GSP985

Descripción general
Looker es una plataforma de datos moderna en Google Cloud que puedes usar para analizar y visualizar tus datos de forma interactiva. Puedes usarla para analizar datos en profundidad, integrar estadísticas de diferentes fuentes de datos, crear flujos de trabajo prácticos basados en datos y crear aplicaciones de datos personalizadas.
Las consultas complejas pueden ser costosas, y ejecutarlas repetidamente sobrecarga tu base de datos, lo que reduce el rendimiento. Lo ideal es evitar volver a ejecutar consultas masivas si no cambió nada y, en su lugar, agregar datos nuevos a los resultados existentes para reducir las solicitudes repetitivas. Aunque hay muchas formas de optimizar el rendimiento de las consultas de LookML, este lab se enfoca en los métodos más utilizados para optimizar el rendimiento de las consultas en Looker: tablas derivadas persistentes, reconocimiento de agregaciones y uniones de vistas de forma eficiente.
Actividades
- Comprender cuándo y cómo agregar persistencia y actualizaciones incrementales a las tablas derivadas
- Usar el reconocimiento de agregaciones para optimizar las consultas sobre datos integrados o resumidos
- Crear un refinamiento de una exploración existente
- Unir vistas de manera eficaz para optimizar las consultas de exploración
- Supervisar las compilaciones de tablas derivadas persistentes en una instancia de Looker
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs son cronometrados y no se pueden pausar. El temporizador, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome)
Nota: Usa una ventana de navegador privada o de incógnito para ejecutar el lab. Así evitarás conflictos entre tu cuenta personal y la cuenta de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
- Tiempo para completar el lab (recuerda que, una vez que comienzas un lab, no puedes pausarlo).
Nota: Si ya tienes un proyecto o una cuenta personal de Google Cloud, no los uses en este lab para evitar cargos adicionales en tu cuenta.
Cómo iniciar tu lab y acceder a Looker
-
Cuando tengas todo listo, haz clic en Comenzar lab.
Aparecerá el panel Detalles del lab con las credenciales temporales que debes usar para este lab.
Si debes pagar por el lab, se abrirá una ventana emergente para que selecciones tu forma de pago.
Observa tus credenciales del lab en el panel Detalles del lab. Las usarás para acceder a la instancia de Looker de este lab.
Nota: Si usas otras credenciales, recibirás errores o incurrirás en cargos.
-
Haz clic en Abrir Looker.
-
Ingresa el nombre de usuario y la contraseña que se proporcionaron en los campos Correo electrónico y Contraseña.
Nombre de usuario:
{{{looker.developer_username | Username}}}
Contraseña:
{{{looker.developer_password | Password}}}
Importante: Debes usar las credenciales del panel Detalles del lab en esta página. No uses tus credenciales de Google Cloud Skills Boost. Si tienes una cuenta personal de Looker, no la uses para este lab.
-
Haz clic en Acceder.
Después de acceder correctamente, verás la instancia de Looker para este lab.
Recomendaciones clave para optimizar el rendimiento de las consultas
En esta sección, aprenderás sobre los métodos que se usan comúnmente para optimizar el rendimiento de las consultas en Looker. En este lab, obtendrás experiencia práctica con los tres primeros métodos.
Tablas derivadas persistentes (PDT)
La primera solución son las tablas derivadas persistentes (PDT). Looker te permite escribir consultas en SQL y LookML en tu base de datos como una tabla temporal. Cuando esta tabla se almacena en caché o se conserva, se denomina PDT. Esto te permite ejecutar de forma repetida consultas complejas o de uso común y almacenar en caché los resultados para un acceso rápido.
Si guardas estas consultas como una tabla, tendrás control sobre cuándo o cómo se crean. Las tablas pueden reconstruirse cada mañana, una vez al mes o solo cuando se agreguen datos nuevos. Lo ideal es que configures tus tablas derivadas para que reflejen la naturaleza de tus datos.
Las tablas derivadas son útiles para crear nuevas estructuras o agregaciones que no están disponibles en tus tablas de bases de datos subyacentes, pero no todas las tablas derivadas deben persistir para ser útiles. La persistencia se aplica comúnmente a consultas complejas que son costosas de ejecutar o a consultas que una gran cantidad de usuarios o aplicaciones usan con frecuencia.
También puedes crear PDT incrementales para agregar datos nuevos sin volver a compilar toda la tabla. Aplicar cambios incrementales funciona bien para tablas grandes en las que los datos existentes (más antiguos) no se actualizan con frecuencia, ya que la actualización principal de la tabla son los registros nuevos.
Reconocimiento de agregaciones
Para tablas muy grandes en tu base de datos, el reconocimiento de agregaciones de Looker puede crear tablas de agregaciones más pequeñas de datos agrupados según varias combinaciones de atributos. Las tablas agregadas actúan como "integraciones" o tablas de resumen que Looker puede usar en lugar de la tabla grande original para las consultas siempre que sea posible. El reconocimiento de agregaciones permite que Looker encuentre la tabla más pequeña y eficiente disponible en tu base de datos para ejecutar una consulta sin perder la precisión. Cuando se implementa de forma estratégica, este reconocimiento puede acelerar una consulta típica en órdenes de magnitud. Piensa en una tabla de pedidos en línea para una tienda de comercio electrónico con mucho movimiento, en la que se agregan filas nuevas cada pocos segundos.
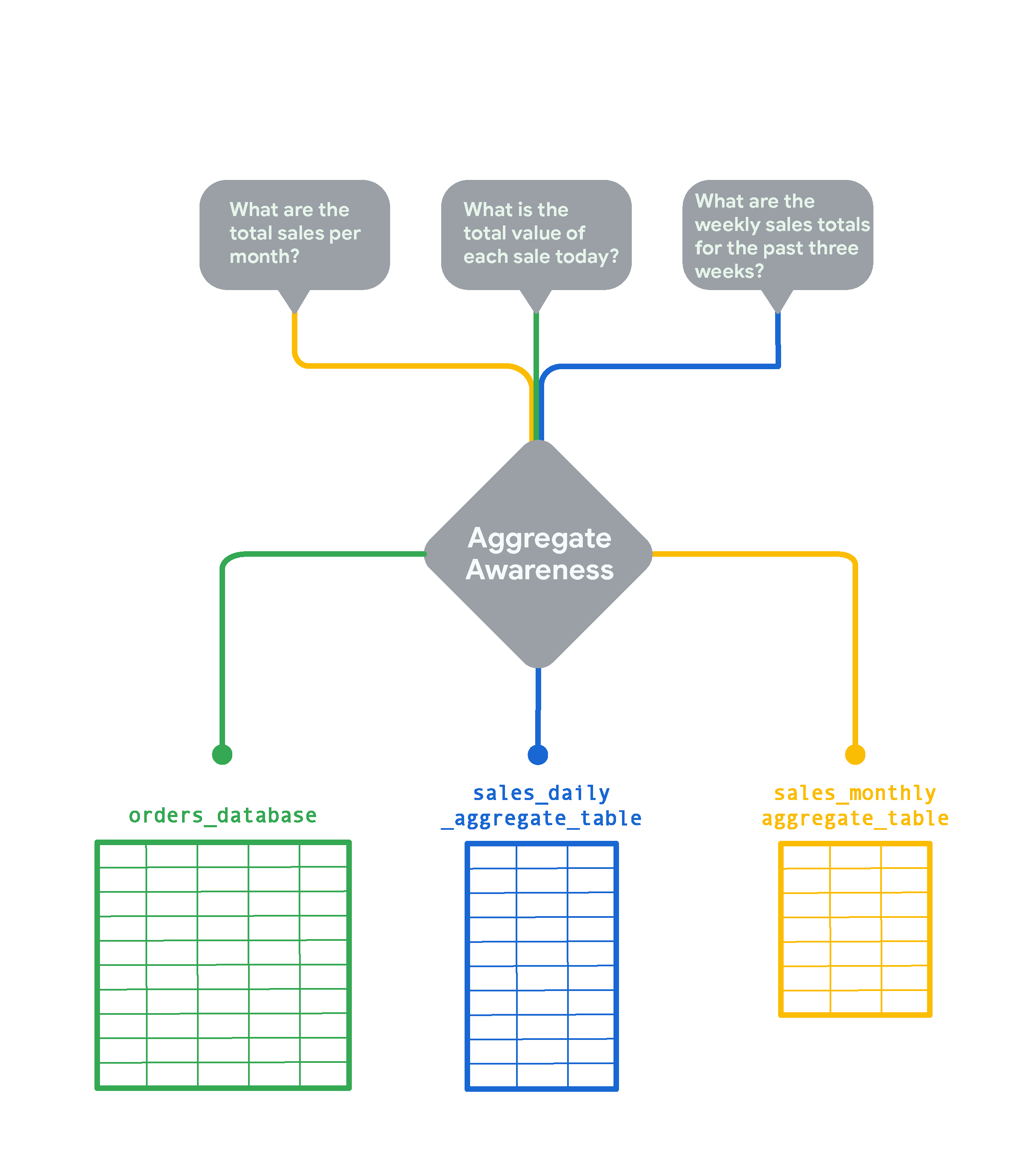
Si quieres hacer un seguimiento de los pedidos en tiempo real, se requiere una mayor cantidad de detalles, pero si quieres analizar tendencias mensuales como “Ventas totales por mes”, analizar un resumen mensual de los datos es mucho más rápido y rentable. En este caso, Looker crea y consulta la sales_monthly_aggregate_table.
Para una pregunta como “¿Cuál es el valor total de cada venta hoy?”, necesitas datos de pedidos detallados a nivel de fila. En este caso, Looker consultará la tabla original orders_database sin ninguna agregación. Si quieres ver los totales de ventas semanales de las últimas tres semanas, Looker creará y seleccionará una tabla de datos agregados de ventas diaria. Esta será más detallada que la tabla de ventas mensuales, pero será un resumen de la orders_database sin procesar.
El reconocimiento de agregaciones en Looker se usa comúnmente para integrar o resumir datos de varios períodos. Además, las tablas agregadas deben conservarse en una instancia de Looker para poder aprovecharlas con este tipo de reconocimiento.
Une vistas de manera eficaz
Otra forma de optimizar el rendimiento es unir solo las vistas que necesitas cuando defines una nueva exploración. Para minimizar las uniones, puedes definir varias exploraciones para diferentes propósitos (por ejemplo, consultar datos por usuario o consultar datos agregados de ventas). Además, debes usar campos base en lugar de campos concatenados como claves primarias. Cuando sea posible, usa uniones many_to_one: cuando se unen vistas desde el nivel de detalle más particular hasta el más general (many-to-one), se suele obtener el mejor rendimiento de las consultas en Looker.
Incluye filtros en las definiciones de la exploración
Incluir filtros en las definiciones de las exploraciones puede optimizar el rendimiento, ya que con eso se evita que se devuelva una gran cantidad de datos de forma predeterminada. Hay muchas opciones de filtro, incluidos filtros que son visibles y que los usuarios pueden modificar, como always_filter y conditionally_filter. También puedes modificar las sugerencias de filtros para los campos en una exploración. Para obtener más información y practicar con los filtros de exploraciones, prueba el lab Filtra exploraciones con LookML.
Implementa políticas de almacenamiento en caché
Para reducir el tráfico de las consultas de bases de datos, debes maximizar el almacenamiento en caché para sincronizarlo con tus políticas de extracción, transformación y carga (ETL) siempre que sea posible. De forma predeterminada, Looker almacena en caché las consultas durante una hora. Puedes controlar la política de almacenamiento en caché y sincronizar las actualizaciones de datos de Looker con tu proceso de ETL usando el parámetro persist_with para aplicar grupos de datos en las exploraciones. Esta opción permite que Looker se integre más estrechamente con la canalización de datos de backend para que el uso de la caché se pueda maximizar sin el riesgo de analizar datos obsoletos.
Por ejemplo, algunas tablas de datos podrían actualizarse solo una vez al día, por lo que actualizar la caché cada hora para esas tablas no agrega valor. En este lab, usarás varias opciones para personalizar el almacenamiento en caché en Looker, incluidos los grupos de datos o las políticas de almacenamiento en caché, para conservar las tablas derivadas. Para obtener más información y practicar con las políticas de almacenamiento en caché, prueba el lab Almacenamiento en caché y grupos de datos con LookML.
Optimización adicional de consultas
Según tu dialecto de base de datos, puedes explorar funciones adicionales de optimización de consultas, como indexes y cluster_keys.
Tarea 1: Crea una tabla derivada persistente incremental que se actualice automáticamente sin necesidad de volver a compilar toda la tabla
Como se describió anteriormente, las tablas derivadas persistentes (PDT) se escriben en un esquema temporal en tu base de datos y se regeneran según el programa que especifiques con una estrategia de persistencia. Las PDT son útiles porque, cuando el usuario solicita datos de la tabla, esta ya suele existir, lo que reduce el tiempo de consulta y la carga de la base de datos.
En una PDT estándar, la tabla completa se vuelve a crear según un programa establecido en su política de almacenamiento en caché. En cambio, las PDT que se crean incrementalmente agregarán datos recientes a una tabla existente. Esto puede reducir en gran medida el tamaño de la consulta que envías a la base de datos.
En esta tarea, crearás una tabla derivada nativa (NDT) para agregar datos de pedidos por período o estado. También habilitarás la persistencia con una actualización diaria y actualizaciones incrementales que se remontan 3 días para recuperar datos tardíos.
Usa una exploración para crear una tabla derivada nativa
-
Haz clic en el botón de activación para ingresar al Modo de desarrollo.
-
Navega a Exploración > Order Items.
-
En Order Items > Dimensiones, selecciona lo siguiente:
- Order ID
- Sale Price
-
Created Date > Date
-
Created Date > Week
-
Created Date > Month
-
En Users > Dimensiones, selecciona State.
-
Haz clic en Ejecutar.
-
Haz clic en Configuración ( ).
).
-
Selecciona Visualizar LookML.
-
En la pestaña Tabla derivada, copia el código de LookML en un editor de texto.
Usarás este código para crear una nueva vista para la tabla derivada nativa.
Crea un archivo de vista para una tabla derivada
-
Abre una nueva pestaña de Looker en el navegador.
-
En el menú Desarrollo, haz clic en qwiklabs_ecommerce.
-
Haz clic en el signo más (+) junto a Navegador de archivos y selecciona Crear vista.
-
Asígnale el nombre incremental_pdt al archivo nuevo y haz clic en Crear.
-
En el navegador de archivos, haz clic en incremental_pdt.view y arrástralo a la carpeta Vistas.
-
Reemplaza el código de LookML predeterminado en incremental_pdt.view por el que copiaste anteriormente para la tabla derivada nativa.
-
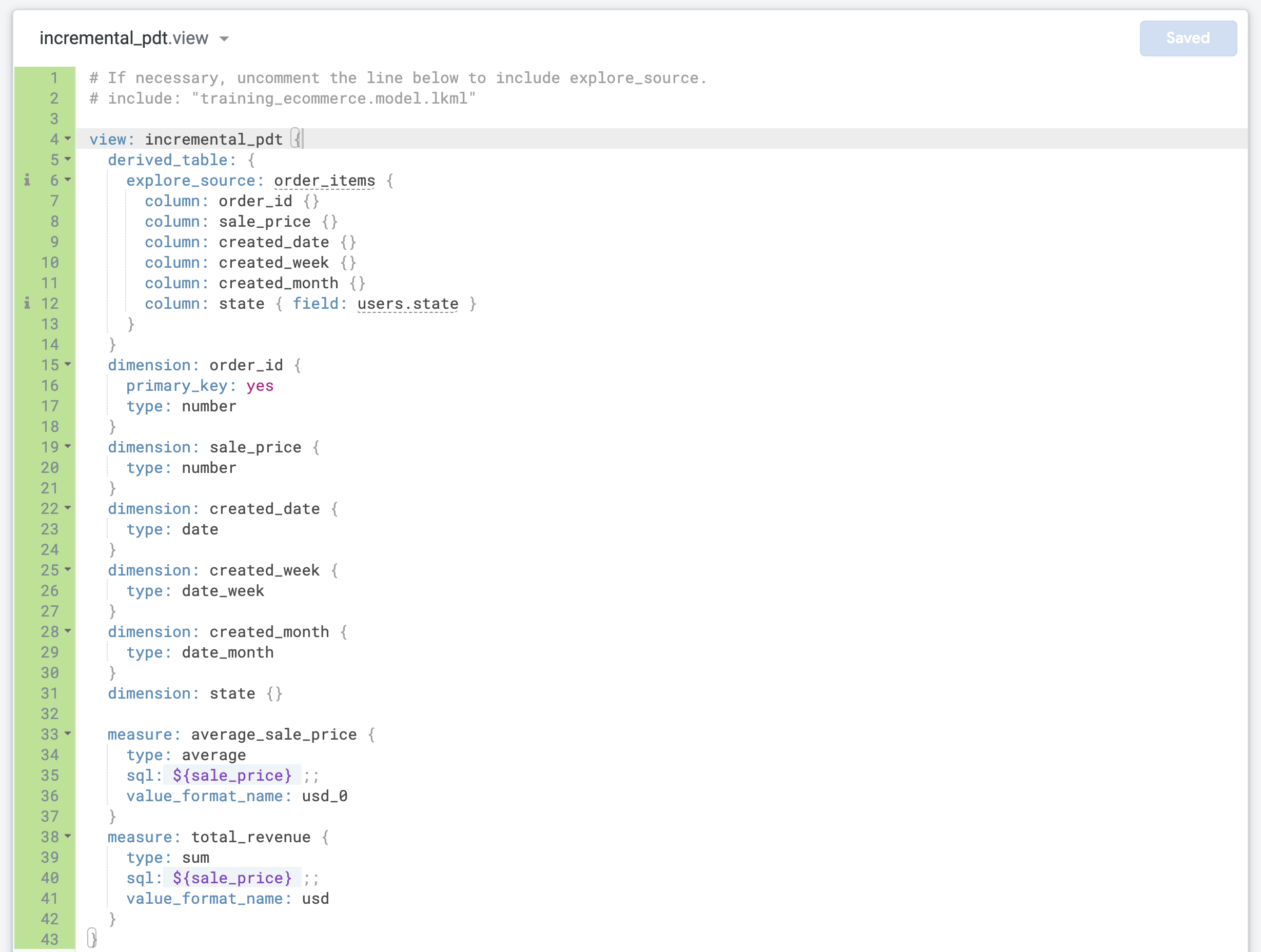
Actualiza la línea 4 con el nombre de vista correcto (incremental_pdt).
-
Actualiza la dimensión order_id para definirla como la primary_key de la vista:
dimension: order_id {
primary_key: yes
type: number
}
Esto se debe a que cada registro representa un pedido con un order_id único.
- Busca la última dimensión y agrega dos nuevas mediciones antes del corchete de cierre final (
}) en el archivo:
measure: average_sale_price {
type: average
sql: ${sale_price} ;;
value_format_name: usd_0
}
measure: total_revenue {
type: sum
sql: ${sale_price} ;;
value_format_name: usd
}
- Haz clic en Guardar cambios. Tu archivo debería ser similar al siguiente:
Agrega persistencia y actualizaciones incrementales a una tabla derivada
-
Abre training_ecommerce.model.
-
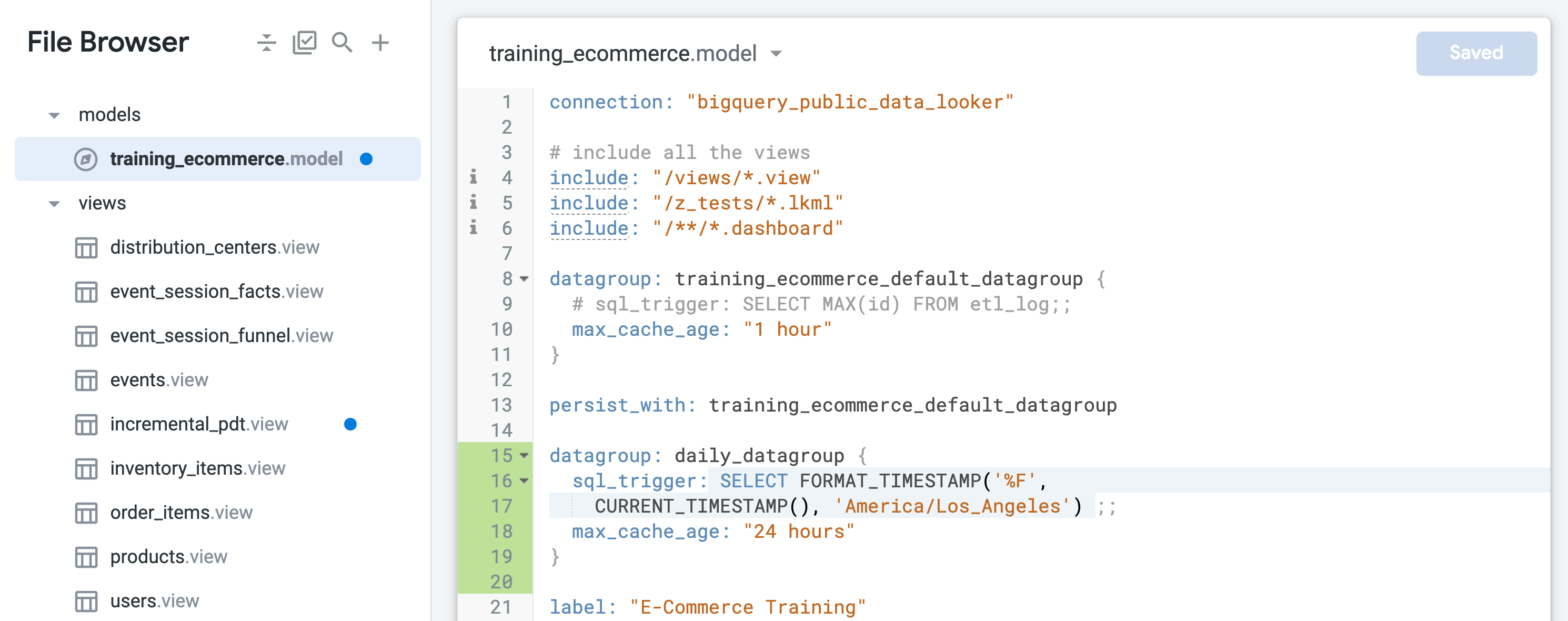
Busca el grupo de datos predeterminado llamado training_ecommerce_default_datagroup y agrega una nueva línea (línea 13).
-
Define un nuevo grupo de datos para conservar objetos con actualización diaria (tiempo máximo de 24 horas):
datagroup: daily_datagroup {
sql_trigger: SELECT FORMAT_TIMESTAMP('%F',
CURRENT_TIMESTAMP(), 'America/Los_Angeles') ;;
max_cache_age: "24 hours"
}
sql_trigger comprueba la fecha actual y activa una actualización cuando esta cambia, y max_cache_age garantiza que la tabla se volverá a compilar después de 24 horas, incluso si el sql_trigger no se ejecuta correctamente.
- Al final de
training_ecommerce.model (alrededor de la línea 67), define una nueva exploración que contenga solo la vista incremental_pdt para que puedas probarla en los pasos posteriores:
explore: incremental_pdt {}
- Haz clic en Guardar cambios.
- Abre incremental_pdt.view y agrega persistencia incluyendo el grupo de datos daily en la definición de la tabla derivada en la línea 6:
datagroup_trigger: daily_datagroup
- Agrega actualizaciones incrementales incluyendo los siguientes parámetros en la definición de la tabla derivada en las líneas 7 y 8:
increment_key: "created_date"
increment_offset: 3
- Haz clic en Guardar cambios. Tu archivo debería ser similar al siguiente:
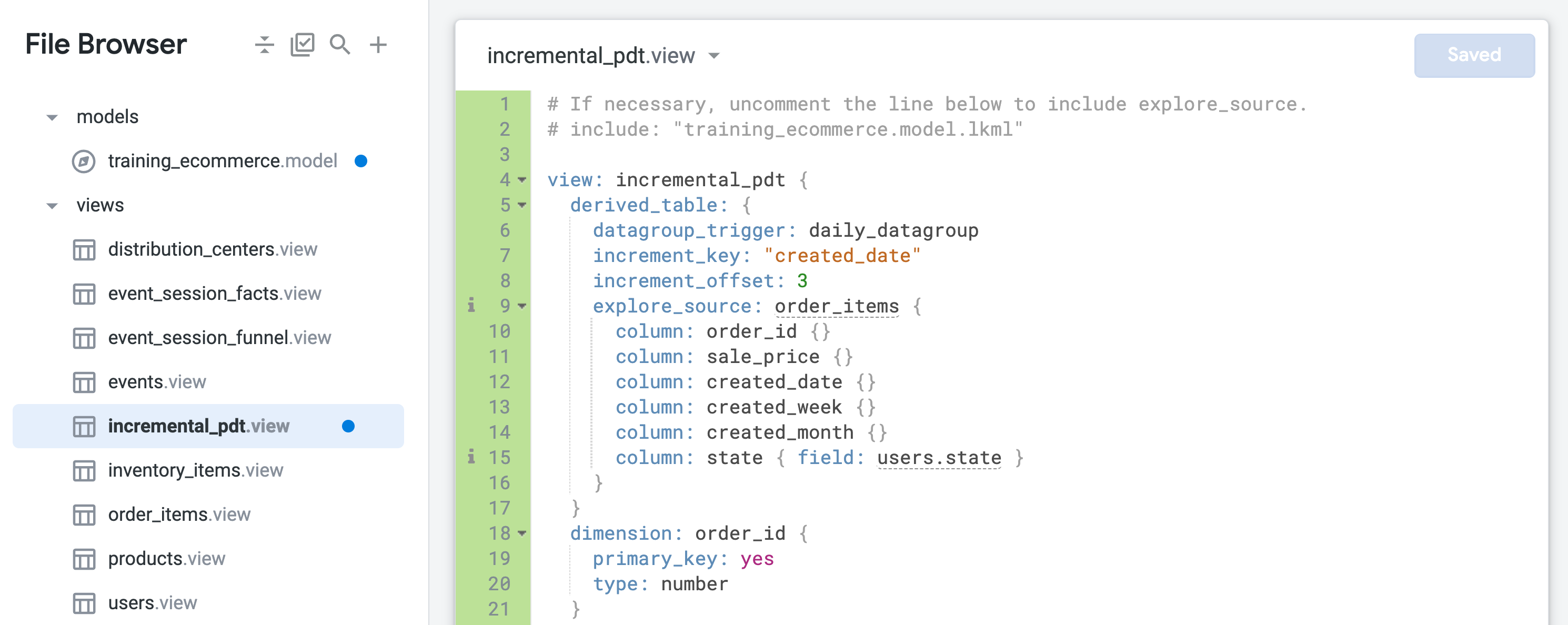
La tabla derivada persistente ahora se conservará y se volverá a crear una vez al día, retrocediendo 3 días para capturar cualquier pedido que pueda haber llegado tarde.
- Cierra la pestaña del navegador para la consulta de exploración original, pero deja abierta la pestaña del IDE de Looker.
Prueba consultas de exploración en una tabla derivada persistente incremental
-
Abre una nueva pestaña de Looker en el navegador.
-
Navega a Exploración > PDT incremental.
-
En el panel Datos, abre la pestaña SQL.
-
En PDT incremental > Dimensiones, selecciona Created Date.
-
En PDT incremental > Mediciones, selecciona Average Sale Price y Total Revenue.
Antes de ejecutar la consulta, observa que hay dos consultas en la ventana de SQL (que pueden tardar unos segundos en cargarse). La primera consulta genera la PDT llamada incremental_pdt, y la segunda recupera los resultados de la PDT recién creada.
-
Haz clic en Ejecutar.
-
Abre la pestaña Resultados para ver los resultados.
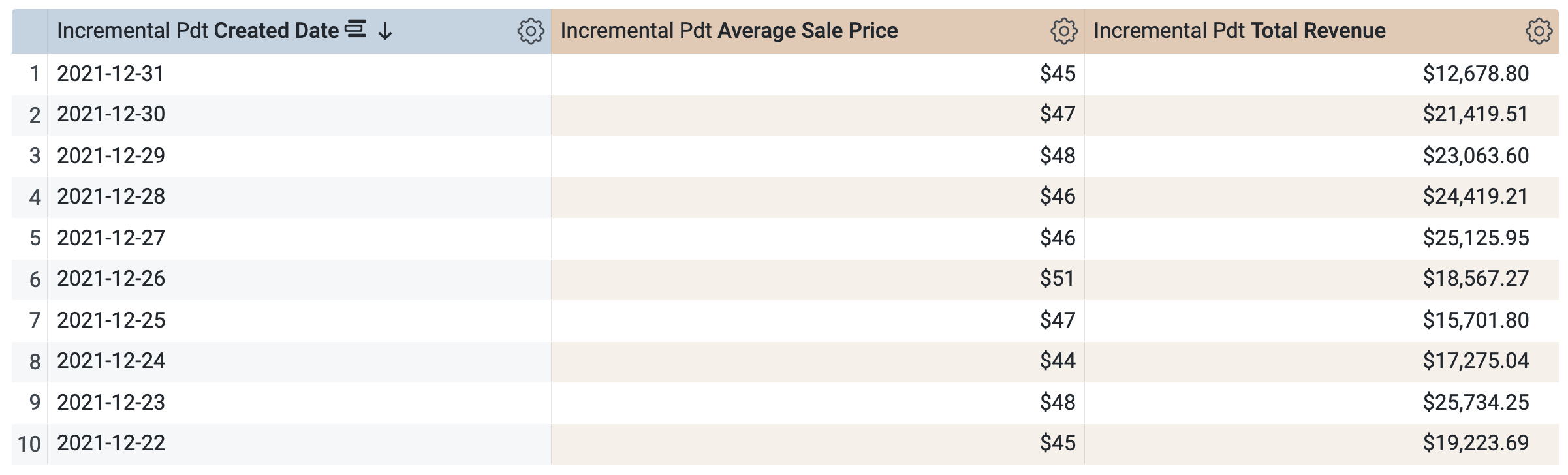
-
En PDT incremental > Dimensiones:
-
Borra Created Date.
- Selecciona Created Month.
-
En el panel Datos, abre la pestaña SQL.
Ten en cuenta que la consulta usará la misma PDT para recuperar los resultados, lo que tiene sentido porque solicitaste un período que ya está definido (y almacenado en caché) en la PDT. Sin embargo, ten en cuenta que no puedes seleccionar y ejecutar una consulta en un período diferente que no esté incluido en la PDT, como Trimestre o Año.
-
Haz clic en Ejecutar.
-
Abre la pestaña Resultados para ver los resultados.
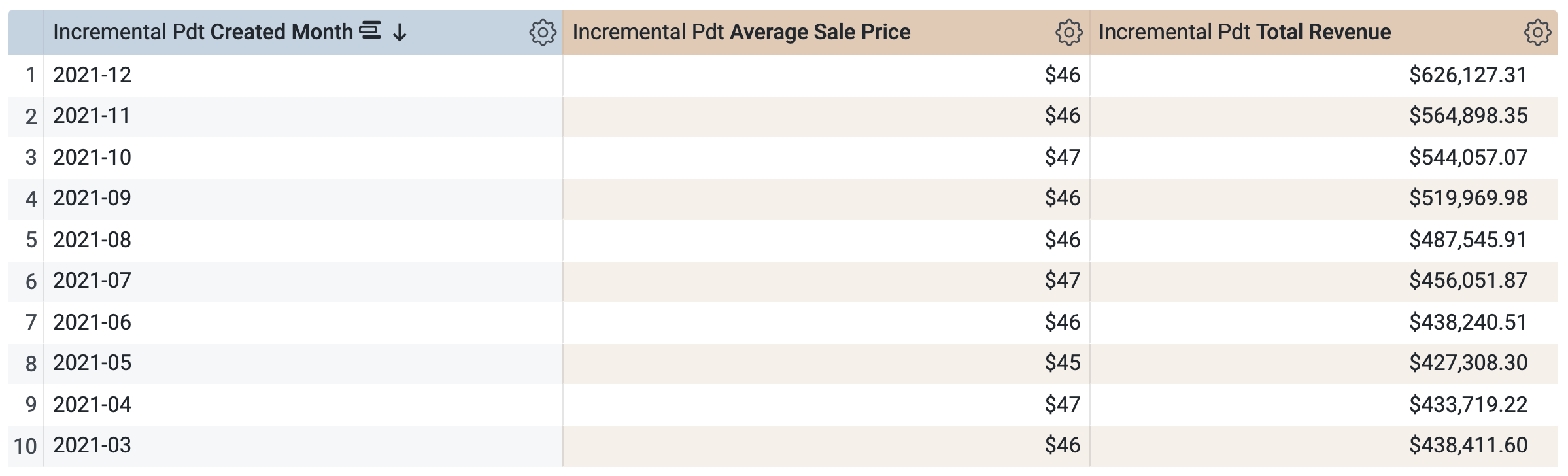
Desafío
- Ejecuta una nueva consulta usando solo la dimensión State y las mediciones Average Sale Price y Total Revenue. Responde la siguiente pregunta.
-
Cierra la pestaña del navegador de la consulta de exploración y vuelve a la pestaña con el IDE de Looker.
-
Haz clic en Validar LookML.
No debería haber errores de LookML.
Confirma los cambios y realiza la implementación en producción
-
Haz clic en Validar LookML y, luego, en Commit Changes & Push.
-
Agrega un mensaje de confirmación y haz clic en Confirmar.
-
Por último, haz clic en Implementar en producción.
Permanece en la pestaña del navegador del IDE de Looker mientras comienzas la siguiente tarea.
Haz clic en Revisar mi progreso para verificar el objetivo.
Crear una tabla derivada persistente incremental
Tarea 2: Crea una tabla de datos agregados incremental para resumir los datos de los pedidos en varios períodos
En Looker, puedes crear tablas agregadas estratégicas que minimicen la cantidad de consultas necesarias en las tablas grandes de una base de datos. Las tablas agregadas deben conservarse en tu base de datos para que puedan ser accesibles para el reconocimiento de agregaciones. Por lo tanto, las tablas agregadas son un tipo de tabla derivada persistente (PDT).
Una tabla de datos agregados se define con el parámetro aggregate_table en un parámetro de exploración de tu proyecto de LookML. Después de crear tus tablas de datos agregados, puedes ejecutar consultas en la exploración para ver cuáles de esas tablas son las que usa Looker. Looker utiliza la lógica de reconocimiento de agregaciones para encontrar la tabla de datos agregados más pequeña y eficiente disponible en tu base de datos para ejecutar una consulta y, al mismo tiempo, mantener la exactitud.
En esta tarea, volverás a crear la PDT incremental de la tarea anterior como una nueva tabla de datos agregados incremental. También pondrás la nueva tabla conjunta a disposición de los usuarios con un refinamiento de la exploración existente de artículos de pedidos.
Crea una tabla conjunta en un refinamiento de una exploración existente
-
En la página del IDE de Looker, abre training_ecommerce.model.
-
Al final del archivo (alrededor de la línea 69), agrega el siguiente código para crear un refinamiento de la exploración order_items:
explore: +order_items {
label: "Order Items - Aggregate Sales"
}
Este refinamiento se basa en la exploración order_items existente definida en el archivo del modelo y agrega las modificaciones especificadas en el nuevo código de LookML, como la etiqueta o la tabla conjunta que incluirás en los próximos pasos.
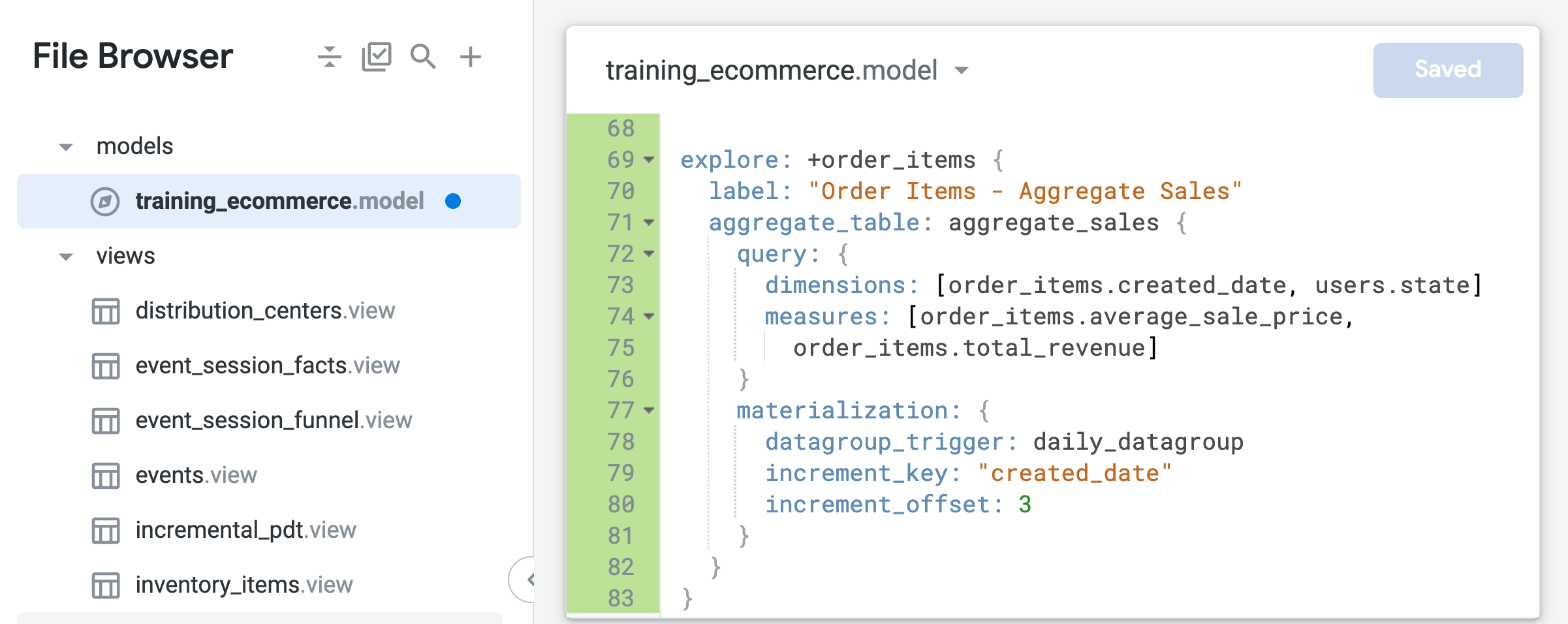
- Expande el código de LookML para el refinamiento de modo que incluya una tabla conjunta que resuma los datos de los pedidos por período o estado:
explore: +order_items {
label: "Order Items - Aggregate Sales"
aggregate_table: aggregate_sales {
query: {
dimensions: [order_items.created_date, users.state]
measures: [order_items.average_sale_price,
order_items.total_revenue]
}
materialization: {
datagroup_trigger: daily_datagroup
increment_key: "created_date"
increment_offset: 3
}
}
}
Ten en cuenta que, a diferencia de la tabla derivada nativa que creaste en la tarea anterior, la única dimensión de tiempo especificada en la tabla de datos agregados es created_date. Con el reconocimiento de agregaciones, Looker puede aprovechar esta tabla única para las consultas de la exploración que solicitan el precio de venta promedio o los ingresos totales agregados por tiempo, independientemente del período que se solicite (día, mes o año).
- Haz clic en Guardar cambios.
Deja esta pestaña abierta para el IDE de Looker.
Prueba consultas de Exploración en una tabla de datos agregados incremental persistente
-
Abre una nueva pestaña de Looker en el navegador.
-
Navega a Exploración > Order Items - Aggregate Sales.
-
En el panel Datos, abre la pestaña SQL.
-
En Order Items > Dimensiones, selecciona Created Date > Date.
-
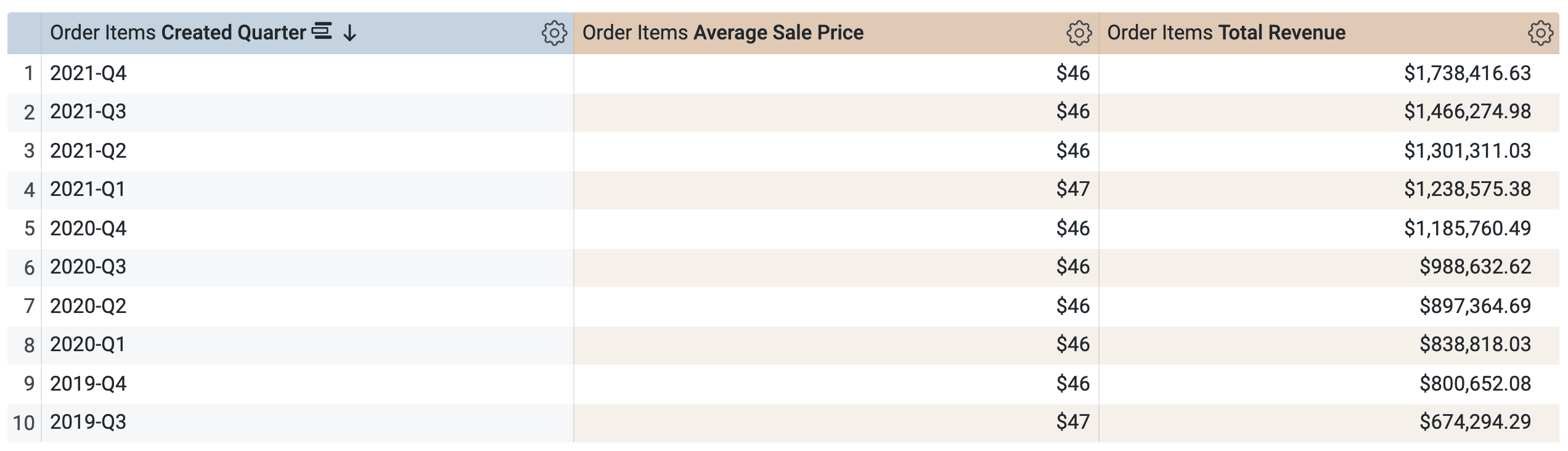
En Order Items > Mediciones, selecciona Average Sale Price y Total Revenue.
Antes de ejecutar la consulta, observa que hay dos consultas, similares a la ventana de SQL en la tarea 1. La primera consulta genera la PDT llamada aggregate_sales y, la segunda, recupera los resultados de esta nueva PDT.
-
Haz clic en Ejecutar.
-
Abre la pestaña Resultados para ver los resultados.
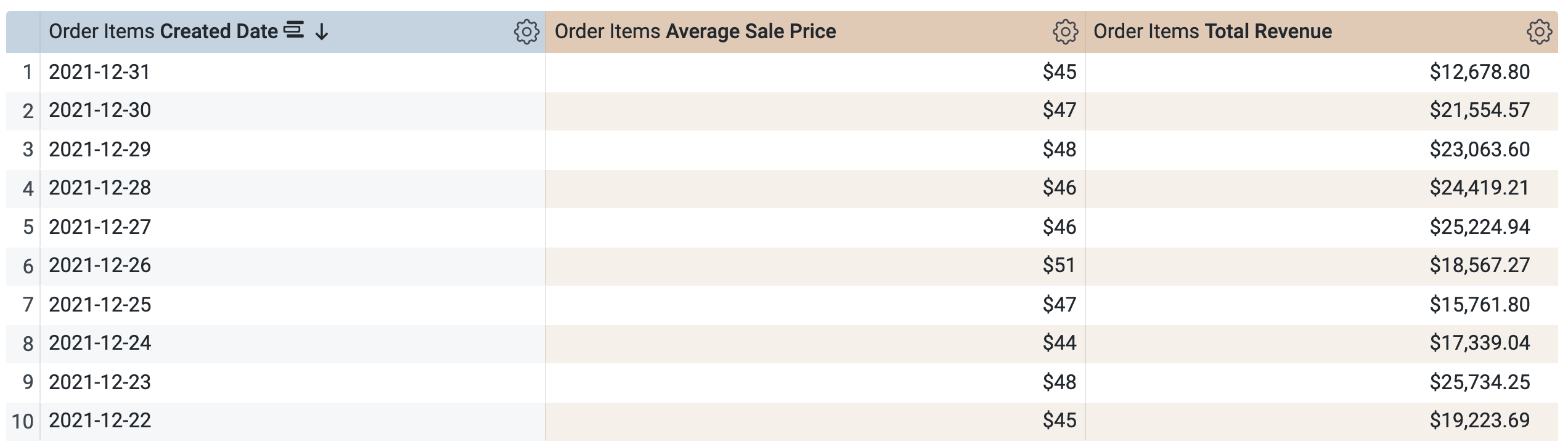
-
En Order Items > Dimensiones > Created Date:
-
Borra Fecha.
- Selecciona Trimestre.
-
En el panel Datos, abre la pestaña SQL.
Ten en cuenta que la consulta usará la misma PDT (aggregate_sales) para recuperar los resultados por trimestre. Looker aplica el reconocimiento de agregaciones para acumular el precio de venta promedio y los ingresos totales en los períodos solicitados disponibles en Created Date.
-
Haz clic en Ejecutar.
-
Abre la pestaña Resultados para ver los resultados.
Desafío
- Ejecuta una nueva consulta usando solo la dimensión State (en Users) y las mediciones Average Sale Price y Total Revenue. Responde la siguiente pregunta.
- Ejecuta una nueva consulta usando solo la dimensión Country (en Users) y las mediciones Average Sales Price y Total Revenue. Responde la siguiente pregunta.
-
Cierra la pestaña del navegador de la consulta de exploración y vuelve a la pestaña con el IDE de Looker.
-
Haz clic en Validar LookML. No debería haber errores de LookML.
Confirma los cambios y realiza la implementación en producción
-
Haz clic en Validar LookML y, luego, en Commit Changes & Push.
-
Agrega un mensaje de confirmación y haz clic en Confirmar.
-
Por último, haz clic en Implementar en producción.
Permanece en la pestaña del navegador del IDE de Looker mientras comienzas la siguiente tarea.
Haz clic en Revisar mi progreso para verificar el objetivo.
Crear una tabla de datos agregados
Tarea 3: Une vistas de manera eficaz para optimizar las consultas de exploración
Las uniones eficientes son componentes clave para definir exploraciones de alto rendimiento en Looker. Para mejorar la eficiencia de las uniones, asegúrate de unir solo las vistas que se necesitan para definir la exploración, usar campos base (en lugar de campos concatenados) como claves primarias para las vistas y utilizar uniones many_to_one siempre que sea posible.
Como se describe en la documentación, las claves primarias proporcionan un identificador único para los registros en una vista y son esenciales para establecer agregaciones y relaciones precisas en Looker. La clave primaria de una vista es un campo que contiene valores únicos (como una columna de ID) y se identifica en el archivo de la vista con el parámetro primary_key: yes.
En esta sección, primero identificarás la columna más adecuada para usar una clave primaria para una vista. Luego, definirás una nueva exploración para la tabla de datos agregados con solo la vista de usuarios unida, usarás el parámetro from para especificar order_items como la vista base de la exploración y, luego, unirás la vista de usuarios. Por último, omitirás las uniones adicionales que se incluyen en la exploración existente de Order Items y usarás la relación de unión many_to_one para respaldar la eficiencia de las consultas.
Identifica el campo más adecuado para usar como clave primaria de una vista
- Abre el archivo users.view. Responde la siguiente pregunta.
En users.view, la columna ID ya se identificó como la clave primaria, con primary_key: yes. Es un campo base que contiene valores únicos (un ID para cada usuario), y no un campo concatenado creado a partir de varias columnas. Por lo tanto, ID es la mejor opción para la clave primaria de la vista de usuarios y puede admitir uniones eficientes.
- Abre el archivo order_items.view. Responde la siguiente pregunta.
order_item_id se basa en la columna ID de la tabla order_items y se identifica como la clave primaria. Sin embargo, otros campos de ID en esta vista podrían ser la clave única de la tabla, incluido order_id, que se basa en la columna order_id de la tabla order_items.
En los próximos pasos, explorarás la tabla order_items en el Ejecutor de SQL para identificar por qué order_item_id es el mejor campo para usar como primary_key.
-
Abre una nueva pestaña de Looker en el navegador.
-
Navega a Desarrollo > Ejecutor de SQL.
-
Haz clic en Configuración () junto a Connection y selecciona Search public projects.
-
El cuadro de Proyecto ahora estará vacío. Escribe cloud-training-demos y presiona INTRO.
-
En Conjunto de datos, selecciona looker_ecomm.
Se muestra una lista de las tablas disponibles en este conjunto de datos de BigQuery.
Un método rápido y sencillo para comprobar si una columna es una clave primaria adecuada es comparar el recuento de registros en la tabla con el recuento de valores únicos en la columna. Si los dos recuentos coinciden, la columna contiene valores únicos y es una clave primaria adecuada para la tabla.
- Para verificar si la columna
user_id sería una clave primaria adecuada, agrega la siguiente consulta a la ventana Consulta en SQL y haz clic en Ejecutar:
SELECT count(*), count(distinct user_id)
FROM cloud-training-demos.looker_ecomm.order_items
- Repite la consulta para las columnas
order_id, inventory_item_id y id.
En este caso, tanto id como inventory_item_id coincidieron con el recuento de registros en la tabla porque son IDs diferentes para el mismo artículo dentro de un pedido. Por lo tanto, cualquiera de ellas podría usarse como clave primaria.
La columna id se eligió como clave primaria para order_items porque es el ID generado para un artículo en la tabla order_items, pero inventory_item_id es el ID del mismo artículo en la tabla inventory_items.
- Cierra la pestaña del navegador del Ejecutor de SQL y regresa a la pestaña con el IDE de Looker.
Une la cantidad mínima de vistas para definir nuevas exploraciones
-
Abre training_ecommerce.model.
-
Revisa la exploración order_items existente.
Observa que incluye cuatro uniones diferentes que usan el tipo de relación many_to_one. Según tu caso de uso, es posible que necesites todas estas uniones. Sin embargo, ¿qué sucede si solo necesitas los datos de usuarios y pedidos agrupados por estado o período? Si es así, estas uniones adicionales nunca se usarían y ralentizarían las consultas en la exploración.
En los próximos pasos, crearás una nueva exploración que unirá solo los datos de pedidos y usuarios, en función de user_id en la vista order_items y id en la vista users.
- Al final del archivo (alrededor de la línea 85), agrega el siguiente código para definir una nueva exploración con
order_items como la vista base y solo la vista users unida:
explore: aggregated_orders {
from: order_items
label: "Aggregated Sales"
join: users {
type: left_outer
sql_on: ${aggregated_orders.user_id} = ${users.id} ;;
relationship: one_to_many
}
aggregate_table: aggregate_sales {
query: {
dimensions: [aggregated_orders.created_date,
users.state]
measures: [aggregated_orders.average_sale_price,
aggregated_orders.total_revenue]
}
materialization: {
datagroup_trigger: daily_datagroup
increment_key: "created_date"
increment_offset: 3
}
}
}
- Haz clic en Guardar cambios.
Tu archivo debería ser similar al siguiente:
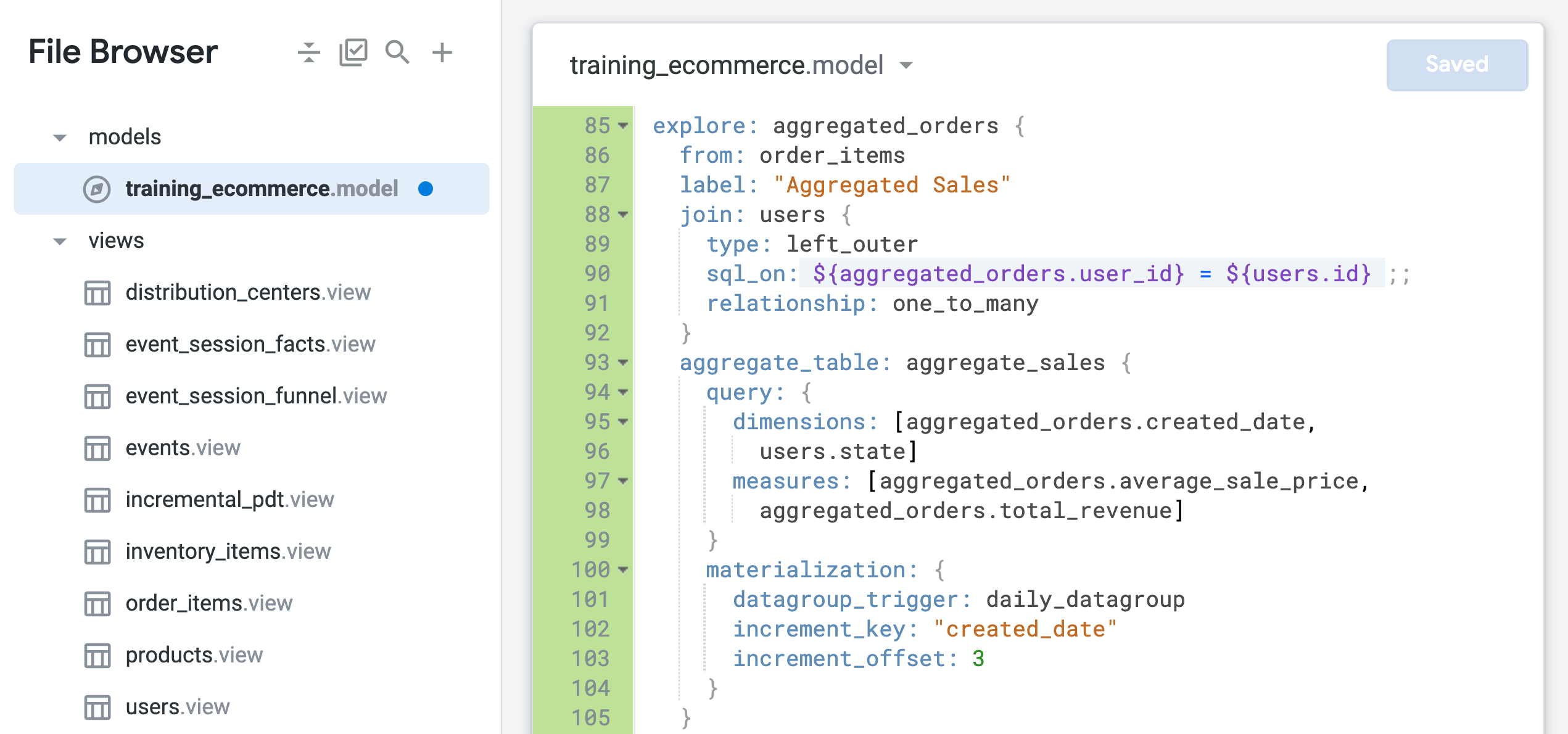
El parámetro from se usa para especificar order_items como la vista base de la exploración, a la que se une la vista de usuarios. Los campos de la vista order_items ahora se identifican con el nuevo nombre de la exploración como aggregated_orders.fieldname.
Observa también que la relación entre las vistas users y order_items se identifica actualmente como one_to_many. En los próximos pasos, probarás si esta unión basada en una relación one_to_many es la configuración óptima para esta exploración.
Define relaciones de unión de alto rendimiento para realizar consultas de exploración eficientes
-
Abre una nueva pestaña de Looker en el navegador.
-
Navega a Exploración > Aggregated Sales.
-
En el panel Datos, abre la pestaña SQL.
-
En Aggregated Orders > Dimensiones, selecciona Created Date > Fecha.
-
En Aggregated Orders > Mediciones, selecciona lo siguiente:
- Average Sale Price
- Total Revenue
Antes de ejecutar la consulta, observa que la tabla de datos agregados no se usa debido a un problema con el fanout de la unión:
-- Did not use aggregated_orders::aggregate_sales; field aggregated_orders.average_sale_price was DISTINCT in the table due to a join fanout, but there was no fanout in the query
Un fanout no intencional puede ocurrir cuando la relación entre dos tablas no se identifica correctamente para una unión. En este caso, la vista base de la exploración es order_items, que puede contener muchos pedidos para un usuario. Sin embargo, la vista users contiene solo un registro por usuario.
Por lo tanto, esta unión debería definirse como many_to_one, o varios pedidos para un usuario, en lugar de un pedido para varios usuarios (obtén más información sobre el problema de fanouts en el Centro de ayuda de Looker).
-
Haz clic en Ejecutar.
-
Abre la pestaña Resultados.
Se devuelven los resultados, pero Looker no usó la tabla de datos agregados eficiente para recuperarlos.
-
Deja abierta esta pestaña del navegador de la exploración y vuelve a la pestaña con el IDE de Looker.
-
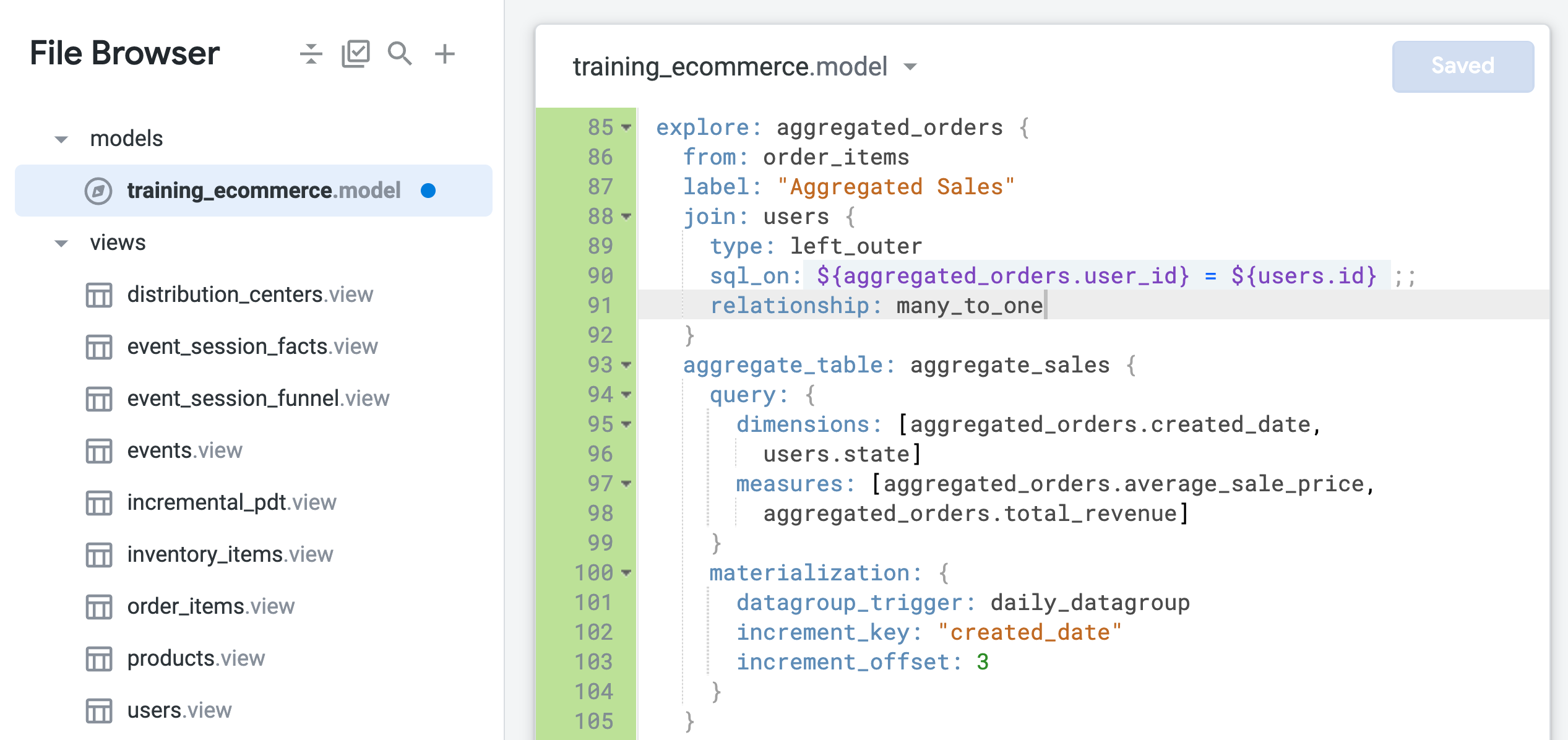
Actualiza el parámetro de relación a many_to_one (línea 91) en la exploración aggregated_orders:
relationship: many_to_one
- Haz clic en Guardar cambios.
Tu archivo debería ser similar al siguiente:
-
Vuelve a la pestaña del navegador de la consulta de exploración y actualiza la página.
-
En el panel Datos, abre la pestaña SQL.
De manera similar a la pestaña SQL de las tareas 1 y 2, ahora hay dos consultas: la primera para generar la PDT y la segunda para recuperar resultados de la PDT.
- Abre la pestaña Resultados para ver los resultados.
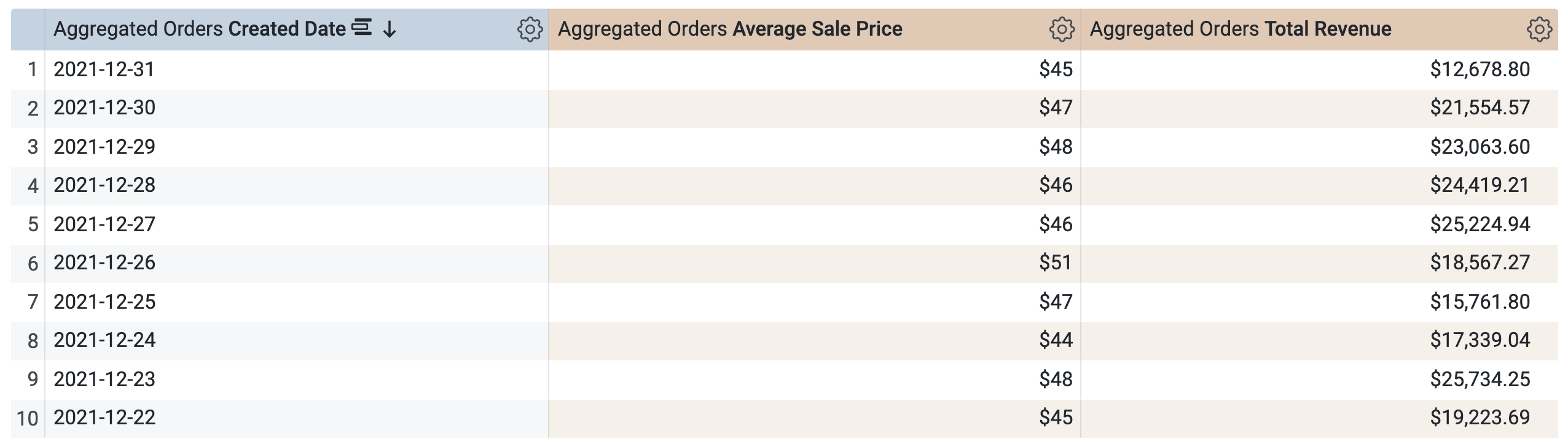
-
Cierra la pestaña del navegador de la consulta de exploración y vuelve a la pestaña con el IDE de Looker.
-
Haz clic en Validar LookML.
No debería haber errores de LookML.
Confirma los cambios y realiza la implementación en producción
-
Haz clic en Validar LookML y, luego, en Commit Changes & Push.
-
Agrega un mensaje de confirmación y haz clic en Confirmar.
-
Por último, haz clic en Implementar en producción.
Permanece en la pestaña del navegador del IDE de Looker mientras comienzas la siguiente tarea.
Haz clic en Revisar mi progreso para verificar el objetivo.
Unir la cantidad mínima de vistas para definir nuevas exploraciones
Tarea 4: Supervisa las compilaciones de tablas derivadas persistentes en una instancia de Looker
Looker ofrece la posibilidad de supervisar las compilaciones de PDT en una instancia de Looker a través de la página Tablas derivadas persistentes del menú Administrador. Según la configuración de Looker, los usuarios de Looker con privilegios para conservar tablas pueden ver esta página incluso sin acceso al menú Administrador completo. Puedes verificar el estado, los tiempos de compilación y el almacenamiento en caché de las PDT en tus entornos de desarrollo y producción para probarlas y supervisarlas fácilmente en tu instancia de Looker.
En esta tarea, supervisarás las PDT creadas en este lab con respecto al estado, el tiempo de compilación, el almacenamiento en caché y la producción en comparación con el desarrollo. La PDT incremental creada a partir de la NDT (tarea 1) debería tener el tiempo de compilación más largo, y las tablas agregadas (tareas 2 y 3) deberían tener los tiempos más cortos. Esto se debe a que usan la misma definición de tabla, pero se incluyen en exploraciones configuradas de manera diferente. También modificarás una PDT en desarrollo y supervisarás su estado antes y después de enviarla a producción.
Revisa el estado de las PDT en producción
-
Abre una nueva pestaña de Looker en el navegador.
-
Navega a Administrador > Tablas derivadas persistentes.
No se enumeran PDT en la pestaña Desarrollo porque todas las tuyas se enviaron a producción.
-
Abre la pestaña Producción para ver las PDT que creaste en las tareas 1 a 3.
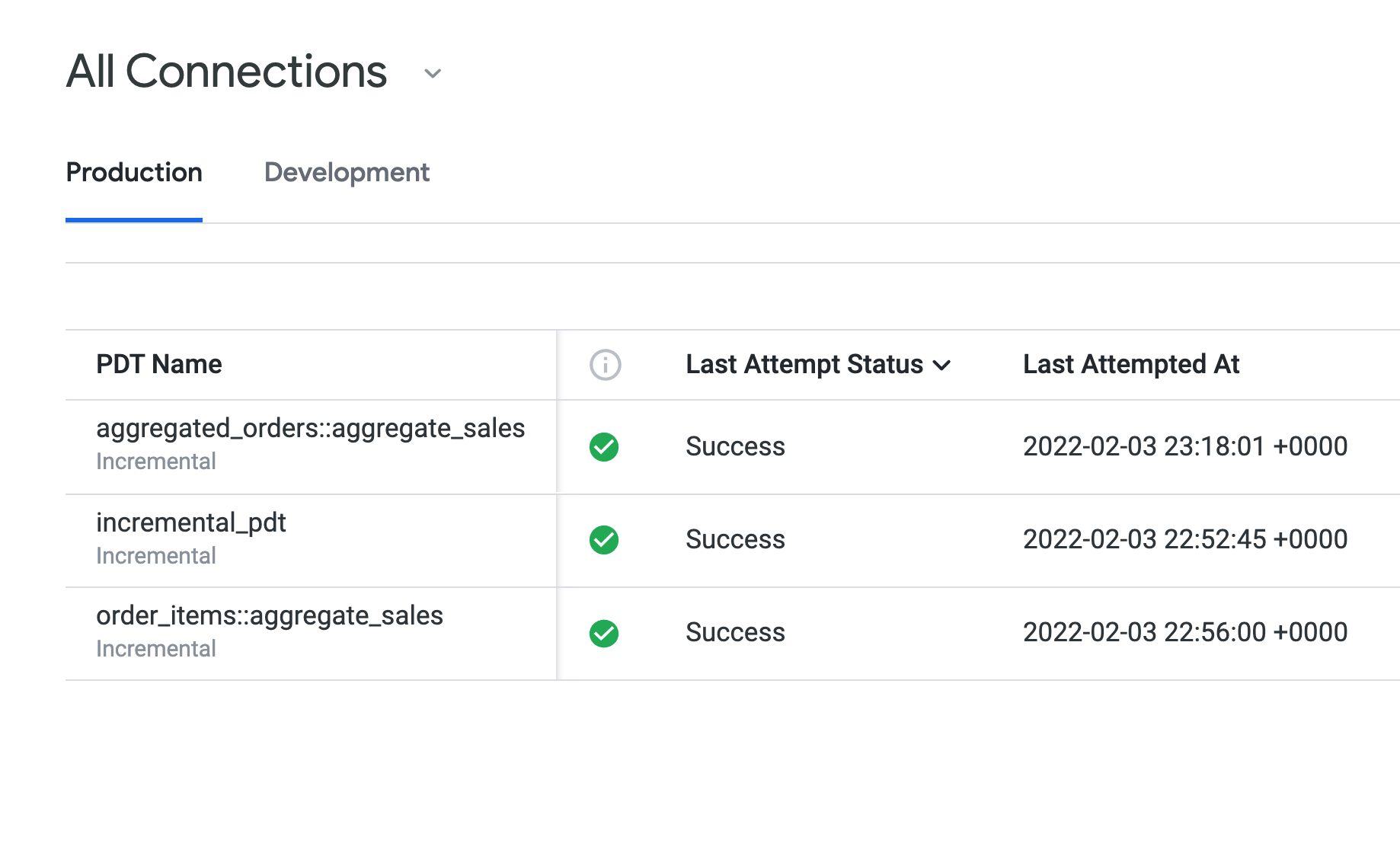
El Estado del último intento muestra Completado correctamente para todas las PDT, y todas usan la misma regla de persistencia (daily_datagroup). En el tiempo de compilación de Duración de la última compilación, puede que incremental_pdt tenga una compilación ligeramente más prolongada que las dos tablas de datos agregados.
Deja abierta esta página de Tablas derivadas persistentes mientras comienzas los siguientes pasos.
Modifica y revisa PDT en desarrollo
-
Regresa a la pestaña del navegador con el IDE de Looker.
-
Abre training_ecommerce.model.
-
Agrega una nueva dimensión para users.country a la exploración aggregated_orders (alrededor de la línea 96):
dimensions: [aggregated_orders.created_date, users.state, users.country]
-
Haz clic en Guardar cambios.
-
Regresa a la página Tablas derivadas persistentes y actualízala.
En la pestaña Producción, la PDT aggregated_orders::aggregate_sales aún aparece como compilada, aunque modificaste el código LookML la PDT en el Modo de desarrollo.
Looker permite que los desarrolladores prueben los cambios en las PDT en el Modo de desarrollo, de manera similar a como trabajarían con otros objetos de Looker en ese modo. Por ejemplo, cuando los desarrolladores crean nuevas dimensiones y mediciones en el Modo de desarrollo, estos nuevos objetos no se muestran en producción hasta que el desarrollador confirma los cambios y los implementa en producción.
- Abre la pestaña Desarrollo.
-
Deja abierta esta página de Tablas derivadas persistentes y abre una nueva pestaña de Looker en el navegador.
-
Navega a Exploración > Aggregate Sales.
-
En el panel Datos, abre la pestaña SQL.
-
En Usuarios > Dimensiones, selecciona Country.
-
En Aggregated Orders > Mediciones, selecciona lo siguiente:
- Average Sale Price
- Total Revenue
Hay dos consultas en la pestaña SQL: la primera genera la PDT y la segunda recupera los resultados de la PDT recién compilada.
-
Haz clic en Ejecutar.
-
Abre la pestaña Resultados para ver los resultados.
-
Cierra la pestaña del navegador de la consulta de exploración, vuelve a la pestaña con la página Tablas derivadas persistentes y actualízala.
En la pestaña Desarrollo, ahora se muestra que aggregated_orders::aggregate_sales se compiló correctamente.
-
Deja abierta la pestaña del navegador con la página Tablas derivadas persistentes y regresa a la pestaña del navegador con el IDE de Looker.
-
Haz clic en Validar LookML.
No hay errores de LookML.
Confirma los cambios y realiza la implementación en producción
-
Haz clic en Validar LookML y, luego, en Commit Changes & Push.
-
Agrega un mensaje de confirmación y haz clic en Confirmar.
-
Por último, haz clic en Implementar en producción.
Regresa a la pestaña del navegador con la página Tablas derivadas persistentes y actualízala. Ahora que los cambios en la producción se implementaron, la PDT aggregated_orders::aggregate_sales ya no aparece en la pestaña Desarrollo, sino solo en la pestaña Producción.
¡Felicitaciones!
En este lab, aprendiste cuándo y cómo agregar persistencia y actualizaciones incrementales a tablas derivadas, usar el reconocimiento de agregaciones, unir vistas de manera eficaz y supervisar las compilaciones de PDT para optimizar las consultas de Looker.
Próximos pasos y más información
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 23 de abril de 2024
Prueba más reciente del lab: 6 de octubre de 2023
Copyright 2026 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.





