



시작하기 전에
- 실습에서는 정해진 기간 동안 Google Cloud 프로젝트와 리소스를 만듭니다.
- 실습에는 시간 제한이 있으며 일시중지 기능이 없습니다. 실습을 종료하면 처음부터 다시 시작해야 합니다.
- 화면 왼쪽 상단에서 실습 시작을 클릭하여 시작합니다.
Create a training dataset
/ 5
Improving the model through feature engineering
/ 5
Make predictions
/ 5
Examine model weights
/ 5
Create a training dataset
/ 5
Improving the model through feature engineering
/ 5
Make predictions
/ 5
Examine model weights
/ 5
BigQuery는 Google의 완전 관리형, 노옵스(NoOps), 저비용 분석 데이터베이스입니다. BigQuery를 사용하면 관리할 인프라나 데이터베이스 관리자가 없어도 테라바이트 단위의 대규모 데이터를 쿼리할 수 있습니다. BigQuery는 SQL을 사용하므로 사용한 만큼만 지불하는 모델의 장점을 활용할 수 있습니다. BigQuery는 데이터를 분석하여 의미 있고 유용한 정보를 찾는 데 집중할 수 있게 해줍니다.
BigQuery 머신러닝은 데이터 분석가가 최소한의 코딩으로 머신러닝 모델을 만들고, 학습시키고, 평가하며, 이를 통해 예측할 수 있도록 해주는 BigQuery의 기능입니다.
이 실습에서는 런던의 자전거 데이터 세트로 BigQuery ML에서 회귀 모델을 빌드하여 자전거 여행 시간을 예측합니다. 두 가지 종류의 자전거(튼튼한 통근용 자전거와 빠르지만 취약한 로드 바이크)를 보유하고 있는 자전거 대여업체를 운영 중이라고 가정해 보겠습니다. 자전거 대여 시간이 길어질 가능성이 높으면 로드 바이크의 재고가 있어야 하지만, 대여 시간이 짧을 것 같은 경우에는 통근용 자전거의 재고가 있어야 합니다. 따라서 자전거의 재고를 적절하게 유지할 수 있는 시스템을 빌드하기 위해서는 자전거 대여 시간을 예측해야 합니다.
이 실습에서는 다음 작업을 수행하는 방법에 대해 알아봅니다.
각 실습에서는 정해진 기간 동안 새 Google Cloud 프로젝트와 리소스 집합이 무료로 제공됩니다.
시크릿 창을 사용하여 Qwiklabs에 로그인합니다.
실습 사용 가능 시간(예: 1:15:00)을 참고하여 해당 시간 내에 완료합니다.
일시중지 기능은 없습니다. 필요한 경우 다시 시작할 수 있지만 처음부터 시작해야 합니다.
준비가 되면 실습 시작을 클릭합니다.
실습 사용자 인증 정보(사용자 이름 및 비밀번호)를 기록해 두세요. Google Cloud Console에 로그인합니다.
Google Console 열기를 클릭합니다.
다른 계정 사용을 클릭한 다음, 안내 메시지에 이 실습에 대한 사용자 인증 정보를 복사하여 붙여넣습니다.
다른 사용자 인증 정보를 사용하는 경우 오류가 발생하거나 요금이 부과됩니다.
약관에 동의하고 리소스 복구 페이지를 건너뜁니다.
Cloud Console의 BigQuery에 오신 것을 환영합니다라는 메시지 상자가 열립니다. 이 메시지 상자에서는 빠른 시작 가이드 링크 및 UI 업데이트 목록을 확인할 수 있습니다.
ML 문제를 해결하는 첫 번째 단계는 모델과 라벨의 특성을 파악하여 문제를 체계적으로 정리하는 것입니다. 첫 번째 모델의 목표는 자전거 대여의 과거 데이터 세트를 바탕으로 대여 시간을 예측하는 것이므로 라벨은 대여 시간입니다.
자전거를 대여하는 역, 요일, 시간에 따라 대여 시간이 달라질 수 있다고 판단된다면 해당 역, 요일, 시간은 특성이 될 수 있습니다. 하지만 이러한 특성을 사용하여 모델을 만들기 전에 이러한 요소가 라벨에 영향을 미치는지 확인하는 것이 좋습니다.
머신러닝 모델에 필요한 특성을 찾아내는 것을 특성 추출이라고 합니다. 특성 추출이 정확한 ML 모델을 빌드하는 데 가장 중요한 부분인 경우가 많으며, 사용할 알고리즘을 결정하거나 초매개변수를 조정하는 것보다 훨씬 더 효과적일 수 있습니다. 우수한 특성 추출을 위해서는 데이터와 도메인에 대한 깊은 이해가 필요합니다. 이는 가설 테스트의 과정인 경우가 많으며, 어떤 특성을 생각하여 이 특성이 잘 작동하는지(라벨과 상호 정보가 있는지) 확인한 다음 모델에 추가합니다. 올바르게 작동하지 않는 경우 다른 특성으로 시도해 보세요.
Looker Studio로 다음 쿼리 결과를 시각화하여 대여 시간이 역마다 다른지 확인할 수 있습니다.
막대 그래프: 세로 막대 그래프
막대: 100
축: 축 표시
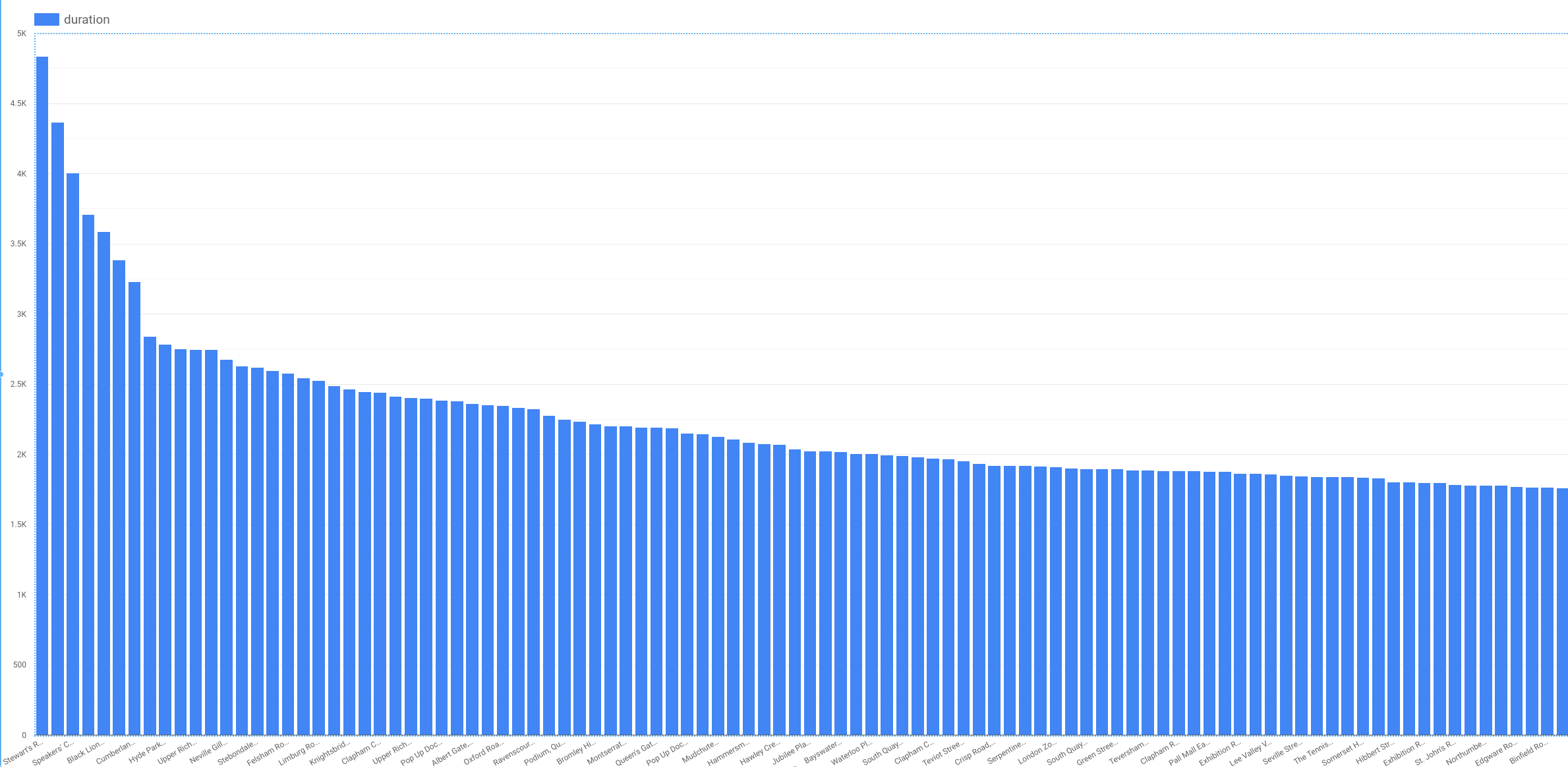
플롯은 다음과 유사합니다.
일부 역에서 장기 대여(3,000초 이상)가 가능하기는 하지만, 대부분의 역에서는 대여 시간이 비교적 짧습니다. 런던의 모든 역에서의 대여 시간이 짧았다면 대여를 시작한 역은 좋은 특성이 아니었을 것입니다. 하지만 그래프에서 알 수 있듯이 이 문제에서는 start_station_name이 중요합니다.
다음 후보 특성의 경우 프로세스는 유사합니다. dayofweek(또는 마찬가지로 hourofday)가 중요한지 확인할 수 있습니다.
duration 및 dayofweek 데이터가 포함된 테이블을 클릭합니다.
설정 > 측정항목에서 dayofweek 위로 마우스를 가져간 다음 수정 연필 아이콘을 클릭합니다.
표시 형식 드롭다운에서 주 수를 클릭한 다음 커스텀 날짜 형식을 선택합니다.
커스텀 날짜를 '일'로 변경한 다음 적용을 클릭합니다. 이제 그래프에서 dayofweek 필드에 1일 차부터 7일 차까지 표시됩니다.
시스템 오류가 표시된 차트를 클릭합니다.
설정 > 측정기준에서 Duration을 클릭하고 dayofweek로 변경합니다.
설정 > 측정기준에서 dayofweek 위로 마우스를 가져간 다음 수정 연필 아이콘을 클릭합니다.
표시 형식 드롭다운에서 커스텀 날짜 형식을 선택하고 커스텀 날짜를 '일'로 변경합니다. 그런 다음 적용을 클릭합니다.
설정 > 측정항목에서 dayofweek를 클릭하고 duration으로 변경합니다.
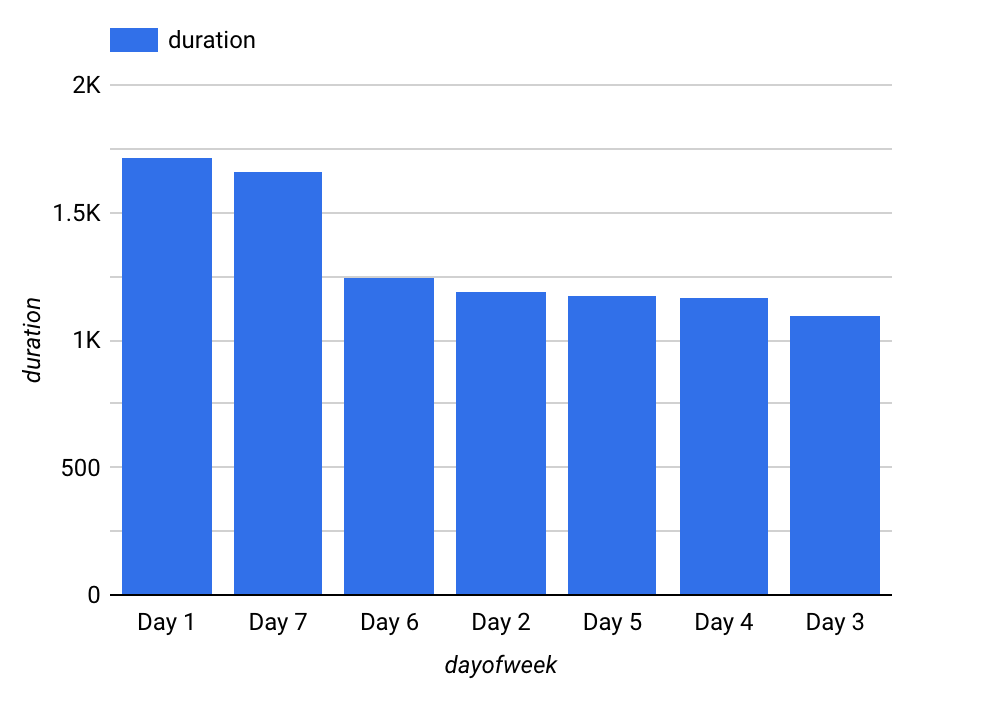
요일별로 시각화하면 다음과 유사합니다.
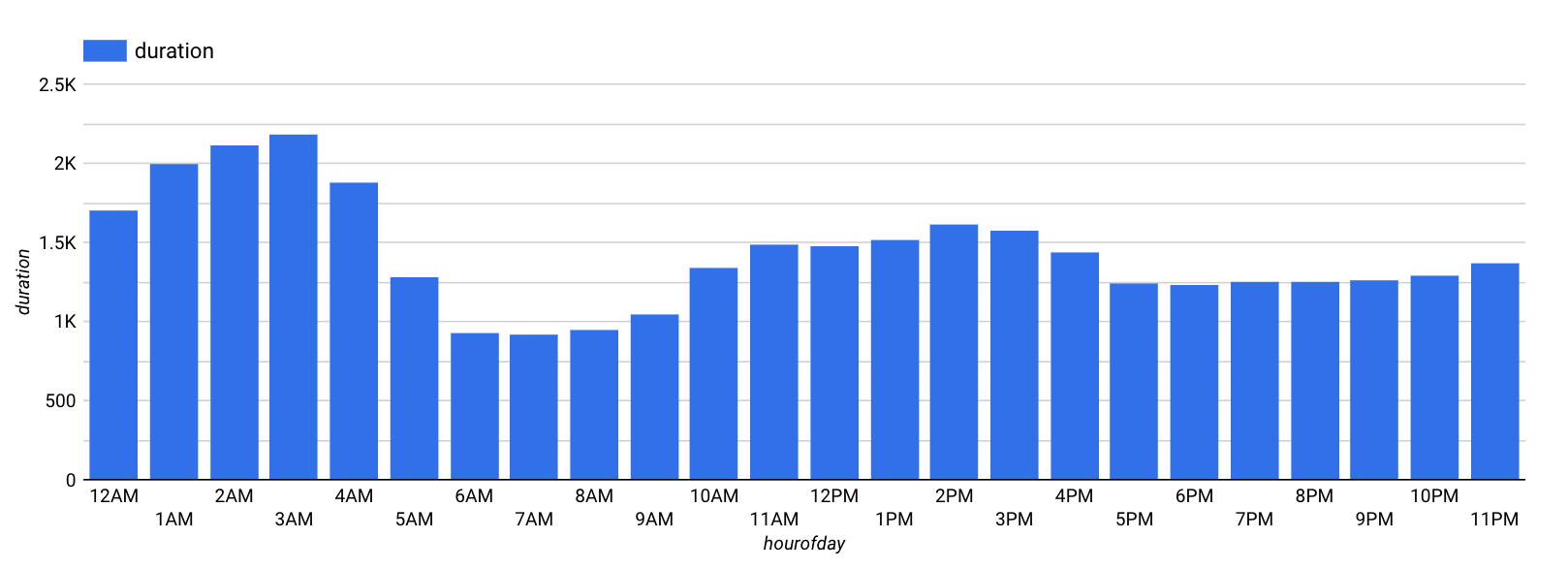
시간별로 시각화하면 다음과 같이 표시됩니다.
요일별, 시간별로 모두 대여 시간이 달라집니다. 대여 시간은 평일보다 주말(1일째와 7일째)이 더 긴 것으로 확인됩니다. 마찬가지로 이른 아침 시간과 오후의 대여 시간이 더 깁니다. 따라서 dayofweek 및 hourofday는 좋은 특성이 됩니다.
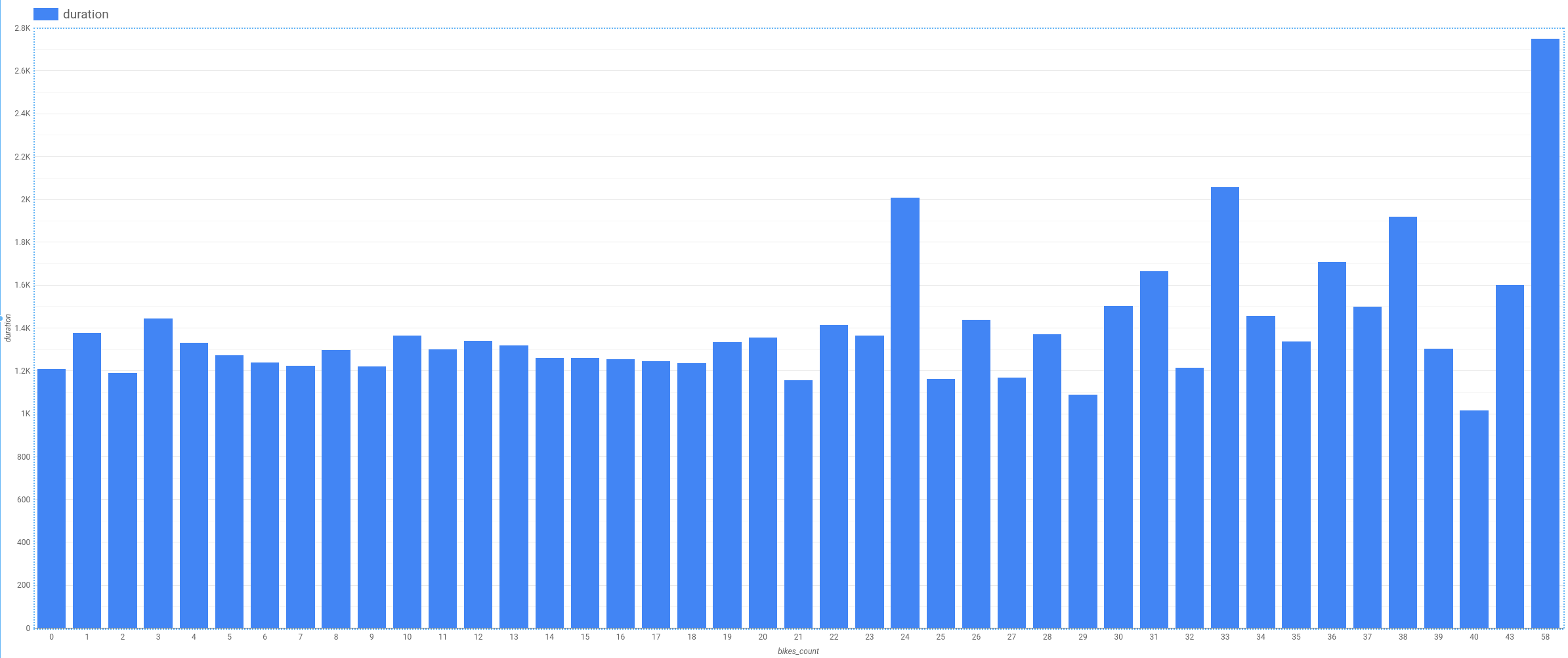
역에 있는 자전거의 수는 또 다른 특성이 될 수 있습니다. 자전거를 대여한 역의 자전거 수가 적은 경우 자전거를 더 장시간 대여한 상태로 둔다고 가정해 봅시다.
예를 들어 hour-of-day 특성에 비해 관계성이 약하고 가시적인 추세도 없음을 알 수 있습니다. 이는 자전거의 수가 좋은 특성이 아님을 나타냅니다.
자전거 데이터 세트에 대한 탐색과 라벨 열에 대한 다양한 열의 관계를 바탕으로, 선택한 특성 및 라벨을 가져와 학습 데이터 세트를 준비할 수 있습니다.
특성 열은 숫자 열(INT64, FLOAT64 등) 또는 범주형 열(STRING)이어야 합니다. 특성이 숫자이지만 범주형으로 취급되어야 하는 경우 문자열로 변환해야 합니다. 따라서 각각 1~7과 0~23 범위의 정수인 dayofweek 및 hourofday는 문자열로 변환되었습니다.
데이터 준비 시 컴퓨팅 부하가 높은 변환이나 조인이 포함된 경우, 준비된 학습 데이터를 테이블로 저장하여 실험 중에 해당 작업을 반복하지 않도록 하는 것이 좋습니다. 변환은 간단하지만 쿼리 자체의 실행 시간이 길 때는 쿼리를 뷰로 저장해 두면 반복 작업을 방지할 수 있습니다.
쿼리가 단순하고 짧은 경우에는 쿼리를 명확하게 하기 위해 저장하지 않아도 됩니다.
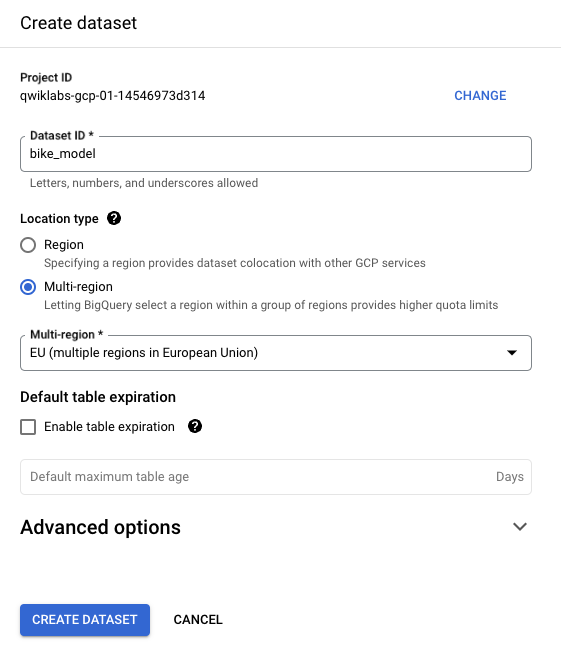
bike_model라는 데이터 세트를 만들어 모델을 저장합니다. 위치 유형을 멀티 리전으로 설정하고 학습하는 데이터가 EU에 있으므로 EU(유럽연합의 멀티 리전) 리전을 선택합니다. 데이터 세트 만들기를 클릭합니다.ML 모델을 학습시켜 bike_model 데이터 세트에 저장하려면 CREATE TABLE과 유사하게 작동하는 CREATE MODEL을 호출해야 합니다. 예측하려는 라벨이 숫자이기 때문에 이는 회귀 문제가 됩니다. 따라서 OPTIONS에서 linear_reg를 모델 유형으로 선택하는 것이 가장 적합한 옵션입니다.
이 모델을 학습시키는 데 2~3분이 소요됩니다.
평균 절대 오차는 1,025초 또는 약 17분이며, 이는 평균 17분 정도의 오차로 자전거 대여 시간을 예측할 수 있을 것으로 예상해야 한다는 의미입니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
특성을 표현하기 위해 선택할 수 있는 다른 방법이 있습니다. 예를 들어 자전거 대여 시 dayofweek와 duration의 관계를 조사한 결과 평일보다 주말의 대여 시간이 더 긴 것으로 나타났습니다. 따라서 dayofweek의 원시 값을 특성으로 처리하는 대신 여러 dayofweek 값을 평일 카테고리에 통합하여 이 통계를 사용할 수 있습니다.
이 모델의 평균 절대 오차는 966초로 원래 모델의 1,025초보다 짧습니다. 모델이 개선되었습니다.
hourofday와 duration의 관계를 바탕으로 변수를 (-inf,5), [5,10), [10,17), [17,inf)의 4가지 구간으로 버킷화하는 실험을 할 수 있습니다.
이 모델의 평균 절대 오차는 904초로 weekday-weekend 모델의 966초보다 짧습니다. 모델이 더욱 개선되었습니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
최적의 모델에는 몇 가지 데이터 변환이 포함되어 있습니다. 학습 시 이루어진 일련의 변환이 Big Query에 기억되어 예측 시 자동으로 적용된다면 좋지 않을까요? TRANSFORM 절을 사용하면 됩니다.
이 경우 결과 모델은 start_station_name 및 start_date만 사용하여 duration을 예측할 수 있습니다. 변환은 제공된 원시 데이터에 저장 및 수행되어 모델의 입력 특성을 생성합니다. 모든 전처리 함수를 TRANSFORM 절 내에 배치하는 주요 이점은 모델의 클라이언트가 어떤 종류의 전처리가 수행되었는지 알 필요가 없다는 것입니다.
TRANSFORM 절로 BigQuery ML 모델을 빌드합니다.TRANSFORM 절을 배치하고 다음 쿼리를 입력하면 파크 레인(Park Lane)에서의 자전거 대여 시간을 실시간으로 예측할 수 있습니다(결과는 경우에 따라 다를 수 있음).내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
선형 회귀 모델은 입력의 가중치 합계로 출력을 예측합니다. 모델의 가중치는 프로덕션 환경에서 활용되는 경우가 많습니다.
다음 쿼리를 사용하여 모델의 가중치를 검사(또는 내보내기)합니다.
숫자형 특성에는 단일 가중치가 적용되고 범주형 특성에는 가능한 각 값에 대한 가중치가 적용됩니다. 예를 들어 dayofweek 특성에는 다음과 같은 가중치가 있습니다.
즉, 평일의 경우 전체 예측 대여 시간에 대한 dayofweek 특성의 기여도는 1,709초입니다(최적의 성능을 제공하는 가중치는 고유하지 않으므로 다른 값을 얻을 수도 있음).
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
실습을 완료하면 실습 종료를 클릭합니다. Google Cloud Skills Boost에서 사용된 리소스를 자동으로 삭제하고 계정을 지웁니다.
실습 경험을 평가할 수 있습니다. 해당하는 별표 수를 선택하고 의견을 입력한 후 제출을 클릭합니다.
별점의 의미는 다음과 같습니다.
의견을 제공하고 싶지 않다면 대화상자를 닫으면 됩니다.
의견이나 제안 또는 수정할 사항이 있다면 지원 탭을 사용하세요.
Copyright 2026 Google LLC All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.



현재 이 콘텐츠를 이용할 수 없습니다
이용할 수 있게 되면 이메일로 알려드리겠습니다.

감사합니다
이용할 수 있게 되면 이메일로 알려드리겠습니다.

한 번에 실습 1개만 가능
모든 기존 실습을 종료하고 이 실습을 시작할지 확인하세요.
실습을 시작하려면 이 간단한 단계를 완료하세요.