![[トレーニング] タブにテーブル形式で表示されている penguins_model の統計情報](https://cdn.qwiklabs.com/BnX93kLgP0ixyOZzsn8RQ7aCbQchcw3y6imIenH62SI%3D)
![penguins_model の [評価] タブに、平均絶対誤差、平均二乗誤差、平均二乗対数誤差、中央絶対誤差、決定係数の詳細が表示されている](https://cdn.qwiklabs.com/4wjyiofSLAXibmOW6E26xpXRf5OcvXwzyADkdvK87rY%3D)

![[Row]、[feature]、[attribution] の列見出しの下に 6 行のデータを表示しているクエリ結果ページ](https://cdn.qwiklabs.com/aAmRJ7zncxMLi2TKAtGejI9nknN9klicw731ij3ndYo%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します

このラボでは、penguins テーブル(ペンギンに関するテーブル)を使用して、ペンギンの種類、生息地、くちばしの長さと高さ、フリッパーの長さ、性別に基づいてペンギンの体重を予測するモデルを作成します。
このラボでは、データ アナリストの方を対象に BigQuery ML を紹介します。BigQuery ML を使用すると、BigQuery で SQL クエリを使用して ML モデルを作成して実行できます。SQL のユーザーが使い慣れたツールを使用してモデルを構築し、データ移動の必要性を排除することで開発スピードを向上させ、より多くの人が ML を利用できるようにすることを目標としています。
CREATE MODEL ステートメントを使用して線形回帰モデルを作成するML.EVALUATE 関数を使用して ML モデルを評価するML.PREDICT 関数を使用して予測を行う各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
シークレット ウィンドウを使用して Google Skills にログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
 )で、[API とサービス] > [ライブラリ] をクリックします。
)で、[API とサービス] > [ライブラリ] をクリックします。まず、ML モデルを格納する BigQuery データセットを作成します。データセットを作成するには、次の操作を行います。
Cloud コンソールのナビゲーション メニューで [BigQuery] をクリックします。
[エクスプローラ] パネルで、プロジェクト ID の横にあるアクションを表示アイコン(縦に 3 つ並んだ点)をクリックし、[データセットを作成] をクリックします。
[データセットを作成する] ページで次の操作を行います。
[データセット ID] に「bqml_tutorial」と入力します。
(省略可)[データのロケーション] で、[us(米国の複数のリージョン)] を選択します。
現在、一般公開データセットは米国のマルチリージョン ロケーションに保存されています。わかりやすくするため、データセットは同じロケーションに配置してください。
次に、BigQuery の penguins テーブルを使用して線形回帰モデルを作成します。
CREATE MODEL コマンドを実行して、作成したモデルをトレーニングします。CREATE MODEL 句を使用して、bqml_tutorial.penguins_model という名前のモデルを作成してトレーニングします。
OPTIONS(model_type='linear_reg', input_label_cols=['body_mass_g']) 句は、線形回帰モデルを作成することを意味します。線形回帰は、入力する特徴量の線型結合から連続値を生成する回帰モデルです。body_mass_g 列は入力ラベルの列です。線形回帰モデルの場合、ラベル列は実数にする必要があります(列の値が実数でなければなりません)。
このクエリの SELECT ステートメントは、bigquery-public-data.ml_datasets.penguins テーブルのすべての列を使用します。このテーブルには、ペンギンの体重予測に使用される次の列が含まれています。
species: ペンギンの種類(STRING)island: ペンギンが生息する島(STRING)culmen_length_mm: くちばしの長さ(ミリメートル)(FLOAT64)culmen_depth_mm: くちばしの高さ(ミリメートル)(FLOAT64)flipper_length_mm: フリッパーの長さ(ミリメートル)(FLOAT64)sex: ペンギンの性別(STRING)FROM 句(bigquery-public-data.ml_datasets.penguins)は、ml_datasets データセットの penguins テーブルに対してクエリを実行していることを示します。このデータセットは bigquery-public-data プロジェクトにあります。
WHERE 句(WHERE body_mass_g IS NOT NULL)で body_mass_g の値が NULL である行を除外します。
モデルを作成してトレーニングする CREATE MODEL クエリを実行するには、次の操作を行います。
Cloud コンソールで、[クエリを新規作成] をクリックします。
クエリエディタのテキスト領域に、次の標準 SQL クエリを入力します。
クエリが完了するまでに約 30 秒かかります。完了後、モデル(penguins_model)がナビゲーション パネルに表示されます。このクエリは CREATE MODEL ステートメントを使用してテーブルを作成するため、クエリの結果は表示されません。
モデルのトレーニング結果を確認するには、ML.TRAINING_INFO 関数を使用するか、Cloud コンソールで統計情報を表示します。このチュートリアルでは Cloud コンソールを使用します。
ML アルゴリズムは、多くのサンプルを検査し、損失を最小限に抑えるモデルを見つけることでモデルを構築します。このプロセスを経験損失最小化と呼びます。
損失とは、精度の低い予測に対するペナルティです。これは、1 つのサンプルでモデルが行った予測の精度がどのくらい低いかで表します。モデルの予測が完璧であれば、損失はゼロになります。それ以外の場合、精度に応じて損失が大きくなります。モデルをトレーニングする目的は、すべてのサンプルで平均的に損失の少ない重みとバイアスの組み合わせを見つけることです。
CREATE MODEL クエリの実行時に生成されたモデルのトレーニング統計を確認するには、次の操作を行います。
Cloud コンソールのナビゲーション メニューの [エクスプローラ] セクションで、[PROJECT_ID] > [bqml_tutorial] > [Models (1)] を開き、[penguins_model] をクリックします。
[トレーニング] タブをクリックしてから、[テーブル] をクリックします。結果は次のようになります。
[トレーニング データの損失] 列は、トレーニング データセットでモデルのトレーニングを行った後に計算された損失指標を表します。線形回帰を行ったので、この列には平均二乗誤差の値が表示されています。
このトレーニングでは「normal_equation」の最適化戦略が自動的に使用されるため、最終モデルに変換するために必要な反復処理は 1 回だけです。optimize_strategy オプションの詳細については、一般化線形モデルの CREATE MODEL ステートメントをご覧ください。
ML.TRAINING_INFO 関数と「optimize_strategy」トレーニング オプションの詳細については、BigQuery ML の構文リファレンスをご覧ください。
モデルを作成したら、ML.EVALUATE 関数を使用してモデルの性能を評価します。ML.EVALUATE 関数は、実際のデータに照らして予測値を評価します。
SELECT ステートメントで、モデルから列を取得します。FROM 句で、モデル bqml_tutorial.penguins_model に対して ML.EVALUATE 関数を使用します。SELECT ステートメントと FROM 句は、CREATE MODEL クエリのものと同じです。WHERE 句(WHERE body_mass_g IS NOT NULL)で body_mass_g の値が NULL である行を除外します。適切な評価を行うには、penguins テーブルのうち、モデルのトレーニングに使用したデータとは別のサブセットを使用する必要があります。また、入力データを指定せずに ML.EVALUATE を呼び出すこともできます。ML.EVALUATE はトレーニング中に計算された評価指標を取得します。これは、自動的に取り分けられた評価用のデータセットを使用しています。
Cloud コンソールを使用して、トレーニング中に計算された評価指標を表示することもできます。結果は次のようになります。
モデルを評価する ML.EVALUATE クエリを実行するには、次の操作を行います。
Cloud コンソールで、[クエリを新規作成] をクリックします。
クエリエディタのテキスト領域に、次の標準 SQL クエリを入力します。
(省略可)データのロケーションを設定するには、[展開] > [クエリ設定] をクリックします。[データのロケーション] で、[us(米国の複数のリージョン)] を選択します。
[実行] をクリックします。
クエリが完了したら、クエリテキスト領域の下にある [結果] タブをクリックします。結果は次のようになります。
線形回帰を使用しているため、結果には次の列が含まれます。
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance評価結果における重要な測定指標は、R2スコア(決定係数)です。R2スコアは、線形回帰予測が実際のデータに近似するかどうかを決定する統計的尺度です。0 は、平均値からのレスポンス データの変動をモデルがまったく説明していないことを示しています。1 は、平均値からのレスポンス データの変動をモデルがすべて説明していることを示しています。
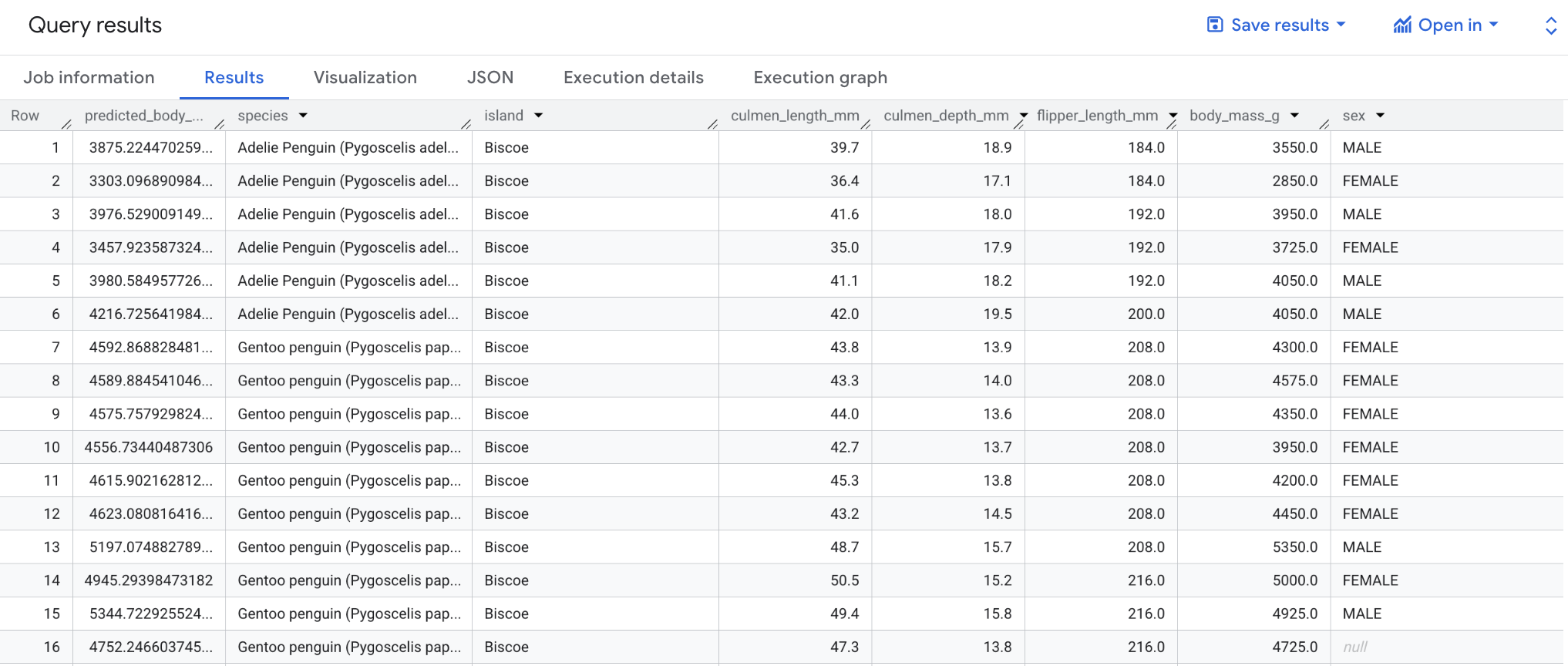
モデルの評価を行ったので、モデルを使用して結果を予測します。このモデルを使用して、ビスコー諸島に生息するすべてのペンギンの体重をグラムで予測します。
最初の SELECT ステートメントで、predicted_body_mass_g 列を bigquery-public-data.ml_datasets.penguins 内の列とともに取得します。この列は ML.PREDICT 関数によって生成されます。ML.PREDICT 関数を使用する場合、モデルの出力列名は predicted_<label_column_name> になります。線形回帰モデルの場合、predicted_label は label の推定値になります。ロジスティック回帰モデルの場合、predicted_label は、2 つの入力ラベルのうち予測された確率の高い方になります。
ML.PREDICT 関数は、モデル bqml_tutorial.penguins_model による結果の予測を行うために使われます。SELECT ステートメントと FROM 句は、CREATE MODEL クエリのものと同じです。WHERE 句(WHERE island = "Biscoe")は、予測をビスコー諸島に限定していることを示します。モデルを使用して結果を予測するクエリを実行するには、次の操作を行います。
Cloud コンソールで、[クエリを新規作成] をクリックします。
クエリエディタのテキスト領域に、次の標準 SQL クエリを入力します。
(省略可)データのロケーションを設定するには、[展開] > [クエリ設定] をクリックします。[データのロケーション] で、[us(米国の複数のリージョン)] を選択します。
[実行] をクリックします。
クエリが完了したら、クエリテキスト領域の下にある [結果] タブをクリックします。結果は次のようになります。
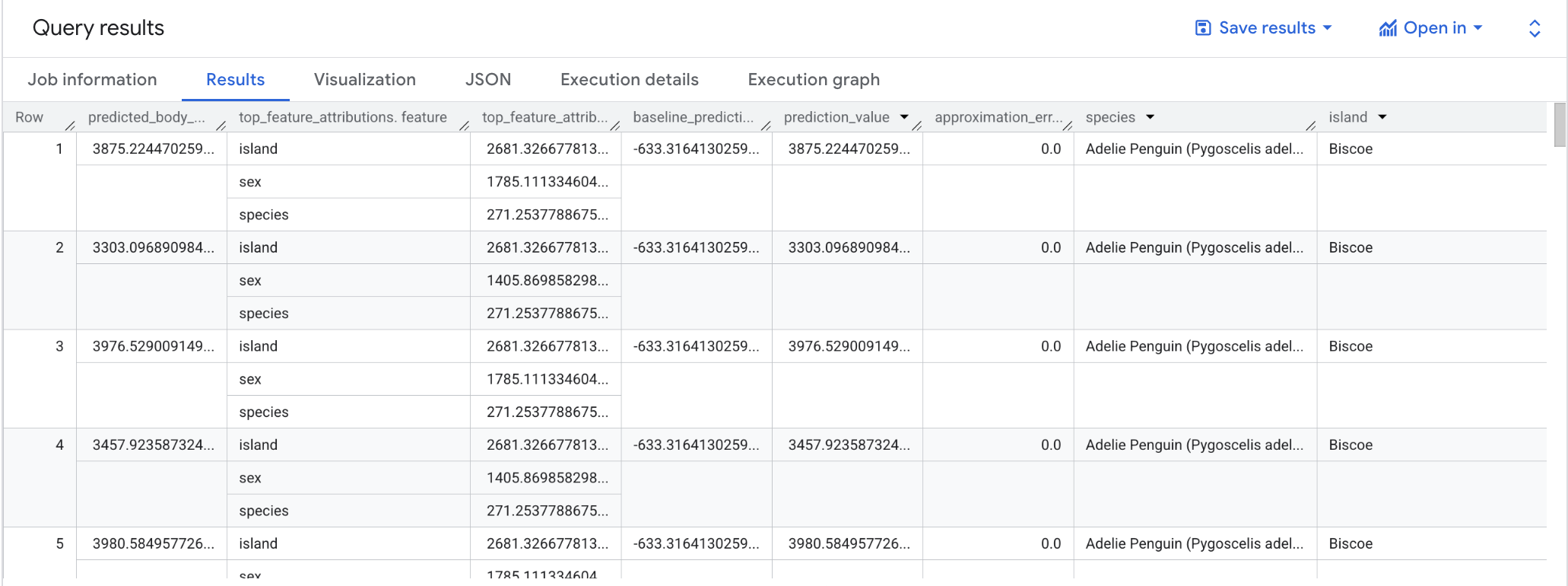
モデルがこれらの予測結果を生成する理由を理解するには、ML.EXPLAIN_PREDICT 関数を使用します。
ML.EXPLAIN_PREDICT は ML.PREDICT の拡張版です。ML.EXPLAIN_PREDICT は、予測結果と結果の説明を含む追加の列を返します。
ML.EXPLAIN_PREDICT を実行する場合、ML.PREDICT の実行は不要です。BigQuery ML での Shapley 値と Explainable AI の詳細については、BigQuery ML Explainable AI の概要をご覧ください。
モデルを説明する ML.EXPLAIN_PREDICT クエリを実行するには、次の操作を行います。
Cloud コンソールで、[クエリを新規作成] をクリックします。
クエリエディタのテキスト領域に、次の標準 SQL クエリを入力します。
[実行] をクリックします。
クエリが完了したら、クエリテキスト領域の下にある [結果] タブをクリックします。結果は次のようになります。
線形回帰モデルでは、Shapley 値を使用して、モデル内の各特徴量の特徴アトリビューション値を生成します。クエリで top_k_features が 3 に設定されているため、ML.EXPLAIN_PREDICT は指定されたテーブルの行ごとに上位 3 つの特徴アトリビューションを出力します。
これらのアトリビューションは、アトリビューションの絶対値の降順で並べ替えられます。すべての例で、特徴量 sex が予測全体に最も貢献しています。ML.EXPLAIN_PREDICT クエリの出力列の詳細な説明については、ML.EXPLAIN_PREDICT 構文に関するドキュメントをご覧ください。
一般的にペンギンの体重を決定するうえで最も重要な特徴を特定するには、ML.GLOBAL_EXPLAIN 関数を使用します。ML.GLOBAL_EXPLAIN を使用するには、オプション ENABLE_GLOBAL_EXPLAIN=TRUE を指定してモデルを再トレーニングする必要があります。
ML.GLOBAL_EXPLAIN クエリを実行するには、次の操作を行います。
Cloud コンソールで、[クエリを新規作成] をクリックします。
クエリエディタのテキスト領域に、次の標準 SQL クエリを入力します。
(省略可)データのロケーションを設定するには、[展開] > [クエリ設定] をクリックします。[データのロケーション] で、[us(米国の複数のリージョン)] を選択します。
[実行] をクリックします。
クエリが完了したら、クエリテキスト領域の下にある [結果] タブをクリックします。結果は次のようになります。
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
プロジェクトを削除すると、プロジェクト内のデータセットとテーブルがすべて削除されます。プロジェクトを再利用する場合は、このチュートリアルで作成したデータセットを削除します。
必要に応じて、Cloud コンソールで BigQuery ページを開きます。
[エクスプローラ] パネルでデータセットの横にあるアクションを表示のアイコン(
[削除] をクリックします。
[データセット削除の確認] ダイアログ ボックスで、削除コマンドを確定するために「delete」と入力し、[削除] をクリックします。
プロジェクトを削除するには、次の操作を行います。
プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
ここでは、以下の方法を学びました。
CREATE MODEL ステートメントを使用して線形回帰モデルを作成するML.EVALUATE 関数を使用して ML モデルを評価するML.PREDICT 関数を使用して予測を行う機械学習集中講座で ML について学習する。
BigQuery ML の概要で BigQuery ML の概要を確認する。
Cloud コンソールの詳細については、Cloud コンソールを使用するをご覧ください。
ラボでの学習が完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Qwiklabs から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバック、ご提案、修正が必要な箇所については、[サポート] タブからお知らせください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください