Questi contenuti non sono ancora ottimizzati per i dispositivi mobili.
Per un'esperienza ottimale, visualizza il sito su un computer utilizzando un link inviato via email.
Panoramica
In questo lab, imparerai come caricare i dati in BigQuery ed eseguire query complesse. Successivamente, eseguirai una pipeline Dataflow in grado di eseguire operazioni di mappatura e riduzione, utilizzare input aggiuntivi e inserire flussi di dati in BigQuery.
Obiettivo
In questo lab, imparerai a utilizzare BigQuery come origine dati in Dataflow e i risultati di una pipeline come input aggiuntivo per un'altra pipeline. Apprenderai come:
Leggere i dati da BigQuery in Dataflow
Utilizzare l'output di una pipeline come input aggiuntivo per un'altra pipeline
Configurazione
Per ciascun lab, riceverai un nuovo progetto Google Cloud e un insieme di risorse per un periodo di tempo limitato senza alcun costo aggiuntivo.
Accedi a Qwiklabs utilizzando una finestra di navigazione in incognito.
Tieni presente la durata dell'accesso al lab (ad esempio, 1:15:00) e assicurati di finire entro quell'intervallo di tempo.
Non è disponibile una funzionalità di pausa. Se necessario, puoi riavviare il lab ma dovrai ricominciare dall'inizio.
Quando è tutto pronto, fai clic su Inizia lab.
Annota le tue credenziali del lab (Nome utente e Password). Le userai per accedere a Google Cloud Console.
Fai clic su Apri console Google.
Fai clic su Utilizza un altro account e copia/incolla le credenziali per questo lab nei prompt.
Se utilizzi altre credenziali, compariranno errori oppure ti verranno addebitati dei costi.
Accetta i termini e salta la pagina di ripristino delle risorse.
Verifica le autorizzazioni del progetto
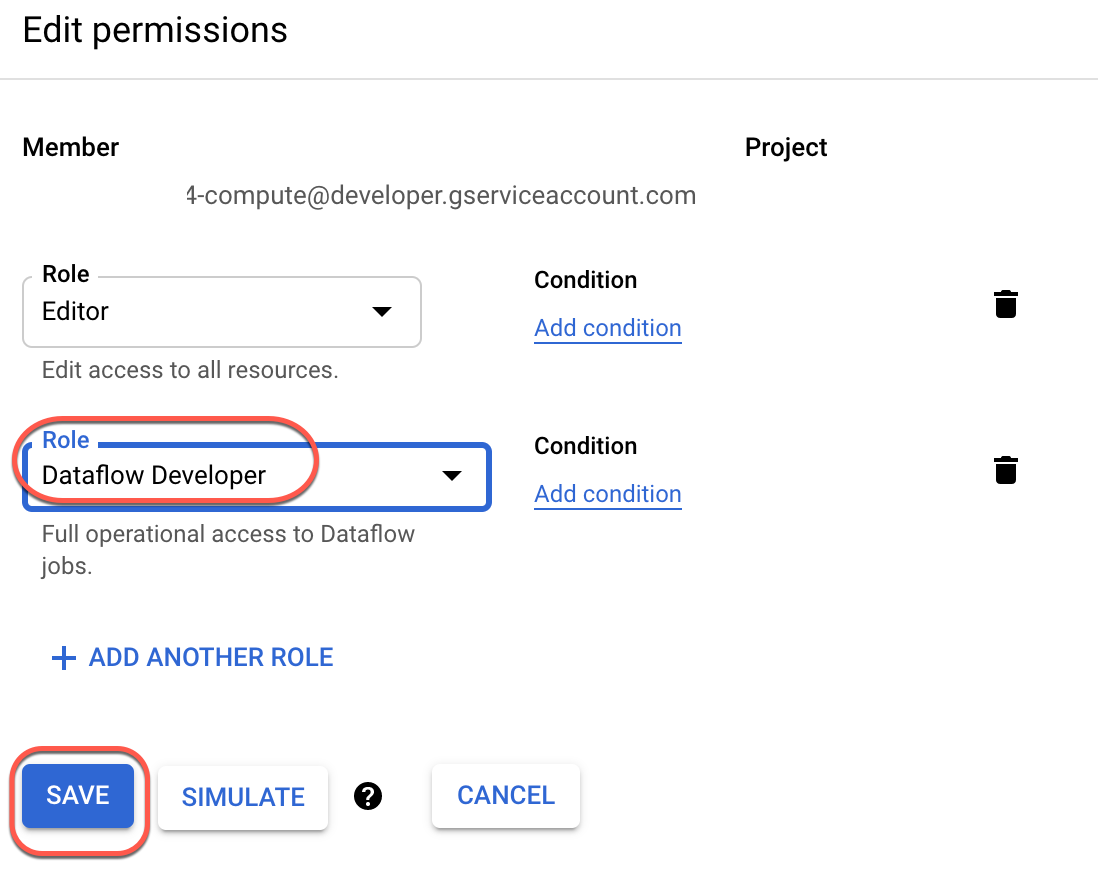
Prima di iniziare il tuo lavoro su Google Cloud, devi assicurarti che il tuo progetto disponga delle autorizzazioni corrette in Identity and Access Management (IAM).
Nella console Google Cloud, nel menu di navigazione (), seleziona IAM e amministrazione > IAM.
Conferma che l'account di servizio di computing predefinito {project-number}-compute@developer.gserviceaccount.com sia presente e che abbia il ruolo di editor assegnato. Il prefisso dell'account è il numero del progetto, che puoi trovare in Menu di navigazione > Panoramica di Cloud > Dashboard
Nota: se l'account non è presente in IAM o non dispone del ruolo editor, attieniti alla procedura riportata di seguito per assegnare il ruolo richiesto.
Nel menu di navigazione della console Google Cloud, fai clic su Panoramica di Cloud > Dashboard.
Copia il numero del progetto (es. 729328892908).
Nel menu di navigazione, seleziona IAM e amministrazione > IAM.
Nella parte superiore della tabella dei ruoli, sotto Visualizza per entità, fai clic su Concedi accesso.
Nella Console, nel menu di navigazione, fai clic su Cloud Storage > Bucket.
Fai clic su + Crea.
Specifica quanto segue e non modificare le altre impostazioni predefinite:
Proprietà
Valore (digita il valore o seleziona l'opzione come specificato)
Nome
Tipo di località > Regione
Fai clic su Crea.
Se ricevi il messaggio Public access will be prevented, seleziona Enforce public access prevention on this bucket e fai clic su Conferma.
Nel terminale SSH di training-vm, inserisci quanto segue per creare tre variabili di ambiente. Una chiamata "BUCKET", un'altra chiamata "PROJECT" e un'altra ancora chiamata "REGION". Verifica che esistano entrambe con il comando echo:
Nella console, nel menu di navigazione (), fai clic su BigQuery.
Se richiesto, fai clic su Fine.
Fai clic su "+" (Query SQL) e digita la seguente query:
SELECT
content
FROM
`cloud-training-demos.github_repos.contents_java`
LIMIT
10
Fai clic su Esegui.
Cosa viene restituito?
Nella tabella BigQuery cloud-training-demos.github_repos.contents_java si trovano i contenuti (e alcuni metadati) di tutti i file Java presenti in GitHub nel 2016.
Per trovare quanti file Java sono contenuti nella tabella, digita la query riportata di seguito e fai clic su Esegui:
SELECT
COUNT(*)
FROM
`cloud-training-demos.github_repos.contents_java`
Quanti file ci sono in questo set di dati?
È un set di dati da elaborare in locale o sul cloud?
Attività 3: esplora il codice della pipeline
Torna al terminale SSH di training-vm e vai alla directory /training-data-analyst/courses/data_analysis/lab2/python per visualizzare il file JavaProjectsThatNeedHelp.py.
Visualizza il file con Nano. Non apportare modifiche al codice. Premi Ctrl+X per uscire da Nano.
cd ~/training-data-analyst/courses/data_analysis/lab2/python
nano JavaProjectsThatNeedHelp.py
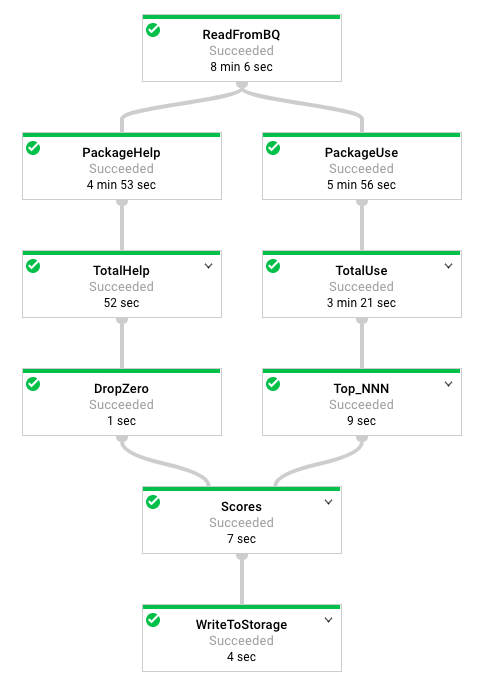
Fai riferimento a questo diagramma mentre leggi il codice. La pipeline ha questo aspetto:
Rispondi alle seguenti domande:
Guardando la documentazione della classe nella parte superiore, a cosa serve questa pipeline?
Da dove provengono i contenuti?
Cosa fa la parte sinistra della pipeline?
Cosa fa la parte destra della pipeline?
Cosa fa ToLines? (Suggerimento: guarda il campo dei contenuti nei risultati di BigQuery)
Perché il risultato di ReadFromBQ viene archiviato in una PCollection invece che passato direttamente a un altro passaggio?
Quali sono le due azioni eseguite sulla PCollection generata da ReadFromBQ?
Se il contenuto di un file include 3 FIXME e 2 TODO (su righe diverse), quante chiamate di assistenza vi sono associate?
A quali pacchetti è associato un file, se si trova nel pacchetto com.google.devtools.build?
popular_packages ed help_packages sono entrambe PCollection denominate ed entrambe sono utilizzate nel passaggio Scores (input aggiuntivi) della pipeline. Qual è l'input principale e quale l'input aggiuntivo?
Quale metodo è utilizzato nel passaggio Scores?
Quale tipo di dati Python si trova nell'input aggiuntivo convertito nel passaggio Scores?
Nota: la versione Java di questo programma è leggermente diversa dalla versione Python. L'SDK Java supporta AsMap, l'SDK Python non lo supporta. Supporta invece AsDict. In Java, la PCollection viene convertita in una vista come passaggio preparatorio prima dell'uso. In Python, la conversione della PCollection avviene nel passaggio in cui viene utilizzata.
Attività 4: esegui la pipeline
Il programma richiede i valori BUCKET, PROJECT e REGION e devi scegliere se eseguire la pipeline in locale utilizzando --DirectRunner o sul cloud utilizzando --DataFlowRunner
Esegui la pipeline in locale digitando quanto segue nel terminale SSH di training-vm:
python3 JavaProjectsThatNeedHelp.py --bucket $BUCKET --project $PROJECT --region $REGION --DirectRunner
Nota: ignora eventuali avvisi, ad esempio 'BeamDeprecationWarning', e vai avanti.
Una volta terminata l'esecuzione della pipeline, nel menu di navigazione (), fai clic su Cloud Storage > Bucket e poi sul tuo bucket. Troverai i risultati nella cartella javahelp. Fai clic sull'oggetto Risultato per esaminare l'output.
Esegui la pipeline sul cloud digitando quanto segue nel terminale SSH di training-vm:
python3 JavaProjectsThatNeedHelp.py --bucket $BUCKET --project $PROJECT --region $REGION --DataFlowRunner
Nota: ignora eventuali avvisi, ad esempio 'BeamDeprecationWarning', e vai avanti.
Torna alla scheda del browser della console. Nel menu di navigazione (), fai clic su Visualizza tutti i prodotti e seleziona Dataflow dalla sezione Analisi.
Fai clic sul job per monitorare l'avanzamento.
Al termine dell'esecuzione della pipeline, nel menu di navigazione (), fai clic su Cloud Storage > Bucket e poi sul tuo bucket. Troverai i risultati nella cartella javahelp. Fai clic sull'oggetto Risultato per esaminare l'output. Il nome del file sarà lo stesso, ma noterai che l'ora di creazione del file è più recente.
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Esegui la pipeline
Termina il lab
Una volta completato il lab, fai clic su Termina lab. Google Cloud Skills Boost rimuove le risorse che hai utilizzato ed esegue la pulizia dell'account.
Avrai la possibilità di inserire una valutazione in merito alla tua esperienza. Seleziona il numero di stelle applicabile, inserisci un commento, quindi fai clic su Invia.
Il numero di stelle corrisponde alle seguenti valutazioni:
1 stella = molto insoddisfatto
2 stelle = insoddisfatto
3 stelle = esperienza neutra
4 stelle = soddisfatto
5 stelle = molto soddisfatto
Se non vuoi lasciare un feedback, chiudi la finestra di dialogo.
Per feedback, suggerimenti o correzioni, utilizza la scheda Assistenza.
Copyright 2026 Google LLC Tutti i diritti riservati. Google e il logo Google sono marchi di Google LLC. Tutti gli altri nomi di società e prodotti sono marchi delle rispettive società a cui sono associati.
I lab creano un progetto e risorse Google Cloud per un periodo di tempo prestabilito
I lab hanno un limite di tempo e non possono essere messi in pausa. Se termini il lab, dovrai ricominciare dall'inizio.
In alto a sinistra dello schermo, fai clic su Inizia il lab per iniziare
Utilizza la navigazione privata
Copia il nome utente e la password forniti per il lab
Fai clic su Apri console in modalità privata
Accedi alla console
Accedi utilizzando le tue credenziali del lab. L'utilizzo di altre credenziali potrebbe causare errori oppure l'addebito di costi.
Accetta i termini e salta la pagina di ripristino delle risorse
Non fare clic su Termina lab a meno che tu non abbia terminato il lab o non voglia riavviarlo, perché il tuo lavoro verrà eliminato e il progetto verrà rimosso
Questi contenuti non sono al momento disponibili
Ti invieremo una notifica via email quando sarà disponibile
Bene.
Ti contatteremo via email non appena sarà disponibile
Un lab alla volta
Conferma per terminare tutti i lab esistenti e iniziare questo
Utilizza la navigazione privata per eseguire il lab
Il modo migliore per eseguire questo lab è utilizzare una finestra del browser in incognito o privata. Ciò evita eventuali conflitti tra il tuo account personale e l'account studente, che potrebbero causare addebiti aggiuntivi sul tuo account personale.
In questo lab, proverai a eseguire una query BigQuery, esplorerai il codice della pipeline ed eseguirai la pipeline utilizzando Python.
Durata:
Configurazione in 1 m
·
Accesso da 90 m
·
Completamento in 90 m

 ), seleziona IAM e amministrazione > IAM.
), seleziona IAM e amministrazione > IAM.