Vertex AI is now Gemini Enterprise Agent Platform! We are currently updating our content to reflect this change. Please bear with us if you encounter naming inconsistencies during this transition.
Applica le tue competenze nella console Google Cloud
Checkpoint
Create a new dataset and load JSON data into the table
Controlla i miei progressi
/ 20
Creating arrays with ARRAY_AGG()
Controlla i miei progressi
/ 20
Querying datasets that already have ARRAYs
Controlla i miei progressi
/ 20
Explore a dataset with STRUCTs
Controlla i miei progressi
/ 20
Practice with STRUCTs and ARRAYs
Controlla i miei progressi
/ 20
Create a new dataset and load JSON data into the table
Controlla i miei progressi
/ 20
Creating arrays with ARRAY_AGG()
Controlla i miei progressi
/ 20
Querying datasets that already have ARRAYs
Controlla i miei progressi
/ 20
Explore a dataset with STRUCTs
Controlla i miei progressi
/ 20
Practice with STRUCTs and ARRAYs
Controlla i miei progressi
/ 20
Questo lab potrebbe incorporare strumenti di AI a supporto del tuo apprendimento.
Panoramica
BigQuery è il database di analisi NoOps a basso costo e completamente gestito di Google. Con BigQuery puoi eseguire query su molti terabyte di dati senza dover gestire alcuna infrastruttura o aver bisogno di un amministratore del database. BigQuery utilizza SQL e sfrutta i vantaggi offerti dal modello di pagamento a consumo. BigQuery ti permette di concentrarti sull'analisi dei dati per ricavare insight significativi.
Questo lab è una procedura dettagliata che illustra in modo approfondito l'uso di dati semistrutturati (importazione di tipi di dati per array JSON) all'interno di BigQuery. Denormalizzando lo schema in una singola tabella con campi nidificati e ripetuti, è possibile aumentare le prestazioni, ma la sintassi SQL per l'uso dei dati di array può essere molto complicata. Ti eserciterai a caricare, denidificare ed eseguire query su vari set di dati semistrutturati, risolvendo anche i problemi relativi.
Obiettivi
In questo lab imparerai a:
Caricare dati JSON semistrutturati in BigQuery
Creare array ed eseguirvi query
Creare struct ed eseguirvi query
Eseguire query su campi nidificati e ripetuti
Configurazione e requisiti
Per ciascun lab, riceverai un nuovo progetto Google Cloud e un insieme di risorse per un periodo di tempo limitato senza alcun costo aggiuntivo.
Accedi a Qwiklabs utilizzando una finestra di navigazione in incognito.
Tieni presente la durata dell'accesso al lab (ad esempio, 1:15:00) e assicurati di finire entro quell'intervallo di tempo.
Non è disponibile una funzionalità di pausa. Se necessario, puoi riavviare il lab ma dovrai ricominciare dall'inizio.
Quando è tutto pronto, fai clic su Inizia lab.
Annota le tue credenziali del lab (Nome utente e Password). Le userai per accedere a Google Cloud Console.
Fai clic su Apri console Google.
Fai clic su Utilizza un altro account e copia/incolla le credenziali per questo lab nei prompt.
Se utilizzi altre credenziali, compariranno errori oppure ti verranno addebitati dei costi.
Accetta i termini e salta la pagina di ripristino delle risorse.
Apri la console di BigQuery
Nella console Google Cloud, seleziona Menu di navigazione > BigQuery.
Si aprirà la finestra con il messaggio Ti diamo il benvenuto in BigQuery nella console Cloud. Questa finestra fornisce un link alla guida rapida ed elenca gli aggiornamenti dell'interfaccia utente.
Fai clic su Fine.
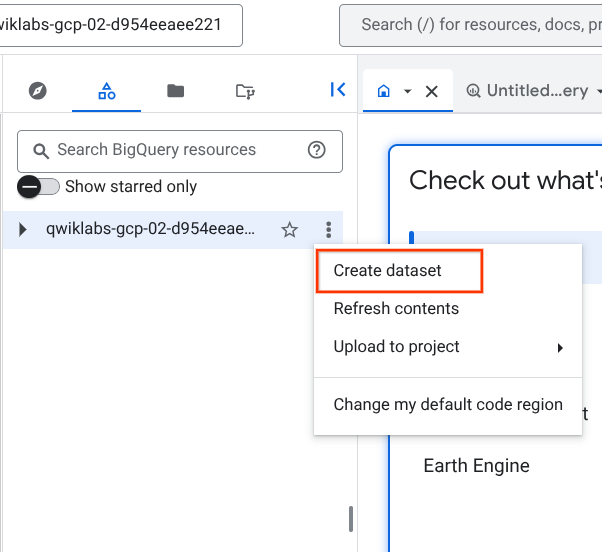
Attività 1: crea un nuovo set di dati per l'archiviazione delle tue tabelle
Per creare un set di dati, fai clic sull'icona Visualizza azioni accanto all'ID del tuo progetto, quindi seleziona Crea set di dati.
Assegna il nome fruit_store al nuovo set di dati. Mantieni i valori predefiniti per tutte le altre opzioni (Località dei dati, Scadenza tabella predefinita).
Fai clic su Crea set di dati.
Attività 2: esercitati a utilizzare gli array in SQL
Solitamente, in SQL è presente un singolo valore per ogni riga, come nel seguente elenco di nomi di frutti:
Row
Fruit
1
raspberry
2
blackberry
3
strawberry
4
cherry
E se invece volessi un elenco di nomi di frutti per ogni persona nel negozio? Potrebbe avere un aspetto simile al seguente:
Row
Fruit
Person
1
raspberry
sally
2
blackberry
sally
3
strawberry
sally
4
cherry
sally
5
orange
frederick
6
apple
frederick
Nel codice SQL tradizionale dei database relazionali, vedendo i nomi ripetuti penseresti immediatamente di suddividere la tabella precedente in due tabelle separate, di nome Fruit Items e People. Questo processo si chiama normalizzazione (conversione da una a più tabelle). Questo approccio è molto comune per i database transazionali, come mySQL.
Per il data warehousing, invece, gli analisti di dati usano spesso l'approccio inverso (denormalizzazione), convertendo più tabelle separate in una singola tabella report di grandi dimensioni.
Ora stai per apprendere un altro approccio, in cui tutti i dati vengono memorizzati in una singola tabella, con livelli di granularità diversi, utilizzando campi ripetuti:
Row
Fruit (array)
Person
1
raspberry
sally
blackberry
strawberry
cherry
2
orange
frederick
apple
Che cos'ha di strano la tabella precedente?
Contiene solo due righe.
Una singola riga contiene più campi con i nomi dei frutti.
Le persone sono associate a tutti i valori dei campi.
L'insight chiave è costituito dal tipo di dati array.
Ecco un modo più semplice per interpretare l'array dei nomi di frutti:
Row
Fruit (array)
Person
1
[raspberry, blackberry, strawberry, cherry]
sally
2
[orange, apple]
frederick
Queste due tabelle sono identiche. Questo ci insegna due cose importanti:
Un array è semplicemente un elenco di elementi fra parentesi quadre ([ ]).
BigQuery mostra gli array in una forma lineare semplificata, limitandosi a elencare verticalmente i valori nell'array (ricorda che tutti questi valori appartengono sempre a una sola riga).
Fai una prova.
Inserisci il codice seguente nell'editor di query di BigQuery:
#standardSQL
SELECT
['raspberry', 'blackberry', 'strawberry', 'cherry'] AS fruit_array
Fai clic su Esegui.
Ora prova a eseguire questo codice:
#standardSQL
SELECT
['raspberry', 'blackberry', 'strawberry', 'cherry', 1234567] AS fruit_array
Dovresti ricevere un errore simile al seguente:
Error: Array elements of types {INT64, STRING} do not have a common supertype at [3:1].
I dati di un array devono essere tutti dello stesso tipo (tutte stringhe o tutti numeri).
Questa è la tabella finale da utilizzare per le query:
#standardSQL
SELECT person, fruit_array, total_cost FROM `data-to-insights.advanced.fruit_store`;
Fai clic su Esegui.
Dopo aver visualizzato i risultati, fai clic sulla scheda JSON per vedere la relativa struttura nidificata.
Caricare dati JSON semistrutturati in BigQuery
E se avessi l'esigenza di importare un file JSON in BigQuery?
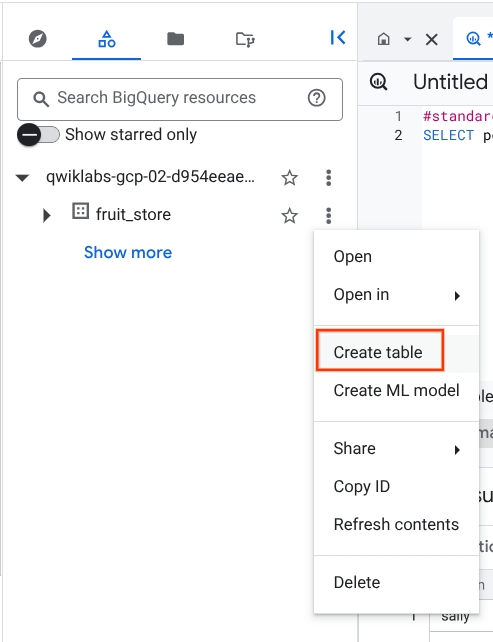
Crea una nuova tabella nel set di dati fruit_store.
Per creare una tabella, fai clic sull'icona Visualizza azioni accanto al set di dati fruit_store e seleziona Crea tabella.
Aggiungi i seguenti dettagli relativi alla tabella:
Origine: seleziona Google Cloud Storage dal menu a discesa Crea tabella da.
Seleziona il file dal bucket GCS (digita o incolla quanto segue): cloud-training/data-insights-course/labs/optimizing-for-performance/shopping_cart.json.
Formato file: JSONL (JSON delimitato da nuova riga) {verrà compilato automaticamente}.
Schema: seleziona Rilevamento automatico (schema e parametri di input).
Assegna il nome fruit_details alla nuova tabella.
Fai clic su Crea tabella.
Nello schema, nota che fruit_array è contrassegnato come REPEATED, per indicare che si tratta di un array.
Riepilogo
BigQuery supporta gli array in modo nativo.
I dati di un array devono essere tutti dello stesso tipo.
In BigQuery gli array vengono chiamati campi ripetuti (REPEATED).
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Crea un nuovo set di dati e carica i dati JSON nella tabella.
Attività 3: crea i tuoi array personalizzati con la funzione ARRAY_AGG()
Se le tue tabelle non contengono ancora alcun array, puoi crearli ora.
Copia e incolla la query riportata di seguito per esplorare questo set di dati pubblico:
SELECT
fullVisitorId,
date,
v2ProductName,
pageTitle
FROM `data-to-insights.ecommerce.all_sessions`
WHERE visitId = 1501570398
ORDER BY date
Fai clic su Esegui e osserva i risultati.
Adesso utilizziamo la funzione ARRAY_AGG() per aggregare i valori di stringa in modo da formare un array. Copia e incolla la query riportata di seguito per esplorare questo set di dati pubblico:
SELECT
fullVisitorId,
date,
ARRAY_AGG(v2ProductName) AS products_viewed,
ARRAY_AGG(pageTitle) AS pages_viewed
FROM `data-to-insights.ecommerce.all_sessions`
WHERE visitId = 1501570398
GROUP BY fullVisitorId, date
ORDER BY date
Fai clic su Esegui e osserva i risultati.
Ora utilizziamo la funzione ARRAY_LENGTH() per contare il numero di pagine e il numero di prodotti visualizzati:
SELECT
fullVisitorId,
date,
ARRAY_AGG(v2ProductName) AS products_viewed,
ARRAY_LENGTH(ARRAY_AGG(v2ProductName)) AS num_products_viewed,
ARRAY_AGG(pageTitle) AS pages_viewed,
ARRAY_LENGTH(ARRAY_AGG(pageTitle)) AS num_pages_viewed
FROM `data-to-insights.ecommerce.all_sessions`
WHERE visitId = 1501570398
GROUP BY fullVisitorId, date
ORDER BY date
Adesso deduplichiamo le pagine e i prodotti, per determinare il numero dei prodotti univoci visualizzati. Basta aggiungere DISTINCT alla funzione ARRAY_AGG():
SELECT
fullVisitorId,
date,
ARRAY_AGG(DISTINCT v2ProductName) AS products_viewed,
ARRAY_LENGTH(ARRAY_AGG(DISTINCT v2ProductName)) AS distinct_products_viewed,
ARRAY_AGG(DISTINCT pageTitle) AS pages_viewed,
ARRAY_LENGTH(ARRAY_AGG(DISTINCT pageTitle)) AS distinct_pages_viewed
FROM `data-to-insights.ecommerce.all_sessions`
WHERE visitId = 1501570398
GROUP BY fullVisitorId, date
ORDER BY date
Riepilogo
Gli array consentono di eseguire alcune operazioni molto interessanti, ad esempio:
Determinare il numero di elementi, con ARRAY_LENGTH(<array>).
Deduplicare gli elementi, con ARRAY_AGG(DISTINCT <field>).
Ordinare gli elementi, con ARRAY_AGG(<field> ORDER BY <field>).
Limitare ARRAY_AGG(<field> LIMIT 5).
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Crea alcuni array con la funzione ARRAY_AGG().
Attività 4: esegui query sui set di dati che contengono già ARRAY
Il set di dati pubblico di BigQuery per Google Analytics, bigquery-public-data.google_analytics_sample, contiene molti più campi e righe, rispetto al set di dati data-to-insights.ecommerce.all_sessions del nostro corso. Soprattutto, contiene già valori di campo come prodotti, pagine e transazioni, archiviati in modo nativo come ARRAY.
Copia e incolla la query riportata di seguito per esplorare i dati disponibili e verifica se riesci a trovare i campi con valori ripetuti (array):
SELECT
*
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
WHERE visitId = 1501570398
Esegui la query.
Nei risultati, scorri verso destra finché non vedi il campo hits.product.v2ProductName (gli alias dei campi multipli verranno descritti più avanti).
Il numero dei campi disponibili nello schema di Google Analytics può essere eccessivo per la nostra analisi. Limitiamoci a eseguire query sui campi delle visite e dei nomi delle pagine, come abbiamo fatto prima:
SELECT
visitId,
hits.page.pageTitle
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
WHERE visitId = 1501570398
Viene visualizzato il messaggio di errore:
Cannot access field page on a value with type ARRAY<STRUCT<hitNumber INT64, time INT64, hour INT64, ...>> at [3:8].
Di norma, prima di eseguire query sui campi ripetuti (array), devi scomporre nuovamente gli array in righe.
Ad esempio, l'array di hits.page.pageTitle è attualmente memorizzato sotto forma di riga singola, come:
['homepage','product page','checkout']
ma noi dobbiamo convertirlo in:
['homepage',
'product page',
'checkout']
Come possiamo farlo con SQL?
Risposta: utilizzando la funzione UNNEST() sul campo che contiene l'array:
SELECT DISTINCT
visitId,
h.page.pageTitle
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`,
UNNEST(hits) AS h
WHERE visitId = 1501570398
LIMIT 10
La funzione UNNEST() verrà descritta in maggior dettaglio più avanti. Per il momento, devi solo sapere che:
Devi eseguire UNNEST() sugli array per ridisporre gli elementi su righe.
La funzione UNNEST() segue sempre il nome della tabella nella clausola FROM (concettualmente, è simile a una tabella sottoposta a join preliminare).
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Esegui query sui set di dati che contengono già ARRAY.
Attività 5: introduzione agli STRUCT
Probabilmente hai pensato che l'alias del campo hit.page.pageTitle sembra formato da tre nomi di campo separati da punti. Mentre i valori di tipo ARRAY offrono la possibilità di suddividere il contenuto dei campi per aumentarne la granularità, esiste un altro tipo di dati che consente di aggregarli nello schema, raggruppando i campi correlati. Si tratta del tipo di dati SQL STRUCT.
Per semplicità, il tipo di dati STRUCT può essere visto come una tabella separata sottoposta a join preliminare all'interno della tabella principale.
Uno STRUCT può presentare:
Uno o più campi al suo interno.
Tipi di dati uguali o diversi per ogni campo.
Un alias proprio.
Assomiglia a una tabella, vero?
Esploriamo un set di dati che contiene alcuni STRUCT
Nel riquadro Spazio di esplorazione, trova il set di dati bigquery-public-data.
Se non è già presente, fai clic su + Aggiungi dati > Aggiungi un progetto a Speciali per nome.
Inserisci bigquery-public-data e fai clic su Aggiungi a Speciali.
Fai clic su bigquery-public-data nell'elenco dei progetti fissato, per espanderlo.
Trova e apri google_analytics_sample.
Fai clic sulla tabella ga_sessions.
Inizia a scorrere lo schema e rispondi alla domanda seguente, utilizzando la funzionalità di ricerca del browser (ovvero, CTRL + F). Suggerimento: prima di iniziare il conteggio, espandi tutte le colonne.
Come puoi immaginare, per un moderno sito web di e-commerce viene archiviata un'enorme quantità di dati di sessione. Il vantaggio principale di avere 32 STRUCT in una singola tabella è costituito dal fatto che consente di eseguire query come questa senza utilizzare alcun JOIN:
SELECT
visitId,
totals.*,
device.*
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
WHERE visitId = 1501570398
LIMIT 10
Nota: la sintassi ".*" chiede a BigQuery di restituire tutti i dati per lo STRUCT, come se totals.* fosse una tabella separata sottoposta a join.
Memorizzando come STRUCT ("tabelle" sottoposte a join preliminare) e ARRAY (granularità superiore) le tabelle report di grandi dimensioni, hai la possibilità di:
Aumentare notevolmente le prestazioni, evitando di eseguire 32 JOIN di tabelle.
Recuperare dati granulari dagli ARRAY quando necessario, senza subire alcuna penalizzazione se non lo fai (BigQuery memorizza le singole colonne separatamente sul disco).
Aggregare tutti i contesti di business in una singola tabella, evitando di preoccuparti delle chiavi di JOIN e di conoscere le tabelle contenenti i dati che ti servono.
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Esplora un set di dati contenente vari STRUCT.
Attività 6: esercitati con gli STRUCT e gli ARRAY
Il set di dati successivo contiene i tempi intermedi dei corridori su una pista. Ogni giro prende il nome di "split".
Questa query consente di sperimentare la sintassi STRUCT e osservare i diversi tipi di campi all'interno del container struct:
#standardSQL
SELECT STRUCT("Rudisha" as name, 23.4 as split) as runner
Row
runner.name
runner.split
1
Rudisha
23.4
Noti qualche cosa di particolare negli alias dei campi? Poiché lo struct contiene campi nidificati (name e split sono sottoinsiemi di runner), ti ritrovi con una notazione puntata.
Ma cosa faresti se un corridore avesse più tempi intermedi per una singola corsa (come un tempo per ogni giro)?
Utilizzeresti un array, ovviamente! Per verificarlo, esegui questa query:
#standardSQL
SELECT STRUCT("Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as splits) AS runner
Row
runner.name
runner.splits
1
Rudisha
23.4
26.3
26.4
26.1
Riepilogo:
Gli struct sono container in cui possono essere annidati più nomi di campi e tipi di dati.
Gli array possono contenere solo dati dello stesso tipo, all'interno di uno struct (come mostrato sopra con i campi splits).
Esercitati nell'importazione di dati JSON
Crea un nuovo set di dati con titolo racing.
Crea una nuova tabella dati con titolo race_results.
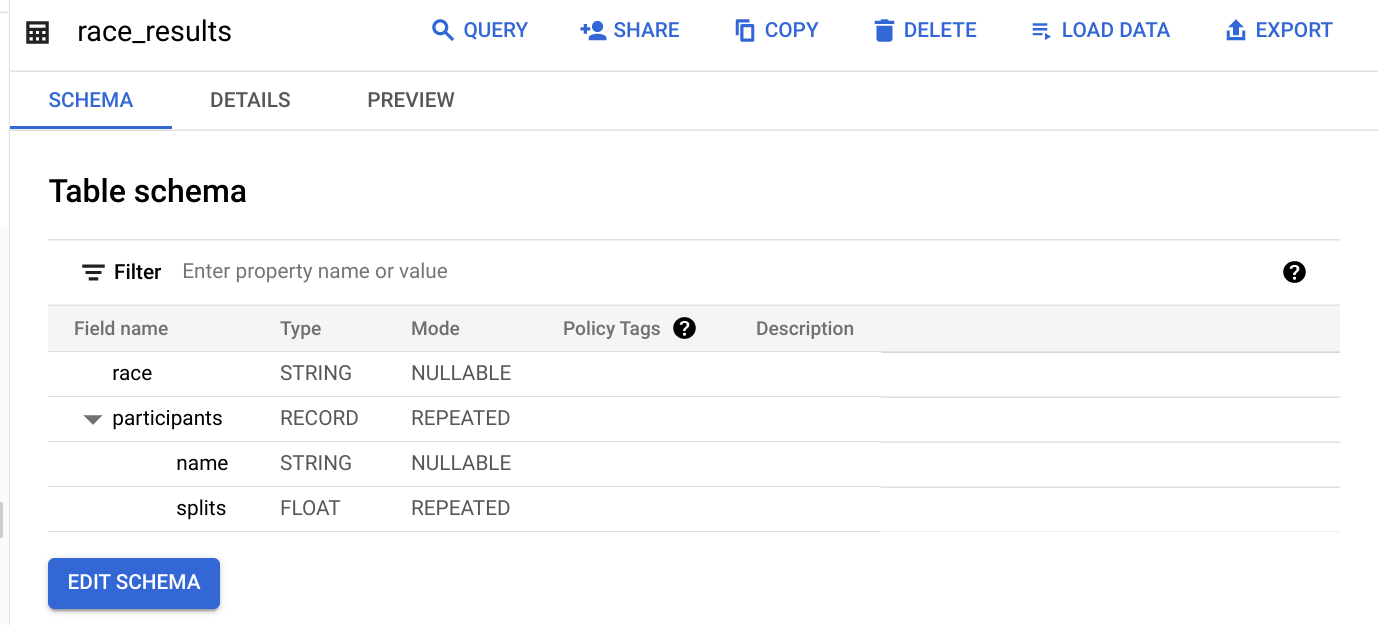
Terminato il job di caricamento, visualizza un'anteprima dello schema per la tabella che hai appena creato:
Qual è il campo di tipo STRUCT? Come fai a riconoscerlo?
Il campo di tipo STRUCT è participants, perché è di tipo RECORD.
Qual è il campo di tipo ARRAY?
Il campo participants.splits è un array di numeri in virgola mobile all'interno dello struct participants padre. La modalità REPEATED indica che si tratta di un array. I valori di questo array sono denominati valori nidificati, perché sono più valori all'interno di un singolo campo.
Esercitati a eseguire query sui campi nidificati e ripetuti
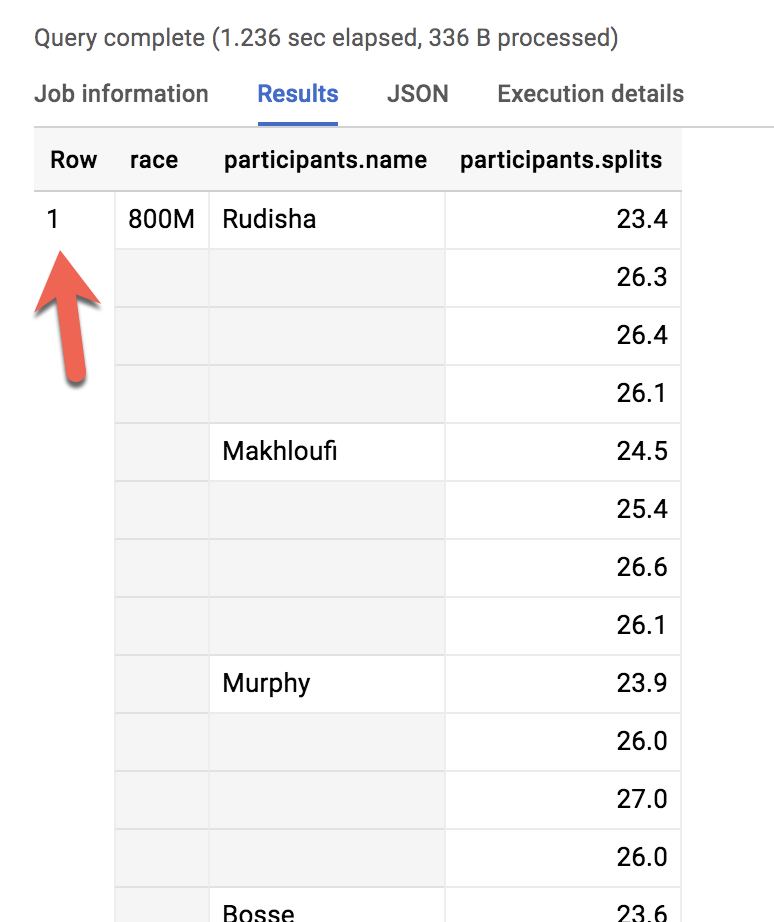
Visualizziamo tutti i partecipanti alla gara degli 800 metri:
#standardSQL
SELECT * FROM racing.race_results
Quante sono le righe restituite?
Risposta: 1
Cosa dovresti fare per elencare i nomi dei singoli corridori insieme al tipo di gara?
Esegui questo schema e osserva quello che succede:
#standardSQL
SELECT race, participants.name
FROM racing.race_results
Error: Cannot access field name on a value with type ARRAY<STRUCT<name STRING, splits ARRAY<FLOAT64>>> at [2:27].
Come avviene quando si dimentica di usare GROUP BY con le funzioni di aggregazione, in questo caso ci sono due livelli di granularità diversi, ovvero una riga per il tipo di gara e tre righe per i nomi dei partecipanti. Quindi, come lo modifichi da così…
Row
race
participants.name
1
800M
Rudisha
2
???
Makhloufi
3
???
Murphy
… a così:
Row
race
participants.name
1
800M
Rudisha
2
800M
Makhloufi
3
800M
Murphy
Nel tradizionale codice SQL relazionale, se avessi una tabella con le gare e una con i partecipanti, cosa faresti per estrarre informazioni da entrambe? Le aggregheresti con un JOIN. In questo caso lo STRUCT dei partecipanti (che concettualmente è molto simile a una tabella) fa già parte della tabella delle gare, ma non è ancora correttamente correlato con il campo "race", che non è di tipo STRUCT.
Quale comando SQL di due parole potresti usare per correlare la gara degli 800 metri a ciascuno dei corridori nella prima tabella?
Risposta: CROSS JOIN
Bene.
Ora proviamo a eseguire questo codice:
#standardSQL
SELECT race, participants.name
FROM racing.race_results
CROSS JOIN
participants # this is the STRUCT (it's like a table within a table)
Error: Table "participants" must be qualified with a dataset (e.g. dataset.table).
Anche se lo STRUCT dei partecipanti è simile a una tabella, tecnicamente è ancora un campo della tabella racing.race_results.
Aggiungi il nome del set di dati alla query:
#standardSQL
SELECT race, participants.name
FROM racing.race_results
CROSS JOIN
race_results.participants # full STRUCT name
Fai clic su Esegui.
Ottimo! Hai correttamente elencato tutti i partecipanti a ogni gara.
Row
race
name
1
800M
Rudisha
2
800M
Makhloufi
3
800M
Murphy
4
800M
Bosse
5
800M
Rotich
6
800M
Lewandowski
7
800M
Kipketer
8
800M
Berian
Per semplificare l'ultima query, puoi:
Aggiungere un alias alla tabella originale.
Sostituire le parole "CROSS JOIN" con una virgola (la virgola è un cross join implicito).
In questo modo ottieni lo stesso risultato della query precedente:
#standardSQL
SELECT race, participants.name
FROM racing.race_results AS r, r.participants
Se avessi più tipi di gara (800M, 100M, 200M), un CROSS JOIN non si limiterebbe ad associare il nome di ogni partecipante a tutte le gare possibili, come un prodotto cartesiano?
Risposta: no, questo è un cross join correlato, che separa solo gli elementi associati a una singola riga. Per informazioni più dettagliate, vedi Utilizzo degli ARRAY e degli STRUCT.
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Esercitati con gli STRUCT e gli ARRAY.
Riepilogo degli STRUCT
In SQL uno STRUCT è semplicemente un container di altri campi dati, che possono essere di tipo diverso. La parola struct significa struttura di dati. Nel caso dell'esempio precedente:
STRUCT("Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as splits) AS runner.
Agli STRUCT viene assegnato un alias (come runner, nell'esempio sopra). Concettualmente, possono essere visti come una tabella all'interno della tabella principale.
Per poter operare sugli elementi degli STRUCT (e degli ARRAY) devi prima separarli. Per separare lo struct stesso, o il campo dello struct costituito da un array, allo scopo di elencarne i dati linearmente, devi inserirne il nome in una funzione UNNEST().
Attività 7: domanda del lab - STRUCT()
Rispondi alle domande che seguono utilizzando la tabella racing.race_results che hai creato in precedenza.
Attività: scrivi una query per contare (mediante COUNT) il numero totale dei partecipanti.
Comincia dalla query parziale riportata di seguito:
#standardSQL
SELECT COUNT(participants.name) AS racer_count
FROM racing.race_results
Nota: ricorda che devi eseguire il cross join del nome dello struct come origine dati aggiuntiva dopo la clausola FROM.
Possibile soluzione:
#standardSQL
SELECT COUNT(p.name) AS racer_count
FROM racing.race_results AS r, UNNEST(r.participants) AS p
Row
racer_count
1
8
Risposta: alla gara hanno partecipato 8 corridori.
Attività 8: domanda del lab - Uso di UNNEST( ) per la separazione degli ARRAY
Scrivi una query che elenca il tempo totale della gara per i corridori il cui nome inizia con la lettera R. Ordina i risultati a partire dal tempo più veloce. Usa l'operatore UNNEST() e inizia dalla query parziale riportata di seguito.
Completa la query:
#standardSQL
SELECT
p.name,
SUM(split_times) as total_race_time
FROM racing.race_results AS r
, r.participants AS p
, p.splits AS split_times
WHERE
GROUP BY
ORDER BY
;
Note:
Dovrai separare sia lo struct che l'array all'interno dello struct come origini dati, dopo la clausola FROM.
Assicurati di usare gli alias, ove appropriato.
Possibile soluzione:
#standardSQL
SELECT
p.name,
SUM(split_times) as total_race_time
FROM racing.race_results AS r
, UNNEST(r.participants) AS p
, UNNEST(p.splits) AS split_times
WHERE p.name LIKE 'R%'
GROUP BY p.name
ORDER BY total_race_time ASC;
Row
name
total_race_time
1
Rudisha
102.19999999999999
2
Rotich
103.6
Attività 9: domanda del lab - Filtraggio dei valori di un ARRAY
Hai notato che il tempo intermedio più veloce per la gara degli 800 metri è stato di 23,2 secondi, ma non hai visto quale corridore ha registrato questo tempo. Crea una query che restituisce questo risultato.
Attività: completa la query parziale riportata di seguito:
#standardSQL
SELECT
p.name,
split_time
FROM racing.race_results AS r
, r.participants AS p
, p.splits AS split_time
WHERE split_time = ;
Possibile soluzione:
#standardSQL
SELECT
p.name,
split_time
FROM racing.race_results AS r
, UNNEST(r.participants) AS p
, UNNEST(p.splits) AS split_time
WHERE split_time = 23.2;
Row
name
split_time
1
Kipketer
23.2
Complimenti!
Hai correttamente importato set di dati JSON, creato ARRAY e STRUCT, e separato dati semistrutturati per ricavare gli insight.
Copyright 2026 Google LLC Tutti i diritti riservati. Google e il logo Google sono marchi di Google LLC. Tutti gli altri nomi di società e prodotti sono marchi delle rispettive società a cui sono associati.
Prima di iniziare
I lab creano un progetto e risorse Google Cloud per un periodo di tempo prestabilito
I lab hanno un limite di tempo e non possono essere messi in pausa. Se termini il lab, dovrai ricominciare dall'inizio.
In alto a sinistra dello schermo, fai clic su Inizia il lab per iniziare
Utilizza la navigazione privata
Copia il nome utente e la password forniti per il lab
Fai clic su Apri console in modalità privata
Accedi alla console
Accedi utilizzando le tue credenziali del lab. L'utilizzo di altre credenziali potrebbe causare errori oppure l'addebito di costi.
Accetta i termini e salta la pagina di ripristino delle risorse
Non fare clic su Termina lab a meno che tu non abbia terminato il lab o non voglia riavviarlo, perché il tuo lavoro verrà eliminato e il progetto verrà rimosso
Questi contenuti non sono al momento disponibili
Ti invieremo una notifica via email quando sarà disponibile
Bene.
Ti contatteremo via email non appena sarà disponibile
Un lab alla volta
Conferma per terminare tutti i lab esistenti e iniziare questo
Utilizza la navigazione privata per eseguire il lab
Il modo migliore per eseguire questo lab è utilizzare una finestra del browser in incognito o privata. Ciò evita eventuali conflitti tra il tuo account personale e l'account studente, che potrebbero causare addebiti aggiuntivi sul tuo account personale.
In questo lab imparerai a utilizzare i dati semistrutturati (importazione di tipi di dati per array JSON) all'interno di BigQuery. Ti eserciterai a caricare, interrogare e denidificare vari set di dati semistrutturati, risolvendo anche i problemi relativi.
Durata:
Configurazione in 0 m
·
Accesso da 60 m
·
Completamento in 60 m