Este contenido aún no está optimizado para dispositivos móviles.
Para obtener la mejor experiencia, visítanos en una computadora de escritorio con un vínculo que te enviaremos por correo electrónico.
Descripción general
En este instructivo, se muestra cómo usar las funciones de Wrangler y de Data pipelines en Cloud Data Fusion a fin de limpiar, transformar y procesar datos de viajes en taxi para realizar más análisis.
Qué aprenderá
En este lab, aprenderá a hacer lo siguiente:
Conectar Cloud Data Fusion a un par de fuentes de datos
Aplicar transformaciones básicas
Unir dos fuentes de datos
Escribir datos en un receptor
Introducción
A menudo, los datos requieren varios pasos previos al procesamiento antes de que los analistas puedan aprovecharlos para recopilar estadísticas. Por ejemplo, podría ser necesario ajustar los tipos de datos, quitar anomalías y convertir los identificadores poco precisos en entradas más significativas. Cloud Data Fusion es un servicio para crear canalizaciones de datos ETL/ELT de forma eficiente. Cloud Data Fusion usa un clúster de Cloud Dataproc para realizar todas las transformaciones en la canalización.
El uso de Cloud Data Fusion se mostrará con un ejemplo en este instructivo, donde se usará un subconjunto de los datos de viajes en taxi de NYC TLC en BigQuery.
Configuración y requisitos
En cada lab, recibirás un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
Accede a Google Skills en una ventana de incógnito.
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 1:15:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesitas, puedes reiniciar el lab, pero deberás hacerlo desde el comienzo.
Cuando esté listo, haga clic en Comenzar lab.
Anote las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
Haga clic en Abrir Google Console.
Haga clic en Usar otra cuenta, copie las credenciales para este lab y péguelas en el mensaje emergente que aparece.
Si usas otras credenciales, se generarán errores o incurrirás en cargos.
Acepta las condiciones y omite la página de recursos de recuperación.
Active Cloud Shell
Cloud Shell es una máquina virtual que contiene herramientas de desarrollo y un directorio principal persistente de 5 GB. Se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a sus recursos de Google Cloud. gcloud es la herramienta de línea de comandos de Google Cloud, la cual está preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
En el panel de navegación de Google Cloud Console, haga clic en Activar Cloud Shell ().
Haga clic en Continuar.
El aprovisionamiento y la conexión al entorno tardan solo unos momentos. Una vez que se conecte, también estará autenticado, y el proyecto estará configurado con su PROJECT_ID. Por ejemplo:
Comandos de muestra
Si desea ver el nombre de cuenta activa, use este comando:
Si desea ver el ID del proyecto, use este comando:
gcloud config list project
(Resultado)
[core]
project = <project_ID>
(Resultado de ejemplo)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Verifica los permisos del proyecto
Antes de comenzar a trabajar en Google Cloud, asegúrate de que tu proyecto tenga los permisos correctos en Identity and Access Management (IAM).
En el Menú de navegación () de la consola de Google Cloud, haga clic en IAM y administración > IAM.
Confirma que aparezca la cuenta de servicio predeterminada de Compute {project-number}-compute@developer.gserviceaccount.com, y que tenga asignado el rol Editor. El prefijo de la cuenta es el número del proyecto, que puedes encontrar en el menú de navegación > Descripción general de Cloud.
Si no aparece la cuenta en IAM o no tiene asignado el rol Editor, sigue los pasos que se indican a continuación para asignar el rol necesario.
En la consola de Google Cloud, en el menú de navegación, haz clic en Descripción general de Cloud.
En la tarjeta Información del proyecto, copia el Número de proyecto.
En el menú de navegación, haz clic en IAM y administración > IAM.
En la parte superior de la página IAM, haga clic en Agregar.
Para asegurarse de que el entorno de entrenamiento está configurado correctamente, primero debe parar y reiniciar la API de Cloud Data Fusion. Ejecute en Cloud Shell el comando que se muestra a continuación. Tardará unos minutos en completarse.
gcloud services disable datafusion.googleapis.com
El resultado muestra un mensaje que indica que la operación finalizó correctamente.
A continuación, reinicia la conexión a la API de Cloud Data Fusion.
En la barra de búsqueda superior de la consola de Google Cloud, ingrese API de Cloud Data Fusion.
Haz clic en el resultado de API de Cloud Data Fusion.
En la página de la API de Cloud Data Fusion que se carga, haz clic en Habilitar.
Cuando se haya habilitado de nuevo la API, la página se actualizará y mostrará la opción para inhabilitarla, además de otros detalles sobre su uso y rendimiento.
En el menú de navegación, selecciona Data Fusion.
Para crear una instancia de Cloud Data Fusion, haz clic en Crear una instancia.
Asígnale un nombre a tu instancia.
Para el tipo de edición, selecciona Básico.
En la sección Autorización, haz clic en Otorgar permiso.
Deja los otros campos con sus valores predeterminados y haz clic en Crear.
Nota:La creación de la instancia tardará alrededor de 15 minutos.
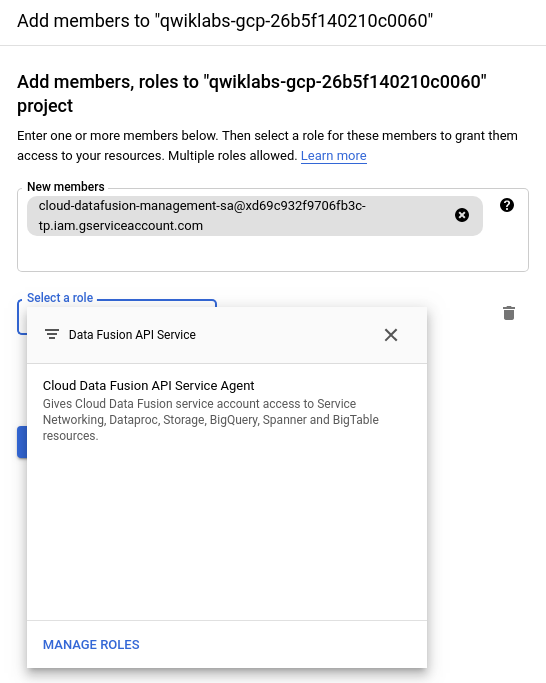
Una vez que se cree la instancia, necesitará realizar un paso adicional a fin de proporcionar a la cuenta de servicio asociada con la instancia los permisos para su proyecto. Haz clic en el nombre de la instancia para navegar a su página de detalles.
Copia la cuenta de servicio a tu portapapeles.
En la consola de Cloud, navega a IAM y administración > IAM.
En la página Permisos de IAM, agrega la cuenta de servicio que copiaste como un miembro nuevo y asígnale el rol Agente de servicio de la API de Cloud Data Fusion. Para ello, haz clic en el botón Agregar.
Haz clic en Guardar.
Tarea 2. Carga los datos
Puedes comenzar a usar Cloud Data Fusion una vez que tu instancia esté funcionando. Sin embargo, antes de que Cloud Data Fusion pueda comenzar a transferir datos, debe realizar algunos pasos preliminares.
En este ejemplo, Cloud Data Fusion leerá datos de un bucket de almacenamiento. Abre una consola de Cloud Shell y ejecuta los siguientes comandos para crear un bucket nuevo y copiar en él los datos relevantes:
export BUCKET=$GOOGLE_CLOUD_PROJECT
gsutil mb gs://$BUCKET
gsutil cp gs://cloud-training/OCBL017/ny-taxi-2018-sample.csv gs://$BUCKET
Nota:
El nombre del bucket creado es el ID de tu proyecto.
En la línea de comandos, ejecuta el siguiente comando para crear un bucket que almacene de manera temporal los elementos que creará Cloud Data Fusion:
gsutil mb gs://$BUCKET-temp
Nota: El nombre del bucket creado es el ID de tu proyecto seguido de “-temp”.
Haz clic en el vínculo Ver instancia, en la página de instancias de Cloud Data Fusion o en la página de detalles de una instancia. Si se le solicita hacer una visita guiada por el servicio, haga clic en No, gracias. Ahora deberías estar en la IU de Cloud Data Fusion.
Nota: Es posible que debas volver a cargar o actualizar las páginas de la IU de Cloud Data Fusion para que se cargue el mensaje.
Wrangler es una herramienta interactiva visual que te permite ver los efectos de las transformaciones en un subconjunto pequeño de tus datos antes de despachar trabajos grandes de procesamiento paralelo en todo el conjunto de datos. En la IU de Cloud Data Fusion, elige Wrangler. En el lado izquierdo, verá un panel con las conexiones previamente configuradas de sus datos, incluida la conexión de Cloud Storage.
Debajo de Google Cloud Storage, seleccione Cloud Storage Predeterminado.
Haga clic en el bucket correspondiente a su nombre de proyecto.
Seleccione ny-taxi-2018-sample.csv. Los datos se cargan en la pantalla de Wrangler en forma de fila/columna.
Tarea 3: Limpia los datos
Ahora realizarás algunas transformaciones para analizar y limpiar los datos de viajes en taxi.
A la izquierda de la columna body, haga clic en la flecha Abajo.
Haga clic en Analizar > CSV, seleccione Configurar primera fila como encabezado y, luego, haga clic en Aplicar. Los datos se dividen en varias columnas.
Dado que la columna body ya no es necesaria, haz clic en la flecha Abajo, junto a la columna body, y elige Borrar columna.
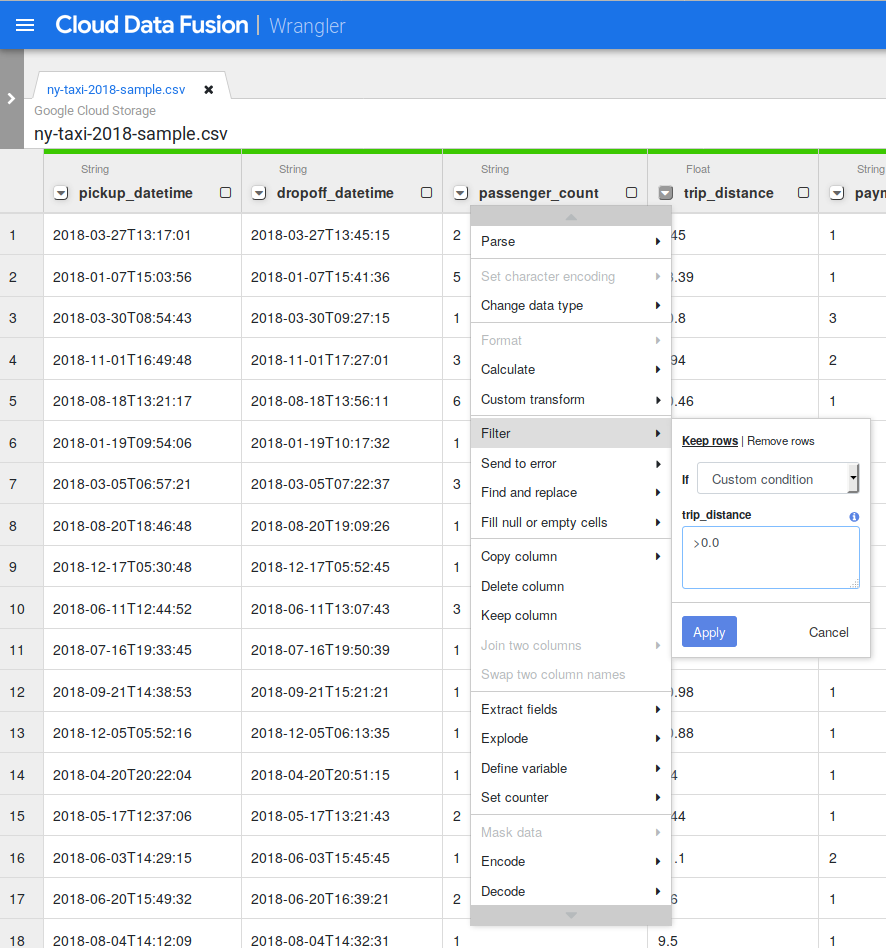
Notarás que todos los tipos de columna se cargaron como String. Haga clic en la flecha Abajo junto a la columna trip_distance, seleccione Cambiar tipo de datos y, luego, haga clic en Flotante. Repita lo mismo con la columna total_amount.
Si observa los datos con cuidado, encontrará algunas anomalías, como distancias de viaje negativas. Para evitar esos valores negativos, puede filtrarlos en Wrangler. Haga clic en la flecha Abajo junto a la columna trip_distance y seleccione Filtrar. Haz clic si la Condición personalizada y la entrada son >0.0.
Haz clic en Aplicar.
Tarea 4: Crea la canalización
Ya se completó la limpieza básica de datos, y ejecutaste transformaciones en un subconjunto de datos. Ahora puede crear una canalización por lotes para ejecutar transformaciones en todos sus datos.
Cloud Data Fusion traduce tu canalización creada de manera visual en un programa de Apache Spark o MapReduce que ejecuta transformaciones en un clúster efímero de Cloud Dataproc en paralelo. Esto te permite ejecutar transformaciones complejas con facilidad en grandes cantidades de datos de una forma escalable y confiable sin dificultades asociadas con la infraestructura o la tecnología.
En el lado superior derecho de la IU de Google Cloud Fusion, haga clic en Crear canalización.
En el diálogo que aparece, selecciona Canalización por lotes.
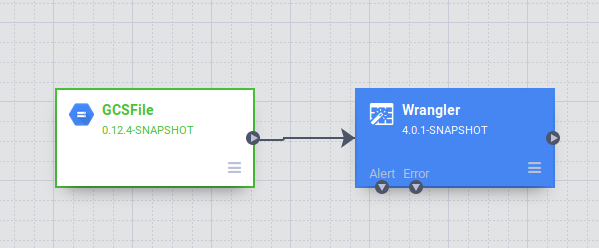
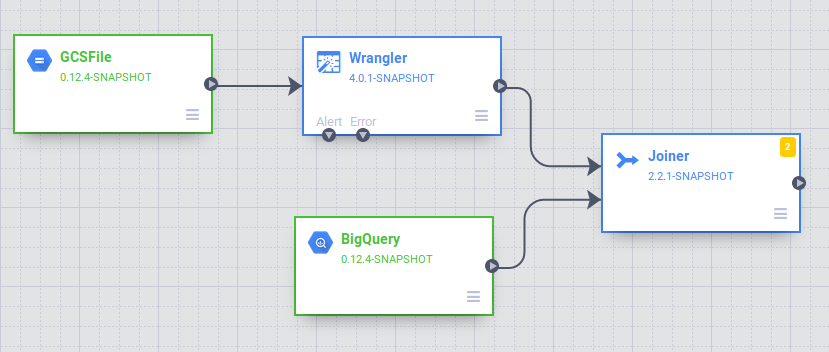
En la IU de Data pipelines, verás un nodo fuente GCSFile conectado a un nodo Wrangler. Este contiene todas las transformaciones que aplicaste en la vista de Wrangler capturada como gramática directiva. Coloca el cursor sobre el nodo Wrangler y selecciona Propiedades.
En esta etapa, puede aplicar más transformaciones. Para ello, haga clic en el botón Wrangle. Presione el ícono rojo de la papelera junto al nombre de la columna extra para borrarla. Para cerrar la herramienta Wrangler, haz clic en el botón X en la esquina superior derecha.
Tarea 5. Agrega una fuente de datos
Los datos de viajes en taxi contienen varias columnas crípticas, como pickup_location_id, que no son evidentes a simple vista para los analistas. Agregará una fuente de datos a la canalización que asigna la columna pickup_location_id a un nombre de ubicación relevante. Los detalles de la asignación se almacenarán en una tabla de BigQuery.
En la sección Explorador de la IU de BigQuery, haga clic en los tres puntos junto al ID del proyecto de GCP (que empezará con Qwiklabs).
En el menú que aparece, haz clic en el vínculo Crear conjunto de datos.
En el campo ID de conjunto de datos, escribe trips.
Haga clic en Crear conjunto de datos.
Para crear la tabla deseada en el conjunto de datos que se creó, navegue a Más > Configuración de consulta. Este proceso garantizará que puedas acceder a tu tabla mediante Cloud Data Fusion.
Selecciona el elemento Establecer una tabla de destino para los resultados de la consulta. Además, debajo del Nombre de la tabla, ingrese zone_id_mapping. Haz clic en Guardar.
Ingresa la siguiente consulta en el Editor de consultas y, luego, haz clic en Ejecutar:
SELECT
zone_id,
zone_name,
borough
FROM
`bigquery-public-data.new_york_taxi_trips.taxi_zone_geom`
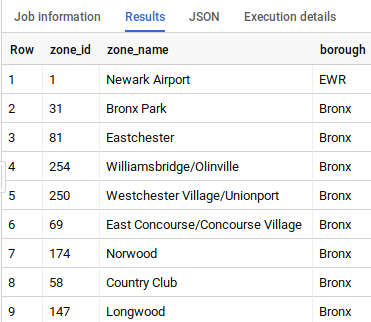
Puedes ver que esta tabla contiene la asignación de zone_id a su nombre y municipio.
Ahora agregarás una fuente en tu canalización para acceder a la tabla de BigQuery. Vuelve a la pestaña donde tienes abierto Cloud Data Fusion y, desde la paleta de complementos que se encuentra a la izquierda, selecciona BigQuery en la sección Fuente. Un nodo fuente de BigQuery aparecerá en el lienzo junto con los otros dos nodos.
Coloque el cursor sobre el nodo fuente de BigQuery y haga clic en Propiedades.
Para configurar el Nombre de referencia, ingrese zone_mapping, que se usa para identificar esta fuente de datos para fines de linaje. La configuración del Conjunto de datos y de la Tabla de BigQuery son el conjunto de datos y la tabla que estableció en BigQuery unos pases antes: trips y zone_id_mapping. En Nombre del bucket temporal, ingresa el nombre de tu proyecto seguido de “-temp”, que corresponde al bucket que creaste en la tarea 2.
Para propagar el esquema de esta tabla de BigQuery, haz clic en Obtener esquema. Los campos se mostrarán en el lado derecho del asistente.
Haz clic en el botón X en la esquina superior derecha para cerrar la ventana Propiedades de BigQuery.
Tarea 6. Une dos fuentes
Ahora, puedes unir dos fuentes de datos, los viajes en taxi y los nombres de las zonas, para generar un resultado más significativo.
En la sección Analítica de la paleta de complementos, elija Unión. Aparece en el recuadro un nodo de Unión.
Para conectar los nodos de Wrangler y BigQuery al nodo Joiner, arrastra una flecha de conexión > del borde derecho del nodo fuente y suéltala en el nodo de destino.
Para configurar el nodo de Unión, que es similar a una sintaxis JOIN de SQL, haz lo siguiente:
Haga clic en Propiedades de la Unión.
Deje la etiqueta de recurso como Unión.
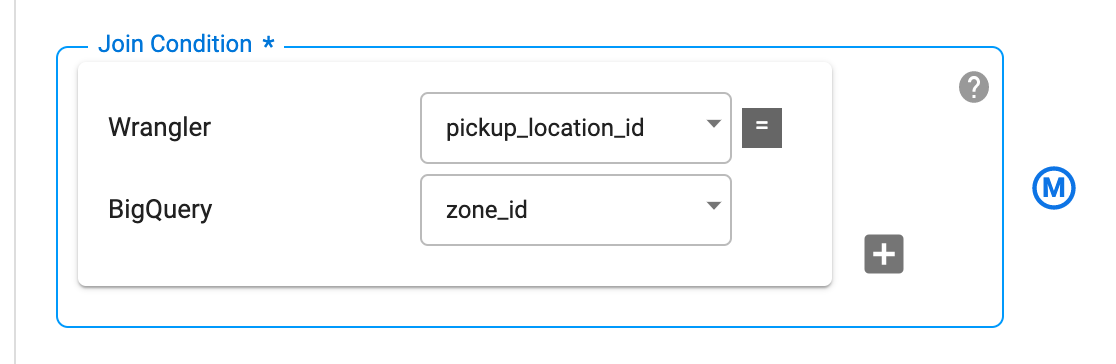
Cambie el tipo de Join Typea Inner
Configura Join Condition para unir la columnapickup_location_id en el nodo de Wrangler a la columna zone_id en el nodo de BigQuery
Para generar el esquema de la unión resultante, haz clic en Obtener esquema.
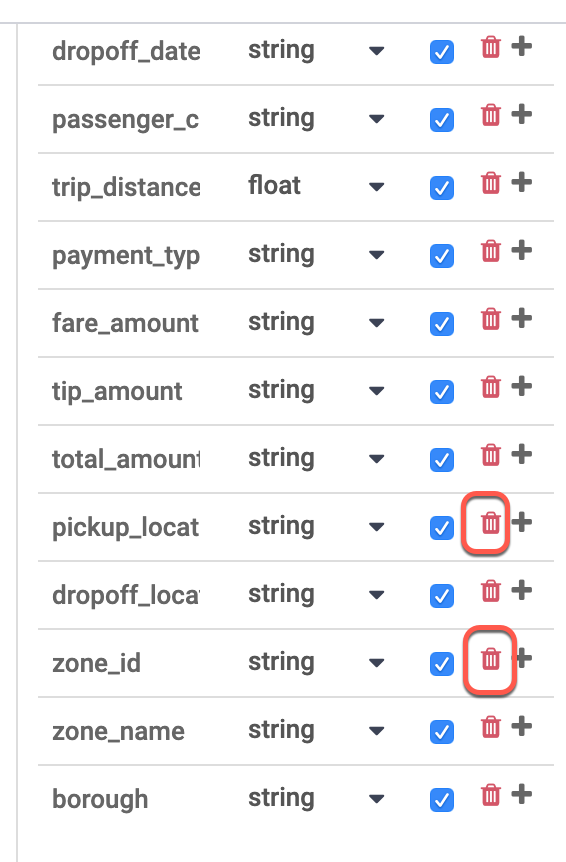
En la tabla Esquema de salida que se encuentra a la derecha, quita los campos zone_id y pickup_location_id. Para ello, presiona el ícono rojo de la papelera.
Haz clic en el botón X en la esquina superior derecha para cerrar la ventana.
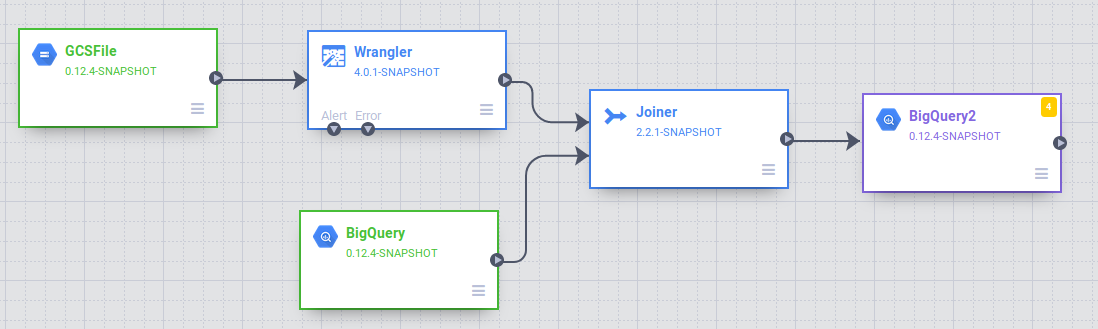
Tarea 7. Almacena el resultado en BigQuery
Almacenarás el resultado de la canalización en una tabla de BigQuery. El lugar donde almacena sus datos se denomina receptor.
En la sección Receptor de la paleta de complementos, elija BigQuery.
Conecte el nodo de Unión al de BigQuery. Arrastra una flecha de conexión > del borde derecho del nodo fuente y suéltala en el nodo de destino.
Coloca el cursor y haz clic en Propiedades para abrir el nodo de BigQuery. Configúrelo como se muestra a continuación. Usará una configuración similar a la fuente existente de BigQuery. Proporcione bq_insert para el campo Nombre de referencia y use trips en el Conjunto de datos y el nombre de su proyecto seguido de “-temp” como Nombre de bucket temporal. Escribirás una nueva tabla que se creará para ejecutar esta canalización. En el campo Tabla, ingresa trips_pickup_name.
Haz clic en el botón X en la esquina superior derecha para cerrar la ventana.
Tarea 8. Implementa y ejecuta la canalización
En este punto, ya creaste tu primera canalización y puedes implementarla y ejecutarla.
Asigna un nombre a la canalización en la esquina superior izquierda de la IU de Data Fusion y haz clic en Guardar.
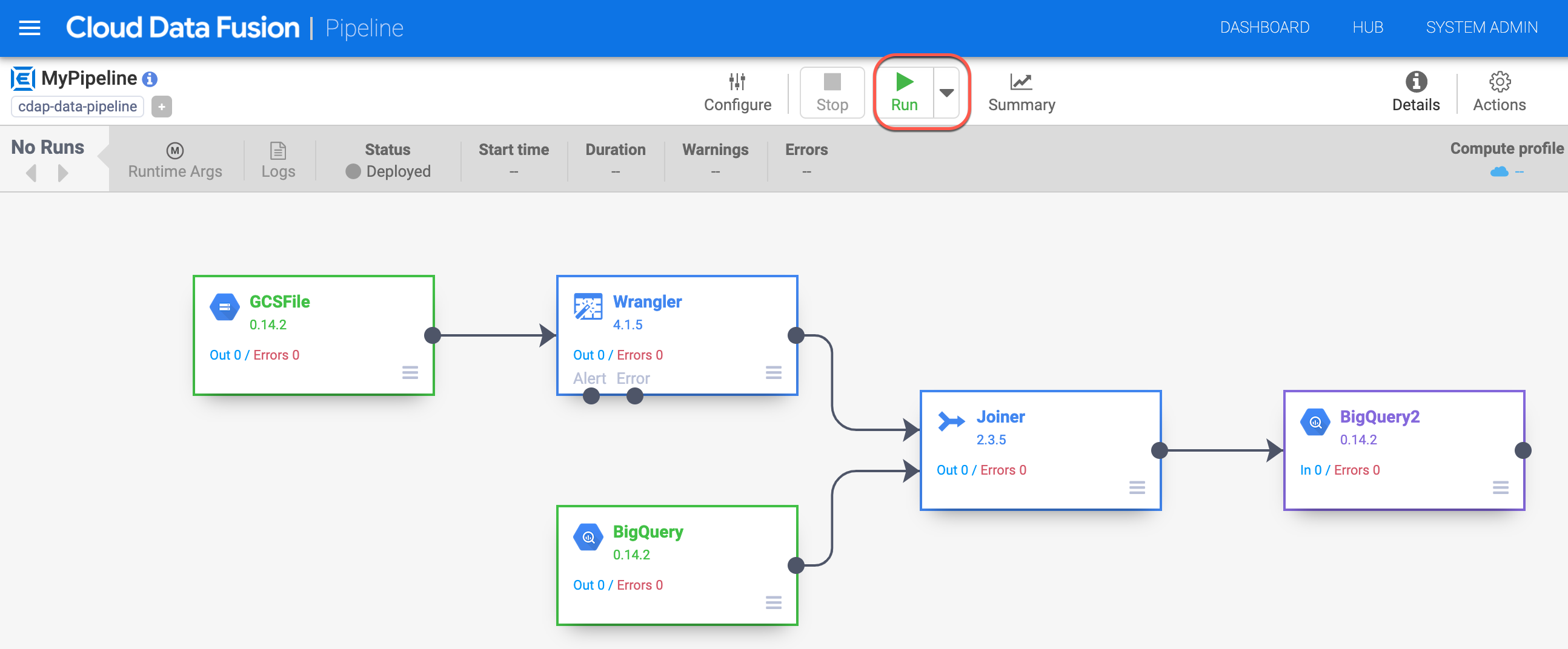
Ahora implementarás la canalización. En la esquina superior derecha de la página, haz clic en Implementar.
En la siguiente pantalla, haz clic en Ejecutar para comenzar a procesar datos.
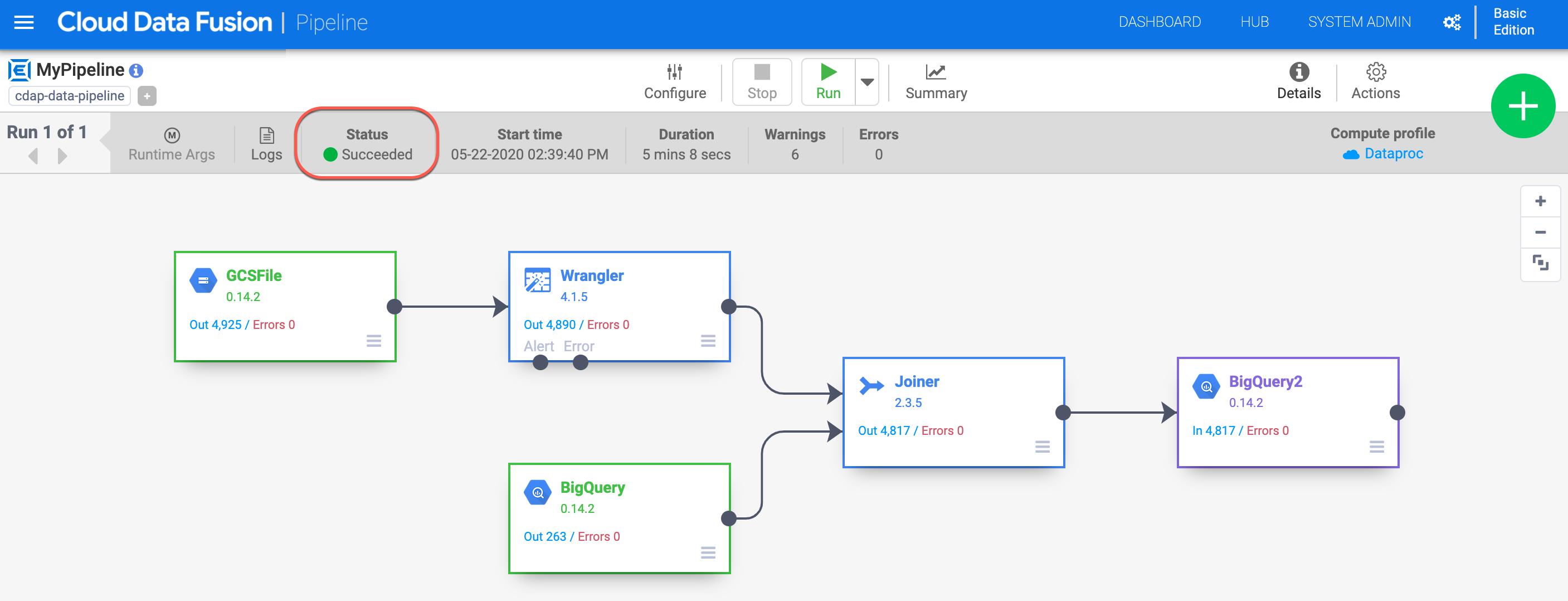
Cuando ejecutas una canalización, Cloud Data Fusion aprovisiona un clúster efímero de Cloud Dataproc, ejecuta la canalización y, luego, elimina el clúster. Esto puede tardar algunos minutos. Puedes observar el estado de la transición de la canalización de Aprovisionando a Iniciada y de Iniciada a En ejecución a Completada durante este tiempo.
Nota: La canalización puede tardar de 10 a 15 minutos en completarse.
Tarea 9. Observa los resultados
Para ver los resultados después de ejecutar una canalización, haz lo siguiente:
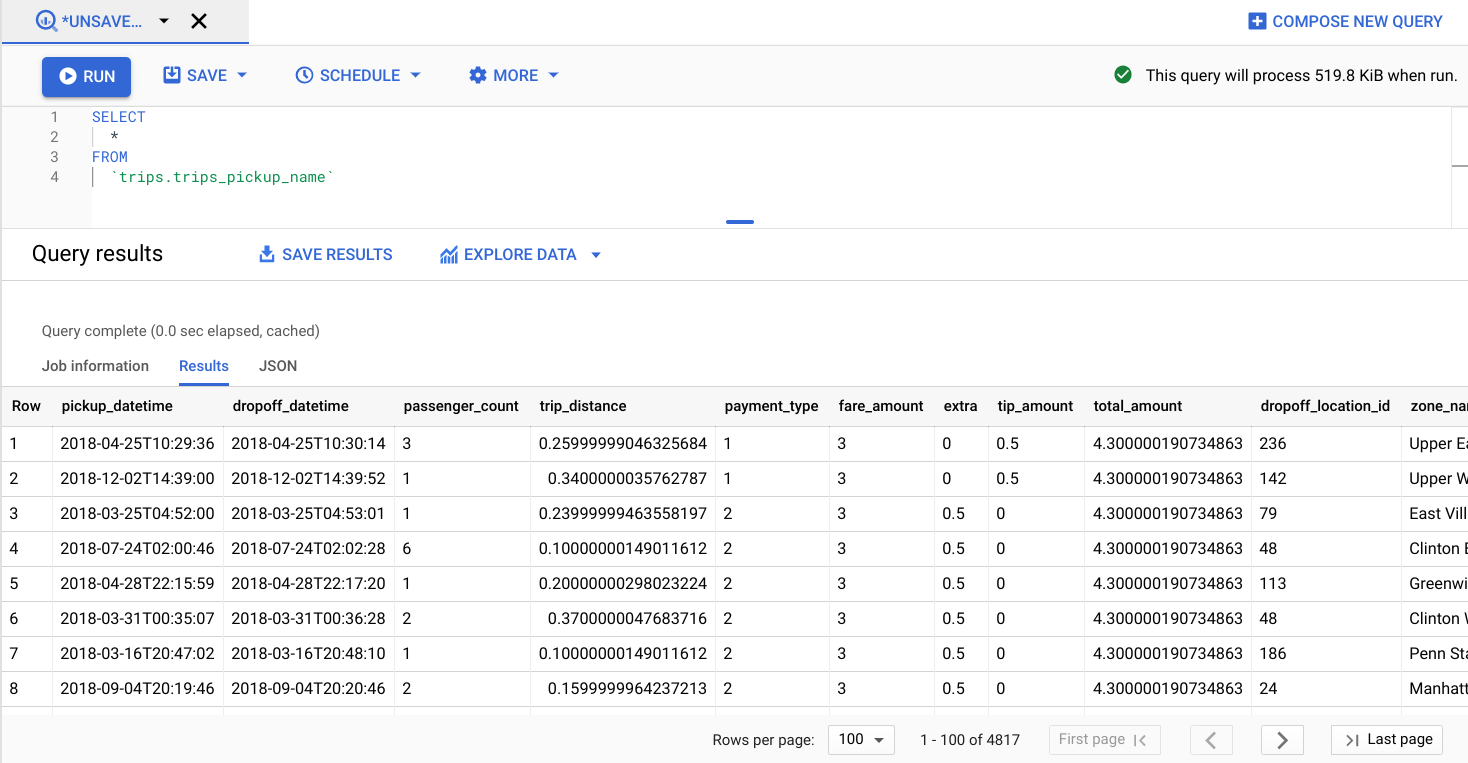
Vuelve a la pestaña donde tienes abierto BigQuery. Ejecuta la siguiente consulta para ver los valores en la tabla trips_pickup_name:
SELECT
*
FROM
`trips.trips_pickup_name`
RESULTADOS DE BQ
Finalice su lab
Cuando haya completado su lab, haga clic en Finalizar lab. Qwiklabs quitará los recursos que usó y limpiará la cuenta por usted.
Tendrá la oportunidad de calificar su experiencia en el lab. Seleccione la cantidad de estrellas que corresponda, ingrese un comentario y haga clic en Enviar.
La cantidad de estrellas indica lo siguiente:
1 estrella = Muy insatisfecho
2 estrellas = Insatisfecho
3 estrellas = Neutral
4 estrellas = Satisfecho
5 estrellas = Muy satisfecho
Puede cerrar el cuadro de diálogo si no desea proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, use la pestaña Asistencia.
Copyright 2026 Google LLC. Todos los derechos reservados. Google y el logotipo de Google son marcas de Google LLC. El resto de los nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que están asociados.
Los labs crean un proyecto de Google Cloud y recursos por un tiempo determinado
.
Los labs tienen un límite de tiempo y no tienen la función de pausa. Si finalizas el lab, deberás reiniciarlo desde el principio.
En la parte superior izquierda de la pantalla, haz clic en Comenzar lab para empezar
Usa la navegación privada
Copia el nombre de usuario y la contraseña proporcionados para el lab
Haz clic en Abrir la consola en modo privado
Accede a la consola
Accede con tus credenciales del lab. Si usas otras credenciales, se generarán errores o se incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación
No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo, ya que se borrará tu trabajo y se quitará el proyecto
Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible
¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible
Un lab a la vez
Confirma para finalizar todos los labs existentes y comenzar este
Usa la navegación privada para ejecutar el lab
Usar una ventana de incógnito o de navegación privada es la mejor forma de ejecutar
este lab. Así evitarás cualquier conflicto entre tu cuenta personal
y la cuenta de estudiante, lo que podría generar cargos adicionales en
tu cuenta personal.
En este instructivo, se muestra cómo usar las funciones de Wrangler y de canalización de datos en Cloud Data Fusion para limpiar, transformar y procesar datos de viajes en taxi y así realizar más análisis.
Duración:
0 min de configuración
·
Acceso por 150 min
·
150 min para completar

 ).
).
 ) de la consola de Google Cloud, haga clic en IAM y administración > IAM.
) de la consola de Google Cloud, haga clic en IAM y administración > IAM.