
始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
BQ Dataset Created
/ 20
BQ Table JSON
/ 20
BQ Table CSV
/ 20
BQ Player Query
/ 20
BQ Events Query
/ 20


情報へのアクセスを構築する際にはさまざまな形式を扱いますが、BigQuery を使用すると複数のデータソースを簡単に操作できます。このラボでは、スポーツに関する外部データソースを BigQuery テーブルにインポートし、スポーツ データ サイエンスに挑戦します。これにより、後続のラボでより高度な分析を構築するための基礎が身に付きます。
このラボで使用するデータは、次のソースから取得されます。
このラボでは、次の方法について学びます。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

[Cloud コンソールの BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスには、クイックスタート ガイドとリリースノートへのリンクが表示されます。
BigQuery コンソールが開きます。
BigQuery コンソールには、テーブルに対してクエリを実行するためのインターフェースが用意されており、BigQuery が提供する一般公開データセットも利用できます。また、データセットに情報を追加する便利な方法も提供されています。BigQuery では、テーブルを使用してデータを構造化された方法で表現します。次のセクションでは、BigQuery とカスタム テーブルの作成方法について詳しく学びます。
このセクションでは、データセットを作成します。このデータセットを使用して、プロジェクトにデータを追加します。データセットにはテーブルとビューがあり、プロジェクト内のデータアクセスを制御するために使用されます。
![ハイライト表示された [データセットを作成] オプション](https://cdn.qwiklabs.com/SXQX9UvusFy1Vqy2T5Pxyu1Qo65VyPeS06j41YKS6N4%3D)
| フィールド | 値 |
|---|---|
| データセット ID | soccer |
| データのロケーション | us(米国の複数のリージョン) |
| [詳細オプション] > [デフォルトのテーブルの有効期限] | デフォルト |
![データセットの詳細とハイライト表示された [データセットを作成] ボタンが表示された [データセットの作成] 画面。](https://cdn.qwiklabs.com/KgP1CGXWGB8A0GiS1B7V5Z2BHVypiIirdhCNQhJIyq4%3D)
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このセクションでは、BigQuery を使用して新しいデータセットを作成しました。このプロセスでは、作成する情報をどこに保存するかを BigQuery に指定する必要があります。必要に応じて、顧客管理の暗号化を含めることもできます。
次のセクションでは、一般的なデータ形式である JavaScript Object Notation(JSON)を使用して、作成したデータセットにデータを入力する方法を学びます。
今度は、サッカーのデータを使用して事前に作成したテーブルをデータセットに読み込みます。
BigQuery は、さまざまなインポート形式をサポートしています。このラボでは、前のセクションで作成したデータセットで JSON を使用します。
[エクスプローラ] セクションで soccer データセットの横にあるアクションを表示アイコンをクリックし、テーブルを作成します。
[テーブルを作成] を選択します。
次のセクションでは、別途指定のない限り、すべての設定にデフォルト値を使用します。データは Google Cloud Storage の公開バケットに保存されています。
| フィールド | 値 |
|---|---|
| テーブルの作成元 | Google Cloud Storage |
| バケットからファイルを選択 | spls/bq-soccer-analytics/competitions.json |
| ファイル形式 | JSONL(改行区切り JSON) |
| テーブル名 | competitions |
| スキーマ | [スキーマ] の [自動検出] チェックボックスをオンにする |
gs:// というプレフィックスを適用する必要はありません。
![[データセットの作成] 画面。[ソース]、[宛先]、[スキーマ] の各セクションが表示されている。](https://cdn.qwiklabs.com/M5tK5HHy8Z1dCU8fBZxpFwfATxyphUClVyk3o97KaCQ%3D)
| Cloud Storage バケットのファイル | テーブル名 |
|---|---|
| spls/bq-soccer-analytics/matches.json | matches |
| spls/bq-soccer-analytics/teams.json | teams |
| spls/bq-soccer-analytics/players.json | players |
| spls/bq-soccer-analytics/events.json | events |
![[エクスプローラ] メニューの soccer データセットの下にリストされているテーブル](https://cdn.qwiklabs.com/qNRe%2Fz2TSF4pWwRW4Vy5XQgTgCbPwV7jIbcj8ISHBLk%3D)
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このセクションでは、BigQuery を使用して新しいテーブルを作成しました。このプロセスでは、JSON ファイルの参照元として Cloud Storage を使用しました。Cloud Storage は、オブジェクト ファイルの中間ストレージとして使用するのに適したストレージです。
次のセクションでは、作成したデータセットに、もう一つの一般的なデータ形式であるカンマ区切り値(CSV)ファイルを読み込む方法を学びます。
このセクションでは、サッカーのデータがある別のテーブルをこのデータセットに読み込みます。今回の読み込みプロセスのソースとして使用するのは、Cloud Storage に保存されているカンマ区切り値(CSV)ファイルです。
soccer データセットの横にあるアクションを表示アイコンをクリックし、[テーブルを作成] を選択します。別途指定のない限り、すべての設定にデフォルト値を使用します。
| フィールド | 値 |
|---|---|
| テーブルの作成元 | Google Cloud Storage |
| バケットからファイルを選択 | spls/bq-soccer-analytics/tags2name.csv |
| ファイル形式 | CSV |
| テーブル名 | tags2name |
| スキーマ | [自動検出] チェックボックスをオンにします。 |
![[テーブルの作成] 画面。[ソース]、[宛先]、[スキーマ] の各セクションが表示されている。](https://cdn.qwiklabs.com/TIxjs6XUXu2TDdzOv%2B9FcuWnnDS%2BaI0SGTGZdDQIxNQ%3D)
「tags2name」が作成されたことを示すポップアップ メッセージが表示されます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このセクションでは、BigQuery を使用して新しいテーブルを作成しました。このプロセスでは、CSV ファイルの参照元として Cloud Storage を使用しました。Cloud Storage は、オブジェクト ファイルの中間ストレージとして使用するのに適したストレージです。
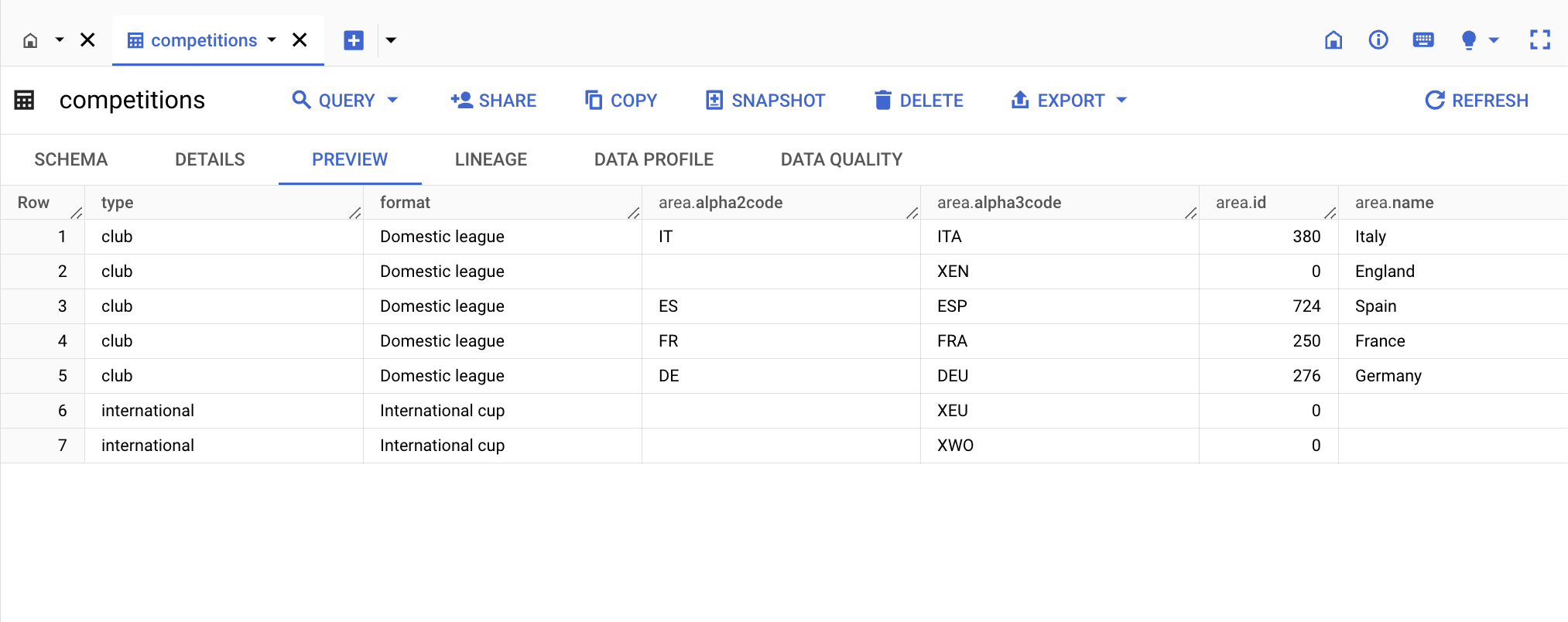
BigQuery では、これまでさまざまな形式で保持されていたデータを簡単に保存できます。BigQuery でデータを取り込む手法について詳しくは、データ取り込み方法の選択をご覧ください。
次の 2 つのセクションでは、BigQuery で作成したデータセットに対してクエリを実行する方法を学びます。
テーブルにデータが読み込まれたので、クエリを実行できます。次に、players テーブルで、身長がわかっているディフェンダーのうち、身長の高い上位 10 人を取得するクエリを作成します。
![[結果] タブページに表示されたクエリ結果。](https://cdn.qwiklabs.com/zR0pE3gsmzBeaa5NBzp123znYsOXtaL9tGrSIp5v%2BP0%3D)
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
BigQuery でクエリを実行する方法を理解することは不可欠です。BigQuery のクエリは、強力なデータ分析情報を簡単に抽出できる手段です。
events テーブルで見つかったすべてのイベントタイプの数を取得するクエリを作成します。
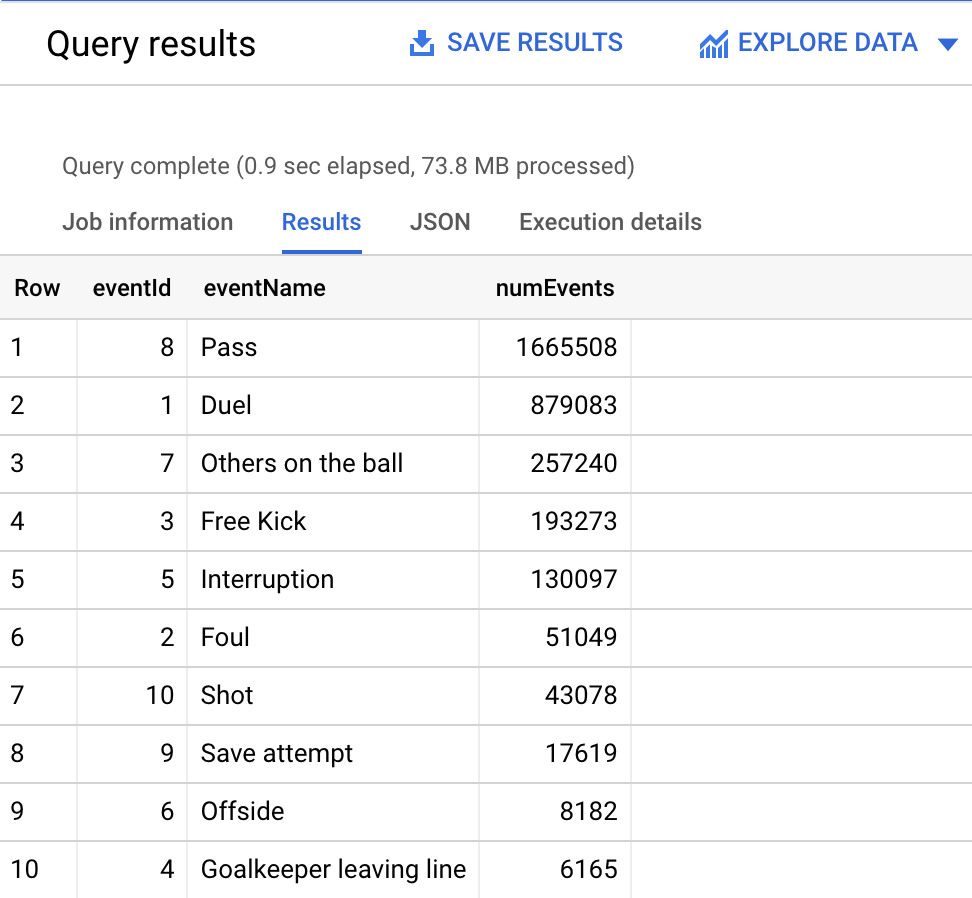
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
保存されたデータを活用して傾向やパターンを確立できると、エンドユーザーに真のメリットをもたらせる機会が増えます。次のセクションでは、ここまで学んできた BigQuery の概要の理解度をテストします。
このラボで扱ったトピックに関する短い問題に答えて、BigQuery の理解度をテストしてください。
Cloud Storage に保存されているファイルを BigQuery のテーブルにアップロードし、テーブルからデータを抽出するクエリを作成する方法を学びました。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2025 年 11 月 24 日
ラボの最終テスト日: 2025 年 7 月 29 日
Copyright 2026 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください