![UI でハイライト表示された [データセットを作成] オプション](https://cdn.qwiklabs.com/431LfWfGu3cCtrT2Wm8cOO7eDZD6Uy4ZsQTW%2BF1%2F9FA%3D)
![ハイライト表示された [テーブルを作成] ボタンと ecommerce データセット](https://cdn.qwiklabs.com/2WTvGjONwrL%2F342h8F2D8sWa1VIVWNafJkWveh1IXPk%3D)
![products テーブルの [詳細] タブ](https://cdn.qwiklabs.com/wiHXC7Uil3F5e7Lqc5rpoi8E0jNrdWjZOIkcfShVQ84%3D)
![エラー メッセージがハイライト表示された [プロジェクト履歴] タブ](https://cdn.qwiklabs.com/kyO4WY7nXq1ykPQWdNc2Gut0%2F8iFktegME7aAGDdiOw%3D)
![展開された状態の [結果を保存する] プルダウン メニュー](https://cdn.qwiklabs.com/uxbrO%2FGMeA5vsICowa36IcRbpnZUHWk93%2Bi%2F%2FnvwOaY%3D)
![[テーブルを作成] ダイアログ](https://cdn.qwiklabs.com/FElwy6Ywb3UM7GzEppDreMwpDg%2FBnaRW%2BmgabPb%2BiWM%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
BigQuery は、Google が提供する低コスト、NoOps のフルマネージド分析データベースです。インフラストラクチャを所有して管理したり、データベース管理者を置いたりすることなく、テラバイト単位の大規模なデータでクエリを実行できます。また、SQL が採用されており、従量課金制というメリットもあります。ユーザーはこのような特徴を活かし、有用な情報を得るためのデータ分析に専念できます。
ここでは、ecommerce データセットを使用します。このデータセットには、Google Merchandise Store に関する数百万件の Google アナリティクス レコードが含まれており、BigQuery に読み込まれています。このデータセットのコピーを使用して、フィールドや行からどのような分析情報が得られるのかを確認します。
このラボでは、数種類のデータセットを BigQuery 内のテーブルに取り込みます。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
Qwiklabs にシークレット ウィンドウでログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
[Cloud Console の BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスにはクイックスタート ガイドへのリンクと、UI の更新情報が表示されます。
[データセット ID] に「ecommerce」と入力します。他のフィールドはデフォルト値のままにします。
[データセットを作成] をクリックします。
プロジェクト名の下に ecommerce データセットが表示されます。
シナリオ: あなたはマーケティング チームから、プロモーションの対象にする商品を在庫ストックレベルに基づいて決定できるようにして欲しいと頼まれました。商品レビューに基づいて、各商品の顧客感情の傾向を把握できるようにする必要もあります。
既存の e コマース トランザクション データセットには在庫ストックレベルや商品レビューのデータは含まれていませんが、運用チームとマーケティング チームから分析用に新しいデータセットが提供されています。
次のように作業を開始します。
商品のストックレベルのデータセットをローカルのコンピュータにダウンロードします。
ecommerce データセットを選択し、[テーブルを作成] をクリックします。
ソース:
先ほどローカルにダウンロードしたファイルを選択
送信先:
テーブル名: products
他の設定はデフォルト値のままにします。
スキーマ:
ヒント: このチェックボックスが表示されない場合は、ファイル形式が Avro ではなく CSV になっていることを確認してください。
詳細オプション:
ecommerce データセットの下に products テーブルが表示されます。
|
SKU |
name |
orderedQuantity |
stockLevel |
restockingLeadTime |
|
GGOEGDHQ014899 |
20 oz Stainless Steel Insulated Tumbler |
499 |
652 |
2 |
|
GGOEGOAB022499 |
Satin Black Ballpoint Pen |
403 |
477 |
2 |
|
GGOEYHPB072210 |
Twill Cap |
1429 |
1997 |
2 |
|
GGOEGEVB071799 |
Pocket Bluetooth Speaker |
214 |
246 |
2 |
CSV ファイルを新しい BigQuery テーブルに読み込むことができました。
次に、基本的なクエリを使用して新しい products テーブルから分析情報を得る方法を実践します。
ecommerce データセットを選択し、[テーブルを作成] をクリックします。
以下のテーブル オプションを指定します。
ソース:
送信先:
テーブル名: products
その他の設定はすべてデフォルトのままにします。
スキーマ:
詳細オプション:
うまくいきましたか?いいえ
[キャンセル] をクリックしてメッセージを閉じ、[テーブルを作成] ダイアログで [はい、終了します] をクリックします。
[エクスプローラ] ペインで [ジョブ履歴] に移動し、[プロジェクト履歴] をクリックして、表示されたエラー メッセージを選択します。
詳細を確認し、[閉じる] をクリックします。
スキーマ セクションに到達するまで、タスク 3 を繰り返します。
下にスクロールして [詳細オプション] を開き、[書き込み設定] のプルダウン メニューから [テーブルを上書きする] を選択します。
次に、[テーブルを作成] をクリックします。
テーブルが正常に作成されたことを確認します。
[+ SQL クエリ] を選択します。
次のクエリを実行します。在庫回転率と補充に要する時間に基づいて、最初に補充すべき商品が示されます。
project_id.ecommerce.products の代わりに ecommerce.products と指定するなど)、BigQuery では現在のプロジェクトのパスと見なされます。シナリオ: あなたは、サプライ チェーン管理チームが商品についてのメモ(サプライヤーに再注文の連絡をしたかどうかなど)を記録できるようにする必要があります。これを迅速に実現するため、Google スプレッドシートを使用することにしました。
まずそのスプレッドシートを作成します。
ポップアップが開き、スプレッドシートを開くためのリンクが表示されます。[開く] を選択します。
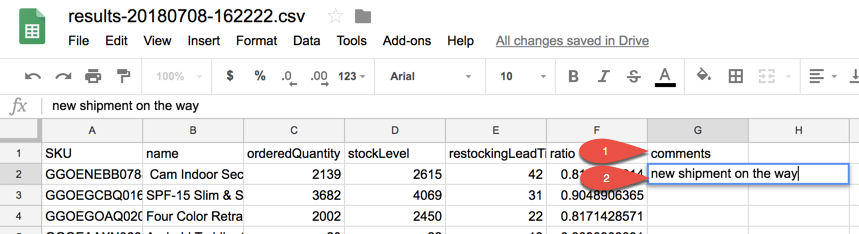
そのスプレッドシートの G 列に「comments」という名前の新しいフィールドを追加し、最初の商品の行に「new shipment on the way」と入力します。
Google スプレッドシートで、[共有]、[共有可能なリンクを取得] の順に選択し、リンクをコピーします。
BigQuery のタブに戻ります。
ecommerce データセットをクリックし、[テーブルを作成] をクリックします。
以下のテーブル オプションを指定します。
ソース:
スプレッドシートの URL を入力
送信先:
スキーマ:
詳細オプション:
[+ SQL クエリ] をクリックします。
以下のクエリを追加して、[実行] をクリックします。
クエリが実行されるのを待ちます。今度は新しい comments フィールドが返されます。
|
SKU |
name |
orderedQuantity |
stockLevel |
restockingLeadTime |
ratio |
comments |
|
GGOENEBB078899 |
Cam Indoor Security Camera - USA |
2139 |
2615 |
42 |
0.8179732314 |
new shipment on the way |
Google スプレッドシートのタブに戻ります。
comments フィールドにさらにコメントを入力します。
BigQuery に戻り、[実行] をクリックしてクエリをもう一度実行します。
新しいデータが結果に正しく表示されることを確認します。
Google スプレッドシートから BigQuery への外部テーブル接続が作成されました。
BigQuery に外部テーブルをリンクする場合(Google スプレッドシートをリンクする場合や、Google Cloud Storage から直接リンクする場合など)、いくつかの制限があります。特に重要なのは次の 2 つです。
新しいデータセットを作成し、CSV、Google Cloud Storage、Google ドライブから BigQuery に新しい外部データソースを取り込むことができました。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。