Vertex AI is now Gemini Enterprise Agent Platform! We are currently updating our content to reflect this change. Please bear with us if you encounter naming inconsistencies during this transition.
Applica le tue competenze nella console Google Cloud
Istruzioni e requisiti di configurazione del lab
Proteggi il tuo account e i tuoi progressi. Per eseguire questo lab, utilizza sempre una finestra del browser privata e le credenziali del lab.
Esecuzione di job Apache Spark su Cloud Dataproc
Lab
1 ora 30 minuti
universal_currency_alt
5 crediti
show_chart
Avanzati
info
Questo lab potrebbe incorporare strumenti di AI a supporto del tuo apprendimento.
Questi contenuti non sono ancora ottimizzati per i dispositivi mobili.
Per un'esperienza ottimale, visualizza il sito su un computer utilizzando un link inviato via email.
Panoramica
In questo lab imparerai a eseguire la migrazione del codice Apache Spark a Cloud Dataproc. Seguirai una sequenza di passaggi che ti consentiranno di spostare sempre più componenti del job ai servizi Google Cloud:
Esecuzione del codice Spark originale su Cloud Dataproc (lift and shift)
Sostituzione di HDFS con Cloud Storage (cloud-native)
Automazione di tutte le operazioni, di modo che vengano eseguite su cluster specifici del job (ottimizzazione per il cloud)
Cosa imparerai a fare
In questo lab imparerai a:
Eseguire la migrazione di job Spark esistenti a Cloud Dataproc
Modificare i job Spark in modo che utilizzino Cloud Storage al posto di HDFS
Ottimizzare i job Spark in modo da eseguirli su cluster specifici del job
Cosa utilizzerai
Cloud Dataproc
Apache Spark
Configurazione e requisiti
Per ciascun lab, riceverai un nuovo progetto Google Cloud e un insieme di risorse per un periodo di tempo limitato senza alcun costo aggiuntivo.
Accedi a Google Skills utilizzando una finestra Incognito.
Tieni presente la durata dell'accesso al lab (ad esempio, 1:15:00) e assicurati di finire entro quell'intervallo di tempo.
Non è disponibile una funzionalità di pausa. Se necessario, puoi riavviare il lab ma dovrai ricominciare dall'inizio.
Quando è tutto pronto, fai clic su Inizia lab.
Annota le tue credenziali del lab (Nome utente e Password). Le userai per accedere a Google Cloud Console.
Fai clic su Apri console Google.
Fai clic su Utilizza un altro account e copia/incolla le credenziali per questo lab nei prompt.
Se utilizzi altre credenziali, compariranno errori oppure ti verranno addebitati dei costi.
Accetta i termini e salta la pagina di ripristino delle risorse.
Attiva Google Cloud Shell
Google Cloud Shell è una macchina virtuale in cui sono caricati strumenti per sviluppatori. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud.
Google Cloud Shell fornisce l'accesso da riga di comando alle risorse Google Cloud.
Nella barra degli strumenti in alto a destra della console Cloud, fai clic sul pulsante Apri Cloud Shell.
Fai clic su Continua.
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Quando la connessione è attiva, l'autenticazione è già avvenuta e il progetto è impostato sul tuo PROJECT_ID. Ad esempio:
gcloud è lo strumento a riga di comando di Google Cloud. È preinstallato su Cloud Shell e supporta il completamento.
Puoi visualizzare il nome dell'account attivo con questo comando:
Prima di iniziare il tuo lavoro su Google Cloud, devi assicurarti che il tuo progetto disponga delle autorizzazioni corrette in Identity and Access Management (IAM).
Nella console Google Cloud, nel menu di navigazione (), seleziona IAM e amministrazione > IAM.
Conferma che l'account di servizio di computing predefinito {project-number}-compute@developer.gserviceaccount.com sia presente e che abbia il ruolo di editor assegnato. Il prefisso dell'account è il numero del progetto, che puoi trovare in Menu di navigazione > Panoramica di Cloud > Dashboard
Nota: se l'account non è presente in IAM o non dispone del ruolo editor, attieniti alla procedura riportata di seguito per assegnare il ruolo richiesto.
Nel menu di navigazione della console Google Cloud, fai clic su Panoramica di Cloud > Dashboard.
Copia il numero del progetto (es. 729328892908).
Nel menu di navigazione, seleziona IAM e amministrazione > IAM.
Nella parte superiore della tabella dei ruoli, sotto Visualizza per entità, fai clic su Concedi accesso.
Sostituisci {project-number} con il numero del tuo progetto.
Come Ruolo, seleziona Progetto (o Base) > Editor.
Fai clic su Salva.
Scenario
Stai eseguendo la migrazione di un carico di lavoro Spark esistente a Cloud Dataproc e devi modificare progressivamente il codice Spark in modo che utilizzi le funzionalità e i servizi nativi di Google Cloud.
Attività 1: lift and shift
Eseguire la migrazione di job Spark esistenti a Cloud Dataproc
Dovrai creare un nuovo cluster Cloud Dataproc e quindi eseguire un blocco note Jupyter importato, che utilizza il File system distribuito (HDFS, Hadoop Distributed File System) locale predefinito del cluster per archiviare i dati di origine e quindi elaborarli esattamente come faresti utilizzando Spark su qualsiasi cluster Hadoop. Questo dimostra che molti carichi di lavoro di analisi e dati esistenti, come i blocchi note Jupyter contenenti codice Spark, possono essere migrati a un ambiente Cloud Dataproc senza richiedere alcuna modifica.
Configura e avvia un cluster Cloud Dataproc
Nella console Google Cloud, fai clic su Dataproc nella sezione Analisi e dati del menu di navigazione.
Fai clic su Crea cluster.
Fai clic su Crea per l'elemento Cluster su Compute Engine.
Inserisci sparktodp nel campo Nome cluster.
Imposta Regione su e Zona su .
Nella sezione Controllo delle versioni, fai clic su Cambia e seleziona 2.1 (Debian 11, Hadoop 3.3, Spark 3.3).
Questa versione include Python3, necessario per il codice campione utilizzato in questo lab.
Fai clic su Seleziona.
Nella sezione Componenti > Gateway dei componenti seleziona Attiva gateway dei componenti.
In Componenti facoltativi seleziona Blocco note Jupyter.
Sotto Configura cluster, fai clic su Configura nodi (facoltativo) nell'elenco sulla sinistra.
In Nodo gestore reimposta Serie su E2 e Tipo di macchina su e2-standard-2 (2 vCPU, 8 GB di memoria).
In Nodi worker reimposta Serie su E2 e Tipo di macchina su e2-standard-2 (2 vCPU, 8 GB di memoria).
Fai clic su Crea.
Il cluster dovrebbe essere avviato entro pochi minuti. Prima di procedere con il passaggio successivo, attendi il completamento del deployment del cluster Cloud Dataproc.
Clona il repository di codice sorgente per il lab
In Cloud Shell, devi clonare il repository Git per il lab e copiare i file di blocco note necessari nel bucket Cloud Storage utilizzato da Cloud Dataproc come home directory per i blocchi note Jupyter.
Per clonare il repository Git per il lab inserisci il comando seguente in Cloud Shell:
Appena il cluster risulta completamente avviato, puoi connetterti alle interfacce web. Quando arrivi a questa fase, fai clic sul pulsante di aggiornamento per verificare che il deployment sia stato completato.
Nella pagina Cluster Dataproc attendi che il cluster completi la fase di avvio, quindi fai clic sul nome del cluster per aprire la pagina Dettagli cluster.
Fai clic su Interfacce web.
Fai clic sul link Jupyter per aprire una nuova scheda per Jupyter nel browser.
Viene visualizzata la home page di Jupyter, in cui viene mostrato il contenuto della directory /notebooks/jupyter in Cloud Storage, che ora include i blocchi note Jupyter di esempio utilizzati in questo lab.
Nella scheda File, fai clic sulla cartella GCS e quindi fai clic sul blocco note 01_spark.ipynb per aprirlo.
Fai clic su Celle e seleziona Esegui tutto, per eseguire tutte le celle nel blocco note.
Torna alla pagina iniziale del blocco note e segui l'esecuzione delle singole celle, osservando i risultati a mano a mano che vengono restituiti sotto di loro.
Ora puoi seguire le celle passo per passo ed esaminare il codice mentre viene elaborato, per vedere quello che sta facendo il blocco note. In particolare, presta attenzione alla posizione in cui vengono salvati i dati e quella da cui vengono elaborati.
La prima cella del codice recupera il file di dati di origine, tratto dalla competizione KDD Cup che si è svolta durante l'edizione 1999 delle conferenza Knowledge, Discovery, and Data (KDD). Tali dati riguardano gli eventi di rilevamento delle intrusioni nei computer.
Nella seconda cella del codice, i dati di origine vengono copiati nel file system Hadoop predefinito (locale).
!hadoop fs -put kddcup* /
Il comando nella terza cella del codice elenca il contenuto della directory predefinita nel file system HDFS del cluster.
!hadoop fs -ls /
Lettura dei dati
I dati sono costituiti da file CSV compressi in formato gzip. In Spark, questi dati possono essere letti direttamente tramite il metodo textFile e quindi analizzati, suddividendoli in righe in corrispondenza delle virgole.
Il codice Python di Spark viene avviato nelle cella In[4].
In questa cella viene inizializzato Spark SQL e si utilizza Spark per leggere i dati di origine, in formato testo, per poi restituire le prime 5 righe.
Nella cella In [5], le righe vengono separate utilizzando la virgola (,) come delimitatore, quindi analizzate utilizzando uno schema incorporato preparato nel codice.
Nella cella In [6] viene creato un contesto SparkSQL, quindi viene creato un DataFrame Spark utilizzando tale contesto e i dati di input analizzati nella pagina precedente.
I dati delle righe possono essere selezionati e analizzati utilizzando il metodo .show() del DataFrame per generare una vista con il riepilogo del numero di campi selezionati:
Per interrogare i dati analizzati archiviati nel DataFrame è possibile utilizzare anche SparkSQL.
Nella cellaIn [7] viene registrata una tabella temporanea (connections), che in seguito verrà referenziata all'interno dell'istruzione di query SQL successiva di SparkSQL:
df.registerTempTable("connections")
attack_stats = sqlContext.sql("""
SELECT
protocol_type,
CASE label
WHEN 'normal.' THEN 'no attack'
ELSE 'attack'
END AS state,
COUNT(*) as total_freq,
ROUND(AVG(src_bytes), 2) as mean_src_bytes,
ROUND(AVG(dst_bytes), 2) as mean_dst_bytes,
ROUND(AVG(duration), 2) as mean_duration,
SUM(num_failed_logins) as total_failed_logins,
SUM(num_compromised) as total_compromised,
SUM(num_file_creations) as total_file_creations,
SUM(su_attempted) as total_root_attempts,
SUM(num_root) as total_root_acceses
FROM connections
GROUP BY protocol_type, state
ORDER BY 3 DESC
""")
attack_stats.show()
Al termine della query viene visualizzato un output simile a quello di questo esempio troncato:
Ora puoi visualizzare questi dati anche in formato grafico, utilizzando i grafici a barre.
L'ultima cella, In [8], usa la funzione magica di Jupyter %matplotlib inline per reindirizzare matplotlib, in modo che esegua il rendering di un'immagine grafica incorporata nel blocco note, anziché limitarsi a eseguire il dump dei dati in una variabile. Questa cella visualizza un grafico a barre utilizzando la query attack_stats del passo precedente.
Terminata l'esecuzione di tutte le celle nel blocco note, la prima parte dell'output dovrebbe essere simile alla seguente. Per visualizzare il grafico di output completo, puoi scorrere il blocco note fino in fondo.
Attività 2: separa le risorse di elaborazione da quelle di archiviazione
Modifica i job Spark in modo che utilizzino Cloud Storage al posto di HDFS
Ora devi utilizzare il blocco note originale di esempio "Lift and shift" per creare una copia che separa i requisiti di archiviazione del job da quelli di elaborazione. In questo caso devi semplicemente sostituire le chiamate al file system Hadoop con chiamate a Cloud Storage, sostituendo i riferimenti allo spazio di archiviazione hdfs:// con riferimenti a gs:// nel codice e aggiustando i nomi delle cartelle come necessario.
Devi innanzitutto utilizzare Cloud Shell per inserire una copia dei dati di origine in un nuovo bucket Cloud Storage.
In Cloud Shell, crea un nuovo bucket di archiviazione per i dati di origine:
export PROJECT_ID=$(gcloud info --format='value(config.project)')
gcloud storage buckets create gs://$PROJECT_ID
In Cloud Shell, copia i dati di origine nel bucket:
Assicurati che l'ultimo comando venga completato e verifica che il file sia stato copiato nel nuovo bucket di archiviazione.
Nel browser, torna alla scheda del blocco note Jupyter 01_spark.
Fai clic su File, quindi seleziona Crea una copia.
All'apertura della copia fai clic sul titolo 01_spark-Copy1 e rinominalo in De-couple-storage.
Apri la scheda di Jupyter per 01_spark.
Fai clic su File e quindi su Salvataggio e checkpoint, per salvare il blocco note.
Fai clic su File, quindi su Chiudi e arresta, per arrestare il blocco note.
Se ti viene richiesto di confermare la chiusura del blocco note, fai clic su Esci o su Annulla.
Torna alla scheda del blocco note Jupyter De-couple-storage nel browser, se necessario.
Poiché ora le celle che scaricano e copiano i dati nel file system HDFS interno del cluster non sono più necessarie, devi rimuoverle prima di procedere.
Per eliminare una cella, fai clic nella cella per selezionarla, quindi fai clic sull'icona delle forbici sulla barra degli strumenti del blocco note per tagliare le celle selezionate.
Elimina le celle di commento iniziali e le prime tre celle del codice (In [1], In [2] e In [3]), di modo che il blocco note venga avviato con la sezione Reading in Data.
Ora devi modificare il codice nella prima cella (che si chiama ancora In[4], a meno che tu non abbia rieseguito il blocco note ), che definisce la posizione di origine del file di dati e legge i dati di origine. Attualmente la cella contiene il codice che segue:
Sostituisci il contenuto della cella In [4] con il codice che segue. L'unica modifica consiste nella creazione di una variabile per la memorizzazione del nome di un bucket Cloud Storage e l'indirizzamento di data_file al bucket utilizzato in precedenza per archiviare i dati di origine in Cloud Storage:
Dopo la sostituzione del codice, la prima cella avrà un aspetto simile al seguente e il nome del bucket coinciderà con l'ID progetto del lab:
Nella cella che hai appena aggiornato, sostituisci il segnaposto [Your-Bucket-Name] con il nome del bucket di archiviazione che hai creato nel primo passo di questa sezione. Per la creazione di tale bucket hai utilizzato l'ID progetto come nome, e ora puoi copiarlo dal riquadro delle informazioni di accesso al lab Qwiklabs, sulla sinistra di questa schermata. Sostituisci tutto il testo del segnaposto, incluse le parentesi quadre ([]).
Fai clic su Celle e seleziona Esegui tutto, per eseguire tutte le celle nel blocco note.
Verrà visualizzato esattamente lo stesso output generato quando il file era stato caricato ed eseguito dallo spazio di archiviazione del cluster interno. Per spostare in Cloud Storage i file dei dati di origine è sufficiente modificare da hdfs:// a gs:// il riferimento dall'origine dello spazio di archiviazione.
Attività 3: esegui il deployment dei job Spark
Ottimizza i job Spark in modo da eseguirli su cluster specifici del job
Ora devi creare un file Python autonomo, che eseguirà le stesse funzioni di questo blocco note e può essere distribuito come un job di Cloud Dataproc. A tale scopo devi creare una copia del blocco note e aggiungere alle celle Python i comandi magici necessari per scrivere i contenuti delle celle in un file. Devi aggiungere anche un gestore di parametri di input, per impostare la posizione del bucket di archiviazione quando lo script Python viene chiamato, per aumentare la portabilità del codice.
Nel menu del blocco note Jupyter De-couple-storage fai clic su File e seleziona Crea una copia.
All'apertura della copia fai clic sul nome De-couple-storage-Copy1 e modificalo in PySpark-analysis-file.
Apri la scheda di Jupyter per De-couple-storage.
Fai clic su File e quindi su Salvataggio e checkpoint, per salvare il blocco note.
Fai clic su File, quindi su Chiudi e arresta, per arrestare il blocco note.
Se ti viene richiesto di confermare la chiusura del blocco note, fai clic su Esci o su Annulla.
Se necessario, torna alla scheda del blocco note Jupyter PySpark-analysis-file.
Fai clic sulla prima cella all'inizio del blocco note.
Fai clic su Inserisci e seleziona Inserisci cella sopra.
Incolla nella prima cella di codice il seguente codice per l'importazione della libreria e la gestione dei parametri:
Il comando magico %%writefile spark_analysis.py di Jupyter crea un nuovo file di output in cui verrà inserito il tuo script Python autonomo. Nelle celle rimanenti aggiungerai una variante di questo comando che aggiunge il contenuto di ogni singola cella al file dello script autonomo.
Inoltre, questo codice importa il modulo matplotlib e imposta esplicitamente il backend di tracciamento predefinito tramite matplotlib.use('agg'), in modo da eseguire il codice di tracciamento all'esterno di un blocco note Jupyter.
Nelle celle rimanenti inserisci %%writefile -a spark_analysis.py all'inizio di ogni cella di codice Python. Sono le cinque celle con etichetta In [x].
%%writefile -a spark_analysis.py
Ad esempio, la cella successiva dovrebbe avere un aspetto simile al seguente:
Ripeti questo passaggio, inserendo %%writefile -a spark_analysis.py all'inizio di ogni cella di codice, fino ad arrivare alla fine.
Nell'ultima cella, che traccia il grafico a barre Pandas, rimuovi il comando magico %matplotlib inline.
Nota: se non rimuovi il comando magico matplotlib Jupyter incorporato, lo script genererà un errore durante l'esecuzione.
Assicurati di aver selezionato l'ultima cella del codice nel blocco note, quindi fai clic su Inserisci sulla barra dei menu e seleziona Inserisci cella sotto.
Incolla il codice seguente nella nuova cella:
%%writefile -a spark_analysis.py
ax[0].get_figure().savefig('report.png');
Aggiungi una nuova cella in fondo al blocco note e incollaci il codice seguente:
%%writefile -a spark_analysis.py
import google.cloud.storage as gcs
bucket = gcs.Client().get_bucket(BUCKET)
for blob in bucket.list_blobs(prefix='sparktodp/'):
blob.delete()
bucket.blob('sparktodp/report.png').upload_from_filename('report.png')
Aggiungi una nuova cella in fondo al blocco note e incollaci il codice seguente:
%%writefile -a spark_analysis.py
connections_by_protocol.write.format("csv").mode("overwrite").save(
"gs://{}/sparktodp/connections_by_protocol".format(BUCKET))
Automazione dei test
Ora devi verificare che il codice PySpark venga eseguito correttamente come file, chiamando la copia locale dall'interno del blocco note, passando un parametro per identificare il bucket di archiviazione che hai creato in precedenza per archiviare i dati di input per questo job. Lo stesso bucket verrà utilizzato per archiviare i file di dati di report generati dallo script.
Aggiungi una nuova cella in fondo al blocco note PySpark-analysis-file e incollaci il codice seguente:
BUCKET_list = !gcloud info --format='value(config.project)'
BUCKET=BUCKET_list[0]
print('Writing to {}'.format(BUCKET))
!/opt/conda/miniconda3/bin/python spark_analysis.py --bucket=$BUCKET
Questo codice presuppone che tu abbia creato un bucket Cloud Storage utilizzando l'ID progetto come nome del bucket di archiviazione, come indicato nelle istruzioni precedenti. Se hai usato un nome diverso, modifica il codice in modo da impostare la variabile BUCKET sul nome che hai utilizzato.
Aggiungi una nuova cella in fondo al blocco note e incollaci il codice seguente:
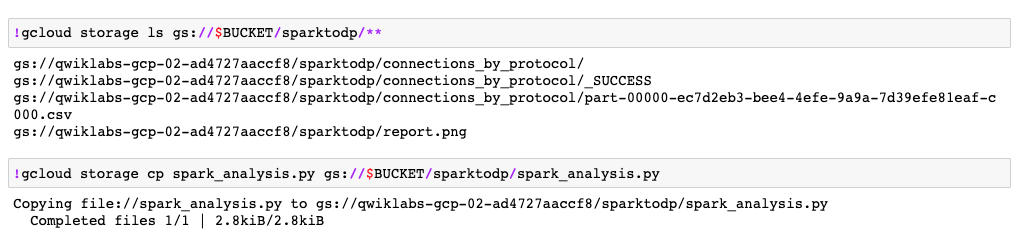
!gcloud storage ls gs://$BUCKET/sparktodp/**
Questo codice elenca i file di output dello script che sono stati salvati nel bucket Cloud Storage.
Per salvare una copia del file Python nello spazio di archiviazione permanente, aggiungi una nuova cella e incollaci il codice seguente:
Fai clic su Celle e seleziona Esegui tutto, per eseguire tutte le celle nel blocco note.
Se il blocco note crea ed esegue correttamente il file Python, dovresti vedere un output simile al seguente per le ultime due celle. Questo indica che lo script è stato eseguito fino alla fine, salvando l'output nel bucket Cloud Storage che hai creato precedentemente in questo lab.
Nota: se si verifica un errore in questa fase, probabilmente non hai rimosso la direttiva matplotlib dalla cella In [7]. Verifica nuovamente di aver modificato tutte le celle come indicato nelle istruzioni precedenti e di non aver saltato alcun passaggio.
Esegui il job di analisi da Cloud Shell.
Torna a Cloud Shell e copia lo script Python da Cloud Storage, in modo da poterlo eseguire come job di Cloud Dataproc:
#!/bin/bash
gcloud dataproc jobs submit pyspark \
--cluster sparktodp \
--region {{{project_0.default_region | REGION }}} \
spark_analysis.py \
-- --bucket=$1
Premi CTRL+X, quindi i tasti Y e Invio per uscire e salvare.
Rendi eseguibile lo script:
chmod +x submit_onejob.sh
Lancia il job di analisi PySpark:
./submit_onejob.sh $PROJECT_ID
Nella scheda Console Cloud, passa alla pagina Dataproc > Cluster, se non è già aperta.
Fai clic su Job.
Fai clic sul nome del job visualizzato. Qui puoi monitorare i progressi come da Cloud Shell. Attendi il completamento del job.
Accedi al bucket di archiviazione e nota che il timestamp del report di output, /sparktodp/report.png, è stato aggiornato, indicando che il job autonomo è stato completato correttamente.
Il bucket di archiviazione utilizzato da questo job come spazio di archiviazione dati di input e output è il bucket con il nome che corrisponde all'ID progetto.
Torna alla pagina Dataproc > Cluster.
Seleziona il cluster sparktodp e fai clic su Elimina, perché non ti serve più.
Fai clic su CONFERMA.
Chiudi le schede Jupyter nel browser.
Termina il lab
Una volta completato il lab, fai clic su Termina lab. Google Skills rimuove le risorse che hai utilizzato ed esegue la pulizia dell'account.
Avrai la possibilità di inserire una valutazione in merito alla tua esperienza. Seleziona il numero di stelle applicabile, inserisci un commento, quindi fai clic su Invia.
Il numero di stelle corrisponde alle seguenti valutazioni:
1 stella = molto insoddisfatto
2 stelle = insoddisfatto
3 stelle = esperienza neutra
4 stelle = soddisfatto
5 stelle = molto soddisfatto
Se non vuoi lasciare un feedback, puoi chiudere la finestra di dialogo.
Per feedback, suggerimenti o correzioni, utilizza la scheda Assistenza.
Copyright 2026 Google LLC Tutti i diritti riservati. Google e il logo Google sono marchi di Google LLC. Tutti gli altri nomi di società e prodotti sono marchi delle rispettive società a cui sono associati.
I lab creano un progetto e risorse Google Cloud per un periodo di tempo prestabilito
I lab hanno un limite di tempo e non possono essere messi in pausa. Se termini il lab, dovrai ricominciare dall'inizio.
In alto a sinistra dello schermo, fai clic su Inizia il lab per iniziare
Utilizza la navigazione privata
Copia il nome utente e la password forniti per il lab
Fai clic su Apri console in modalità privata
Accedi alla console
Accedi utilizzando le tue credenziali del lab. L'utilizzo di altre credenziali potrebbe causare errori oppure l'addebito di costi.
Accetta i termini e salta la pagina di ripristino delle risorse
Non fare clic su Termina lab a meno che tu non abbia terminato il lab o non voglia riavviarlo, perché il tuo lavoro verrà eliminato e il progetto verrà rimosso
Questi contenuti non sono al momento disponibili
Ti invieremo una notifica via email quando sarà disponibile
Bene.
Ti contatteremo via email non appena sarà disponibile
Un lab alla volta
Conferma per terminare tutti i lab esistenti e iniziare questo
Utilizza la navigazione privata per eseguire il lab
Il modo migliore per eseguire questo lab è utilizzare una finestra del browser in incognito o privata. Ciò evita eventuali conflitti tra il tuo account personale e l'account studente, che potrebbero causare addebiti aggiuntivi sul tuo account personale.
Questo lab è incentrato sull'esecuzione di job Apache Spark su Cloud Dataproc.
Durata:
Configurazione in 0 m
·
Accesso da 90 m
·
Completamento in 90 m



 ), seleziona IAM e amministrazione > IAM.
), seleziona IAM e amministrazione > IAM.
![gcs_bucket='[Your-Bucket-Name]'](https://cdn.qwiklabs.com/lxRwZFWWNgly1JKdY9s5JNVNwgW4rKxzYKwBIgkHlBw%3D)