GSP985

Présentation
Looker est une plate-forme de données moderne intégrée à Google Cloud. Elle permet d'analyser et de visualiser vos données de manière interactive. Vous pouvez utiliser Looker pour effectuer des analyses de données approfondies, intégrer des insights provenant de différentes sources de données, mettre en place des workflows exploitables basés sur les données et créer des applications de données personnalisées.
Les requêtes complexes peuvent être coûteuses, et leur exécution répétée met à rude épreuve votre base de données, ce qui réduit les performances. Dans l'idéal, vous devez éviter de réexécuter des requêtes volumineuses si rien n'a changé. Au lieu de cela, ajoutez les nouvelles données aux résultats existants pour réduire les requêtes répétitives. Bien qu'il existe de nombreuses façons d'optimiser les performances des requêtes LookML, cet atelier se concentre sur les méthodes les plus couramment utilisées pour optimiser les performances des requêtes dans Looker : les tables dérivées persistantes, la reconnaissance d'agrégats et la jointure performante de vues.
Objectifs de l'atelier
- Comprendre quand et comment ajouter la persistance et des mises à jour incrémentales aux tables dérivées
- Utiliser la reconnaissance d'agrégats pour optimiser les requêtes sur les données cumulées ou résumées.
- Créer un affinement d'une exploration existante
- Joindre des vues de manière performante pour optimiser les requêtes d'exploration
- Surveiller les compilations de tables dérivées persistantes dans une instance Looker
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
Remarque : Ouvrez une fenêtre de navigateur en mode incognito/navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
- vous disposez d'un temps limité ; n'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Si vous possédez déjà votre propre compte ou projet Google Cloud, veillez à ne pas l'utiliser pour réaliser cet atelier afin d'éviter que des frais supplémentaires ne vous soient facturés.
Démarrer votre atelier et vous connecter à Looker
-
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Le volet "Détails concernant l'atelier" s'affiche avec les identifiants temporaires que vous devez utiliser pour cet atelier.
Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement.
Notez les identifiants qui vous ont été attribués pour cet atelier dans le volet "Détails concernant l'atelier". Ils vous serviront à vous connecter à l'instance Looker de cet atelier.
Remarque : Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
-
Cliquez sur Ouvrir Looker.
-
Saisissez le nom d'utilisateur et le mot de passe fournis dans les champs Adresse e-mail et Mot de passe.
Nom d'utilisateur :
{{{looker.developer_username | Username}}}
Mot de passe :
{{{looker.developer_password | Password}}}
Important : Vous devez utiliser les identifiants fournis dans le volet "Détails concernant l'atelier" sur cette page. Ne saisissez pas vos identifiants Google Cloud Skills Boost. Si vous possédez un compte Looker personnel, ne l'utilisez pas pour cet atelier.
-
Cliquez sur Connexion.
Une fois la connexion établie, l'instance Looker de cet atelier s'affichera.
Recommandations clés pour optimiser les performances des requêtes
Dans cette section, vous allez découvrir les méthodes couramment utilisées pour optimiser les performances des requêtes dans Looker. Dans cet atelier, vous allez vous familiariser avec les trois premières méthodes.
Tables dérivées persistantes (PDT)
La première solution est celle des tables dérivées persistantes (PDT). Looker vous permet d'écrire des requêtes SQL et LookML dans votre base de données sous forme de table temporaire. Lorsqu'une table est mise en cache ou conservée, on parle de table dérivée persistante (PDT). Cela vous permet d'exécuter de manière répétée des requêtes complexes ou couramment utilisées, et de mettre en cache les résultats pour y accéder rapidement.
En enregistrant ces requêtes sous forme de table, vous contrôlez le moment et la manière dont elles sont créées. Les tables peuvent être recompilées chaque matin, une fois par mois ou uniquement lorsque de nouvelles données sont ajoutées. Dans l'idéal, vous configurez vos tables dérivées pour qu'elles reflètent la nature de vos données.
Les tables dérivées sont utiles pour créer des structures ou des agrégations qui ne sont pas encore disponibles dans les tables de votre base de données sous-jacente, mais toutes les tables dérivées n'ont pas besoin d'être conservées pour être utiles. La persistance est généralement appliquée aux requêtes complexes qui sont coûteuses à exécuter ou aux requêtes qui sont fréquemment utilisées par un grand nombre d'utilisateurs ou d'applications.
Vous pouvez également créer des PDT incrémentales pour ajouter de nouvelles données sans recompiler la table entière. L'application de modifications incrémentales est une bonne solution pour les grandes tables dont les données existantes (plus anciennes) ne sont pas fréquemment mises à jour, car la mise à jour principale de la table consiste à ajouter de nouveaux enregistrements.
Reconnaissance d'agrégats
Pour les très grandes tables de votre base de données, la reconnaissance d'agrégats de Looker peut créer des tables agrégées moins volumineuses contenant des données regroupées selon diverses combinaisons d'attributs. Les tables agrégées servent de tables de "cumul" ou de synthèse. Looker peut les utiliser à la place de la grande table d'origine pour les requêtes, chaque fois que cela est possible. La reconnaissance d'agrégats permet à Looker de trouver la table la plus petite et la plus efficace disponible dans votre base de données pour exécuter une requête tout en restant le plus précis possible. Lorsqu'elle est implémentée de manière stratégique, la reconnaissance d'agrégats peut accélérer la requête moyenne de plusieurs ordres de grandeur. Prenons l'exemple d'une table de commandes en ligne pour une boutique d'e-commerce très fréquentée, à laquelle de nouvelles lignes sont ajoutées toutes les quelques secondes.
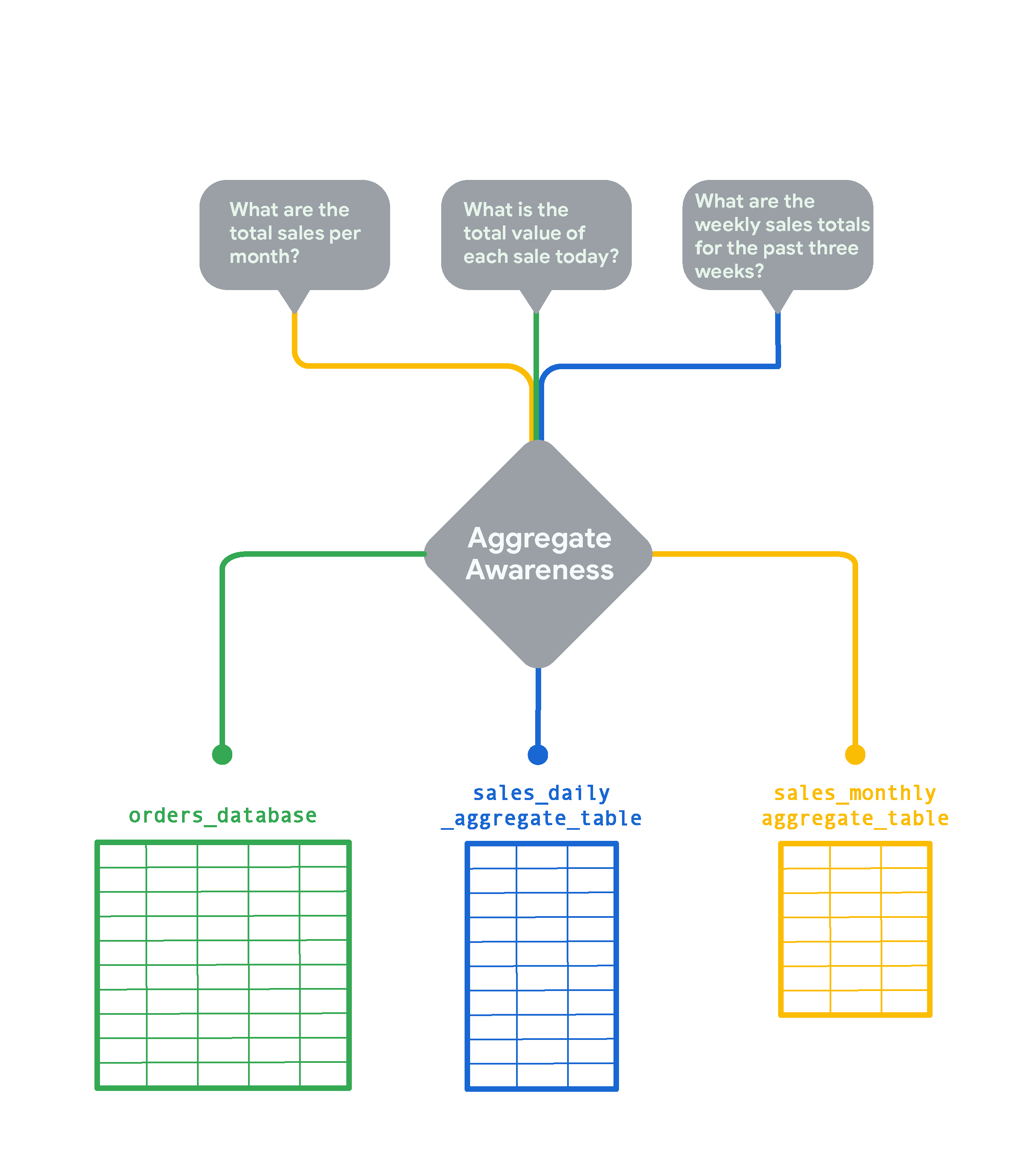
Si vous souhaitez suivre les commandes en temps réel, vous aurez besoin de plus de détails. En revanche, si vous voulez examiner les tendances mensuelles, comme le total des ventes par mois, il est beaucoup plus rapide et économique d'agréger les données mensuellement. Dans ce cas, Looker crée et interroge la table sales_monthly_aggregate_table.
Pour répondre à une question comme "Quelle est la valeur totale de chaque vente aujourd'hui ?", vous avez besoin de données de commande granulaires au niveau des lignes. Dans ce cas, Looker interrogera la table orders_database d'origine sans aucune agrégation. Si vous souhaitez consulter le total des ventes hebdomadaires des trois dernières semaines, Looker crée et sélectionne une table agrégée des ventes quotidiennes. Cette table est plus détaillée que la table des ventes mensuelles, mais elle représente le cumul de la table brute orders_database.
La reconnaissance d'agrégats dans Looker est couramment utilisée pour cumuler ou résumer des données sur plusieurs périodes. De plus, les tables agrégées doivent être conservées dans une instance Looker pour pouvoir être utilisées pour la reconnaissance d'agrégats.
Joindre des vues de manière performante
Une autre façon d'optimiser les performances consiste à joindre uniquement les vues dont vous avez besoin lorsque vous créez une exploration. Pour limiter les jointures, vous pouvez définir plusieurs explorations à des fins différentes (par exemple, interroger les données par utilisateur ou interroger les données de ventes agrégées). De plus, vous devez utiliser des champs de base plutôt que des champs concaténés comme clés primaires. Dans la mesure du possible, utilisez des jointures many_to_one (plusieurs à un) : joindre des vues du niveau le plus précis au niveau de détail le plus élevé (many_to_one) offre généralement les meilleures performances de requête dans Looker.
Inclure des filtres dans les définitions d'exploration
En incluant des filtres dans les définitions d'exploration, vous pouvez optimiser les performances en évitant de renvoyer une grande quantité de données par défaut. Il existe de nombreuses options de filtrage, y compris des filtres visibles et modifiables par les utilisateurs, comme always_filter et conditionally_filter. Vous pouvez également modifier les suggestions de filtres pour les champs d'une exploration. Pour en savoir plus sur les filtres d'exploration et vous entraîner à les utiliser, suivez l'atelier Filtrer des explorations avec LookML.
Implémenter des règles de mise en cache
Pour réduire le trafic des requêtes de base de données, vous devez maximiser la mise en cache afin de vous synchroniser avec vos règles d'extraction, de chargement et de transformation (ETL), dans la mesure du possible. Par défaut, Looker met en cache les requêtes pendant une heure. Vous pouvez contrôler la règle de mise en cache et synchroniser les actualisations des données Looker avec votre processus ETL en utilisant le paramètre persist_with pour appliquer des groupes de données dans les explorations. Cela permet à Looker de s'intégrer plus étroitement au pipeline de données backend afin que l'utilisation du cache puisse être maximisée, sans risque d'analyser des données obsolètes.
Par exemple, certaines tables de données ne sont mises à jour qu'une fois par jour. Dans ce cas, actualiser le cache toutes les heures n'apporte aucune valeur ajoutée. Dans cet atelier, vous allez utiliser différentes options pour personnaliser la mise en cache dans Looker, y compris les groupes de données ou les règles de mise en cache, afin de rendre persistantes les tables dérivées. Pour en savoir plus sur les règles de mise en cache et vous entraîner à les utiliser, suivez l'atelier Mise en cache et groupes de données avec LookML.
Optimisation supplémentaire des requêtes
Selon le dialecte de votre base de données, vous pouvez explorer d'autres fonctionnalités d'optimisation des requêtes, telles que cluster_keys et indexes.
Tâche 1 : Créer une table dérivée persistante incrémentale qui s'actualisera automatiquement sans recompiler l'intégralité de la table
Comme nous l'avons vu, une table dérivée persistante (PDT) est écrite dans un schéma brouillon de la base de données. Elle est ensuite régénérée selon une fréquence que vous définissez dans votre stratégie de persistance. Les PDT sont utiles : lorsque l'utilisateur demande des données de la table, celle-ci existe déjà, ce qui réduit le temps de requête et la charge de la base de données.
Dans une table PDT standard, la totalité de la table est recréée selon une programmation définie dans sa règle de mise en cache. En revanche, les PDT créées de manière incrémentale ajoutent de nouvelles données à une table existante. Cela peut réduire considérablement la taille de la requête que vous envoyez à la base de données.
Dans cette tâche, vous allez créer une table dérivée native (NDT) pour agréger les données de commande par période ou par état. Vous activez également la persistance avec une actualisation quotidienne et des mises à jour incrémentales qui remontent jusqu'à trois jours en arrière pour récupérer les données tardives.
Utiliser une exploration pour créer une table dérivée native
-
Cliquez sur le bouton d'activation pour passer en mode Développement.
-
Accédez à Exploration > Order Items (Articles de la commande).
-
Sous Order Items > Dimensions (Articles de la commande > Dimensions), sélectionnez les éléments suivants :
- ID de commande
- Prix de vente
-
Date de création > Date
-
Date de création > Semaine
-
Date de création > Mois
-
Sous Users > Dimensions (Utilisateurs > Dimensions), sélectionnez State (État).
-
Cliquez sur Exécuter.
-
Cliquez sur Paramètres ( ).
).
-
Sélectionnez Afficher le code LookML.
-
Dans l'onglet Table dérivée, copiez le code LookML dans un éditeur de texte.
Vous allez utiliser ce code pour créer une vue pour la table dérivée native.
Créer un fichier d'affichage pour une table dérivée
-
Ouvrez une nouvelle fenêtre Looker dans un nouvel onglet du navigateur.
-
Dans le menu Développer, cliquez sur qwiklabs_ecommerce.
-
Cliquez sur l'icône + à côté de l'explorateur de fichiers, puis sélectionnez Créer une vue.
-
Nommez le nouveau fichier incremental_pdt, puis cliquez sur Créer.
-
Dans l'explorateur de fichiers, cliquez sur incremental_pdt.view et faites-le glisser sous le dossier views.
-
Remplacez le code LookML par défaut dans incremental_pdt.view par le code que vous avez copié précédemment pour la table dérivée native.
-
Mettez à jour la ligne 4 avec le nom de vue correct (incremental_pdt).
-
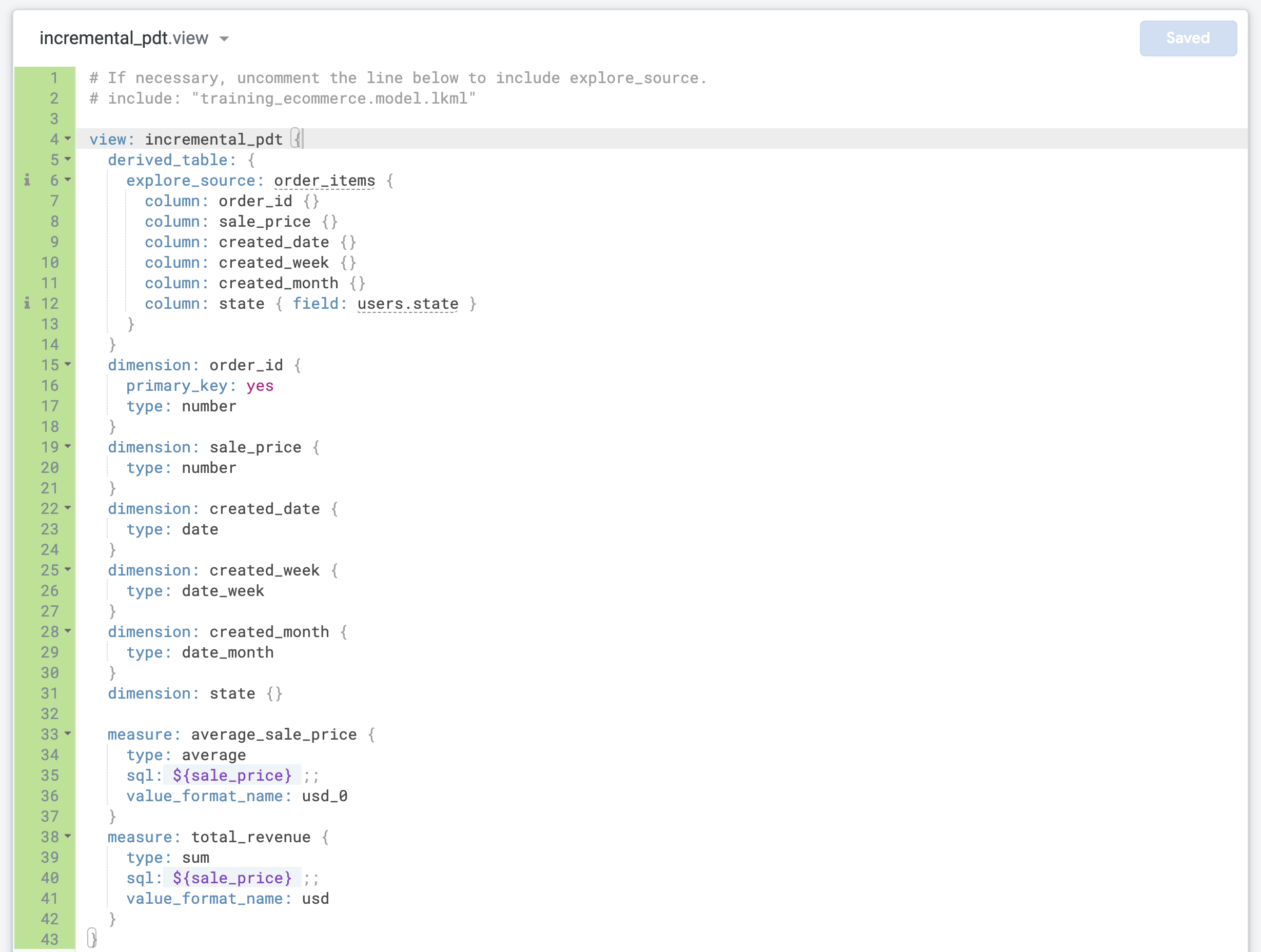
Mettez à jour la dimension order_id pour la définir comme primary_key de la vue :
dimension: order_id {
primary_key: yes
type: number
}
En effet, chaque enregistrement représente une commande avec un order_id unique.
- Recherchez la dernière dimension et ajoutez deux mesures avant l'accolade fermante finale (
}) dans le fichier :
measure: average_sale_price {
type: average
sql: ${sale_price} ;;
value_format_name: usd_0
}
measure: total_revenue {
type: sum
sql: ${sale_price} ;;
value_format_name: usd
}
- Cliquez sur Enregistrer les modifications. Votre fichier doit se présenter comme suit :
Ajouter la persistance et des mises à jour incrémentales à une table dérivée
-
Ouvrez training_ecommerce.model.
-
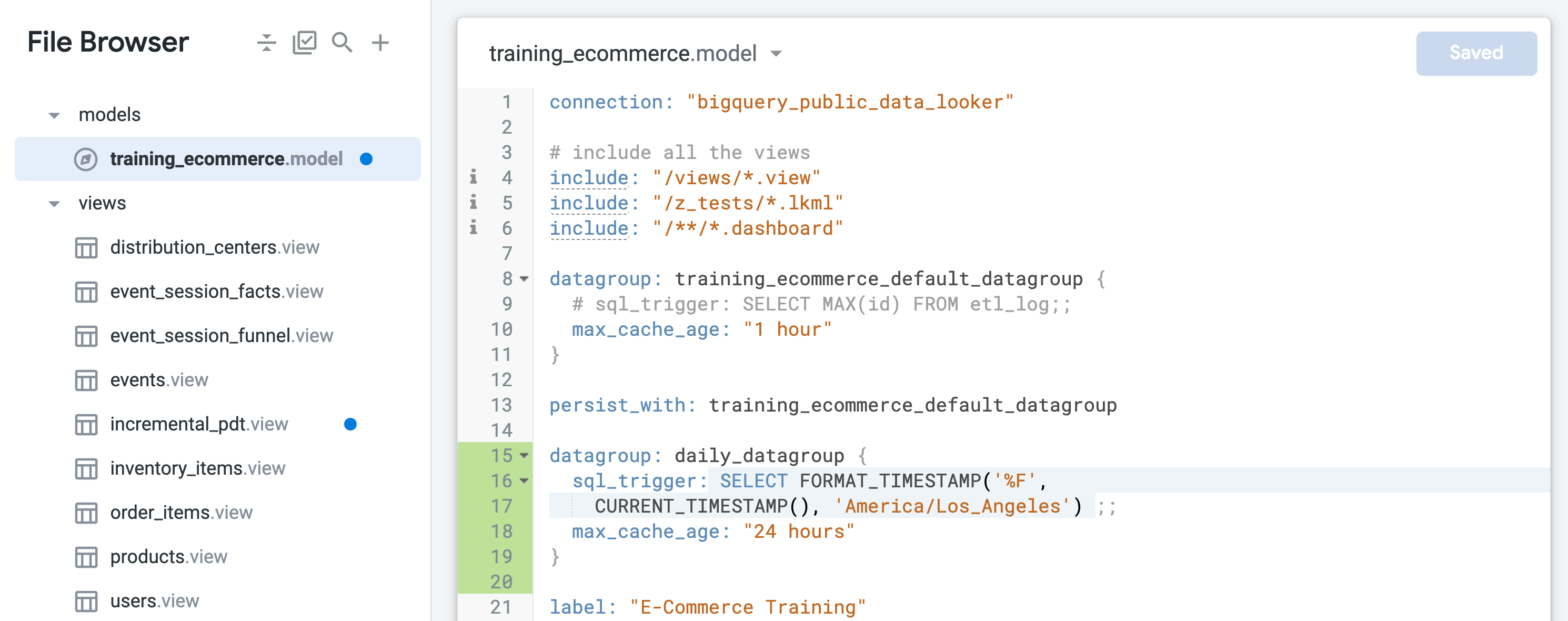
Recherchez le groupe de données par défaut nommé training_ecommerce_default_datagroup et ajoutez une nouvelle ligne (ligne 13).
-
Définissez un nouveau groupe de données pour conserver les objets avec une actualisation quotidienne (durée maximale de 24 heures) :
datagroup: daily_datagroup {
sql_trigger: SELECT FORMAT_TIMESTAMP('%F',
CURRENT_TIMESTAMP(), 'America/Los_Angeles') ;;
max_cache_age: "24 hours"
}
Le sql_trigger vérifie la date actuelle et déclenche une actualisation lorsque la date change. Le paramètre max_cache_age garantit que la table sera recompilée au bout de 24 heures, même si le sql_trigger ne s'exécute pas correctement.
- À la fin de
training_ecommerce.model (vers la ligne 67), définissez une exploration qui ne contient que la vue incremental_pdt afin de pouvoir la tester dans les étapes suivantes :
explore: incremental_pdt {}
- Cliquez sur Enregistrer les modifications.
- Ouvrez incremental_pdt.view, puis ajoutez la persistance en incluant le datagroup "daily" (quotidien) dans la définition de la table dérivée à la ligne 6 :
datagroup_trigger: daily_datagroup
- Ajoutez des mises à jour incrémentales en incluant les paramètres suivants dans la définition de la table dérivée aux lignes 7 et 8 :
increment_key: "created_date"
increment_offset: 3
- Cliquez sur Enregistrer les modifications. Votre fichier doit se présenter comme suit :
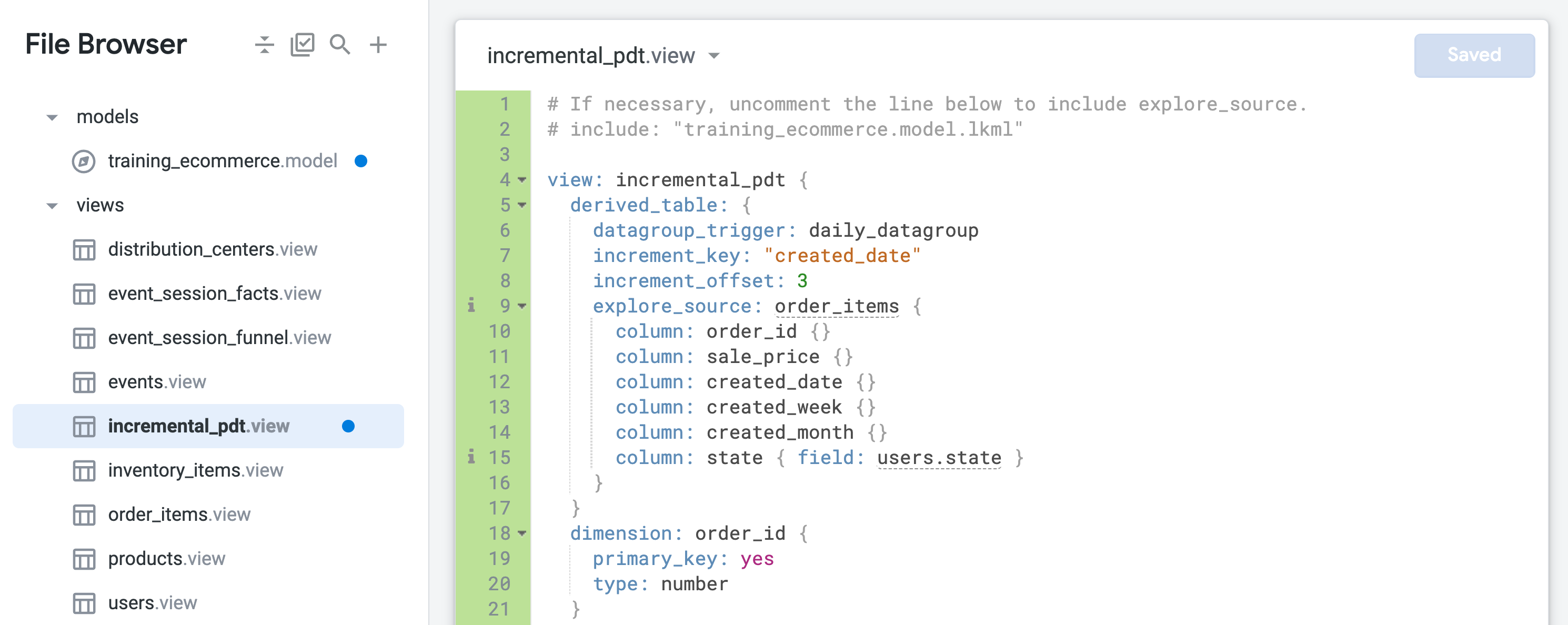
La table dérivée persistante sera désormais conservée et recompilée une fois par jour, en remontant trois jours en arrière pour capturer les commandes qui auraient pu arriver en retard.
- Fermez l'onglet du navigateur contenant la requête d'exploration d'origine, mais laissez l'onglet de l'IDE Looker ouvert.
Tester des requêtes d'exploration sur une table dérivée persistante incrémentale
-
Ouvrez une nouvelle fenêtre Looker dans un onglet du navigateur.
-
Accédez à Exploration > Incremental Pdt (table dérivée persistante incrémentale).
-
Dans le volet "Données", ouvrez l'onglet SQL.
-
Sous Incremental Pdt > Dimensions, sélectionnez Date de création.
-
Sous Incremental Pdt > Mesures, sélectionnez Average Sale Price (prix de vente moyen) et Total Revenue (revenu total).
Avant d'exécuter la requête, notez qu'il y a deux requêtes dans la fenêtre SQL (le chargement peut prendre quelques secondes). La première requête génère la PDT nommée incremental_pdt, et la deuxième requête récupère les résultats de la PDT nouvellement créée.
-
Cliquez sur Exécuter.
-
Ouvrez l'onglet Résultats pour afficher les résultats.
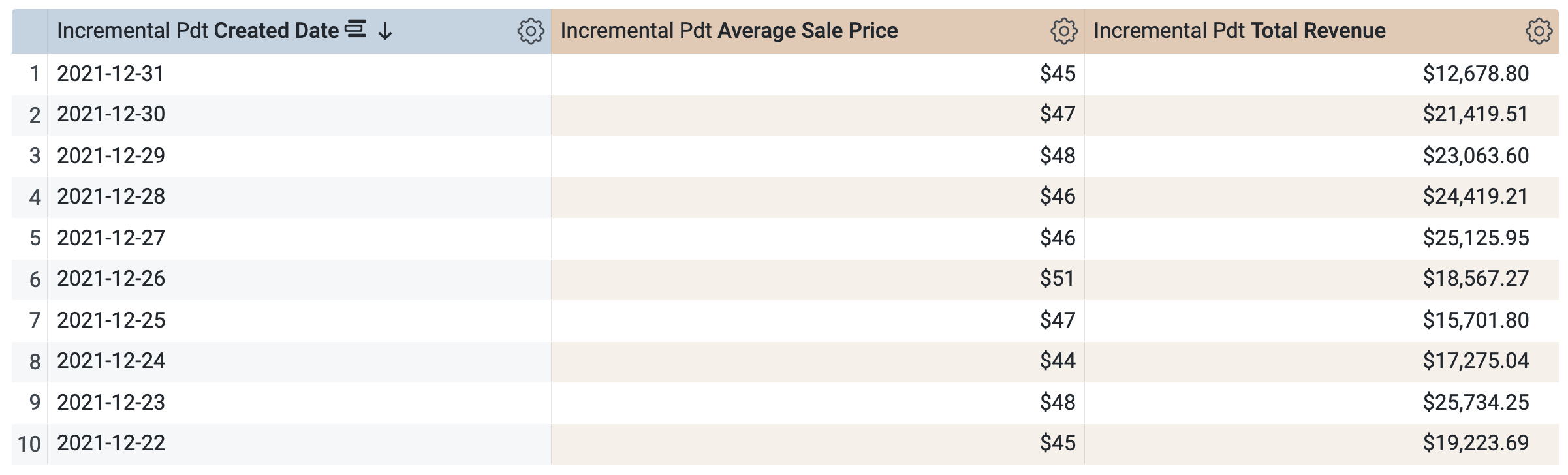
-
Sous Incremental Pdt > Dimensions :
-
Effacez Date de création.
- Sélectionnez Mois de création.
-
Dans le volet "Données", ouvrez l'onglet SQL.
Notez que la requête utilisera la même PDT pour récupérer les résultats, ce qui est logique, car vous avez demandé une période déjà définie (et mise en cache) dans la PDT. Toutefois, vous ne pouvez pas sélectionner et exécuter une requête sur une période qui n'est pas déjà incluse dans la PDT, comme un trimestre ou une année.
-
Cliquez sur Exécuter.
-
Ouvrez l'onglet Résultats pour afficher les résultats.
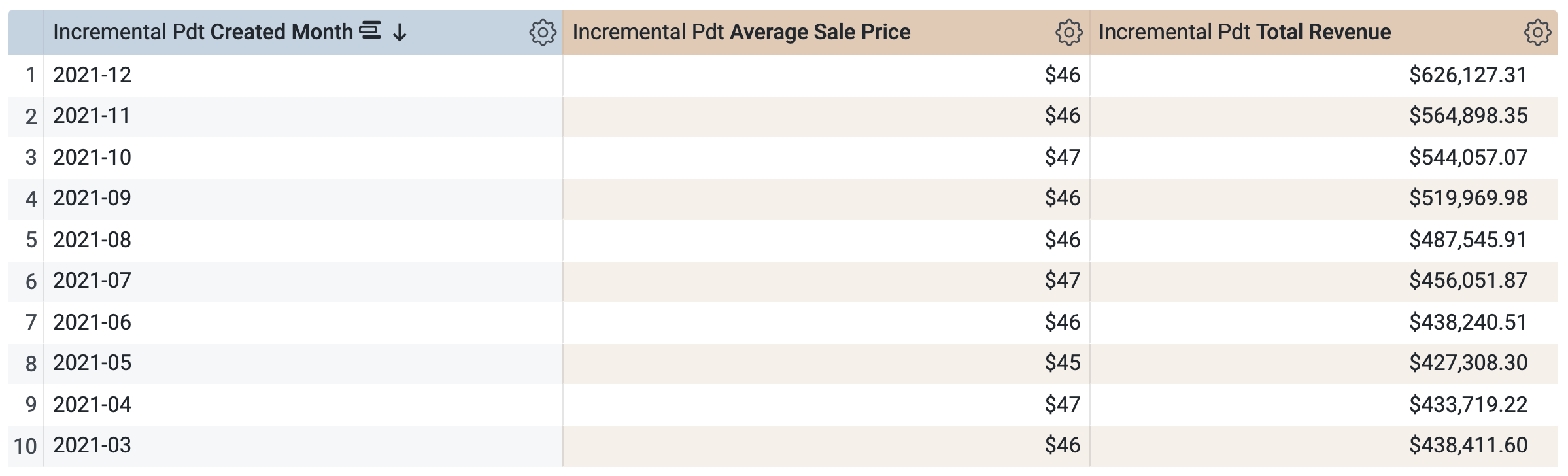
Challenge
- Exécutez une nouvelle requête en utilisant uniquement la dimension State et les mesures Average Sale Price et Total Revenue. Répondez à la question suivante.
-
Fermez l'onglet de navigateur de la requête d'exploration et revenez à l'onglet de navigateur de l'IDE Looker.
-
Cliquez sur Valider le code LookML.
Il ne devrait y avoir aucune erreur de code LookML.
Valider les modifications et les déployer en production
-
Cliquez sur Valider le LookML, puis sur Valider les modifications et envoyer.
-
Ajoutez un message de commit, puis cliquez sur Valider.
-
Enfin, cliquez sur Déployer en production.
Restez dans l'onglet de navigateur de l'IDE Looker et passez à la tâche suivante.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer une table dérivée persistante incrémentale
Tâche 2 : Créer une table agrégée incrémentale pour résumer les données de commande sur plusieurs périodes
Dans Looker, vous pouvez créer des tables agrégées stratégiques qui minimisent le nombre de requêtes nécessaires sur les grandes tables d'une base de données. Les tables agrégées doivent être conservées dans votre base de données pour être accessibles à la fonctionnalité de reconnaissance d'agrégats. Les tables agrégées sont donc un type de table dérivée persistante (PDT).
Une table agrégée est définie à l'aide du paramètre aggregate_table sous un paramètre d'exploration dans votre projet LookML. Une fois que vous avez créé vos tables agrégées, vous pouvez exécuter des requêtes dans l'exploration pour voir quelles tables agrégées Looker utilise. Looker utilise une logique de reconnaissance des agrégats pour trouver la table agrégée la plus petite et la plus efficace disponible dans votre base de données, afin d'exécuter une requête tout en restant le plus précis possible.
Dans cette tâche, vous allez recréer la PDT incrémentale de la tâche précédente en tant que table agrégée incrémentale. Vous mettez également la nouvelle table agrégée à la disposition des utilisateurs en utilisant un affinement de l'exploration "Order Items" existante.
Créer une table agrégée dans l'affinement d'une exploration existante
-
Sur la page de l'IDE Looker, ouvrez training_ecommerce.model.
-
À la fin du fichier (vers la ligne 69), ajoutez le code suivant pour créer un affinement de l'exploration order_items :
explore: +order_items {
label: "Order Items - Aggregate Sales"
}
Cet affinement s'appuie sur l'exploration order_items existante définie dans le fichier de modèle et ajoute les modifications spécifiées dans le nouveau code LookML, comme l'étiquette ou la table agrégée que vous ajouterez lors des prochaines étapes.
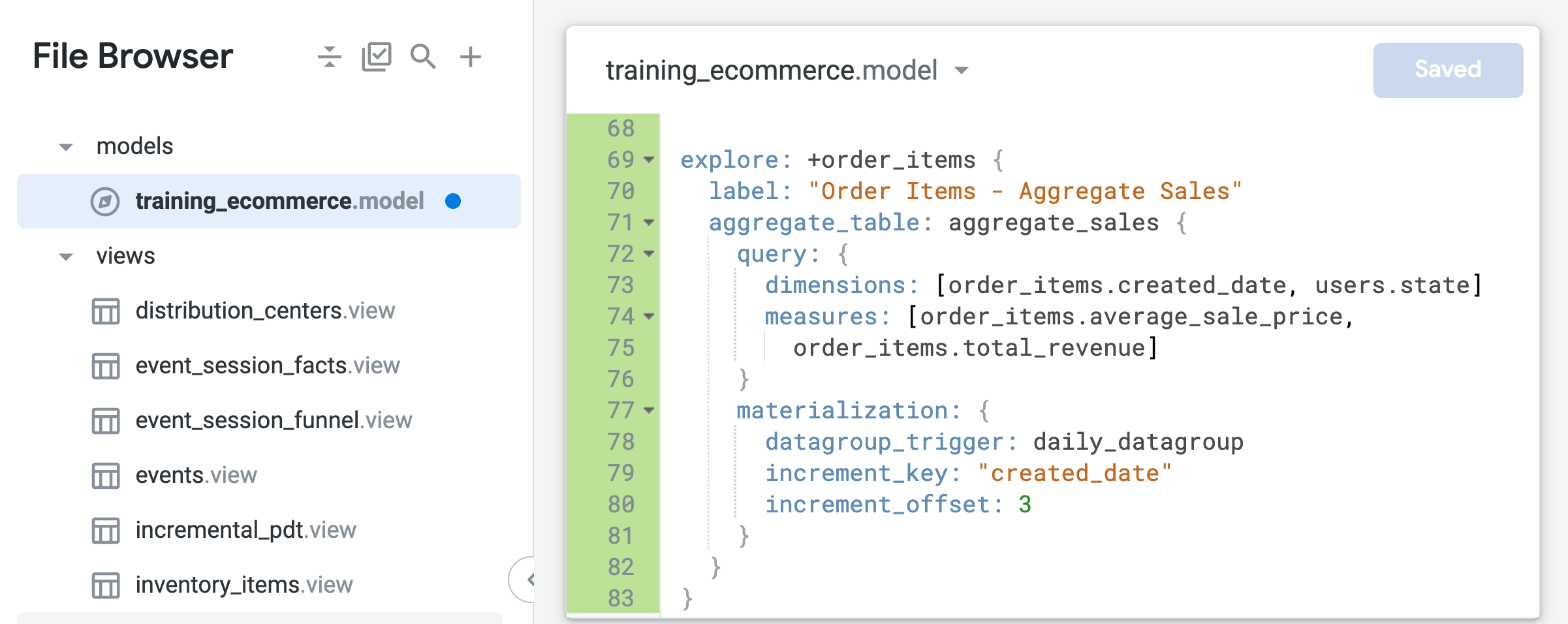
- Développez le code LookML pour afin que l'affinement puisse inclure une table agrégée qui résume les données de commande par période ou par état :
explore: +order_items {
label: "Order Items - Aggregate Sales"
aggregate_table: aggregate_sales {
query: {
dimensions: [order_items.created_date, users.state]
measures: [order_items.average_sale_price,
order_items.total_revenue]
}
materialization: {
datagroup_trigger: daily_datagroup
increment_key: "created_date"
increment_offset: 3
}
}
}
Notez que, contrairement à la table dérivée native que vous avez créée dans la tâche précédente, la seule dimension temporelle spécifiée dans la table agrégée est created_date. Grâce à la reconnaissance d'agrégats, Looker peut exploiter cette table unique pour les requêtes d'exploration qui demandent le prix de vente moyen (Average Sale Price) ou le revenu total (Total Revenue) agrégés dans le temps, quelle que soit la période demandée (jour, mois, année).
- Cliquez sur Enregistrer les modifications.
Laissez l'onglet de l'IDE Looker ouvert.
Tester des requêtes d'exploration sur une table agrégée incrémentale persistante
-
Ouvrez une nouvelle fenêtre Looker dans un onglet du navigateur.
-
Accédez à Exploration > Order Items - Aggregate Sales.
-
Dans le volet "Données", ouvrez l'onglet SQL.
-
Sous Order Items > Dimensions, sélectionnez Date de création > Date.
-
Sous Order Items > Mesures, sélectionnez Average Sale Price et Total Revenue.
Avant d'exécuter la requête, notez qu'il y a deux requêtes, comme dans la fenêtre SQL de la tâche 1. La première requête génère la PDT nommée aggregate_sales, et la seconde récupère les résultats de cette nouvelle PDT.
-
Cliquez sur Exécuter.
-
Ouvrez l'onglet Résultats pour afficher les résultats.
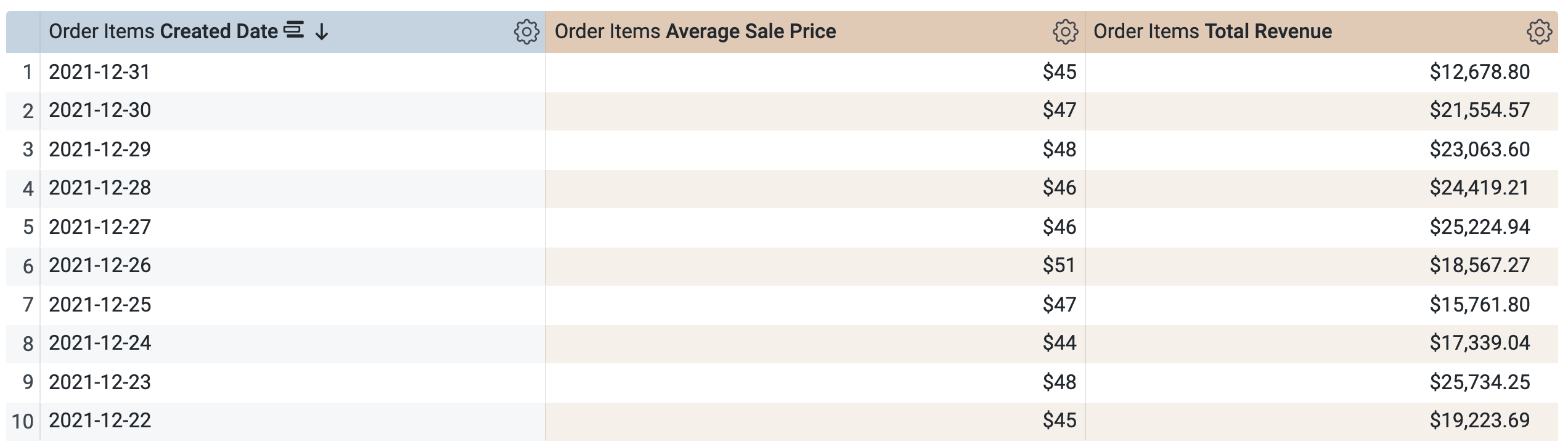
-
Sous Order Items > Dimensions > Date de création :
-
Effacez Date.
- Sélectionnez Trimestre.
-
Dans le volet "Données", ouvrez l'onglet SQL.
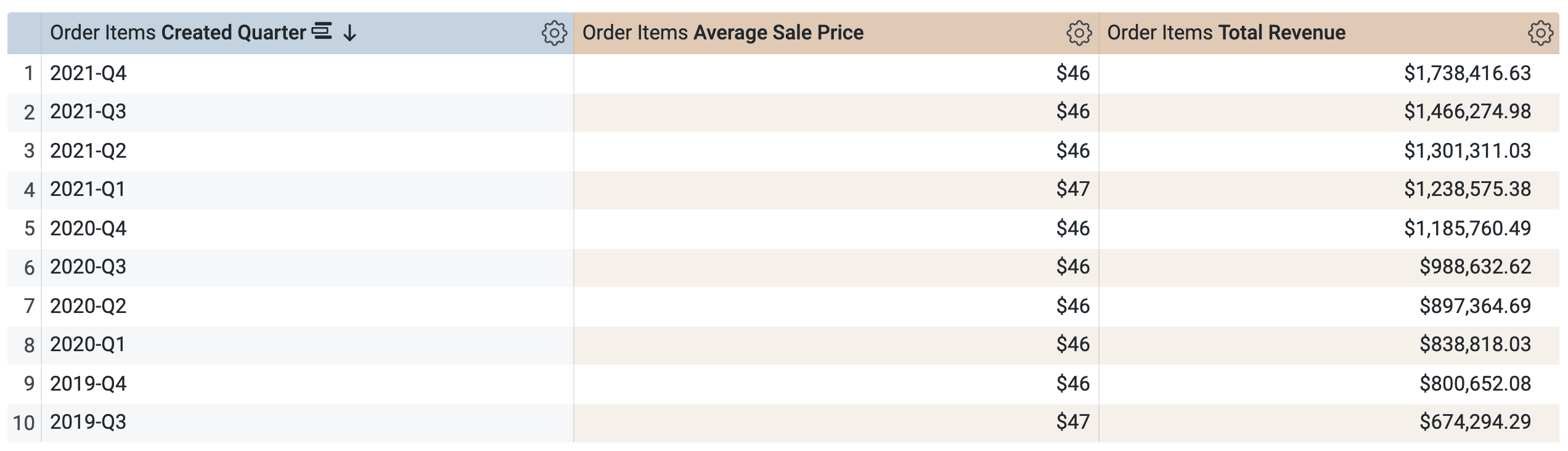
Notez que la requête utilisera la même PDT (aggregate_sales) pour récupérer les résultats par trimestre. Looker applique la reconnaissance d'agrégats pour cumuler le prix de vente moyen (Average Sale Price) et le revenu total (Total Revenue) sur les périodes demandées disponibles sous "Date de création".
-
Cliquez sur Exécuter.
-
Ouvrez l'onglet Résultats pour afficher les résultats.
Challenge
- Exécutez une nouvelle requête en utilisant uniquement la dimension State (sous "Users") et les mesures Average Sale Price et Total Revenue. Répondez à la question suivante.
- Exécutez une nouvelle requête en utilisant uniquement la dimension Country (sous "Users") et les mesures Average Sale Price et Total Revenue. Répondez à la question suivante.
-
Fermez l'onglet de navigateur de la requête d'exploration et revenez à l'onglet de navigateur de l'IDE Looker.
-
Cliquez sur Valider le code LookML. Il ne devrait y avoir aucune erreur de code LookML.
Valider les modifications et les déployer en production
-
Cliquez sur Valider le LookML, puis sur Valider les modifications et envoyer.
-
Ajoutez un message de commit, puis cliquez sur Valider.
-
Enfin, cliquez sur Déployer en production.
Restez dans l'onglet de navigateur de l'IDE Looker et passez à la tâche suivante.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer une table agrégée
Tâche 3 : Joindre des vues de manière performante pour optimiser les requêtes d'exploration
Les jointures efficaces sont des éléments clés pour définir des explorations performantes dans Looker. Pour améliorer l'efficacité des jointures, veillez à ne joindre que les vues nécessaires pour définir l'exploration, à utiliser des champs de base (au lieu de champs concaténés) comme clés primaires pour les vues, et à utiliser des jointures many_to_one chaque fois que possible.
Comme indiqué dans la documentation, les clés primaires fournissent un identifiant unique pour les enregistrements d'une vue et sont cruciales pour la précision des agrégations et des relations dans Looker. La clé primaire d'une vue est un champ contenant des valeurs uniques (comme une colonne d'ID). Elle est identifiée dans le fichier d'affichage à l'aide du paramètre primary_key: yes.
Dans cette section, vous allez d'abord identifier la colonne qui est la plus appropriée pour être utilisée comme clé primaire pour une vue. Vous définirez ensuite une nouvelle exploration pour la table agrégée avec uniquement la vue "users" jointe. Vous utiliserez le paramètre "from" pour spécifier order_items comme vue de base de l'exploration, puis vous joindrez la vue "users". Enfin, vous omettrez les jointures supplémentaires incluses dans l'exploration "Order Items" existante et utiliserez la relation de jointure many_to_one pour améliorer l'efficacité des requêtes.
Identifier le champ le plus approprié pour être utilisé comme clé primaire d'une vue
- Ouvrez le fichier users.view. Répondez à la question suivante.
Dans users.view, la colonne ID est déjà identifiée comme clé primaire à l'aide de primary_key: yes. Il s'agit d'un champ de base qui contient des valeurs uniques (un ID pour chaque utilisateur) et qui n'est pas un champ concaténé créé à partir de plusieurs colonnes. Par conséquent, ID est le meilleur choix pour la clé primaire de la vue "users" et peut prendre en charge des jointures efficaces.
- Ouvrez le fichier order_items.view. Répondez à la question suivante.
Le champ order_item_id est basé sur la colonne "ID" de la table order_items et est identifié comme la clé primaire. Toutefois, d'autres champs d'ID de cette vue pourraient potentiellement être la clé unique de la table, y compris order_id, qui est basé sur la colonne order_id de la table order_items.
Dans les étapes suivantes, vous allez explorer la table order_items dans l'exécuteur SQL pour identifier pourquoi order_item_id est le meilleur champ à utiliser comme primary_key.
-
Ouvrez une nouvelle fenêtre Looker dans un nouvel onglet du navigateur.
-
Accédez à Développer > Exécuteur SQL.
-
Cliquez sur Paramètres () à côté de "Connexion", puis sélectionnez Search public projects (Rechercher des projets publics).
-
La zone "Project" (Projet) est maintenant vide. Saisissez cloud-training-demos, puis appuyez sur ENTRÉE.
-
Dans le champ "Dataset" (Ensemble de données), sélectionnez looker_ecomm.
La liste des tables disponibles dans cet ensemble de données BigQuery s'affiche.
Pour vérifier rapidement et facilement si une colonne peut servir de clé primaire, comparez le nombre d'enregistrements dans la table au nombre de valeurs distinctes dans la colonne. Si les deux nombres correspondent, la colonne contient des valeurs uniques et constitue une clé primaire appropriée pour la table.
- Pour vérifier si la colonne
user_id peut servir de clé primaire, ajoutez la requête suivante à la fenêtre de l'exécuteur SQL et cliquez sur Exécuter :
SELECT count(*), count(distinct user_id)
FROM cloud-training-demos.looker_ecomm.order_items
- Répétez la requête pour les colonnes
order_id, inventory_item_id et id.
Dans ce cas, les valeurs id et inventory_item_id correspondent au nombre d'enregistrements dans la table, car il s'agit de différents ID pour le même article dans une commande. Par conséquent, l'un ou l'autre peut potentiellement être utilisé comme clé primaire.
La colonne id a été choisie comme clé primaire pour order_items, car il s'agit de l'ID généré pour un article dans la table order_items. En revanche, inventory_item_id est l'ID du même élément dans la table inventory_items.
- Fermez l'onglet de navigateur de l'exécuteur SQL et revenez à l'onglet de navigateur de l'IDE Looker.
Joindre le moins de vues possible pour définir de nouvelles explorations
-
Ouvrez training_ecommerce.model.
-
Examinez l'exploration order_items existante.
Notez qu'elle inclut quatre jointures différentes qui utilisent chacune le type de relation many_to_one. Selon votre cas d'utilisation, vous aurez peut-être besoin de toutes ces jointures. Mais que faire si vous n'avez besoin que des données sur les utilisateurs et les commandes cumulées par état ou période ? Si c'est le cas, ces jointures supplémentaires ne seront jamais utilisées et ralentiront les requêtes dans l'exploration.
Dans les étapes suivantes, vous allez créer une exploration qui joint uniquement les données de commande et d'utilisateur, en fonction de user_id dans la vue order_items et de id dans la vue users.
- À la fin du fichier (vers la ligne 85), ajoutez le code suivant pour définir une nouvelle exploration avec
order_items comme vue de base et uniquement la vue "users" jointe :
explore: aggregated_orders {
from: order_items
label: "Aggregated Sales"
join: users {
type: left_outer
sql_on: ${aggregated_orders.user_id} = ${users.id} ;;
relationship: one_to_many
}
aggregate_table: aggregate_sales {
query: {
dimensions: [aggregated_orders.created_date,
users.state]
measures: [aggregated_orders.average_sale_price,
aggregated_orders.total_revenue]
}
materialization: {
datagroup_trigger: daily_datagroup
increment_key: "created_date"
increment_offset: 3
}
}
}
- Cliquez sur Enregistrer les modifications.
Votre fichier doit se présenter comme suit :
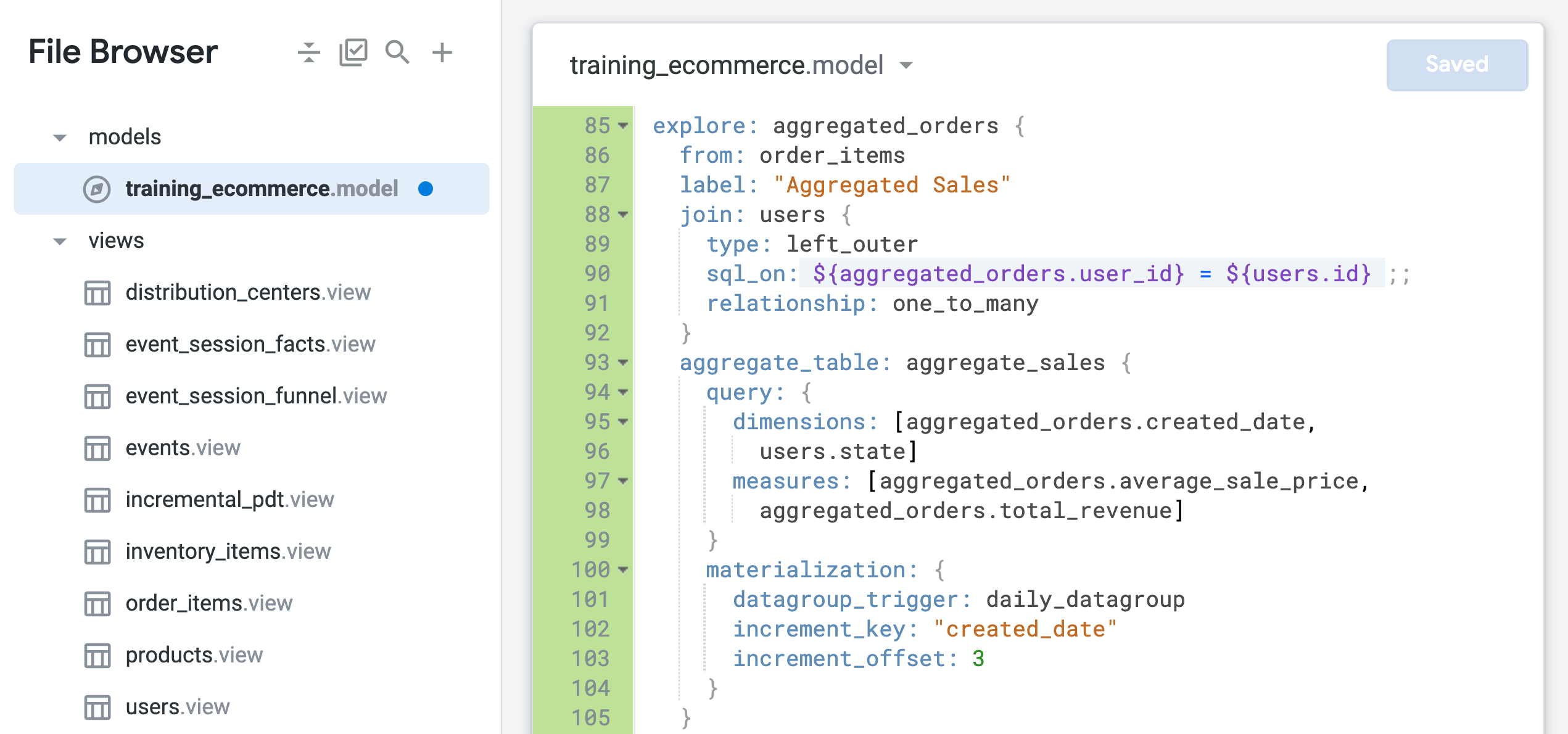
Le paramètre from est utilisé pour spécifier order_items comme vue de base de l'exploration, à laquelle la vue "users" est jointe. Les champs de la vue order_items sont désormais identifiés à l'aide du nouveau nom de l'exploration, aggregated_orders.fieldname.
Notez également que la relation entre la vue users et la vue order_items est actuellement identifiée comme étant de type one_to_many. Dans les étapes suivantes, vous allez tester si cette jointure basée sur une relation one_to_many est la meilleure configuration pour cette exploration.
Définir des relations de jointure performantes pour des requêtes d'exploration efficaces
-
Ouvrez une nouvelle fenêtre Looker dans un nouvel onglet du navigateur.
-
Accédez à Exploration > Aggregated Sales (ventes agrégées).
-
Dans le volet "Données", ouvrez l'onglet SQL.
-
Sous Aggregated Orders (Commandes agrégées) > Dimensions, sélectionnez Date de création > Date.
-
Sous Aggregated Orders > Mesures, sélectionnez :
- Average Sale Price
- Total Revenue
Avant d'exécuter la requête, notez que la table agrégée n'est pas utilisée en raison d'un problème de sortance de jointure :
-- Did not use aggregated_orders::aggregate_sales; field aggregated_orders.average_sale_price was DISTINCT in the table due to a join fanout, but there was no fanout in the query
Une sortance involontaire peut se produire lorsque la relation entre deux tables n'est pas correctement identifiée pour une jointure. Dans ce cas, la vue de base de l'exploration est order_items. Elle peut contenir plusieurs commandes pour un même utilisateur. Cependant, la vue users ne contient qu'un seul enregistrement par utilisateur.
Par conséquent, cette jointure doit être définie en tant que many_to_one (plusieurs commandes pour un utilisateur) et non comme un à plusieurs (une commande pour plusieurs utilisateurs). (Pour en savoir plus sur le problème des sortances, consultez le centre d'aide Looker.)
-
Cliquez sur Exécuter.
-
Ouvrez l'onglet "Résultats".
Les résultats sont renvoyés, mais Looker n'a pas utilisé la table agrégée efficace pour les récupérer.
-
Laissez cet onglet du navigateur avec l'exploration ouvert et revenez à l'onglet du navigateur contenant l'IDE Looker.
-
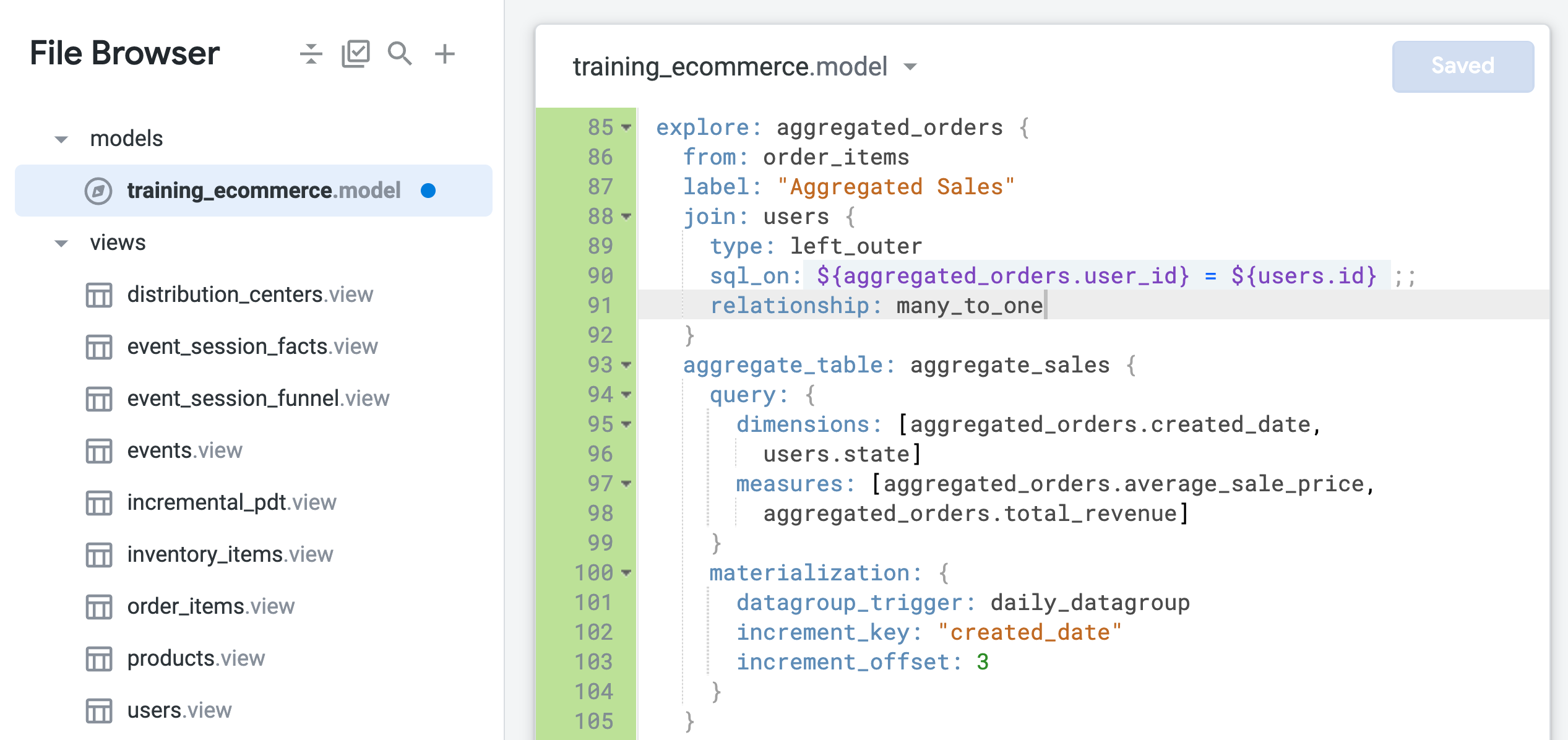
Dans l'exploration "aggregated_orders", remplacez la valeur du paramètre "relationship" par many_to_one (ligne 91) :
relationship: many_to_one
- Cliquez sur Enregistrer les modifications.
Votre fichier doit se présenter comme suit :
-
Revenez à l'onglet du navigateur contenant la requête d'exploration et actualisez la page.
-
Dans le volet "Données", ouvrez l'onglet SQL.
Comme dans les tâches 1 et 2, l'onglet "SQL" contient désormais deux requêtes : la première pour générer la table PDT et la seconde pour récupérer les résultats de la table PDT.
- Ouvrez l'onglet "Résultats" pour afficher les résultats.
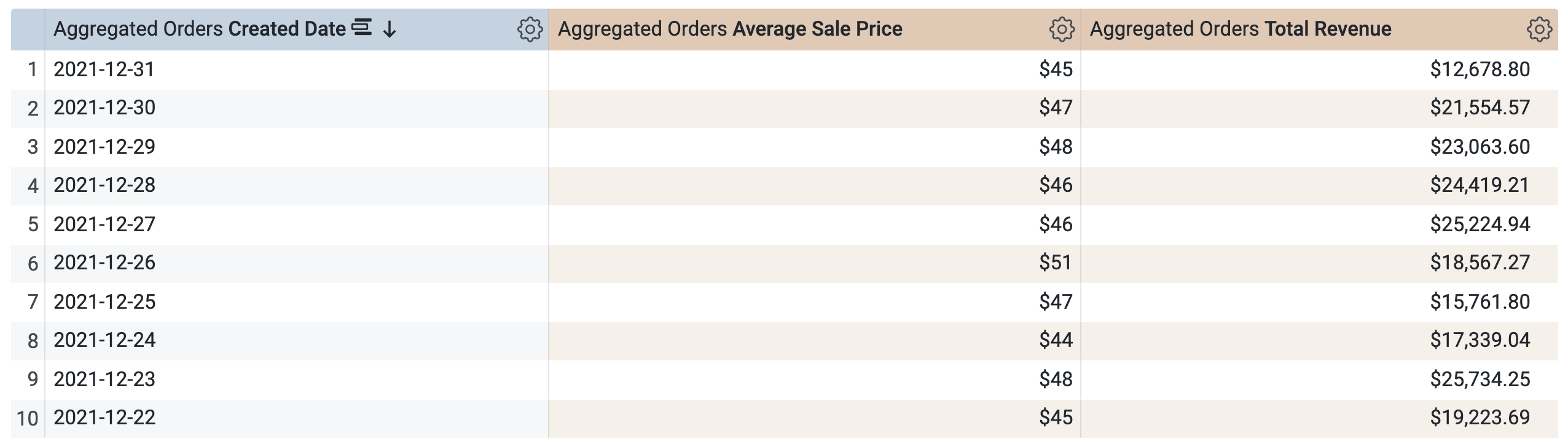
-
Fermez l'onglet de navigateur de la requête d'exploration et revenez à l'onglet de navigateur de l'IDE Looker.
-
Cliquez sur Valider le code LookML.
Il ne devrait y avoir aucune erreur de code LookML.
Valider les modifications et les déployer en production
-
Cliquez sur Valider le LookML, puis sur Valider les modifications et envoyer.
-
Ajoutez un message de commit, puis cliquez sur Valider.
-
Enfin, cliquez sur Déployer en production.
Restez dans l'onglet de navigateur de l'IDE Looker et passez à la tâche suivante.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Joindre le moins de vues possible aux nouvelles explorations
Tâche 4 : Surveiller les compilations de tables dérivées persistantes dans une instance Looker
Looker permet de surveiller la compilation de tables PDT dans une instance Looker via la page "Tables dérivées persistantes" du menu "Admin". Selon la configuration de Looker, les utilisateurs Looker qui disposent des droits nécessaires pour rendre les tables persistantes peuvent afficher cette page, même s'ils n'ont pas accès à l'intégralité du menu "Admin". Vous pouvez vérifier l'état, la durée de compilation et la mise en cache des PDT dans vos environnements de développement et de production. Vous pouvez ainsi facilement tester et surveiller les PDT dans votre instance Looker.
Dans cette tâche, vous allez surveiller l'état, la durée de compilation et la mise en cache des PDT créées dans cet atelier, en production et en développement. La PDT incrémentale créée à partir de la NDT (tâche 1) devrait avoir la durée de compilation la plus longue, et les tables agrégées (tâches 2 et 3) devraient présenter les durées de compilation les plus courtes. En effet, elles utilisent la même définition de table, mais elles sont incluses dans des explorations configurées différemment. Vous allez également modifier une PDT en développement et surveiller son état avant et après son passage en production.
Vérifier l'état des PDT en production
-
Ouvrez une nouvelle fenêtre Looker dans un nouvel onglet du navigateur.
-
Accédez à Admin > Tables dérivées persistantes.
Aucune table PDT n'est affichée dans l'onglet "Développement", car toutes vos tables PDT ont été transférées en production.
-
Ouvrez l'onglet Production pour afficher les PDT que vous avez créées dans les tâches 1 à 3.
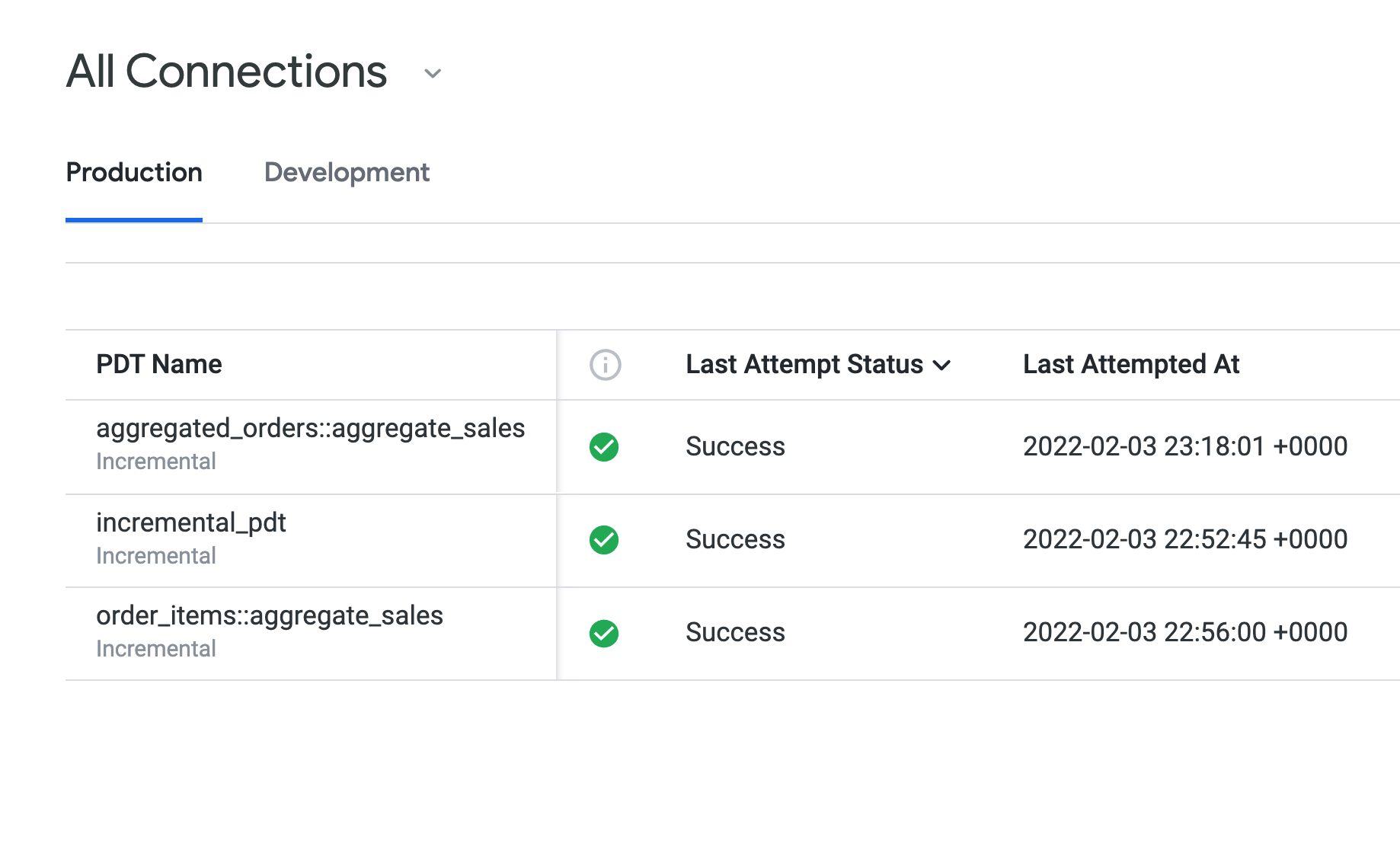
La colonne État de la dernière tentative affiche Success (opération réussie) pour toutes les PDT. Elles utilisent toutes la même règle de persistance (daily_datagroup). Concernant la durée de compilation, sous "Durée de la dernière compilation", la table incremental_pdt présente probablement une durée de compilation légèrement plus longue que les deux tables agrégées.
Laissez la page Tables dérivées persistantes ouverte pendant que vous passez aux étapes suivantes.
Modifier et examiner les tables PDT en développement
-
Revenez à l'onglet de navigateur contenant l'IDE Looker.
-
Ouvrez training_ecommerce.model.
-
Ajoutez une dimension pour users.country à l'exploration aggregated_orders (vers la ligne 96) :
dimensions: [aggregated_orders.created_date, users.state, users.country]
-
Cliquez sur Enregistrer les modifications.
-
Revenez à la page Tables dérivées persistantes et actualisez-la.
Dans l'onglet "Production", la table PDT aggregated_orders::aggregate_sales est toujours indiquée comme étant compilée, même si vous avez modifié le code LookML de la table PDT en mode Développement.
Looker permet aux développeurs de tester les modifications apportées aux tables PDT en mode Développement, de la même manière que pour d'autres objets Looker en mode Développement. Par exemple, lorsque les développeurs créent des dimensions et des mesures en mode Développement, ces nouveaux objets n'apparaissent pas en production tant que le développeur n'a pas validé les modifications et ne les a pas déployées en production.
- Ouvrez l'onglet Développement.
-
Laissez la page Tables dérivées persistantes ouverte et ouvrez une nouvelle fenêtre Looker dans un nouvel onglet du navigateur.
-
Accédez à Exploration > Aggregate Sales.
-
Dans le volet "Données", ouvrez l'onglet SQL.
-
Sous Users > Dimensions, sélectionnez Country.
-
Sous Aggregated Orders > Mesures, sélectionnez :
- Average Sale Price
- Total Revenue
L'onglet "SQL" contient deux requêtes : la première génère la table PDT, et la seconde récupère les résultats de la table PDT nouvellement créée.
-
Cliquez sur Exécuter.
-
Ouvrez l'onglet "Résultats" pour afficher les résultats.
-
Fermez l'onglet du navigateur contenant la requête d'exploration, revenez à l'onglet du navigateur contenant la page Tables dérivées persistantes, puis actualisez la page.
L'onglet "Développement" indique désormais que la table aggregated_orders::aggregate_sales a été correctement compilée.
-
Laissez l'onglet de navigateur contenant la page "Tables dérivées persistantes" ouvert et revenez à l'onglet du navigateur contenant l'IDE Looker.
-
Cliquez sur Valider le code LookML.
Aucune erreur de code LookML n'a été détectée.
Valider les modifications et les déployer en production
-
Cliquez sur Valider le LookML, puis sur Valider les modifications et envoyer.
-
Ajoutez un message de commit, puis cliquez sur Valider.
-
Enfin, cliquez sur Déployer en production.
Revenez à l'onglet de navigateur contenant la page "Tables dérivées persistantes" et actualisez la page. Maintenant que les modifications ont été déployées en production, la PDT aggregated_orders::aggregate_sales ne figure plus dans l'onglet "Développement", mais uniquement dans l'onglet "Production".
Félicitations !
Dans cet atelier, vous avez appris quand et comment ajouter la persistance et des mises à jour incrémentales aux tables dérivées, utiliser la reconnaissance des agrégats, joindre des vues de manière efficace et surveiller les compilations de PDT pour optimiser les requêtes Looker.
Étapes suivantes et informations supplémentaires
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 23 avril 2024
Dernier test de l'atelier : 6 octobre 2023
Copyright 2026 Google LLC. Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.





