Vertex AI is now Gemini Enterprise Agent Platform! We are currently updating our content to reflect this change. Please bear with us if you encounter naming inconsistencies during this transition.
Applica le tue competenze nella console Google Cloud
Checkpoint
Create a training dataset
Controlla i miei progressi
/ 5
Improving the model through feature engineering
Controlla i miei progressi
/ 5
Make predictions
Controlla i miei progressi
/ 5
Examine model weights
Controlla i miei progressi
/ 5
Create a training dataset
Controlla i miei progressi
/ 5
Improving the model through feature engineering
Controlla i miei progressi
/ 5
Make predictions
Controlla i miei progressi
/ 5
Examine model weights
Controlla i miei progressi
/ 5
Questo lab potrebbe incorporare strumenti di AI a supporto del tuo apprendimento.
Panoramica
BigQuery è il database di analisi NoOps a basso costo e completamente gestito di Google. Con BigQuery puoi interrogare molti terabyte di dati senza dover gestire alcuna infrastruttura o aver bisogno di un amministratore del database. BigQuery utilizza SQL e sfrutta i vantaggi offerti dal modello di pagamento a consumo. BigQuery permette di concentrarsi sull'analisi dei dati per trovare insight significativi.
BigQuery Machine Learning è una funzionalità di BigQuery in cui gli analisti di dati possono creare, addestrare, valutare e prevedere tramite modelli di machine learning con una programmazione minima.
In questo lab userai il set di dati delle biciclette di Londra per creare un modello di regressione in BigQuery ML per prevedere la durata dei viaggi. Ipotizziamo che tu abbia un'attività di noleggio di biciclette che offre ai clienti due tipi di biciclette: un modello robusto per il traffico pendolare e un modello da corsa veloce ma fragile. Nel caso dei noleggi di lunga durata, dobbiamo avere a disposizione bici da corsa, viceversa nel caso dei noleggi per periodi brevi, dobbiamo avere a disposizione biciclette per il traffico pendolare. Per poter creare un sistema che consenta di mettere in inventario le biciclette appropriate, abbiamo bisogno di prevedere la durata dei noleggi delle biciclette.
Obiettivi
In questo lab imparerai a:
Eseguire query nel set di dati delle biciclette di Londra per il feature engineering
Creare un modello di regressione lineare in BigQuery ML
Valutare le prestazioni del tuo modello di machine learning
Estrarre i pesi del tuo modello
Che cosa ti serve
Un progetto Google Cloud
Un browser, ad esempio Google Chrome o Mozilla Firefox
Configura l'ambiente
Per ciascun lab, riceverai un nuovo progetto Google Cloud e un insieme di risorse per un periodo di tempo limitato senza alcun costo aggiuntivo.
Accedi a Qwiklabs utilizzando una finestra di navigazione in incognito.
Tieni presente la durata dell'accesso al lab (ad esempio, 1:15:00) e assicurati di finire entro quell'intervallo di tempo.
Non è disponibile una funzionalità di pausa. Se necessario, puoi riavviare il lab ma dovrai ricominciare dall'inizio.
Quando è tutto pronto, fai clic su Inizia lab.
Annota le tue credenziali del lab (Nome utente e Password). Le userai per accedere a Google Cloud Console.
Fai clic su Apri console Google.
Fai clic su Utilizza un altro account e copia/incolla le credenziali per questo lab nei prompt.
Se utilizzi altre credenziali, compariranno errori oppure ti verranno addebitati dei costi.
Accetta i termini e salta la pagina di ripristino delle risorse.
Apri la console di BigQuery
Nella console Google Cloud, seleziona Menu di navigazione > BigQuery.
Si aprirà la finestra con il messaggio Ti diamo il benvenuto in BigQuery nella console Cloud. Questa finestra fornisce un link alla guida rapida ed elenca gli aggiornamenti dell'interfaccia utente.
Fai clic su Fine.
Attività 1: esplora i dati relativi alle biciclette per il feature engineering
Il primo passaggio per risolvere un problema di ML consiste nel formularlo: identificare le caratteristiche del nostro modello e l'etichetta. Poiché l'obiettivo del nostro primo modello è prevedere la durata di un noleggio sulla base del set di dati storico dei noleggi di biciclette, l'etichetta è la durata del noleggio.
Se crediamo che la durata varierà in base alla stazione in cui verrà noleggiata la bicicletta, il giorno della settimana e l'ora del giorno, queste potrebbero essere le nostre caratteristiche. Prima di proseguire e creare un modello con queste caratteristiche, però, è una buona idea verificare che questi fattori incidano davvero sull'etichetta.
Il processo mediante il quale stabiliamo le caratteristiche per un modello di machine learning è chiamato feature engineering. Spesso il feature engineering è la fase più importante della creazione di modelli di ML accurati e può avere un impatto più significativo della decisione di quali algoritmi usare o dell'ottimizzazione degli iperparametri. Un buon feature engineering richiede una profonda conoscenza dei dati e del dominio. Si tratta spesso di un processo di verifica delle ipotesi: hai un'idea per una caratteristica, controlli che funzioni (ha delle informazioni reciproche con l'etichetta), quindi la aggiungi al modello. Se non funziona, riprovi.
Impatto della stazione
Per controllare se la durata del noleggio varia in base alla stazione, possiamo visualizzare i risultati della query riportata di seguito in Looker Studio.
Nell'EDITOR di query, incolla questa query:
SELECT
start_station_name,
AVG(duration) AS duration
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
GROUP BY
start_station_name
Fai clic su ESEGUI.
Fai clic su APRI IN > Looker Studio nella console Cloud di BigQuery.
Quando richiesto, seleziona il pulsante INIZIA.
Fai clic sul grafico presente nel canvas.
Nella scheda CONFIGURAZIONE sul lato destro del menu laterale, configura le impostazioni come segue:
Dimensioni: start_station_name
Metrica: duration
Ordina: per duration in ordine Decrescente.
Interazione con i grafici: abilita Filtro incrociato e Modifica ordinamento.
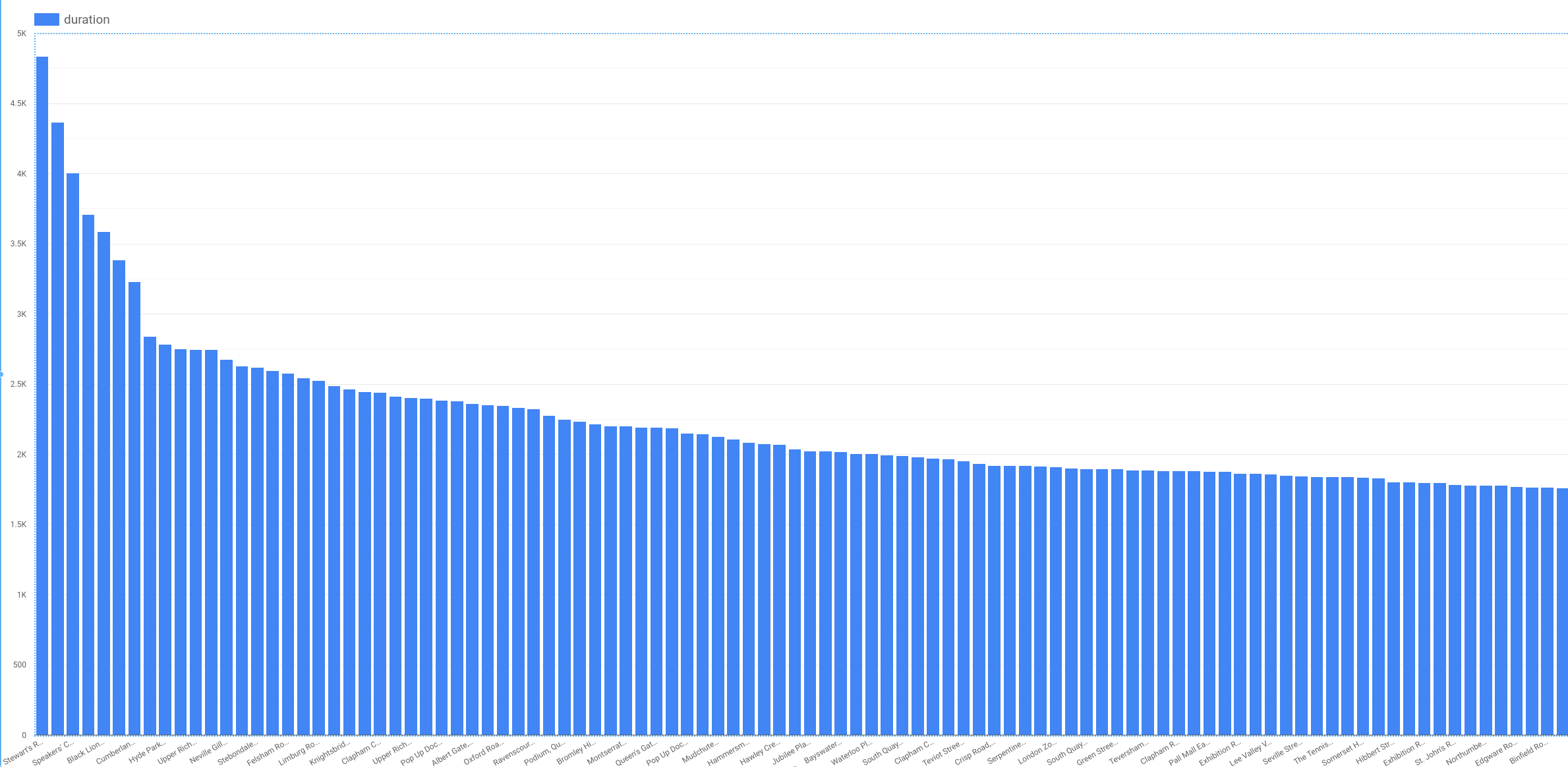
Nella scheda STILE sul lato destro del menu laterale, configura le impostazioni come segue:
Grafico a barre: Verticale
Barre: 100
Assi: Mostra assi
Il tuo grafico dovrebbe assomigliare a questo:
È evidente che alcune stazioni sono associate a noleggi di lunga durata (più di 3000 secondi), ma che la maggior parte delle stazioni registra durate relativamente brevi. Se tutte le stazioni di Londra fossero associate a durate brevi, la stazione in cui è iniziato il noleggio non sarebbe una buona caratteristica. Ma, come dimostra il grafico, in questo problema la caratteristica start_station_name è importante.
Nota: non possiamo usare la caratteristica end_station_name perché quando viene noleggiata una bicicletta non sappiamo dove verrà restituita.
Siccome stiamo creando un modello di machine learning per prevedere eventi futuri, dobbiamo prestare molta attenzione a non usare colonne che non saranno note al momento in cui viene fatta la previsione. Questo criterio di tempo/causalità impone dei vincoli sulle caratteristiche che è possibile usare.
Impatto del giorno della settimana e dell'ora del giorno
Per la successiva potenziale caratteristica, il processo è simile. Possiamo verificare se dayofweek (o, analogamente, hourofday) è importante.
Nella finestra dell'editor di query, incolla questa query:
SELECT
EXTRACT(dayofweek
FROM
start_date) AS dayofweek,
AVG(duration) AS duration
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
GROUP BY
dayofweek
Fai clic su APRI IN > Looker Studio nella console Cloud di BigQuery.
Nota: se vedi un messaggio di errore di sistema, devi effettuare alcune modifiche per visualizzare i dati in Looker Studio descritti nei passaggi da 3 a 11.
Fai clic sulla tabella che contiene i dati relativi a duration e dayofweek.
In Configurazione > Metrica, passa il mouse sopra dayofweek e fai clic sull'icona di modifica con la matita.
Nel menu a discesa Formato visualizzazione, fai clic su Numero settimana, poi scegli Formato data personalizzato.
Modifica la data personalizzata selezionando 'Day' w, quindi fai clic su Applica.
Nel grafico, il campo dayofweek ora mostra dal giorno 1 al giorno 7.
Fai clic sul grafico che restituisce l'errore di sistema.
In Configurazione > Dimensione, fai clic su duration e seleziona dayofweek.
In Configurazione > Dimensione, passa il mouse sopra dayofweek e fai clic sull'icona di modifica con la matita.
Nel menu a discesa Formato visualizzazione, seleziona Formato data personalizzato e modifica la data personalizzata selezionando 'Day' w. Quindi, fai clic su Applica.
In Configurazione > Metrica, fai clic su dayofweek e seleziona duration.
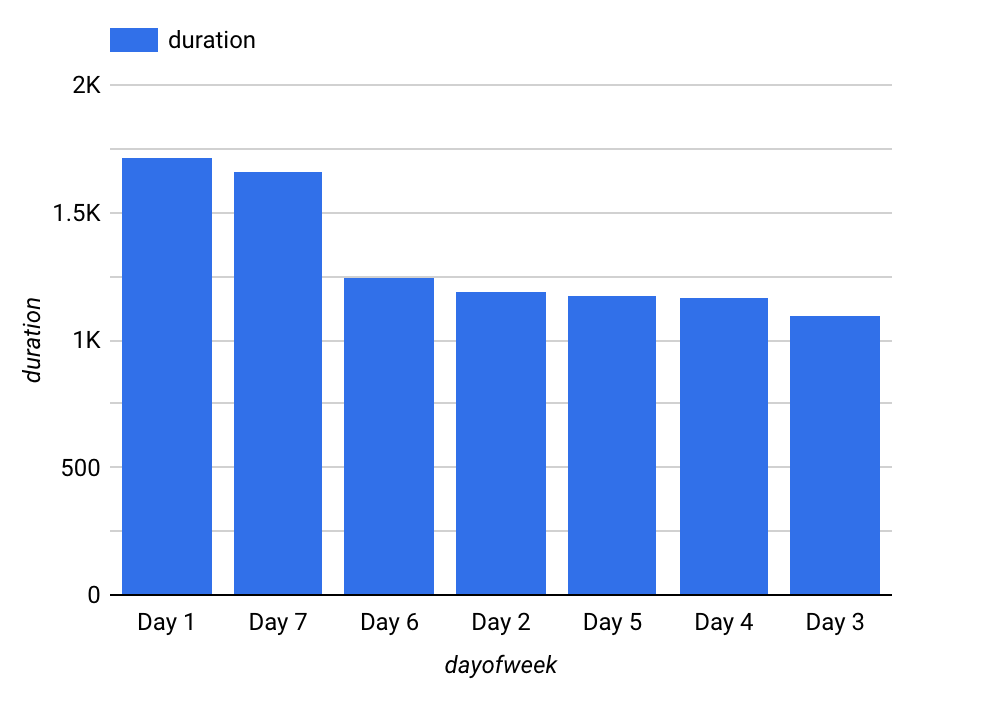
Per il giorno della settimana la visualizzazione dovrebbe essere simile alla seguente:
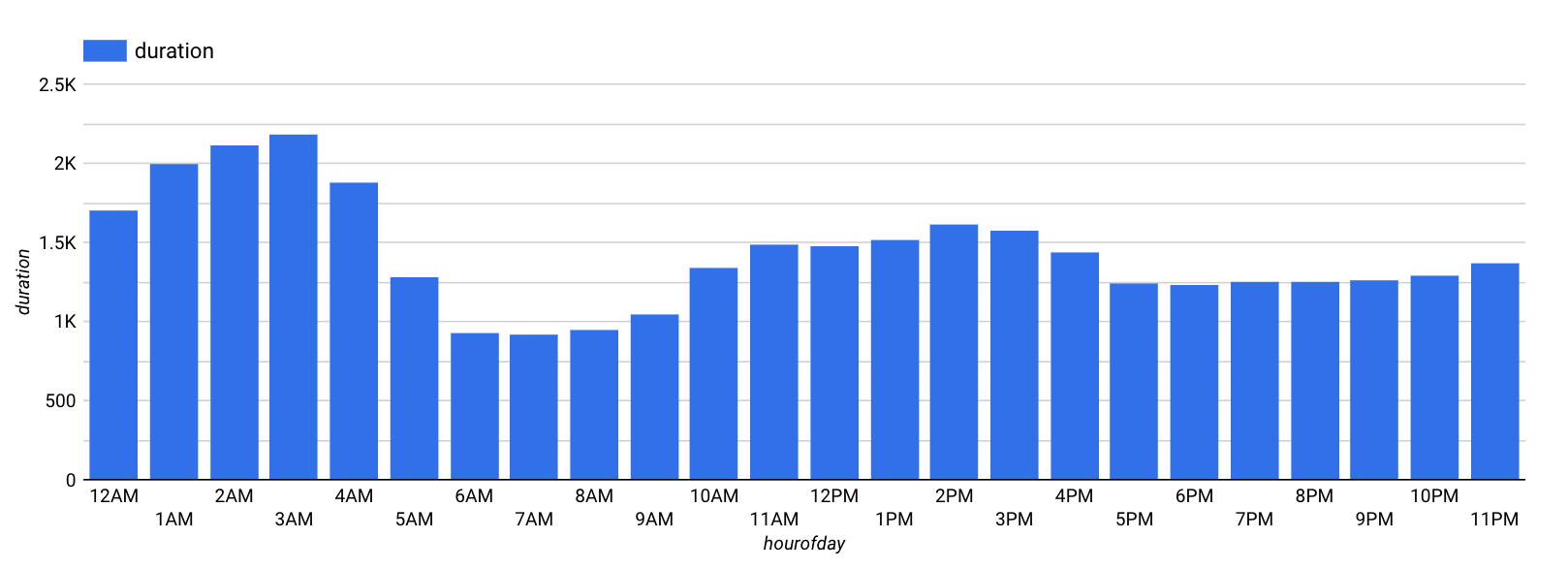
Per l'ora della settimana la visualizzazione dovrebbe essere simile alla seguente:
Nota: come nei passaggi precedenti, potresti dover modificare le proprietà in Looker Studio per vedere l'output desiderato.
È evidente che la durata varia in base sia al giorno della settimana sia all'ora del giorno. Sembra che le durate siano maggiori durante i fine settimana (giorni 1 e 7) rispetto ai giorni infrasettimanali. Allo stesso modo, le durate sono maggiori di mattina presto e a metà pomeriggio. Pertanto, sia dayofweek sia hourofday sono buone caratteristiche.
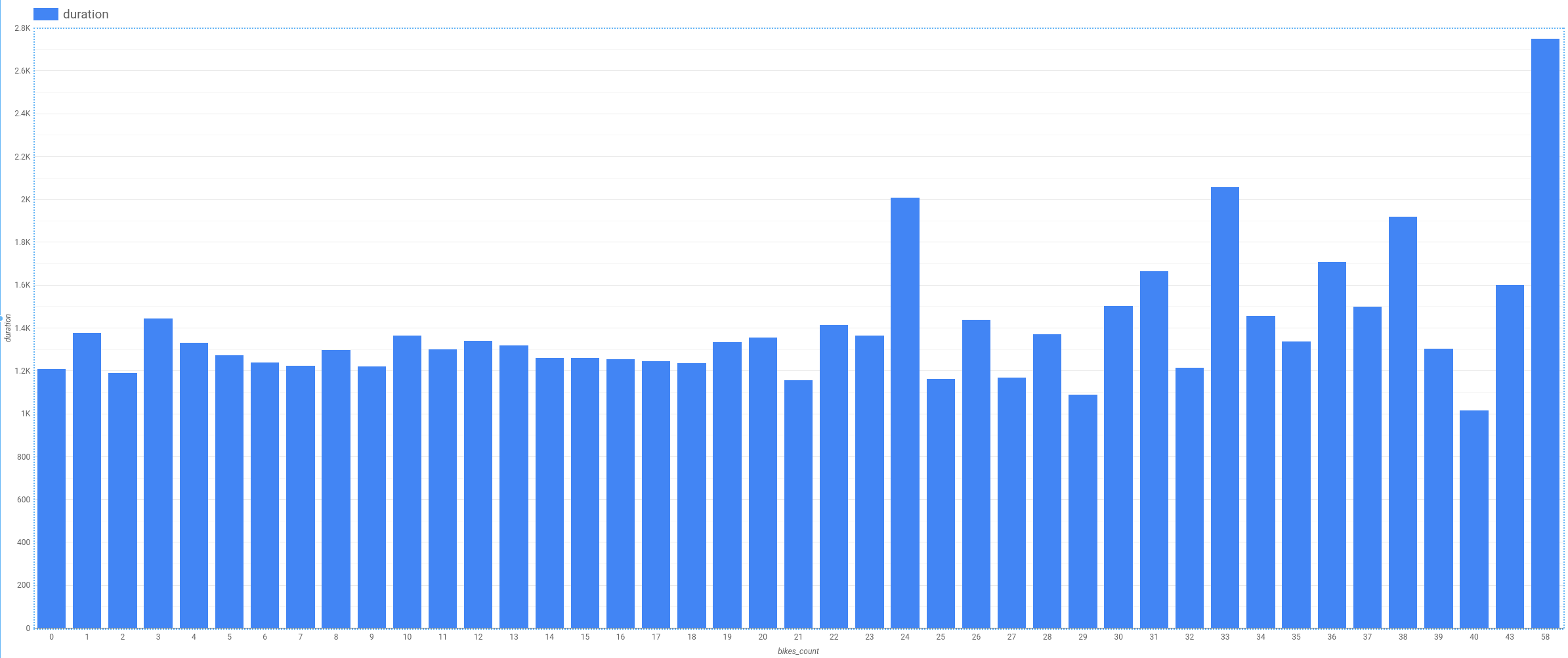
Impatto del numero di biciclette
Un'altra potenziale caratteristica è il numero di biciclette nella stazione. Forse, ipotizziamo, le persone tengono le biciclette più a lungo se nella stazione in cui effettuano il noleggio ce ne sono meno disponibili.
Nella finestra dell'editor di query, incolla questa query:
SELECT
bikes_count,
AVG(duration) AS duration
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
JOIN
`bigquery-public-data`.london_bicycles.cycle_stations
ON
cycle_hire.start_station_name = cycle_stations.name
GROUP BY
bikes_count
Visualizza i dati in Looker Studio.
Notiamo che la relazione è rumorosa e non presenta una tendenza visibile (fai un confronto, ad esempio, con l'ora del giorno). Questo indica che il numero di biciclette non è una buona caratteristica.
Attività 2: crea un set di dati di addestramento
Basandoci sull'esplorazione del set di dati delle biciclette e sulla relazione delle varie colonne con la colonna dell'etichetta, possiamo preparare il set di dati di addestramento estraendo le caratteristiche selezionate e l'etichetta:
SELECT
duration,
start_station_name,
CAST(EXTRACT(dayofweek
FROM
start_date) AS STRING) AS dayofweek,
CAST(EXTRACT(hour
FROM
start_date) AS STRING) AS hourofday
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
Le colonne delle caratteristiche devono essere numeriche (INT64, FLOAT64 e così via) o categoriche (STRING). Se la caratteristica è numerica, ma deve essere trattata come categorica, dobbiamo trasmetterla come stringa, questo spiega perché abbiamo trasmesso le colonne dayofweek e hourofday che sono numeri interi (negli intervalli 1-7 e 0-23, rispettivamente) in stringhe.
Se la preparazione dei dati implica trasformazioni o unioni che richiedono molte risorse di calcolo, potrebbe essere una buona idea salvare i dati di addestramento ben organizzati in forma di tabella in modo da non dover ripetere l'operazione durante la sperimentazione. Se le trasformazioni sono poco significative ma la query stessa è molto lunga, potrebbe convenire evitare ripetitività salvandoli come visualizzazione.
In questo caso la query è semplice e breve, quindi per chiarezza non la salveremo.
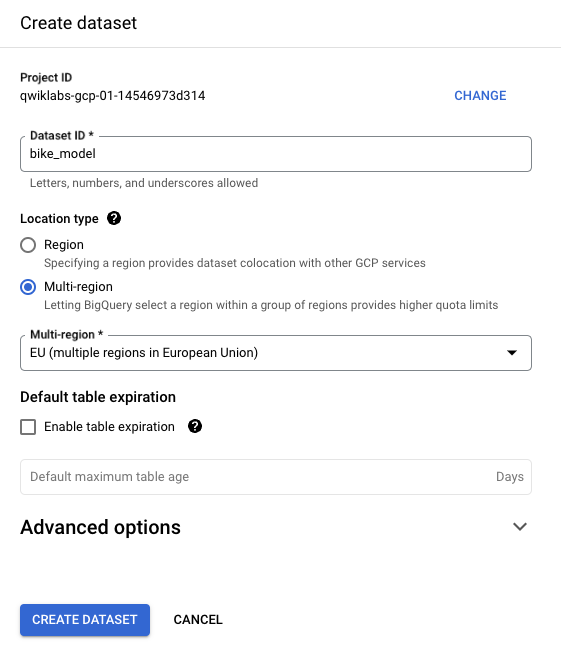
Crea un set di dati in BigQuery chiamato bike_model per archiviare il tuo modello. Imposta il Tipo di località su Più regioni e seleziona la regione UE (più regioni nell'Unione Europea), poiché i dati che stiamo addestrando si riferiscono all'UE. Fai clic su Crea set di dati.
Per addestrare un modello di ML e salvarlo nel set di dati bike_model, dobbiamo chiamare CREA MODELLO, che funziona in modo simile a CREA TABELLA. Poiché l'etichetta che stiamo cercando di prevedere è numerica, si tratta di un problema di regressione, per cui l'opzione più appropriata è scegliere il tipo di modello linear_reg nella sezione OPZIONI.
Inserisci la seguente query nell'editor di query:
CREATE OR REPLACE MODEL
bike_model.model
OPTIONS
(input_label_cols=['duration'],
model_type='linear_reg') AS
SELECT
duration,
start_station_name,
CAST(EXTRACT(dayofweek
FROM
start_date) AS STRING) AS dayofweek,
CAST(EXTRACT(hour
FROM
start_date) AS STRING) AS hourofday
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE `duration` IS NOT NULL
Tieni presente che l'addestramento del modello impiega 2-3 minuti.
Per vedere alcune metriche relative all'addestramento del modello, inserisci la seguente query nella finestra dell'editor di BigQuery:
SELECT * FROM ML.EVALUATE(MODEL `bike_model.model`)
L'errore assoluto medio è di 1025 secondi o circa 17 minuti. Questo significa che dovremmo aspettarci di riuscire a prevedere la durata dei noleggi di biciclette con un errore medio di 17 minuti.
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Crea un set di dati di addestramento
Attività 3: migliora il modello mediante il feature engineering
Combina i giorni della settimana
Esistono altri modi che avremmo potuto scegliere per rappresentare le nostre caratteristiche. Ad esempio, ricorda che quando abbiamo esplorato la relazione tra le caratteristiche dei noleggi dayofweek e duration, abbiamo scoperto che le durate erano maggiori durante i fine settimana rispetto ai giorni infrasettimanali. Quindi, invece che trattare il valore non elaborato di dayofweek come caratteristica, possiamo impiegare questo insight fondendo diversi valori dayofweek nella categoria weekday.
Crea un modello di ML di BigQuery con la caratteristica giorni della settimana combinati usando la seguente query:
CREATE OR REPLACE MODEL
bike_model.model_weekday
OPTIONS
(input_label_cols=['duration'],
model_type='linear_reg') AS
SELECT
duration,
start_station_name,
IF
(EXTRACT(dayofweek
FROM
start_date) BETWEEN 2 AND 6,
'weekday',
'weekend') AS dayofweek,
CAST(EXTRACT(hour
FROM
start_date) AS STRING) AS hourofday
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE `duration` IS NOT NULL
Per vedere le metriche per questo modello, inserisci questa query nella finestra dell'editor di BigQuery:
SELECT * FROM ML.EVALUATE(MODEL `bike_model.model_weekday`)
Questo modello restituisce un errore assoluto medio di 966 secondi, inferiore ai 1025 secondi del modello originale. Significa che c'è stato un miglioramento.
Suddividi in bucket l'ora del giorno
In base alla relazione tra hourofday e duration, possiamo sperimentare con la suddivisione in bucket della variabile in 4 bin; (-inf,5), [5,10), [10,17) e [17,inf).
Crea un modello di ML di BigQuery con le caratteristiche ora del giorno suddivisa in bucket e giorni della settimana combinati usando la seguente query:
CREATE OR REPLACE MODEL
bike_model.model_bucketized
OPTIONS
(input_label_cols=['duration'],
model_type='linear_reg') AS
SELECT
duration,
start_station_name,
IF
(EXTRACT(dayofweek
FROM
start_date) BETWEEN 2 AND 6,
'weekday',
'weekend') AS dayofweek,
ML.BUCKETIZE(EXTRACT(hour
FROM
start_date),
[5, 10, 17]) AS hourofday
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE `duration` IS NOT NULL
Per vedere le metriche per questo modello, inserisci questa query nella finestra dell'editor di BigQuery:
SELECT * FROM ML.EVALUATE(MODEL `bike_model.model_bucketized`)
Questo modello restituisce un errore assoluto medio di 904 secondi, inferiore ai 966 secondi del modello basato su giorno della settimana e fine settimana. C'è stato un ulteriore miglioramento.
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Migliora il modello mediante il feature engineering
Attività 4: fai previsioni
Il nostro modello migliore contiene diverse trasformazioni dei dati. Non sarebbe bello se BigQuery potesse ricordare i set di trasformazioni che abbiamo creato durante l'addestramento e li applicasse automaticamente al momento della previsione? Lo può fare, usando la clausola TRANSFORM.
In questo caso il modello risultante richiede solo i valori start_station_name e start_date per prevedere il valore duration. Le trasformazioni vengono salvate ed eseguite sui dati non elaborati forniti per creare caratteristiche di input per il modello. Il principale vantaggio di inserire tutte le caratteristiche di pre-elaborazione nella clausola TRANSFORM è che i client del modello non devono sapere che tipo di pre-elaborazione è stata svolta.
Crea un modello di ML di BigQuery con la clausola TRANSFORM che incorpora le caratteristiche ora del giorno suddivisa in bucket e giorni della settimana combinati usando la seguente query:
CREATE OR REPLACE MODEL
bike_model.model_bucketized TRANSFORM(* EXCEPT(start_date),
IF
(EXTRACT(dayofweek
FROM
start_date) BETWEEN 2 AND 6,
'weekday',
'weekend') AS dayofweek,
ML.BUCKETIZE(EXTRACT(HOUR
FROM
start_date),
[5, 10, 17]) AS hourofday )
OPTIONS
(input_label_cols=['duration'],
model_type='linear_reg') AS
SELECT
duration,
start_station_name,
start_date
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE `duration` IS NOT NULL
Con la clausola TRANSFORM in funzione, inserisci questa query per prevedere la durata di un noleggio da Park Lane in questo momento (i risultati saranno variabili):
SELECT
*
FROM
ML.PREDICT(MODEL bike_model.model_bucketized,
(
SELECT
'Park Lane , Hyde Park' AS start_station_name,
CURRENT_TIMESTAMP() AS start_date) )
Per eseguire previsioni batch su un campione di 100 righe nel set di addestramento, usa la query:
SELECT
*
FROM
ML.PREDICT(MODEL bike_model.model_bucketized,
(
SELECT
start_station_name,
start_date
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
LIMIT
100) )
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Fai previsioni
Attività 5: esamina i pesi del modello
Un modello di regressione lineare prevede l'output come una somma ponderata dei suoi input. Spesso, i pesi del modello devono essere utilizzati in un ambiente di produzione.
Esamina (o esporta) i pesi del modello usando la seguente query:
SELECT * FROM ML.WEIGHTS(MODEL bike_model.model_bucketized)
Tieni presente che le caratteristiche numeriche hanno un singolo peso, mentre le caratteristiche categoriche hanno un peso per ogni valore possibile. Ad esempio, la caratteristica dayofweek ha i seguenti pesi:
Questo significa che se il giorno è infrasettimanale, il contributo di questa caratteristica alla durata prevista generale è di 1709 secondi (i pesi che offrono le prestazioni ottimali non sono univoci, quindi potresti ottenere un valore diverso).
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Esamina i pesi del modello
Termina il lab
Una volta completato il lab, fai clic su Termina lab. Google Cloud Skills Boost rimuove le risorse che hai utilizzato ed esegue la pulizia dell'account.
Avrai la possibilità di inserire una valutazione in merito alla tua esperienza. Seleziona il numero di stelle applicabile, inserisci un commento, quindi fai clic su Invia.
Il numero di stelle corrisponde alle seguenti valutazioni:
1 stella = molto insoddisfatto
2 stelle = insoddisfatto
3 stelle = esperienza neutra
4 stelle = soddisfatto
5 stelle = molto soddisfatto
Se non vuoi lasciare un feedback, chiudi la finestra di dialogo.
Per feedback, suggerimenti o correzioni, utilizza la scheda Assistenza.
Copyright 2026 Google LLC Tutti i diritti riservati. Google e il logo Google sono marchi di Google LLC. Tutti gli altri nomi di società e prodotti sono marchi delle rispettive società a cui sono associati.
Prima di iniziare
I lab creano un progetto e risorse Google Cloud per un periodo di tempo prestabilito
I lab hanno un limite di tempo e non possono essere messi in pausa. Se termini il lab, dovrai ricominciare dall'inizio.
In alto a sinistra dello schermo, fai clic su Inizia il lab per iniziare
Utilizza la navigazione privata
Copia il nome utente e la password forniti per il lab
Fai clic su Apri console in modalità privata
Accedi alla console
Accedi utilizzando le tue credenziali del lab. L'utilizzo di altre credenziali potrebbe causare errori oppure l'addebito di costi.
Accetta i termini e salta la pagina di ripristino delle risorse
Non fare clic su Termina lab a meno che tu non abbia terminato il lab o non voglia riavviarlo, perché il tuo lavoro verrà eliminato e il progetto verrà rimosso
Questi contenuti non sono al momento disponibili
Ti invieremo una notifica via email quando sarà disponibile
Bene.
Ti contatteremo via email non appena sarà disponibile
Un lab alla volta
Conferma per terminare tutti i lab esistenti e iniziare questo
Utilizza la navigazione privata per eseguire il lab
Il modo migliore per eseguire questo lab è utilizzare una finestra del browser in incognito o privata. Ciò evita eventuali conflitti tra il tuo account personale e l'account studente, che potrebbero causare addebiti aggiuntivi sul tuo account personale.
In questo lab userai il set di dati delle biciclette di Londra per creare un modello di regressione in BQML per prevedere la durata dei viaggi.
Durata:
Configurazione in 0 m
·
Accesso da 60 m
·
Completamento in 60 m