

시작하기 전에
- 실습에서는 정해진 기간 동안 Google Cloud 프로젝트와 리소스를 만듭니다.
- 실습에는 시간 제한이 있으며 일시중지 기능이 없습니다. 실습을 종료하면 처음부터 다시 시작해야 합니다.
- 화면 왼쪽 상단에서 실습 시작을 클릭하여 시작합니다.

이 실습에서는 펭귄 테이블을 사용하여 펭귄의 종, 서식하는 섬, 부리 길이 및 두께, 지느러미 길이, 성별을 기반으로 펭귄의 무게를 예측하는 모델을 만듭니다.
이 실습에서는 데이터 분석가를 위한 BigQuery ML을 소개합니다. BigQuery ML을 사용하면 BigQuery에서 SQL 쿼리를 사용하여 머신러닝 모델을 만들고 실행할 수 있습니다. BigQuery ML의 목표는 SQL 실무자가 기존 도구를 사용하여 모델을 빌드할 수 있도록 지원하여 머신러닝을 대중화하고 데이터 이동의 필요성을 제거하여 개발 속도를 향상시키는 것입니다.
CREATE MODEL 문을 사용하여 선형 회귀 모델 만들기ML.EVALUATE 함수를 사용하여 ML 모델 평가ML.PREDICT 함수가 있는 ML 모델을 사용하여 예측각 실습에서는 정해진 기간 동안 새 Google Cloud 프로젝트와 리소스 집합이 무료로 제공됩니다.
시크릿 창을 사용하여 Google Skills에 로그인합니다.
실습 사용 가능 시간(예: 1:15:00)을 참고하여 해당 시간 내에 완료합니다.
일시중지 기능은 없습니다. 필요한 경우 다시 시작할 수 있지만 처음부터 시작해야 합니다.
준비가 되면 실습 시작을 클릭합니다.
실습 사용자 인증 정보(사용자 이름 및 비밀번호)를 기록해 두세요. Google Cloud Console에 로그인합니다.
Google Console 열기를 클릭합니다.
다른 계정 사용을 클릭한 다음, 안내 메시지에 이 실습에 대한 사용자 인증 정보를 복사하여 붙여넣습니다.
다른 사용자 인증 정보를 사용하는 경우 오류가 발생하거나 요금이 부과됩니다.
약관에 동의하고 리소스 복구 페이지를 건너뜁니다.
 )에서 API 및 서비스 > 라이브러리를 클릭합니다.
)에서 API 및 서비스 > 라이브러리를 클릭합니다.첫 번째 단계는 ML 모델을 저장할 BigQuery 데이터 세트를 만드는 것입니다. 데이터 세트를 만들려면 다음 안내를 따르세요.
Cloud 콘솔의 탐색 메뉴에서 BigQuery를 클릭합니다.
탐색기 패널에서 프로젝트 ID 옆에 있는 작업 보기 아이콘(3개의 수직 점)을 클릭한 다음 데이터 세트 만들기를 클릭합니다.
'데이터 세트 만들기' 페이지에서 다음을 실행합니다.
데이터 세트 ID에 bqml_tutorial을 입력합니다.
(선택사항) 데이터 위치로 us(미국 내 여러 리전)를 선택합니다.
현재 공개 데이터 세트는 미국 멀티 리전 위치에 저장됩니다. 여기에서는 편의상 같은 위치에 데이터세트를 배치합니다.
다음으로 BigQuery용 펭귄 테이블을 사용하여 선형 회귀 모델을 만듭니다.
CREATE MODEL 명령어를 실행하면 모델을 만드는 것 외에도 만든 모델을 학습시킬 수 있습니다.CREATE MODEL 절은 bqml_tutorial.penguins_model이라는 모델을 만들고 학습하는 데 사용됩니다.
OPTIONS(model_type='linear_reg', input_label_cols=['body_mass_g']) 절은 선형 회귀 모델을 만든다는 것을 나타냅니다. 선형 회귀는 입력 특성의 선형 조합에서 연속 값을 생성하는 회귀 모델의 한 유형입니다. body_mass_g 열은 입력 라벨 열입니다. 선형 회귀 모델에서 라벨 열은 실수치여야 합니다. 즉, 해당 열 값이 실수여야 합니다.
이 쿼리의 SELECT 문은 bigquery-public-data.ml_datasets.penguins 테이블의 모든 열을 사용합니다. 해당 테이블에는 펭귄의 몸무게 예측에 사용될 다음과 같은 열이 포함됩니다.
species: 펭귄의 종(STRING)island: 펭귄이 서식하는 섬(STRING)culmen_length_mm — 부리 길이(밀리미터)(FLOAT64)culmen_depth_mm: 부리 두께(밀리미터)(FLOAT64)flipper_length_mm: 날개 길이(밀리미터)(FLOAT64)sex: 펭귄의 성별(STRING)FROM 절인 bigquery-public-data.ml_datasets.penguins는 ml_datasets 데이터 세트에서 펭귄 테이블을 쿼리 중임을 나타냅니다. 이 데이터 세트는 bigquery-public-data 프로젝트에 있습니다.
WHERE 절인 WHERE body_mass_g IS NOT NULL은 body_mass_g가 NULL인 행을 제외합니다.
CREATE MODEL 쿼리를 실행하여 모델을 만들고 학습시키려면 다음 안내를 따르세요.
Cloud 콘솔에서 새 쿼리 작성을 클릭합니다.
쿼리 편집기 텍스트 영역에 다음 표준 SQL 쿼리를 입력합니다.
이 쿼리는 완료하는 데 약 30초가 소요되며 이후에는 모델(penguins_model)이 탐색 패널에 표시됩니다. 이 쿼리에서는 CREATE MODEL 문을 사용하여 테이블을 만들므로 쿼리 결과가 표시되지 않습니다.
모델 학습 결과를 확인하려면 ML.TRAINING_INFO 함수를 사용하거나 Cloud 콘솔에서 통계를 확인하면 됩니다. 이 튜토리얼에서는 Cloud 콘솔을 사용합니다.
머신러닝 알고리즘은 많은 예를 검사하고 손실을 최소화하는 모델을 찾으려고 시도함으로써 모델을 빌드합니다. 이 프로세스를 경험적 위험 최소화라고 합니다.
손실은 잘못된 예측에 대한 페널티입니다. 예를 들어 모델 예측이 얼마나 잘못되었는지를 나타내는 숫자입니다. 모델의 예측이 완벽하면 손실은 0이고 그렇지 않으면 손실은 그보다 커집니다. 모델 학습의 목표는 모든 예시에서 평균적으로 손실이 적은 가중치와 편향의 집합을 찾는 것입니다.
CREATE MODEL 쿼리를 실행할 때 생성된 모델 학습 통계를 확인하려면 다음 안내를 따르세요.
Cloud 콘솔 탐색 패널의 탐색기 섹션에서 [PROJECT_ID] > bqml_tutorial > 모델(1)을 펼친 다음 penguins_model을 클릭합니다.
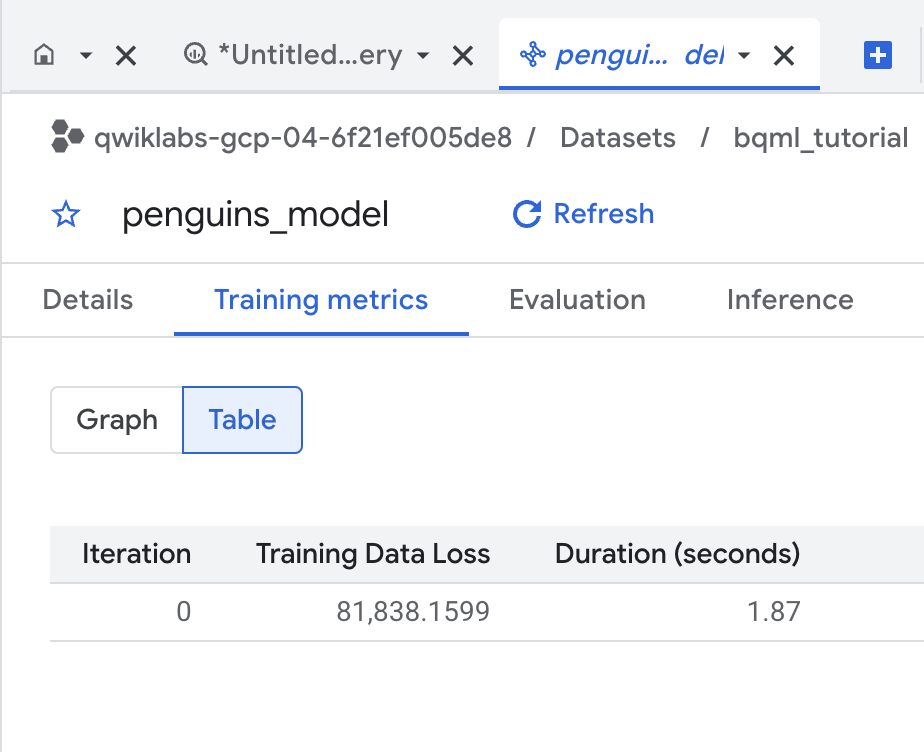
학습 탭을 클릭한 후 테이블을 클릭합니다. 다음과 같은 결과가 표시됩니다.
학습 데이터 손실 열은 학습 데이터 세트에서 모델 학습이 진행된 후 계산된 손실 측정항목을 나타냅니다. 선형 회귀를 수행했으므로 이 열은 평균 제곱 오차입니다.
이 학습에는 'normal_equation' 최적화 전략이 자동으로 사용되므로 반복 1회만 최종 모델에 수렴하면 됩니다. optimize_strategy 옵션에 대한 자세한 내용은 일반화 선형 모델을 위한 CREATE MODEL 문을 참조하세요.
ML.TRAINING_INFO 함수 및 'optimize_strategy' 학습 옵션에 대한 자세한 내용은 BigQuery ML 문법 참조를 확인하세요.
모델을 만든 후에 ML.EVALUATE 함수를 사용하여 모델의 성능을 평가합니다. ML.EVALUATE 함수는 실제 데이터를 기준으로 예측 값을 평가합니다.
SELECT 문은 모델에서 열을 가져옵니다.FROM 절은 bqml_tutorial.penguins_model 모델에 ML.EVALUATE 함수를 사용합니다.SELECT 문과 FROM 절은 CREATE MODEL 쿼리에 있는 것과 동일합니다.WHERE 절인 WHERE body_mass_g IS NOT NULL은 body_mass_g가 NULL인 행을 제외합니다.올바르게 평가하려면 모델 학습에 사용된 데이터와 분리된 펭귄 테이블의 하위 집합에서 평가를 수행해야 하지만, 입력 데이터를 제공하지 않고 ML.EVALUATE를 호출할 수도 있습니다. ML.EVALUATE는 자동으로 예약된 평가 데이터 세트를 사용하는 학습 중에 계산된 평가 측정항목을 검색합니다.
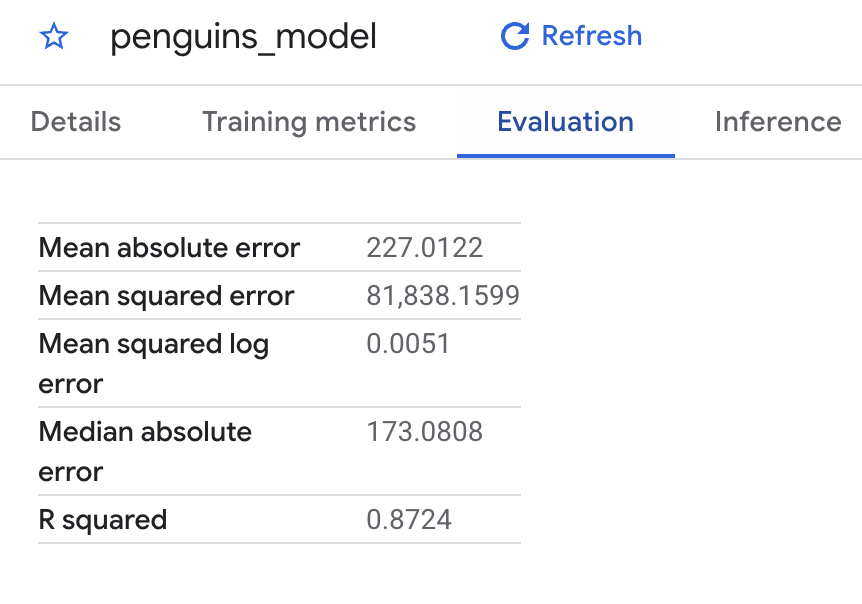
Cloud 콘솔을 사용하여 학습 중에 계산된 평가 측정항목을 볼 수도 있습니다. 다음과 같은 결과가 표시됩니다.
모델을 평가하는 ML.EVALUATE 쿼리를 실행하려면 다음 안내를 따르세요.
Cloud 콘솔에서 새 쿼리 작성을 클릭합니다.
쿼리 편집기 텍스트 영역에 다음 표준 SQL 쿼리를 입력합니다.
(선택사항) 데이터 위치를 설정하려면 더보기 > 쿼리 설정을 클릭합니다. 데이터 위치로 us(미국 내 여러 리전)를 선택합니다.
실행을 클릭합니다.
쿼리가 완료되면 쿼리 텍스트 영역 아래의 결과 탭을 클릭합니다. 다음과 같은 결과가 표시됩니다.
선형 회귀를 수행했으므로 결과에 다음 열이 포함됩니다.
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance평가 결과에서 중요 측정항목은 R2 점수입니다. R2 점수는 선형 회귀 예측이 실제 데이터에 가까운지 알 수 있는 통계 척도입니다. 0은 모델이 평균 주위 응답 데이터의 변동성을 전혀 설명하지 못한다는 것을 나타냅니다. 1은 모델이 평균 주위 응답 데이터의 변동성을 모두 설명한다는 것을 나타냅니다.
모델을 평가했으므로 다음 단계에서는 이 모델을 사용하여 결과를 예측합니다. 모델을 사용하여 Biscoe에 사는 모든 펭귄의 체질량을 그램 단위로 예측합니다.
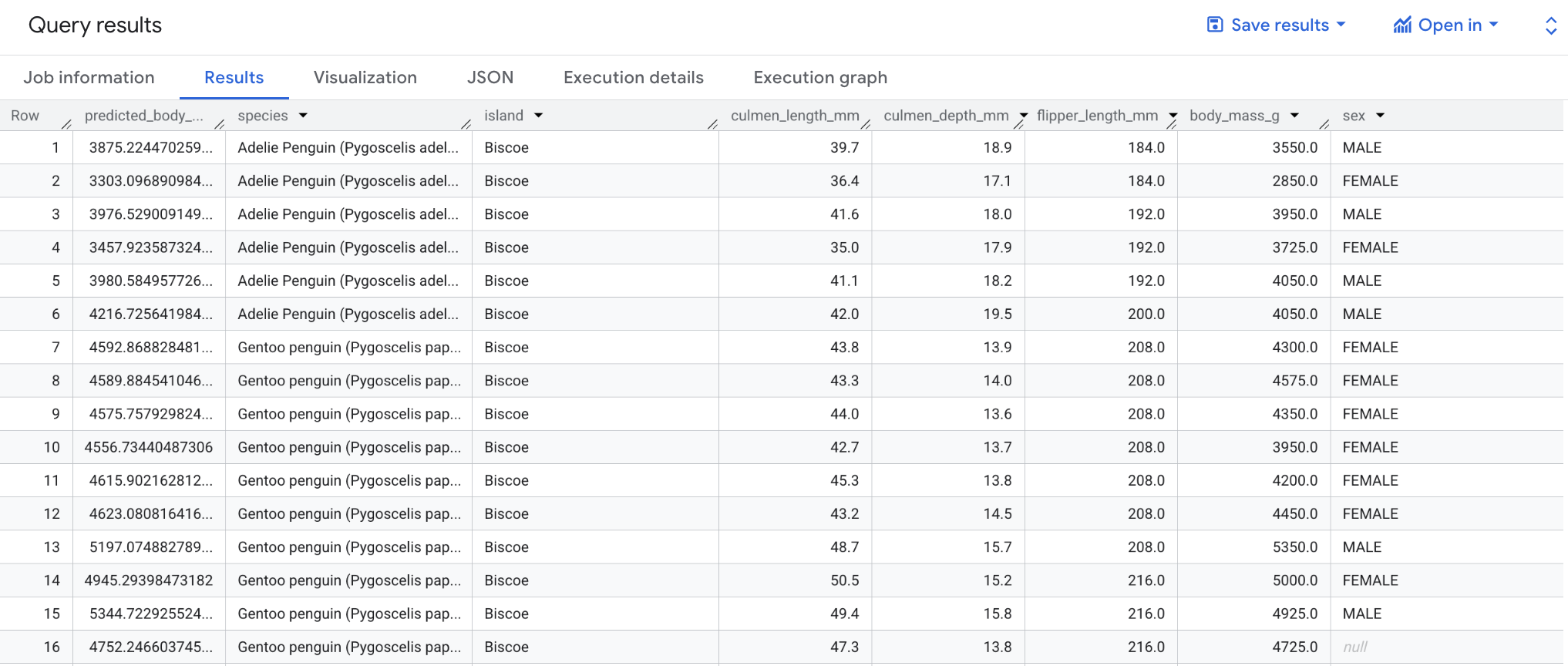
첫 번째 SELECT 문은 bigquery-public-data.ml_datasets.penguins의 열과 함께 predicted_body_mass_g 열을 검색합니다. 이 열은 ML.PREDICT 함수에서 생성됩니다. ML.PREDICT 함수를 사용할 때 모델의 출력 열 이름은 predicted_<label_column_name>입니다. 선형 회귀 모델의 경우 predicted_label은 label의 예상 값입니다. 로지스틱 회귀 모델의 경우 predicted_label은 두 입력 라벨 중 하나이며 예측 가능성이 더 높은 라벨이 됩니다.
ML.PREDICT 함수는 bqml_tutorial.penguins_model 모델을 사용하여 결과를 예측하는 데 사용됩니다.SELECT 문과 FROM 절은 CREATE MODEL 쿼리에 있는 것과 동일합니다.WHERE 절인 WHERE island = "Biscoe"는 예측이 Biscoe 섬에 한정되어 있음을 나타냅니다.모델을 사용하여 결과를 예측하는 쿼리를 실행하려면 다음 안내를 따르세요.
Cloud 콘솔에서 새 쿼리 작성을 클릭합니다.
쿼리 편집기 텍스트 영역에 다음 표준 SQL 쿼리를 입력합니다.
(선택사항) 데이터 위치를 설정하려면 더보기 > 쿼리 설정을 클릭합니다. 데이터 위치로 us(미국 내 여러 리전)를 선택합니다.
실행을 클릭합니다.
쿼리가 완료되면 쿼리 텍스트 영역 아래의 결과 탭을 클릭합니다. 다음과 같은 결과가 표시됩니다.
모델에서 이러한 예측 결과를 생성하는 이유를 알아보려면 ML.EXPLAIN_PREDICT 함수를 사용하면 됩니다.
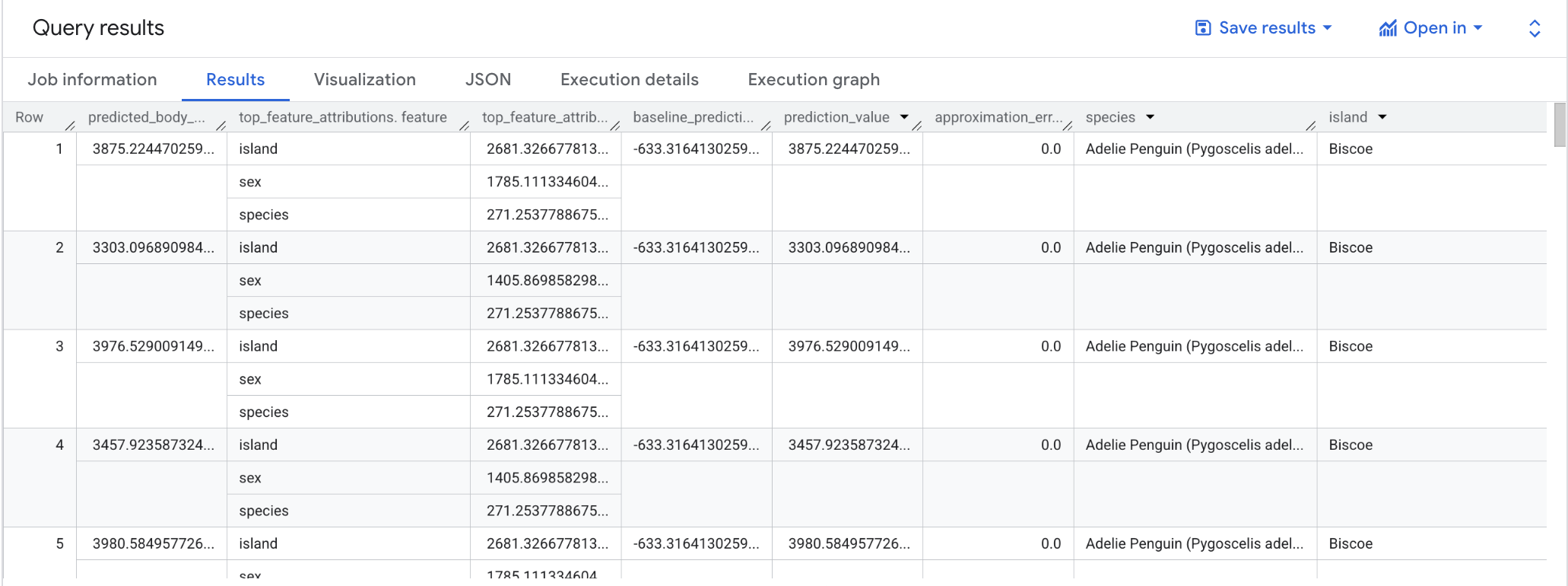
ML.EXPLAIN_PREDICT는 ML.PREDICT의 확장된 버전입니다. ML.EXPLAIN_PREDICT는 결과를 설명하는 추가 열이 있는 예측 결과를 반환합니다.
ML.PREDICT 없이 ML.EXPLAIN_PREDICT를 실행할 수 있습니다. BigQuery ML의 Shapley 값과 Explainable AI에 대한 자세한 내용은 BigQuery ML Explainable AI 개요를 참조하세요.
모델을 설명하는 ML.EXPLAIN_PREDICT 쿼리를 실행하려면 다음 안내를 따르세요.
Cloud 콘솔에서 새 쿼리 작성을 클릭합니다.
쿼리 편집기 텍스트 영역에 다음 표준 SQL 쿼리를 입력합니다.
실행을 클릭합니다.
쿼리가 완료되면 쿼리 텍스트 영역 아래의 결과 탭을 클릭합니다. 다음과 같은 결과가 표시됩니다.
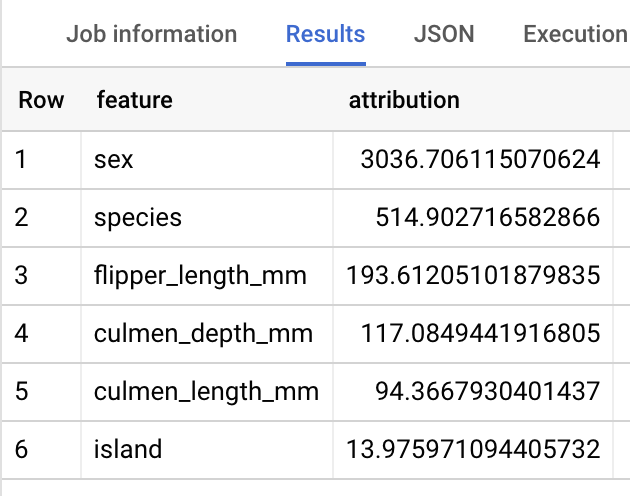
선형 회귀 모델에서 Shapley 값은 모델의 특성별로 특성 기여값을 생성하는 데 사용됩니다. ML.EXPLAIN_PREDICT는 쿼리에서 top_k_features가 3으로 설정되었기 때문에 제공된 테이블의 행당 특성 기여 항목 3개를 출력합니다.
이러한 기여 항목은 절댓값을 기준으로 내림차순으로 정렬됩니다. 모든 예시에서 sex 특성이 전체 예측에 가장 많이 기여했습니다. ML.EXPLAIN_PREDICT 쿼리 출력 열에 대한 자세한 설명은 ML.EXPLAIN_PREDICT 문법 문서를 참조하세요.
일반적으로 펭귄의 체중을 결정하는 데 가장 중요한 특성이 무엇인지 알아보려면 ML.GLOBAL_EXPLAIN 함수를 사용하면 됩니다. ML.GLOBAL_EXPLAIN을 사용하려면 ENABLE_GLOBAL_EXPLAIN=TRUE 옵션을 사용하여 모델을 다시 학습시켜야 합니다.
ML.GLOBAL_EXPLAIN 쿼리를 실행하려면 다음 안내를 따르세요.
Cloud 콘솔에서 새 쿼리 작성을 클릭합니다.
쿼리 편집기 텍스트 영역에 다음 표준 SQL 쿼리를 입력합니다.
(선택사항) 데이터 위치를 설정하려면 더보기 > 쿼리 설정을 클릭합니다. 데이터 위치로 us(미국 내 여러 리전)를 선택합니다.
실행을 클릭합니다.
쿼리가 완료되면 쿼리 텍스트 영역 아래의 결과 탭을 클릭합니다. 다음과 같은 결과가 표시됩니다.
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트는 유지하되 개별 리소스를 삭제하세요.
프로젝트를 삭제하면 프로젝트의 데이터 세트와 테이블이 모두 삭제됩니다. 프로젝트를 다시 사용하려면 이 튜토리얼에서 만든 데이터 세트를 삭제할 수 있습니다.
필요한 경우 Cloud 콘솔에서 BigQuery 페이지를 엽니다.
탐색기 패널에서 데이터 세트 옆에 있는 작업 보기(
삭제를 클릭합니다.
데이터 세트 삭제 대화상자에서 삭제 명령어를 확인하려면 delete를 입력하고 삭제를 클릭합니다.
프로젝트를 삭제하는 방법은 다음과 같습니다.
프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
대화상자에서 프로젝트 ID를 입력하고 종료를 클릭하여 프로젝트를 삭제합니다.
다음과 같은 내용을 배웠습니다.
CREATE MODEL 문을 사용하여 선형 회귀 모델 만들기ML.EVALUATE 함수를 사용하여 ML 모델 평가ML.PREDICT 함수가 있는 ML 모델을 사용하여 예측머신러닝 단기집중과정을 참조하여 머신러닝을 알아보세요.
BigQuery ML 개요는 BigQuery ML 소개를 참조하세요.
Cloud 콘솔에 대해 자세히 알아보려면 Cloud 콘솔 사용을 참조하세요.
실습을 완료하면 실습 종료를 클릭합니다. Qwiklabs에서 사용된 리소스를 자동으로 삭제하고 계정을 지웁니다.
실습 경험을 평가할 수 있습니다. 해당하는 별표 수를 선택하고 의견을 입력한 후 제출을 클릭합니다.
별점의 의미는 다음과 같습니다.
의견을 제공하고 싶지 않다면 대화상자를 닫으면 됩니다.
의견이나 제안 또는 수정할 사항이 있다면 지원 탭을 사용하세요.
Copyright 2026 Google LLC All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.



현재 이 콘텐츠를 이용할 수 없습니다
이용할 수 있게 되면 이메일로 알려드리겠습니다.

감사합니다
이용할 수 있게 되면 이메일로 알려드리겠습니다.

한 번에 실습 1개만 가능
모든 기존 실습을 종료하고 이 실습을 시작할지 확인하세요.