
시작하기 전에
- 실습에서는 정해진 기간 동안 Google Cloud 프로젝트와 리소스를 만듭니다.
- 실습에는 시간 제한이 있으며 일시중지 기능이 없습니다. 실습을 종료하면 처음부터 다시 시작해야 합니다.
- 화면 왼쪽 상단에서 실습 시작을 클릭하여 시작합니다.
Create an incremental persistent derived table
/ 40
Create an aggregate table
/ 30
Join the minimal amount of views new Explores
/ 30
Create an incremental persistent derived table
/ 40
Create an aggregate table
/ 30
Join the minimal amount of views new Explores
/ 30

Looker는 대화식으로 데이터를 분석하고 시각화하는 데 사용할 수 있는 Google Cloud의 최신 데이터 플랫폼입니다. Looker를 사용하여 심도 있게 데이터를 분석하고, 다양한 데이터 소스에서 인사이트를 통합하고, 작업 가능한 데이터 기반 워크플로를 구축하며, 커스텀 데이터 애플리케이션을 만들 수 있습니다.
복잡한 쿼리는 비용이 많이 들 수 있으며, 반복적으로 실행하면 데이터베이스에 부담이 가해져 성능이 저하됩니다. 변경된 내용이 없다면 대규모 쿼리를 다시 실행하는 대신 기존 결과에 새 데이터를 추가하여 반복적인 요청을 줄이는 것이 좋습니다. LookML 쿼리의 성능을 최적화하는 방법에는 여러 가지가 있지만, 이 실습에서는 Looker에서 쿼리 성능을 최적화하는 데 가장 일반적으로 사용되는 방법인 영구 파생 테이블, 집계 인식, 효율적인 뷰 조인을 살펴봅니다.
다음 안내를 확인하세요. 실습에는 시간 제한이 있으며 일시중지할 수 없습니다. 실습 시작을 클릭하면 타이머가 시작됩니다. 이 타이머는 Google Cloud 리소스를 사용할 수 있는 시간이 얼마나 남았는지를 표시합니다.
실무형 실습을 통해 시뮬레이션이나 데모 환경이 아닌 실제 클라우드 환경에서 직접 실습 활동을 진행할 수 있습니다. 실습 시간 동안 Google Cloud에 로그인하고 액세스하는 데 사용할 수 있는 새로운 임시 사용자 인증 정보가 제공됩니다.
이 실습을 완료하려면 다음을 준비해야 합니다.
준비가 되면 실습 시작을 클릭합니다.
이 실습에서 사용해야 하는 임시 사용자 인증 정보가 '실습 세부정보' 창에 표시됩니다.
실습 비용을 결제해야 하는 경우 결제 수단을 선택할 수 있는 팝업이 열립니다.
'실습 세부정보' 창에 표시된 실습 사용자 인증 정보를 확인합니다. 이 실습에서 Looker 인스턴스에 로그인할 때 이 정보를 사용합니다.
Looker 열기를 클릭합니다.
제공된 사용자 이름과 비밀번호를 이메일 및 비밀번호 입력란에 입력합니다.
사용자 이름:
비밀번호:
로그인을 클릭합니다.
로그인이 완료되면 이 실습에서 사용할 Looker 인스턴스가 표시됩니다.
이 섹션에서는 Looker에서 쿼리 성능 최적화를 위해 일반적으로 사용되는 방법을 알아봅니다. 이 실습에서는 처음 세 가지 방법을 직접 실습해 봅니다.
첫 번째 솔루션은 영구 파생 테이블(PDT)입니다. Looker에서는 SQL 및 LookML 쿼리를 데이터베이스에 임시 테이블로 쓸 수 있습니다. 이 테이블이 캐시되거나 지속되는 경우를 PDT라고 합니다. 이를 통해 복잡하거나 자주 사용되는 쿼리를 반복적으로 실행하고 빠른 액세스를 위해 결과를 캐시할 수 있습니다.
쿼리를 테이블로 저장하면 쿼리가 빌드되는 경우와 방식을 제어할 수 있습니다. 테이블은 매일 아침, 한 달에 한 번 또는 새 데이터가 추가되었을 때 다시 빌드될 수 있습니다. 가장 좋은 것은 데이터의 특성을 반영하여 파생 테이블을 구성하는 것입니다.
파생 테이블은 기본 데이터베이스 테이블에 없는 새로운 구조나 집계를 만드는 데 유용하지만, 모든 파생 테이블이 반드시 지속되어야만 유용한 것은 아닙니다. 일반적으로 지속성은 실행 비용이 많이 드는 복잡한 쿼리나 많은 수의 사용자 또는 애플리케이션에 의해 자주 사용되는 쿼리에 적용됩니다.
테이블 전체를 다시 빌드하지 않고도 새 데이터를 추가할 수 있도록 증분 PDT를 만들 수도 있습니다. 증분 변경 적용은 테이블에 대해 이루어지는 주된 업데이트는 신규 레코드이며 기존(오래된) 데이터는 빈번하게 업데이트되지 않는 대규모 테이블에 적합합니다.
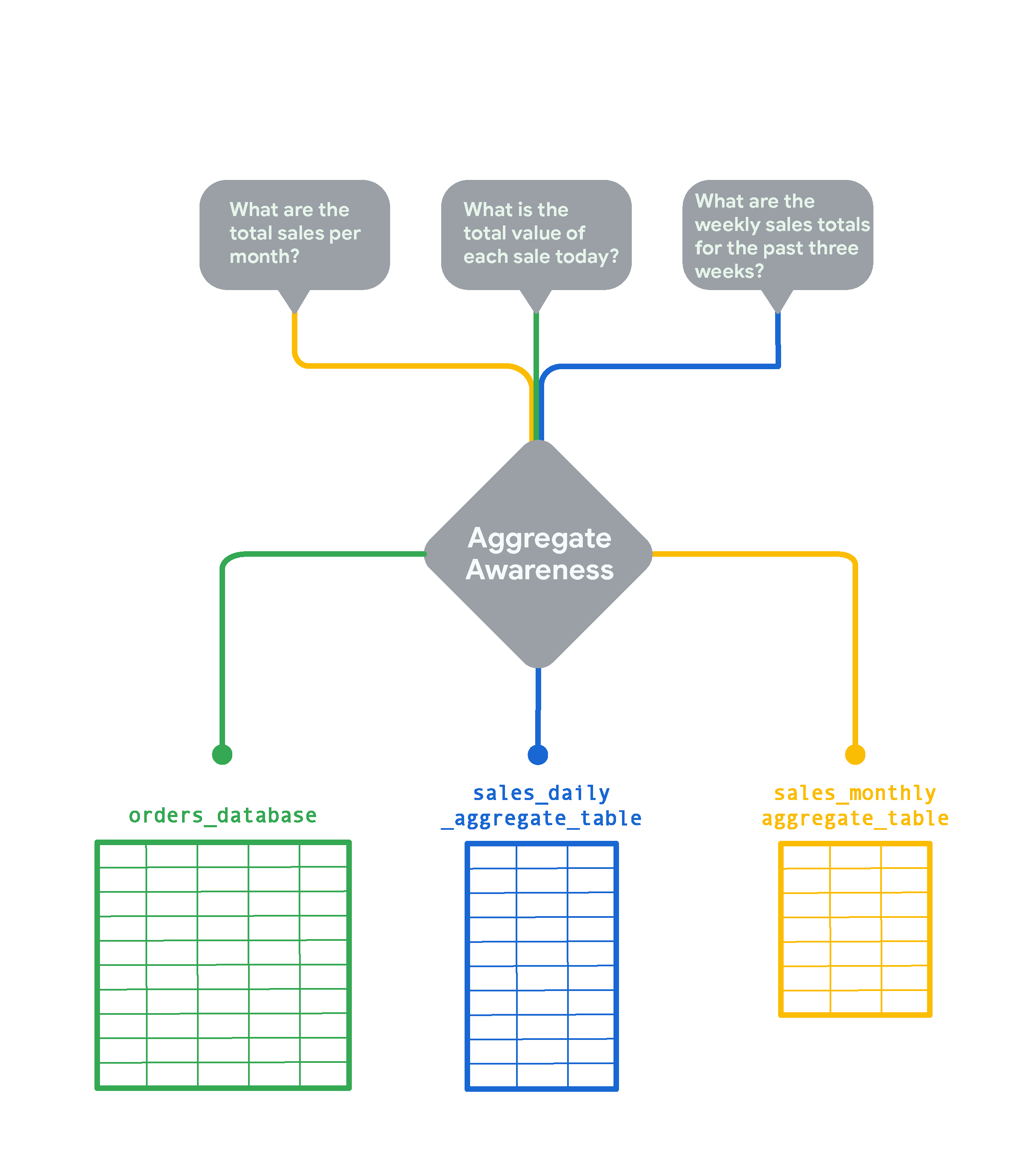
데이터베이스에 있는 매우 큰 테이블의 경우, Looker의 집계 인식을 사용하여 데이터가 다양한 속성 조합으로 그룹화된 작은 집계 테이블을 만들 수 있습니다. 집계 테이블은 가능한 경우 Looker가 원본 대규모 테이블 대신 쿼리에 사용할 수 있는 '롤업' 또는 요약 테이블로 역할을 합니다. 집계 인식을 통해 Looker는 데이터베이스에서 정확성을 유지하면서도 쿼리를 실행하는 데 사용할 수 있는 가장 작고 효율적인 테이블을 찾습니다. 전략적으로 구현된 집계 인식은 평균 쿼리 속도를 크게 높일 수 있습니다. 몇 초에 한 번씩 신규 행이 추가되는 분주한 이커머스 스토어의 온라인 주문 테이블을 생각해 보겠습니다.
실시간 주문을 추적하려면 훨씬 더 많은 세부정보가 필요하지만, '월간 총 판매량' 같은 월간 추세를 살펴보려면 데이터의 월별 롤업을 살펴보는 것이 훨씬 빠르고 비용 효율적입니다. 이 경우에는 Looker가 sales_monthly_aggregate_table을 만들고 쿼리합니다.
'오늘 각 판매의 총 금액은 얼마인가?'와 같은 질문에 답하려면 세분화된 행 수준 주문 데이터가 필요합니다. 이 경우에는 Looker가 집계 없이 원본 orders_database 테이블을 쿼리합니다. 지난 3주간의 주간 총 판매를 확인해야 하는 경우 Looker가 판매 일일 집계 테이블을 만들고 선택합니다. 월간 판매 테이블보다 세분화된 이 테이블은 원시 orders_database의 롤업입니다.
Looker의 집계 인식은 여러 기간의 데이터를 롤업하거나 요약하는 데 일반적으로 사용됩니다. 집계 인식에 사용하려면 집계 테이블이 Looker 인스턴스 내에서 지속되어야 합니다.
성능을 최적화하는 또 다른 방법은 새 Explore를 정의할 때 필요한 뷰만 조인하는 것입니다. 조인을 최소화하려면 각 용도별로 여러 Explore를 정의할 수 있습니다(예: 사용자별 데이터 쿼리, 집계 판매 데이터 쿼리). 또한 연결된 필드 대신 기본 필드를 기본 키로 사용해야 합니다. 가능한 경우 many_to_one 조인을 사용합니다. 가장 세분화된 수준의 뷰를 가장 높은 수준의 세부정보를 갖는 뷰에 연결하는 many_to_one 조인은 일반적으로 Looker에서 가장 뛰어난 쿼리 성능을 제공합니다.
Explore 정의에 필터를 포함하면 기본적으로 많은 양의 데이터를 반환하는 일을 방지하여 성능을 최적화할 수 있습니다. 필터에는 always_filter, conditionally_filter와 같이 사용자에게 표시되고 사용자가 수정할 수 있는 필터를 비롯한 다양한 옵션이 있습니다. Explore에서 필드에 대한 필터 제안을 수정할 수도 있습니다. Explore 필터에 대한 자세한 내용과 실습은 LookML로 Explore 필터링 실습을 참고하세요.
데이터베이스 쿼리 트래픽을 줄이려면 가능한 경우 추출, 로드, 변환(ETL) 정책과 동기화되도록 캐싱을 극대화해야 합니다. Looker는 기본적으로 쿼리를 1시간 동안 캐시합니다. persist_with 파라미터를 사용하여 Explore 내에서 데이터 그룹을 적용하는 방식으로 캐싱 정책을 제어하고 Looker 데이터 새로고침을 ETL 프로세스와 동기화할 수 있습니다. 이렇게 하면 Looker가 백엔드 데이터 파이프라인과 더 긴밀하게 통합되어 오래된 데이터를 분석하게 되는 일 없이 캐시 사용을 극대화할 수 있습니다.
예를 들어 하루에 한 번만 업데이트되는 데이터 테이블은 캐시를 한 시간에 한 번 새로고침하는 것이 비효율적입니다. 이 실습에서는 Looker에서 캐싱을 맞춤설정하는 여러 옵션(데이터 그룹 포함하기 또는 캐싱 정책)을 사용하여 파생 테이블을 지속시킵니다. 캐싱 정책에 대한 자세한 내용과 실습은 LookML을 사용한 캐싱 및 데이터 그룹 실습을 참고하세요.
사용 중인 데이터베이스 언어에 따라 cluster_keys, indexes와 같은 추가적인 쿼리 최적화 기능을 살펴볼 수 있습니다.
앞에서 설명했듯이, 영구 파생 테이블(PDT)은 데이터베이스의 스크래치 스키마에 작성되고 지속성 전략을 통해 지정된 일정에 따라 재생성되는 파생 테이블입니다. PDT는 사용자가 테이블에서 데이터를 요청하는 경우 테이블이 이미 존재하는 경우가 많기 때문에 쿼리 시간과 데이터베이스 부하를 줄인다는 점에서 유용합니다.
표준 PDT에서는 테이블 전체가 캐싱 정책에 설정된 일정에 따라 다시 빌드됩니다. 반면에 증분식으로 빌드된 PDT는 기존 테이블에 새 데이터를 추가합니다. 따라서 데이터베이스로 전송되는 쿼리의 크기를 크게 줄일 수 있습니다.
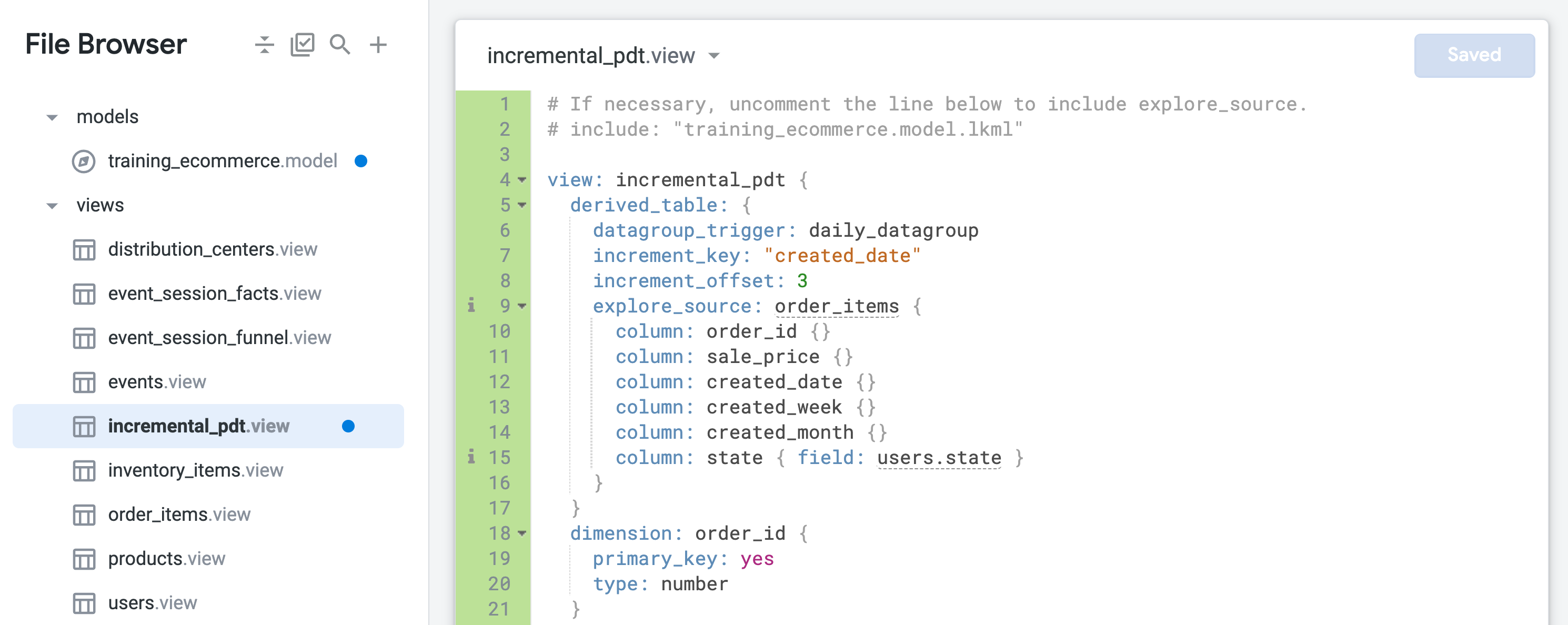
이 작업에서는 기간 또는 주를 기준으로 주문 데이터를 집계하기 위해 기본 파생 테이블(NDT)을 만듭니다. 또한 지연된 데이터를 가져오기 위해 일일 새로고침과 최대 3일 전까지의 증분 업데이트를 적용하여 지속성을 사용 설정합니다.
전환 버튼을 클릭하여 개발 모드로 전환합니다.
Explore > 주문 항목으로 이동합니다.
주문 항목 > 측정기준에서 다음을 선택합니다.
사용자 > 측정기준에서 주를 선택합니다.
실행을 클릭합니다.
설정(
LookML 가져오기를 선택합니다.
파생 테이블 탭에서 LookML 코드를 복사하여 텍스트 편집기에 붙여넣습니다.
이 코드는 기본 파생 테이블의 새 뷰를 만드는 데 사용합니다.
새 브라우저 탭에서 새 Looker 창을 엽니다.
개발 메뉴에서 qwiklabs_ecommerce를 클릭합니다.
파일 브라우저 옆의 더하기 아이콘(+)을 클릭하고 뷰 만들기를 선택합니다.
새 파일 이름을 incremental_pdt로 지정하고 만들기를 클릭합니다.
파일 브라우저에서 incremental_pdt.view를 클릭하고 views 폴더로 드래그합니다.
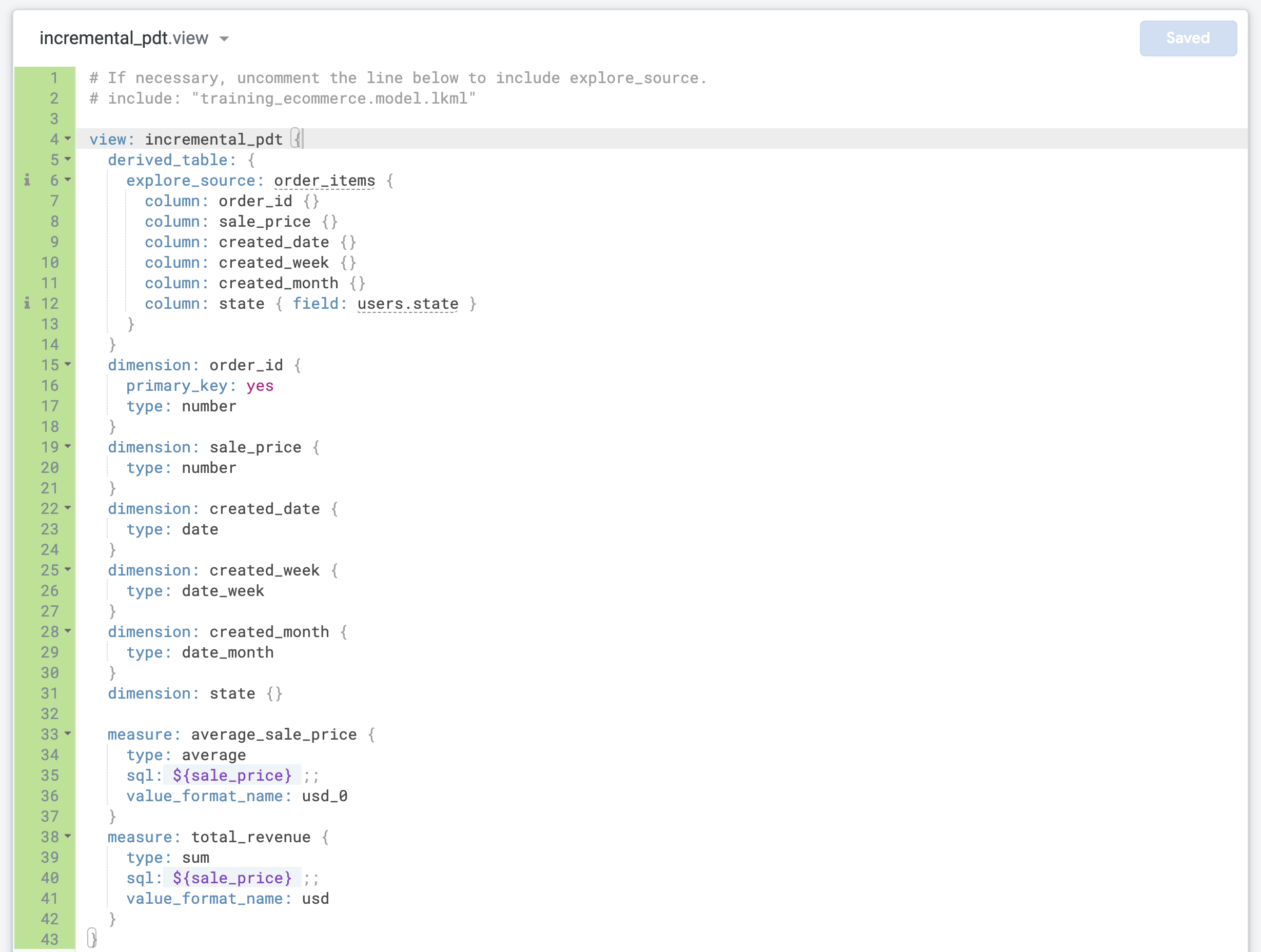
incremental_pdt.view의 기본 LookML 코드를 앞에서 기본 파생 테이블에 사용하기 위해 복사한 코드로 바꿉니다.
4번째 줄을 올바른 뷰 이름(incremental_pdt)으로 업데이트합니다.
order_id 측정기준을 업데이트하여 이것을 뷰의 primary_key로 정의합니다.
각 레코드가 고유한 order_id를 갖는 하나의 주문을 나타내기 때문입니다.
}) 앞에 두 개의 새 측정을 추가합니다.training_ecommerce.model을 엽니다.
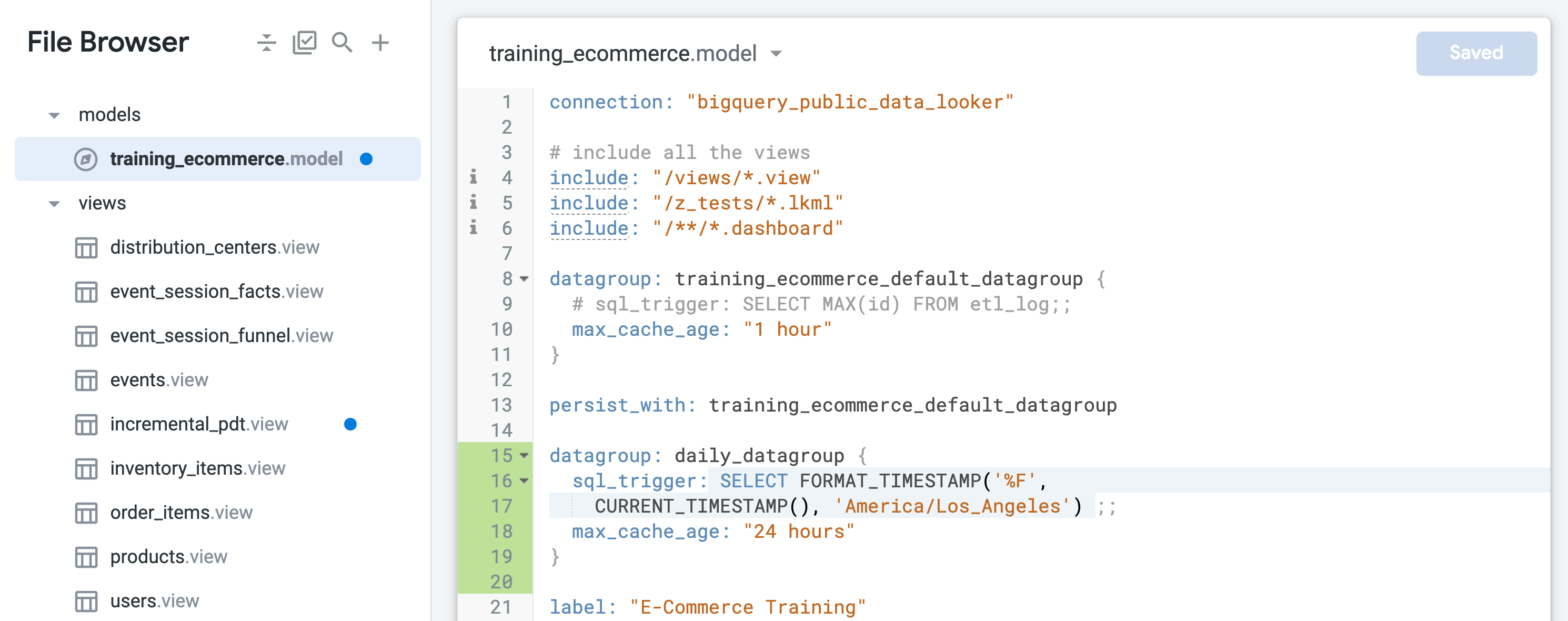
training_ecommerce_default_datagroup이라는 이름의 기본 데이터 그룹을 찾아서 새 줄(13번째 줄)을 추가합니다.
일일 새로고침(최대 24시간)을 사용하여 객체를 지속시키는 새 데이터 그룹을 정의합니다.
sql_trigger는 현재 날짜를 확인하고 날짜가 변경되면 새로고침을 트리거하며, max_cache_age는 sql_trigger가 성공적으로 실행되지 않더라도 24시간 후에 테이블이 다시 빌드되도록 보장합니다.
training_ecommerce.model의 끝부분(약 67번째 줄)에서 후속 단계에서 테스트할 수 있도록 incremental_pdt 뷰만 포함하는 새 Explore를 정의합니다.이제 영구 파생 테이블이 지속되며 하루에 한 번 다시 빌드되고 최대 3일 전으로 돌아가서 늦게 도착한 주문을 캡처합니다.
브라우저 탭에서 새 Looker 창을 엽니다.
Explore > 증분 PDT로 이동합니다.
데이터 창에서 SQL 탭을 엽니다.
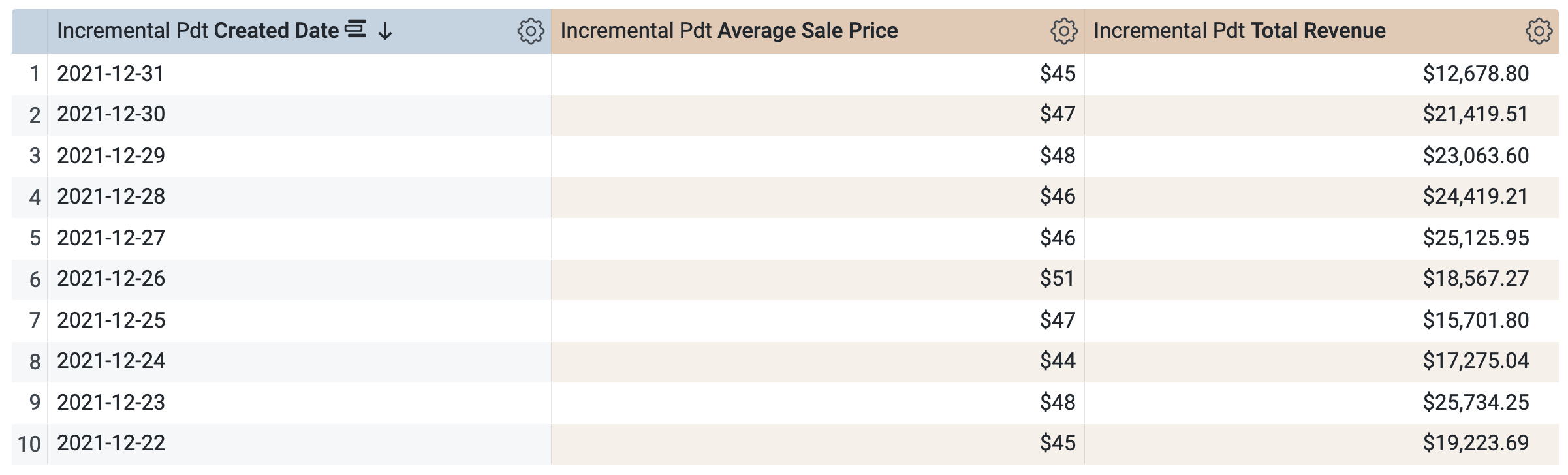
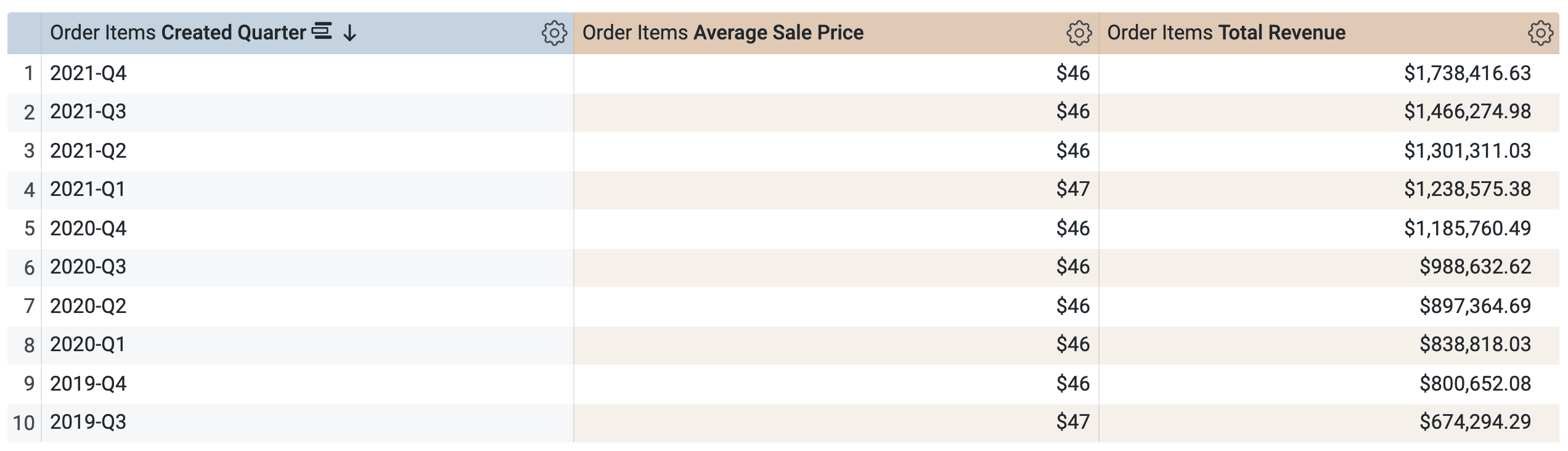
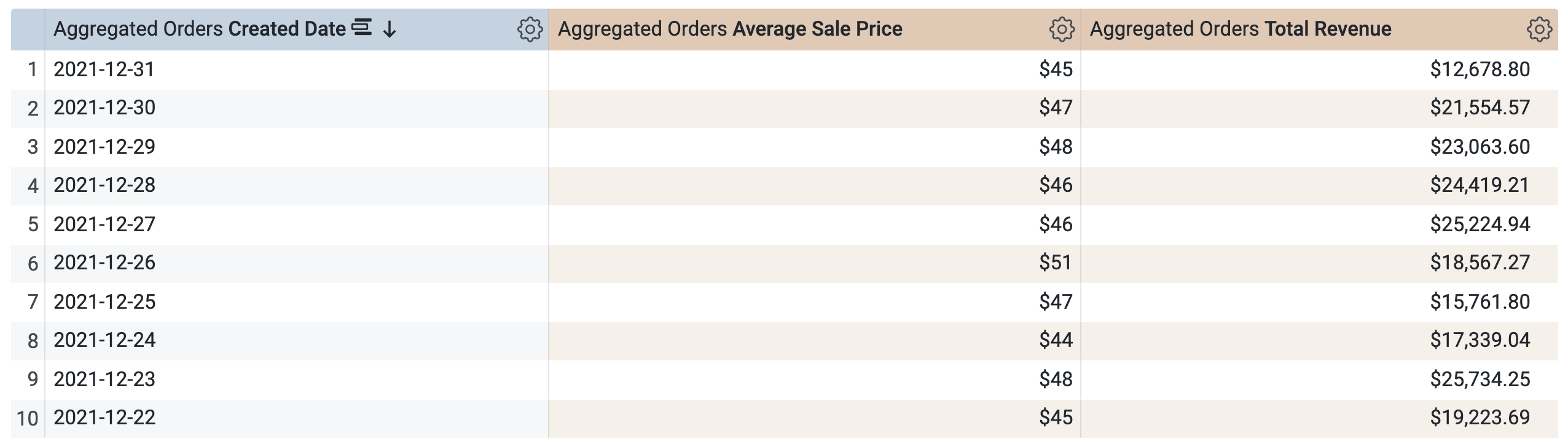
증분 PDT > 측정기준에서 생성일을 선택합니다.
증분 PDT > 측정에서 평균 판매가 및 총수익을 선택합니다.
쿼리를 실행하기 전에 SQL 창에 두 개의 쿼리가 있음을 확인합니다(로드하는 데 몇 초 정도 걸릴 수 있음). 첫 번째 쿼리는 incremental_pdt라는 이름의 PDT를 생성하고, 두 번째 쿼리는 새로 생성된 PDT에서 결과를 가져옵니다.
실행을 클릭합니다.
결과 탭을 열어 결과를 확인합니다.
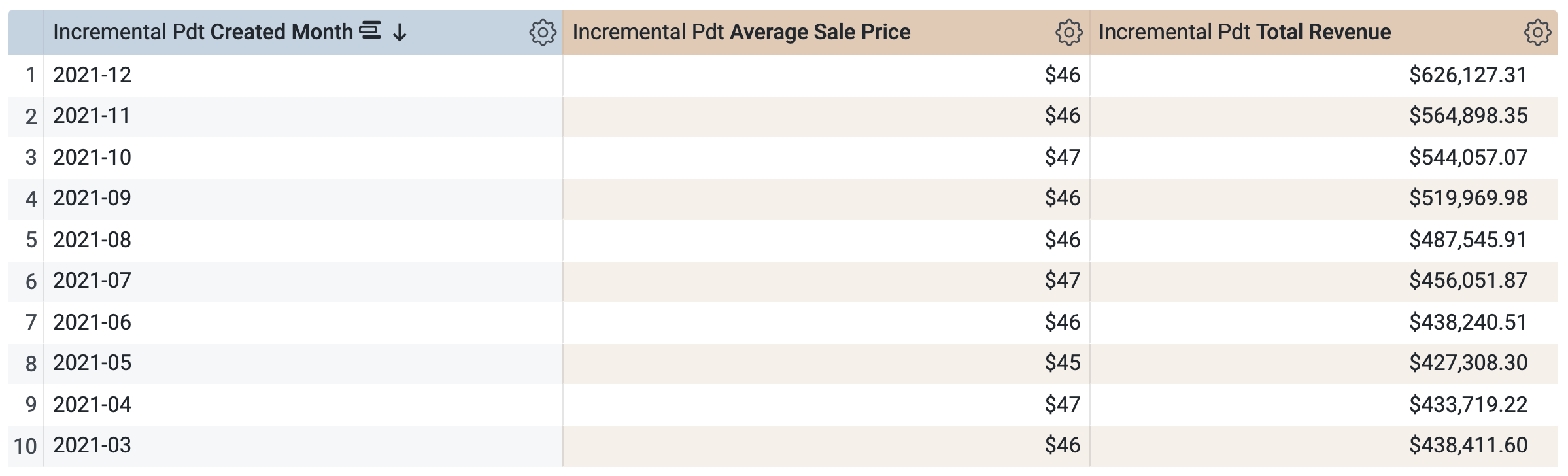
증분 PDT > 측정기준에서:
데이터 창에서 SQL 탭을 엽니다.
쿼리가 동일한 PDT를 사용하여 결과를 가져오는 것을 알 수 있습니다. PDT에 이미 정의되어 있고 캐시된 기간을 요청했기 때문에 이는 합리적입니다. 그러나 분기나 연도와 같이 PDT에 이미 포함되어 있지 않은 다른 기간에 대한 쿼리를 선택하여 실행할 수는 없습니다.
실행을 클릭합니다.
결과 탭을 열어 결과를 확인합니다.
Explore 쿼리의 브라우저 탭을 닫고 Looker IDE가 있는 브라우저 탭으로 돌아갑니다.
LookML 검증을 클릭합니다.
LookML 오류가 없을 것입니다.
LookML 검사를 클릭한 다음 변경사항 커밋 및 푸시를 클릭합니다.
커밋 메시지를 추가하고 커밋을 클릭합니다.
마지막으로 프로덕션에 배포를 클릭합니다.
Looker IDE의 브라우저 탭에서 다음 작업을 시작합니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
Looker에서는 데이터베이스에서 큰 테이블에 필요한 쿼리 수를 최소화하는 전략적 집계 테이블을 만들 수 있습니다. 집계 테이블은 집계 인식을 위해 액세스할 수 있도록 데이터베이스에 지속되어야 합니다. 따라서 집계 테이블은 일종의 영구 파생 테이블(PDT)입니다.
집계 테이블은 LookML 프로젝트의 탐색 파라미터 아래에 있는 aggregate_table 파라미터를 사용하여 정의됩니다. 집계 테이블을 만든 후 Explore에서 쿼리를 실행하여 Looker가 어느 집계 테이블을 사용하는지 알아볼 수 있습니다. Looker는 집계 인식 로직을 사용하여 정확성을 유지하면서도 데이터베이스에서 쿼리를 실행하는 데 사용할 수 있는 가장 작고 효율적인 집계 테이블을 찾습니다.
이 작업에서는 이전 작업의 증분 PDT를 새로운 증분 집계 테이블로 만듭니다. 또한 기존 Order Items Explore의 리파인먼트를 사용하여 사용자가 새 집계 테이블을 사용할 수 있도록 합니다.
Looker IDE 페이지에서 training_ecommerce.model을 엽니다.
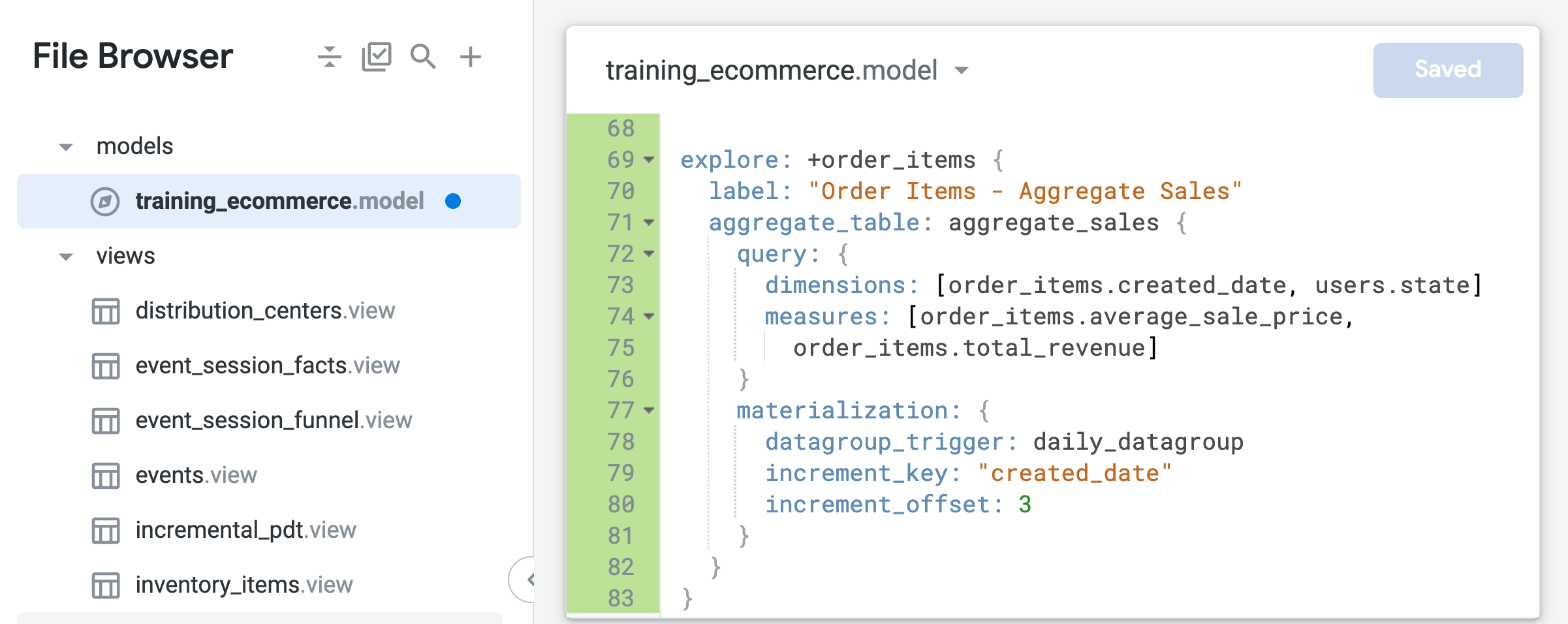
파일의 끝(약 69번째 줄)에 다음 코드를 추가하여 order_items Explore의 리파인먼트를 만듭니다.
이 리파인먼트는 모델 파일에 정의된 기존 order_items Explore를 기반으로 하며 다음 단계에서 추가할 라벨이나 집계 테이블과 같은 새로운 LookML 코드에 지정된 수정사항을 추가합니다.
이전 작업에서 만든 기본 파생 테이블과 달리, 집계 테이블에 지정된 유일한 시간 측정기준은 created_date입니다. Looker는 집계 인식을 사용하여 시간을 기준으로 집계된 평균 판매가 또는 총수익을 요청하는 Explore 쿼리에 요청된 기간(일, 월, 연도)과 관계없이 하나의 단일 테이블을 사용할 수 있습니다.
이 탭을 Looker IDE용으로 열어 둡니다.
브라우저 탭에서 새 Looker 창을 엽니다.
Explore > 주문 항목 - 집계 판매로 이동합니다.
데이터 창에서 SQL 탭을 엽니다.
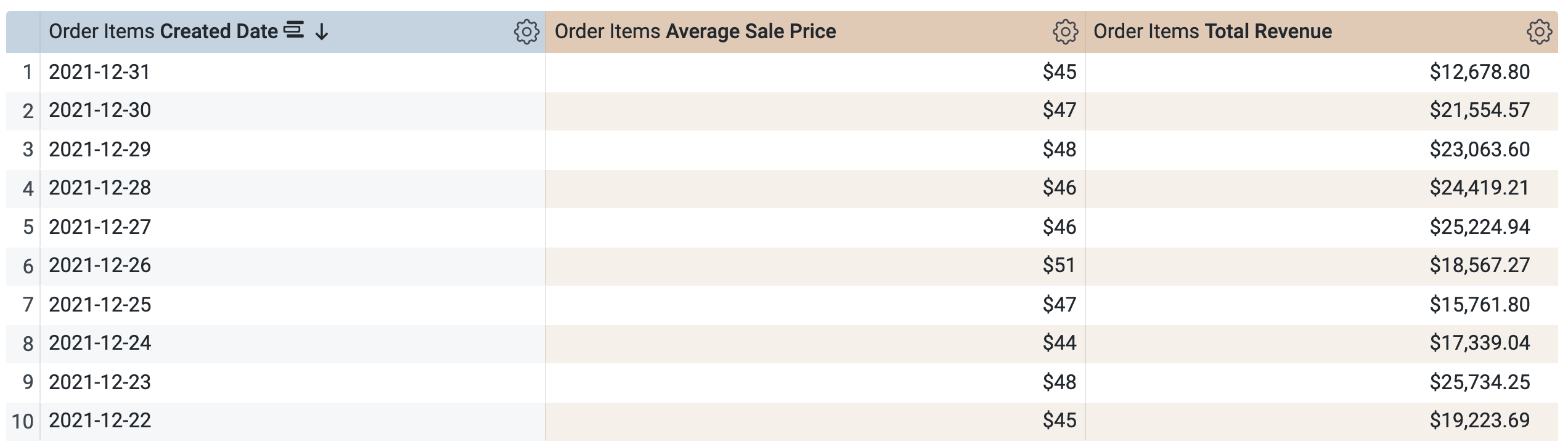
주문 항목 > 측정기준에서 생성일 > 날짜를 선택합니다.
주문 항목 > 측정에서 평균 판매가 및 총수익을 선택합니다.
쿼리를 실행하기 전에 작업 1의 SQL 창과 마찬가지로 두 개의 쿼리가 있음을 확인합니다. 첫 번째 쿼리는 aggregate_sales라는 이름의 PDT를 생성하고, 두 번째 쿼리는 새로 생성된 PDT에서 결과를 가져옵니다.
실행을 클릭합니다.
결과 탭을 열어 결과를 확인합니다.
주문 항목 > 측정기준 > 생성일에서:
데이터 창에서 SQL 탭을 엽니다.
쿼리가 동일한 PDT(aggregate_sales)를 사용하여 분기별 결과를 가져오는 것을 알 수 있습니다. Looker가 집계 인식을 적용하여 생성일의 사용 가능한 요청된 기간에 대해 평균 판매가 및 총수익을 롤업합니다.
실행을 클릭합니다.
결과 탭을 열어 결과를 확인합니다.
Explore 쿼리의 브라우저 탭을 닫고 Looker IDE가 있는 브라우저 탭으로 돌아갑니다.
LookML 검증을 클릭합니다. LookML 오류가 없을 것입니다.
LookML 검사를 클릭한 다음 변경사항 커밋 및 푸시를 클릭합니다.
커밋 메시지를 추가하고 커밋을 클릭합니다.
마지막으로 프로덕션에 배포를 클릭합니다.
Looker IDE의 브라우저 탭에서 다음 작업을 시작합니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
효율적인 조인은 Looker에서 성능이 우수한 Explore를 정의하기 위한 핵심 구성요소입니다. 조인의 효율성을 개선하려면 Explore를 정의하는 데 필요한 뷰만 조인하고, 연결된 필드 대신 기본 필드를 뷰의 기본 키로 사용하고, 가능한 경우 many_to_one 조인을 사용해야 합니다.
문서에 설명된 대로 기본 키는 뷰 내에서 레코드에 대한 고유 식별자를 제공하며 Looker에서 정확한 집계와 관계를 설정하는 데 필수적입니다. 뷰의 기본 키는 고유한 값을 포함하는 필드(예: ID 열)이며, 뷰 파일에서 primary_key: yes 파라미터로 식별됩니다.
이 섹션에서는 먼저 뷰의 기본 키로 사용할 가장 적절한 열을 식별합니다. 그런 다음 users 뷰만 조인된 집계 테이블에 대해 새 Explore를 정의하고 from 파라미터를 사용하여 Explore의 기본 뷰로 order_items를 지정한 다음 users 뷰를 조인합니다. 마지막으로, 기존 주문 항목 Explore에 포함된 추가 조인을 생략하고 many_to_one 조인 관계를 사용하여 쿼리 효율성을 높입니다.
users.view에서 IDd 열은 이미 primary_key: yes를 사용하여 기본 키로 식별되었습니다. 이 열은 고유한 값(사용자당 하나의 ID)을 포함하는 기본 필드이며, 여러 열에서 생성된 연결된 필드가 아닙니다. 따라서 ID는 users 뷰의 기본 키로 가장 적합한 옵션이며, 효율적인 조인을 지원할 수 있습니다.
order_item_id는 order_items 테이블의 ID 열을 기반으로 하며 기본 키로 식별되었습니다. 그러나 이 뷰의 다른 ID 필드(예: order_items 테이블의 order_id 열을 기반으로 하는 order_id)도 테이블의 고유 키가 될 수 있습니다.
다음 단계에서는 SQL Runner에서 order_items 테이블을 탐색하여 order_item_id가 primary_key로 사용하기에 가장 적합한 필드인 이유를 알아봅니다.
새 브라우저 탭에서 새 Looker 창을 엽니다.
개발 > SQL Runner로 이동합니다.
연결 옆에 있는 설정(
프로젝트 상자가 비어 있을 것입니다. cloud-training-demos를 입력하고 Enter 키를 누릅니다.
데이터 세트로 looker_ecomm을 선택합니다.
이 BigQuery 데이터 세트에서 사용 가능한 테이블 목록이 표시됩니다.
열이 적절한 기본 키인지 확인하는 한 가지 쉽고 빠른 방법은 테이블의 레코드 수를 열의 고유 값 수와 비교하는 것입니다. 두 수가 일치하면 열이 고유한 값을 포함하며 테이블의 적절한 기본 키인 것입니다.
user_id 열이 적절한 기본 키인지 알아보려면 SQL 쿼리 창에 다음 쿼리를 추가하고 실행을 클릭합니다.order_id, inventory_item_id, id 열에 대해 쿼리를 반복합니다.여기서 id와 inventory_item_id는 모두 테이블의 레코드 수와 일치합니다. 각각 하나의 주문에서 동일한 항목에 대한 서로 다른 ID이기 때문입니다. 따라서 둘 중 하나를 기본 키로 사용할 수 있습니다.
id 열은 order_items 테이블에 있는 항목에 대해 생성된 ID이므로 order_items의 기본 키로 선택되었지만, inventory_item_id는 inventory_items 테이블에 있는 동일한 항목의 ID입니다.
training_ecommerce.model을 엽니다.
기존 order_items Explore를 검토합니다.
각각 many_to_one 관계 유형을 사용하는 4개의 조인이 있는 것을 알 수 있습니다. 사용 사례에 따라 이러한 조인이 모두 필요할 수 있습니다. 하지만 주 또는 기간별로 롤업된 사용자 및 주문 데이터만 필요한 경우라면 어떻게 해야 할까요? 이 경우에는 이러한 추가 조인은 사용되지 않으며 Explore의 쿼리 속도를 늦추게 됩니다.
다음 단계에서는 order_items 뷰의 user_id와 users 뷰의 id를 기준으로 주문 데이터와 사용자 데이터만 조인하는 새 Explore를 만듭니다.
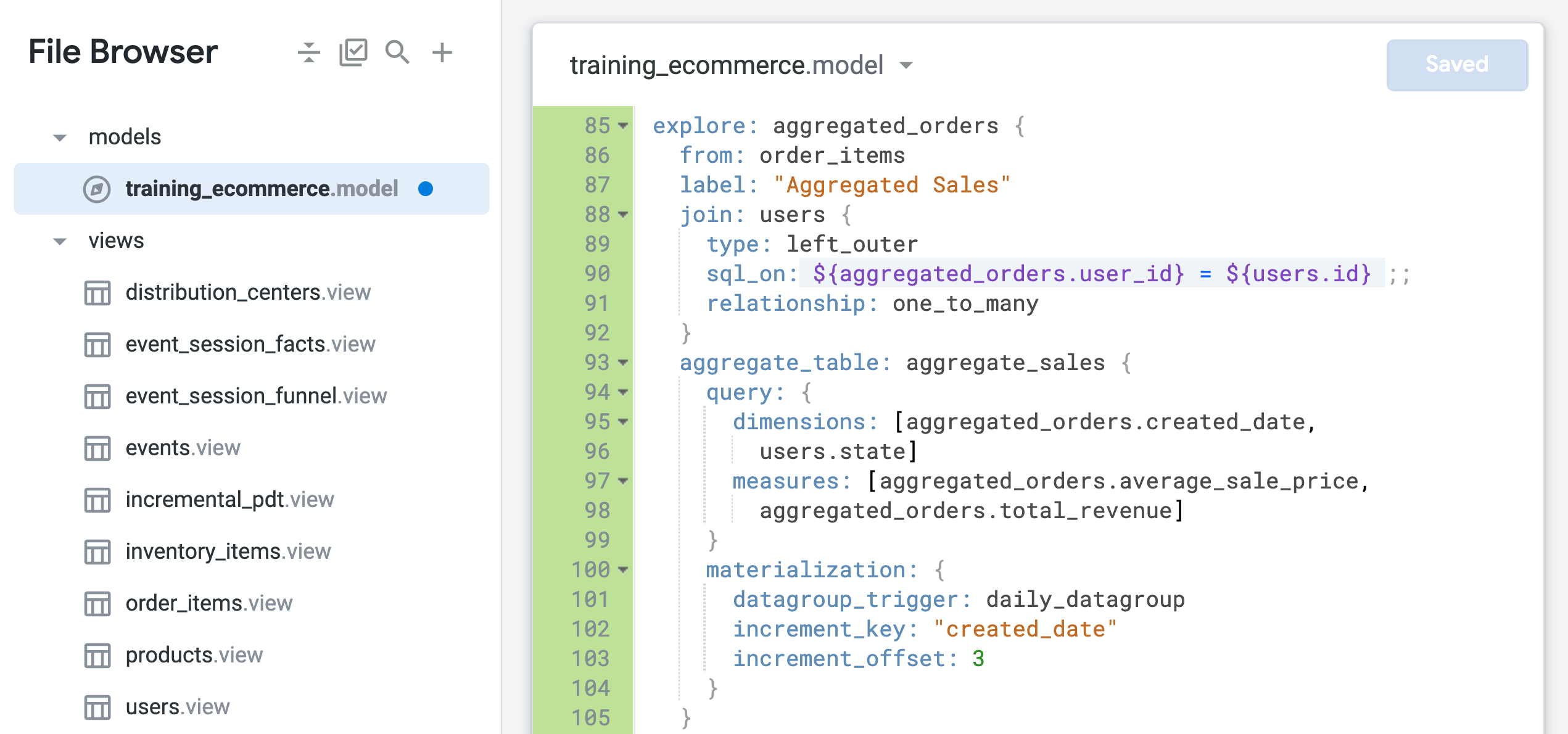
order_items를 기본 뷰로 사용하고 users 뷰만 조인된 새 Explore를 정의합니다.from 파라미터는 order_items를 Explore의 기본 뷰로 지정하는 데 사용되며, 이 뷰에 사용자 뷰가 조인됩니다. 이제 order_items 뷰의 필드가 새 Explore 이름인 aggregated_orders.fieldname을 사용하여 식별되었습니다.
users 뷰와 order_items 뷰의 관계가 현재 one_to_many로 식별되어 있는 것도 알 수 있습니다. 다음 단계에서는 one_to_many 관계를 기반으로 하는 이 조인이 이 Explore에 가장 최적화된 구성인지 테스트합니다.
새 브라우저 탭에서 새 Looker 창을 엽니다.
Explore > 집계된 판매로 이동합니다.
데이터 창에서 SQL 탭을 엽니다.
집계된 주문 > 측정기준에서 생성일 > 날짜를 선택합니다.
집계된 주문 > 측정에서 다음을 선택합니다.
쿼리를 실행하기 전에 조인 팬아웃 문제로 인해 집계 테이블이 사용되지 않는다는 점을 확인합니다.
의도하지 않은 팬아웃은 두 테이블의 관계가 조인에 대해 올바르게 식별되지 않은 경우에 발생할 수 있습니다. 여기서 Explore의 기본 뷰는 order_items이며, 이 뷰는 한 사용자의 여러 주문을 포함할 수 있습니다. 그러나 users 뷰는 사용자당 하나의 레코드만 포함합니다.
따라서 이 조인은 실제로 일대다(하나의 주문에 여러 사용자)가 아닌 many_to_one(여러 주문에 한 명의 사용자)로 정의되어야 합니다. (팬아웃 문제에 관한 자세한 내용은 Looker 고객센터를 참고하세요.)
실행을 클릭합니다.
결과 탭을 엽니다.
결과가 반환되었지만 Looker가 효율적인 집계 테이블을 사용하여 결과를 가져오지 않았습니다.
Explore 브라우저 탭은 열어 두고 Looker IDE 브라우저 탭으로 돌아갑니다.
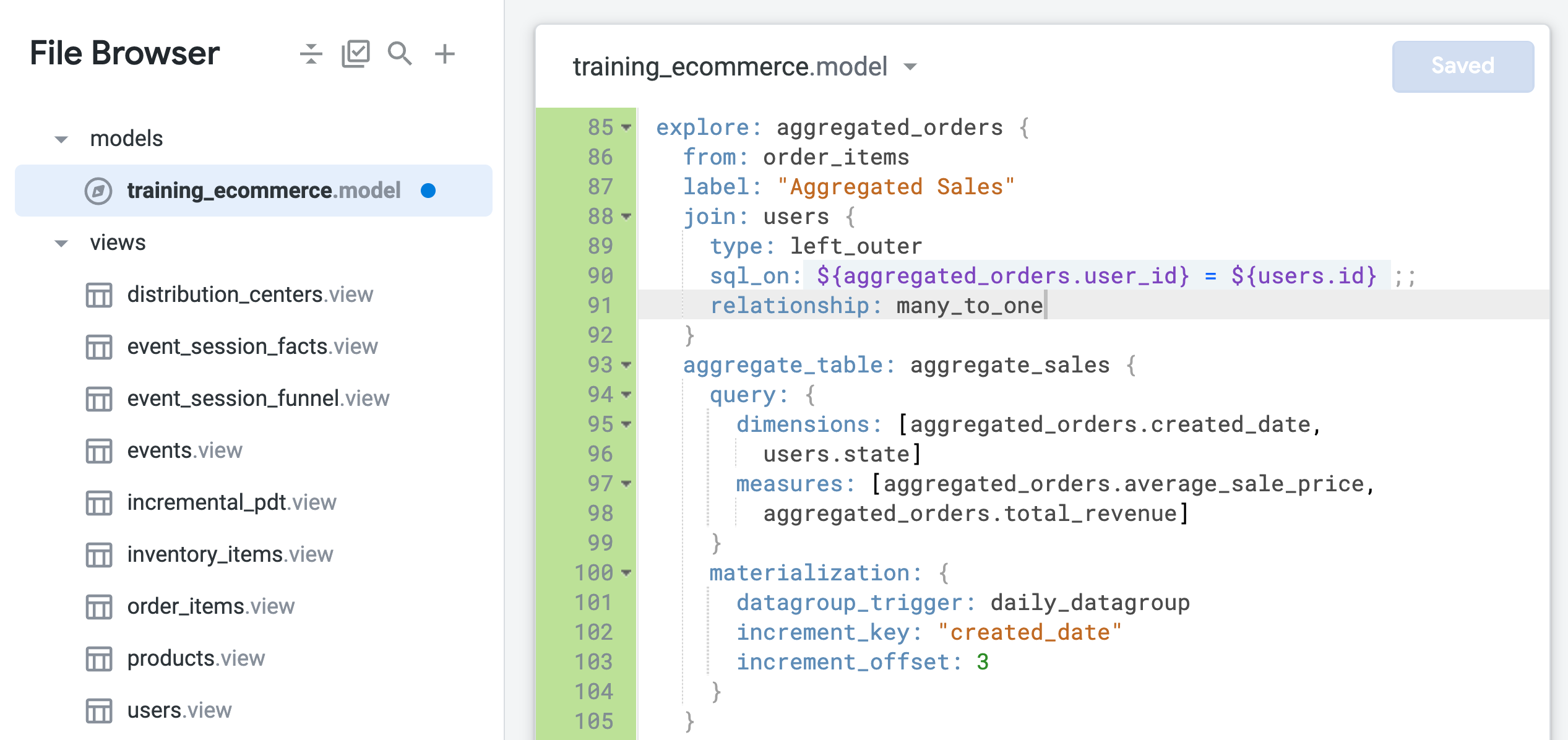
aggregated_orders Explore에서 관계 파라미터를 many_to_one로 업데이트합니다(91번째 줄).
Explore 쿼리 브라우저 탭으로 돌아가서 페이지를 새로고침합니다.
데이터 창에서 SQL 탭을 엽니다.
작업 1과 2의 SQL 탭과 마찬가지로, 이제 두 개의 쿼리가 있는 것을 볼 수 있습니다. 첫 번째는 PDT를 생성하는 쿼리이고 두 번째는 PDT에서 결과를 가져오는 쿼리입니다.
Explore 쿼리의 브라우저 탭을 닫고 Looker IDE가 있는 브라우저 탭으로 돌아갑니다.
LookML 검증을 클릭합니다.
LookML 오류가 없을 것입니다.
LookML 검사를 클릭한 다음 변경사항 커밋 및 푸시를 클릭합니다.
커밋 메시지를 추가하고 커밋을 클릭합니다.
마지막으로 프로덕션에 배포를 클릭합니다.
Looker IDE의 브라우저 탭에서 다음 작업을 시작합니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
Looker는 관리자 메뉴의 영구 파생 테이블 페이지를 통해 Looker 인스턴스의 PDT 빌드를 모니터링하는 기능을 제공합니다. Looker 구성에 따라, 테이블을 지속시킬 권한이 있는 Looker 사용자는 전체 관리 메뉴에 대한 액세스 권한이 없어도 이 페이지를 볼 수 있습니다. 개발 환경과 프로덕션 환경 양쪽에서 PDT의 상태, 빌드 시간, 캐싱을 확인하여 Looker 인스턴스의 PDT를 쉽게 테스트하고 모니터링할 수 있습니다.
이 작업에서는 이 실습에서 만든 PDT의 상태, 빌드 시간, 캐싱, 프로덕션과 개발을 모니터링합니다. NDT(작업 1)에서 만든 증분 PDT는 빌드 시간이 가장 길 것이고, 집계 테이블(작업 2 및 3)은 빌드 시간이 가장 짧을 것입니다. 모두 동일한 테이블 정의를 사용하긴 하나, 서로 다르게 구성된 Explore에 포함되어 있기 때문입니다. 또한 개발 중인 PDT를 수정하고 프로덕션으로 푸시하기 전후의 상태를 모니터링합니다.
새 브라우저 탭에서 새 Looker 창을 엽니다.
관리자 > 영구 파생 테이블로 이동합니다.
모든 PDT가 프로덕션으로 푸시되었으므로 개발 탭에 표시되는 PDT가 없습니다.
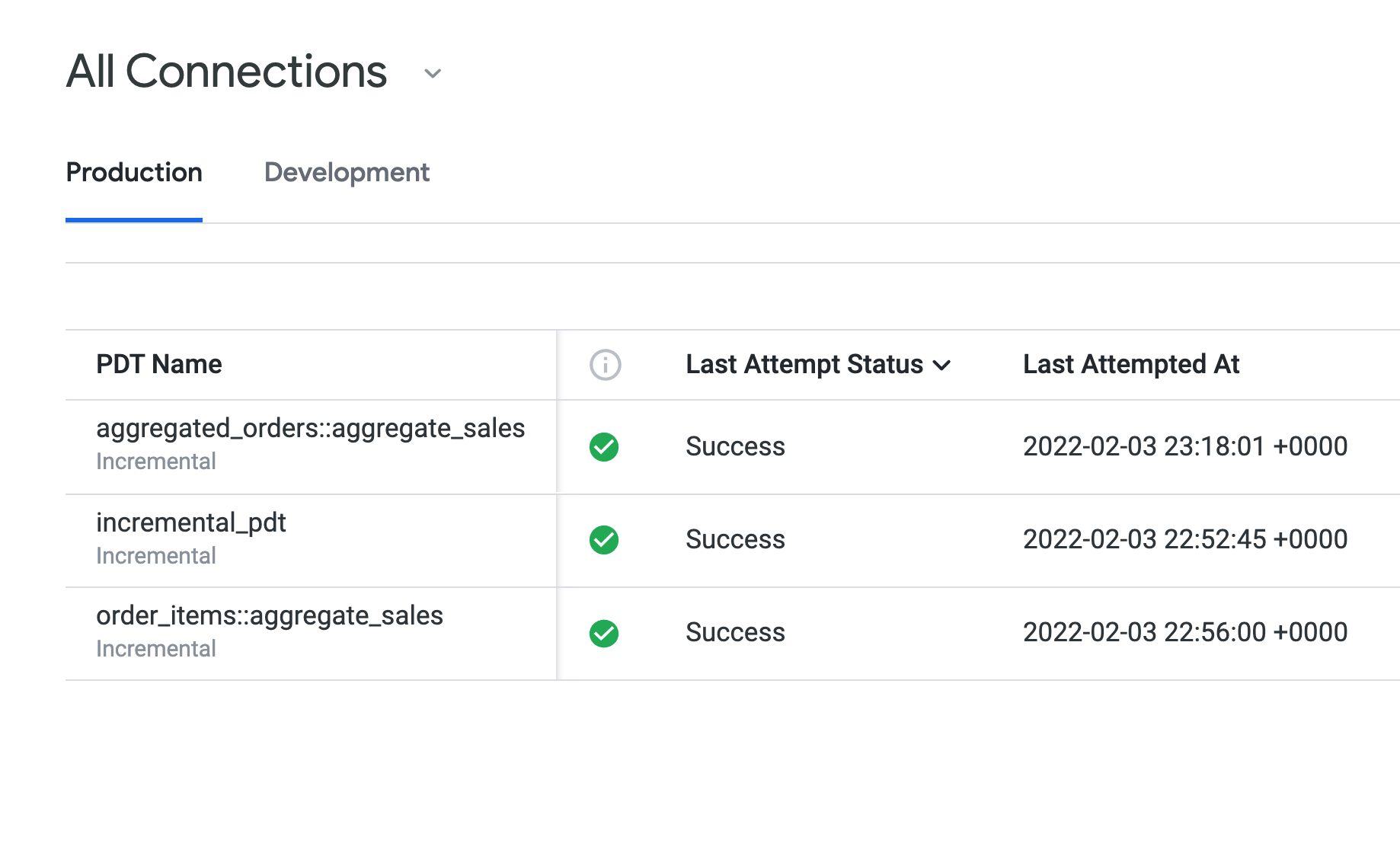
프로덕션 탭을 열어 작업 1~3에서 만든 PDT를 확인합니다.
마지막 시도 상태에는 모든 PDT에 대해 성공이 표시되며, 모두 동일한 지속성 규칙(daily_datagroup)을 사용하고 있습니다. 마지막 빌드 기간에 표시되는 빌드 시간의 경우 incremental_pdt가 두 집계 테이블보다 약간 더 길 것입니다.
이 영구 파생 테이블 페이지를 열어 두고 다음 단계를 시작하세요.
Looker IDE 브라우저 탭으로 돌아갑니다.
training_ecommerce.model을 엽니다.
aggregated_orders Explore에 users.country에 대한 새 측정기준을 추가합니다(약 96번째 줄).
변경사항 저장을 클릭합니다.
영구 파생 테이블 페이지로 돌아가서 페이지를 새로고침합니다.
개발 모드에서 PDT에 대해 LookML 코드를 수정했음에도 불구하고 프로덕션 탭에는 aggregated_orders::aggregate_sales PDT가 여전히 '빌드됨'으로 표시됩니다.
Looker에서는 개발자가 개발 모드에서 다른 Looker 객체로 작업하는 방식과 유사하게 개발 모드에서 PDT의 변경사항을 테스트할 수 있습니다. 예를 들어 개발자가 개발 모드에서 새로운 측정기준과 측정을 만든 경우, 개발자가 변경사항을 커밋하고 프로덕션으로 배포하기 전까지는 새로운 객체가 프로덕션에 표시되지 않습니다.
이 영구 파생 테이블 페이지를 열어 둔 채 새 브라우저 탭에서 새 Looker 창을 엽니다.
Explore > 집계 판매로 이동합니다.
데이터 창에서 SQL 탭을 엽니다.
사용자 > 측정기준에서 국가를 선택합니다.
집계된 주문 > 측정에서 다음을 선택합니다.
SQL 탭에 두 개의 쿼리가 있는 것을 볼 수 있습니다. 첫 번째 쿼리는 PDT를 생성하고, 두 번째 쿼리는 새로 빌드된 PDT에서 결과를 가져옵니다.
실행을 클릭합니다.
결과 탭을 열어 결과를 확인합니다.
Explore 쿼리 브라우저 탭을 닫고 영구 파생 테이블 페이지가 있는 브라우저 탭으로 돌아가서 페이지를 새로고침합니다.
이제 개발 탭에 aggregated_orders::aggregate_sales가 성공적으로 빌드되었다고 표시됩니다.
영구 파생 테이블 페이지 브라우저 탭을 열어 둔 채 Looker IDE 브라우저 탭으로 돌아갑니다.
LookML 검증을 클릭합니다.
LookML 오류가 없습니다.
LookML 검사를 클릭한 다음 변경사항 커밋 및 푸시를 클릭합니다.
커밋 메시지를 추가하고 커밋을 클릭합니다.
마지막으로 프로덕션에 배포를 클릭합니다.
영구 파생 테이블 페이지 브라우저 탭으로 돌아가서 페이지를 새로고침합니다. 프로덕션에 대한 변경사항이 배포되었으므로 aggregated_orders::aggregate_sales PDT는 더 이상 개발 탭에 표시되지 않고 프로덕션 탭에만 표시됩니다.
이 실습에서는 파생 테이블에 지속성과 증분 업데이트를 추가해야 하는 경우와 방법, 집계 인식을 사용해야 하는 경우와 방법, 효율적인 뷰 조인을 사용해야 하는 경우와 방법, PDT 빌드를 모니터링하여 Looker 쿼리를 최적화하는 방법을 알아보았습니다.
Google Cloud 기술을 최대한 활용하는 데 도움이 됩니다. Google 강의에는 빠른 습득과 지속적인 학습을 지원하는 기술적인 지식과 권장사항이 포함되어 있습니다. 기초에서 고급까지 수준별 학습을 제공하며 바쁜 일정에 알맞은 주문형, 실시간, 가상 옵션이 포함되어 있습니다. 인증은 Google Cloud 기술에 대한 역량과 전문성을 검증하고 입증하는 데 도움이 됩니다.
설명서 최종 업데이트: 2024년 4월 23일
실습 최종 테스트: 2023년 10월 6일
Copyright 2026 Google LLC. All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.



현재 이 콘텐츠를 이용할 수 없습니다
이용할 수 있게 되면 이메일로 알려드리겠습니다.

감사합니다
이용할 수 있게 되면 이메일로 알려드리겠습니다.

한 번에 실습 1개만 가능
모든 기존 실습을 종료하고 이 실습을 시작할지 확인하세요.