

![[実行] ボタン](https://cdn.qwiklabs.com/1g%2FDwAD49lqee1EVfuPMnaBW9nSBwBnqFk3jq9xH7a8%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します

このチュートリアルでは、Cloud Data Fusion の Wrangler 機能と Data Pipeline 機能を使用して、タクシーの走行データを詳細に分析するためにクリーニング、変換、処理を行う方法について説明します。
このラボでは、次の作業を行います。
データを分析して情報を取得するには、多くの場合、事前にいくつかの前処理を行う必要があります。たとえば、データ型の調整や異常値の削除が必要になる場合や、あいまいな識別子を区別しやすい識別子に変換する必要がある場合があります。Cloud Data Fusion は、ETL および ELT のデータ パイプラインを効率的に構築するためのサービスで、Cloud Dataproc クラスタを使用してパイプラインのすべての変換を実行します。
このチュートリアルでは、BigQuery の NYC TLC Taxi Trips データセットのサブセットを使って Cloud Data Fusion の使用方法を説明します。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
シークレット ウィンドウを使用して Google Skills にログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
Cloud Shell は、開発ツールが組み込まれた仮想マシンです。5 GB の永続ホーム ディレクトリを提供し、Google Cloud 上で実行されます。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。gcloud は Google Cloud のコマンドライン ツールで、Cloud Shell にプリインストールされており、Tab キーによる入力補完がサポートされています。
Google Cloud Console のナビゲーション パネルで、「Cloud Shell をアクティブにする」アイコン(
[次へ] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続の際に認証も行われ、プロジェクトは現在のプロジェクト ID に設定されます。次に例を示します。
有効なアカウント名前を一覧表示する:
(出力)
(出力例)
プロジェクト ID を一覧表示する:
(出力)
(出力例)
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] から確認できます。
アカウントが IAM に存在しない場合やアカウントに編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。
Google Cloud コンソールのナビゲーション メニューで、[Cloud の概要] をクリックします。
[プロジェクト情報] カードからプロジェクト番号をコピーします。
ナビゲーション メニューで、[IAM と管理] > [IAM] をクリックします。
IAM ページの上部にある [追加] をクリックします。
新しいプリンシパルの場合は、次のように入力します。
{project-number} はプロジェクト番号に置き換えてください。
[ロールを選択] で、[基本](または [Project])> [編集者] を選択します。
[保存] をクリックします。
Cloud Data Fusion インスタンスの詳細な作成手順については、Cloud Data Fusion インスタンスの作成ガイドをご覧ください。基本的な手順は次のとおりです。
オペレーションが正常に完了したことを示すメッセージが出力されます。
読み込まれた Cloud Data Fusion API ページで、[有効にする] をクリックします。
API が再度有効になると、ページが更新され、API を無効にするオプションと、API の使用状況やパフォーマンスについての詳細が表示されます。
ナビゲーション メニューで、[Data Fusion] を選択します。
[インスタンスを作成] をクリックして、Cloud Data Fusion インスタンスを作成します。
インスタンスの名前を入力します。
エディションには [Basic] を選択します。
[認可] セクションで [権限を付与] をクリックします。
その他の設定はすべてデフォルトのままにして、[作成] をクリックします。
注: インスタンスの作成には 15 分ほどかかります。
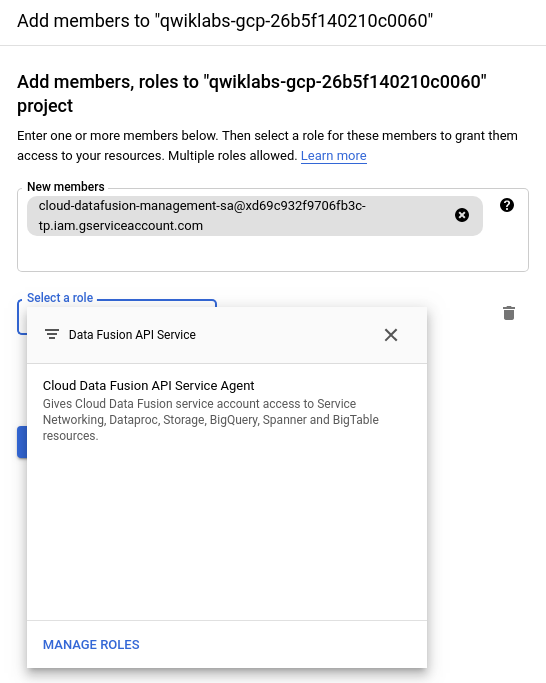
インスタンスが作成されたら、最後のステップとして、インスタンスに関連付けられたサービス アカウントにプロジェクトの権限を付与する必要があります。インスタンス名をクリックして、インスタンスの詳細ページに移動します。
サービス アカウントをクリップボードにコピーします。
Cloud コンソールで、[IAM と管理] > [IAM] に移動します。
IAM の権限ページで [追加] ボタンをクリックし、先ほどコピーしたサービス アカウントを新しいメンバーとして追加して、Cloud Data Fusion API サービス エージェントのロールを付与します。
Cloud Data Fusion インスタンスの準備ができたら Cloud Data Fusion を使い始めることができます。ただし、Cloud Data Fusion にデータを取り込む前にいくつかの準備作業を行う必要があります。
Wrangler はインタラクティブなビジュアル ツールです。データセット全体に大規模な並列処理ジョブをディスパッチする前に、データの小規模なサブセットで変換の効果を確認できます。Cloud Data Fusion UI で、[Wrangler] を選択します。左側に、Cloud Storage 接続など、データへの事前構成の接続が表示されたパネルがあります。
[Google Cloud Storage] の [Cloud Storage Default] を選択します。
プロジェクト名に対応するバケットをクリックします。
[ny-taxi-2018-sample.csv] を選択します。データが行と列の形式で Wrangler の画面に読み込まれます。
次に、いくつかの変換を実行してタクシーデータの解析とクリーニングを行います。
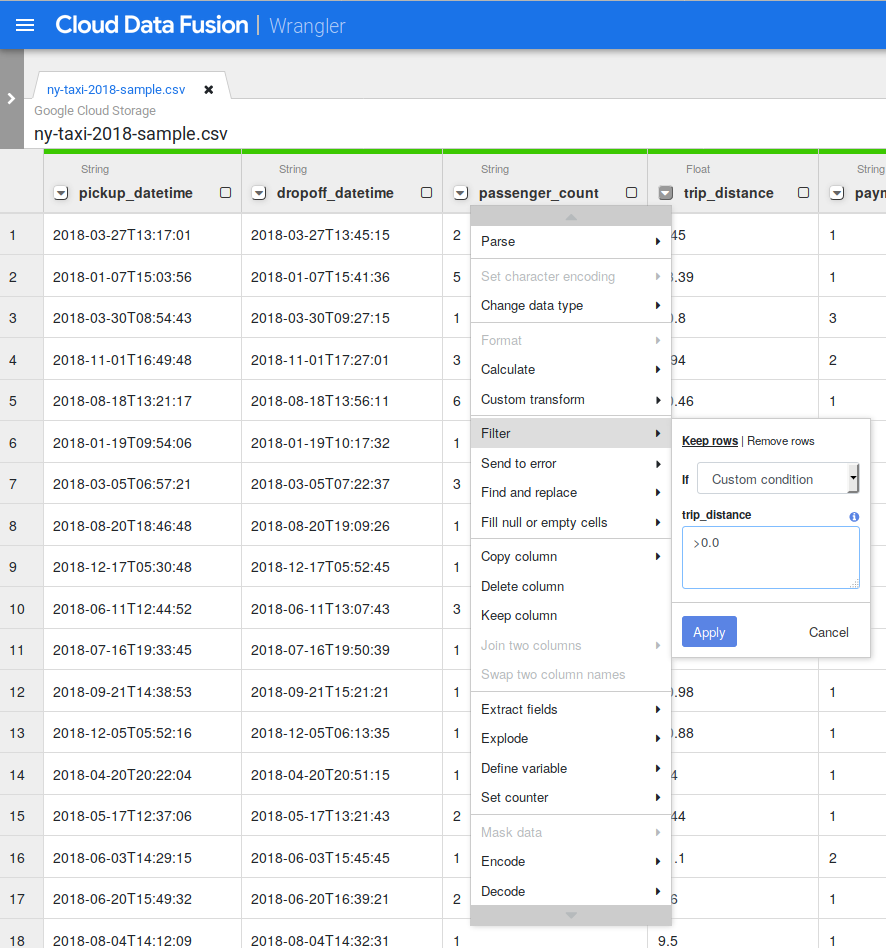
body 列の左側にある下矢印をクリックします。
[Parse] > [CSV] をクリックし、[Set first row as header] を選択して、[Apply] をクリックします。データが複数の列に分割されます。
body 列はもう必要ないため、body 列の隣にある下矢印をクリックし、[列を削除] を選択します。
すべての列が String 型として読み込まれているため、データ型を調整します。trip_distance 列の隣にある下矢印をクリックし、[Change data type] を選択して、[Float] をクリックします。同じ手順を total_amount 列に対して繰り返します。
データを細かく見ると異常値(負の値の移動距離など)が見つかることがあります。このような負の値は Wrangler ではフィルタで除外できます。trip_distance 列の隣にある下矢印をクリックし、[Filter] を選択します。[If] の後で [Custom condition] を選択し、「>0.0」と入力します。
基本的なデータ クレンジングが完了し、データのサブセットに対して変換を実行しました。これで、すべてのデータに対して変換を行うバッチ パイプラインを作成できます。
Cloud Data Fusion を使用すると、視覚的に構築されたパイプラインを Apache Spark または MapReduce のプログラムに変換して、Cloud Dataproc のエフェメラル クラスタで並行して変換を実施できます。これにより、インフラストラクチャやテクノロジーに煩わされることなく、スケーラブルかつ信頼性の高い方法で、膨大な量のデータに対して複雑な変換を簡単に行うことができます。
Cloud Data Fusion UI の右上から [Create a Pipeline] をクリックします。
表示されたダイアログで、[Batch pipeline] を選択します。
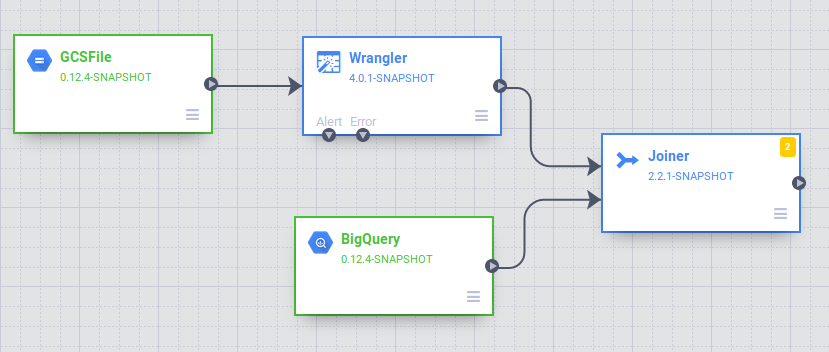
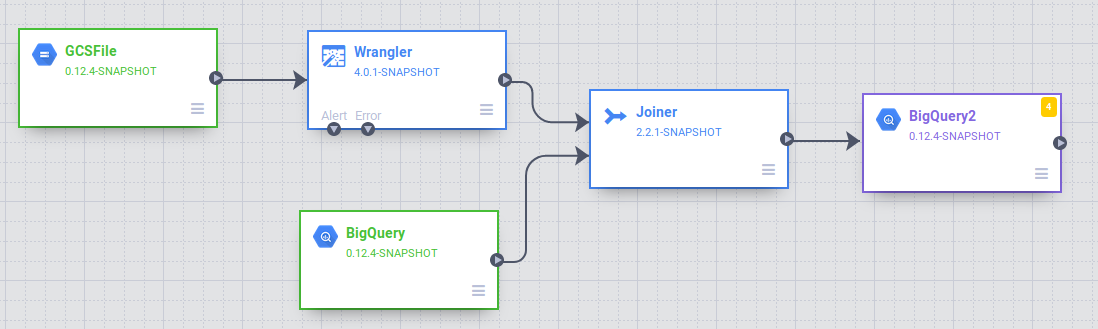
Data Pipelines UI で、Wrangler ノードに接続した GCSFile ソースノードが表示されます。Wrangler ノードには、Wrangler ビューで適用した変換がすべて含まれており、ディレクティブ法としてキャプチャされています。Wrangler ノードにカーソルを合わせて [プロパティ] を選択します。
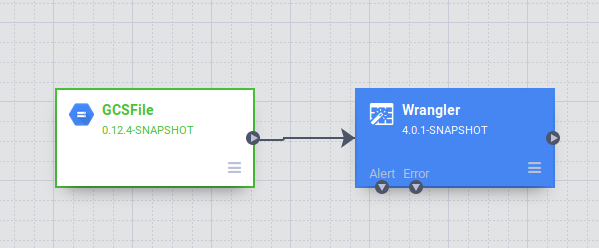
extra 列を削除します。右上にある [X] ボタンをクリックして Wrangler ツールを閉じます。タクシーデータには、そのまま分析に使用することが難しい列がいくつか含まれています(pickup_location_id など)。そのため、パイプラインにデータソースを追加して、pickup_location_id 列を該当する場所の名前にマッピングします。マッピング情報は BigQuery テーブルに保存します。
別のタブで、GCP コンソールの BigQuery UI を開きます。[Cloud コンソールの BigQuery へようこそ] ページで [完了] をクリックします。
BigQuery UI の [エクスプローラ] セクションで GCP Project ID(qwiklabs で始まるもの)の横の 3 つの点をクリックします。
表示されたメニューから [データセットを作成] リンクをクリックします。
[データセット ID] フィールドに「trips」と入力します。
[データセットを作成] をクリックします。
新しく作成したデータセットに目的のテーブルを作成するには、[展開] > [クエリ設定] に移動します。これにより、作成したテーブルに Cloud Data Fusion からアクセスできるようになります。
[クエリ結果の宛先テーブルを設定する] を選択します。さらに、[Table Id] に「zone_id_mapping」と入力します。[保存] をクリックします。
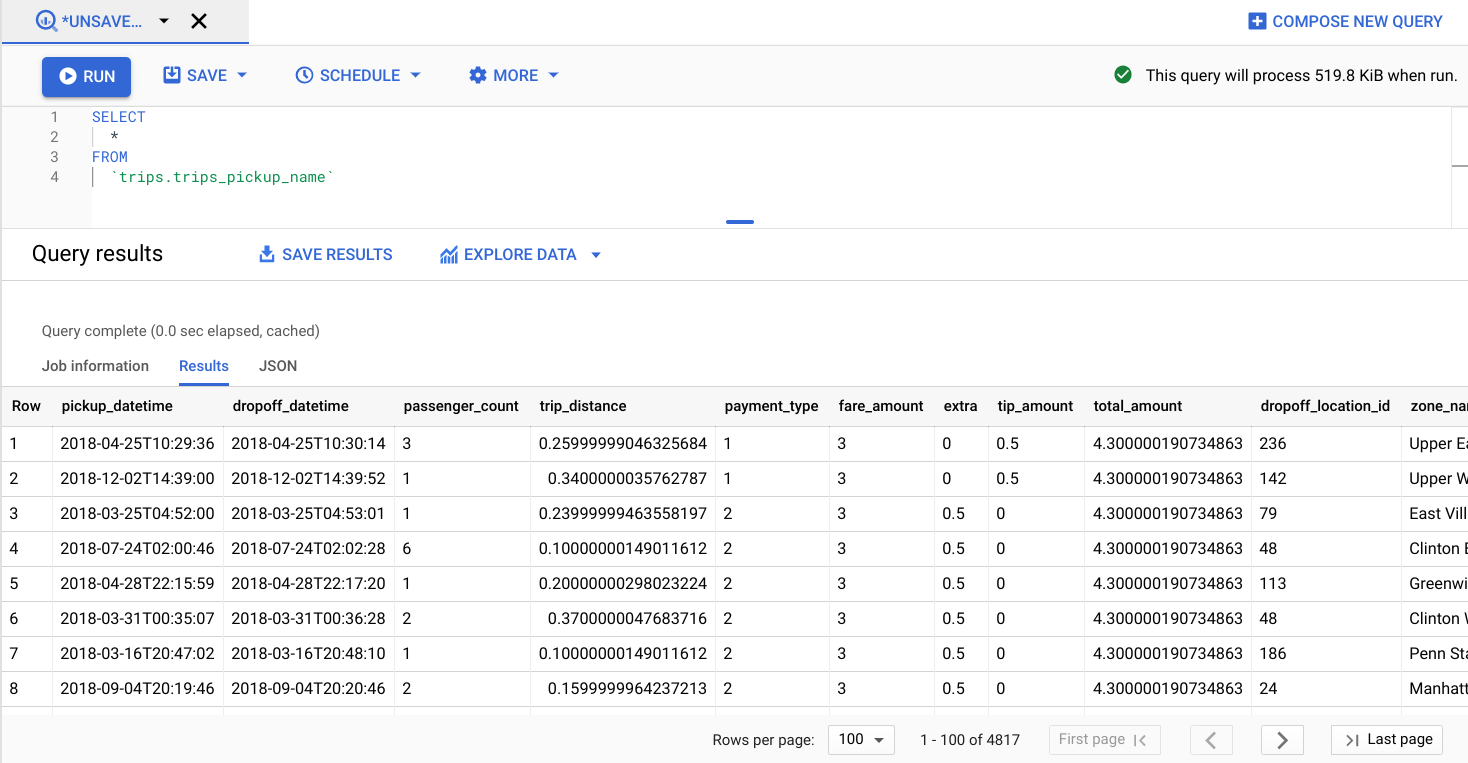
クエリエディタに次のクエリを入力し、[実行] をクリックします。
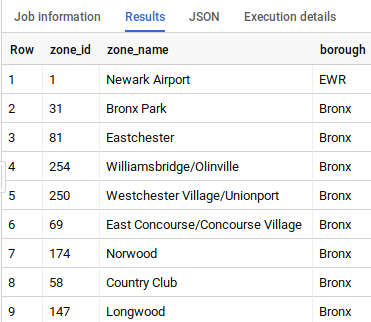
このテーブルには、zone_id からゾーンの名前や区画へのマッピング情報が含まれています。
次に、パイプラインにソースを追加して、この BigQuery テーブルにアクセスできるようにします。Cloud Data Fusion を開いたタブに戻り、左側にあるプラグイン パレットの [ソース] セクションで [BigQuery] ソースを選択します。BigQuery ソースノードが他の 2 つのノードとともにキャンバスに表示されます。
新しい BigQuery ソースノードにカーソルを合わせ、[Properties] をクリックします。
[Reference Name] は「zone_mapping」と入力して構成します。これは、このデータソースを系統立ててとらえるうえで使用されます。BigQuery の [Dataset] と [Table] は、BigQuery で設定したデータセットとテーブル(前の手順で作成した trips と zone_id_mapping)で構成します。[一時バケット名] には、プロジェクト名の末尾に「-temp」を付けた名前を入力します。これは、タスク 2 で作成したバケットの名前です。
[Get Schema] をクリックして、このテーブルのスキーマを BigQuery から反映します。ウィザードの右側にフィールドが表示されます。
右上隅の [X] ボタンをクリックして [BigQuery Properties] ウィンドウを閉じます。
これで、2 つのデータソース(タクシーの走行データとゾーン名)を結合して、より有意な出力を生成できるようになりました。
プラグイン パレットの [Analytics] セクションで [Joiner] を選択します。キャンバスに Joiner ノードが表示されます。
ソースノードの右端にある接続矢印 > を宛先ノードにドラッグ&ドロップして、Wrangler ノードと BigQuery ノードを Joiner ノードに接続します。
[Joiner] の [Properties] をクリックします。
ラベルは Joiner のままにします。
[Join Type] を [Inner] に変更します。
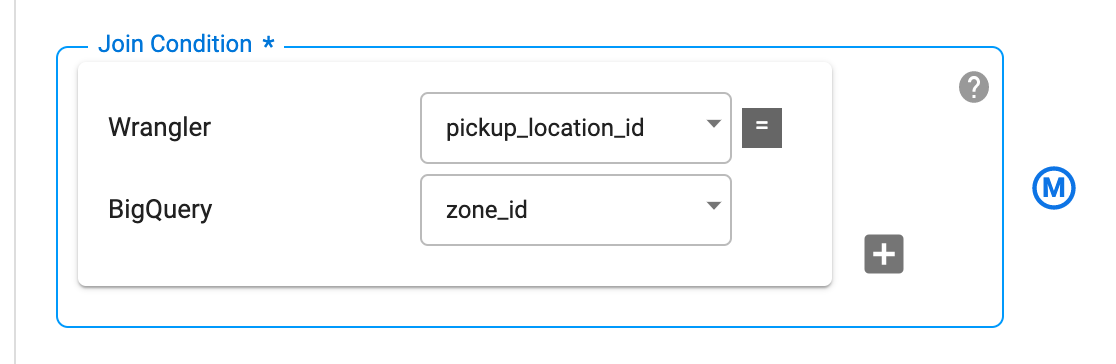
Wrangler ノードの pickup_location_id 列が BigQuery ノードの zone_id 列と結合されるように、[結合条件] を設定します。
[Get Schema] をクリックして、結合後のスキーマを生成します。
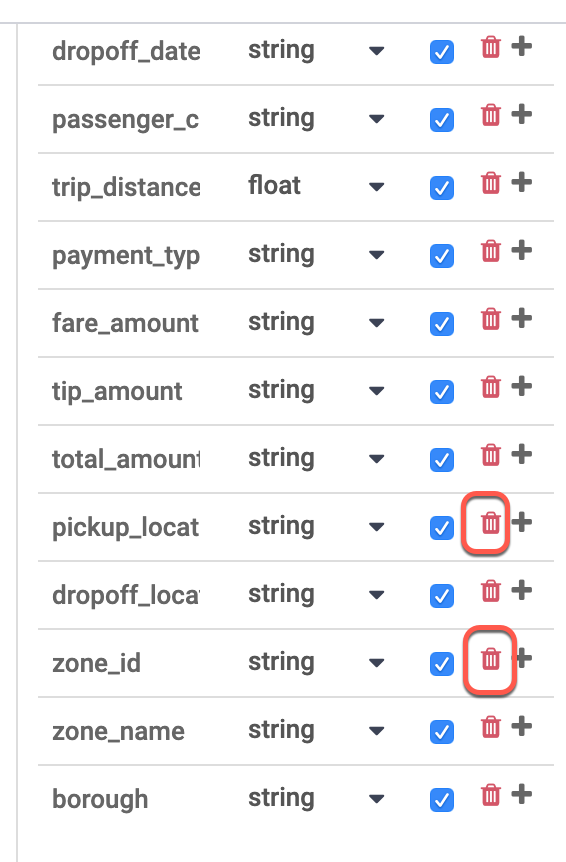
右側の [Output Schema] テーブルで、zone_id フィールドと pickup_location_id フィールドを削除します。赤いゴミ箱アイコンをクリックすると削除できます。
パイプラインの結果を BigQuery テーブルに保存します。データを格納する場所をシンクといいます。
プラグイン パレットの [Sink] セクションで [BigQuery] を選択します。
Joiner ノードを BigQuery ノードに接続します。ソースノードの適切なエッジから接続矢印 > をドラッグして宛先ノードでドロップします。
BigQuery ノードの上にカーソルを合わせ、[Properties] をクリックして開きます。次に、ノードを次に示すように構成します。既存のBigQuery ソースと同様な構成を使用します。[Reference Name] フィールドに「bq_insert」、[Dataset] に「trips」と入力し、[Temporary Bucket Name] にはプロジェクト名の末尾に「-temp」を付けたものを入力します。このパイプラインの実行により新しいテーブルが作成されます。このテーブルの名前として、[テーブル] フィールドに「trips_pickup_name」と入力します。
右上にある [X] ボタンをクリックしてウィンドウを閉じます。
最初のパイプラインの作成が完了したので、次はパイプラインをデプロイして実行します。
次に、パイプラインをデプロイします。ページの右上で [デプロイ] をクリックします。
次の画面で [実行] をクリックしてデータの処理を開始します。
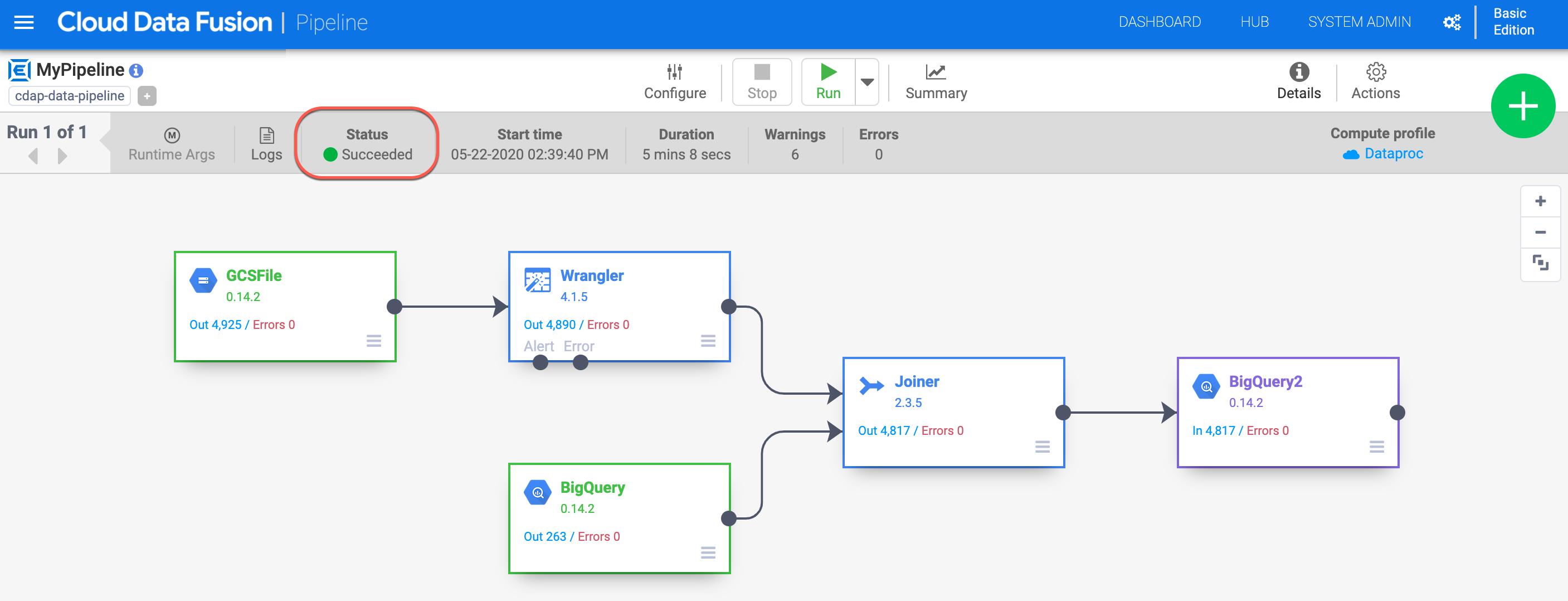
パイプラインを実行すると、Cloud Data Fusion は Cloud Dataproc のエフェメラル クラスタをプロビジョニングし、パイプラインを実行してクラスタを破棄します。これには数分かかることがあります。その間に、パイプラインのステータスが「プロビジョニング中」から「開始中」、「開始中」から「実行中」、「成功」に変わるのを確認できます。
パイプラインの実行後、次の手順で結果を確認します。
trips_pickup_name テーブルの値を確認します。BigQuery の結果
ラボでの学習が完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Qwiklabs から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバック、ご提案、修正が必要な箇所については、[サポート] タブからお知らせください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください