GSP965

Panoramica
Le pipeline ti aiutano ad automatizzare e riprodurre il tuo workflow ML. Vertex AI integra le offerte ML di Google Cloud in un'esperienza di sviluppo fluida. In precedenza, i modelli addestrati con AutoML e i modelli personalizzati erano accessibili tramite servizi separati. Vertex AI combina entrambi in un'unica API, insieme ad altri nuovi prodotti. Vertex AI include anche una varietà di prodotti MLOps, come Vertex AI Pipelines. In questo lab imparerai a creare ed eseguire delle pipeline ML con Vertex AI Pipelines.
Perché le pipeline ML sono utili?
Prima di entrare nel dettaglio dell'argomento, capiamo innanzitutto perché potresti voler utilizzare una pipeline. Immagina di creare un workflow ML che includa l'elaborazione dei dati, l'addestramento di un modello, l'ottimizzazione degli iperparametri, la valutazione e il deployment del modello. Ciascuno di questi passaggi può avere dipendenze diverse, che potrebbero diventare difficili da gestire se consideri l'intero workflow come un monolite. Quando inizi a scalare il tuo processo ML, potresti voler condividere il tuo workflow ML con altri membri del tuo team in modo che possano eseguirlo e contribuire al codice. Senza un processo affidabile e riproducibile, questo può diventare difficile. Con le pipeline, ogni passaggio del processo ML è un container a sé stante. Ciò consente di sviluppare passaggi in modo indipendente e tenere traccia dell'input e output di ciascun passaggio in modo riproducibile. Puoi anche pianificare o attivare esecuzioni della pipeline in base ad altri eventi nel tuo ambiente Cloud, ad esempio quando sono disponibili nuovi dati di addestramento.
Obiettivi
In questo lab imparerai a:
- Utilizzare l'SDK Kubeflow Pipelines per creare pipeline ML scalabili
- Creare ed eseguire una pipeline introduttiva composta da 3 passaggi che accetta input di testo
- Creare ed eseguire una pipeline che addestra, valuta ed esegue il deployment di un modello di classificazione AutoML
- Utilizzare i componenti predefiniti per interagire con i servizi Vertex AI, forniti tramite la libreria google_cloud_pipeline_components
- Pianificare un job della pipeline con Cloud Scheduler
Configurazione e requisiti
Prima di fare clic sul pulsante Avvia lab
Leggi le seguenti istruzioni. I lab sono a tempo e non possono essere messi in pausa. Il timer si avvia quando fai clic su Inizia il lab e ti mostra per quanto tempo avrai a disposizione le risorse Google Cloud.
Con questo lab pratico avrai la possibilità di completare le attività in un ambiente cloud reale e non di simulazione o demo. Riceverai delle nuove credenziali temporanee che potrai utilizzare per accedere a Google Cloud per la durata del lab.
Per completare il lab, avrai bisogno di:
- Accesso a un browser internet standard (Chrome è il browser consigliato).
Nota: per eseguire questo lab, utilizza una finestra del browser in modalità di navigazione in incognito (consigliata) o privata. Ciò evita conflitti tra il tuo account personale e l'account studente, che potrebbero causare addebiti aggiuntivi sul tuo account personale.
- È ora di completare il lab: ricorda che, una volta iniziato, non puoi metterlo in pausa.
Nota: utilizza solo l'account studente per questo lab. Se utilizzi un altro account Google Cloud, potrebbero essere addebitati costi su quell'account.
Come avviare il lab e accedere alla console Google Cloud
-
Fai clic sul pulsante Avvia lab. Se devi effettuare il pagamento per il lab, si aprirà una finestra di dialogo per permetterti di selezionare il metodo di pagamento.
A sinistra, trovi il riquadro Dettagli lab con le seguenti informazioni:
- Il pulsante Apri la console Google Cloud
- Tempo rimanente
- Credenziali temporanee da utilizzare per il lab
- Altre informazioni per seguire questo lab, se necessario
-
Fai clic su Apri console Google Cloud (o fai clic con il tasto destro del mouse e seleziona Apri link in finestra di navigazione in incognito se utilizzi il browser Chrome).
Il lab avvia le risorse e apre un'altra scheda con la pagina di accesso.
Suggerimento: disponi le schede in finestre separate posizionate fianco a fianco.
Nota: se visualizzi la finestra di dialogo Scegli un account, fai clic su Usa un altro account.
-
Se necessario, copia il Nome utente di seguito e incollalo nella finestra di dialogo di accesso.
{{{user_0.username | "Username"}}}
Puoi trovare il Nome utente anche nel riquadro Dettagli lab.
-
Fai clic su Avanti.
-
Copia la Password di seguito e incollala nella finestra di dialogo di benvenuto.
{{{user_0.password | "Password"}}}
Puoi trovare la Password anche nel riquadro Dettagli lab.
-
Fai clic su Avanti.
Importante: devi utilizzare le credenziali fornite dal lab. Non utilizzare le credenziali del tuo account Google Cloud.
Nota: utilizzare il tuo account Google Cloud per questo lab potrebbe comportare addebiti aggiuntivi.
-
Fai clic nelle pagine successive:
- Accetta i termini e le condizioni.
- Non inserire opzioni di recupero o l'autenticazione a due fattori, perché si tratta di un account temporaneo.
- Non registrarti per le prove gratuite.
Dopo qualche istante, la console Google Cloud si apre in questa scheda.
Nota: per accedere ai prodotti e ai servizi Google Cloud, fai clic sul menu di navigazione o digita il nome del servizio o del prodotto nel campo Cerca.

Attività 1: apri il notebook in Vertex AI Workbench
-
Nella console Google Cloud, nel menu di navigazione ( ), fai clic su Vertex AI > Workbench.
), fai clic su Vertex AI > Workbench.
-
Trova l'istanza e fai clic sul pulsante Apri JupyterLab.
L'interfaccia JupyterLab per la tua istanza Workbench si apre in una nuova scheda del browser.
Nota: se non vedi i notebook in JupyterLab, segui questi passaggi aggiuntivi per reimpostare l'istanza:
1. Chiudi la scheda del browser per JupyterLab e torna alla home page di Workbench.
2. Seleziona la casella di controllo accanto al nome dell'istanza e fai clic su Reimposta.
3. Dopo che il pulsante Apri JupyterLab è stato riabilitato, attendi un minuto e poi fai clic su Apri JupyterLab.
Attività 2: configurazione di Vertex AI Pipelines
Per utilizzare Vertex AI Pipelines, devi installare alcune librerie aggiuntive:
-
Kubeflow Pipelines: questo è l'SDK utilizzato per creare la pipeline. Vertex AI Pipelines supporta l'esecuzione di pipeline create con Kubeflow Pipelines o TFX.
-
Google Cloud Pipeline Components: questa libreria fornisce componenti predefiniti che semplificano l'interazione con i servizi Vertex AI dai passaggi della pipeline.
Passaggio 1: crea un notebook Python e installa le librerie
- Fai clic sull'icona Python 3 per lanciare un nuovo notebook Python.
- Nella barra dei menu, fai clic con il tasto destro del mouse sul file
Untitled.ipynb e seleziona Rinomina notebook per assegnargli un nome significativo.
- Per installare entrambi i servizi necessari per questo lab, imposta prima il flag utente in una cella del notebook:
USER_FLAG = "--user"
- Poi esegui questo codice dal notebook:
%pip install $USER_FLAG google-cloud-aiplatform==1.59.0
%pip install $USER_FLAG kfp google-cloud-pipeline-components==0.1.1 --upgrade
%pip uninstall -y shapely pygeos geopandas
%pip install shapely==1.8.5.post1 pygeos==0.12.0 geopandas>=0.12.2
%pip install google-cloud-pipeline-components
Nota: se vedi avvisi ed errori relativi alle versioni, puoi ignorarli tranquillamente.
- Dopo aver installato questi pacchetti, devi riavviare il kernel:
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
- Infine, verifica di aver installato correttamente i pacchetti. La versione dell'SDK KFP deve essere uguale o superiore alla 1.6:
!python3 -c "import kfp; print('KFP SDK version: {}'.format(kfp.__version__))"
!python3 -c "import google_cloud_pipeline_components; print('google_cloud_pipeline_components version: {}'.format(google_cloud_pipeline_components.__version__))"
Passaggio 2: imposta l'ID progetto e il bucket
Durante questo lab, farai riferimento all'ID progetto Cloud e al bucket che hai creato in precedenza. Poi creerai le variabili per ciascuno di questi.
- Se non conosci l'ID progetto, potresti recuperarlo eseguendo questo comando:
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
- Adesso crea una variabile per archiviare il nome del bucket.
BUCKET_NAME="gs://" + PROJECT_ID + "-labconfig-bucket"
Passaggio 3: importa le librerie
- Aggiungi quanto segue per importare le librerie che utilizzerai in questo lab:
from typing import NamedTuple
import kfp
from kfp import dsl
from kfp.v2 import compiler
from kfp.v2.dsl import (Artifact, Dataset, Input, InputPath, Model, Output,
OutputPath, ClassificationMetrics, Metrics, component)
from kfp.v2.google.client import AIPlatformClient
from google.cloud import aiplatform
from google_cloud_pipeline_components import aiplatform as gcc_aip
Passaggio 4: definisci le costanti
- L'ultima cosa da fare prima di creare la pipeline è definire alcune variabili delle costanti.
PIPELINE_ROOT è il percorso Cloud Storage in cui verranno scritti gli artefatti creati dalla pipeline. Qui utilizzi come regione, ma se hai utilizzato un valore region diverso quando hai creato il bucket, devi aggiornare la variabile REGION nel codice riportato di seguito:
PATH=%env PATH
%env PATH={PATH}:/home/jupyter/.local/bin
REGION="{{{ project_0.default_region | Placeholder value. }}}"
PIPELINE_ROOT = f"{BUCKET_NAME}/pipeline_root/"
PIPELINE_ROOT
Dopo aver eseguito il codice in alto, dovresti visualizzare la directory principale della pipeline. Questa è la posizione di Cloud Storage in cui verranno scritti gli artefatti della pipeline. Sarà nel formato gs://<bucket_name>/pipeline_root/.
Attività 3: creazione della prima pipeline
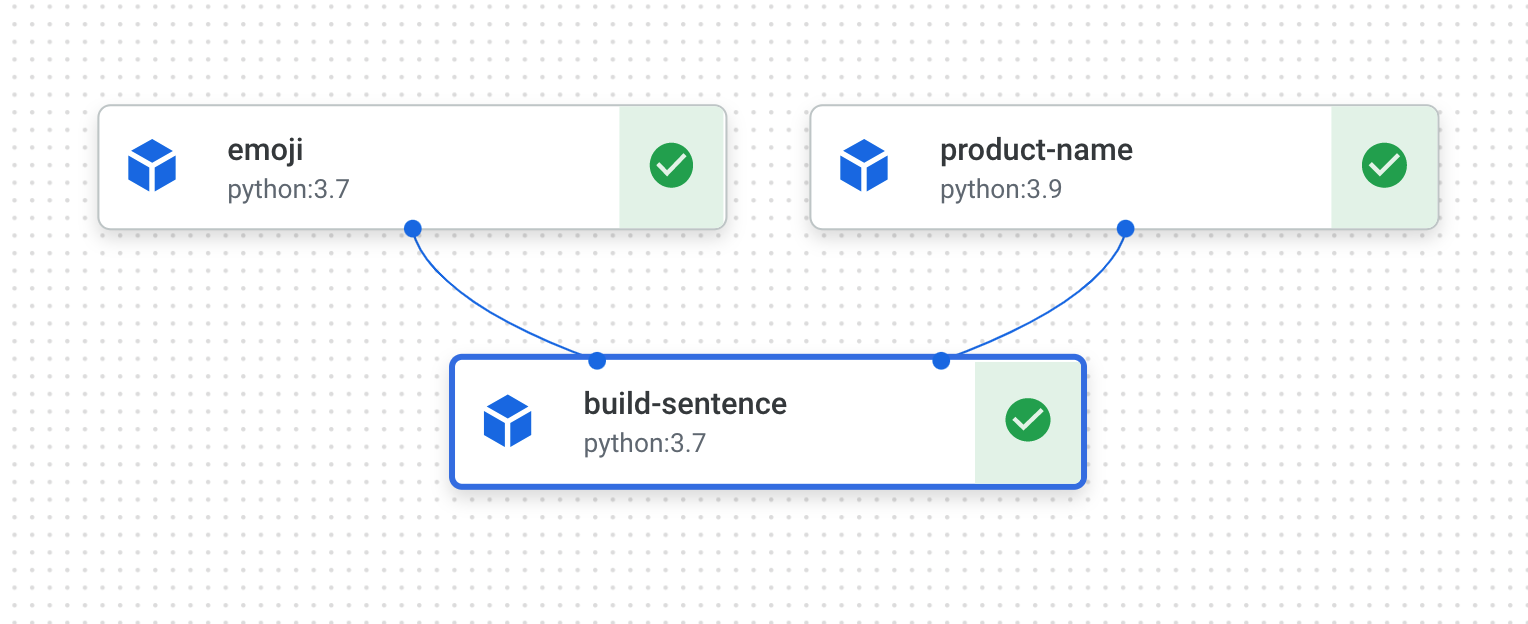
Creerai una pipeline che stampa una frase utilizzando due output: il nome di un prodotto e una descrizione con un'emoji. Questa pipeline sarà composta da tre componenti:
-
product_name: questo componente accetta un nome di prodotto come input e restituisce la stringa come output.
-
emoji: questo componente prende la descrizione testuale di un'emoji e la converte in un'emoji. Ad esempio, il codice di testo per ✨ è "sparkles". Questo componente utilizza una libreria di emoji per mostrare come gestire le dipendenze esterne nella pipeline.
-
build_sentence: questo componente finale utilizzerà l'output dei due precedenti per creare una frase che utilizzi l'emoji. Ad esempio, l'output risultante potrebbe essere "Vertex AI Pipelines è ✨".
Passaggio 1: crea un componente basato su una funzione Python
Utilizza l'SDK KFP per creare componenti basati su funzioni Python. Innanzitutto, crea il componente product_name, che accetta semplicemente una stringa come input e la restituisce.
- Aggiungi quanto segue al notebook:
@component(base_image="python:3.9", output_component_file="first-component.yaml")
def product_name(text: str) -> str:
return text
Analizza questa sintassi:
- Il decorator
@component compila questa funzione in un componente quando viene eseguita la pipeline. Lo utilizzerai ogni volta che scrivi un componente personalizzato.
- Il parametro
base_image specifica l'immagine del container che verrà utilizzata da questo componente.
- Il parametro
output_component_file è facoltativo e specifica il file YAML in cui scrivere il componente compilato. Dopo aver eseguito la cella, dovresti vedere il file scritto nell'istanza del notebook. Per condividere questo componente con qualcuno, potresti inviare il file YAML generato e chiedere di caricarlo con il seguente comando:
product_name_component = kfp.components.load_component_from_file('./first-component.yaml')
Il valore -> str dopo la definizione della funzione specifica il tipo di output per questo componente.
Passaggio 2: crea due componenti aggiuntivi
- Per completare la pipeline, crea altri due componenti. Il primo accetta una stringa come input e la converte nell'emoji corrispondente, se presente. Restituisce una tupla con il testo di input passato e l'emoji risultante:
@component(base_image="python:3.9", output_component_file="second-component.yaml", packages_to_install=["emoji"])
def emoji(
text: str,
) -> NamedTuple(
"Outputs",
[
("emoji_text", str), # Return parameters
("emoji", str),
],
):
import emoji
emoji_text = text
emoji_str = emoji.emojize(':' + emoji_text + ':', language='alias')
print("output one: {}; output_two: {}".format(emoji_text, emoji_str))
return (emoji_text, emoji_str)
Questo componente è un po' più complesso del precedente. Ci sono alcune novità:
- Il parametro
packages_to_install indica al componente le eventuali dipendenze da librerie esterne per questo container. In questo caso, utilizzi una libreria chiamata emoji.
- Questo componente restituisce una
NamedTuple chiamata Outputs. Nota che ogni stringa di questa tupla include le chiavi emoji_text ed emoji. Le utilizzerai nel componente successivo per accedere all'output.
- Il componente finale di questa pipeline utilizzerà l'output dei primi due e li combinerà per restituire una stringa:
@component(base_image="python:3.9", output_component_file="third-component.yaml")
def build_sentence(
product: str,
emoji: str,
emojitext: str
) -> str:
print("We completed the pipeline, hooray!")
end_str = product + " is "
if len(emoji) > 0:
end_str += emoji
else:
end_str += emojitext
return(end_str)
Potresti chiederti come fa questo componente a sapere che deve utilizzare l'output dei passaggi precedenti che hai definito.
Ottima domanda! Tutto sarà spiegato nel prossimo passaggio.
Passaggio 3: combina i componenti in una pipeline
Le definizioni dei componenti definite sopra hanno creato delle funzioni factory che possono essere utilizzate in una definizione di pipeline per creare i passaggi.
-
Per configurare una pipeline, utilizza il decorator @dsl.pipeline, assegna alla pipeline un nome e una descrizione e fornisci il percorso principale in cui devono essere scritti gli artefatti della pipeline. Per artefatti si intendono tutti i file di output generati dalla pipeline. Questa pipeline introduttiva non ne genera nessuno, mentre la prossima pipeline sì.
-
Nel blocco di codice successivo definisci una funzione intro_pipeline. Qui puoi specificare gli input per i passaggi iniziali della pipeline e il modo in cui i passaggi si connettono tra loro:
-
product_task accetta un nome prodotto come input. Qui stai passando "Vertex AI Pipelines", ma puoi modificarlo come preferisci.
-
emoji_task prende come input il codice di testo di un'emoji. Puoi anche modificarlo come preferisci. Ad esempio, "party_face" corrisponde all'emoji 🥳. Tieni presente che, poiché sia questo componente sia product_task non hanno passaggi che forniscono input, devi specificare manualmente l'input per questi componenti quando definisci la pipeline.
- L'ultimo passaggio della pipeline,
consumer_task, ha tre parametri di input:
- L'output di
product_task. Poiché questo passaggio produce un solo output, puoi farvi riferimento tramite product_task.output.
- L'output
emoji del passaggio emoji_task. Vedi il componente emoji definito sopra, dove hai assegnato un nome ai parametri di output.
- Lo stesso vale per l'output denominato
emoji_text del componente emoji. Se alla pipeline viene passato un testo che non corrisponde a un'emoji, questo testo verrà utilizzato per costruire una frase.
@dsl.pipeline(
name="hello-world",
description="An intro pipeline",
pipeline_root=PIPELINE_ROOT,
)
# You can change the `text` and `emoji_str` parameters here to update the pipeline output
def intro_pipeline(text: str = "Vertex AI Pipelines", emoji_str: str = "sparkles"):
product_task = product_name(text)
emoji_task = emoji(emoji_str)
consumer_task = build_sentence(
product_task.output,
emoji_task.outputs["emoji"],
emoji_task.outputs["emoji_text"],
)
Passaggio 4: compila ed esegui la pipeline
- Una volta definita la pipeline, puoi compilarla. Il seguente comando genererà un file JSON che utilizzerai per eseguire la pipeline:
compiler.Compiler().compile(
pipeline_func=intro_pipeline, package_path="intro_pipeline_job.json"
)
- Adesso crea un'istanza di un client API:
api_client = AIPlatformClient(
project_id=PROJECT_ID,
region=REGION,
)
- Infine, esegui la pipeline:
response = api_client.create_run_from_job_spec(
job_spec_path="intro_pipeline_job.json",
# pipeline_root=PIPELINE_ROOT # this argument is necessary if you did not specify PIPELINE_ROOT as part of the pipeline definition.
)
L'esecuzione della pipeline dovrebbe generare un link per visualizzare pipeline eseguita nella console. Al termine, dovrebbe avere l'aspetto seguente:
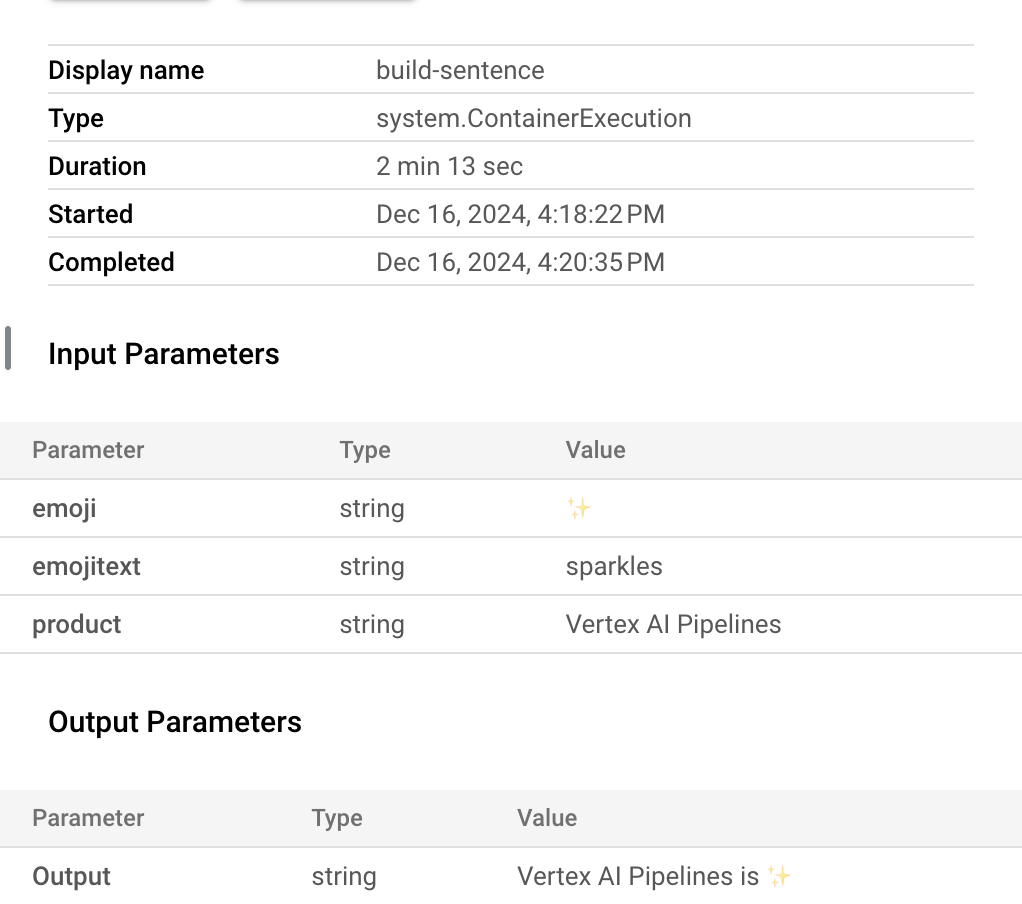
- L'esecuzione di questa pipeline richiede 5-6 minuti. Al termine, puoi fare clic sul componente
build-sentence per visualizzare l'output finale:
Ora che hai familiarità con il funzionamento dell'SDK KFP e di Vertex AI Pipelines, puoi generare una pipeline che crea ed esegue il deployment di un modello ML utilizzando altri servizi Vertex AI.
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Controlla se la pipeline delle emoji è stata completata
Attività 4: creazione di una pipeline ML end-to-end
È il momento di creare la tua prima pipeline ML. In questa pipeline, utilizzerai il set di dati UCI Machine Learning Dry Beans da KOKLU, M. e OZKAN, I.A., (2020), "Multiclass Classification of Dry Beans Using Computer Vision and Machine Learning Techniques."In Computers and Electronics in Agriculture, 174, 105507. DOI.
Nota: il completamento di questa pipeline richiederà più di 2 ore, perciò non dovrai attendere l'intera durata della pipeline per completare il lab. Segui i passaggi finché il job della pipeline non viene avviato.
Questo è un set di dati tabulare che utilizzerai nella pipeline per addestrare, valutare ed eseguire il deployment di un modello AutoML che classifica i bean in una di sette tipologie in base alle loro caratteristiche.
Questa pipeline:
- Crea un set di dati in Vertex AI
- Addestra un modello di classificazione tabulare con AutoML
- Ottiene le metriche di valutazione sulla base di questo modello
- In base alle metriche di valutazione, decide se eseguire il deployment del modello utilizzando la logica condizionale in Vertex AI Pipelines
- Esegue il deployment del modello su un endpoint utilizzando Vertex AI Prediction
Ciascuno dei passaggi descritti sarà un componente. La maggior parte dei passaggi della pipeline utilizzerà componenti predefiniti per i servizi Vertex AI tramite la libreria google_cloud_pipeline_components che hai importato in precedenza in questo lab.
In questa sezione, definiremo prima un componente personalizzato, quindi definiremo il resto dei passaggi della pipeline utilizzando componenti predefiniti. Questi semplificano l'accesso ai servizi Vertex AI, come l'addestramento e il deployment dei modelli.
La maggior parte del tempo per questo passaggio è dedicata alla fase di addestramento di AutoML di questa pipeline, che richiederà circa un'ora.
Passaggio 1: un componente personalizzato per la valutazione del modello
Il componente personalizzato che definirai verrà utilizzato verso la fine della pipeline, una volta completato l'addestramento del modello. Questo componente svolge alcune attività:
- Recupera le metriche di valutazione dal modello di classificazione AutoML addestrato
- Analizza le metriche e le visualizza nell'interfaccia utente di Vertex AI Pipelines
- Confronta le metriche con una soglia per determinare se eseguire il deployment del modello
Prima di definire il componente, comprendi i relativi parametri di input e output. Come input, questa pipeline accetta alcuni metadati nel progetto Cloud, il modello addestrato risultante (che definirai in un secondo momento), le metriche di valutazione del modello e un valore thresholds_dict_str.
thresholds_dict_str è un valore che definirai quando esegui la pipeline. Nel caso di questo modello di classificazione, si tratta dell'area sotto la curva ROC per cui devi eseguire il deployment del modello. Ad esempio, se inserisci 0,95, significa che vuoi che la pipeline esegua il deployment del modello solo se questa metrica è superiore al 95%.
Il componente di valutazione restituisce una stringa che indica se eseguire o meno il deployment del modello.
- Aggiungi quanto segue in una cella del notebook per creare questo componente personalizzato:
@component(
base_image="gcr.io/deeplearning-platform-release/tf2-cpu.2-3:latest",
output_component_file="tables_eval_component.yaml", # Optional: you can use this to load the component later
packages_to_install=["google-cloud-aiplatform"],
)
def classif_model_eval_metrics(
project: str,
location: str, # "region",
api_endpoint: str, # "region-aiplatform.googleapis.com",
thresholds_dict_str: str,
model: Input[Model],
metrics: Output[Metrics],
metricsc: Output[ClassificationMetrics],
) -> NamedTuple("Outputs", [("dep_decision", str)]): # Return parameter.
"""This function renders evaluation metrics for an AutoML Tabular classification model.
It retrieves the classification model evaluation generated by the AutoML Tabular training
process, does some parsing, and uses that info to render the ROC curve and confusion matrix
for the model. It also uses given metrics threshold information and compares that to the
evaluation results to determine whether the model is sufficiently accurate to deploy.
"""
import json
import logging
from google.cloud import aiplatform
# Fetch model eval info
def get_eval_info(client, model_name):
from google.protobuf.json_format import MessageToDict
response = client.list_model_evaluations(parent=model_name)
metrics_list = []
metrics_string_list = []
for evaluation in response:
print("model_evaluation")
print(" name:", evaluation.name)
print(" metrics_schema_uri:", evaluation.metrics_schema_uri)
metrics = MessageToDict(evaluation._pb.metrics)
for metric in metrics.keys():
logging.info("metric: %s, value: %s", metric, metrics[metric])
metrics_str = json.dumps(metrics)
metrics_list.append(metrics)
metrics_string_list.append(metrics_str)
return (
evaluation.name,
metrics_list,
metrics_string_list,
)
# Use the given metrics threshold(s) to determine whether the model is
# accurate enough to deploy.
def classification_thresholds_check(metrics_dict, thresholds_dict):
for k, v in thresholds_dict.items():
logging.info("k {}, v {}".format(k, v))
if k in ["auRoc", "auPrc"]: # higher is better
if metrics_dict[k] < v: # if under threshold, don't deploy
logging.info(
"{} < {}; returning False".format(metrics_dict[k], v)
)
return False
logging.info("threshold checks passed.")
return True
def log_metrics(metrics_list, metricsc):
test_confusion_matrix = metrics_list[0]["confusionMatrix"]
logging.info("rows: %s", test_confusion_matrix["rows"])
# log the ROC curve
fpr = []
tpr = []
thresholds = []
for item in metrics_list[0]["confidenceMetrics"]:
fpr.append(item.get("falsePositiveRate", 0.0))
tpr.append(item.get("recall", 0.0))
thresholds.append(item.get("confidenceThreshold", 0.0))
print(f"fpr: {fpr}")
print(f"tpr: {tpr}")
print(f"thresholds: {thresholds}")
metricsc.log_roc_curve(fpr, tpr, thresholds)
# log the confusion matrix
annotations = []
for item in test_confusion_matrix["annotationSpecs"]:
annotations.append(item["displayName"])
logging.info("confusion matrix annotations: %s", annotations)
metricsc.log_confusion_matrix(
annotations,
test_confusion_matrix["rows"],
)
# log textual metrics info as well
for metric in metrics_list[0].keys():
if metric != "confidenceMetrics":
val_string = json.dumps(metrics_list[0][metric])
metrics.log_metric(metric, val_string)
# metrics.metadata["model_type"] = "AutoML Tabular classification"
logging.getLogger().setLevel(logging.INFO)
aiplatform.init(project=project)
# extract the model resource name from the input Model Artifact
model_resource_path = model.uri.replace("aiplatform://v1/", "")
logging.info("model path: %s", model_resource_path)
client_options = {"api_endpoint": api_endpoint}
# Initialize client that will be used to create and send requests.
client = aiplatform.gapic.ModelServiceClient(client_options=client_options)
eval_name, metrics_list, metrics_str_list = get_eval_info(
client, model_resource_path
)
logging.info("got evaluation name: %s", eval_name)
logging.info("got metrics list: %s", metrics_list)
log_metrics(metrics_list, metricsc)
thresholds_dict = json.loads(thresholds_dict_str)
deploy = classification_thresholds_check(metrics_list[0], thresholds_dict)
if deploy:
dep_decision = "true"
else:
dep_decision = "false"
logging.info("deployment decision is %s", dep_decision)
return (dep_decision,)
Passaggio 2: aggiunta di componenti predefiniti di Google Cloud
In questo passaggio definirai il resto dei componenti della pipeline e vedrai come si combinano tra loro.
- Innanzitutto, definisci il nome visualizzato per l'esecuzione della pipeline utilizzando un timestamp:
import time
DISPLAY_NAME = 'automl-beans{}'.format(str(int(time.time())))
print(DISPLAY_NAME)
- Poi copia il seguente codice in una nuova cella del notebook:
@kfp.dsl.pipeline(name="automl-tab-beans-training-v2",
pipeline_root=PIPELINE_ROOT)
def pipeline(
bq_source: str = "bq://aju-dev-demos.beans.beans1",
display_name: str = DISPLAY_NAME,
project: str = PROJECT_ID,
gcp_region: str = "{{{ project_0.default_region | Placeholder value. }}}",
api_endpoint: str = "{{{ project_0.default_region | Placeholder value. }}}-aiplatform.googleapis.com",
thresholds_dict_str: str = '{"auRoc": 0.95}',
):
dataset_create_op = gcc_aip.TabularDatasetCreateOp(
project=project, display_name=display_name, bq_source=bq_source
)
training_op = gcc_aip.AutoMLTabularTrainingJobRunOp(
project=project,
display_name=display_name,
optimization_prediction_type="classification",
budget_milli_node_hours=1000,
column_transformations=[
{"numeric": {"column_name": "Area"}},
{"numeric": {"column_name": "Perimeter"}},
{"numeric": {"column_name": "MajorAxisLength"}},
{"numeric": {"column_name": "MinorAxisLength"}},
{"numeric": {"column_name": "AspectRation"}},
{"numeric": {"column_name": "Eccentricity"}},
{"numeric": {"column_name": "ConvexArea"}},
{"numeric": {"column_name": "EquivDiameter"}},
{"numeric": {"column_name": "Extent"}},
{"numeric": {"column_name": "Solidity"}},
{"numeric": {"column_name": "roundness"}},
{"numeric": {"column_name": "Compactness"}},
{"numeric": {"column_name": "ShapeFactor1"}},
{"numeric": {"column_name": "ShapeFactor2"}},
{"numeric": {"column_name": "ShapeFactor3"}},
{"numeric": {"column_name": "ShapeFactor4"}},
{"categorical": {"column_name": "Class"}},
],
dataset=dataset_create_op.outputs["dataset"],
target_column="Class",
)
model_eval_task = classif_model_eval_metrics(
project,
gcp_region,
api_endpoint,
thresholds_dict_str,
training_op.outputs["model"],
)
with dsl.Condition(
model_eval_task.outputs["dep_decision"] == "true",
name="deploy_decision",
):
deploy_op = gcc_aip.ModelDeployOp( # noqa: F841
model=training_op.outputs["model"],
project=project,
machine_type="e2-standard-4",
)
Che cosa succede in questo codice:
- Innanzitutto, come nella pipeline precedente, definisci i parametri di input accettati da questa pipeline. Devi impostarli manualmente perché non dipendono dall'output di altri passaggi della pipeline.
- Il resto della pipeline utilizza alcuni componenti predefiniti per interagire con i servizi Vertex AI:
-
TabularDatasetCreateOp crea un set di dati tabulare in Vertex AI la cui origine è in Cloud Storage o BigQuery. In questa pipeline, i dati vengono trasmessi tramite l'URL di una tabella BigQuery.
-
AutoMLTabularTrainingJobRunOp avvia un job di addestramento AutoML per un set di dati tabulare. A questo componente vengono passati alcuni parametri di configurazione, tra cui il tipo di modello (in questo caso di classificazione), alcuni dati sulle colonne, la durata dell'addestramento e un puntatore al set di dati. Tieni presente che per passare il set di dati a questo componente, stai fornendo l'output del componente precedente tramite dataset_create_op.outputs["dataset"] .
-
ModelDeployOp esegue il deployment di un modello specifico su un endpoint in Vertex AI. Sono disponibili altre opzioni di configurazione, ma qui devi fornire il tipo di macchina endpoint, il progetto e il modello che vuoi eseguire il deployment. Per passare il modello, accedi agli output del passaggio di addestramento nella pipeline.
- Questa pipeline utilizza anche la logica condizionale, una funzionalità di Vertex AI Pipelines che consente di definire una condizione, insieme a branche diversi in base al risultato della condizione. Ricorda che, quando hai definito la pipeline, hai passato un parametro
thresholds_dict_str. Questa è la soglia di accuratezza che consente di determinare se eseguire il deployment del modello in un endpoint. Per implementarla, utilizza la classe Condition dell'SDK KFP. La condizione trasmessa è l'output del componente di valutazione personalizzato che hai definito in precedenza in questo lab. Se questa condizione è vera, la pipeline continuerà a eseguire il componente deploy_op. Se l'accuratezza non soddisfa la soglia predefinita, la pipeline si interrompe qui e non esegue il deployment di un modello.
Passaggio 3: compila ed esegui la pipeline ML end-to-end
- Una volta definita la pipeline completa, è il momento di compilarla:
compiler.Compiler().compile(
pipeline_func=pipeline, package_path="tab_classif_pipeline.json"
)
- Ora avvia l'esecuzione di una pipeline:
response = api_client.create_run_from_job_spec(
"tab_classif_pipeline.json", pipeline_root=PIPELINE_ROOT,
parameter_values={"project": PROJECT_ID,"display_name": DISPLAY_NAME}
)
- Fai clic sul link mostrato dopo aver eseguito la cella precedente per visualizzare la pipeline nella console. L'esecuzione di questa pipeline richiederà poco più di un'ora. La maggior parte del tempo viene impiegata nella fase di addestramento di AutoML. La pipeline completata avrà un aspetto simile a questo:
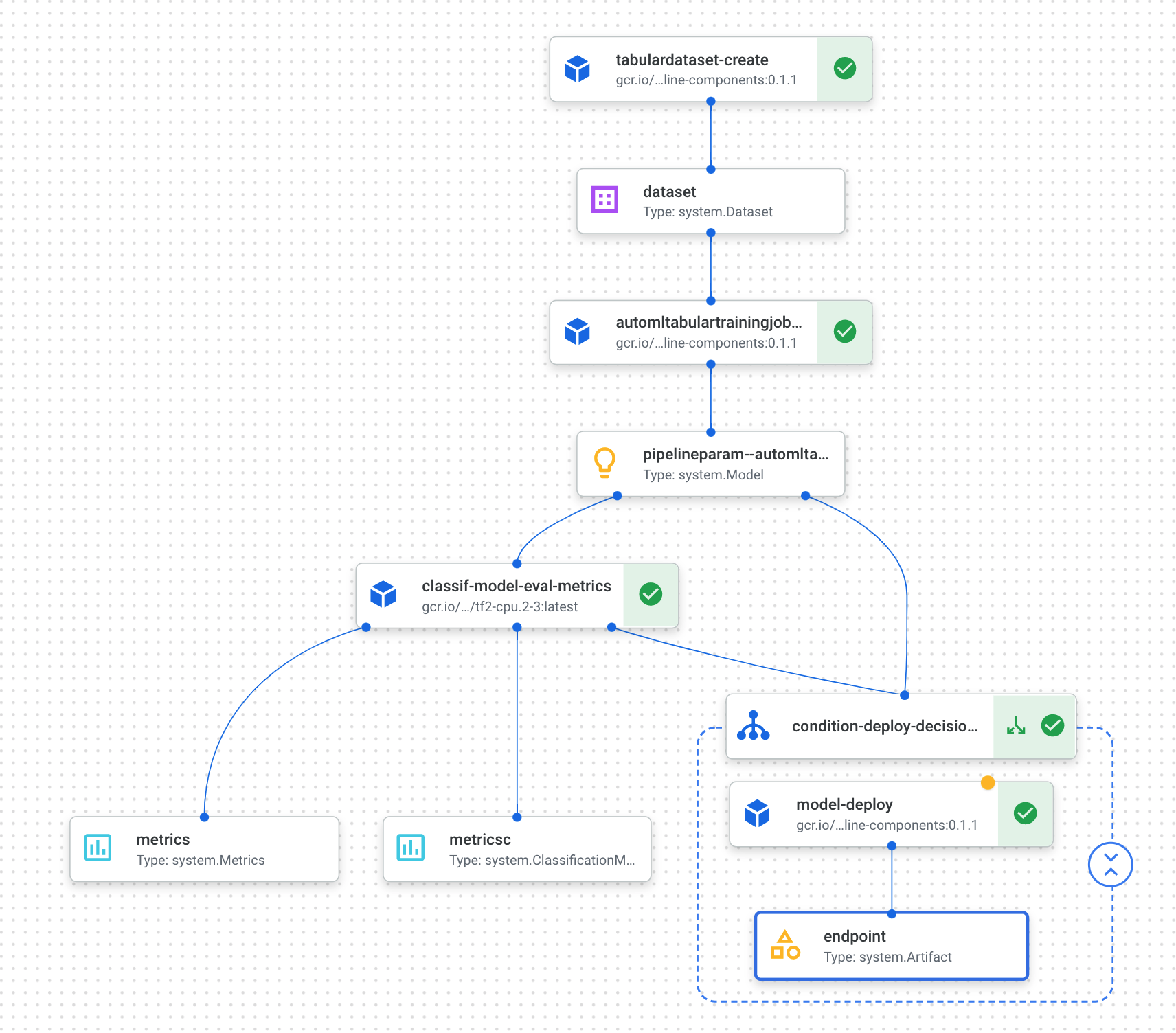
- Se attivi il pulsante "Espandi artefatti" in alto, potrai visualizzare i dettagli dei diversi artefatti creati dalla pipeline. Ad esempio, se fai clic sull'artefatto
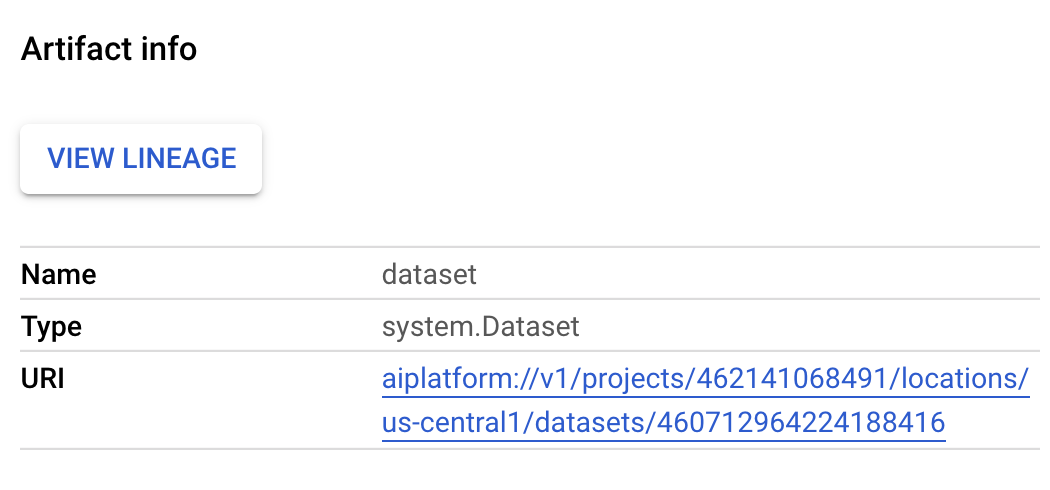
dataset, vedrai i dettagli del set di dati Vertex AI creato. Puoi fare clic sul link qui per andare alla pagina del set di dati:
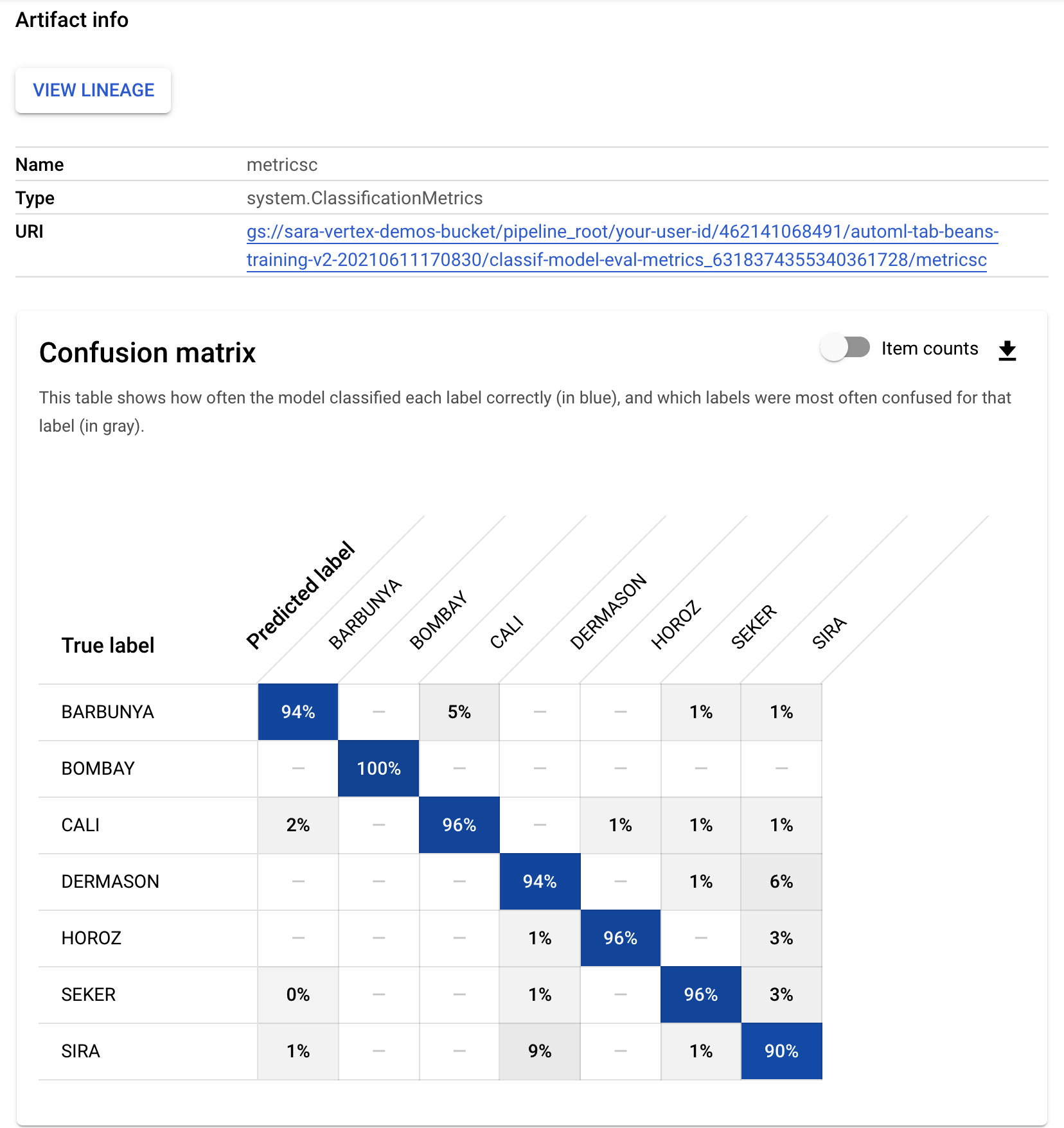
- Allo stesso modo, per vedere le visualizzazioni delle metriche risultanti dal componente di valutazione personalizzato, fai clic sull'artefatto denominato metricsc. Sul lato destro della dashboard, potrai vedere la matrice di confusione per questo modello:
- Per visualizzare il modello e l'endpoint creati da questa esecuzione della pipeline, vai alla sezione dei modelli e fai clic sul modello denominato
automl-beans. Dovresti visualizzare il modello di cui è stato eseguito il deployment in un endpoint:
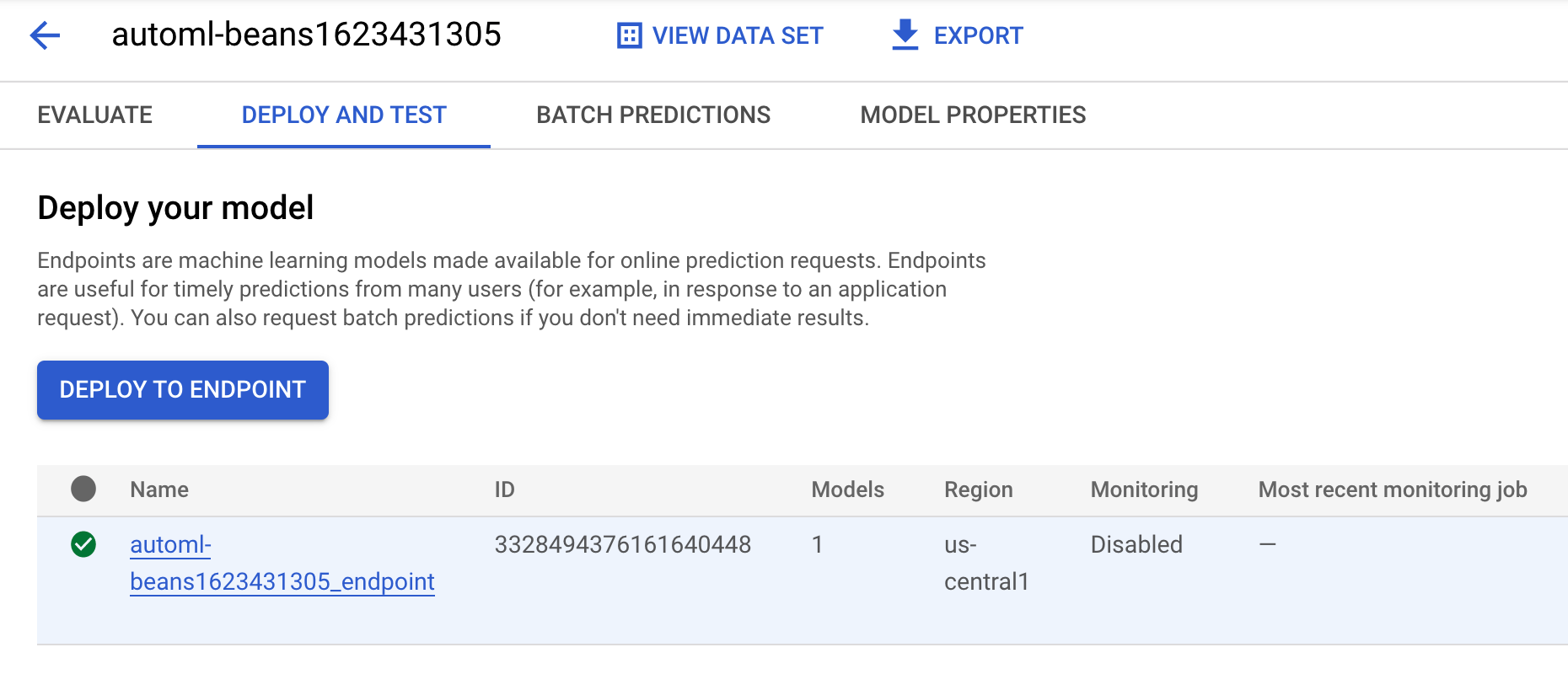
-
Puoi accedere a questa pagina anche facendo clic sull'artefatto endpoint nel grafico della pipeline.
-
Oltre a esaminare il grafico della pipeline nella console, puoi utilizzare Vertex AI Pipelines anche per il monitoraggio della derivazione.
-
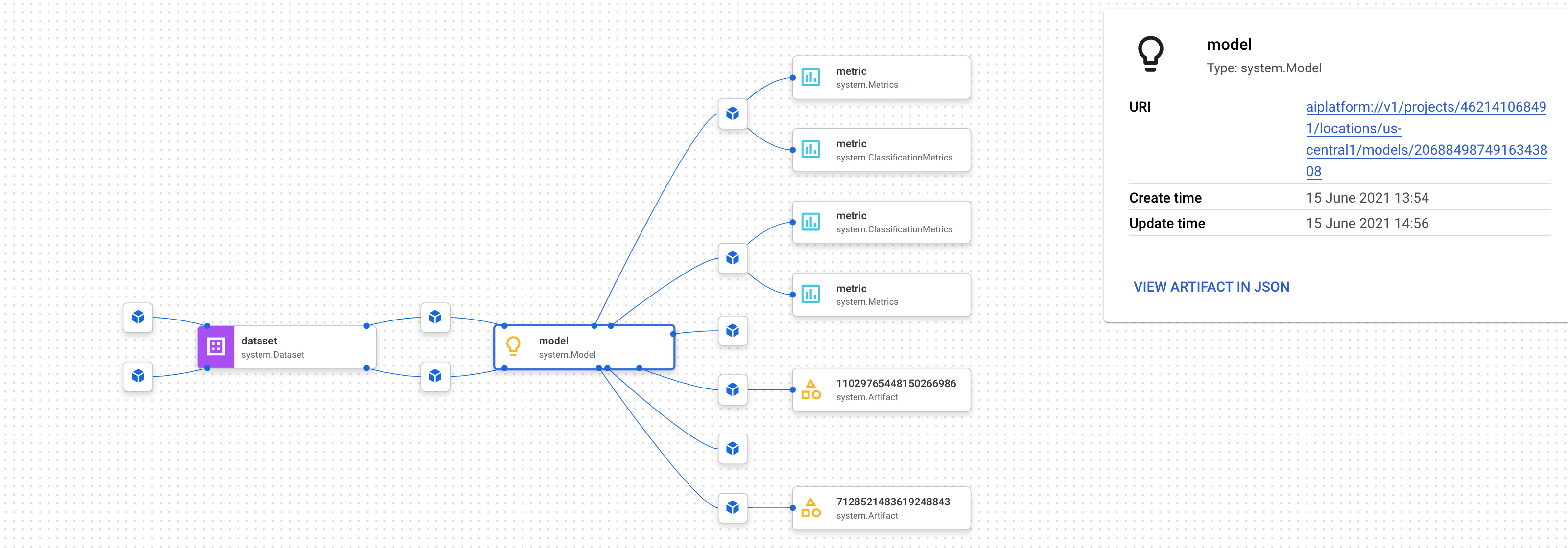
Il monitoraggio della derivazione consiste nel monitorare gli artefatti creati durante la pipeline. In questo modo puoi capire dove sono stati creati gli artefatti e come vengono utilizzati in un workflow ML. Ad esempio, per vedere il monitoraggio della derivazione per il set di dati creato in questa pipeline, fai clic sull'artefatto del set di dati e poi su Visualizza derivazione:
Vengono visualizzati tutte le posizioni in cui viene utilizzato questo artefatto:
Nota: attendi l'avvio del job di addestramento nella pipeline, quindi controlla i tuoi progressi di seguito. Il job di addestramento richiederà più tempo di quello assegnato per questo lab, ma ti verranno assegnati tutti i punti per l'invio del job di addestramento.
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Controlla se il job di addestramento della pipeline ML end-to-end è stato avviato
Passaggio 4: (facoltativo) confronta le metriche tra le esecuzioni della pipeline
- Se esegui questa pipeline più volte, potresti voler confrontare le metriche tra le varie esecuzioni. Puoi utilizzare il metodo
aiplatform.get_pipeline_df() per accedere ai metadati dell'esecuzione. Qui recupereremo i metadati per tutte le esecuzioni di questa pipeline e li caricheremo in un DataFrame Pandas:
pipeline_df = aiplatform.get_pipeline_df(pipeline="automl-tab-beans-training-v2")
small_pipeline_df = pipeline_df.head(2)
small_pipeline_df
Hai imparato a creare, eseguire e recuperare i metadati per una pipeline ML end-to-end su Vertex AI Pipelines.
Complimenti!
In questo lab hai creato ed eseguito una pipeline con emoji. Hai anche imparato a creare, eseguire e recuperare i metadati per una pipeline ML end-to-end su Vertex AI Pipelines.
Passaggi successivi/Scopri di più
Prova lo stesso scenario in un tuo progetto Google Cloud utilizzando il codelab di Developer Relations.
Formazione e certificazione Google Cloud
… per utilizzare al meglio le tecnologie Google Cloud. I nostri corsi ti consentono di sviluppare competenze tecniche e best practice per aiutarti a metterti subito al passo e avanzare nel tuo percorso di apprendimento. Offriamo vari livelli di formazione, dal livello base a quello avanzato, con opzioni di corsi on demand, dal vivo e virtuali, in modo da poter scegliere il più adatto in base ai tuoi impegni. Le certificazioni ti permettono di confermare e dimostrare le tue abilità e competenze relative alle tecnologie Google Cloud.
Ultimo aggiornamento del manuale: 3 gennaio 2025
Ultimo test del lab: 3 gennaio 2025
Copyright 2025 Google LLC. Tutti i diritti riservati. Google e il logo Google sono marchi di Google LLC. Tutti gli altri nomi di società e prodotti sono marchi delle rispettive società a cui sono associati.





