Mettez en pratique vos compétences dans la console Google Cloud
Instructions et exigences de configuration de l'atelier
Protégez votre compte et votre progression. Utilisez toujours une fenêtre de navigation privée et les identifiants de l'atelier pour exécuter cet atelier.
Utiliser BigQuery ML pour prédire le poids d'un manchot
Ce contenu n'est pas encore optimisé pour les appareils mobiles.
Pour une expérience optimale, veuillez accéder à notre site sur un ordinateur de bureau en utilisant un lien envoyé par e-mail.
Présentation
Dans cet atelier, vous allez utiliser la table penguins pour créer un modèle capable de prédire le poids d'un manchot en fonction de l'espèce, de l'île de résidence, de la longueur et de la profondeur du culmen, de la longueur des nageoires et du sexe.
Cet atelier présente BigQuery ML aux analystes de données. BigQuery ML permet aux utilisateurs de créer et d'exécuter des modèles de machine learning dans BigQuery à l'aide de requêtes SQL. L'objectif est de démocratiser le machine learning en permettant aux utilisateurs de SQL de créer des modèles à l'aide de leurs propres outils et d'accélérer le rythme de développement en leur évitant d'avoir à transférer des données.
Objectifs de la formation
Créer un modèle de régression linéaire à l'aide de l'instruction CREATE MODEL avec BigQuery ML
Évaluer le modèle de ML grâce à la fonction ML.EVALUATE
Effectuer des prédictions à l'aide du modèle de ML avec la fonction ML.PREDICT
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Google Skills dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à la console Google Cloud.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Activer l'API BigQuery
Dans le menu de navigation () de la console Cloud, cliquez sur API et services > Bibliothèque.
Recherchez l'API BigQuery, puis cliquez sur Activer si elle n'est pas déjà activée.
Tâche 1 : Créer votre ensemble de données
La première étape consiste à créer un ensemble de données BigQuery afin de stocker votre modèle de ML. Procédez comme suit :
Dans la console Cloud, accédez au menu de navigation, puis cliquez sur BigQuery.
Dans le panneau Explorateur, cliquez sur l'icône Afficher les actions (trois points alignés verticalement) située à côté de votre ID de projet, puis cliquez sur Créer un ensemble de données.
Sur la page "Créer un ensemble de données", procédez comme suit :
Dans le champ ID de l'ensemble de données, saisissez bqml_tutorial.
(Facultatif) Pour Emplacement des données, sélectionnez us (plusieurs régions aux États-Unis). Les ensembles de données publics sont actuellement stockés dans l'emplacement multirégional "US". Par souci de simplicité, vous devez placer votre ensemble de données dans le même emplacement.
Conservez les autres paramètres par défaut, puis cliquez sur Créer l'ensemble de données.
Tâche 2 : Créer votre modèle
Vous allez ensuite créer un modèle de régression linéaire à l'aide de la table "penguins" pour BigQuery.
La requête SQL standard présentée ci-dessous permet de créer le modèle dont vous vous servez pour prédire le poids d'un manchot :
#standardSQL
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model`
OPTIONS
(model_type='linear_reg',
input_label_cols=['body_mass_g']) AS
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
La commande CREATE MODEL permet de créer le modèle, mais aussi de l'entraîner.
Détails de la requête
La clause CREATE MODEL permet de créer et d'entraîner le modèle bqml_tutorial.penguins_model.
La clause OPTIONS(model_type='linear_reg', input_label_cols=['body_mass_g']) indique que vous créez un modèle de régression linéaire. Une régression linéaire est un type de modèle de régression qui génère une valeur continue à partir d'une combinaison linéaire de caractéristiques d'entrée. La colonne body_mass_g correspond à la colonne de l'étiquette d'entrée. Pour les modèles de régression linéaire, la colonne de l'étiquette doit contenir des valeurs réelles (les valeurs de la colonne doivent être des nombres réels).
L'instruction SELECT de cette requête utilise toutes les colonnes de la table bigquery-public-data.ml_datasets.penguins. Cette table contient les colonnes suivantes qui seront toutes utilisées pour prédire le poids d'un manchot :
species : espèces de manchots (STRING)
island : île où vit le manchot (STRING)
culmen_length_mm : longueur du culmen en millimètres (FLOAT64)
culmen_depth_mm : profondeur du culmen en millimètres (FLOAT64)
flipper_length_mm : longueur de la nageoire en millimètres (FLOAT64)
sex : sexe du manchot (STRING)
La clause FROM (bigquery-public-data.ml_datasets.penguins) indique que vous interrogez la table "penguins" dans l'ensemble de données ml_datasets. Cet ensemble de données se trouve dans le projet bigquery-public-data.
La clause WHERE (WHERE body_mass_g IS NOT NULL) exclut les lignes dans lesquelles body_mass_g est NULL.
Exécuter la requête CREATE MODEL
Pour exécuter la requête CREATE MODEL qui permet de créer et d'entraîner votre modèle, procédez comme suit :
Dans la console Cloud, cliquez sur Saisir une nouvelle requête.
Dans la zone de texte de l'éditeur de requête, saisissez la requête SQL standard suivante :
#standardSQL
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model`
OPTIONS
(model_type='linear_reg',
input_label_cols=['body_mass_g']) AS
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
Cliquez sur Exécuter.
L'exécution de la requête prend environ 30 secondes, puis votre modèle (penguins_model) s'affiche dans le panneau de navigation. Étant donné que la requête utilise une instruction CREATE MODEL pour créer une table, les résultats de la requête ne sont pas affichés.
Remarque : Vous pouvez ignorer l'avertissement concernant les valeurs NULL pour les données d'entrée.
Tâche 3 : Obtenir des statistiques d'entraînement (facultatif)
Pour afficher les résultats de l'entraînement du modèle, vous pouvez vous servir de la fonction ML.TRAINING_INFO. Vous avez également la possibilité d'afficher les statistiques dans la console Cloud. Dans ce tutoriel, vous utilisez la console Cloud.
Pour créer un modèle, un algorithme de machine learning examine de nombreux exemples et essaie de trouver un modèle qui minimise la perte. Ce processus est appelé minimisation du risque empirique.
La perte est la pénalité liée à une mauvaise prédiction, exprimée sous la forme d'un nombre qui indique à quel point la prédiction du modèle est fausse pour un exemple donné. Si la prédiction du modèle est parfaite, la perte est nulle. Sinon, la perte est supérieure à zéro. L'objectif de l'entraînement d'un modèle est de trouver un ensemble de pondérations et de biais présentant une faible perte pour tous les exemples (en moyenne).
Pour afficher les statistiques d'entraînement du modèle générées lors de l'exécution de la requête CREATE MODEL, procédez comme suit :
Dans le panneau de navigation de la console Cloud, dans la section Explorateur, développez [PROJECT_ID] > bqml_tutorial > Models (1), puis cliquez sur penguins_model.
Cliquez sur l'onglet Entraînement, puis sur Table. Les résultats doivent se présenter sous la forme suivante :
La colonne Perte de données d'entraînement représente la métrique de perte calculée après entraînement du modèle avec l'ensemble de données d'entraînement. Comme vous avez effectué une régression linéaire, cette colonne correspond à l'erreur quadratique moyenne.
Après avoir créé votre modèle, vous allez évaluer ses performances à l'aide de la fonction ML.EVALUATE. La fonction ML.EVALUATE compare les valeurs prédites aux données réelles.
La requête suivante est utilisée pour l'évaluation du modèle :
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL))
Détails de la requête
La première instruction SELECT récupère les colonnes de votre modèle.
La clause FROM utilise la fonction ML.EVALUATE sur votre modèle bqml_tutorial.penguins_model.
L'instruction SELECT et la clause FROM imbriquées de cette requête sont identiques à celles de la requête CREATE MODEL.
La clause WHERE (WHERE body_mass_g IS NOT NULL) exclut les lignes dans lesquelles "body_mass_g" est NULL.
Pour effectuer une évaluation appropriée, vous devez utiliser un sous-ensemble de la table "penguins" distinct des données appliquées pour l'entraînement du modèle. Vous pouvez également appeler la fonction ML.EVALUATE sans fournir les données d'entrée. ML.EVALUATE récupère les métriques d'évaluation calculées pendant l'entraînement, lequel utilise l'ensemble de données d'évaluation réservé automatiquement :
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`)
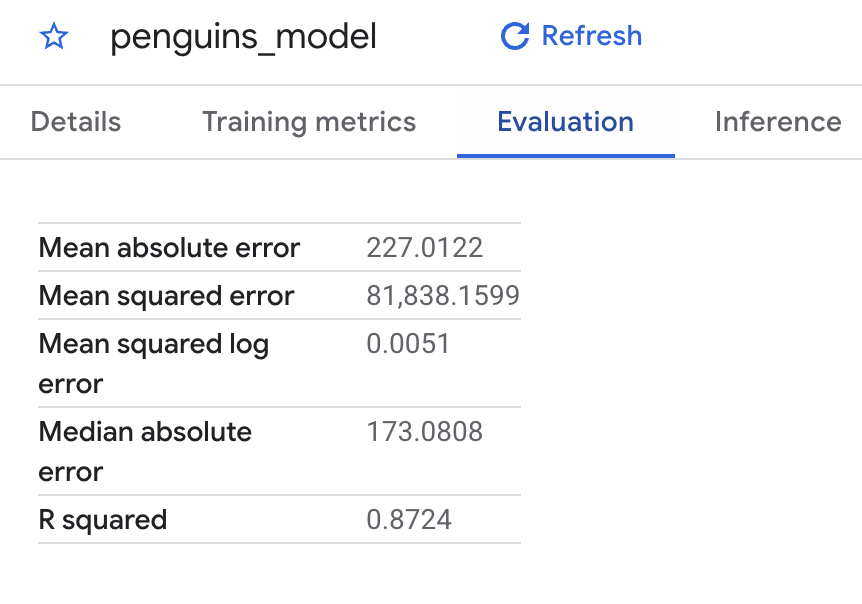
Vous pouvez également utiliser la console Cloud pour afficher les métriques d'évaluation calculées pendant l'entraînement. Les résultats doivent se présenter sous la forme suivante :
Exécuter la requête ML.EVALUATE
Pour exécuter la requête ML.EVALUATE permettant d'évaluer le modèle :
Dans la console Cloud, cliquez sur Saisir une nouvelle requête.
Dans la zone de texte de l'éditeur de requête, saisissez la requête SQL standard suivante :
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL))
(Facultatif) Pour définir l'emplacement des données, cliquez sur Plus > Paramètres de requête. Pour Emplacement des données, sélectionnez us (plusieurs régions aux États-Unis).
Cliquez sur Exécuter.
Lorsque la requête est terminée, cliquez sur l'onglet Résultats sous la zone de texte de la requête. Les résultats doivent se présenter sous la forme suivante :
Étant donné que vous avez effectué une régression linéaire, les résultats incluent les colonnes suivantes :
mean_absolute_error
mean_squared_error
mean_squared_log_error
median_absolute_error
r2_score
explained_variance
Le score R2 est une métrique importante dans les résultats de l'évaluation. Le score R2 est une mesure statistique qui détermine si les prédictions de régression linéaire se rapprochent des données réelles. 0 indique que le modèle n'apporte aucune explication sur la variabilité des données de réponse autour de la moyenne. 1 indique que le modèle explique toute la variabilité des données de réponse autour de la moyenne.
Tâche 5 : Utiliser votre modèle pour prédire les résultats
Maintenant que vous avez évalué votre modèle, l'étape suivante consiste à vous en servir pour prédire un résultat. Vous utilisez votre modèle pour prédire la masse corporelle en grammes de tous les manchots vivant sur l'île de Biscoe.
La requête suivante est utilisée pour prédire le résultat :
#standardSQL
SELECT
*
FROM
ML.PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"))
Détails de la requête
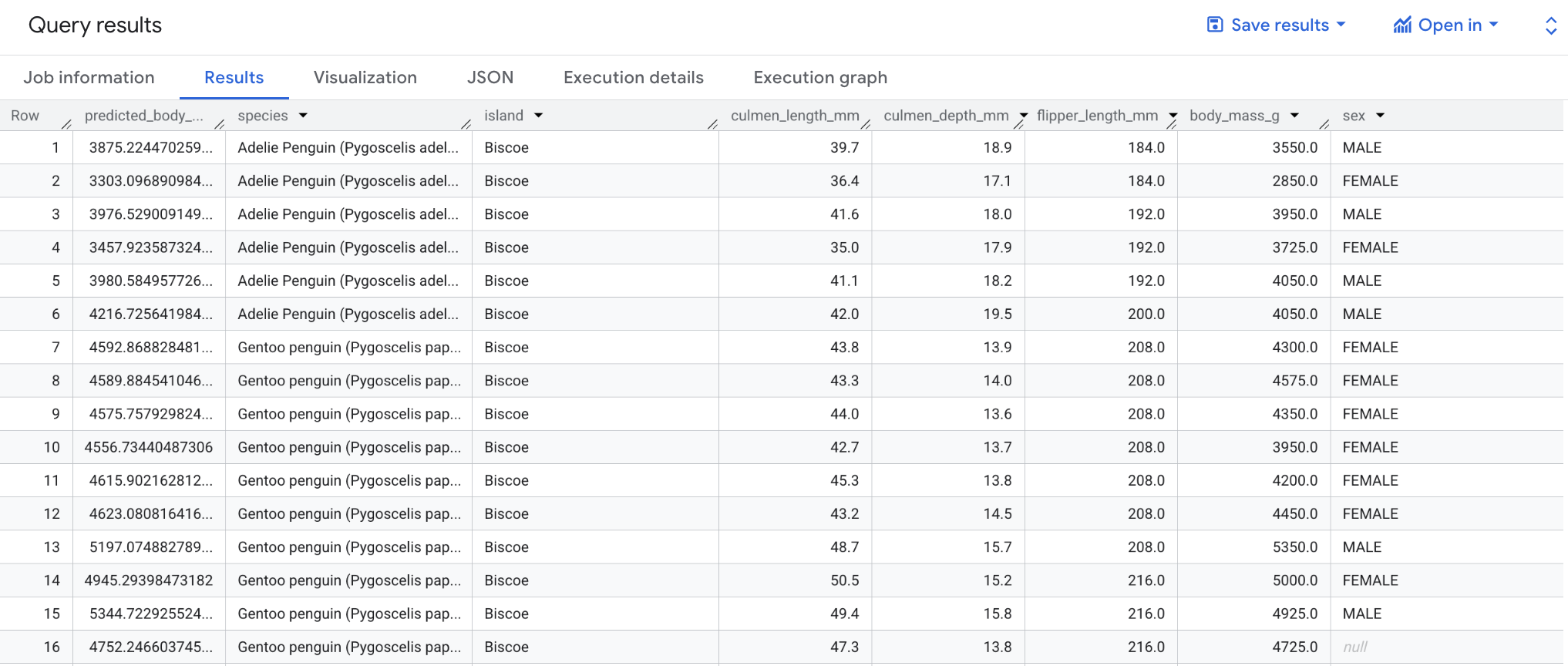
La première instruction SELECT récupère la colonne predicted_body_mass_g avec les colonnes de bigquery-public-data.ml_datasets.penguins. Cette colonne est générée par la fonction ML.PREDICT. Lorsque vous utilisez la fonction ML.PREDICT, le nom de la colonne de sortie du modèle est predicted_<label_column_name>. Pour les modèles de régression linéaire, predicted_label est la valeur estimée de label. Pour les modèles de régression logistique, predicted_label est l'une des deux étiquettes d'entrée, selon celle qui dispose de la probabilité prédite la plus élevée.
La fonction ML.PREDICT sert à prédire les résultats à l'aide de votre modèle bqml_tutorial.penguins_model.
L'instruction SELECT et la clause FROM imbriquées de cette requête sont identiques à celles de la requête CREATE MODEL.
La clause WHERE (WHERE island = "Biscoe") indique que vous limitez la prédiction à l'île de Biscoe.
Exécuter la requête ML.PREDICT
Pour exécuter la requête permettant de prédire un résultat à l'aide votre modèle, procédez comme suit :
Dans la console Cloud, cliquez sur Saisir une nouvelle requête.
Dans la zone de texte de l'éditeur de requête, saisissez la requête SQL standard suivante :
#standardSQL
SELECT
*
FROM
ML.PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"))
(Facultatif) Pour définir l'emplacement des données, cliquez sur Plus > Paramètres de requête. Pour Emplacement des données, sélectionnez us (plusieurs régions aux États-Unis).
Cliquez sur Exécuter.
Lorsque la requête est terminée, cliquez sur l'onglet Résultats sous la zone de texte de la requête. Les résultats doivent se présenter sous la forme suivante :
Tâche 6 : Expliquer les résultats des prédictions avec des méthodes Explainable AI
Pour comprendre pourquoi votre modèle génère ces résultats de prédiction, vous pouvez utiliser la fonction ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT est une version étendue de ML.PREDICT. ML.EXPLAIN_PREDICT renvoie les résultats de la prédiction et fournit des explications dans des colonnes supplémentaires.
Vous pouvez exécuter ML.EXPLAIN_PREDICT sans ML.PREDICT. Pour une explication détaillée des valeurs de Shapley et de Explainable AI dans BigQuery ML, consultez la présentation de Explainable AI pour BigQuery ML.
La requête suivante est utilisée pour générer les explications :
#standardSQL
SELECT
*
FROM
ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"),
STRUCT(3 as top_k_features))
Détails de la requête
Exécuter la requête ML.EXPLAIN_PREDICT
Pour exécuter la requête ML.EXPLAIN_PREDICT qui explique le modèle, procédez comme suit :
Dans la console Cloud, cliquez sur Saisir une nouvelle requête.
Dans la zone de texte de l'éditeur de requête, saisissez la requête SQL standard suivante :
#standardSQL
SELECT
*
FROM
ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"),
STRUCT(3 as top_k_features))
Cliquez sur Exécuter.
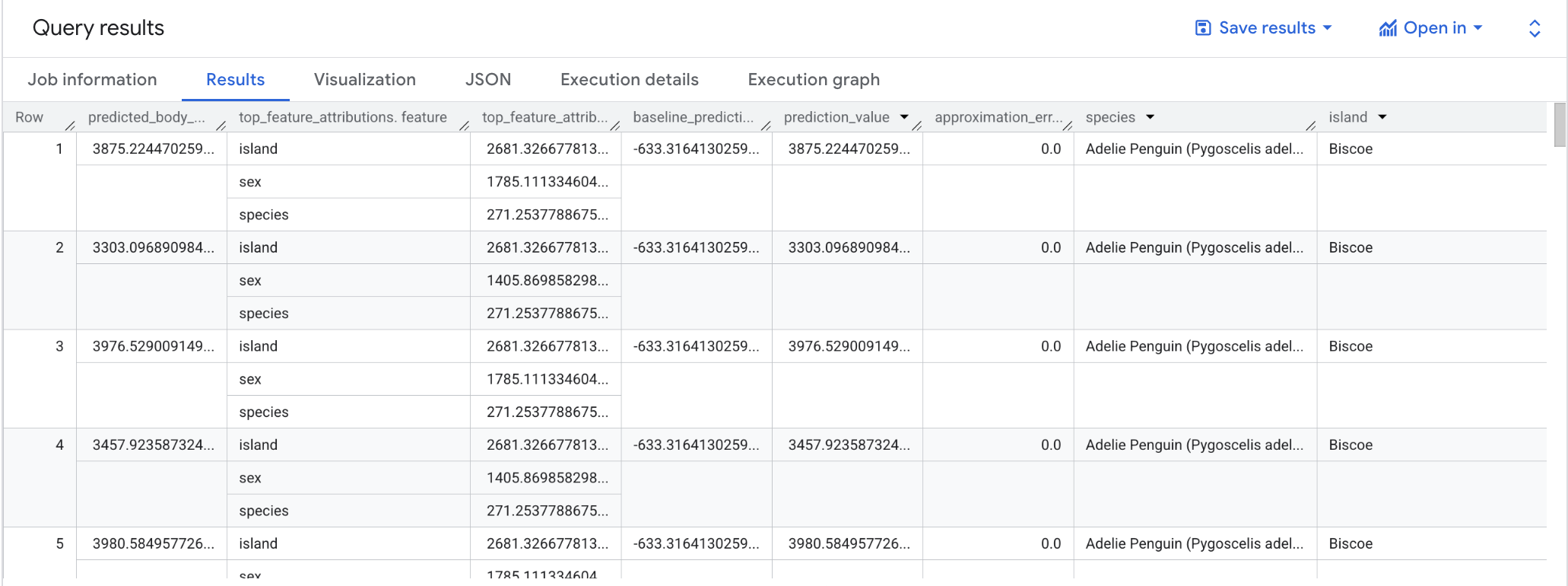
Lorsque la requête est terminée, cliquez sur l'onglet Résultats sous la zone de texte de la requête. Les résultats doivent se présenter sous la forme suivante :
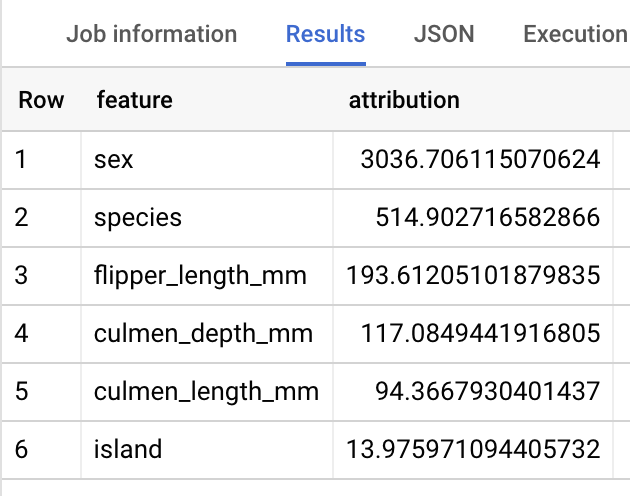
Remarque : Tout comme la fonction ML.PREDICT, la requête ML.EXPLAIN_PREDICT génère toutes les colonnes de caractéristiques d'entrée. Pour des raisons de lisibilité, la figure ci-dessus ne montre qu'une seule colonne de caractéristiques, "species".
Pour les modèles de régression linéaire, les valeurs de Shapley permettent de générer les valeurs d'attribution des caractéristiques par caractéristique du modèle. ML.EXPLAIN_PREDICT génère les trois premières attributions de caractéristiques par ligne de la table fournie, car top_k_features a été défini sur 3 dans la requête.
Ces attributions sont triées en fonction de la valeur absolue de l'attribution par ordre décroissant. Dans tous les exemples, la caractéristique sex a le plus contribué à la prédiction globale. Pour obtenir des explications détaillées sur les colonnes de sortie de la requête ML.EXPLAIN_PREDICT, consultez la documentation sur la syntaxe de ML.EXPLAIN_PREDICT.
Afin d'identifier les caractéristiques les plus importantes pour déterminer le poids des manchots en général, vous pouvez utiliser la fonction ML.GLOBAL_EXPLAIN. Si vous souhaitez utiliser ML.GLOBAL_EXPLAIN, le modèle doit être entraîné une nouvelle fois, avec l'option ENABLE_GLOBAL_EXPLAIN=TRUE.
Exécutez à nouveau la requête d'entraînement avec cette option à l'aide de la requête suivante :
#standardSQL
CREATE OR REPLACE MODEL bqml_tutorial.penguins_model
OPTIONS
(model_type='linear_reg',
input_label_cols=['body_mass_g'],
enable_global_explain=TRUE) AS
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
Remarque : Vous pouvez ignorer l'avertissement concernant les valeurs NULL pour les données d'entrée.
Accéder à des explications globales via ML.GLOBAL_EXPLAIN
La requête suivante est utilisée pour générer les explications globales :
#standardSQL
SELECT
*
FROM
ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
Détails de la requête
Exécuter la requête ML.GLOBAL_EXPLAIN
Pour exécuter la requête ML.GLOBAL_EXPLAIN, procédez comme suit :
Dans la console Cloud, cliquez sur Saisir une nouvelle requête.
Dans la zone de texte de l'éditeur de requête, saisissez la requête SQL standard suivante :
#standardSQL
SELECT
*
FROM
ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
(Facultatif) Pour définir l'emplacement des données, cliquez sur Plus > Paramètres de requête. Pour Emplacement des données, sélectionnez us (plusieurs régions aux États-Unis).
Cliquez sur Exécuter.
Lorsque la requête est terminée, cliquez sur l'onglet Résultats sous la zone de texte de la requête. Les résultats doivent se présenter sous la forme suivante :
Tâche 8 : Effectuer un nettoyage
Pour éviter que les ressources utilisées dans le cadre de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Supprimer l'ensemble de données
Si vous supprimez votre projet, tous les ensembles de données et toutes les tables qui lui sont associés sont également supprimés. Si vous préférez réutiliser le projet, vous pouvez supprimer l'ensemble de données que vous avez créé dans ce tutoriel :
Si nécessaire, ouvrez la page BigQuery dans la console Cloud.
Dans le panneau Explorateur, cliquez sur l'icône Afficher les actions () située à côté de votre ensemble de données.
Cliquez sur Supprimer.
Dans la boîte de dialogue "Supprimer l'ensemble de données", saisissez supprimer pour confirmer la suppression de cet ensemble, puis cliquez sur Supprimer.
Supprimer le projet
Pour supprimer le projet :
Dans le menu de navigation de la console Cloud, cliquez sur IAM et administration > Gérer les ressources.
Remarque : Si le message "Travail non enregistré" s'affiche, cliquez sur QUITTER.
Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Félicitations !
Vous avez appris à effectuer les tâches suivantes :
Créer un modèle de régression linéaire à l'aide de l'instruction CREATE MODEL avec BigQuery ML
Évaluer le modèle de ML grâce à la fonction ML.EVALUATE
Effectuer des prédictions à l'aide du modèle de ML avec la fonction ML.PREDICT
Pour obtenir plus d'informations sur BigQuery ML, consultez la page de présentation de BigQuery ML.
Pour en savoir plus sur la console Cloud, consultez la page expliquant comment utiliser la console Cloud.
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur End Lab (Terminer l'atelier). Qwiklabs supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez le nombre d'étoiles correspondant à votre note, saisissez un commentaire, puis cliquez sur Submit (Envoyer).
Le nombre d'étoiles que vous pouvez attribuer à un atelier correspond à votre degré de satisfaction :
1 étoile = très mécontent(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez utiliser l'onglet Support (Assistance).
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Le meilleur moyen d'exécuter cet atelier consiste à utiliser une fenêtre de navigation privée. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Dans cet atelier, vous allez apprendre à créer et exécuter des modèles de machine learning dans BigQuery à l'aide de requêtes SQL.
Durée :
0 min de configuration
·
Accessible pendant 120 min
·
Terminé après 120 min

 ) de la console Cloud, cliquez sur API et services > Bibliothèque.
) de la console Cloud, cliquez sur API et services > Bibliothèque.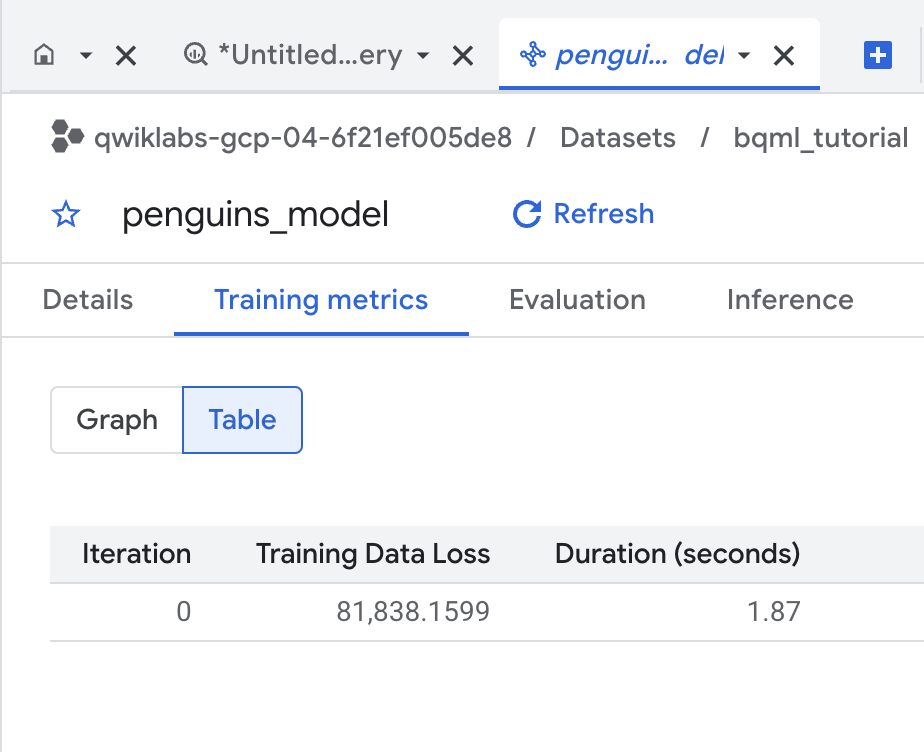

 ) située à côté de votre ensemble de données.
) située à côté de votre ensemble de données.




