![Compute Engine のデフォルトのサービス アカウント名と編集者のステータスがハイライト表示された [権限] タブページ](https://cdn.qwiklabs.com/1nytD9OUuNUV9undyjUWeOS7LJmekReBDmkUjveCjcU%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Execute the pipeline
/ 5

このラボでは、データを BigQuery に読み込んで複雑なクエリを実行する方法を学習します。また、Map オペレーションと Reduce オペレーションの実行、副入力の使用、BigQuery へのストリーミングを行うことができる Dataflow パイプラインを実行します。
このラボでは、Dataflow に対するデータソースとして BigQuery を使用する方法と、あるパイプラインで得られた結果を別のパイプラインへの副入力として使用する方法について学習します。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
Qwiklabs にシークレット ウィンドウでログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
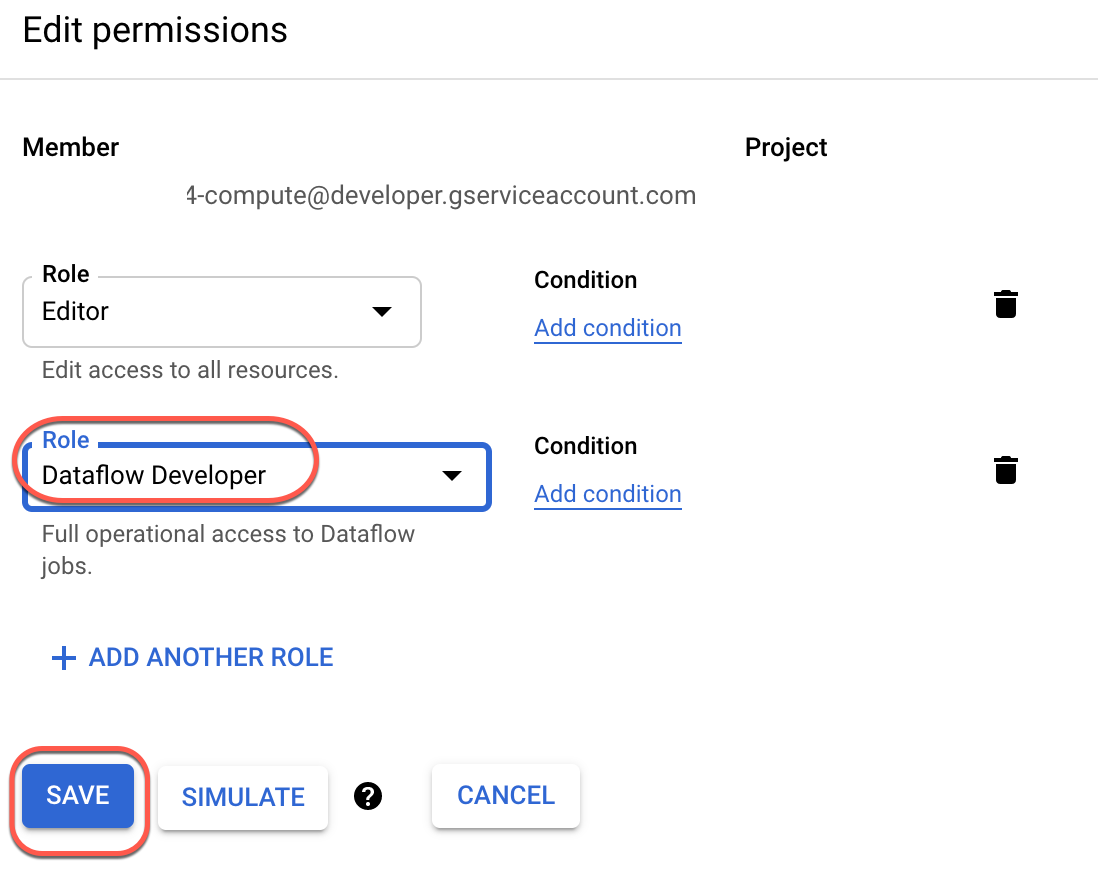
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] > [ダッシュボード] から確認できます。
編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。729328892908)をコピーします。{project-number} はプロジェクト番号に置き換えてください。アカウントに Dataflow デベロッパーのロールがない場合は、以下の手順に沿って必要なロールを割り当てます。
ナビゲーション メニューで、[IAM と管理] > [IAM] をクリックします。
デフォルトのコンピューティング サービス アカウント、「{project-number}-compute@developer.gserviceaccount.com」を選択します。
編集オプション(右端にある鉛筆アイコン)を選択します。
[別のロールを追加] をクリックします。
[ロールを選択] のボックス内をクリックします。[フィルタ テキストを入力] セレクタに入力して [Dataflow デベロッパー] を表示し、選択します。
[保存] をクリックします。
Google Cloud コンソールのタイトルバーで、[Cloud Shell をアクティブにする] をクリックします。プロンプトが表示されたら、[続行] をクリックします。
次のコマンドを実行して、プロジェクトで Dataflow API がスムーズに有効化されるようにします。プロンプトが表示されたら、[承認] をクリックします。
以後すべてのコードは特定の整備済みトレーニング VM から実行します。
Cloud コンソールのナビゲーション メニュー(
training-vm という名前のインスタンスがある行を確認します。
右端の [接続] の下にある [SSH] をクリックしてターミナル ウィンドウを開きます。プロンプトが表示されたら、[承認] をクリックします。
このラボでは、training-vm 上で CLI コマンドを入力します。
次の手順に沿ってバケットを作成します。
| プロパティ | 値(値を入力するか、指定されたオプションを選択) |
|---|---|
| 名前 | |
| [ロケーション タイプ] > [リージョン] |
[作成] をクリックします。
[公開アクセスの防止] というメッセージが表示されたら、[このバケットに対する公開アクセス禁止を適用する] を選択して [確認] をクリックします。
training_vm の SSH ターミナルで、次のように入力して 3 つの環境変数を設定します。環境変数の名前は「BUCKET」、「PROJECT」、「REGION」です。echo コマンドを使用して環境変数がそれぞれ存在することを確認します。
)で、[BigQuery] をクリックします。返された内容を確認します。
この BigQuery テーブル cloud-training-demos.github_repos.contents_java には、2016 年の GitHub に存在するすべての Java ファイルのコンテンツ(および一部のメタデータ)が含まれています。
このデータセットには、ファイルがいくつありましたか?
このデータセットは、ローカルとクラウド、どちらでの処理を予定していますか?
/training-data-analyst/courses/data_analysis/lab2/python ディレクトリに移動して、JavaProjectsThatNeedHelp.py ファイルを表示します。ファイルの表示には nano を使用します。コードは変更しないでください。Ctrl+X キーを押して nano を終了します。
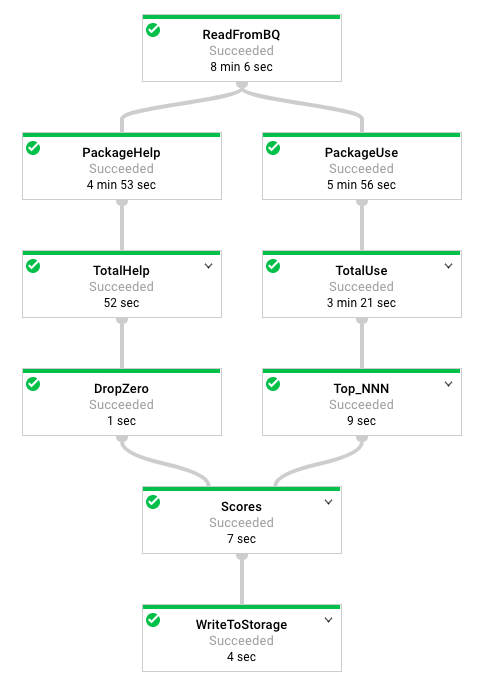
この図を参照しながらコードを読みます。パイプラインは次のようになります。
プログラムは BUCKET、PROJECT、REGION の値、および --DirectRunner を使用してパイプラインをローカルで実行するのか、--DataFlowRunner を使用してクラウドで実行するのかの指定を必要とします。
training-vm の SSH ターミナルで次のように入力して、パイプラインをローカルで実行します。
パイプラインの実行が完了したら、ナビゲーション メニュー(
training-vm の SSH ターミナルで次のように入力して、パイプラインをクラウドで実行します。
コンソールのブラウザタブに戻り、ナビゲーション メニュー(
ジョブをクリックして進行状況をモニタリングします。
パイプラインの実行が完了したら、ナビゲーション メニュー(
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください