![[Production] タブページで [All Connection] ページが開き、本番環境の PDT が表示されている](https://cdn.qwiklabs.com/NlrayC2jcFACcNAlQJjlZXTi%2FlT%2BHJKIL%2FTJAzuglgE%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create an incremental persistent derived table
/ 40
Create an aggregate table
/ 30
Join the minimal amount of views new Explores
/ 30
Create an incremental persistent derived table
/ 40
Create an aggregate table
/ 30
Join the minimal amount of views new Explores
/ 30

Looker は Google Cloud で利用できる最新のデータ プラットフォームで、インタラクティブにデータを分析して可視化できます。Looker を使用すると、詳細なデータ分析、さまざまなデータソース間での分析情報の統合、実用的なデータドリブン ワークフローの構築、独自のデータ アプリケーションの作成を行うことができます。
複雑なクエリは費用が高くなる可能性があります。また、繰り返し実行するとデータベースに負荷がかかり、パフォーマンスが低下します。そのため、何も変更されていない場合は大規模なクエリの再実行を避け、代わりに新しいデータを既存の結果に追加し、繰り返しのリクエストを減らすのが理想的です。LookML クエリのパフォーマンスを最適化する方法は数多くありますが、このラボでは、Looker でクエリのパフォーマンスを最適化するために最もよく使用される方法に焦点を当てます。具体的には、永続的な派生テーブル、集約テーブルの自動認識、パフォーマンスに優れた方法でのビューの結合といった方法を取り上げます。
こちらの説明をお読みください。ラボの時間は制限されており、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
準備ができたら、[ラボを開始] をクリックします。
[ラボの詳細] ペインに、このラボで使用する一時的な認証情報が表示されます。
ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。
[ラボの詳細] ペインに表示されているラボの認証情報を確認してください(このラボの Looker インスタンスにログインする際に使用します)。
[Open Looker] をクリックします。
提供されたユーザー名とパスワードを、[Email] フィールドと [Password] フィールドに入力します。
ユーザー名:
パスワード:
[Log In] をクリックします。
正常にログインすると、このラボで使用する Looker インスタンスが表示されます。
このセクションでは、Looker でクエリのパフォーマンスを最適化するためによく使用される手法について説明します。また、このラボでは最初の 3 つの手法を実際に体験します。
1 つ目のソリューションは、永続的な派生テーブル(PDT)です。Looker では、SQL クエリと LookML クエリを一時テーブルとしてデータベースに書き込むことができます。このテーブルがキャッシュ保存または永続化されると、PDT と呼ばれます。これにより、複雑なクエリやよく使用するクエリを繰り返し実行し、結果をキャッシュに保存してすばやくアクセスできるようになります。
これらのクエリをテーブルとして保存することで、クエリを作成するタイミングや方法を制御できます。テーブルを再ビルドするタイミングは、毎朝、月に 1 回、または新しいデータが追加されたときのみに指定できます。派生テーブルを構成してデータの特性を反映させるのが理想的です。
派生テーブルは、基盤となるデータベース テーブルにまだ存在しない新しい構造や集計を作成するのに便利ですが、すべての派生テーブルを永続化する必要はありません。永続化は、実行に費用がかかる複雑なクエリや、多数のユーザーまたはアプリケーションによって頻繁に使用されるクエリによく適用されます。
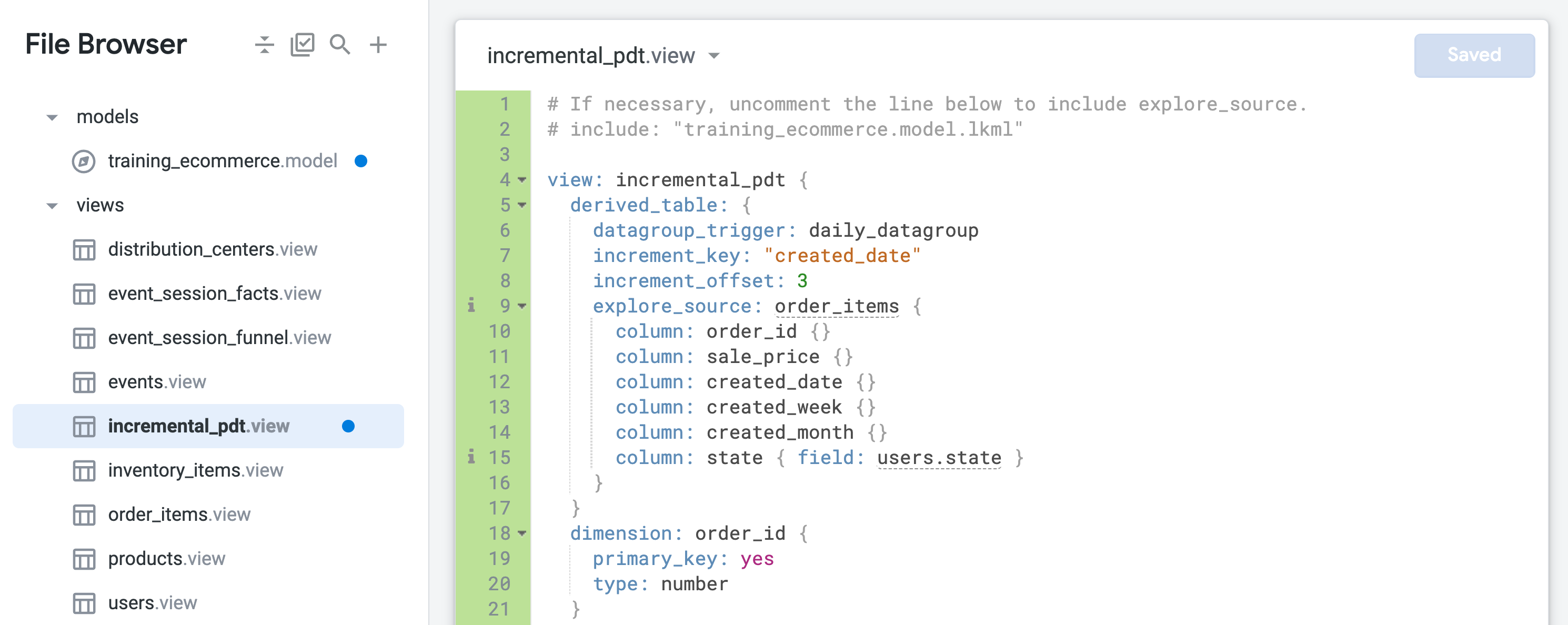
また、増分 PDT を作成して、テーブル全体を再ビルドせずに新しいデータを追加することも可能です。増分変更の適用は、既存(古い)データが頻繁に更新されない大規模なテーブルに適しています。テーブルの主な更新は新しいレコードによるものであるためです。
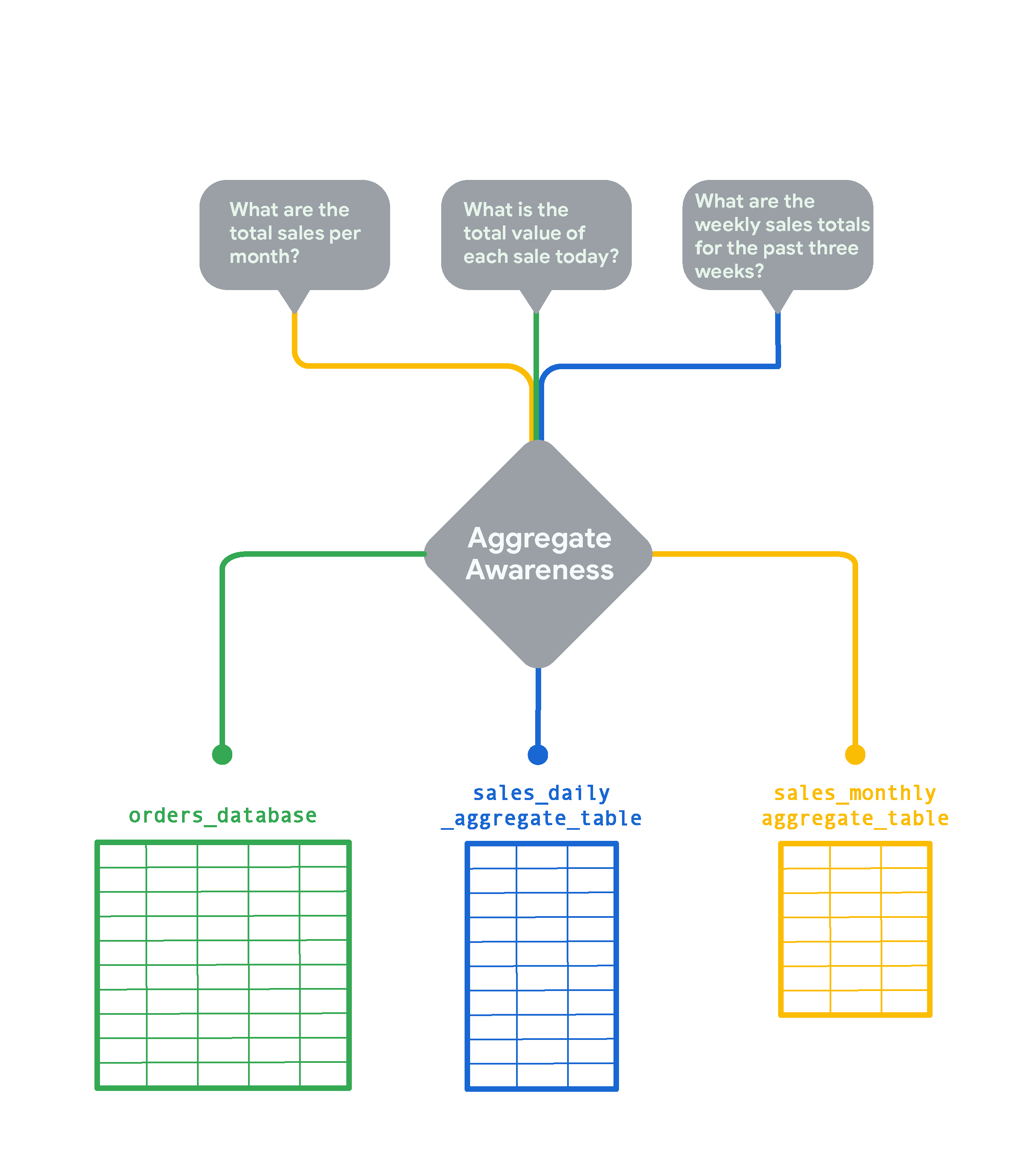
Looker の集約テーブルの自動認識機能を使用すると、データベース内の非常に大きなテーブルに対して、さまざまな属性の組み合わせによってグループ化されたデータのより小さな集約テーブルを作成できます。集約テーブルは、「ロールアップ」またはサマリー テーブルとして機能し、Looker は可能な限り、元の大きなテーブルの代わりにこのテーブルをクエリに使用できます。集約テーブルの自動認識により、Looker はデータベース内で最も小規模で効率的なテーブルを検出し、精度を維持しながらクエリを実行できます。集約テーブルの自動認識を効果的に実装すれば、平均的なクエリを大幅に高速化できます。たとえば、数秒ごとに新しい行が追加される、忙しい e コマースストアのオンライン注文のテーブルについて考えてみましょう。
リアルタイムの注文を追跡する場合は、より詳細な情報が必要になりますが、「月ごとの総売上」のような月ごとの傾向を確認する場合は、データを月単位でロールアップして確認する方がはるかに高速で費用対効果が高くなります。この場合、Looker は sales_monthly_aggregate_table を作成してクエリを実行します。
「今日の各売上の合計金額はいくらですか?」のような質問には、行レベルの詳細な注文データが必要です。この場合、Looker は集計を行わずに元の orders_database テーブルをクエリします。過去 3 週間の週次売上合計を確認する場合は、日次売上の集約テーブルが作成および選択されます。このテーブルは月次売上のテーブルよりも詳細ですが、元の orders_database をロールアップしたものです。
Looker の集約テーブルの自動認識機能は、複数の期間にわたるデータをロールアップまたは要約するためによく使用されます。また、集約テーブルが自動認識されるようにするには、集約テーブルを Looker インスタンスに永続的に保存する必要があります。
パフォーマンスを最適化するもう一つの方法は、新しい Explore を定義する際に必要なビューのみを結合することです。結合を最小限に抑えるために、目的の異なる複数の Explore を定義できます(たとえば、ユーザー別のデータのクエリ、売上集計データのクエリなど)。また、主キーとして連結フィールドではなく基本フィールドを使用する必要があります。可能な場合は、many_to_one 結合を使用します。最も詳細なレベルから最も概略的なレベル(many_to_one)にビューを結合すると、通常は Looker におけるクエリのパフォーマンスが最適化されます。
Explore の定義にフィルタを含めることで、デフォルトで大量のデータが返されるのを防ぎ、パフォーマンスを最適化できます。always_filter や conditionally_filter など、ユーザーが確認して変更できるフィルタを含め、フィルタ オプションは多数あります。また、Explore のフィールドのフィルタ候補を変更することもできます。Explore フィルタの詳細と演習については、LookML での Explore のフィルタリングのラボをお試しください。
データベースのクエリ トラフィックを削減するには、可能な限りキャッシュを最大化して、抽出、変換、読み込み(ETL)ポリシーと同期させる必要があります。デフォルトでは、Looker でクエリがキャッシュされるのは 1 時間です。persist_with パラメータを使用して Explore 内でデータグループを適用することで、キャッシュ ポリシーを制御し、Looker のデータ更新を ETL プロセスと同期させることができます。これにより、Looker とバックエンド データ パイプラインの統合を強化できるので、古いデータを分析するリスクを伴わずにキャッシュ使用量を最大化できます。
たとえば、一部のデータテーブルは 1 日に 1 回しか更新されないため、これらのテーブルのキャッシュを 1 時間ごとに更新してもメリットはありません。このラボでは、Looker でキャッシュをカスタマイズするためのさまざまなオプション(データグループやキャッシュ ポリシーなど)を使用して、派生テーブルを永続化します。キャッシュ ポリシーの詳細と実践については、LookML でのキャッシングとデータグループのラボをお試しください。
特定のデータベース言語に応じて、cluster_keys や indexes などの追加のクエリ最適化機能を検討できます。
前述のように、永続的な派生テーブル(PDT)とは、データベースのスクラッチ スキーマに書き込まれ、永続化戦略で指定したスケジュールで再生成される派生テーブルのことです。PDT が便利なのは、ユーザーがテーブルからデータをリクエストした時点でテーブルがすでに存在していることが多く、それによりクエリ時間が短縮され、データベースの負荷が軽減されるためです。
標準の PDT では、キャッシュ ポリシーで設定されたスケジュールに従ってテーブル全体が再ビルドされます。一方、増分でビルドされる PDT では、既存のテーブルに新しいデータが追加されます。これにより、データベースに送信するクエリのサイズを大幅に削減できます。
このタスクでは、ネイティブ派生テーブル(NDT)を作成して、注文データを期間または州ごとに集計します。また、3 日前のデータまで遡って遅延データを取得する、毎日の更新と増分更新による永続化も有効にします。
切り替えボタンをクリックして Development Mode に切り替えます。
[Explore] > [Order Items] の順に移動します。
[Order Items] > [Dimensions] で、以下を選択します。
[Users] > [Dimensions] で、[State] を選択します。
[Run] をクリックします。
設定アイコン(
[Get LookML] を選択します。
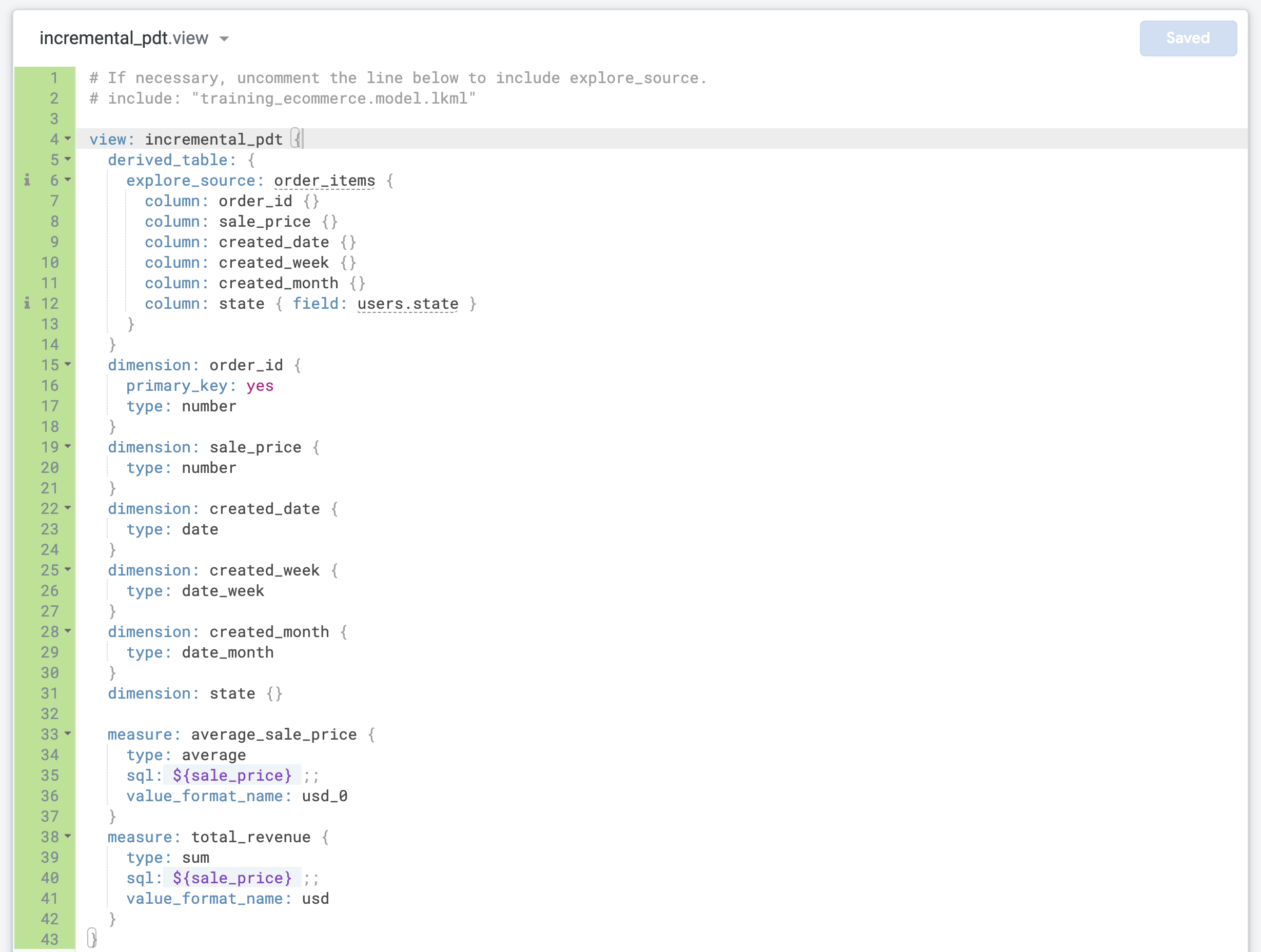
[Derived Table] タブで、LookML コードをテキスト エディタにコピーします。
このコードを使用して、ネイティブ派生テーブルの新しいビューを作成します。
新しいブラウザタブで新しい Looker ウィンドウを開きます。
[Develop] メニューで、[qwiklabs_ecommerce] をクリックします。
[File Browser] の横にあるプラスアイコン(+)をクリックし、[Create View] を選択します。
新しいファイルに「incremental_pdt」という名前を付けて、[Create] をクリックします。
ファイル ブラウザで、incremental_pdt.view をクリックして、views フォルダの下にドラッグします。
incremental_pdt.view のデフォルトの LookML コードを、ネイティブ派生テーブル用に先ほどコピーしたコードに置き換えます。
4 行目を正しいビュー名(incremental_pdt)に更新します。
order_id ディメンションを更新して、ビューの primary_key として定義します。
これは、各レコードが一意の order_id を持つ注文を表しているためです。
})の前に 2 つの新しいメジャーを追加します。training_ecommerce.model を開きます。
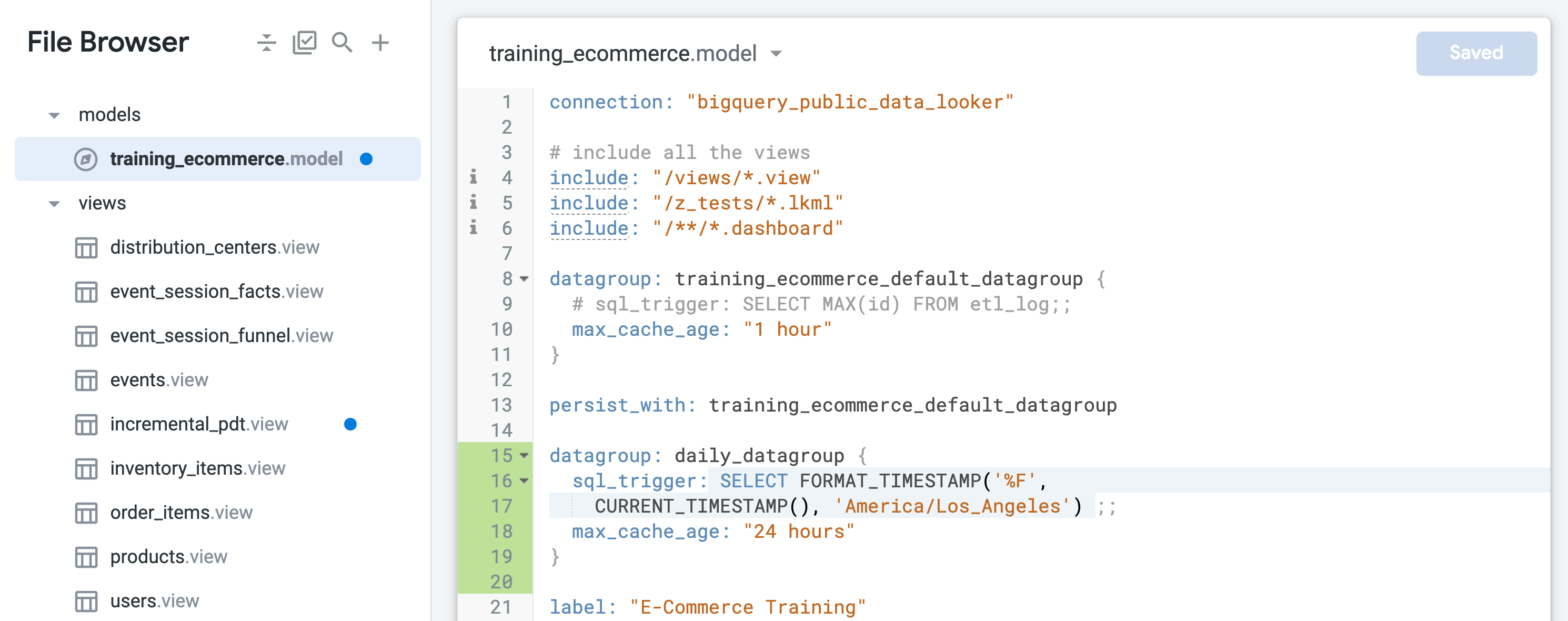
training_ecommerce_default_datagroup という名前のデフォルト データグループを見つけて、新しい行(13 行目)を追加します。
毎日更新されるオブジェクトを永続化する新しいデータグループを定義します(最大時間: 24 時間)。
sql_trigger は現在の日付を確認し、日付が変わると更新をトリガーします。max_cache_age は、sql_trigger が正常に実行されなかった場合でも、24 時間後にテーブルが再ビルドされるようにします。
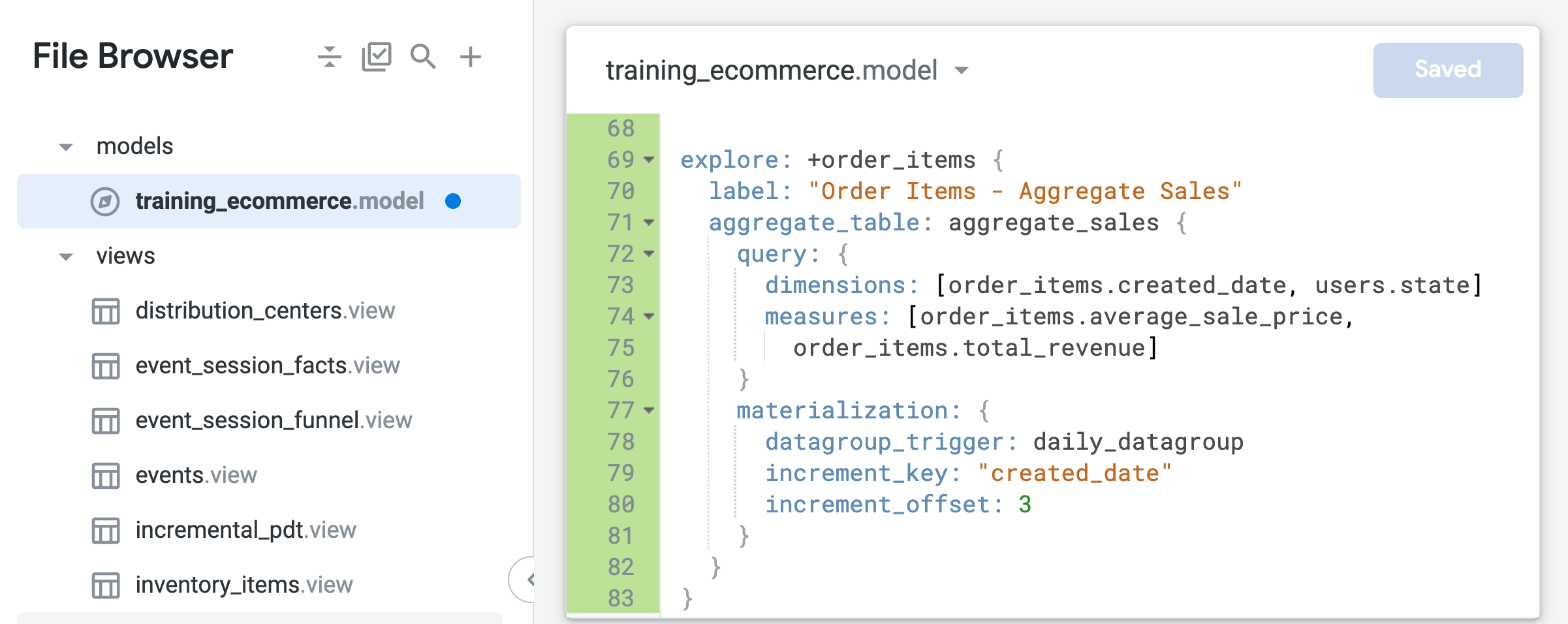
training_ecommerce.model の末尾(67 行目付近)に、incremental_pdt ビューのみを含む新しい Explore を定義して、後続のステップでテストできるようにします。これで永続的な派生テーブルは永続化され、1 日に 1 回再ビルドされ、3 日前まで遡って、遅れて到着した可能性のある注文を取得するようになります。
ブラウザタブで新しい Looker ウィンドウを開きます。
[Explore] > [Incremental Pdt] の順に移動します。
[Data] ペインで [SQL] タブを開きます。
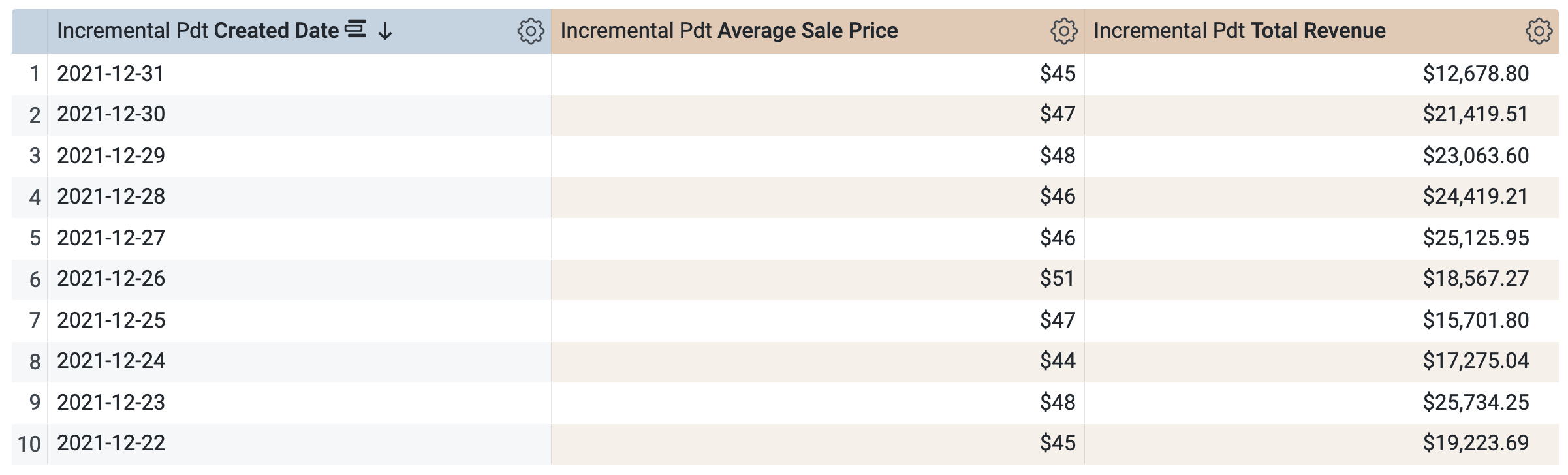
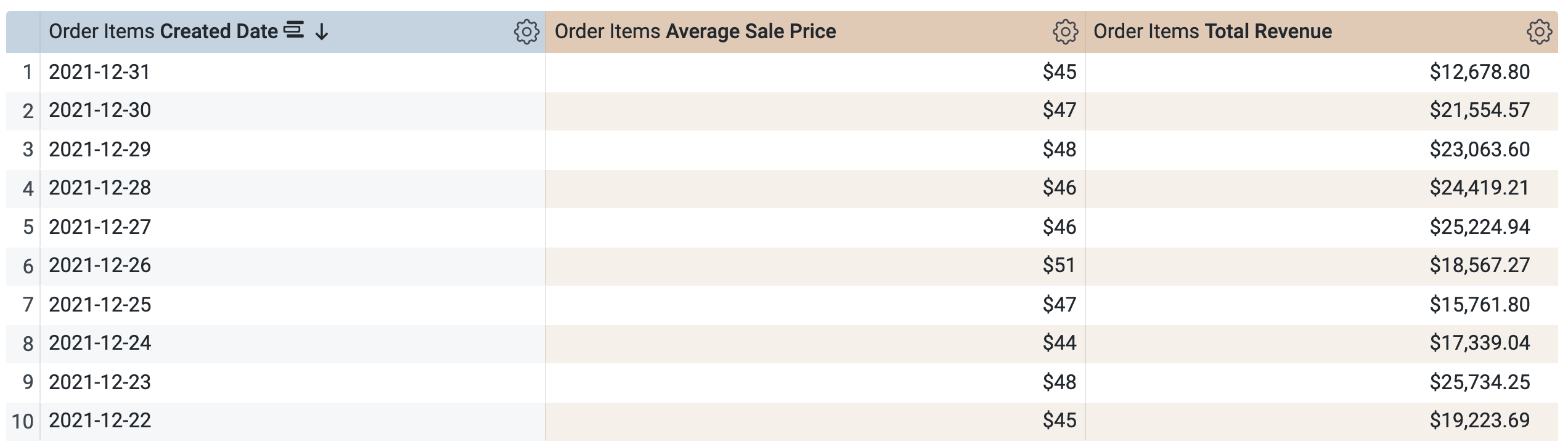
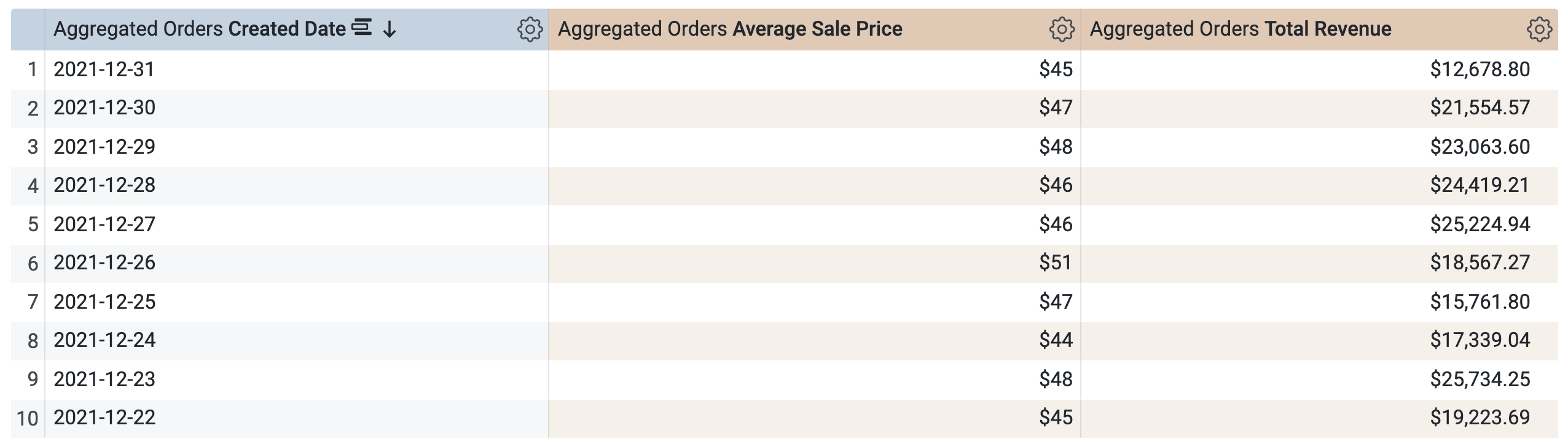
[Incremental Pdt] > [Dimensions] で、[Created Date] を選択します。
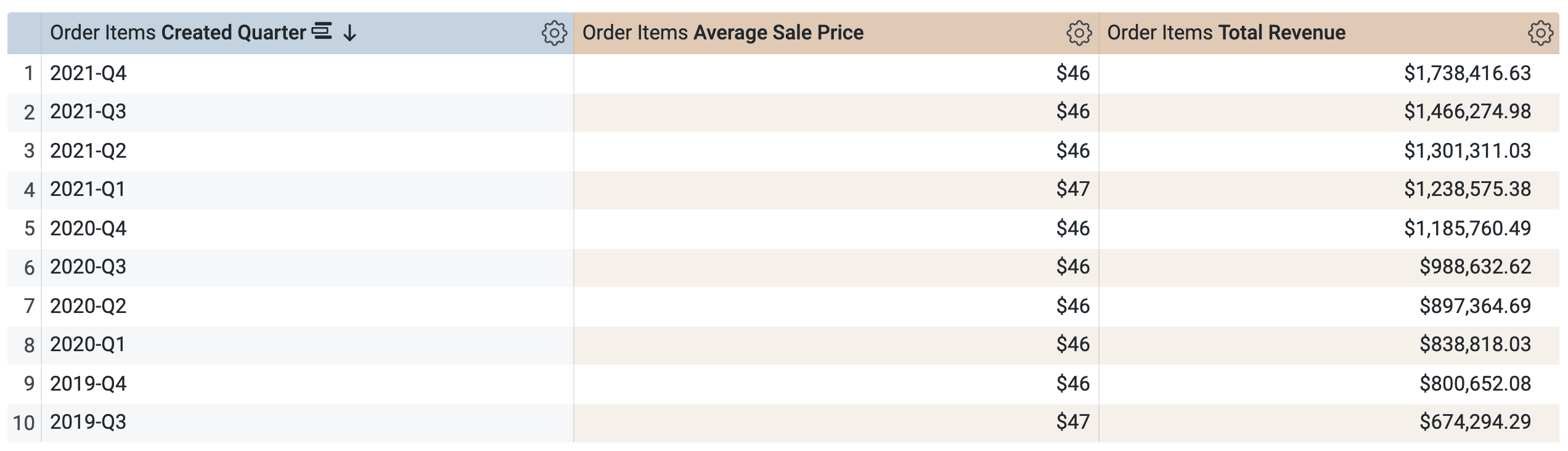
[Incremental Pdt] > [Measures] で、[Average Sale Price] と [Total Revenue] を選択します。
クエリを実行する前に、SQL ウィンドウに 2 つのクエリがあることに注意してください(読み込みに数秒かかる場合があります)。1 つ目のクエリは incremental_pdt という名前の PDT を生成し、2 つ目のクエリは新しく作成された PDT から結果を取得します。
[Run] をクリックします。
[Results] タブを開いて結果を確認します。
[Incremental Pdt] > [Dimensions] で、
[Data] ペインで [SQL] タブを開きます。
クエリは結果を取得するために同じ PDT を使用します。PDT ですでに定義(およびキャッシュ保存)されている期間を要求しているため、これは理にかなっています。ただし、四半期や年など、PDT にまだ含まれていない別の期間のクエリを選択して実行することはできません。
[Run] をクリックします。
[Results] タブを開いて結果を確認します。
Explore クエリのブラウザタブを閉じて、Looker IDE のブラウザタブに戻ります。
[Validate LookML] をクリックします。
LookML エラーは発生しません。
[LookML を検証] をクリックしてから、[Commit Changes & Push] をクリックします。
commit メッセージを追加して、[Commit] をクリックします。
最後に、[本番環境にデプロイ] をクリックします。
Looker IDE のブラウザタブを開いたまま、次のタスクを開始してください。
[Check my progress] をクリックして、目標に沿って進んでいることを確認します。
Looker では、データベース内の大きなテーブルに必要なクエリの数を最小限に抑える、戦略的な集約テーブルを作成できます。集約テーブルはデータベースに保持して、集約テーブルの自動認識でアクセスできるようにする必要があります。したがって、集約テーブルは一種の永続的な派生テーブル(PDT)と言えます。
集約テーブルは、LookML プロジェクトの Explore パラメータの下にある aggregate_table パラメータを使用して定義されます。集約テーブルを作成したら、Explore でクエリを実行して、Looker がどの集約テーブルを使用するかを確認できます。Looker は、集約テーブルの自動認識ロジックを使用して、データベース内で最も小規模の効率的なテーブルを検出し、正確性を維持しながらクエリを実行します。
このタスクでは、前のタスクの増分 PDT を新しい増分集約テーブルとして再作成します。また、既存の Order Items Explore の絞り込みを使用して、新しい集約テーブルをユーザーが利用できるようにします。
Looker IDE ページで、training_ecommerce.model を開きます。
ファイルの末尾(69 行目付近)に、次のコードを追加して order_items Explore の絞り込みを作成します。
この絞り込みは、モデルファイルで定義されている既存の order_items Explore をベースに構築され、新しい LookML コードで指定した変更(ラベルや集約テーブルなど)が追加されます。これらの変更は次のステップで追加します。
前のタスクで作成したネイティブ派生テーブルとは異なり、集約テーブルで指定されている時間ディメンションは created_date のみであることに注意してください。集約テーブルの自動認識により、Looker は、リクエストされた期間(日、月、年)に関係なく、時間集計された平均販売価格または総収益をリクエストする Explore クエリにこの単一のテーブルを活用できます。
このタブは Looker IDE 用に開いたままにしておきます。
ブラウザタブで新しい Looker ウィンドウを開きます。
[Explore] > [Order Items - Aggregate Sales] の順に移動します。
[Data] ペインで [SQL] タブを開きます。
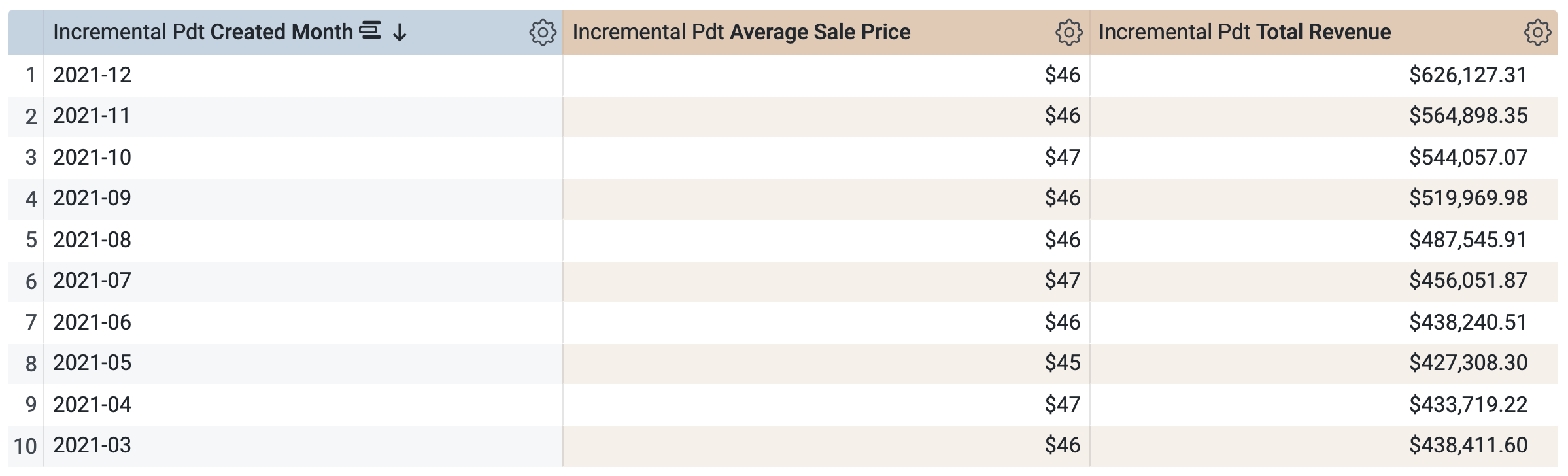
[Order Items] > [Dimensions] で、[Created Date] > [Date] を選択します。
[Order Items] > [Measures] で、[Average Sale Price] と [Total Revenue] を選択します。
クエリを実行する前に、タスク 1 の SQL ウィンドウと同様、2 つのクエリがあることに注意してください。1 つ目のクエリは aggregate_sales という名前の PDT を生成し、2 つ目のクエリはこの新しい PDT から結果を取得します。
[Run] をクリックします。
[Results] タブを開いて結果を確認します。
[Order Items] > [Dimensions] > [Created Date] で、
[Data] ペインで [SQL] タブを開きます。
クエリでは、四半期ごとの結果を取得するために同じ PDT(aggregate_sales)が使用されることに注意してください。Looker は集約テーブルの自動認識を適用して、[Created Date] で選択可能なリクエストされた期間に平均販売価格と総収益をロールアップします。
[Run] をクリックします。
[Results] タブを開いて結果を確認します。
Explore クエリのブラウザタブを閉じて、Looker IDE のブラウザタブに戻ります。
[Validate LookML] をクリックします。LookML エラーは発生しません。
[LookML を検証] をクリックしてから、[Commit Changes & Push] をクリックします。
commit メッセージを追加して、[Commit] をクリックします。
最後に、[本番環境にデプロイ] をクリックします。
Looker IDE のブラウザタブを開いたまま、次のタスクを開始してください。
[Check my progress] をクリックして、目標に沿って進んでいることを確認します。
効率的な結合は、Looker でパフォーマンスに優れた Explore を定義するうえで重要な要素です。結合の効率を向上させるには、Explore の定義に必要なビューのみを結合し、ビューの主キーとして(連結フィールドではなく)基本フィールドを使用して、可能な場合は常に many_to_one 結合を使用するようにします。
ドキュメントで説明されているように、ビュー内のレコードの一意の識別子を提供する役割を担う主キーは、Looker で正確な集計と関係を確立するために不可欠です。ビューの主キーは、一意の値を含むフィールド(ID 列など)であり、ビューファイルではパラメータ primary_key: yes によって識別されます。
このセクションでは、まずビューの主キーとして使用するのに最も適した列を特定します。次に、ユーザービューのみが結合された集約テーブルの新しい Explore を定義し、from パラメータを使用して order_items を Explore のベースビューとして指定し、ユーザービューを結合します。最後に、既存の Order Items Explore に含まれている余分な結合を省略し、many_to_one の結合関係を使用してクエリの効率を向上させます。
users.view では、ID 列は primary_key: yes によってすでに主キーとして識別されています。これは、一意の値(ユーザーごとに 1 つの ID)を含む基本フィールドであり、複数の列から作成された連結フィールドではありません。したがって、ID は users ビューの主キーとして最適であり、効率的な結合をサポートできます。
order_item_id は order_items テーブルの ID 列に基づいており、主キーとして識別されます。ただし、このビューの他の ID フィールドは、テーブルの一意のキーになる可能性があります。たとえば、order_id は order_items テーブルの order_id 列に基づいています。
次のステップでは、SQL Runner で order_items テーブルを調べ、order_item_id が主キーとして使用するのに最適なフィールドである理由を確認します。
新しいブラウザタブで新しい Looker ウィンドウを開きます。
[Develop] > [SQL Runner] に移動します。
[Connection] の横にある設定アイコン(
[Project] のボックスが空になります。「cloud-training-demos」と入力して、Enter キーを押します。
[データセット] は [looker_ecomm] を選択します。
この BigQuery データセットで利用可能なテーブルのリストが表示されます。
列が適切な主キーであるかどうかを確認する迅速かつ簡単な方法は、テーブルのレコード数と列の個別の値の数を比較することです。2 つの数が一致する場合、その列には一意の値が含まれているため、テーブルの主キーとして適切と言えます。
user_id 列が適切な主キーになるかどうかを確認するには、次のクエリを SQL クエリ ウィンドウに追加して、[Run] をクリックします。order_id、inventory_item_id、id 列についてもこのクエリを繰り返します。この場合、id と inventory_item_id はどちらもテーブル内のレコード数と一致しました。これは、注文内の同じアイテムに対して異なる ID が使用されているためです。したがって、どちらも主キーとして使用できる可能性があります。
id 列が order_items の主キーとして選択されたのは、order_items テーブルのアイテムに対して生成された ID であるためです。一方で、inventory_item_id は inventory_items テーブルの同じアイテムの ID です。
training_ecommerce.model を開きます。
既存の order_items Explore を確認します。
それぞれ many_to_one の関係タイプを使用する 4 つの異なる結合が含まれています。ユースケースによっては、これらのすべての結合が必要になる場合があります。しかし、ユーザーと注文のデータを州別または期間別にロールアップするだけでよい場合はどうでしょうか。その場合、これらの追加の結合は実際には使用されず、Explore でのクエリの処理速度が低下します。
次のステップでは、order_items ビューの user_id と users ビューの id に基づいて、注文データとユーザーデータのみを結合する新しい Explore を作成します。
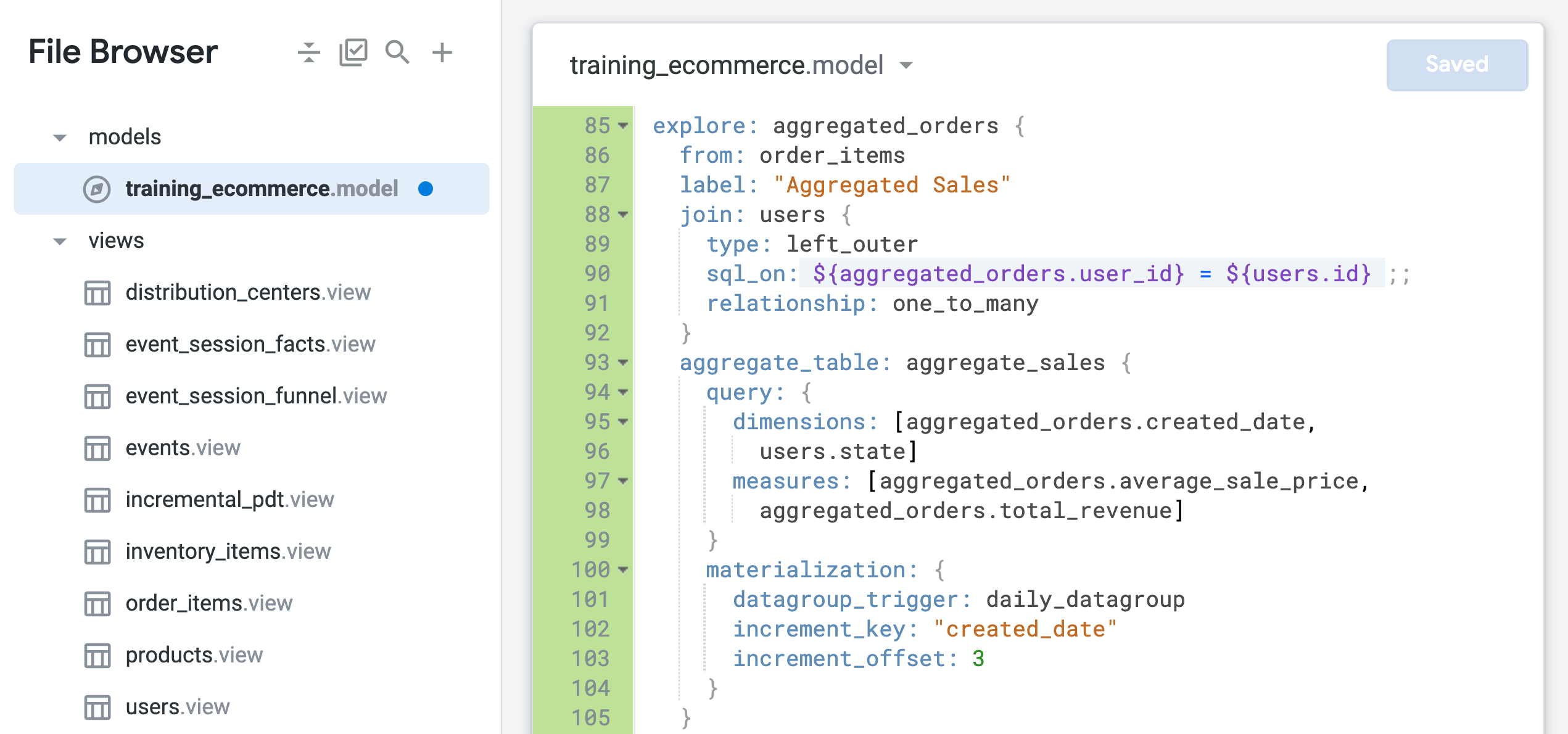
order_items を使用し、users ビューのみを結合した新しい Explore を定義します。from パラメータは、Explore のベースビューとして order_items を指定するために使用されます。このベースビューに users ビューが結合されます。order_items ビューのフィールドは、新しい Explore 名を使用して aggregated_orders.fieldname として識別されるようになりました。
また、users ビューと order_items ビューの関係は、現在 one_to_many として識別されています。次のステップでは、one_to_many の関係に基づくこの結合が、この Explore にとって最適な構成であるかどうかをテストします。
新しいブラウザタブで新しい Looker ウィンドウを開きます。
[Explore] > [Aggregated Sales] に移動します。
[Data] ペインで [SQL] タブを開きます。
[Aggregated Orders] > [Dimensions] で、[Created Date] > [Date] を選択します。
[Aggregated Orders] > [Measures] で、以下を選択します。
クエリを実行する前に、結合ファンアウトの問題により集約テーブルが使用されていないことに注意してください。
2 つのテーブル間の関係が結合で正しく識別されない場合、意図しないファンアウトが発生する可能性があります。この場合、Explore のベースビューは order_items で、1 人のユーザーに対して複数の注文を含めることができます。しかし、users ビューにはユーザーごとに 1 つのレコードしか含まれていません。
したがって、この結合は、1 つの注文を複数のユーザーに結び付けるのではなく、複数の注文を 1 人のユーザーに結び付ける many_to_one として定義する必要があります(ファンアウトの問題について詳しくは、Looker ヘルプセンターをご覧ください)。
[Run] をクリックします。
[Results] タブを開きます。
結果は返されますが、Looker は結果の取得に効率的な集約テーブルを使用しませんでした。
Explore のこのブラウザタブは開いたままにして、Looker IDE のブラウザタブに戻ります。
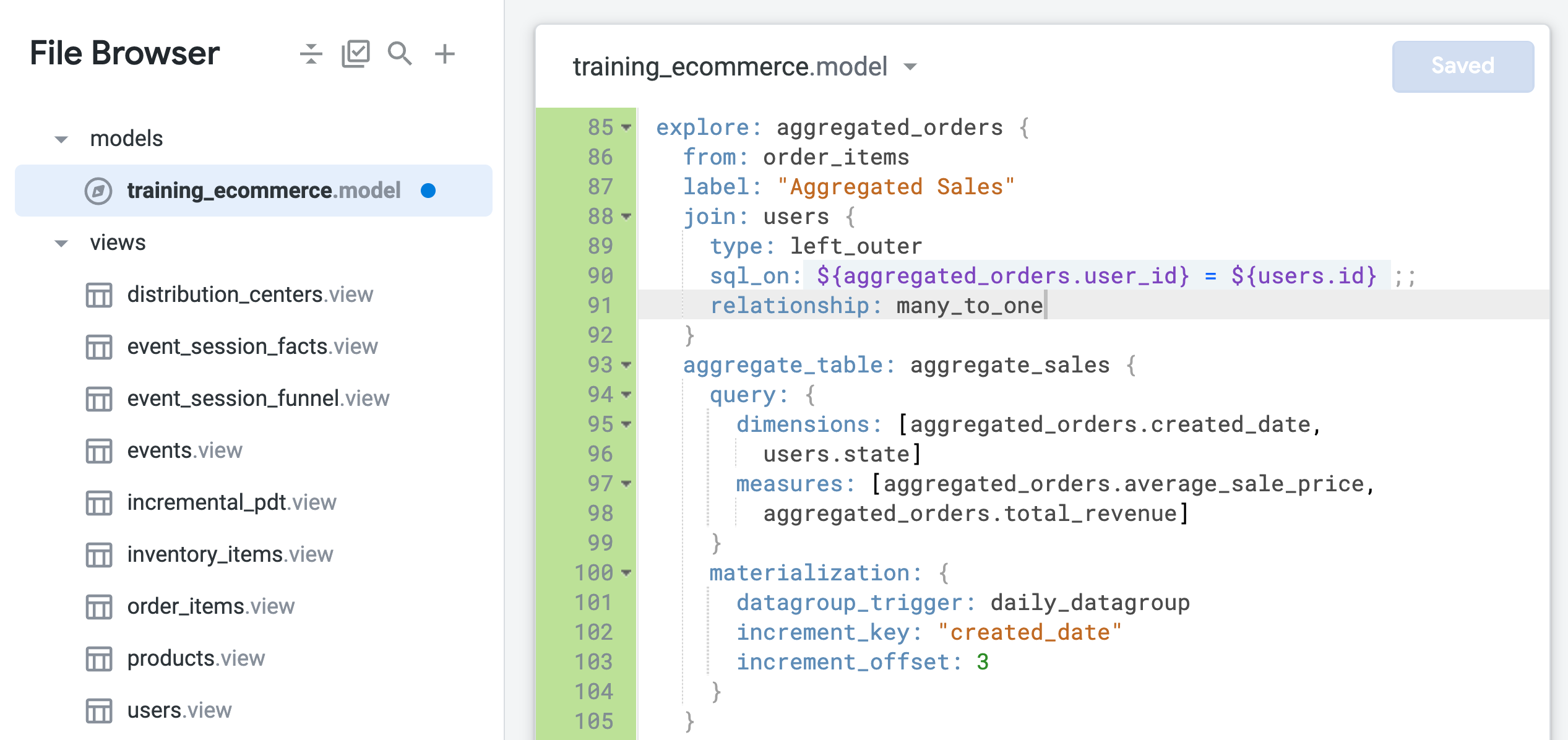
aggregated_orders Explore の relationship パラメータを many_to_one(91 行目)に更新します。
Explore クエリのブラウザタブに戻り、ページを更新します。
[Data] ペインで [SQL] タブを開きます。
タスク 1 とタスク 2 の [SQL] タブと同様に、ここでも 2 つのクエリがあります。1 つ目は PDT を生成し、2 つ目は PDT から結果を取得します。
Explore クエリのブラウザタブを閉じて、Looker IDE のブラウザタブに戻ります。
[Validate LookML] をクリックします。
LookML エラーは発生しません。
[LookML を検証] をクリックしてから、[Commit Changes & Push] をクリックします。
commit メッセージを追加して、[Commit] をクリックします。
最後に、[本番環境にデプロイ] をクリックします。
Looker IDE のブラウザタブを開いたまま、次のタスクを開始してください。
[Check my progress] をクリックして、目標に沿って進んでいることを確認します。
Looker では、[Admin] メニューの [Persistent Derived Tables] ページから、Looker インスタンスの PDT のビルドをモニタリングできます。Looker の構成によっては、テーブルを永続化する権限を持つ Looker ユーザーは、[Admin] メニュー全体にアクセスできなくても、このページを表示できます。開発環境と本番環境の両方で PDT のステータス、ビルド時間、キャッシュを確認できるため、Looker インスタンス内の PDT を簡単にテストおよびモニタリングできます。
このタスクでは、このラボで作成した PDT のステータス、ビルド時間、キャッシュ、本番環境と開発環境をモニタリングします。NDT から作成された増分 PDT(タスク 1)のビルド時間が最も長く、集約テーブル(タスク 2 と 3)のビルド時間が最も短くなります。これは、これらのテーブルが同じテーブル定義を使用しているものの、構成の異なる Explore に含まれているためです。また、開発環境で PDT を変更し、本番環境に push する前後のステータスもモニタリングします。
新しいブラウザタブで新しい Looker ウィンドウを開きます。
[Admin] > [Persistent Derived Tables] に移動します。
すべての PDT が本番環境に push されているため、[Development] タブには PDT が表示されません。
[Production] タブを開き、タスク 1~3 で作成した PDT を確認します。
[Last Attempt Status] には、すべての PDT で [Success] と表示され、すべて同じ永続化ルール(daily_datagroup)が使用されています。[Last Build Duration] のビルド時間については、incremental_pdt のビルド時間がおそらく 2 つの集約テーブルよりもわずかに長くなります。
[Persistent Derived Tables] ページを開いたまま、次のステップを開始します。
Looker IDE のブラウザタブに戻ります。
training_ecommerce.model を開きます。
aggregated_orders Explore に users.country の新しいディメンションを追加します(96 行目付近)。
[Save Changes] をクリックします。
[Persistent Derived Tables] ページに戻り、ページを更新します。
開発モードで PDT の LookML コードを変更したにもかかわらず、[Production] タブでは、aggregated_orders::aggregate_sales PDT がまだビルド済みとして表示されています。
Looker では、Development Mode で他の Looker オブジェクトを操作するのと同様に、Development Mode で PDT の変更をテストできます。たとえば、デベロッパーが Development Mode で新しいディメンションとメジャーを作成した場合、これらの新しいオブジェクトは、デベロッパーが変更を commit して本番環境にデプロイするまで、本番環境に表示されません。
この [Persistent Derived Tables] ページを開いたまま、新しいブラウザタブで新しい Looker ウィンドウを開きます。
[Explore] > [Aggregate Sales] に移動します。
[Data] ペインで [SQL] タブを開きます。
[Users] > [Dimensions] で、[Country] を選択します。
[Aggregated Orders] > [Measures] で、以下を選択します。
[SQL] タブには 2 つのクエリがあります。1 つ目は PDT を生成し、2 つ目は新しくビルドされた PDT から結果を取得します。
[Run] をクリックします。
[Results] タブを開いて結果を確認します。
Explore クエリのブラウザタブを閉じ、[Persistent Derived Tables] ページが表示されているブラウザタブに戻って、ページを更新します。
[Development] タブに、aggregated_orders::aggregate_sales が正常にビルドされたことが表示されます。
[Persistent Derived Tables] ページのブラウザタブを開いたままにして、Looker IDE のブラウザタブに戻ります。
[Validate LookML] をクリックします。
LookML エラーは発生しません。
[LookML を検証] をクリックしてから、[Commit Changes & Push] をクリックします。
commit メッセージを追加して、[Commit] をクリックします。
最後に、[本番環境にデプロイ] をクリックします。
[Persistent Derived Tables] ページが表示されているブラウザタブに戻り、ページを更新します。これで本番環境への変更がデプロイされたため、aggregated_orders::aggregate_sales PDT は [Development] タブに表示されなくなり、[Production] タブにのみ表示されます。
このラボでは、派生テーブルに永続性と増分更新を追加するタイミングと方法や、集約テーブルの自動認識の使用、パフォーマンスに優れた方法でのビューの結合、PDT のビルドのモニタリングによって Looker クエリを最適化する方法について学習しました。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2024 年 4 月 23 日
ラボの最終テスト日: 2023 年 10 月 6 日
Copyright 2026 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください