Questi contenuti non sono ancora ottimizzati per i dispositivi mobili.
Per un'esperienza ottimale, visualizza il sito su un computer utilizzando un link inviato via email.
Panoramica
In questo lab utilizzerai la tabella relativa ai pinguini per creare un modello che preveda il peso di un pinguino in base alla specie, all'isola su cui vive, alla lunghezza e alle profondità del culmen, alla lunghezza delle pinne e al sesso.
Questo lab introduce BigQuery ML agli analisti di dati. BigQuery ML consente agli utenti di creare ed eseguire modelli di machine learning in BigQuery utilizzando query SQL. L'obiettivo è democratizzare il machine learning consentendo a chi utilizza SQL di creare modelli con i propri strumenti esistenti e aumentare la velocità di sviluppo attraverso l'eliminazione della necessità di spostare i dati.
Obiettivi di apprendimento
Creare un modello di regressione lineare utilizzando l'istruzione CREATE MODEL con BigQuery ML.
Valutare il modello ML con la funzione ML.EVALUATE.
Effettuare previsioni utilizzando il modello ML con la funzione ML.PREDICT.
Configurazione
Per ciascun lab, riceverai un nuovo progetto Google Cloud e un insieme di risorse per un periodo di tempo limitato senza alcun costo aggiuntivo.
Accedi a Google Skills utilizzando una finestra Incognito.
Tieni presente la durata dell'accesso al lab (ad esempio, 1:15:00) e assicurati di finire entro quell'intervallo di tempo.
Non è disponibile una funzionalità di pausa. Se necessario, puoi riavviare il lab ma dovrai ricominciare dall'inizio.
Quando è tutto pronto, fai clic su Inizia lab.
Annota le tue credenziali del lab (Nome utente e Password). Le userai per accedere a Google Cloud Console.
Fai clic su Apri console Google.
Fai clic su Utilizza un altro account e copia/incolla le credenziali per questo lab nei prompt.
Se utilizzi altre credenziali, compariranno errori oppure ti verranno addebitati dei costi.
Accetta i termini e salta la pagina di ripristino delle risorse.
Abilita l'API BigQuery
Nella console Cloud, nel menu di navigazione (), fai clic su API e servizi > Libreria.
Cerca API BigQuery, quindi fai clic su Abilita se non è già abilitata.
Attività 1: crea il tuo set di dati
Il primo passaggio prevede di creare un set di dati BigQuery per archiviare il tuo modello ML. Per creare il set di dati:
Nella console Cloud, nel menu di navigazione, fai clic su BigQuery.
Nel riquadro Explorer, fai clic sull'icona Visualizza azioni (tre puntini verticali) accanto al tuo ID progetto, quindi fai clic su Crea set di dati.
Nella pagina Crea set di dati:
Per ID set di dati, digita bqml_tutorial
(Facoltativo) Per Località dei dati, seleziona USA (più regioni negli Stati Uniti).
Attualmente, i set di dati pubblici sono archiviati nella località Stati Uniti (più regioni). Per semplicità, dovresti inserire il tuo set di dati nella stessa località.
Non modificare le altre impostazioni predefinite e fai clic su Crea set di dati.
Attività 2: crea il tuo modello
Ora creerai un modello di regressione lineare utilizzando la tabella penguins per BigQuery.
La seguente query SQL standard viene utilizzata per creare il modello che utilizzerai per prevedere il peso di un pinguino:
#standardSQL
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model`
OPTIONS
(model_type='linear_reg',
input_label_cols=['body_mass_g']) AS
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
Oltre a creare il modello, il comando CREATE MODEL addestra il modello creato.
Dettagli query
La clausola CREATE MODEL viene utilizzata per creare e addestrare il modello denominato bqml_tutorial.penguins_model.
La clausola OPTIONS(model_type='linear_reg', input_label_cols=['body_mass_g']) indica che stai creando un modello di regressione lineare. Una regressione lineare è un tipo di modello di regressione che genera un valore continuo da una combinazione lineare di caratteristiche di input. La colonna body_mass_g è la colonna dell'etichetta di input. Per i modelli di regressione lineare, la colonna dell'etichetta deve avere valori reali (i valori della colonna devono essere numeri reali).
L'istruzione SELECT di questa query utilizza tutte le colonne della tabella bigquery-public-data.ml_datasets.penguins. Questa tabella contiene le seguenti colonne che verranno tutte utilizzate per prevedere il peso di un pinguino:
species: specie del pinguino (STRING)
island: isola su cui vive il pinguino (STRING)
culmen_length_mm: lunghezza del culmen in millimetri (FLOAT64)
culmen_depth_mm: profondità del culmen in millimetri (FLOAT64)
flipper_length_mm: lunghezza delle pinne in millimetri (FLOAT64)
sex: il sesso del pinguino (STRING)
La clausola FROM, bigquery-public-data.ml_datasets.penguins, indica che stai eseguendo query sulla tabella penguins nel set di dati ml_datasets. Questo set di dati si trova nel progetto bigquery-public-data.
La clausola WHERE, WHERE body_mass_g IS NOT NULL, esclude le righe in cui body_mass_g è NULL.
Esegui la query CREATE MODEL
Per eseguire la query CREATE MODEL in modo da creare e addestrare il modello:
Nella console Cloud, fai clic su Crea nuova query.
Nell'area di testo Editor query, immetti la seguente query SQL standard:
#standardSQL
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model`
OPTIONS
(model_type='linear_reg',
input_label_cols=['body_mass_g']) AS
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
Fai clic su Esegui.
Il completamento della query richiede circa 30 secondi, dopodiché il tuo modello (penguins_model) verrà visualizzato nel pannello di navigazione. Poiché la query utilizza un'istruzione CREATE MODEL per creare una tabella, non vengono visualizzati i risultati della query.
Nota: puoi ignorare l'avviso relativo ai valori NULL per i dati di input.
Attività 3: ottieni le statistiche di addestramento (attività facoltativa)
Per visualizzare i risultati dell'addestramento del modello, puoi utilizzare la funzione ML.TRAINING_INFO, altrimenti puoi visualizzare le statistiche nella console Cloud. In questo tutorial utilizzi la console Cloud.
Un algoritmo di machine learning crea un modello esaminando molti esempi e tentando di trovare un modello che minimizzi la perdita. Questo processo è noto come minimizzazione empirica del rischio.
La perdita è la penalità per una previsione errata: un numero che indica quanto fosse negativa la previsione del modello su un singolo esempio. Se la previsione del modello è perfetta, la perdita è zero; in caso contrario, la perdita è maggiore. L'obiettivo dell'addestramento di un modello è trovare un insieme di ponderazioni e bias che presentino, in media, una perdita lieve in tutti gli esempi.
Per visualizzare le statistiche di addestramento del modello generate durante l'esecuzione della query CREATE MODEL:
Nel pannello di navigazione della console Cloud, nella sezione Explorer, espandi [PROJECT_ID] > bqml_tutorial > Models (1), quindi fai clic su penguins_model.
Fai clic sulla scheda Addestramento e quindi su Tabella. I risultati dovrebbero essere simili ai seguenti:
La colonna Perdita di dati di addestramento rappresenta la metrica relativa alla perdita calcolata dopo che il modello è stato addestrato sul set di dati di addestramento. Poiché hai eseguito una regressione lineare, questa colonna rappresenta l'errore quadratico medio.
Per questo addestramento viene utilizzata automaticamente una strategia di ottimizzazione "normal_equation", pertanto è necessaria una sola iterazione per convergere al modello finale. Per maggiori dettagli sull'opzione optimize_strategy, fai riferimento all'istruzione CREATE MODEL per i modelli lineari generalizzati.
Dopo aver creato il tuo modello, valuterai le prestazioni del modello utilizzando la funzione ML.EVALUATE. La funzione ML.EVALUATE valuta i valori previsti rispetto ai dati effettivi.
Per valutare il modello viene utilizzata la seguente query:
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL))
Dettagli query
La prima istruzione SELECT recupera le colonne dal modello.
La clausola FROM utilizza la funzione ML.EVALUATE rispetto al tuo modello: bqml_tutorial.penguins_model.
L'istruzione SELECT e la clausola FROM nidificate di questa query sono le stesse della query CREATE MODEL.
La clausola WHERE, WHERE body_mass_g IS NOT NULL, esclude le righe in cui body_mass_g è NULL.
Una valutazione corretta andrebbe eseguita su un sottoinsieme della tabella penguins separato dai dati utilizzati per addestrare il modello. Puoi possibile chiamare ML.EVALUATE senza fornire dati di input. ML.EVALUATE recupererà le metriche di valutazione calcolate durante l'addestramento, che utilizza il set di dati di valutazione riservato automaticamente:
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`)
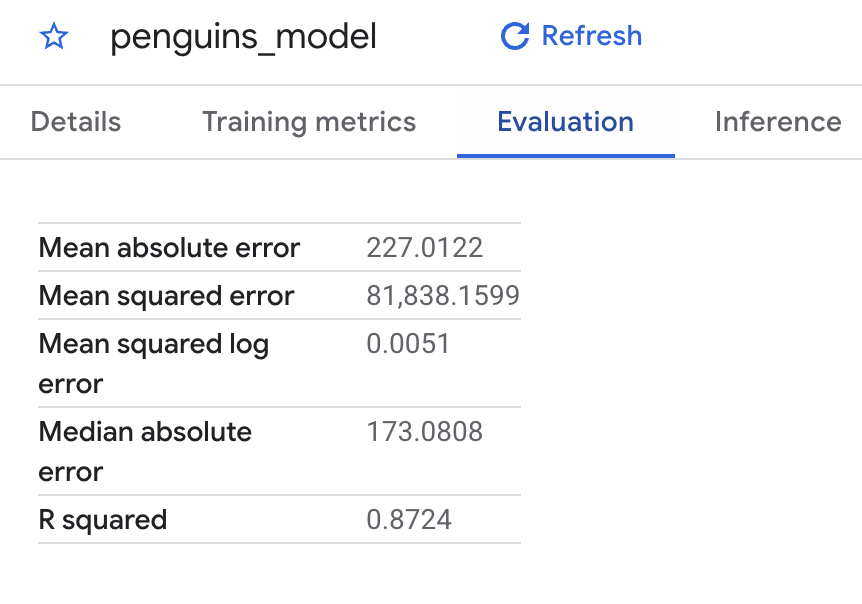
Puoi anche utilizzare la console Cloud per visualizzare le metriche di valutazione calcolate durante l'addestramento. I risultati dovrebbero essere simili ai seguenti:
Esegui la query ML.EVALUATE
Per eseguire la query ML.EVALUATE che valuta il modello:
Nella console Cloud, fai clic su Crea nuova query.
Nell'area di testo Editor query, immetti la seguente query SQL standard:
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL))
(Facoltativo) Per impostare la località dei dati, fai clic su Altro > Impostazioni query. Per Località dei dati, seleziona USA (più regioni negli Stati Uniti).
Fai clic su Esegui.
Una volta completata la query, fai clic sulla scheda Risultati sotto l'area di testo della query. I risultati dovrebbero essere simili ai seguenti:
Poiché hai eseguito una regressione lineare, i risultati includono le seguenti colonne:
mean_absolute_error
mean_squared_error
mean_squared_log_error
median_absolute_error
r2_score
explained_variance
Una metrica importante nei risultati della valutazione è il coefficiente R2. Il coefficiente R2 è una misura statistica che determina se le previsioni della regressione lineare si avvicinano ai dati effettivi. 0 indica che il modello non spiega nessuna delle variabilità dei dati di risposta attorno alla media. 1 indica che il modello spiega tutte le variabilità dei dati di risposta attorno alla media.
Attività 5: usa il tuo modello per prevedere i risultati
Ora che hai valutato il modello, il passaggio successivo consiste nell'utilizzarlo per prevedere un risultato. Utilizzerai il tuo modello per prevedere la massa corporea in grammi di tutti i pinguini che vivono sull'isola di Biscoe.
Per prevedere il risultato, viene utilizzata la seguente query:
#standardSQL
SELECT
*
FROM
ML.PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"))
Dettagli query
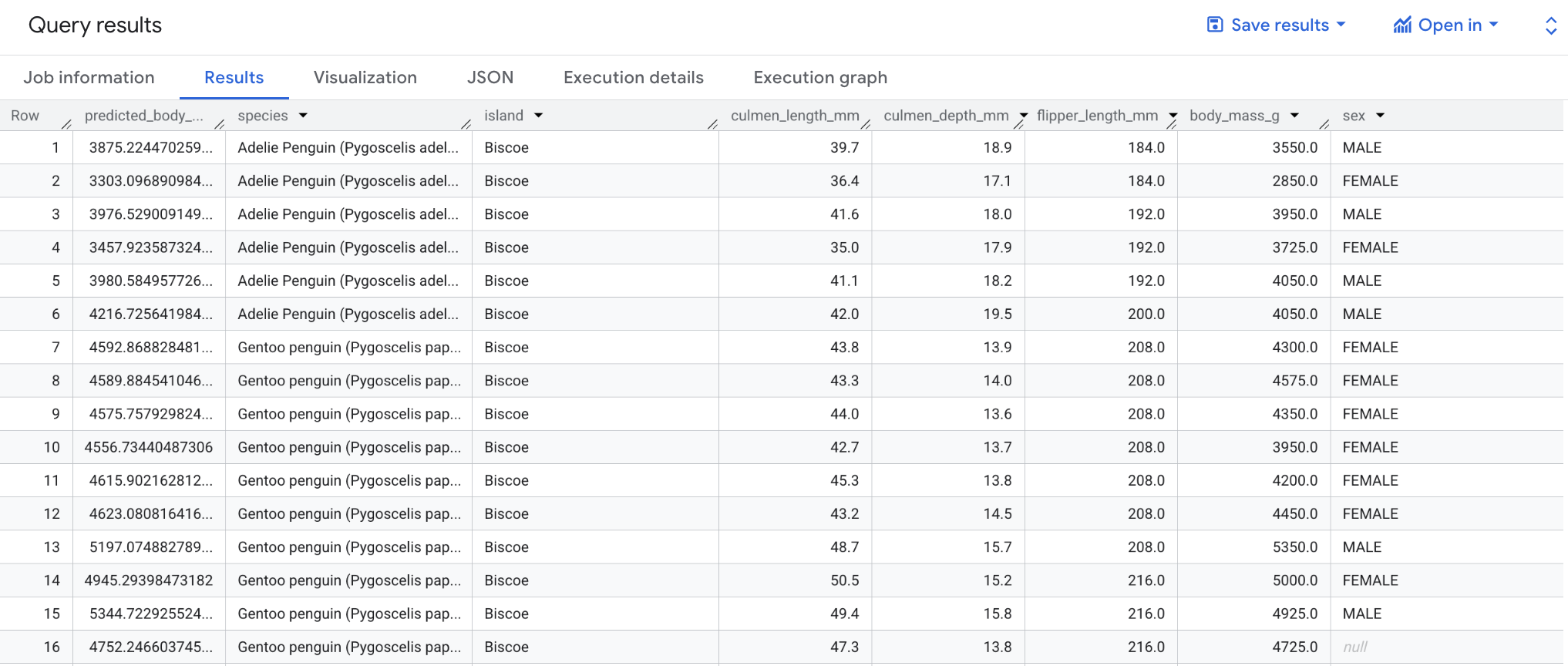
La prima istruzione SELECT recupera la colonna predicted_body_mass_g insieme alle colonne in bigquery-public-data.ml_datasets.penguins. Questa colonna viene generata dalla funzione ML.PREDICT. Quando utilizzi la funzione ML.PREDICT, il nome della colonna di output per il modello è predicted_<label_column_name>. Per i modelli di regressione lineare, predicted_label è il valore stimato di label. Per i modelli di regressione logistica, predicted_label è una delle due etichette di input a seconda di quale etichetta ha la probabilità prevista più elevata.
La funzione ML.PREDICT viene utilizzata per prevedere i risultati mediante il modello bqml_tutorial.penguins_model.
L'istruzione SELECT e la clausola FROM nidificate di questa query sono le stesse della query CREATE MODEL.
La clausola WHERE, WHERE island = "Biscoe", indica che stai limitando la previsione all'isola di Biscoe.
Esegui la query ML.PREDICT
Per eseguire la query che utilizza il modello per prevedere un risultato:
Nella console Cloud, fai clic su Crea nuova query.
Nell'area di testo Editor query, immetti la seguente query SQL standard:
#standardSQL
SELECT
*
FROM
ML.PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"))
(Facoltativo) Per impostare la località dei dati, fai clic su Altro > Impostazioni query. Per Località dei dati, seleziona USA (più regioni negli Stati Uniti).
Fai clic su Esegui.
Una volta completata la query, fai clic sulla scheda Risultati sotto l'area di testo della query. I risultati dovrebbero essere simili ai seguenti:
Attività 6: spiega i risultati della previsione con metodi IA spiegabili
Per capire perché il tuo modello sta generando questi risultati di previsione, puoi utilizzare la funzione ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT è una versione estesa di ML.PREDICT. ML.EXPLAIN_PREDICT restituisce i risultati della previsione con colonne aggiuntive che ne spiegano il significato.
Puoi eseguire ML.EXPLAIN_PREDICT senza ML.PREDICT. Per una spiegazione approfondita dei valori di Shapley e dell'IA spiegabile in BigQuery ML, consulta Panoramica di BigQuery Explainable AI.
Per generare spiegazioni, viene utilizzata la seguente query:
#standardSQL
SELECT
*
FROM
ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"),
STRUCT(3 as top_k_features))
Dettagli query
Esegui la query ML.EXPLAIN_PREDICT
Per eseguire la query ML.EXPLAIN_PREDICT che spiega il modello:
Nella console Cloud, fai clic su Crea nuova query.
Nell'area di testo Editor query, immetti la seguente query SQL standard:
#standardSQL
SELECT
*
FROM
ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"),
STRUCT(3 as top_k_features))
Fai clic su Esegui.
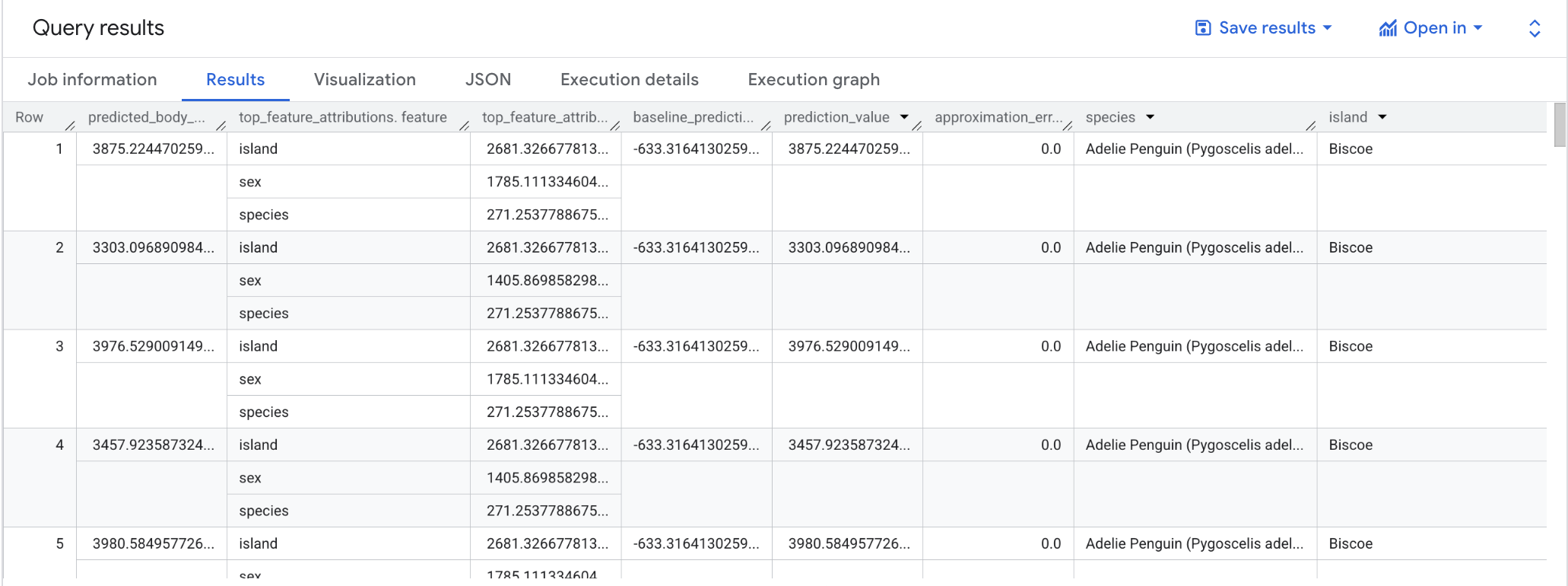
Una volta completata la query, fai clic sulla scheda Risultati sotto l'area di testo della query. I risultati dovrebbero essere simili ai seguenti:
Nota: la query ML.EXPLAIN_PREDICT restituisce tutte le colonne delle caratteristiche di input, in modo analogo alla query ML.PREDICT. Nella figura sopra viene mostrata solo una colonna di caratteristiche, "species", per motivi di leggibilità.
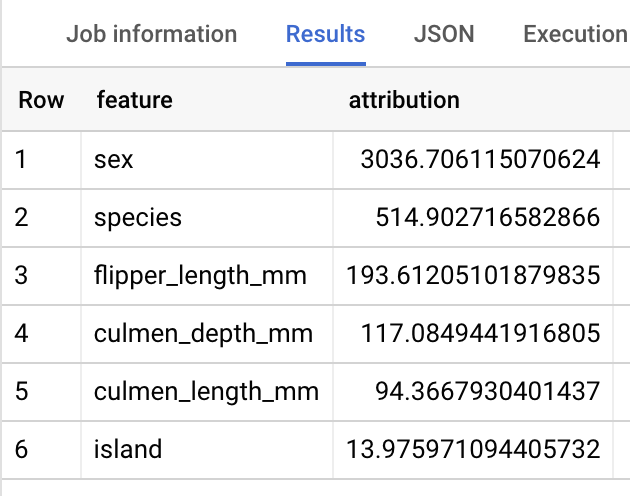
Per i modelli di regressione lineare, vengono utilizzati i valori di Shapley per generare valori di attribuzione di caratteristiche per ogni caratteristica nel modello. ML.EXPLAIN_PREDICT restituisce le prime 3 attribuzioni di caratteristiche per riga della tabella fornita perché top_k_features è stato impostato su 3 nella query.
Queste attribuzioni sono ordinate in base al valore assoluto dell'attribuzione in ordine decrescente. In tutti gli esempi, la caratteristica sex ha contribuito maggiormente alla previsione complessiva. Per spiegazioni dettagliate sulle colonne di output della query ML.EXPLAIN_PREDICT, consulta la documentazione sulla sintassi ML.EXPLAIN_PREDICT.
Attività 7: spiega il tuo modello a livello globale (attività facoltativa)
Per sapere quali caratteristiche sono le più importanti per determinare i pesi dei pinguini in generale, puoi utilizzare la funzione ML.GLOBAL_EXPLAIN. Per utilizzare ML.GLOBAL_EXPLAIN, il modello deve essere riaddestrato con l'opzione ENABLE_GLOBAL_EXPLAIN=TRUE.
Esegui nuovamente la query di addestramento con questa opzione utilizzando la query seguente:
#standardSQL
CREATE OR REPLACE MODEL bqml_tutorial.penguins_model
OPTIONS
(model_type='linear_reg',
input_label_cols=['body_mass_g'],
enable_global_explain=TRUE) AS
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
Nota: puoi ignorare l'avviso relativo ai valori NULL per i dati di input.
Accedi alle spiegazioni globali mediante ML.GLOBAL_EXPLAIN
Per generare spiegazioni globali, viene utilizzata la seguente query:
#standardSQL
SELECT
*
FROM
ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
Dettagli query
Esegui la query ML.GLOBAL_EXPLAIN
Per eseguire la query ML.GLOBAL_EXPLAIN:
Nella console Cloud, fai clic su Crea nuova query.
Nell'area di testo Editor query, immetti la seguente query SQL standard:
#standardSQL
SELECT
*
FROM
ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
(Facoltativo) Per impostare la località dei dati, fai clic su Altro > Impostazioni query. Per Località dei dati, seleziona USA (più regioni negli Stati Uniti).
Fai clic su Esegui.
Una volta completata la query, fai clic sulla scheda Risultati sotto l'area di testo della query. I risultati dovrebbero essere simili ai seguenti:
Attività 8: esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Eliminazione del set di dati
L'eliminazione del progetto rimuove tutti i set di dati e tutte le tabelle nel progetto. Se preferisci riutilizzare il progetto, puoi eliminare il set di dati creato in questo tutorial:
Se necessario, apri la pagina BigQuery nella console Cloud.
Nel riquadro Explorer, fai clic su Visualizza azioni () accanto al tuo set di dati.
Fai clic su Elimina.
Nella finestra di dialogo Elimina set di dati, per confermare il comando, digita delete e fai clic su Elimina.
Eliminazione del progetto
Per eliminare il progetto:
Nella console Cloud, nel menu di navigazione, fai clic su IAM e amministrazione > Gestisci risorse.
Nota: se richiesto, fai clic su ESCI per il lavoro non salvato.
Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
Nella finestra di dialogo, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.
Complimenti!
Hai imparato a:
Creare un modello di regressione lineare utilizzando l'istruzione CREATE MODEL con BigQuery ML.
Valutare il modello ML con la funzione ML.EVALUATE.
Effettuare previsioni utilizzando il modello ML con la funzione ML.PREDICT.
Una volta completato il lab, fai clic su Termina lab. Qwiklabs rimuove le risorse che hai utilizzato ed esegue la pulizia dell'account.
Avrai la possibilità di inserire una valutazione in merito alla tua esperienza. Seleziona il numero di stelle applicabile, inserisci un commento, quindi fai clic su Invia.
Il numero di stelle corrisponde alle seguenti valutazioni:
1 stella = molto insoddisfatto
2 stelle = insoddisfatto
3 stelle = esperienza neutra
4 stelle = soddisfatto
5 stelle = molto soddisfatto
Se non vuoi lasciare un feedback, chiudi la finestra di dialogo.
Per feedback, suggerimenti o correzioni, utilizza la scheda Assistenza.
Copyright 2026 Google LLC Tutti i diritti riservati. Google e il logo Google sono marchi di Google LLC. Tutti gli altri nomi di società e prodotti sono marchi delle rispettive società a cui sono associati.
I lab creano un progetto e risorse Google Cloud per un periodo di tempo prestabilito
I lab hanno un limite di tempo e non possono essere messi in pausa. Se termini il lab, dovrai ricominciare dall'inizio.
In alto a sinistra dello schermo, fai clic su Inizia il lab per iniziare
Utilizza la navigazione privata
Copia il nome utente e la password forniti per il lab
Fai clic su Apri console in modalità privata
Accedi alla console
Accedi utilizzando le tue credenziali del lab. L'utilizzo di altre credenziali potrebbe causare errori oppure l'addebito di costi.
Accetta i termini e salta la pagina di ripristino delle risorse
Non fare clic su Termina lab a meno che tu non abbia terminato il lab o non voglia riavviarlo, perché il tuo lavoro verrà eliminato e il progetto verrà rimosso
Questi contenuti non sono al momento disponibili
Ti invieremo una notifica via email quando sarà disponibile
Bene.
Ti contatteremo via email non appena sarà disponibile
Un lab alla volta
Conferma per terminare tutti i lab esistenti e iniziare questo
Utilizza la navigazione privata per eseguire il lab
Il modo migliore per eseguire questo lab è utilizzare una finestra del browser in incognito o privata. Ciò evita eventuali conflitti tra il tuo account personale e l'account studente, che potrebbero causare addebiti aggiuntivi sul tuo account personale.
In questo lab imparerai a creare ed eseguire modelli di machine learning in BigQuery utilizzando query SQL.
Durata:
Configurazione in 0 m
·
Accesso da 120 m
·
Completamento in 120 m

 ), fai clic su API e servizi > Libreria.
), fai clic su API e servizi > Libreria.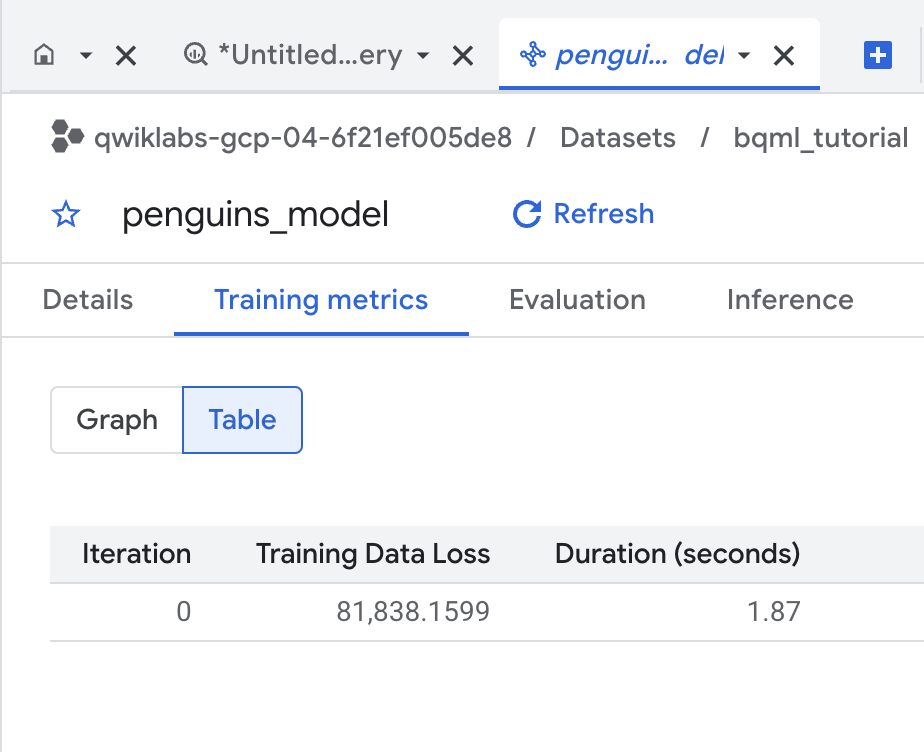

 ) accanto al tuo set di dati.
) accanto al tuo set di dati.




