Vertex AI is now Gemini Enterprise Agent Platform! We are currently updating our content to reflect this change. Please bear with us if you encounter naming inconsistencies during this transition.
Aplica tus habilidades en la consola de Google Cloud
Puntos de control
Create a new dataset and load JSON data into the table
Revisar mi progreso
/ 20
Creating arrays with ARRAY_AGG()
Revisar mi progreso
/ 20
Querying datasets that already have ARRAYs
Revisar mi progreso
/ 20
Explore a dataset with STRUCTs
Revisar mi progreso
/ 20
Practice with STRUCTs and ARRAYs
Revisar mi progreso
/ 20
Create a new dataset and load JSON data into the table
Revisar mi progreso
/ 20
Creating arrays with ARRAY_AGG()
Revisar mi progreso
/ 20
Querying datasets that already have ARRAYs
Revisar mi progreso
/ 20
Explore a dataset with STRUCTs
Revisar mi progreso
/ 20
Practice with STRUCTs and ARRAYs
Revisar mi progreso
/ 20
Es posible que este lab incorpore herramientas de IA para facilitar tu aprendizaje.
Descripción general
BigQuery es la base de datos analítica de bajo costo, no-ops y completamente administrada de Google. Con BigQuery, puedes consultar muchos terabytes de datos sin tener que administrar infraestructuras y sin necesitar un administrador de base de datos. Este producto usa SQL y puede aprovechar el modelo de pago por uso. Además, te permite enfocarte en el análisis de datos para buscar información valiosa.
En este lab, se explicará detalladamente cómo trabajar con datos semiestructurados (transferencia de archivos de tipo JSON y arrays) dentro de BigQuery. Desnormalizar tu esquema en una sola tabla con campos repetidos y anidados puede mejorar el rendimiento; no obstante, puede ser difícil usar la sintaxis de SQL para trabajar con arrays. Practicarás cómo cargar, consultar y desanidar diversos conjuntos de datos semiestructurados, además de cómo solucionar problemas en ellos.
Objetivos
En este lab, aprenderás a realizar lo siguiente:
Cómo cargar archivos JSON semiestructurados a BigQuery
Cómo crear y consultar arrays
Cómo crear y consultar structs
Cómo consultar campos repetidos y anidados
Configuración y requisitos
En cada lab, recibirá un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
Accede a Qwiklabs desde una ventana de incógnito.
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 1:15:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesita, puede reiniciar el lab, pero deberá hacerlo desde el comienzo.
Cuando esté listo, haga clic en Comenzar lab.
Anote las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
Haga clic en Abrir Google Console.
Haga clic en Usar otra cuenta, copie las credenciales para este lab y péguelas en el mensaje emergente que aparece.
Si usa otras credenciales, se generarán errores o incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación.
Abra BigQuery en Console
En la consola de Google Cloud, seleccione elmenú de navegación > BigQuery.
Se abrirá el cuadro de mensaje Te damos la bienvenida a BigQuery en la consola de Cloud, Contiene un vínculo a la guía de inicio rápido y enumera las actualizaciones de la IU.
Haga clic en Listo.
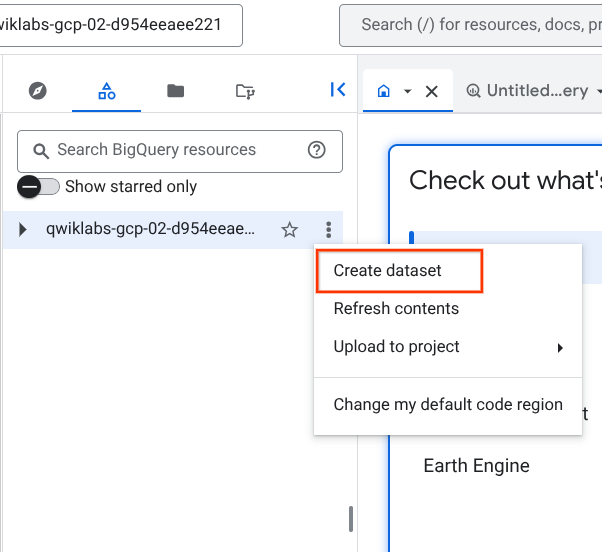
Tarea 1. Crea un conjunto de datos nuevo para almacenar nuestras tablas
Para crear un conjunto de datos, haz clic en el ícono de Ver acciones junto al ID de tu proyecto y selecciona Crear conjunto de datos.
Asígnale el nombre fruit_store al nuevo conjunto de datos. Deja todas las otras opciones en los valores predeterminados (Ubicación de los datos y Vencimiento predeterminado de la tabla).
Haz clic en Crear conjunto de datos.
Tarea 2. Practica cómo trabajar con arrays en SQL
Normalmente, en SQL, habrá un único valor para cada fila, como en esta lista de frutas:
Fila
Fruit
1
raspberry
2
blackberry
3
strawberry
4
cherry
¿Qué pasaría si quisieras tener una lista de frutas para cada persona que hay en la tienda? Tal vez se vería así:
Fila
Fruit
Person
1
raspberry
sally
2
blackberry
sally
3
strawberry
sally
4
cherry
sally
5
orange
frederick
6
apple
frederick
En una base de datos SQL relacional tradicional, tomarías la decisión de dividir la tabla en dos tablas diferentes de inmediato (Fruit y Person) al ver los nombres que se repiten. Ese proceso se denomina normalización (pasar de una tabla a muchas) y es un enfoque frecuente para bases de datos transaccionales como MySQL.
Para el almacenamiento de datos, los analistas de datos suelen hacer lo opuesto (desnormalización) y unen muchas tablas distintas para crear una gran tabla de informes.
Ahora, aprenderás un enfoque diferente que utiliza campos repetidos para almacenar datos con distintos niveles de detalle en una sola tabla:
Fila
Fruit (array)
Person
1
raspberry
sally
blackberry
strawberry
cherry
2
orange
frederick
apple
¿Qué tiene de extraño la tabla anterior?
Solo tiene dos filas.
Hay muchos valores de campo para Fruit en una sola fila.
Las personas y todos los valores de campo están asociados.
¿Cuál es la información clave? El tipo de datos array.
Esta es una forma más sencilla de interpretar el array Fruit:
Fila
Fruit (array)
Person
1
[raspberry, blackberry, strawberry, cherry]
sally
2
[orange, apple]
frederick
Ambas tablas son exactamente iguales. De aquí surgen dos aprendizajes clave:
Básicamente, un array es una lista de elementos entre corchetes [ ].
BigQuery muestra los arrays visualmente como acoplados. Solo ordena los valores del array verticalmente (ten en cuenta que todos esos valores siguen perteneciendo a una sola fila).
Compruébalo.
Ingresa lo siguiente en el editor de consultas de BigQuery:
#standardSQL
SELECT
['raspberry', 'blackberry', 'strawberry', 'cherry'] AS fruit_array
Haz clic en Ejecutar.
Ahora prueba ejecutar esta:
#standardSQL
SELECT
['raspberry', 'blackberry', 'strawberry', 'cherry', 1234567] AS fruit_array
Deberías ver un error parecido al siguiente:
Error: Array elements of types {INT64, STRING} do not have a common supertype at [3:1]
Los arrays solo pueden compartir un tipo de datos (todas las cadenas, todos los números).
Esta es la tabla final para ejecutar la consulta:
#standardSQL
SELECT person, fruit_array, total_cost FROM `data-to-insights.advanced.fruit_store`;
Haz clic en Ejecutar.
Después de ver los resultados, haz clic en la pestaña JSON para visualizar la estructura anidada de los resultados.
Cómo cargar archivos JSON semiestructurados a BigQuery
¿Te preguntas cómo puedes transferir un archivo JSON a BigQuery?
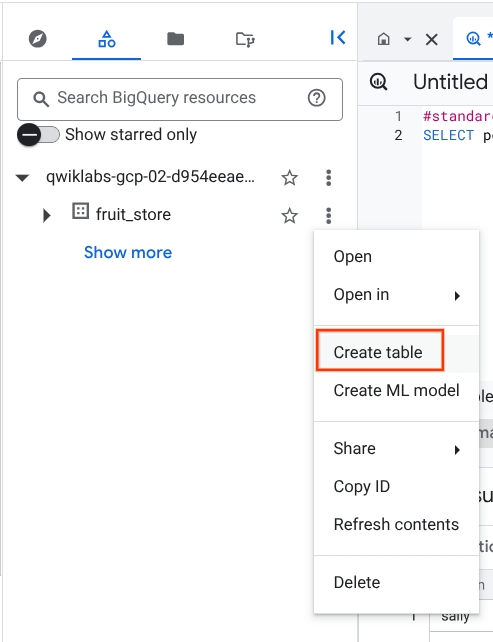
Crea una tabla nueva en el conjunto de datos fruit_store.
Para crear una tabla, haz clic en el ícono Ver acciones junto al conjunto de datos fruit_store y selecciona Crear tabla.
Agrega los siguientes detalles a la tabla:
Fuente: Selecciona Google Cloud Storage en el menú desplegable Crear tabla desde
Selecciona el archivo del bucket de GCS (escribe o pega lo siguiente): cloud-training/data-insights-course/labs/optimizing-for-performance/shopping_cart.json
Formato de archivo: JSONL (JSON delimitado por saltos de línea) {Esto se completará de forma automática}
Esquema: Verifica la detección automática (esquema y parámetros de entrada)
Asigna el nombre fruit_details a la nueva tabla.
Haz clic en Crear tabla.
En el esquema, observa que fruit_array está marcado como REPEATED, lo cual indica que es un array.
Resumen
BigQuery admite arrays de forma nativa.
Los valores de los arrays deben tener un mismo tipo de datos.
Los arrays se llaman campos REPETIDOS en BigQuery.
Haz clic en Revisar mi progreso para verificar el objetivo.
Crear un conjunto de datos nuevo y cargar datos de JSON en la tabla
Tarea 3. Crea tus propios arrays con ARRAY_AGG()
Si aún no tienes arrays en tus tablas, puedes crearlos.
Copia y pega la siguiente consulta para explorar este conjunto de datos público:
SELECT
fullVisitorId,
date,
v2ProductName,
pageTitle
FROM `data-to-insights.ecommerce.all_sessions`
WHERE visitId = 1501570398
ORDER BY date
Haz clic en Ejecutar y visualiza los resultados.
Ahora usaremos la función ARRAY_AGG() para agregar los valores de nuestra cadena a un array. Copia y pega la siguiente consulta para explorar este conjunto de datos público:
SELECT
fullVisitorId,
date,
ARRAY_AGG(v2ProductName) AS products_viewed,
ARRAY_AGG(pageTitle) AS pages_viewed
FROM `data-to-insights.ecommerce.all_sessions`
WHERE visitId = 1501570398
GROUP BY fullVisitorId, date
ORDER BY date
Haz clic en Ejecutar y visualiza los resultados.
A continuación, usaremos la función ARRAY_LENGTH() para contar la cantidad de páginas y productos que se visualizaron:
SELECT
fullVisitorId,
date,
ARRAY_AGG(v2ProductName) AS products_viewed,
ARRAY_LENGTH(ARRAY_AGG(v2ProductName)) AS num_products_viewed,
ARRAY_AGG(pageTitle) AS pages_viewed,
ARRAY_LENGTH(ARRAY_AGG(pageTitle)) AS num_pages_viewed
FROM `data-to-insights.ecommerce.all_sessions`
WHERE visitId = 1501570398
GROUP BY fullVisitorId, date
ORDER BY date
Anulemos ahora el duplicado de las páginas y los productos para ver cuántos productos únicos se visualizaron. Simplemente, agregaremos DISTINCT a nuestro ARRAY_AGG():
SELECT
fullVisitorId,
date,
ARRAY_AGG(DISTINCT v2ProductName) AS products_viewed,
ARRAY_LENGTH(ARRAY_AGG(DISTINCT v2ProductName)) AS distinct_products_viewed,
ARRAY_AGG(DISTINCT pageTitle) AS pages_viewed,
ARRAY_LENGTH(ARRAY_AGG(DISTINCT pageTitle)) AS distinct_pages_viewed
FROM `data-to-insights.ecommerce.all_sessions`
WHERE visitId = 1501570398
GROUP BY fullVisitorId, date
ORDER BY date
Resumen
Puedes hacer cosas muy útiles con los arrays, como las siguientes:
Calcular la cantidad de elementos con ARRAY_LENGTH(<array>)
Anular la duplicación de elementos con ARRAY_AGG(DISTINCT <field>)
Ordenar elementos con ARRAY_AGG(<field> ORDER BY <field>)
Limitar ARRAY_AGG(<field> LIMIT 5)
Haz clic en Revisar mi progreso para verificar el objetivo.
Crear arrays con ARRAY_AGG()
Tarea 4. Consulta conjuntos de datos que ya tienen ARRAYS
El conjunto de datos público de BigQuery para Google Analytics, bigquery-public-data.google_analytics_sample, tiene muchos más campos y filas que el conjunto de datos de nuestro curso, data-to-insights.ecommerce.all_sessions. Lo más importante es que ya almacena valores de campo, como productos, páginas y transacciones, de forma nativa como ARRAYS.
Copia y pega la siguiente consulta para explorar los datos disponibles y comprobar si puedes encontrar campos con valores repetidos (arrays):
SELECT
*
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
WHERE visitId = 1501570398
Ejecuta la consulta.
Desplázate hacia la derecha sobre los resultados hasta que veas el campo hits.product.v2ProductName (en breve hablaremos sobre los distintos alias de campo).
La cantidad de campos disponibles en el esquema de Google Analytics puede resultar excesivo para nuestro análisis. Intentemos consultar solo los campos de nombre de las visitas y las páginas como hicimos anteriormente:
SELECT
visitId,
hits.page.pageTitle
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
WHERE visitId = 1501570398
Verás el siguiente error:
Cannot access field page on a value with type ARRAY<STRUCT<hitNumber INT64, time INT64, hour INT64, ...>> at [3:8]
Para consultar campos REPEATED (arrays) normalmente, primero deberás volver a dividir los arrays en filas.
Por ejemplo, el array de hits.page.pageTitle está almacenado como una sola fila, de la siguiente manera:
['homepage','product page','checkout']
Necesitamos que se almacene de esta manera:
['homepage',
'product page',
'checkout']
¿Cómo lo hacemos con SQL?
Respuesta: Utiliza la función UNNEST() en el campo de array:
SELECT DISTINCT
visitId,
h.page.pageTitle
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`,
UNNEST(hits) AS h
WHERE visitId = 1501570398
LIMIT 10
Hablaremos sobre UNNEST() más adelante en detalle, pero, por ahora, debes saber lo siguiente:
Tienes que utilizar UNNEST() para desanidar los arrays y volver a organizar sus elementos en filas.
UNNEST() siempre aparece después del nombre de la tabla en tu cláusula FROM (piénsalo como una tabla previamente unida).
Haz clic en Revisar mi progreso para verificar el objetivo.
Consultar conjuntos de datos que ya tienen ARRAYS
Tarea 5. Introducción a los STRUCTS
Quizás te hayas preguntado por qué el alias de campo hit.page.pageTitle se ve como tres campos en uno, separados con puntos. Del mismo modo que los valores de los ARRAYS te otorgan flexibilidad para analizar en más profundidad el nivel de detalle de tus campos, otros tipos de datos te permiten ampliar el esquema agrupando campos relacionados. Ese tipo de datos SQL es el tipo de datos STRUCT.
La manera más fácil de pensar en un STRUCT es considerarlo una tabla separada que se unió previamente a tu tabla principal.
Un STRUCT puede tener lo siguiente:
Uno o muchos campos
Los mismos tipos de datos o tipos distintos de datos para cada campo
Su propio alias
Parece igual a una tabla, ¿verdad?
Exploremos un conjunto de datos con STRUCTS
Cambia al panel Explorador y haz clic en + Agregar datos > Destacar un proyecto por nombre.
Ingresa bigquery-public-data y haz clic en Destacar.
Haz clic en bigquery-public-data en la lista de proyectos fijados para expandirla.
Haz clic en Conjuntos de datos, busca y abre google_analytics_sample.
Haz clic en la tabla ga_sessions.
Nota: Selecciona cualquier tabla ga_sessions de la lista.
Comienza a desplazarte por el esquema y responde la siguiente pregunta usando la función de búsqueda en tu navegador (es decir, CTRL + F). Sugerencia: Expande todas las columnas antes de comenzar a contar.
Como puedes imaginar, hay una cantidad enorme de datos de sesión del sitio web almacenados para un sitio web moderno de comercio electrónico. La ventaja principal de tener 32 STRUCTS en una sola tabla es que te permite ejecutar consultas como esta sin tener que realizar UNIONES:
SELECT
visitId,
totals.*,
device.*
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
WHERE visitId = 1501570398
LIMIT 10
Nota: La sintaxis “.*” le indica a BigQuery que devuelva todos los campos para ese STRUCT (de la misma manera que lo haría si totals.* fuera una tabla independiente que unimos).
Almacenar tus tablas grandes de informes como STRUCTS (“tablas” previamente unidas) y ARRAYS (gran nivel de detalle) te permite hacer lo siguiente:
Evitar 32 UNIONES de tabla para obtener ventajas significativas en cuanto al rendimiento
Obtener datos detallados a partir de los ARRAYS cuando lo necesites, sin que haya consecuencias si no lo haces (BigQuery almacena cada columna de forma individual en el disco)
Tener todo el contexto comercial en una tabla, en lugar de preocuparte por las claves de UNIÓN y por recordar qué tablas tienen los datos que necesitas
Haz clic en Revisar mi progreso para verificar el objetivo.
Explorar un conjunto de datos con STRUCTS
Tarea 6. Practica con los STRUCTS y ARRAYS
El próximo conjunto de datos incluirá los tiempos de corredores en sus vueltas alrededor de una pista. A cada vuelta la llamaremos “fracción”.
Para esta consulta, prueba la sintaxis de STRUCT y observa los distintos tipos de campos dentro del contenedor de struct:
#standardSQL
SELECT STRUCT("Rudisha" as name, 23.4 as split) as runner
Fila
runner.name
runner.split
1
Rudisha
23.4
¿Qué puedes observar sobre los alias de campo? Puesto que el struct contiene campos anidados (los nombres y las fracciones son un subconjunto del corredor), se obtiene una notación de puntos.
¿Qué sucede si el corredor tiene varias fracciones de tiempo para una sola carrera (como el tiempo por vuelta)?
Usaremos un array, por supuesto. Ejecuta la siguiente consulta para confirmar esto:
#standardSQL
SELECT STRUCT("Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as splits) AS runner
Fila
runner.name
runner.splits
1
Rudisha
23.4
26.3
26.4
26.1
En resumen:
Los structs son contenedores que pueden tener varios tipos de datos y nombres de campos anidados.
Los arrays pueden ser uno de los tipos de campos dentro de un struct (como se mostró antes con el campo “fracciones”).
Practica transferir los datos de JSON
Cambia al panel Explorador clásico y crea un nuevo conjunto de datos llamado racing.
Crea una nueva tabla llamada race_results.
Transfiere este archivo JSON en Google Cloud Storage:
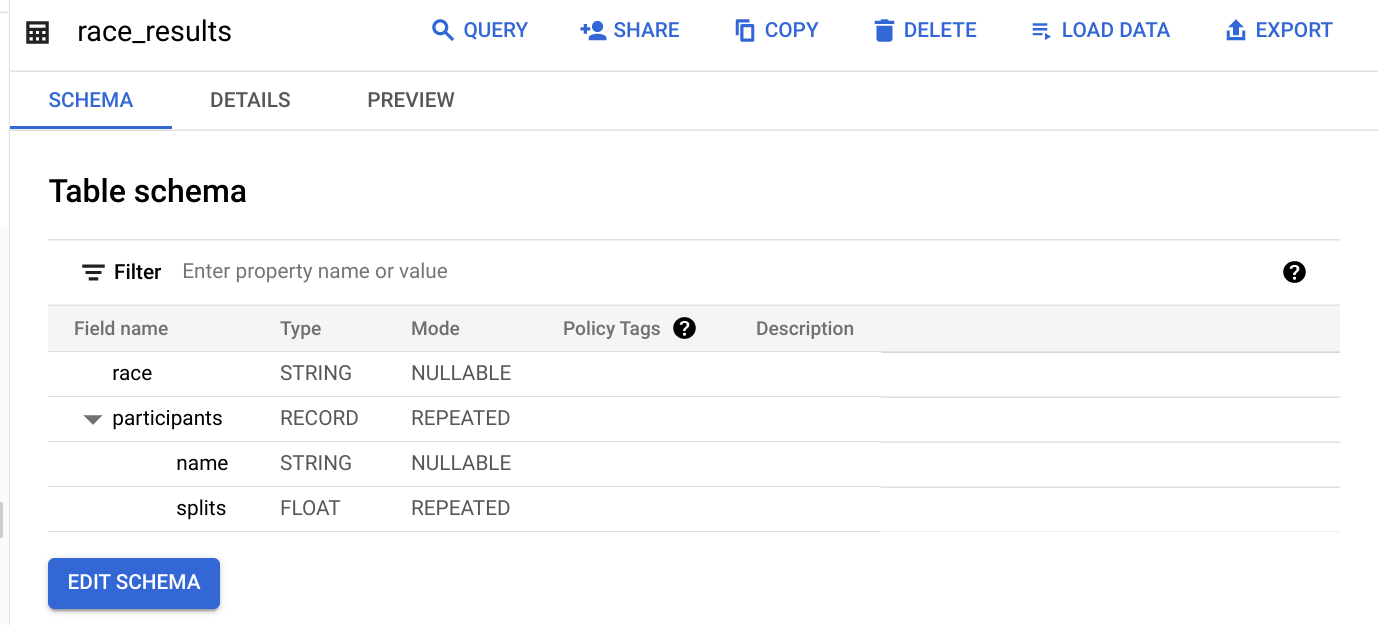
Una vez que se complete el trabajo de carga, obtén una vista previa del esquema de la tabla creada recientemente:
¿Cuál es el campo STRUCT? ¿Cómo lo sabes?
El campo participants es el STRUCT porque es del tipo RECORD.
¿Qué campo es el ARRAY?
El campo participants.splits es un array de números de punto flotante dentro del struct principal participants. Tiene un modo REPEATED, lo que indica que es un array. Los valores de este array se llaman valores anidados porque hay varios valores dentro de un solo campo.
Practica cómo consultar campos repetidos y anidados
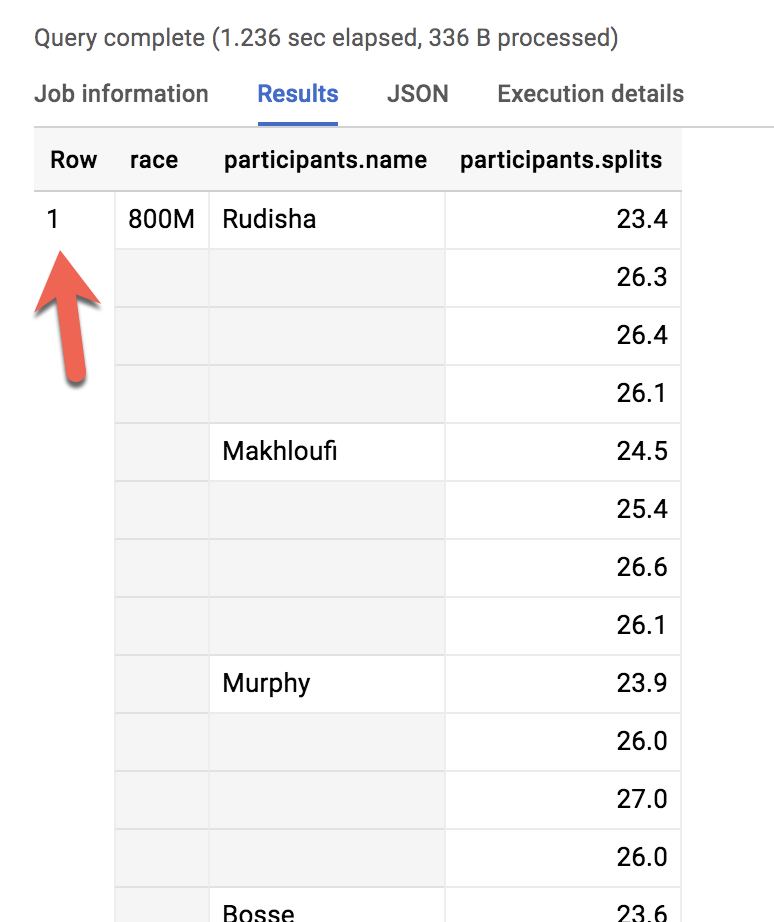
Veamos los tiempos de los corredores para la carrera de 800 metros:
#standardSQL
SELECT * FROM racing.race_results
¿Cuántas filas muestra la consulta?
Respuesta: 1
¿Qué pasaría si quisieras mostrar el nombre de cada corredor y el tipo de carrera?
Ejecuta el siguiente esquema y ve qué sucede:
#standardSQL
SELECT race, participants.name
FROM racing.race_results
Error: Cannot access field name on a value with type ARRAY<STRUCT<name STRING, splits ARRAY<FLOAT64>>> at [2:27]
Tal como sucede cuando olvidas la instrucción GROUP BY al usar funciones de agregación, aquí tenemos dos niveles de detalle diferentes: una fila para la carrera y tres filas para los nombres de los participantes. ¿Qué puedes hacer para cambiar esto…
Fila
race
participants.name
1
800 m
Rudisha
2
???
Makhloufi
3
???
Murphy
…por esto?
Fila
race
participants.name
1
800 m
Rudisha
2
800 m
Makhloufi
3
800 m
Murphy
En SQL relacional tradicional, si tuvieras una tabla de carreras y una de participantes, ¿qué harías para obtener información de ambas tablas? Las UNIRÍAS. El STRUCT de participantes (que es conceptualmente muy similar a una tabla) ya es parte de tu tabla de carreras, pero aún no se correlaciona correctamente con tu campo “race” que no pertenece al STRUCT.
¿Qué comando SQL de dos palabras usarías para correlacionar la carrera de 800 m con cada corredor de la primera tabla?
Respuesta: UNIÓN CRUZADA
Perfecto.
Ahora intenta ejecutar lo siguiente:
#standardSQL
SELECT race, participants.name
FROM racing.race_results
CROSS JOIN
participants # este es el STRUCT (es como una tabla dentro de una tabla)
Error: Table "participants" must be qualified with a dataset (e.g. dataset.table).
Si bien el struct de participantes es como una tabla, técnicamente sigue siendo un campo de la tabla racing.race_results.
Agrega el nombre del conjunto de datos a la consulta:
#standardSQL
SELECT race, participants.name
FROM racing.race_results
CROSS JOIN
race_results.participants # nombre completo del STRUCT
Haz clic en Ejecutar.
¡Guau! Mostraste correctamente la lista de todos los corredores de cada carrera.
Fila
race
name
1
800 m
Rudisha
2
800 m
Makhloufi
3
800 m
Murphy
4
800 m
Bosse
5
800 m
Rotich
6
800 m
Lewandowski
7
800 m
Kipketer
8
800 m
Berian
Para simplificar la última consulta, puedes hacer lo siguiente:
Agregar un alias para la tabla original
Reemplazar las palabras "CROSS JOIN" por una coma, ya que, implícitamente, realiza la unión cruzada
El resultado de la consulta será el mismo:
#standardSQL
SELECT race, participants.name
FROM racing.race_results AS r, r.participants
Si tienes más de un tipo de carrera (800 m, 100 m, 200 m), ¿una UNIÓN CRUZADA no asociaría el nombre de cada corredor con todas las carreras posibles como un producto cartesiano?
Respuesta: No. Esta es una unión cruzada correlacionada que solo descomprime los elementos asociados con una sola fila. Para obtener un análisis más detallado del tema, consulta cómo trabajar con ARRAYS y STRUCTS
Haz clic en Revisar mi progreso para verificar el objetivo.
Practicar con los STRUCT y ARRAYS
Resumen de los STRUCT:
Un STRUCT de SQL es básicamente un contenedor de otros campos de datos que pueden ser de distintos tipos. La palabra "struct" significa "estructura de datos". Recuerda el ejemplo que mencionamos antes:
STRUCT("Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as splits) AS runner
A los STRUCTS se les da un alias (como “runner” en el ejemplo anterior) y podemos entenderlos como una tabla dentro de una tabla principal.
Es necesario descomprimir los STRUCTS (y los ARRAYS) para poder usar sus elementos. Incluye UNNEST() junto al nombre del struct o del campo del struct que es un array para descomprimirlo y compactarlo.
Tarea 7. Pregunta del lab: STRUCT()
Usa la tabla racing.race_results que creaste anteriormente para responder la siguiente pregunta.
Tarea: Escribe una consulta para CONTAR cuántos corredores había en total.
Para comenzar, usa la siguiente consulta escrita parcialmente:
#standardSQL
SELECT COUNT(participants.name) AS racer_count
FROM racing.race_results
Nota: Recuerda que deberás realizar una unión cruzada en el nombre de tu struct como fuente adicional de datos después de FROM.
Solución posible:
#standardSQL
SELECT COUNT(p.name) AS racer_count
FROM racing.race_results AS r, UNNEST(r.participants) AS p
Fila
racer_count
1
8
Respuesta: 8 corredores participaron en la carrera.
Tarea 8. Pregunta del lab: Cómo descomprimir ARRAYS con UNNEST( )
Escribe una consulta que muestre una lista del tiempo total de carrera correspondiente a los corredores cuyos nombres comiencen con R. Ordena los resultados de modo que el mejor tiempo total aparezca primero. Usa el operador UNNEST() y comienza con la consulta escrita parcialmente que figura a continuación.
Completa la consulta:
#standardSQL
SELECT
p.name,
SUM(split_times) as total_race_time
FROM racing.race_results AS r
, r.participants AS p
, p.splits AS split_times
WHERE
GROUP BY
ORDER BY
;
Nota:
Deberás descomprimir el struct y el array dentro del struct como fuentes de datos después de la cláusula FROM.
Asegúrate de usar alias cuando corresponda.
Solución posible:
#standardSQL
SELECT
p.name,
SUM(split_times) as total_race_time
FROM racing.race_results AS r
, UNNEST(r.participants) AS p
, UNNEST(p.splits) AS split_times
WHERE p.name LIKE 'R%'
GROUP BY p.name
ORDER BY total_race_time ASC;
Fila
name
total_race_time
1
Rudisha
102.19999999999999
2
Rotich
103.6
Tarea 9. Pregunta del lab: Cómo filtrar valores de ARRAYS
Descubriste que el tiempo por vuelta más rápido registrado para la carrera de 800 m fue de 23.2 segundos, pero no viste qué corredor dio esa vuelta en particular. Crea una consulta que muestre ese resultado.
Tarea: Completa la consulta escrita parcialmente:
#standardSQL
SELECT
p.name,
split_time
FROM racing.race_results AS r
, r.participants AS p
, p.splits AS split_time
WHERE split_time = ;
Solución posible:
#standardSQL
SELECT
p.name,
split_time
FROM racing.race_results AS r
, UNNEST(r.participants) AS p
, UNNEST(p.splits) AS split_time
WHERE split_time = 23.2;
Fila
name
split_time
1
Kipketer
23.2
¡Felicitaciones!
Transferiste correctamente conjuntos de datos JSON, creaste ARRAYS y STRUCTS y desanidaste datos semiestructurados para obtener información.
Copyright 2026 Google LLC. Todos los derechos reservados. Google y el logotipo de Google son marcas de Google LLC. El resto de los nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que están asociados.
Antes de comenzar
Los labs crean un proyecto de Google Cloud y recursos por un tiempo determinado
.
Los labs tienen un límite de tiempo y no tienen la función de pausa. Si finalizas el lab, deberás reiniciarlo desde el principio.
En la parte superior izquierda de la pantalla, haz clic en Comenzar lab para empezar
Usa la navegación privada
Copia el nombre de usuario y la contraseña proporcionados para el lab
Haz clic en Abrir la consola en modo privado
Accede a la consola
Accede con tus credenciales del lab. Si usas otras credenciales, se generarán errores o se incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación
No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo, ya que se borrará tu trabajo y se quitará el proyecto
Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible
¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible
Un lab a la vez
Confirma para finalizar todos los labs existentes y comenzar este
Usa la navegación privada para ejecutar el lab
Usar una ventana de incógnito o de navegación privada es la mejor forma de ejecutar
este lab. Así evitarás cualquier conflicto entre tu cuenta personal
y la cuenta de estudiante, lo que podría generar cargos adicionales en
tu cuenta personal.
En este lab, trabajarás con datos semiestructurados (transferencia de datos de tipo JSON y arrays) dentro de BigQuery. También practicarás cómo cargar, consultar y desanidar diversos conjuntos de datos semiestructurados, además de cómo solucionar problemas en estos.
Duración:
0 min de configuración
·
Acceso por 60 min
·
60 min para completar