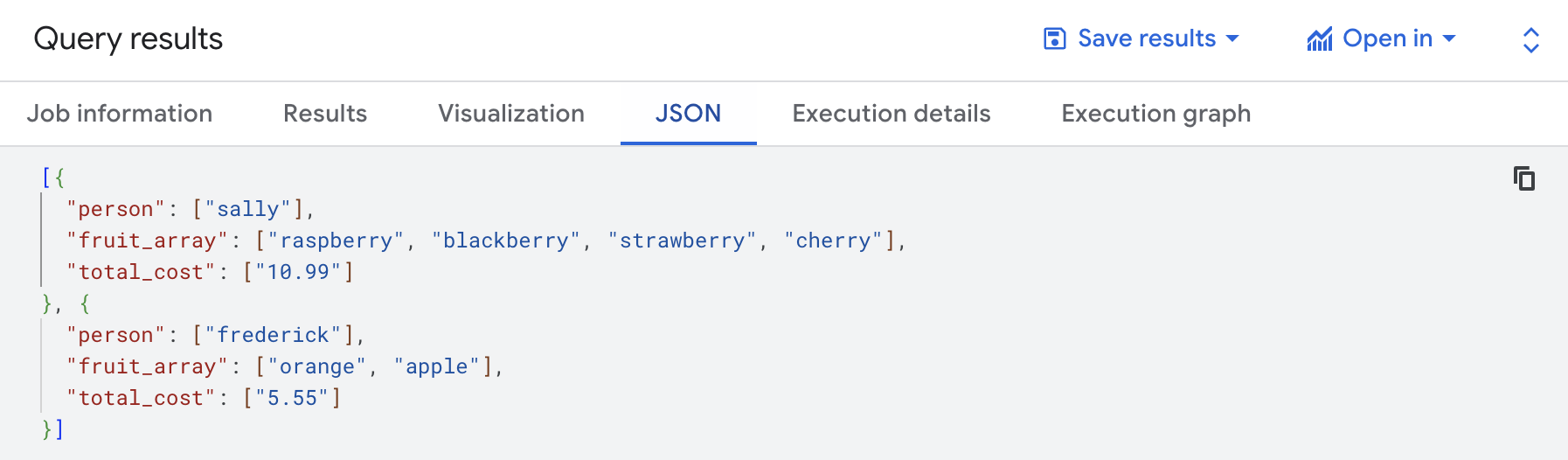
查看結果後,點選「JSON」分頁標籤,即可瀏覽結果的巢狀結構。
如果需要將 JSON 檔案擷取至 BigQuery,該怎麼做?
在資料集建立新的資料表 fruit_details。
fruit_store」資料集。現在您會看到「建立資料表」選項。
spls/gsp416/data-insights-course/labs/optimizing-for-performance/shopping_cart.json
將新資料表命名為 fruit_details。
勾選「Schema (Auto detect)」核取方塊。
點選「建立資料表」。
請注意,結構定義中的 fruit_array 標為 REPEATED,表示這是陣列。
重點回顧
點選「Check my progress」確認目標已達成。
如果資料表沒有陣列,您可以自行建立!
現在請使用 ARRAY_AGG() 函式,將字串值匯總至陣列。
ARRAY_LENGTH() 函式計算頁數和已查看的產品數:DISTINCT 加入 ARRAY_AGG() 來簡化頁面和產品,瞭解已查看的不重複產品數:點選「Check my progress」確認目標已達成。
重點回顧
陣列可在許多方面派上用場,例如:
ARRAY_LENGTH(<array>) 找出元素數量ARRAY_AGG(DISTINCT <field>) 簡化元素ARRAY_AGG(<field> ORDER BY <field>) 排列元素順序ARRAY_AGG(<field> LIMIT 5) 設定上限與本課程資料集 data-to-insights.ecommerce.all_sessions 相比,用於 Google Analytics 的 BigQuery 公開資料集 bigquery-public-data.google_analytics_sample 包含更多欄位和資料列。更重要的是,該資料集已將產品、頁面和交易等欄位值,直接儲存為 ARRAY。
點選「執行」開始查詢。
向右捲動結果,直到看到 hits.product.v2ProductName 欄位 (稍後將介紹各欄位別名)。
Google Analytics 結構定義中的可用欄位數量龐大,難以進行分析。
您會收到下列錯誤訊息:
Error: Cannot access field page on a value with type ARRAY<STRUCT<hitNumber INT64, time INT64, hour INT64, ...>> at [3:8]
您必須先將陣列拆分成多個資料列,才能正常查詢 REPEATED 欄位 (陣列)。
舉例來說,hits.page.pageTitle 陣列目前儲存為單一資料列:
並需要拆分成多個資料列:
您該如何使用 SQL 做到這點?
答:在陣列欄位中使用 UNNEST() 函式:
稍後我們會進一步說明 UNNEST(),目前只要瞭解下列幾點即可:
點選「Check my progress」確認目標已達成。
您可能會好奇,為何欄位別名 hit.page.pageTitle 看起來像是三個欄位合而為一,並以英文句號分隔。除了使用 ARRAY 值靈活「提高」欄位精細程度外,您還能使用一種 SQL 資料類型,將相關欄位歸為一組來「擴大」結構定義。這種資料類型就是 STRUCT (結構體)。
概念上,您可以直接將 STRUCT 視為已預先彙整至主資料表的獨立資料表。
STRUCT 的特點如下:
聽起來很像資料表,對吧?
點選「+ 新增資料」,然後選取「依據名稱為專案加上星號」並輸入名稱 bigquery-public-data,即可開啟 bigquery-public-data 資料集。
點選「加上星號」。
bigquery-public-data 專案會列在「Explorer」專區。
開啟「bigquery-public-data」。
找到並開啟 google_analytics_sample 資料集。
點選 ga_sessions(366)_ 資料表。
捲動瀏覽結構定義,使用瀏覽器的尋找功能回答下列問題。
可想而知,現今的電子商務網站需要儲存大量工作階段資料。
在單一資料表設定 32 個 STRUCT 的主要優點,是讓您不需使用 JOIN 函式就能執行下列查詢:
.* 語法會指示 BigQuery 傳回該 STRUCT 的所有欄位,很像是 totals.* 是我們單獨彙整的資料表。將大量報表表格儲存為 STRUCT (預先彙整的「資料表」) 和 ARRAY (提高精細程度) 可以:
下一個資料集是記錄賽跑選手跑一圈的時間。每一圈稱為「split」。
|
Row |
runner.name |
runner.split |
|
1 |
Rudisha |
23.4 |
您從欄位別名發現了什麼?結構體內的欄位呈現巢狀結構 (表示 name 和 split 是 runner 的子集),因此使用點記號標記。
如果選手在單場比賽中有多段時間記錄 (例如每圈時間),該怎麼辦?
當然是使用陣列!
|
Row |
runner.name |
runner.splits |
|
1 |
Rudisha |
23.4 |
|
26.3 | ||
|
26.4 | ||
|
26.1 |
重點回顧:
建立標題為 racing 的新資料集。
依序點按 racing 資料集和「建立資料表」。
spls/gsp416/data-insights-course/labs/optimizing-for-performance/race_results.json
將新資料表命名為 race_results。
點選「建立資料表」。
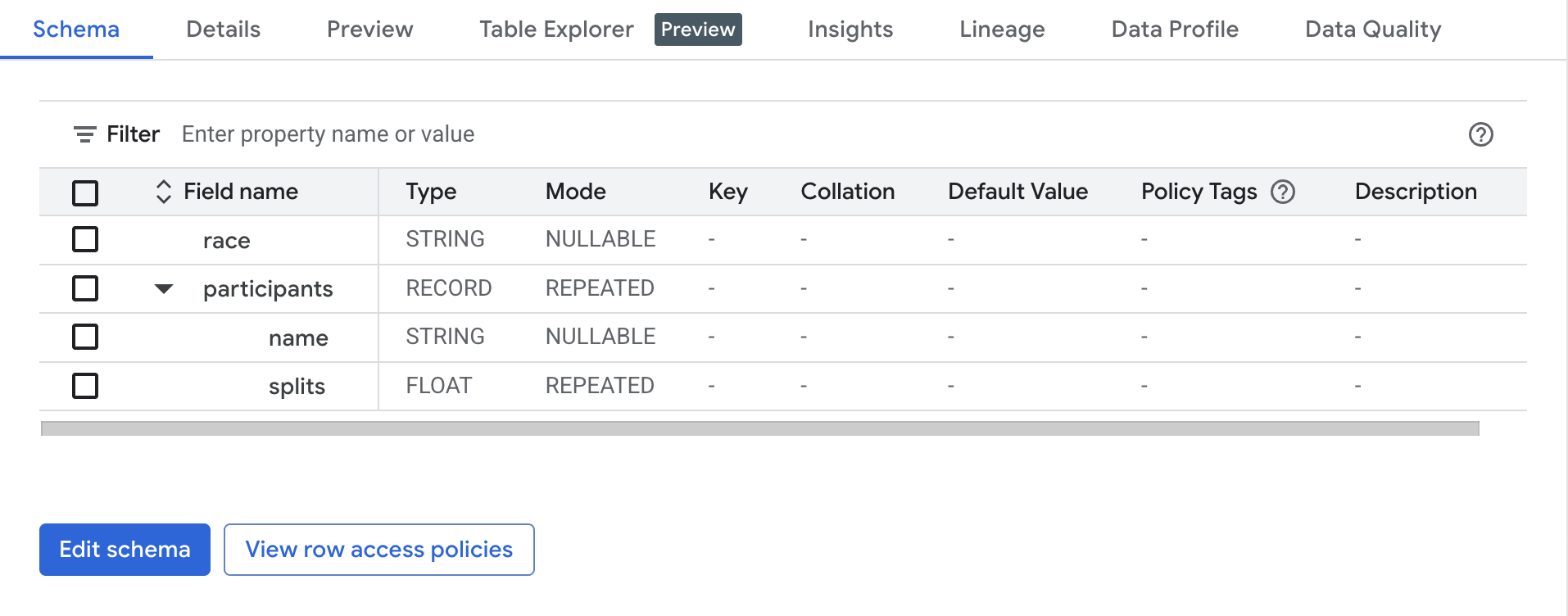
載入工作成功完成後,新建立的資料表結構定義會如下所示:
要怎麼知道哪個欄位屬於 STRUCT?
participants 欄位的資料類型為 RECORD,因此屬於 STRUCT。
哪個欄位屬於 ARRAY?
participants.splits 欄位是父項 participants 結構體內的浮點值陣列,其 REPEATED 模式表示這是陣列。該陣列的值為單一欄位內的多重值,因此屬於巢狀值。
點選「Check my progress」確認目標已達成。
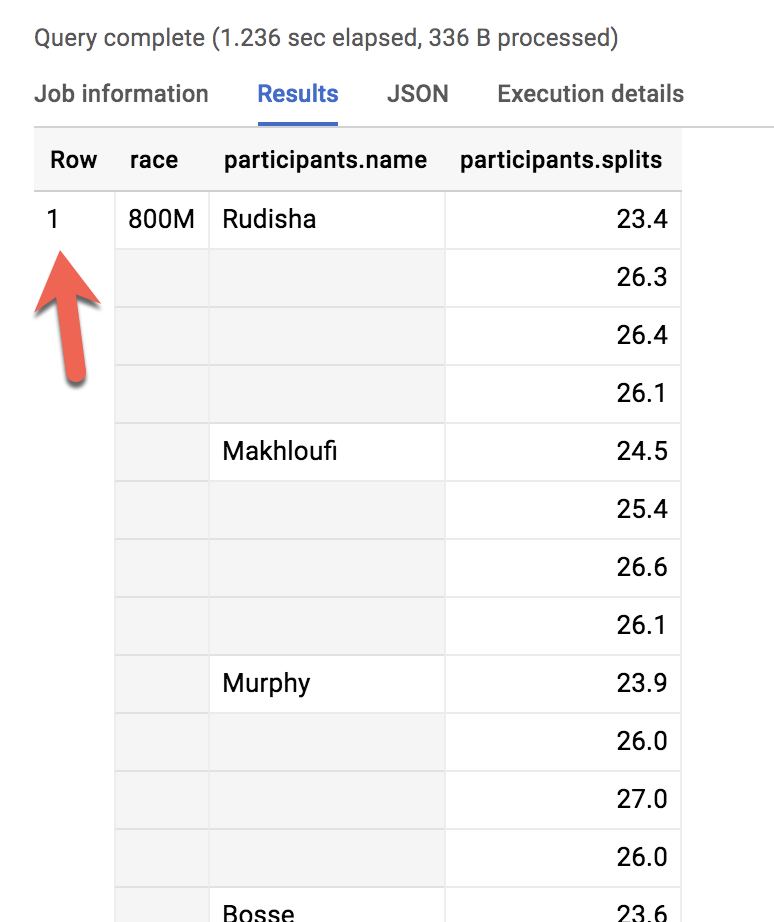
系統傳回多少資料列?
答:1 列
如想逐一列出選手名字和參賽類型,該怎麼做?
Error: Cannot access field name on a value with type ARRAY<STRUCT<name STRING, splits ARRAY<FLOAT64>>>> at [2:27]
就像使用匯總函式時忘記加入 GROUP BY 一樣,這裡的精細程度分成兩個不同等級。一個資料列包含參賽類型,三個資料列包含參賽者名字。該怎麼做,才能將下列資料表...
|
Row |
race |
participants.name |
|
1 |
800M |
Rudisha |
|
2 |
??? |
Makhloufi |
|
3 |
??? |
Murphy |
...改為:
|
Row |
race |
participants.name |
|
1 |
800M |
Rudisha |
|
2 |
800M |
Makhloufi |
|
3 |
800M |
Murphy |
如果使用的是傳統關聯 SQL,該如何從參賽類型資料表和參賽者資料表中擷取資訊?方法是使用 JOIN 函式來彙整這兩個資料表。這裡的參賽者 STRUCT (在概念上與資料表非常類似) 已是參賽類型資料表的一部分,但並未與非 STRUCT 欄位「race」正確建立關聯。
您可以使用某項 SQL 指令,將 800 公尺參賽類型與第一個資料表中的各選手名字建立關聯,想想看是哪項指令?
答:CROSS JOIN
答對了!
Table name "participants" missing dataset while no default dataset is set in the request。
雖然參賽者 STRUCT 類似於資料表,實際上仍是 racing.race_results 資料表的欄位。
太棒了!您成功逐一列出所有參加 800 公尺賽跑的選手!
|
Row |
race |
name |
|
1 |
800M |
Rudisha |
|
2 |
800M |
Makhloufi |
|
3 |
800M |
Murphy |
|
4 |
800M |
Bosse |
|
5 |
800M |
Rotich |
|
6 |
800M |
Lewandowski |
|
7 |
800M |
Kipketer |
|
8 |
800M |
Berian |
查詢結果仍相同:
如有多個參賽類型 (800 公尺、100 公尺、200 公尺),是否能使用 CROSS JOIN,直接將各選手名字與每個可能的參賽類型建立關聯,就像計算笛卡爾乘積一樣?
答:不行。這屬於「關聯 cross join」,只能拆分與單一資料列相關聯的元素。詳情請參閱 ARRAY 與 STRUCT 使用說明文件。
STRUCT 重點回顧:
STRUCT(``"Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as splits``)`` AS runner
請使用先前建立的 racing.race_results 資料表,回答下列問題。
工作:編寫查詢,使用 COUNT 函式計算選手總數。
FROM 後面做為額外資料來源。參考解法:
|
Row |
racer_count |
|
1 |
8 |
答:參賽選手為 8 人。
點選「Check my progress」確認目標已達成。
請編寫查詢,列出名字開頭為 R 的選手的總賽跑時間,並從時間最短的選手開始排序。您必須使用 UNNEST() 運算子,並從下列未編寫完成的查詢著手。
參考解法:
|
Row |
name |
total_race_time |
|
1 |
Rudisha |
102.19999999999999 |
|
2 |
Rotich |
103.6 |
點選「Check my progress」確認目標已達成。
您發現 800 公尺賽跑的最短單圈時間記錄為 23.2 秒,但不知道是哪位選手留下這項記錄。請建立查詢,找出這名選手。
參考解法:
|
Row |
name |
split_time |
|
1 |
Kipketer |
23.2 |
點選「Check my progress」確認目標已達成。
您成功擷取 JSON 資料集,透過建立 ARRAY 和 STRUCT,以及拆分半結構化巢狀資料,取得洞察結果。
協助您瞭解如何充分運用 Google Cloud 的技術。我們的課程會介紹專業技能和最佳做法,讓您可以快速掌握要領並持續進修。我們提供從基本到進階等級的訓練課程,並有隨選、線上和虛擬課程等選項,方便您抽空參加。認證可協助您驗證及證明自己在 Google Cloud 技術方面的技能和專業知識。
使用手冊上次更新日期:2025 年 5 月 8 日
實驗室上次測試日期:2025 年 5 月 8 日
Copyright 2026 Google LLC 保留所有權利。Google 和 Google 標誌是 Google LLC 的商標,其他公司和產品名稱則有可能是其關聯公司的商標。



This content is not currently available
We will notify you via email when it becomes available

Great!
We will contact you via email if it becomes available

One lab at a time
Confirm to end all existing labs and start this one
Complete this quick step to start your lab.