Este contenido aún no está optimizado para dispositivos móviles.
Para obtener la mejor experiencia, visítanos en una computadora de escritorio con un vínculo que te enviaremos por correo electrónico.
Descripción general
En este lab, usarás la tabla de pingüinos para crear un modelo que prediga el peso de uno de ellos según su especie, la isla donde vive, la longitud y profundidad del culmen o parte superior del pico, la longitud de sus aletas y su sexo.
Este es un lab de introducción a BigQuery ML para analistas de datos. BigQuery ML permite a los usuarios crear y ejecutar modelos de aprendizaje automático en BigQuery con consultas en SQL. El objetivo es permitir que más personas tengan acceso al aprendizaje automático facultando a los profesionales de SQL para que creen modelos mediante sus herramientas existentes y quitando la necesidad de trasladar datos para aumentar la velocidad de desarrollo.
Objetivos de aprendizaje
Crear un modelo de regresión lineal usando la instrucción CREATE MODEL con BigQuery ML
Evaluar el modelo de AA con la función ML.EVALUATE
Hacer predicciones con el modelo de AA a través de la función ML.PREDICT
Configuración
En cada lab, recibirás un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
Accede a Google Skills en una ventana de incógnito.
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 1:15:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesitas, puedes reiniciar el lab, pero deberás hacerlo desde el comienzo.
Cuando esté listo, haga clic en Comenzar lab.
Anote las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
Haga clic en Abrir Google Console.
Haga clic en Usar otra cuenta, copie las credenciales para este lab y péguelas en el mensaje emergente que aparece.
Si usas otras credenciales, se generarán errores o incurrirás en cargos.
Acepta las condiciones y omite la página de recursos de recuperación.
Habilita la API de BigQuery
En el Menú de navegación () de la consola de Cloud, haz clic en APIs y servicios > Biblioteca.
Busca la API de BigQuery y, luego, haz clic en Habilitar si aún no está habilitada.
Tarea 1: Crea el conjunto de datos
El primer paso es crear un conjunto de datos de BigQuery en el que se almacenará el modelo de AA. Para crear el conjunto de datos, haz lo siguiente:
En la consola de Cloud, ve a Menú de navegación y haz clic en BigQuery.
En el panel Explorador, haz clic en el ícono de Ver acciones (los tres puntos verticales) que se encuentra junto al ID del proyecto y, luego, en Crear conjunto de datos.
Haz lo siguiente en la página Crear conjunto de datos:
En ID de conjunto de datos, escribe bqml_tutorial.
Selecciona US (multiple regions in United States) en Ubicación de los datos (opcional).
Actualmente, los conjuntos de datos públicos se almacenan en la ubicación multirregional de EE.UU. Para que sea más simple, debes colocar el conjunto de datos en la misma ubicación.
Deja el resto de la configuración con sus valores predeterminados y haz clic en Crear conjunto de datos.
Tarea 2: Crea tu modelo
A continuación, debes crear un modelo de regresión lineal con la tabla de pingüinos para BigQuery.
Con la siguiente consulta en SQL estándar, se crea el modelo que debes usar para predecir el peso de un pingüino:
#standardSQL
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model`
OPTIONS
(model_type='linear_reg',
input_label_cols=['body_mass_g']) AS
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
Además de crear el modelo, el comando CREATE MODEL también lo entrena.
Detalles de la consulta
La cláusula CREATE MODEL se usa para crear y entrenar el modelo llamado bqml_tutorial.penguins_model.
La cláusula OPTIONS(model_type='linear_reg', input_label_cols=['body_mass_g']) indica que estás creando un modelo de regresión lineal. Una regresión lineal es un tipo de modelo de regresión que genera un valor continuo a partir de una combinación lineal de atributos de entrada. La columna body_mass_g es la columna de la etiqueta de entrada. Para los modelos de regresión lineal, la columna de la etiqueta debe tener un valor real (sus valores deben ser números reales).
La instrucción SELECT de esta consulta utiliza todas las columnas de la tabla bigquery-public-data.ml_datasets.penguins. Esta tabla contiene las siguientes columnas que se usarán para predecir el peso de un pingüino:
species: La especie del pingüino (STRING)
island: La isla donde vive el pingüino (STRING)
culmen_length_mm: La longitud de su culmen en milímetros (FLOAT64)
culmen_depth_mm: La profundidad de su culmen en milímetros (FLOAT64)
flipper_length_mm: La longitud de las aletas en milímetros (FLOAT64)
sex: El sexo del pingüino (STRING)
La cláusula FROM — bigquery-public-data.ml_datasets.penguins indica que consultas la tabla de pingüinos en el conjunto de datos ml_datasets. Este conjunto de datos está en el proyecto bigquery-public-data.
La cláusula WHERE (WHERE body_mass_g IS NOT NULL) excluye las filas en las que body_mass_g tiene el valor NULL.
Ejecuta la consulta CREATE MODEL
Sigue estos pasos para ejecutar la consulta CREATE MODEL y crear y entrenar el modelo:
En la consola de Cloud, haz clic en Redactar consulta nueva.
En el área de texto del Editor de consultas, ingresa la siguiente consulta en SQL estándar:
#standardSQL
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model`
OPTIONS
(model_type='linear_reg',
input_label_cols=['body_mass_g']) AS
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
Haz clic en Ejecutar.
La consulta tarda unos 30 segundos en completarse; luego, el modelo (penguins_model) aparecerá en el panel de navegación. Debido a que en la consulta se usa una sentencia CREATE MODEL para crear una tabla, no se muestran los resultados.
Nota: Puedes ignorar la advertencia sobre los valores NULL para los datos de entrada.
Tarea 3. Obtén estadísticas de entrenamiento (opcional)
Para ver los resultados del entrenamiento de modelos, puedes usar la función ML.TRAINING_INFO o ver las estadísticas en la consola de Cloud. En este instructivo, usarás la consola de Cloud.
Para crear un modelo, los algoritmos de aprendizaje automático examinan muchos ejemplos y buscan un modelo que minimice la pérdida. Este proceso se llama minimización del riesgo empírico.
La pérdida es la penalización de una mala predicción, un número que indica qué tan mala fue la predicción del modelo en un ejemplo individual. Si la predicción del modelo es perfecta, la pérdida es cero; de lo contrario, es mayor. El objetivo de entrenar un modelo es encontrar un conjunto de pesos y sesgos que tengan, en promedio, una pérdida baja en todos los ejemplos.
Para ver las estadísticas de entrenamiento del modelo que se generaron cuando se ejecutó la consulta CREATE MODEL, haz lo siguiente:
En la sección Explorador del panel de navegación de la consola de Cloud, expande [PROJECT_ID] > bqml_tutorial > Modelos (1) y, luego, haz clic en penguins_model.
Haz clic en la pestaña Entrenamiento y, luego, en Tabla. Los resultados deberían verse así:
La columna Pérdida de datos de entrenamiento representa la métrica de pérdida calculada después de que se entrena el modelo en el conjunto de datos de entrenamiento. Debido a que realizaste una regresión lineal, esta columna es el error cuadrático medio.
Se utiliza automáticamente una estrategia de optimización “normal_equation” para este entrenamiento, por lo que solo se requiere una iteración para converger en el modelo final. Para obtener más detalles sobre la opción optimize_strategy, consulta la instrucción CREATE MODEL para modelos lineales generalizados.
Para obtener más detalles sobre la función ML.TRAINING_INFO y la opción de entrenamiento "optimize_strategy", consulta la referencia de sintaxis de BigQuery ML.
Tarea 4: Evalúa tu modelo
Después de crear el modelo, debes evaluar su rendimiento con la función ML.EVALUATE. La función ML.EVALUATE compara los valores predichos con los datos reales.
La siguiente consulta se usa para evaluar el modelo:
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL))
Detalles de la consulta
Con la primera instrucción SELECT, se recuperan las columnas del modelo.
La cláusula FROM utiliza la función ML.EVALUATE para evaluar el modelo: bqml_tutorial.penguins_model.
La sentencia SELECT anidada y la cláusula FROM de esta consulta son las mismas de la consulta CREATE MODEL.
La cláusula WHERE (WHERE body_mass_g IS NOT NULL) excluye las filas en las que body_mass_g tiene el valor NULL.
Una evaluación adecuada debería encontrarse en un subconjunto de la tabla de pingüinos que esté separado de los datos usados para entrenar el modelo. También puedes llamar a ML.EVALUATE sin proporcionar los datos de entrada. ML.EVALUATE recuperará las métricas de evaluación calculadas durante el entrenamiento, que usa el conjunto de datos de evaluación reservado de forma automática:
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`)
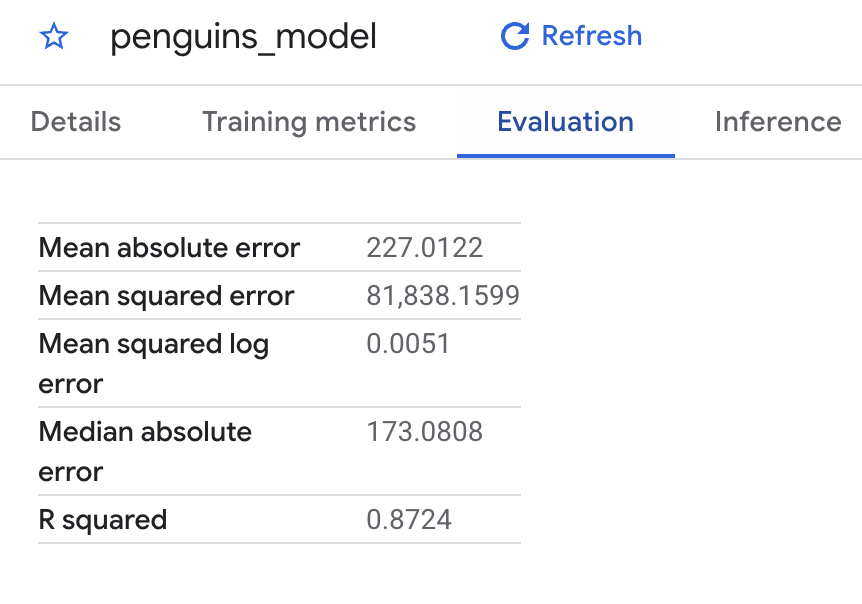
También puedes usar la consola de Cloud para ver las métricas de evaluación calculadas durante el entrenamiento. Los resultados deberían verse así:
Ejecuta la consulta ML.EVALUATE
Para ejecutar la consulta ML.EVALUATE que evalúa el modelo, haz lo siguiente:
En la consola de Cloud, haz clic en Redactar consulta nueva.
En el área de texto del Editor de consultas, ingresa la siguiente consulta en SQL estándar:
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL))
Para configurar la ubicación de los datos, haz clic en Más > Configuración de consulta (opcional). Selecciona US (multiple regions in United States) en Ubicación de los datos (opcional).
Haz clic en Ejecutar.
Cuando la consulta finalice, haz clic en la pestaña Resultados debajo del área de texto de la consulta. Los resultados deberían verse así:
Debido a que realizaste una regresión lineal, los resultados incluyen las siguientes columnas:
mean_absolute_error
mean_squared_error
mean_squared_log_error
median_absolute_error
r2_score
explained_variance
Una métrica importante en los resultados de la evaluación es la puntuación R2. La puntuación R2 es una medida estadística que determina si las predicciones de regresión lineal se aproximan a los datos reales. 0 indica que el modelo no explica la variabilidad de los datos de respuesta en torno a la media. 1 indica que el modelo explica toda la variabilidad de los datos de respuesta en torno a la media.
Tarea 5. Usa el modelo para predecir resultados
Ahora que ya evaluaste tu modelo, el siguiente paso es usarlo para predecir un resultado. Úsalo para predecir la masa corporal en gramos de todos los pingüinos que viven en las islas Biscoe.
La siguiente consulta se usa para predecir el resultado:
#standardSQL
SELECT
*
FROM
ML.PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"))
Detalles de la consulta
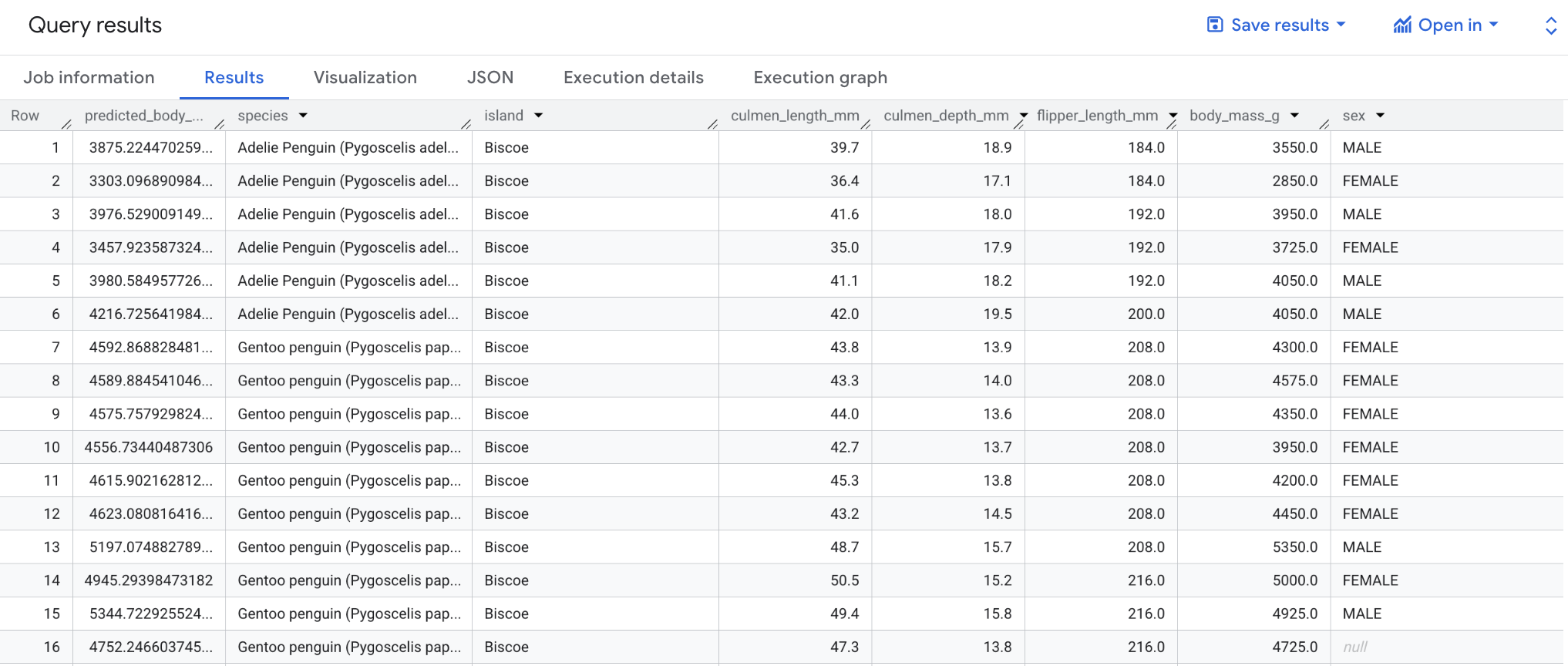
Con la primera sentencia SELECT, se recupera la columna predicted_body_mass_g y las columnas de bigquery-public-data.ml_datasets.penguins. Esta columna se genera con la función ML.PREDICT. Cuando usas la función ML.PREDICT, el nombre de la columna de resultado será predicted_<label_column_name>. Para los modelos de regresión lineal, predicted_label es el valor estimado de label. Para los modelos de regresión logística, predicted_label es una de las dos etiquetas de entrada, según la que tenga la mayor probabilidad predicha.
La función ML.PREDICT se usa para predecir resultados con tu modelo: bqml_tutorial.penguins_model.
La instrucción SELECT anidada y la cláusula FROM de esta consulta son las mismas de la consulta CREATE MODEL.
La cláusula WHERE (WHERE island = "Biscoe") indica que limitas la predicción a las islas Biscoe.
Ejecuta la consulta ML.PREDICT
Para ejecutar la consulta que usa el modelo y predecir un resultado, haz lo siguiente:
En la consola de Cloud, haz clic en Redactar consulta nueva.
En el área de texto del Editor de consultas, ingresa la siguiente consulta en SQL estándar:
#standardSQL
SELECT
*
FROM
ML.PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"))
Para configurar la ubicación de los datos, haz clic en Más > Configuración de consulta (opcional). Selecciona US (multiple regions in United States) en Ubicación de los datos (opcional).
Haz clic en Ejecutar.
Cuando la consulta finalice, haz clic en la pestaña Resultados debajo del área de texto de la consulta. Los resultados deberían verse así:
Tarea 6: Explica los resultados de la predicción con los métodos de Explainable AI
Para comprender por qué el modelo genera estos resultados de predicción, puedes usar la función ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT es una versión ampliada de ML.PREDICT. ML.EXPLAIN_PREDICT muestra resultados de predicción con columnas adicionales que explican esos resultados.
Puedes ejecutar ML.EXPLAIN_PREDICT sin ML.PREDICT. Para obtener una explicación detallada de los valores de Shapley y Explainable AI en BigQuery ML, consulta la descripción general de Explainable AI para BigQuery ML.
Se usa la siguiente consulta para generar explicaciones:
#standardSQL
SELECT
*
FROM
ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"),
STRUCT(3 as top_k_features))
Detalles de la consulta
Ejecuta la consulta ML.EXPLAIN_PREDICT
Haz lo siguiente para ejecutar la consulta ML.EXPLAIN_PREDICT que explica el modelo:
En la consola de Cloud, haz clic en Redactar consulta nueva.
En el área de texto del Editor de consultas, ingresa la siguiente consulta en SQL estándar:
#standardSQL
SELECT
*
FROM
ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"),
STRUCT(3 as top_k_features))
Haz clic en Ejecutar.
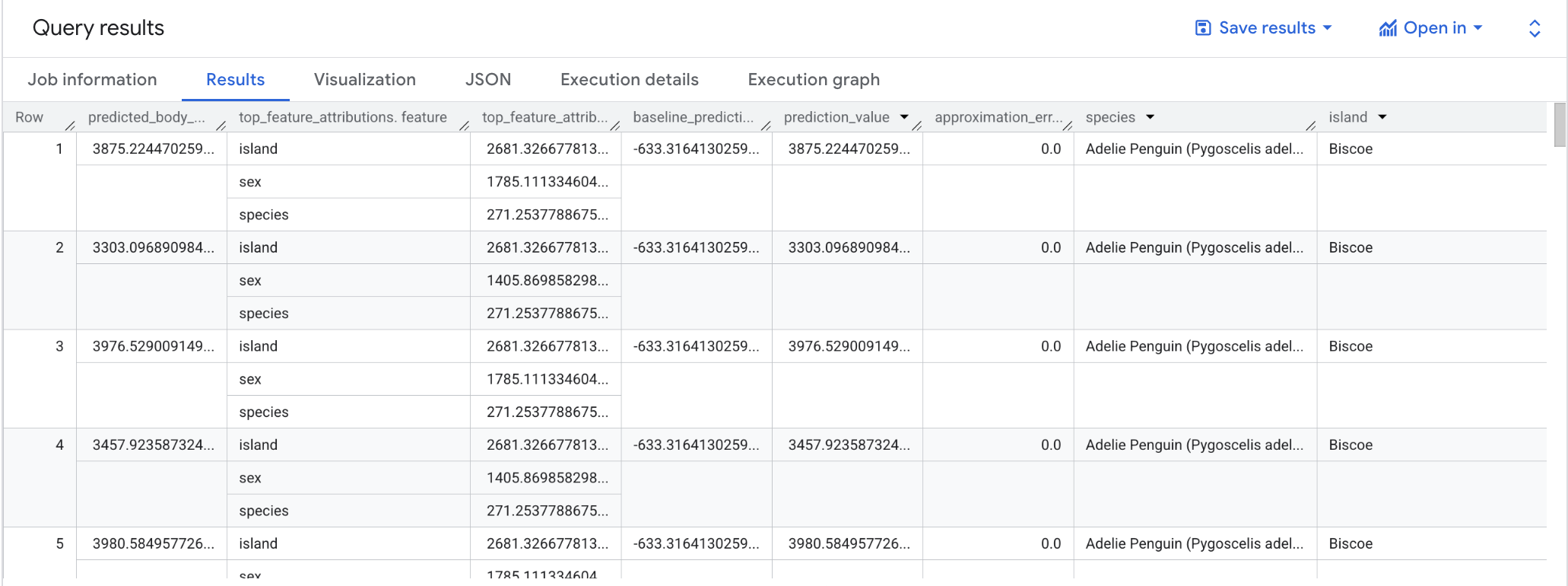
Cuando la consulta finalice, haz clic en la pestaña Resultados debajo del área de texto de la consulta. Los resultados deberían verse así:
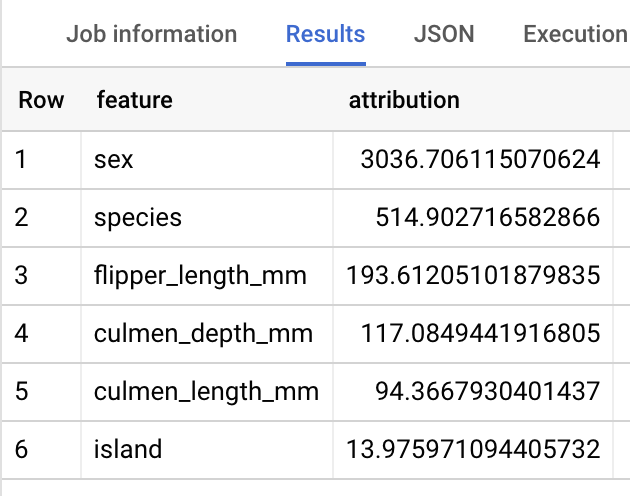
Nota: La consulta ML.EXPLAIN_PREDICT genera todas las columnas de atributos de entrada, de una manera similar a la de ML.PREDICT. Solo se muestra una columna de atributos, “species” en la figura anterior para fines de legibilidad.
Para los modelos de regresión lineal, los valores de Shapley se usan para generar valores de atribución de atributos por cada atributo del modelo. ML.EXPLAIN_PREDICT muestra las 3 atribuciones principales por cada fila de la tabla proporcionada porque top_k_features se estableció como 3 en la consulta.
Estas atribuciones se ordenan por el valor absoluto de la atribución en orden descendente. En todos los ejemplos, el atributo sex fue el que más contribuyó a la predicción general. Para obtener explicaciones detalladas sobre las columnas de resultado de la consulta ML.EXPLAIN_PREDICT, consulta la documentación de la sintaxis de ML.EXPLAIN_PREDICT
Tarea 7: Explica el modelo de forma global (opcional)
Para saber qué características son las más importantes a la hora de determinar los pesos de los pingüinos en general, puedes usar la función ML.GLOBAL_EXPLAIN. Para usar ML.GLOBAL_EXPLAIN, el modelo debe volver a entrenarse con la opción ENABLE_GLOBAL_EXPLAIN=TRUE.
Vuelve a ejecutar la consulta de entrenamiento con esta opción a través de la siguiente consulta:
#standardSQL
CREATE OR REPLACE MODEL bqml_tutorial.penguins_model
OPTIONS
(model_type='linear_reg',
input_label_cols=['body_mass_g'],
enable_global_explain=TRUE) AS
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
Nota: Puedes ignorar la advertencia sobre los valores NULL para los datos de entrada.
Accede a explicaciones globales a través de ML.GLOBAL_EXPLAIN
Se usa la siguiente consulta para generar explicaciones globales:
#standardSQL
SELECT
*
FROM
ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
Detalles de la consulta
Ejecuta la consulta ML.GLOBAL_EXPLAIN
Haz lo siguiente para ejecutar la consulta ML.GLOBAL_EXPLAIN:
En la consola de Cloud, haz clic en Redactar consulta nueva.
En el área de texto del Editor de consultas, ingresa la siguiente consulta en SQL estándar:
#standardSQL
SELECT
*
FROM
ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
Para configurar la ubicación de los datos, haz clic en Más > Configuración de consulta (opcional). Selecciona US (multiple regions in United States) en Ubicación de los datos (opcional).
Haz clic en Ejecutar.
Cuando la consulta finalice, haz clic en la pestaña Resultados debajo del área de texto de la consulta. Los resultados deberían verse así:
Tarea 8. Realiza una limpieza
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra el conjunto de datos
Borrar el proyecto quita todos tus conjuntos de datos y tablas. Si prefieres volver a usar el proyecto, puedes borrar el conjunto de datos que creaste en este instructivo:
Si es necesario, abre la página de BigQuery en la consola de Cloud.
En el panel Explorador, haz clic en Ver acciones () que se encuentra junto a tu conjunto de datos.
Haz clic en Borrar.
En el cuadro de diálogo Borrar conjunto de datos, escribe delete y, luego, haz clic en Borrar.
Borra tu proyecto
Para borrar el proyecto, haz lo siguiente:
En el menú de navegación de la consola de Cloud, haz clic en IAM y administración > Administrar recursos.
Nota: Si se te solicita, haz clic en SALIR en el diálogo Trabajo sin guardar.
En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrarlo.
¡Felicitaciones!
Aprendiste a hacer lo siguiente:
Crear un modelo de regresión lineal mediante la instrucción CREATE MODEL con BigQuery ML
Evaluar el modelo de AA con la función ML.EVALUATE
Hacer predicciones con el modelo de AA usando la función ML.PREDICT
Cuando haya completado su lab, haga clic en Finalizar lab. Qwiklabs quitará los recursos que usó y limpiará la cuenta por usted.
Tendrá la oportunidad de calificar su experiencia en el lab. Seleccione la cantidad de estrellas que corresponda, ingrese un comentario y haga clic en Enviar.
La cantidad de estrellas indica lo siguiente:
1 estrella = Muy insatisfecho
2 estrellas = Insatisfecho
3 estrellas = Neutral
4 estrellas = Satisfecho
5 estrellas = Muy satisfecho
Puede cerrar el cuadro de diálogo si no desea proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, use la pestaña Asistencia.
Copyright 2026 Google LLC. Todos los derechos reservados. Google y el logotipo de Google son marcas de Google LLC. El resto de los nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que están asociados.
Los labs crean un proyecto de Google Cloud y recursos por un tiempo determinado
.
Los labs tienen un límite de tiempo y no tienen la función de pausa. Si finalizas el lab, deberás reiniciarlo desde el principio.
En la parte superior izquierda de la pantalla, haz clic en Comenzar lab para empezar
Usa la navegación privada
Copia el nombre de usuario y la contraseña proporcionados para el lab
Haz clic en Abrir la consola en modo privado
Accede a la consola
Accede con tus credenciales del lab. Si usas otras credenciales, se generarán errores o se incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación
No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo, ya que se borrará tu trabajo y se quitará el proyecto
Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible
¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible
Un lab a la vez
Confirma para finalizar todos los labs existentes y comenzar este
Usa la navegación privada para ejecutar el lab
Usar una ventana de incógnito o de navegación privada es la mejor forma de ejecutar
este lab. Así evitarás cualquier conflicto entre tu cuenta personal
y la cuenta de estudiante, lo que podría generar cargos adicionales en
tu cuenta personal.
En este lab, aprenderás a crear y ejecutar modelos de aprendizaje automático en BigQuery con consultas en SQL.
Duración:
0 min de configuración
·
Acceso por 120 min
·
120 min para completar

 ) de la consola de Cloud, haz clic en APIs y servicios > Biblioteca.
) de la consola de Cloud, haz clic en APIs y servicios > Biblioteca.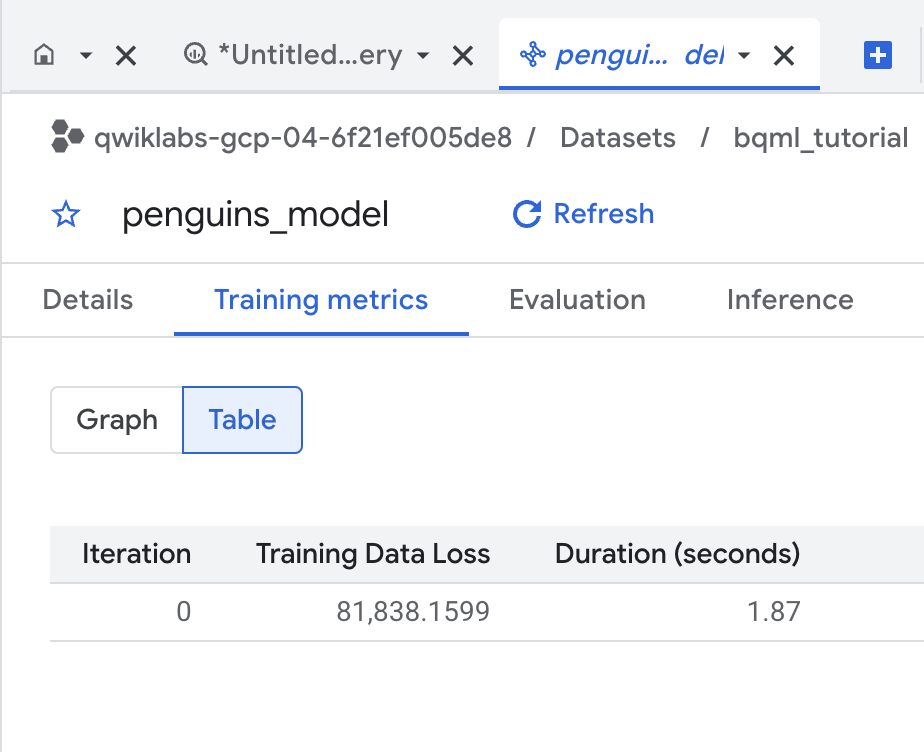

 ) que se encuentra junto a tu conjunto de datos.
) que se encuentra junto a tu conjunto de datos.




