
Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Create an incremental persistent derived table
/ 40
Create an aggregate table
/ 30
Join the minimal amount of views new Explores
/ 30
Create an incremental persistent derived table
/ 40
Create an aggregate table
/ 30
Join the minimal amount of views new Explores
/ 30

Looker 是 Google Cloud 的現代化資料平台,提供互動式分析功能,並可用圖表呈現資料。您能使用 Looker 深入分析資料、整合各種資料來源的洞察資訊、設定可做為行動依據的資料導向工作流程,以及建立自訂資料應用程式。
複雜的查詢可能會耗費不少成本,重複執行則會對資料庫造成負擔,導致效能降低。理想情況下,如果資料沒有任何變動,應避免反覆執行大規模查詢,而是將新資料附加至現有結果,以減少重複要求。雖然有很多方法可以提升 LookML 查詢效能,但本實驗室將著重於 Looker 中最常用的查詢效能最佳化方法:永久衍生資料表、匯總感知和高效彙整檢視表。
請詳閱以下操作說明。實驗室活動會計時,且中途無法暫停。點選「Start Lab」後就會開始計時,顯示可使用 Google Cloud 資源的時間。
您將在真正的雲端環境中完成實作實驗室活動,而不是在模擬或示範環境。為達此目的,我們會提供新的暫時憑證,讓您用來在研究室活動期間登入及存取 Google Cloud。
如要完成這個研究室活動,請先確認:
準備就緒後,請點選「Start Lab」。
「Lab Details」窗格會顯示本實驗室中必須使用的暫時憑證。
如果實驗室會產生費用,畫面中會出現選擇付款方式的彈出式視窗。
請在「Lab Details」窗格查看實驗室憑證,您之後會使用此憑證登入實驗室的 Looker 執行個體。
點選「Open Looker」。
分別在「Email」和「Password」欄位,輸入提供的使用者名稱和密碼。
使用者名稱:
密碼:
點選「Log In」。
成功登入後,您就會在本實驗室看到 Looker 執行個體。
本節將介紹 Looker 中常用的查詢效能最佳化方法。在本實驗室中,您會實際運用前三種方法。
第一種解決方案是永久衍生資料表 (PDT)。Looker 可讓您將 SQL 和 LookML 查詢以臨時資料表的形式寫入資料庫。如果系統加以快取或保留,該資料表就會成為所謂的 PDT。如此一來,您就能重複執行複雜或常用的查詢,並將結果儲存在快取中,以便快速存取。
將這些查詢儲存為資料表後,您便可控制資料表的建構時機和方式。資料表可以每天早上、每月一次或只在有新資料加入時重新建構。理想做法是根據資料性質設定衍生資料表。
衍生資料表適用於建立底層資料庫資料表中沒有的新結構或匯總資料,但並非所有衍生資料表都必須保留下來才能發揮作用。保留機制通常適用於執行成本高昂的複雜查詢,或是大量使用者/應用程式經常使用的查詢。
您也可以建立永久累加型衍生資料表,直接「附加」新資料,而不必重新建構整個資料表。如果資料表很大,且現有的舊資料不常更新,就適合只套用增量變更,因為主要的更新內容是新增的記錄。
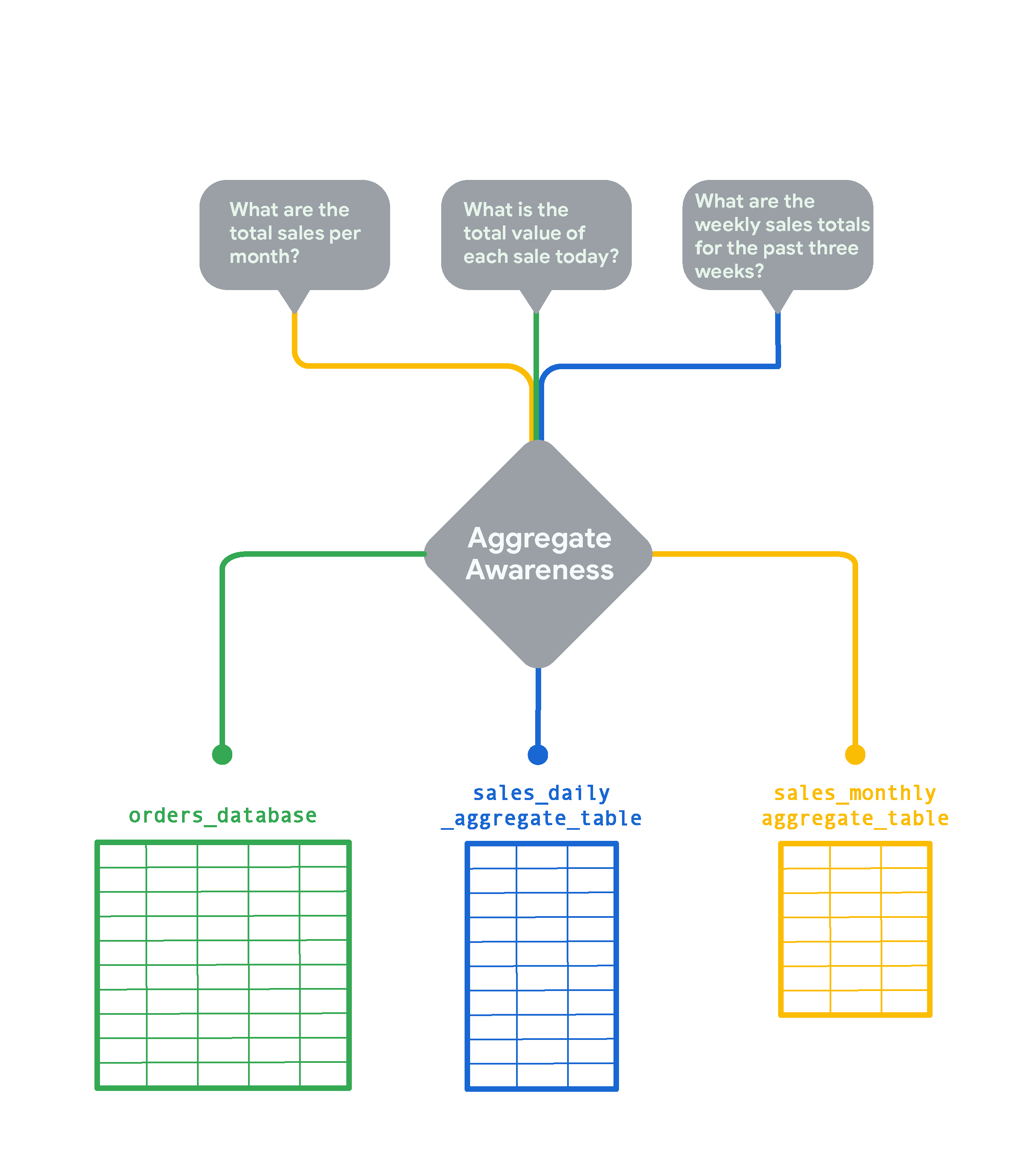
對於資料庫中的超大型資料表,Looker 的匯總感知功能可以建立較小的匯總資料表,將資料依不同屬性組合分組。匯總資料表就像「匯總」或「彙整」資料的表格,Looker 可在查詢時盡可能使用這類資料表,而非原始的大型資料表。匯總感知功能可讓 Looker 在資料庫中找出最小、最有效率的資料表來執行查詢,同時維持結果的準確性。如果在妥善規劃下導入這項功能,可讓平均查詢速度提升好幾倍。假設有家電子商務商店的生意非常好,線上訂單資料表每隔幾秒就會新增好幾列資料。
如果想追蹤即時訂單,就需要更多的詳細資料,但若想確認「每月銷售總額」等每月趨勢,查看每月匯總資料會更快,也更符合成本效益。在這種情況下,Looker 會建立並查詢 sales_monthly_aggregate_table。
如果想知道「今天每筆交易的總金額」這類資訊,就需要資料列級的詳細訂單資料。在這種情況下,Looker 會查詢原始 orders_database 資料表,而不匯總資料。如想查看過去三週的每週銷售總額,Looker 會建立並選取每日銷售匯總資料表。這個資料表比每月銷售資料表更詳細,但仍是 orders_database 原始資料的匯總結果。
Looker 的匯總感知功能通常用於匯總或彙整多個時間範圍的資料。此外,匯總資料表必須保留在 Looker 執行個體中,才能供匯總感知功能使用。
提升效能的另一個方法是在定義新探索時,只彙整「所需的檢視表」。為盡量減少彙整次數,您可以針對不同用途定義多個探索,例如依使用者查詢資料、查詢銷售匯總資料。此外,請使用「基本欄位」 (而非「串連欄位」) 做為主鍵,並盡可能採用 many_to_one 彙整,也就是將最詳細的檢視表分別彙整至提供整體資料的檢視表 (many_to_one),這麼做通常能讓 Looker 發揮最佳查詢效能。
在探索定義中加入篩選器,可防止系統預設傳回大量資料,進而提升效能。篩選器有許多種類,包括使用者可看到及修改的篩選器,例如 always_filter 和 conditionally_filter。您也可以修改探索欄位的篩選建議。如要進一步瞭解探索篩選器並練習操作,請參加「運用 LookML 篩選探索」實驗室。
為減少資料庫查詢流量,請充分利用快取功能,盡可能配合擷取、載入及轉換 (ETL) 政策。根據預設,Looker 會快取查詢一小時。您可以使用 persist_with 參數,在探索中套用資料群組,藉此控管快取政策,並讓 Looker 資料重新整理作業與 ETL 程序保持同步。這樣 Looker 就能與後端資料管道更密切整合,在充分利用快取的同時,也降低分析到過時資料的風險。
舉例來說,有些資料表可能每天只更新一次,因此每小時重新整理快取並無實質效益。在本實驗室中,您將使用 Looker 的各種自訂快取選項 (包括資料群組或快取政策) 來保留衍生資料表。如要進一步瞭解快取政策並練習操作,請參加「透過 LookML 使用快取和資料群組功能」實驗室。
視所用的資料庫方言而定,您還可以探索其他其他查詢最佳化功能,如 cluster_keys 和索引。
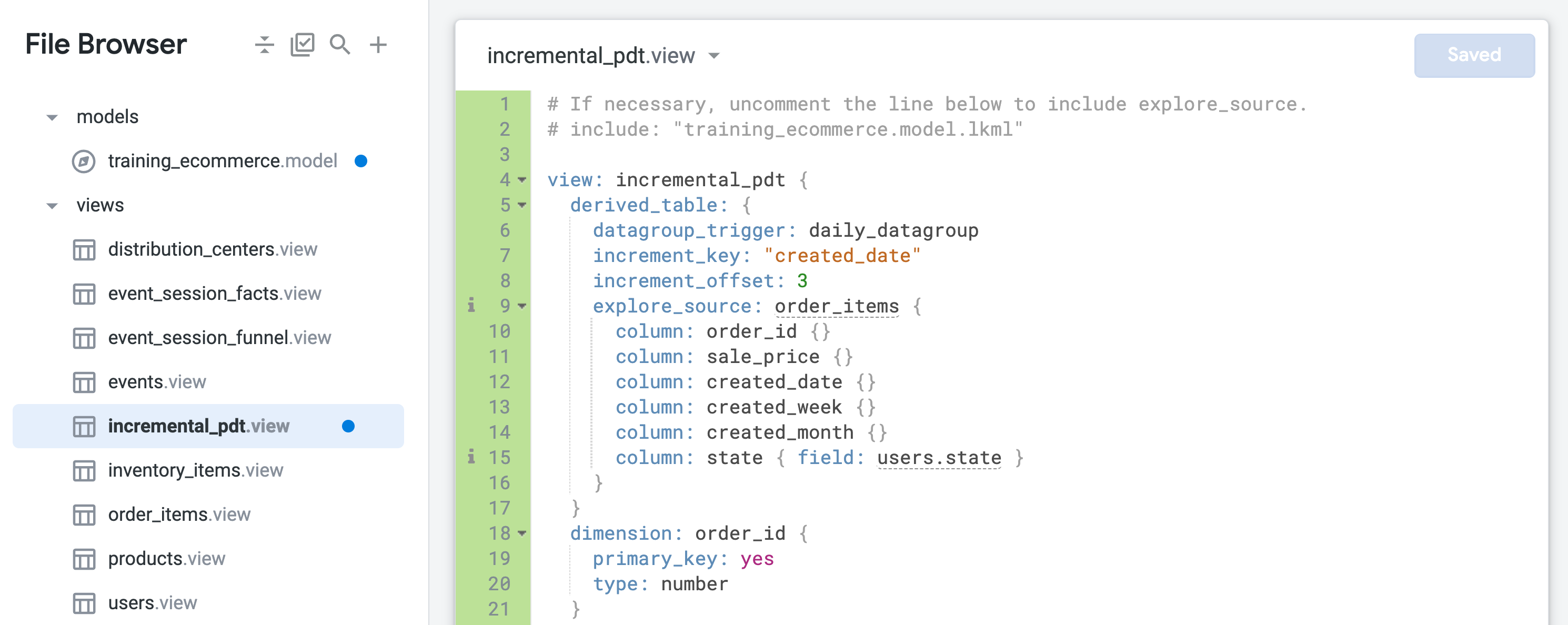
如先前所述,永久衍生資料表 (PDT) 是寫入資料庫臨時結構定義的衍生資料表,且會按照您透過保留策略指定的排程重新產生。PDT 的實用之處在於,當使用者提出資料要求時,資料表通常已存在,因此可縮短查詢時間並降低資料庫負載。
在標準 PDT 中,系統會根據快取政策中設定的排程,重新建構「整個」資料表。相較之下,「累加型」PDT 只會將最新資料附加至現有資料表,這樣可以大幅縮減傳送至資料庫的查詢大小。
在這項工作中,您將建立原生衍生資料表 (NDT),依時間範圍或州別匯總訂單資料。此外,您也會啟用保留功能、指定每天重新整理,並採用增量更新機制 (回溯過去 3 天的資料) 來擷取延遲資料。
按一下切換鈕進入「開發模式」。
依序前往「探索」>「Order Items」。
在「Order Items」>「維度」底下,選取下列項目:
在「使用者」>「維度」底下,選取「State」。
點選「執行」。
點選「設定」圖示 
選取「取得 LookML」。
在「衍生資料表」分頁中,將 LookML 程式碼複製到文字編輯器。
您將使用這段程式碼,為原生衍生資料表建立新檢視表。
在新瀏覽器分頁中開啟新的 Looker 視窗。
在「開發」選單中,點選「qwiklabs_ecommerce」。
點選「檔案瀏覽器」旁的加號圖示 (+),然後選取「建立檢視表」。
將新檔案命名為 incremental_pdt,然後點選「建立」。
在「檔案瀏覽器」中,點選「incremental_pdt.view」並拖曳至「views」資料夾。
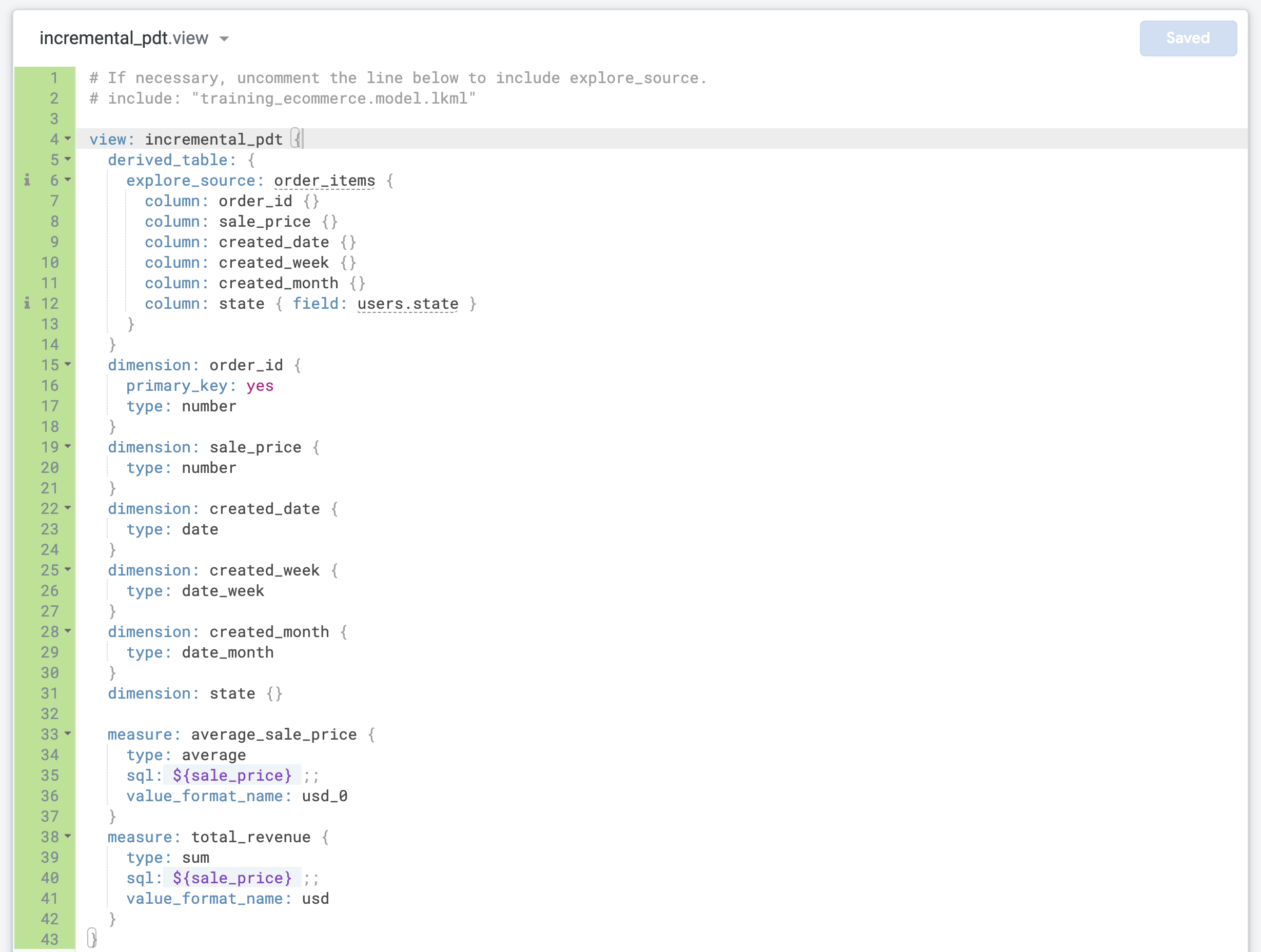
將 incremental_pdt.view 中的預設 LookML 程式碼,改成您先前複製的原生衍生資料表程式碼。
將第 4 行更新為正確的檢視表名稱 (incremental_pdt)。
更新 order_id 維度,將其定義為檢視表的 primary_key:
這麼做是因為每筆記錄都代表一筆訂單,且有專屬的 order_id。
}) 前新增兩個測量指標:開啟「training_ecommerce.model」。
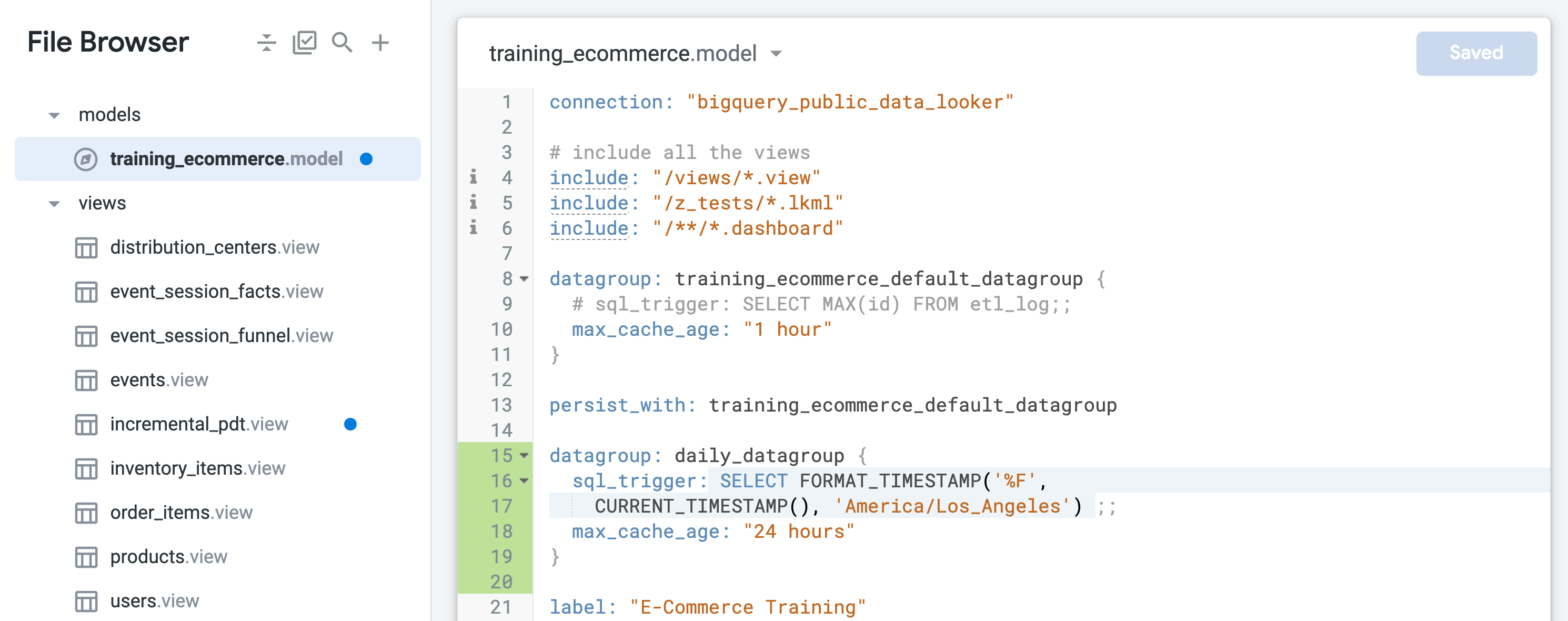
找出名為 training_ecommerce_default_datagroup 的預設資料群組,並新增一行 (第 13 行)。
定義新的資料群組,用來保留物件 (時間上限為 24 小時) 並設定每日重新整理:
sql_trigger 會檢查當前日期,並在日期變更時觸發重新整理作業,max_cache_age 則是確保資料表會在 24 小時後重新建構,即使 sql_trigger 執行失敗也一樣。
training_ecommerce.model 檔案結尾 (約第 67 行),定義一個只包含 incremental_pdt 檢視表的新探索,以便在後續步驟中進行測試:系統現在會保留這個永久衍生資料表,而且每天會重新建構一次,回溯過去 3 天的資料來擷取任何可能延遲送達的訂單。
在瀏覽器分頁中開啟新的 Looker 視窗。
依序前往「探索」>「增量 PDT」。
在「資料」窗格中,開啟「SQL」分頁。
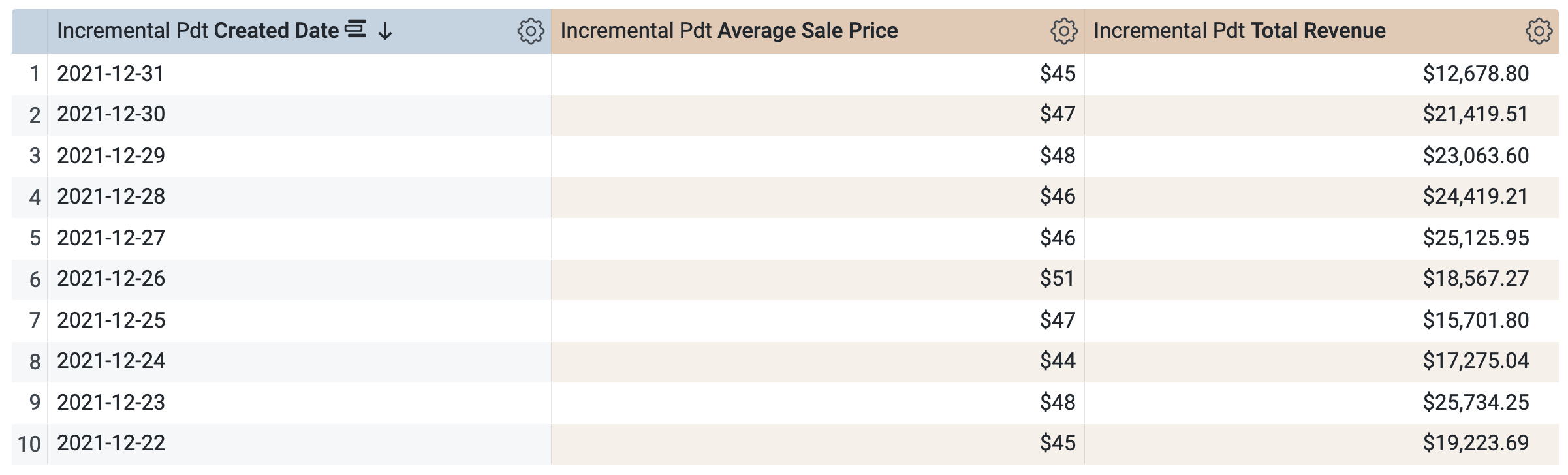
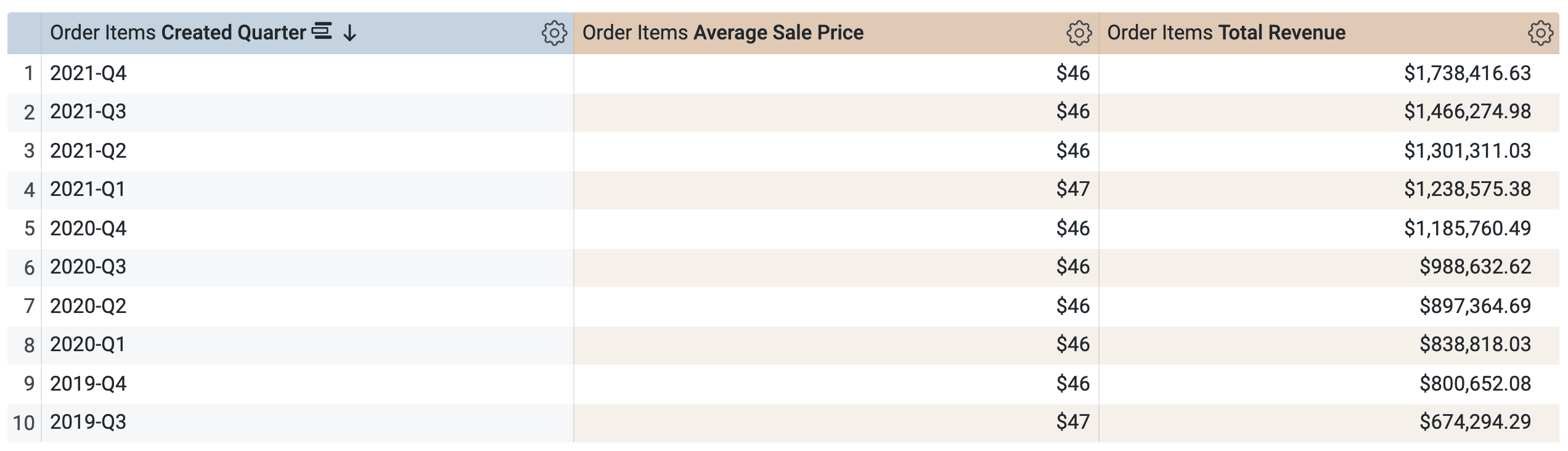
在「增量 PDT」>「維度」底下,選取「建立日期」。
在「增量 PDT」>「度量」底下,選取「Average Sale Price」和「Total Revenue」。
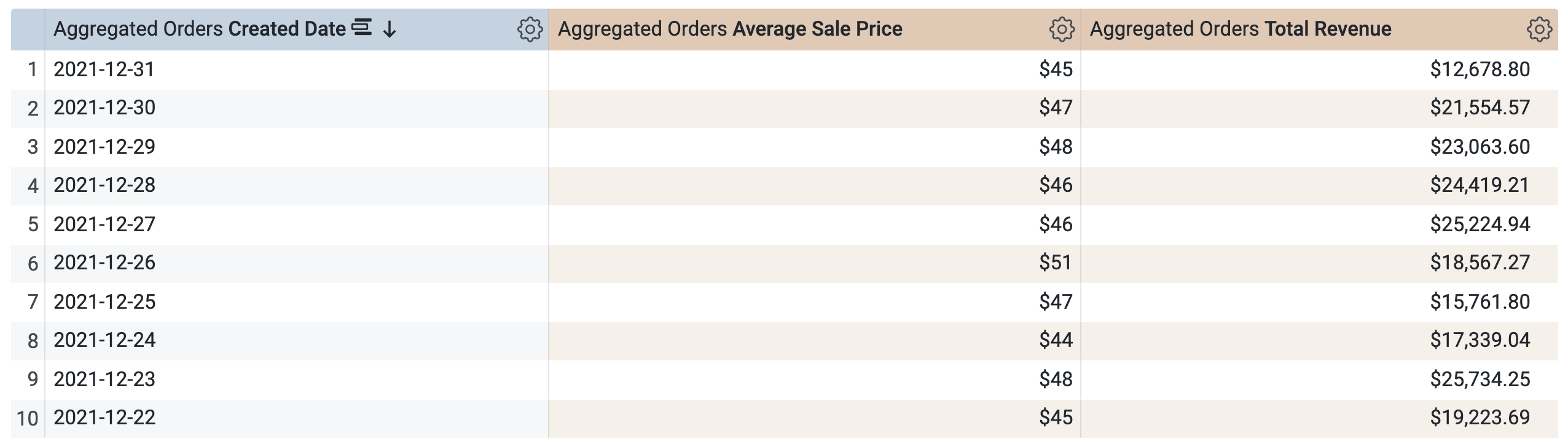
執行查詢前,請注意 SQL 視窗中會有「兩個」查詢 (可能需要幾秒鐘載入)。第一個查詢會產生名為 incremental_pdt 的 PDT,第二個查詢則會從新建立的 PDT 中擷取結果。
點選「執行」。
開啟「結果」分頁來查看結果。
在「增量 PDT」>「維度」底下,執行以下操作:
在「資料」窗格中,開啟「SQL」分頁。
提醒您,查詢會使用同一個 PDT 來擷取結果,這很合理,因為您要求的時間範圍已在 PDT 中定義 (且已快取)。不過請注意,您無法針對 PDT 中未包含的其他時間範圍 (如季別或年分) 選取和執行查詢。
點選「執行」。
開啟「結果」分頁來查看結果。
關閉探索查詢的瀏覽器分頁,然後回到 Looker IDE 所在的瀏覽器分頁。
點選「驗證 LookML」。
此時應該不會出現任何 LookML 錯誤。
依序點按「驗證 LookML」>「修訂變更並推送」。
新增修訂版本訊息,然後點按「修訂」。
最後,點按「部署至正式環境」。
請留在 Looker IDE 的瀏覽器分頁,準備開始執行下一項工作。
點選「Check my progress」,確認目標已達成。
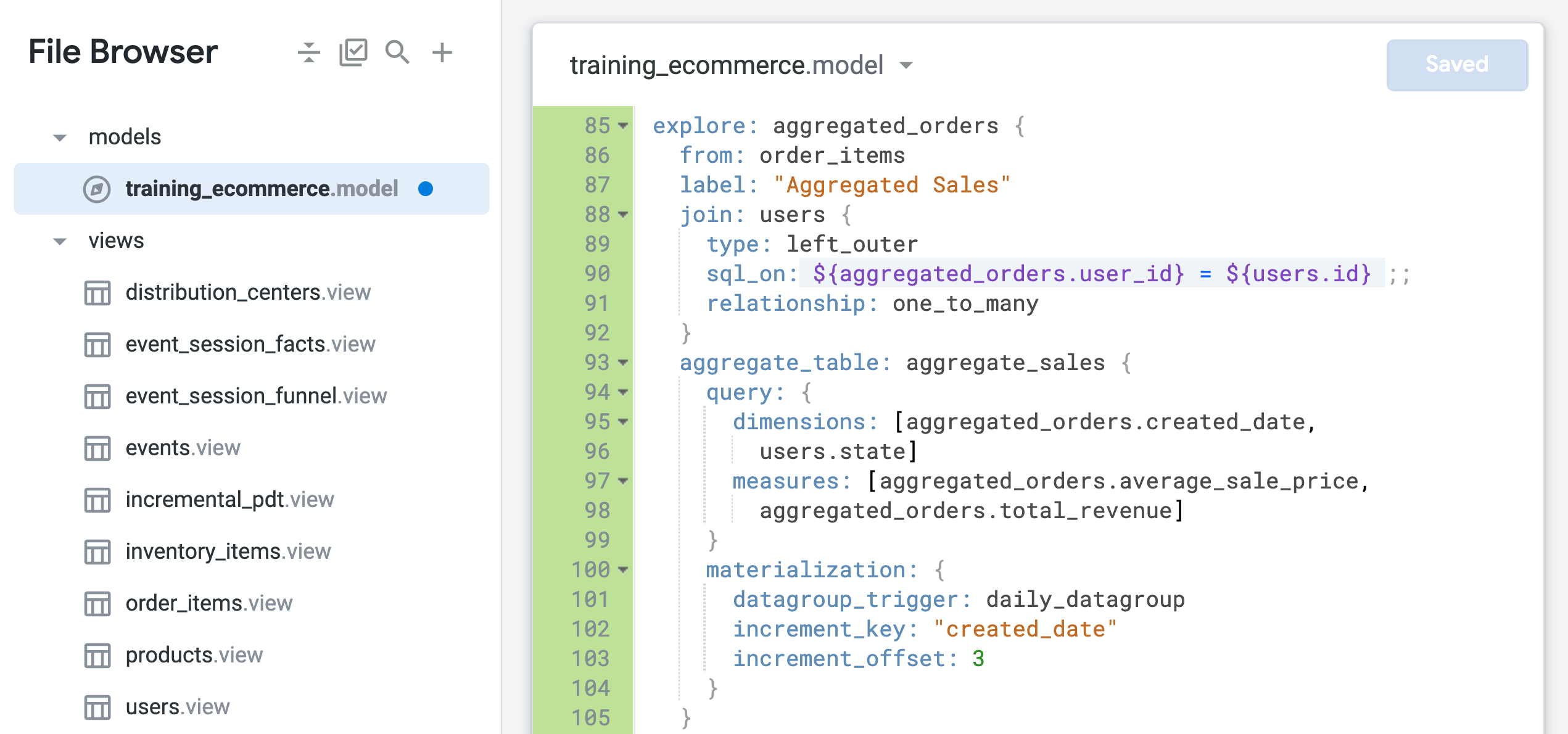
在 Looker 中,您可以建立符合策略需求的匯總資料表,盡量減少須對資料庫中大型資料表執行查詢的次數。匯總資料表必須保留在資料庫中,才能供匯總感知功能使用。因此,匯總資料表也是一種永久衍生資料表 (PDT)。
匯總資料表是透過 LookML 專案中「探索」參數下的 aggregate_table 參數定義。建立匯總資料表後,您可以在「探索」中執行查詢,看看 Looker 使用哪些匯總資料表。Looker 會運用匯總感知邏輯,在資料庫中找出最小、最有效率的匯總資料表來執行查詢,同時維持結果的正確性。
在這項工作中,您將重新建立前一項工作的永久累加型衍生資料表,做為新的累加型匯總資料表,並且透過現有「Order Items」探索的修改設定,將新的匯總資料表提供給使用者。
在 Looker IDE 頁面中,開啟「training_ecommerce.model」。
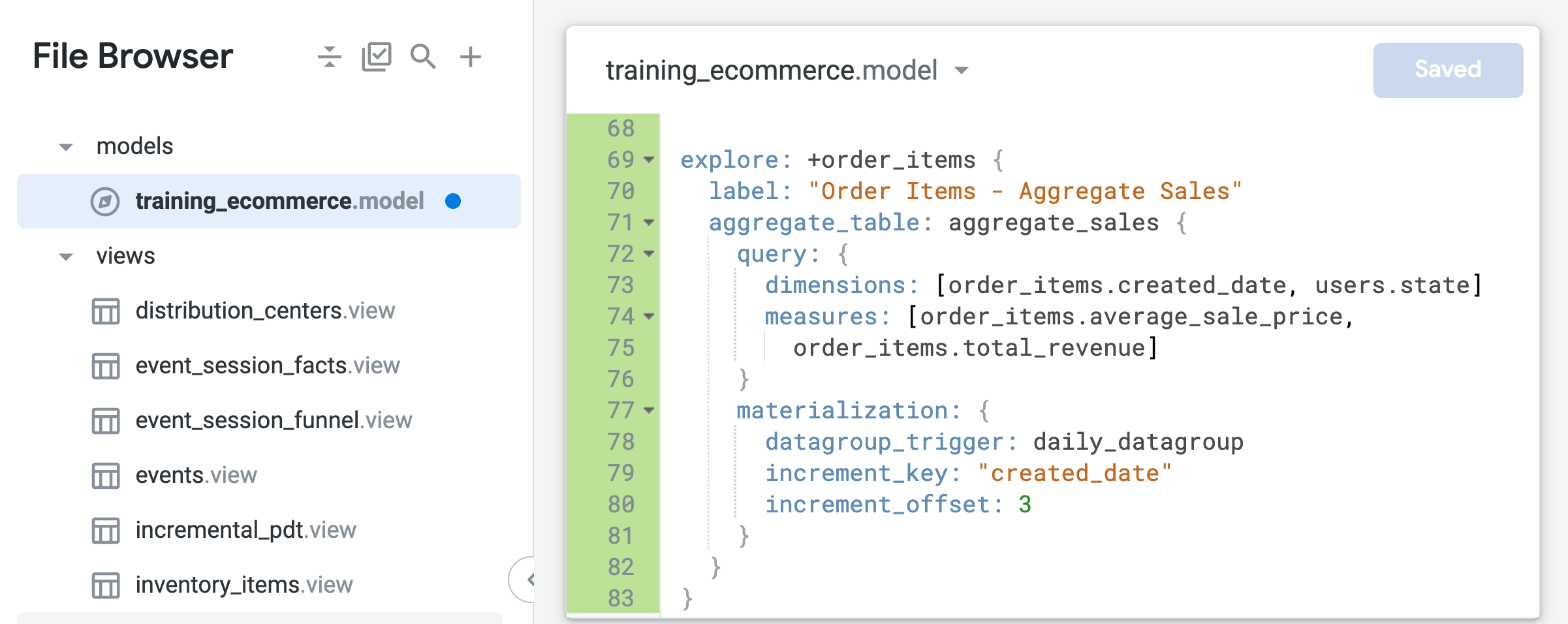
在檔案結尾處 (約第 69 行) 加入下列程式碼,建立 order_items 探索的修改設定:
這項修改設定以模型檔案中定義的現有 order_items 探索為建構基礎,並加入新 LookML 程式碼中指定的修改內容,例如要在後續步驟加入的標籤或匯總資料表。
請注意,與前一項工作中建立的原生衍生資料表不同,這個匯總資料表中僅指定 created_date 這個時間維度。有了匯總感知功能,如有使用者執行探索查詢,要取得按時間匯總的平均售價或總收益資料 (無論指定的時間範圍為日、月或年),Looker 都能透過這個單一資料表來提供結果。
請勿關閉這個 Looker IDE 分頁。
在瀏覽器分頁中開啟新的 Looker 視窗。
依序前往「探索」>「Order Items - Aggregate Sales」。
在「資料」窗格中,開啟「SQL」分頁。
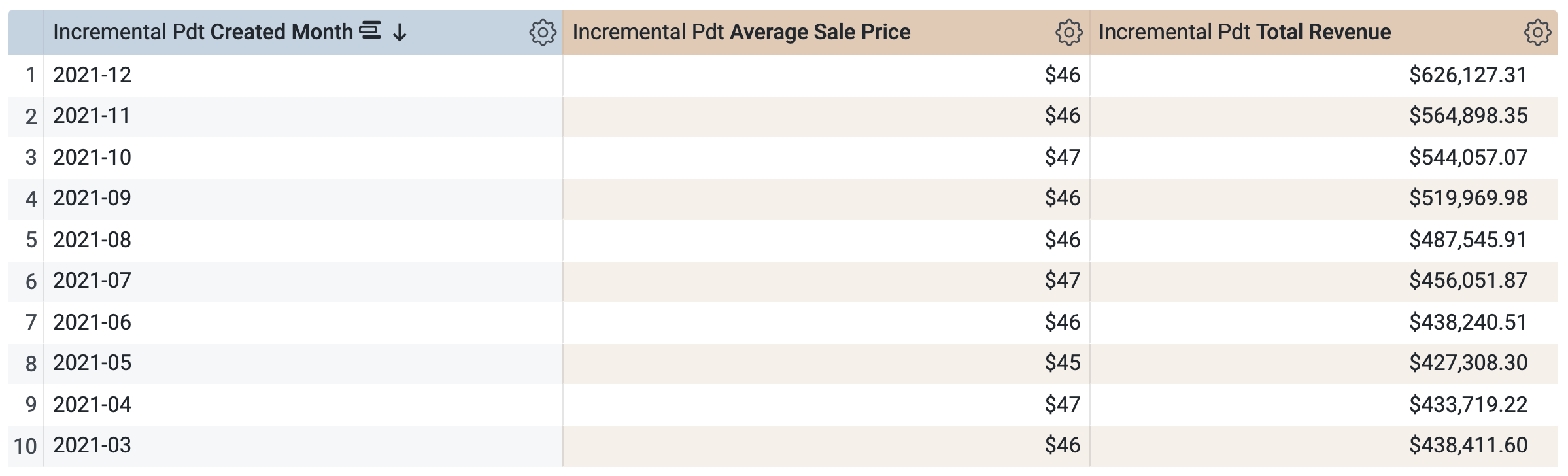
在「Order Items」>「維度」底下,選取「建立日期」>「日期」。
在「Order Items」>「度量」底下,選取「Average Sale Price」和「Total Revenue」。
執行查詢前,請注意這裡會有兩個查詢,與工作 1 中的 SQL 視窗類似。第一個查詢會產生名為 aggregate_sales 的 PDT,第二個查詢則會從這個新 PDT 中擷取結果。
點選「執行」。
開啟「結果」分頁來查看結果。
在「Order Items」>「維度」>「建立日期」底下,執行以下操作:
在「資料」窗格中,開啟「SQL」分頁。
請注意,查詢會使用同一個 PDT (aggregate_sales) 擷取依季度匯總的結果。Looker 會運用匯總感知功能,根據在「建立日期」底下指定的時間範圍匯總平均售價和總收益資料。
點選「執行」。
開啟「結果」分頁來查看結果。
關閉探索查詢的瀏覽器分頁,然後回到 Looker IDE 所在的瀏覽器分頁。
點選「驗證 LookML」。此時應該不會出現任何 LookML 錯誤。
依序點按「驗證 LookML」>「修訂變更並推送」。
新增修訂版本訊息,然後點按「修訂」。
最後,點按「部署至正式環境」。
請留在 Looker IDE 的瀏覽器分頁,準備開始執行下一項工作。
點選「Check my progress」,確認目標已達成。
如要在 Looker 中設定高效能的探索,有效率的彙整是一大關鍵要素。為提高彙整效率,請務必只彙整定義探索所需的檢視表,並使用基本欄位 (而非串連欄位) 做為檢視表的主鍵,且盡可能使用 many_to_one 彙整。
如說明文件所述,主鍵可為檢視表中的記錄提供專屬 ID,這是在 Looker 中準確匯總資料和建立關係的必要條件。檢視表的主鍵是「包含不重複值的欄位」 (例如 ID 資料欄),在檢視表檔案中會透過 primary_key: yes 參數標示。
在本節中,您會先找出最適合做為檢視表主鍵的資料欄,然後為匯總資料表定義新的探索,只彙整 users 檢視表,並使用 from 參數將 order_items 指定為探索的基本檢視表,接著再彙整 users 檢視表。最後,您將省略現有 Order Items 探索中的其他彙整,並使用 many_to_one 彙整關係來提高查詢效率。
在 users.view 中,ID 欄已透過 primary_key: yes 標示為主鍵。這是一個基本欄位,包含不重複的值 (每位使用者一個 ID),而不是由多個資料欄建立而成的串連欄位。因此,ID 最適合用來做為 users 檢視表的主鍵,有助於提升彙整效率。
order_item_id 是根據 order_items 資料表的 ID 欄建立,且已標示為主鍵。不過,這個檢視表中的其他 ID 欄位也有可能是資料表的不重複索引鍵,包括 order_id,這是根據 order_items 資料表中 order_id 欄建立的欄位。
在後續步驟中,您將透過 SQL Runner 探索 order_items 資料表,瞭解為什麼 order_item_id 欄位最適合做為主鍵。
在新瀏覽器分頁中開啟新的 Looker 視窗。
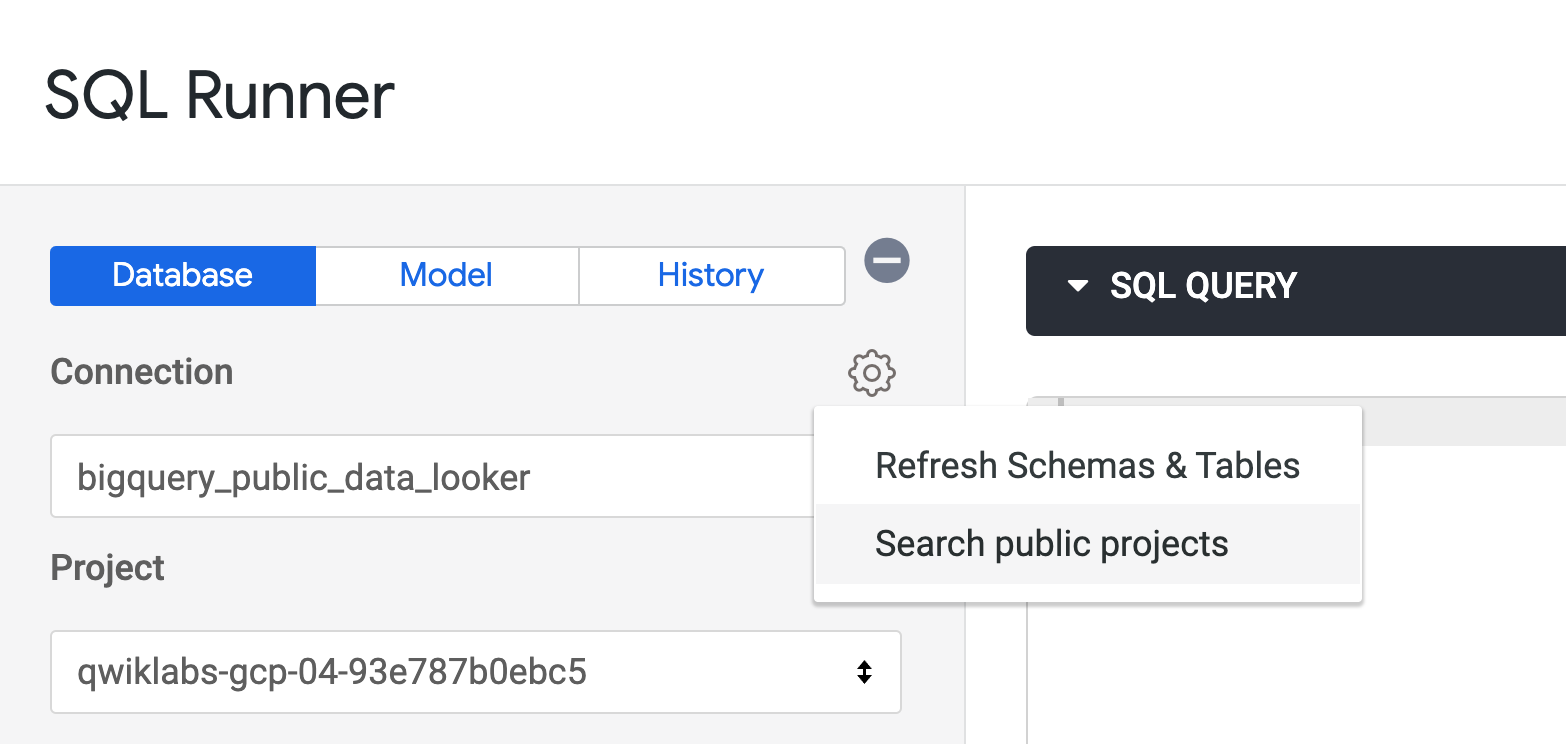
依序前往「開發」>「SQL Runner」。
點選「連線」旁的「設定」圖示
「專案」方塊現在應該是空的。請輸入 cloud-training-demos,然後按下 Enter 鍵。
在「資料集」部分,選取 looker_ecomm。
系統會顯示這個 BigQuery 資料集中的可用資料表清單。
如要快速輕鬆地確認特定資料欄是否適合做為主鍵,可以比較資料表中的「記錄數量」與資料欄中的「不重複值數量」。如果兩者相等,表示該欄中的值皆不重複,適合做為資料表的主鍵。
user_id 欄是否適合做為主鍵,請將下列查詢新增至「SQL 查詢」視窗,然後點選「執行」:order_id、inventory_item_id 和 id 欄重複執行上列查詢。在本例中,id 和 inventory_item_id 的不重複值數量都與資料表中的記錄數量相等,這兩欄雖然列的是不同 ID,但都是代表同一筆訂單中的同一個商品,因此兩者都可做為主鍵。
不過,這裡選擇 id 欄做為 order_items 的主鍵,因為該欄的值是 order_items 資料表中針對各個商品產生的 ID,而 inventory_item_id 的值則是同一商品在 inventory_items 資料表中的 ID。
開啟「training_ecommerce.model」。
查看現有的 order_items 探索。
請注意,這個探索包含四個不同的彙整,每個都使用 many_to_one 關係類型。視用途而定,這些彙整可能全都需要。不過,如果只需要按州別或時間範圍匯總的使用者和訂單資料,其實根本不會用到這些額外的彙整,使用的話反而會導致探索查詢速度變慢。
在後續步驟中,您將建立新的探索,只根據 order_items 檢視表的 user_id 和 users 檢視表的 id 來彙整訂單和使用者資料。
order_items 設為基本檢視表,且只彙整 users 檢視表:from 參數用來將 order_items 指定為探索的基本檢視表,而 users 檢視表則會彙整至該檢視表。order_items 檢視表中的欄位此時會使用新的探索名稱來識別,格式為 aggregated_orders.fieldname。
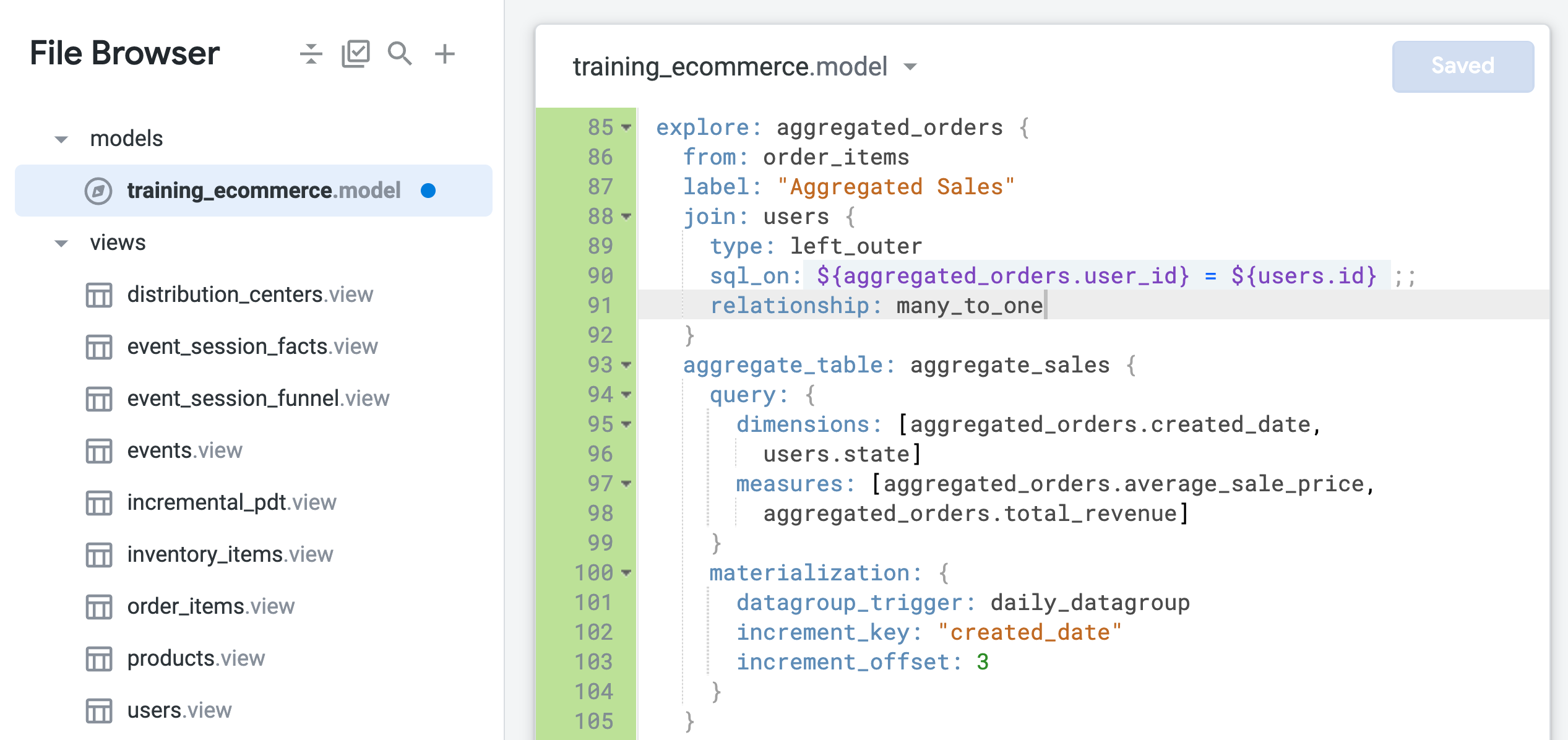
請注意,users 檢視表和 order_items 檢視表之間的關係目前標示為 one_to_many。在後續步驟中,您將測試這種以 one_to_many 關係進行彙整的設定,是否最適合這個探索。
在新瀏覽器分頁中開啟新的 Looker 視窗。
依序前往「探索」>「Aggregated Sales」。
在「資料」窗格中,開啟「SQL」分頁。
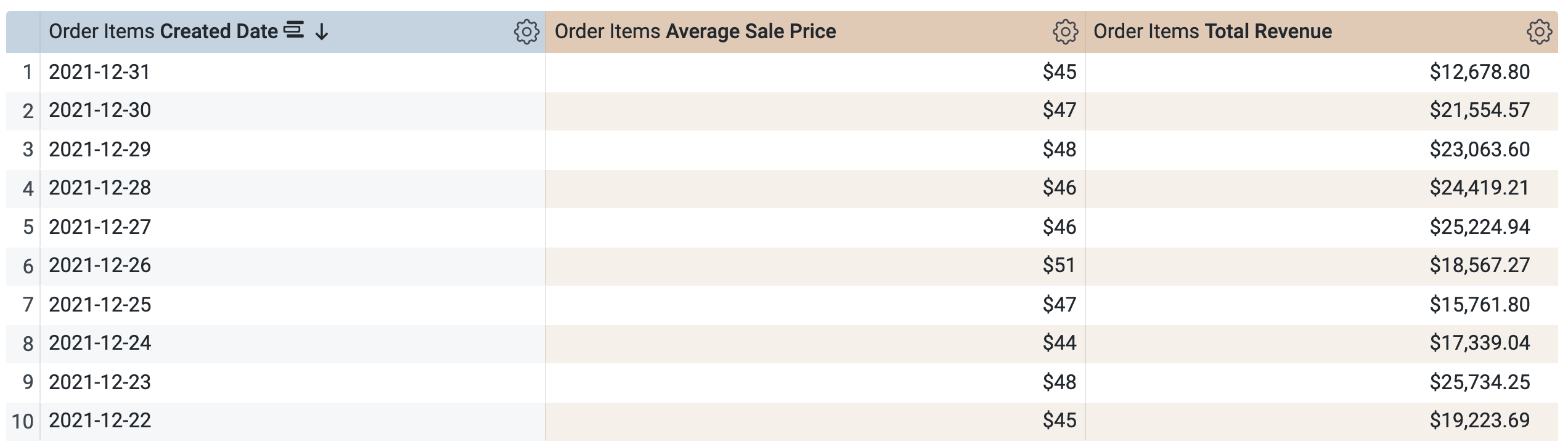
在「Aggregated Orders」>「維度」底下,依序選取「建立日期」>「日期」。
在「Aggregated Orders」>「度量」底下,選取下列項目:
執行查詢前,請注意匯總資料表會因彙整擴散傳遞問題而未使用:
如未正確標示要彙整的兩個資料表之間的關係,可能會引發非預期的擴散傳遞問題。在本例中,探索的基本檢視表是 order_items,其中可能包含「同一位使用者的多筆訂單」。然而,在 users 檢視表中,「每位使用者只有一筆記錄」。
因此,這個彙整應定義為 many_to_one,也就是多筆訂單對應至一位使用者,而非一筆訂單對應至多位使用者 (如要進一步瞭解擴散傳遞問題,請前往 Looker 說明中心)。
點選「執行」。
開啟「結果」分頁。
結果已傳回,但 Looker 並未透過有效率的匯總資料表擷取結果。
請勿關閉這個探索的瀏覽器分頁,回到 Looker IDE 所在的瀏覽器分頁。
在 aggregated_orders 探索中,將 relationship 參數更新為 many_to_one (第 91 行):
回到探索查詢的瀏覽器分頁,然後重新整理頁面。
在「資料」窗格中,開啟「SQL」分頁。
與工作 1 和 2 的「SQL」分頁類似,現在有兩個查詢:第一個用於產生 PDT,第二個用於從 PDT 擷取結果。
關閉探索查詢的瀏覽器分頁,然後回到 Looker IDE 所在的瀏覽器分頁。
點選「驗證 LookML」。
此時應該不會出現任何 LookML 錯誤。
依序點按「驗證 LookML」>「修訂變更並推送」。
新增修訂版本訊息,然後點按「修訂」。
最後,點按「部署至正式環境」。
請留在 Looker IDE 的瀏覽器分頁,準備開始執行下一項工作。
點選「Check my progress」,確認目標已達成。
Looker 可讓您透過「管理員」選單的「永久衍生資料表」頁面,監控 Looker 執行個體中的 PDT 建構情況。視 Looker 設定而定,Looker 使用者只要具備保留資料表的權限,即使沒有完整「管理員」選單的存取權,也能查看這個頁面。您可以查看開發和正式環境中的 PDT 狀態、建構時間和快取情形,以便輕鬆測試及監控 Looker 執行個體中的 PDT。
在這項工作中,您將監控在本實驗室建立的 PDT,包括狀態、建構時間、快取情形,以及正式與開發環境之間的差異。以 NDT 為基礎建立的永久累加型衍生資料表 (工作 1) 建構時間應該最長,而匯總資料表 (工作 2 和 3) 的建構時間應該最短。這是因為雖然使用相同的資料表定義,但兩者是套用於設定不同的探索。此外,您也會修改開發環境中的 PDT,並在推送至正式環境前後監控其狀態。
在新瀏覽器分頁中開啟新的 Looker 視窗。
依序前往「管理員」>「永久衍生資料表」。
所有 PDT 都已推送至正式環境,因此「開發」分頁中不會列出任何 PDT。
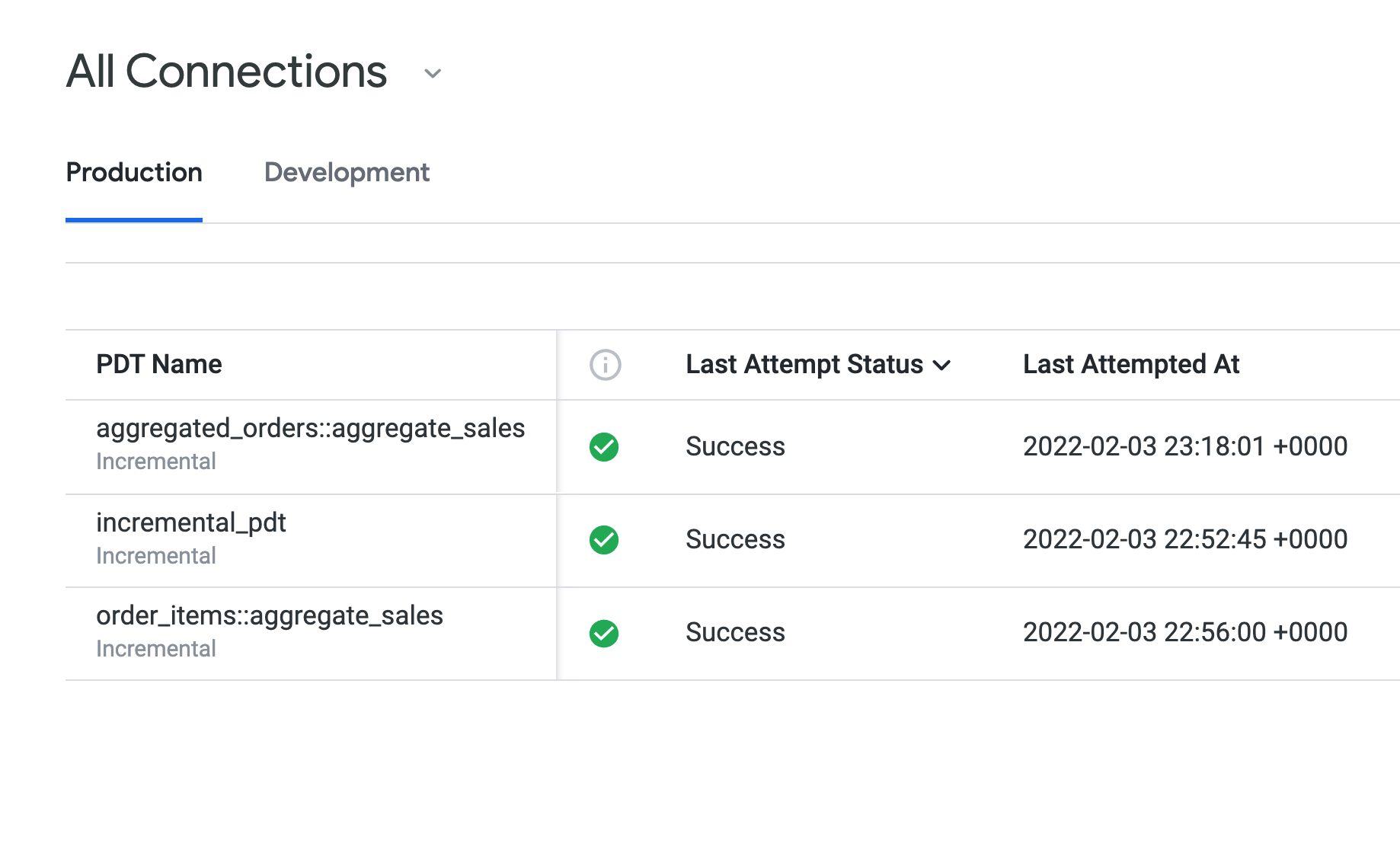
開啟「正式環境」分頁,查看在工作 1 至 3 建立的 PDT。
所有 PDT 的「上次嘗試狀態」欄都會顯示「成功」,且這些 PDT 都使用相同的保留規則 (daily_datagroup)。在「上次建構作業的持續時間」底下,incremental_pdt 的建構時間可能會比兩個匯總資料表稍長。
請勿關閉這個「永久衍生資料表」頁面,準備開始執行後續步驟。
回到 Looker IDE 所在的瀏覽器分頁。
開啟「training_ecommerce.model」。
在 aggregated_orders 探索中新增 users.country 維度 (大約在第 96 行):
點選「儲存變更」。
回到「永久衍生資料表」頁面,然後重新整理頁面。
在「正式環境」分頁中,即使您在開發模式下修改了 PDT 的 LookML 程式碼,aggregated_orders::aggregate_sales PDT 仍會顯示為「已建構」。
Looker 能讓開發人員在開發模式中測試 PDT 的變更,就像在開發模式中處理其他 Looker 物件一樣。舉例來說,開發人員在開發模式中建立新的維度和測量指標時,必須先修訂變更並部署至正式環境,這些新物件才會出現在正式環境中。
請勿關閉這個「永久衍生資料表」頁面,在新的瀏覽器分頁中開啟新的 Looker 視窗。
依序前往「探索」>「Aggregate Sales」。
在「資料」窗格中,開啟「SQL」分頁。
在「使用者」>「維度」底下,選取「Country」。
在「Aggregated Orders」>「度量」底下,選取下列項目:
「SQL」分頁中有兩個查詢:第一個會產生 PDT,第二個則會從新建立的 PDT 中擷取結果。
點選「執行」。
開啟「結果」分頁來查看結果。
關閉探索查詢的瀏覽器分頁,然後回到「永久衍生資料表」頁面所在的瀏覽器分頁,並重新整理頁面。
「開發」分頁此時會顯示 aggregated_orders::aggregate_sales 已建構成功。
請勿關閉「Persistent Derived Tables」頁面的瀏覽器分頁,回到 Looker IDE 所在的瀏覽器分頁。
點選「驗證 LookML」。
此時不會出現任何 LookML 錯誤。
依序點按「驗證 LookML」>「修訂變更並推送」。
新增修訂版本訊息,然後點按「修訂」。
最後,點按「部署至正式環境」。
回到「永久衍生資料表」頁面所在的瀏覽器分頁,然後重新整理頁面。正式環境變更已部署完畢,因此 aggregated_orders::aggregate_sales PDT 不會再列於「開發」分頁中,而是會出現在「正式環境」分頁的清單中。
在本實驗室中,您學到了何時及如何為衍生資料表增設保留和增量更新機制、使用匯總感知功能、以高效方式彙整檢視表,以及監控 PDT 的建構情況來提升 Looker 查詢效能。
協助您瞭解如何充分運用 Google Cloud 的技術。我們的課程會介紹專業技能和最佳做法,讓您可以快速掌握要領並持續進修。我們提供從基本到進階等級的訓練課程,並有隨選、線上和虛擬課程等選項,方便您抽空參加。認證可協助您驗證及證明自己在 Google Cloud 技術方面的技能和專業知識。
使用手冊上次更新日期:2024 年 4 月 23 日
實驗室上次測試日期:2023 年 10 月 6 日
Copyright 2026 Google LLC 保留所有權利。Google 和 Google 標誌是 Google LLC 的商標,其他公司和產品名稱則有可能是其關聯公司的商標。



This content is not currently available
We will notify you via email when it becomes available

Great!
We will contact you via email if it becomes available

One lab at a time
Confirm to end all existing labs and start this one
Complete this quick step to start your lab.